
基于改进SVM 算法的输变电工程异常数据检测方法设计
2023-10-05 08:10靳书栋刘宏志
电子设计工程 2023年19期
靳书栋,李 彦,刘宏志,康 方
(国网山东电力经济技术研究院,山东济南 250021)
随着数字化与信息化技术的发展,全球的数据信息资源正在迅速增长,这也推进了各个领域的数字化进程。与此同时,我国电网的建设投资正逐年增加。故对电网工程造价数据加以监测,在保障工程质量、提高工程建设的智能程度等方面均具有重要意义[1-4]。电网工程异常数据的检测问题,本质上就是数据的分类问题。对于该问题而言,拥有足够数量的标记数据是获得满意学习性能的前提。在众多的实际应用中通常较易获得大量未标记的样本,而对其进行标记则需要较大的成本开销,所以主动学习更适用于此类应用场景。目前的研究中已提出了诸多主动学习的方法,包括单模式及批处理模式。在单模式主动学习中,分类器选择单个样本并在每一轮学习中查询其标签。而对于单模式主动学习而言,每次选择和标记新样本时均要重新训练分类模型,这是一项复杂的工作。
该文针对工程造价的异常数据检测这一应用场景,提出了一种基于改进SVM 的主动学习方法。考虑到数据的不确定性、多样性及代表性,且无需交换节点间的信息,该方法引入了随机预选的策略,并根据基于BIM 模型(Building Information Modeling)的建筑数据进行了分析验证。
1 工程数据估算系统设计
图1 为该文设计的基于BIM 的数据估算系统。
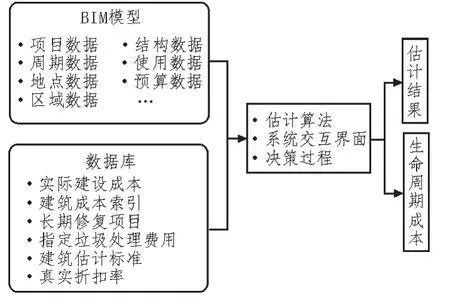
图1 基于BIM的数据估算系统
该系统具有以下功能:
1)模型信息与基于BIM 的项目估计原型相连接,进而可以从资源库服务器中提取项目大纲与BIM 模型的基本信息。
2)具有性能成本、参考数据的数据库以及成本估计算法。
3)根据现场工程数据的基本信息,可通过系统联动,建立与数据库的连接。
4)估算相似的成本与标准数据,并将其应用于算法以实现基于BIM 的初步估算系统。与现有基于BIM 的估算方法不同,该系统根据设计提出的备选方案及估算的总施工成本,通过初始设计阶段的质量模型来支持决策[5]。
1.1 数据与成本数据库设计
数据库的结构与内容包括用于相似性能数据匹配的项目基本信息、实际工程造价及初步估算的建设成本指数。其中,实际数据包含了建筑、机械、电力、通信、土木工程和各明细类型的造价[6-7]。此外,数据库还包括根据详细的工作类型建立长期的维修计划,以预测全生命周期成本的标准以及废物处理、产品与实际折现率等成本的估算标准。为了利用这类数据,该文使用最常见且最为可靠的数据库管理系统Oracle SQL Developer 来进行构建。
1.2 基于BIM的估算系统部署
基于BIM 的估算系统应首先分析工程的需求,然后将需求应用到BIM 模型中[8-9]。而所生成的模型将被保存至存储服务器中,估计所需的数据则会被解析并交付给原型系统,再通过数据库中的算法引用交付的数据和设计替代输入的数据。
整个系统的处理流程如图2 所示。工程估计人员根据工程需求与BIM 模型信息,生成每个工程项目的基本信息及备选方案。系统选定的设计内容与数据库链接得到类似的性能数据;然后将派生数据分配到现值中,使过去成本数据转换为当前成本;最终,将实际建筑成本和标准化数据转变为全生命周期成本的估算值。

