
基于用户云服务集群的资源动态调度研究∗
2023-10-20 08:23陈庆奎
计算机与数字工程 2023年7期
马 龙 陈庆奎
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
近年来,由于云计算的稳步发展。云服务设备有着可按需配置的便捷性以及廉价的优势得到了公司和企业的青睐[1]。越来越多的公司和企业抛弃传统的服务器设施,将服务集群部署在云服务器上[2]。
然而,用户(公司和企业)购买云服务器并将传统的基础设施服务器集群迁移到云服务器上后,很多程度上都没有最大化利用购买的资源[3~4]。据调查显示,用户购买的云服务器设备的CPU利用率和内存的利用率经常达不到50%[5~6]。
现有的很多研究是为了提高云服务器平台的整体资源利用率,将用户的闲置资源利用起来,从而降低云服务器提供商的成本[7~13]。而站在用户角度,用户购买了云服务器的计算资源后,如何最大化利用这些自己的计算资源是一个值得研究和有意义课题。当用户集群(用户购买的多个计算节点形成的集合)中配置的某些服务发生大规模访问时,可以动态调整这些服务在用户集群中的分配和并行运行的数量,以便充分利用用户购买的其他计算节点上的空闲资源,达到集群私有资源的有效利用。用户无需再购买多余的计算节点就可以适应峰值服务访问,从而节约用户的成本。
为了解决上述问题,本文基于对用户集群计算资源的使用和集群中应用的调度方案进行研究。在用户集群中加入了集群监控模块和动态资源调度模块,来调度用户集群中的应用服务的配置和启动,例如在www 服务器访问峰值的时候,可以动态配置多个以上的节点作为www服务器,而在访问低谷的时期可以将www 服务器减少为单个。为了实现集群中应用的动态配置和优化,我们在对用户集群服务器监控的数据资源进行研究后,基于TOPSIS 算法[14~16]提出了一个新的集群调度策略。实验表明,在发生峰值访问时,通过这些模块的监控和调度,用户集群可以适应突发的大规模访问并且提高用户服务器整体的资源利用率。
2 模型设计
本方案中,系统的整体结构图如图1 所示。部署在节点上的监控模块采集节点中的节点数据,并将数据传输给数据处理节点,数据处理节点会对源数据进行处理分析并为调度模块提供数据支持,最后动态调度模块结合监控数据和历史数据动态的调度集群中节点中的应用。
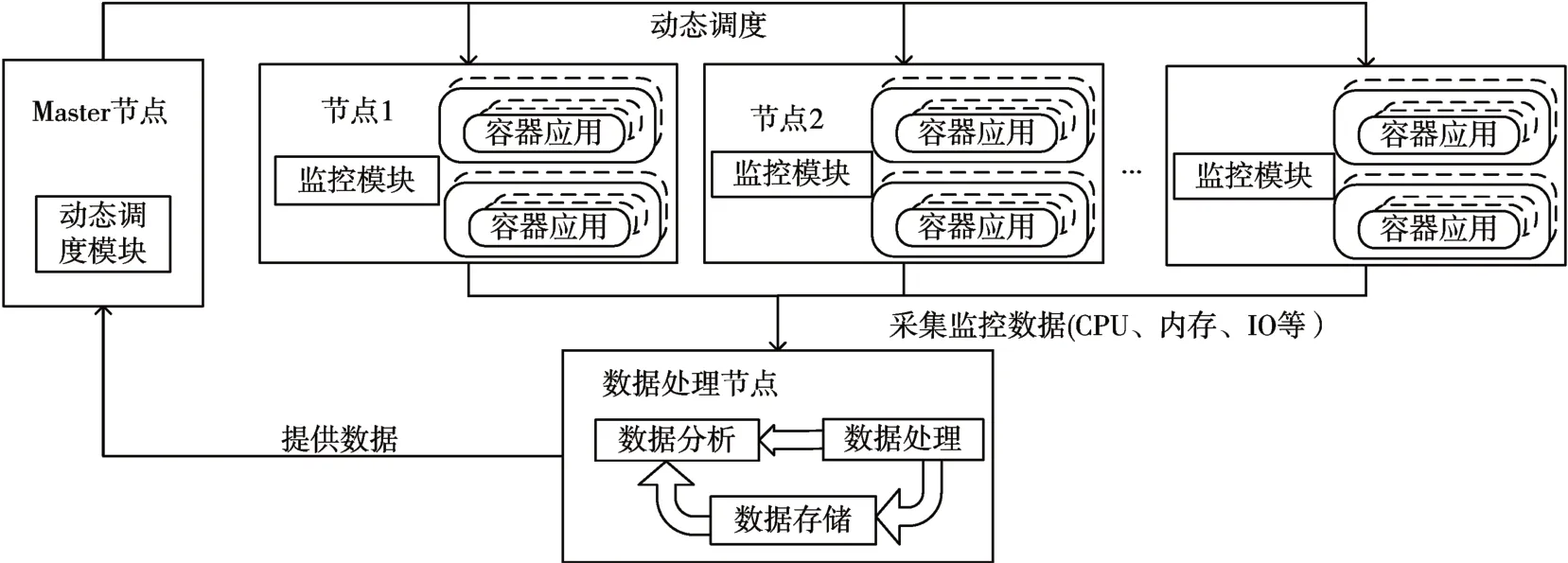
图1 整体模型
