
基于模糊测试生成多样化的数据库隔离级别测试案例
2023-09-22 01:09卢皙钰翁思扬李可强
华东师范大学学报(自然科学版) 2023年5期
卢皙钰, 刘 维, 翁思扬, 李可强, 张 蓉
(1. 华东师范大学 数据科学与工程学院, 上海 200062;2. 工业和信息化部电子第五研究所, 广州 511300 )
0 引 言
数据库隔离级别[1-2]定义了事务与其他事务进行资源或者数据更新的隔离程度, 避免由数据访问冲突造成的数据库状态的不一致和不正确. 隔离级别实现的正确性对于事务型业务的部署至关重要.在事务数据库的开发或部署阶段, 为了评估数据库系统在并发环境下隔离级别实现的正确性, 需要生成多样化的隔离级别测试案例并提升测试覆盖度. 通过生成多样化的测试案例, 涵盖不同的并发事务操作、并发事务执行交互方式以及事务隔离级别组合, 开发人员能够验证数据库系统的设计和实现是否能够正确地处理并发操作. 多样化的测试案例模拟了真实世界中数据库并发访问模式和使用情况,能够更全面地覆盖数据库系统的代码路径. 因此, 开发人员能够从测试案例执行中发现潜在的并发操作问题, 例如脏读或不可重复读等异常情况, 并从中获得开发需改进的方向.
数据库系统的隔离级别实现涉及复杂的数据结构、算法和并发控制机制[3-6]. 不同的隔离级别 (如读未提交、读已提交、可重复读和串行化) 需要在数据库内部实现锁定、版本控制和事务管理策略等功能. 现代数据库种类的数量越来越多, 包括关系型数据库、NoSQL (not only SQL)数据库和分布式数据库等. 然而, 大多数数据库产品不可开源, 现有的测试工具通常只能对数据库进行黑盒测试[7]. 因此, 针对复杂的数据库隔离级别实现, 现有的黑盒测试工具在提供全面探索数据库隔离级别细节方面存在一定的局限性.
传统的数据库隔离级别测试方法存在局限性. 首先, 采用手工测试的工作量巨大, 难以实现全面的测试覆盖. 手工构造测试用例需要消耗大量时间, 并且可能会忽略一些潜在的事务并发执行边界情况和漏洞. 其次, 由于数据库系统中的事务和并发访问模式非常复杂, 不同的并发事务和执行顺序将在数据库中呈现不同的行为, 基于手动构造测试规则的测试方法所生成的测试案例通常难以模拟所有并发事务的交互行为, 无法涵盖到所有可能的输入和边界情况, 具有一定的测试覆盖度限制[8].
因此, 为了深入了解数据库的内部实现细节、高效全面地探索隔离级别测试空间, 需要一种能够与数据库内部实现结合的测试方法. 模糊测试[9-14]是一种广泛应用于软件安全领域的测试技术, 旨在通过广泛探索输入空间、变异和生成测试案例来构建多样化的负载, 发现系统中潜在的漏洞和错误行为. 模糊测试在解决数据库隔离级别测试方面具有明显的优势, 它以全面且自动化的方式进行测试,并生成多样性和针对性的测试案例. 通过分析数据库隔离级别测试行为, 测试可以获取在执行过程中代码覆盖的增长信息. 并且, 模糊测试能够调整测试生成的输入数据, 从而有针对性地探测广泛而复杂的隔离级别测试路径. 具体来说, 模糊测试结合了静态分析和动态测试, 通过监测和分析测试的覆盖情况, 自动变异现有的测试用例以生成新的测试案例可以探索尚未覆盖到的代码路径, 并高效地深入探索数据库隔离级别的测试空间.
然而, 在利用模糊测试对数据库隔离级别进行自动化测试时, 需要考虑到数据库隔离级别涉及多个并发事务之间的交互. 随着模糊测试的进行, 事务数量、隔离级别种类和并发冲突组合的增多, 测试中需要覆盖的复合案例将会呈指数级增长. 在这种情况下, 穷尽所有可能的测试案例几乎是不可行的,故而, 如何高效地探索测试空间是数据库隔离级别模糊测试中的一个挑战. 在数据库领域也出现了一系列模糊测试工具[15-20], 如Squirrel、Ratel、SQLRight 等, 旨在生成多样化的数据库测试案例, 提高测试效率和测试覆盖度. 然而, 这些数据库模糊测试工具除了无法有效支持并发事务测试, 还存在着无法提供隔离级别测试指导的限制. 上述工具的测试案例变异方式主要生成具有复杂查询结构的查询语句, 无法控制模拟并发事务的执行交互行为, 这使得上述工具在数据库隔离级别行为的全面评估中受到限制.
为了解决对数据库隔离级别核心功能的自动化、高覆盖有效测试的问题, 通过对PostgreSQL[21]隔离级别实现的代码和资料进行详细研读[22-24], 本文面向隔离级别设计高效的代码搜索策略来引导多样化的测试案例生成. 本文将数据库隔离级别测试空间定义成两个维度, 即并发事务组合空间和并发事务执行交互模式空间. 通过在并发事务组合空间中搜索, 测试能够涵盖多样化的并发测试案例, 并对不同的并发场景进行测试. 通过搜索并发事务执行交互空间, 可以深入测试事务管理模块中的关键细节, 如读取可见性的判断、锁的管理和事务协调, 这有助于深入研究数据一致性和隔离级别的有效性.