图2 系统处理流程
1.3 基于BIM的数据分类过程
通过实施基于BIM 的项目估算系统,设计建设项目早期的决策过程如下[10]:首先根据项目需求设定总成本,并确定项目目标、楼层数、面积、区域与结构等基本要素;然后结合数据库提取相似项目的建设成本,并应用估算算法得出总建设成本;随后再通过估算及适当的成本比较来进行审查。若成本估算超过合理的建设成本或数据出现异常,则应告警提示采取限制措施。
2 改进SVM异常数据分类算法
在建立建筑成本数据库的基础上,该节对于工程造价数据中的异常数据分类方法进行了研究。由于工程数据具有多维属性,因此基于概率分类器,可获得条件概率为p(y∣xj,n)。通过多类逻辑回归对条件概率进行建模[11],如下所示:
定义W={wk} 是需估计的模型参数。基于逻辑回归模型的分类器通常用于主动学习。模型参数可通过最小化所有标记样本的正则化对数似然来估计:
式中,yj,n是样本xj,n的标签;λ≥0 且为权重系数[12]。由于目标函数依赖于不同节点的标注数据,所以在分布式情况下无法直接在单个节点进行计算。但其可分散为:
式(4)是仅依赖于节点j的局部标记数据的局部目标函数[13]。对于式(3)的目标函数,使用以下两步迭代来获得分布式优化解,具体为:
其中,I(yj,n=k)是指标函数。当yj,n=k时,其值等于1;而当yj,n≠k时,其值等于0。需要注意,梯度只能根据节点j的局部标注数据计算。式(6)中,每个节点融合其相邻节点的中间估计以获得第i次迭代的最终估计。在此过程中,每个节点需要在开始融合之前向所有相邻节点发送其中间估计。每个节点重复以上两步,直到估计收敛,这样就可以使不同节点的估计渐近收敛到目标函数的一致最小值。因此,该文算法提供了一个完全去中心化的场数据分类思路。通过该方法,每个节点可在不传输原始数据的情况下,在全局意义上训练一个分类模型。将分布式样本选择策略与分布式分类算法相结合,得到该文设计的分布式主动学习方法过程,如图3所示[14]。
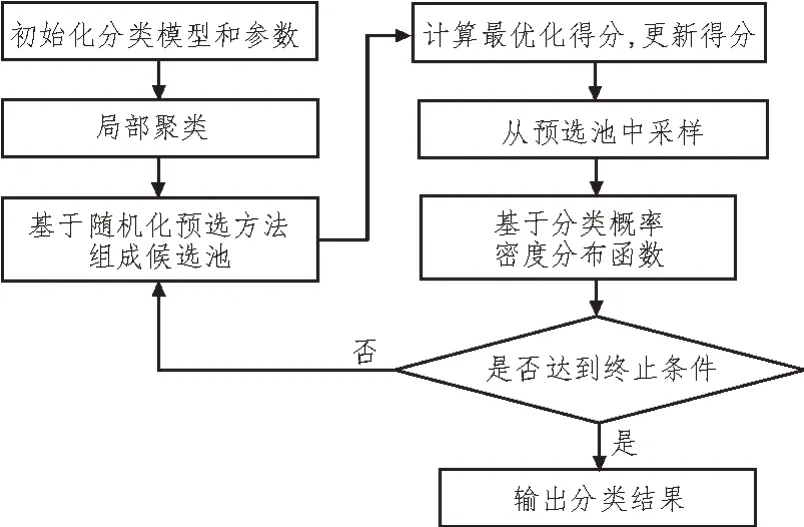
图3 主动式分类学习过程
3 实验验证
该文基于改进SVM 方法的输变电工程异常数据检测算法,以软件形式进行集成[15-16]。设计实验从两方面对软件进行验证:一方面是对于软件算法的性能进行测试,并与常用算法进行对比;另一方面是进行工程数据检测。
3.1 算法性能测试
该文研究了基于分布式SVM 的异常数据分析方法的性能。实验所使用的数据集为基于真实工程数据建模的BIM 数据集。在算法验证时,随机选择每个数据集80%的未标记数据用于训练,使用剩下20%的数据作为测试数据。为了模拟分布式情况,未标记的数据通过网络均匀随机分配到不同节点。
算法验证的场景包括10 个节点(即独立建筑项目)组成的网络,每个节点连接到最近的4 个节点,然后以0.1 的概率随机添加节点进行连接。该文选取了以下4 种方法以及SVM 算法,与所提的改进SVM 算法进行比较:
1)随机算法。每一轮数据遍历中,每个节点随机选择一个未标记的样本进行异常数据分析。
2)分布式BvSB 算法。每一轮数据遍历中,每个节点选择一个具有最高BvSB 值的本地样本进行异常数据分析。
3)集中式BvSB 算法。假设所有数据均收集在一起,集中式数据分析器在每个学习轮中选择n个具有最高BvSB 值的样本进行异常数据分析。
4)集中式All 算法。通过查询所有未标记样本的标签,然后使用所有已标异常数据样本训练SVM分类器。

图4 基于数据集1的算法对比结果
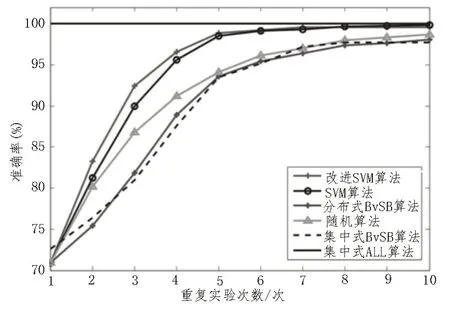
图5 基于数据集2的算法对比结果
对于每种算法,该文在每个数据集上运行了多次重复实验。从图4 和图5 中可以观察到,改进SVM算法相比其他异常数据分类算法的性能优势是显而易见的。尽管优势程度因不同数据集而异,但总体上改进SVM 算法优于其他异常数据分析算法。
3.2 异常数据检测方法验证结果
该文使用基于BIM 数据的异常数据检测方法进行验证。表1 为工程施工方案的成本预测。

表1 工程施工成本预测
每种设计方案的成本预测与实际对比情况表明,建筑成本占设计方案1 总生命周期的84%以上,维护和拆卸成本的比例较小,即15.57%。设计方案2的建筑成本约占生命总周期成本的10.10%,其余大部分为维护、拆卸成本。两种方案代表了实际工程中的典型情况,该方法对于不同方案的工程成本预测准确率能达到约95%,说明可以保证对不同方案、不同工程内容的造价数据进行准确检测,并能够精确定位不同工程项目的造价信息,从而为造价异常数据的甄别提供有力保障。
4 结束语
为解决电网建设过程中异常造价数据的检测问题,该文使用BIM 模型建立基于模板数据与实际建设数据的建筑数据库,并基于改进SVM 模型进行了异常数据的建设。实验结果证明了该文方法的有效性。在实际工程建设中,随着实际情况的不断变化,工程建设及成本数据可能会有所波动。因此,在后续将侧重于动态工程异常造价数据的检测。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
财经(2017年2期)2017-03-10
数学学习与研究(2017年3期)2017-03-09
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
中国老区建设(2016年1期)2016-02-28
财经(2016年6期)2016-02-24