监控模块:监控模块部署在每个集群节点中。除了像传统监控方案一样采集节点的系统信息,包括不限于CPU使用率、内存使用率、网络和磁盘I/O等参数外,监控模块还需采集各节点中运行各应用实例的个数以及单位时间内访问各个应用的次数,监控模块采集的原始数据信息传输到数据处理节点。
数据处理节点:负责将采集的原始监控数据处理后,变成易于分析的二元时间序列资源组nodeR(CPU 信息、内存信息、磁盘IO…)。其中每一项可用如下资源组表示,如nodeRScpu(cpu主频、cpu 核心数、cpu 利用率、cpu 空闲率)、nodeRSmemory(内存大小、可用内存、内存利用率)、nodeRSIO(每秒IO 数、吞吐量、磁盘利用率)等。数据处理节点以接口的形式来提供监控数据的实时访问,可以对接数据库对数据进行持久化存储。
资源调度模块:该模块负责通过本文中的调度算法选出最优的节点,并将应用合理的增加或者减少在对应的节点上。合适的分配应用在节点中的部署,最大化利用用户集群的私有计算资源。
3 关键技术
3.1 监控模块
如图2 所示,监控模块部署在节点中进行数据采集,除了收集各个节点的时序资源使用情况外,还特别记录节点中各应用的每秒对外访问次数。这些数据以供动态调度模块进行计算使用。

图2 监控模型
Prometheus 是一个开源的监控系统[16],它在记录纯数字时间序列方面表现得非常好,它既适用于面向服务器等硬件指标性能,也适用于高动态的服务架构监控。本文选用Prometheus 作为数据处理模块,Prometheus 将所有监控数据进行处理分析,将数据转化为调度模块所需要的时间序列数据,并将数据对外以Rest Api形式提供数据访问。
3.2 资源敏感度计算
根据数据处理节点提供的历史数据,分析应用App在所有节点上的单位时间内的访问次数记为xi,并记录此时节点上应用所占用的整体资源百分比为Rcpui,Rmemoryi,RIOi,每一类计算资源可得到对应的数据组(x1,r1),(x2,r2)…(xn,rn),由于数据分布为线性分布,故将数据按式(1)进行线性回归分析可得到回归系数̂。可计算出对应资源的回归系数
其中ri是实际测量值,是测量的平均值;xi是实际测量值,为测量的资源百分比的均值。̂的大小反应了该应用对相应计算资源的敏感程度。
规定资源的回归系数大于ϑ,则规定应用App对此资源敏感(即随着应用App的对外单位时间访问增加,该应用会更易占用大量的此资源)。
3.3 调度模块
本文使用“类似于理想解决方案的优先级排序技术”(TOPSIS)算法,并结合需要调度的应用对系统资源的敏感程度提出了一种调度策略。该调动策略分为三个阶段:第一阶段为节点预选;第二阶段为节点优选;第三阶段执行应用调度。
假设需要增加的应用所需的计算资源为资源组pod(rcpu,rmemeory,…) ,集群中共有N个应用节点。
算法1.调度策略
1)输入:节点资源信息集合nodeR,所需资源组pod
2)输出:最佳的节点nodej
3)forifrom 1 toN:
4) 判断nodeRi中每一项剩余资源是否满足pod
5) 若满足则加入集合η
6)end for
7)通过改进的TOPSIS算法筛选节点集合η得到nodej
8)returnnodej
如算法1 第3 行~6 行所示,我们的调度策略的原理是,首先过滤基础设施的所有节点,判断节点资源组Node(rcpu,rmemory…)中的每一项是否都能满足资源组pod,保留能够执行应用的节点并加入集合η,此时完成第一阶段预选。然后通过算法1第7行~8行从节点中选择最佳节点来部署应用。
第二阶段基于TOPSIS 算法进行筛选,通过计算选择一个与最佳解距离最短、与最差解距离最远的解(节点)。筛选出的此节点即为最优的调度节点。
调度算法具体流程如下,我们假设通过了第一轮筛选的集合η中有n个节点,为了选择到最佳的节点,我们将对这n个节点使用m个资源标准进行筛选。
1)构建节点资源决策矩阵(DM)。矩阵中的每一行node(f11,f12…f1m)表示某节点中的剩余可用资源组Node(rcpu,rmemory…)。矩阵的行数为节点的个数n,列数为评测节点的m个资源标准(cpu,memory,IO…)。因此,矩阵中的fij代表第i个节点中剩余可利用j资源的数值,若f12=60,则表示第一个节点第二类可用资源为60%。
由于应用可能对单一资源依赖,故需根据资源敏感度数据计算修正后的DM':
其中k为该应用在nodei上的运行个数,资源敏感度由式(1)计算得到,目的是使得对资源敏感的应用尽量均匀分布在Node集群节点中。
2)通过式(3)、(4)带入式(2)中计算,得到节点资源归一化决策矩阵(NDM)。
3)计算加权归一化决策矩阵(WNDM)。加权归一化值vij的计算方式如式(6)所示:
公式中wj表示的是第j个标准所占的权重而且
4)根据权重格式化的值来确定理想解(S+)和最差的解(S-)。
式中I+表示正向标准,比如剩余CPU 资源、剩余内存资源、带宽、CPU 核心数等;I-表示反向标准,比如,IO占用率等。
5)分别计算当中的n个节点与理想节点和最差节点的距离尺度,即每个节点到最优解的距离SM+和最差结果的距离SM-,使用n维度欧式距离来计算,如式(10)~(11)所示:
6)式(12)计算理想贴近度Ci:
最后将节点根据理想解的贴近度大小进行排序,排序结果贴近度值越大,说明目标越优,将优先在此节点中分配需要增加的应用。而贴近度值越小,说明该节点上的资源最紧张,会优先减少该节点上的应用。
4 实验与结果分析
4.1 实验环境和实验计划
本次实验中,我们使用了四台阿里云服务器,一台作为Master 节点,配置为1CPU(1000m CPU =1CPU)内存为1GB。其他三台作为应用节点每台处理器的计算资源为2CPU,内存为4GB,硬盘为256G 构建用户集群。分别在使用默认的集群方案和本文的集群方案进行实验测试。四台服务器运行的应用如表1所示。

表1 服务器配置和节点角色
构建应用所需要的计算资源如表2所示。
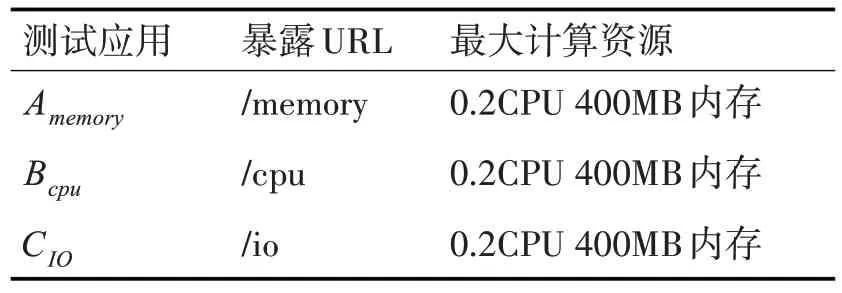
表2 构建应用所需计算资源
“/memory”每次访问会建立一个10KB 的数组并在40s 后释放数组占用的内存空间和对象;“/cpu”应用执行一些CPU 密集型计算且占用很少的内存资源;“/io”应用每次请求将做一些磁盘IO 的操作,并将占用较多cpu和内存资源,持续20s。
使用Jmeter 压力测试工具[17]创建第一个测试应用Test1。Test1测试计划:
1)在集群中添加一个CIO;
2)使用Jmeter 启动一个有1000 个线程的线程组A,在1min 内完成启动,然后线程组开始访问应用memory,时间间隔为1s,持续时间为300s。
第二个测试应用Test2,测试程序计划:
1)使用Jmeter 创建一个有500 个线程的线程组B,和一个有100个线程的线程组C,在1min内完成启动。
2)然后线程组B 和C 开始分别访问应用/memory、/cpu和/io,时间间隔为1s,持续时间为200s。
4.2 性能评估
在改进前后的集群中分别部署这两个测试应用。首先让应用Test1 在改进后的集群中运行,集群的内存剩余百分比情况和应用A 在集群中的个数如图3 所示。图中可以看到集群充分利用了集群中的空闲资源来创建更多的应用A,从而使应用A 能够一直保持健康的运行状态。从图4 可以看到,应用A通过使用本文的调度算法均匀的分布在各节点中,从而尽可能地避免应用对单一资源的竞争,使应用访问速度得到来提高。

图3 集群剩余内存百分比和应用A数量
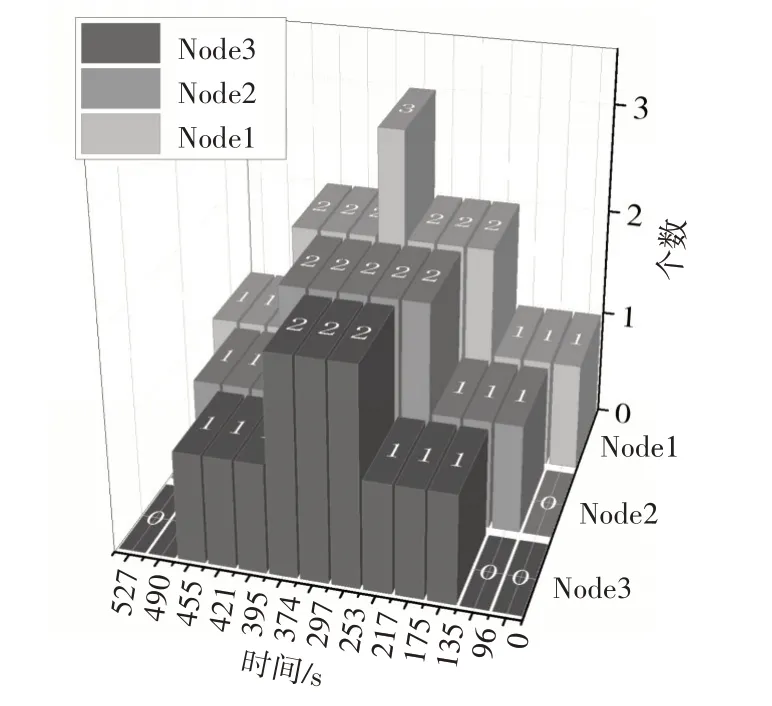
图4 应用A在各节点上分布图
然后让应用A和应用TestB在同时改进前后的集群中运行,记录集群中的应用数量。如图5 所示,在改进后的集群中,当应用负载增加时,改进的集群可以通过负载情况增加或减少相应的应用实例个数,且增加的集群按照本文的调度方案被均匀的分布在了节点中。而在改进前的用户集群中,如图6 所示,随着测试应用的持续访问,改进前的集群在一段时间后由于内存不足导致节点中应用重启,在测试阶段中出现了三次OOM 异常,用户节点的内存利用率不到30%。而在改进后的集群中,随着访问的增多,通过我们的调度方案,用户集群的CPU利用率、内存利用率得到了明显的提高。随着访问峰值过后,调度模块开始减少集群中的应用数量,最后访问停止后,集群中的应用数量恢复至最初状态。

图5 各应用在集群中的总个数
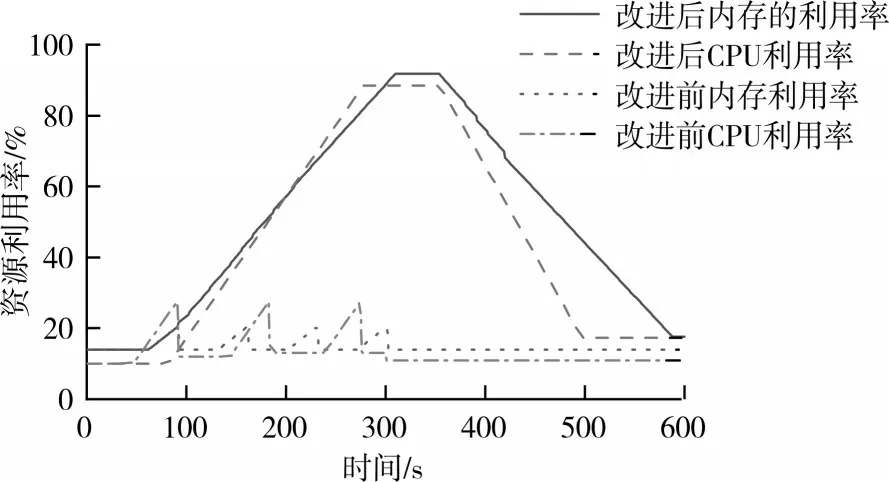
图6 Test2运行时集群各资源利用率
如表3 所示,应用Test2 在改进前后的集群上分别发送了约495000 次请求,在改进前的集群中运行时出现了资源不足的错误而导致平均72.42%的请求都是错误的,而在改进后的集群中,平均响应时间为17ms,且均访问成功。
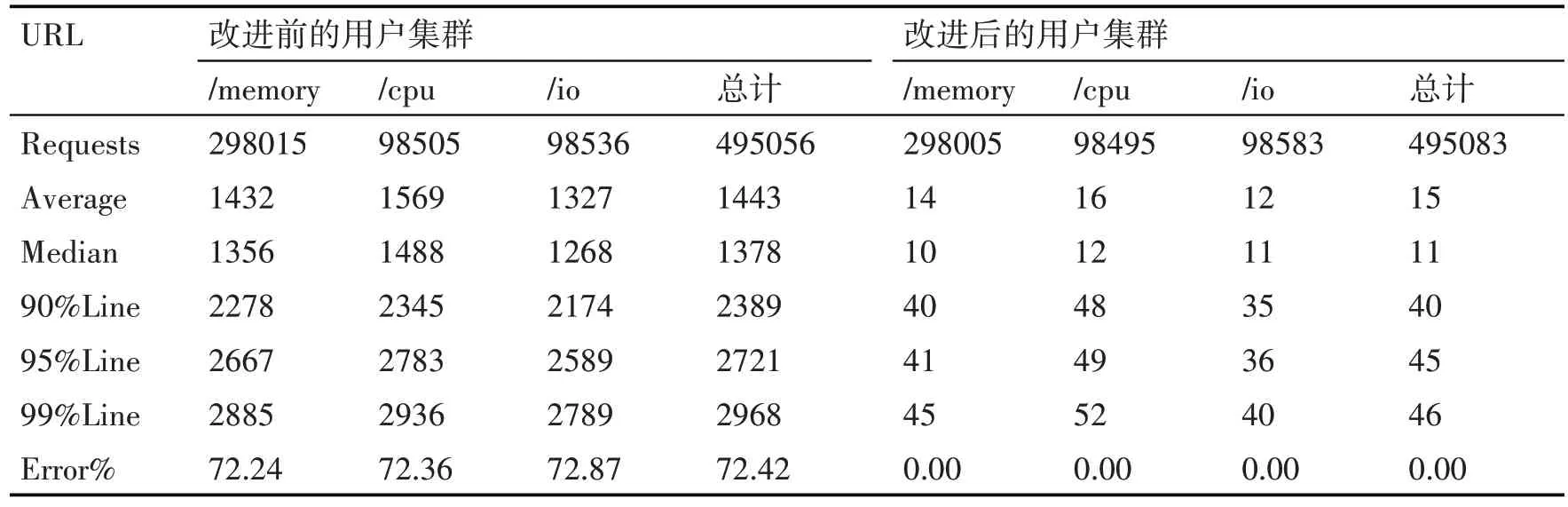
表3 改进前后系统响应状态对照表
5 结语
本文在用户的角度下,基于用户服务集群加入了监控、调度系统,并考虑到集群资源的动态变化以及节点中应用对系统资源的敏感程度,提出了一种基于TOPSIS 算法的动态调度算法。通过本文对用户集群的改进,集群在面对大规模访问时在保证QOS的同时无需购买额外的云服务器设施,大大提高了用户集群资源的利用率,节省了用户的成本。本文提供的方案虽然通过了实验时的各种测试,但考虑到真实的生产环境中的环境会更加恶劣。未来的工作将结合真实的生产环境中进一步研究和优化模型的准确性。
猜你喜欢
高技术通讯(2021年5期)2021-07-16
科学技术创新(2021年18期)2021-06-23
微型电脑应用(2019年10期)2019-10-23
军事运筹与系统工程(2019年4期)2019-09-11
当代陕西(2019年13期)2019-08-20
电子制作(2018年11期)2018-08-04
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