为全面探索这两个测试空间, 本文在模糊测试中提出了结构化的测试输入结构, 包含并发事务组合结构和并发事务执行交互模式结构. 并发事务组合结构表示操作组合, 并发事务执行交互模式影响了并发执行下隔离级别允许的操作行为. 根据两个空间维度的变异满足数据库隔离级别测试的要求,针对这两个维度测试空间的变异搜索, 本文采用了广度和深度的搜索策略, 其中广度搜索策略用于探索并发事务组合的空间, 通过变异和调整事务的组合方式, 覆盖多样的并发测试场景; 深度搜索策略则专注于探索事务交互方式的空间, 通过变异和调整事务的执行顺序、并发冲突方式以及事务执行方式, 以深入挖掘事务之间的执行交互方式. 最后, 通过记忆化变异轨迹记录中的反馈信息, 测试可以自适应地应用这两个搜索策略, 以全面地探索测试空间并指导测试方向, 确保测试用例的多样性、针对性和有效性. 这种指导性的方法能够帮助测试更有针对性地选择测试方向, 重点关注引起更多数据库行为的测试路径, 从而提高测试的效率和效果.
具体来说, 论文贡献点包括以下两点:
(1) 实现了针对数据库隔离级别测试的模糊工具SilverBlade, 引入结构化输入模型, 准确模拟并发事务执行交互; 引入基于反馈指导的广度和深度的搜索策略, 解决了数据库隔离级别测试中测试空间探索不充分的难题.
(2) 在流行的数据库系统PostgreSQL 上进行了测试. 相较于其他工具, SilverBlade 的方法在提高隔离级别关键区域的测试覆盖率方面表现出色. SilverBlade 能够生成更广泛的测试用例, 并覆盖了更多关键测试路径.
1 相关工作
本章将介绍相关数据库的模糊测试工具. 针对数据库的模糊测试可分为两种, 分别是基于生成的模糊测试和基于变异的模糊测试. 基于生成的模糊测试工具近年在数据库测试领域得到广泛研究, 其中包括著名的工具, 如RAGS、SQLancer 和SQLsmith 等, 它们的主要目标是发现数据库中的逻辑错误和崩溃问题. 这些工具根据特定的测试案例生成规则生成随机的SQL 查询语句以测试数据库, 通过随机选择表、列、运算符和条件的组合来模拟真实环境中的各种异常情况和错误.
在数据库测试领域, 众多现有工作对基于变异的模糊测试工具进行了深入的研究和探索, 并且已经有许多现有的工具可供使用. 这些工具根据其变异规则修改测试案例中的SQL 查询语句, 生成新的测试案例, 进而探索数据库系统的不同行为和潜在缺陷, 如Squirrel、Ratel 和SQLRight 等工具, 将测试案例利用抽象语法树[25]进行解析并根据语法规则对其执行各种变异操作以生成多样性的查询语句.
然而, 这些相关工具在测试数据库隔离级别方面存在一定的局限性, 首先, 它们通常不支持并发事务测试, 也无法控制并发事务执行交互. 其次, 基于变异生成的工具大多只针对查询语句进行变异操作, 而没有充分考虑并发环境下的因素. 这样的问题将导致测试无法模拟数据库在并发环境下处理事务的行为. SilverBlade 能够根据数据库隔离级别的特性支持并发事务进行测试, 并更好地模拟并发事务场景和复杂的冲突情况, 从而确保更全面地探索数据库隔离级别的测试空间.
2 方 法
2.1 方法总览
SilverBlade 整体工作流程如图1 所示. 在进行测试之前, 首先, 使用基于GCC (GNU compiler collection)的GCOV 工具对被测试数据库进行插桩, 以获取动态的覆盖信息, 并为后续的测试提供指导. 其次, 将初始案例作为测试用例结构的种子, 并进行初始化. 最后, 将其放入测试队列中, 准备开始测试过程. 一个模糊测试循环的工作步骤如下: ① 从测试队列中提取一个测试案例 (记为t), 在测试案例中, 并发事务组合包含n个事务, 每个事务被标记为Ti( 1 ≤i≤n) . 在测试案例中, 并发事务执行交互结构中存在冲突模式, 涉及3 个单独的事务模版, 分别是T1、T2和T3. 每个事务都包含两个操作, 分别记为o1和o2. 在变异引擎中提取测试用例记忆化的变异轨迹 (ttrace), 并根据ttrace的变异信息指导引擎选择变异策略对测试用例进行变异. ② 将经变异引擎处理后的测试用例传入数据库进行测试. ③ 测试结果分析器将此时整体测试的覆盖信息与未执行之前的整体覆盖信息进行对比, 若其判定此次测试导致数据库整体覆盖度增长, 则定义测试案例t为具有新行为的测试案例. ④ 如果经过测试的测试用例具有新行为, 则将本次变异的内容和覆盖度增长数量添加到ttrace中, 以指导后续测试的变异. 在模糊循环的最后阶段, 将具有新行为的测试用例记录到测试案例队列中, 供后续测试使用.
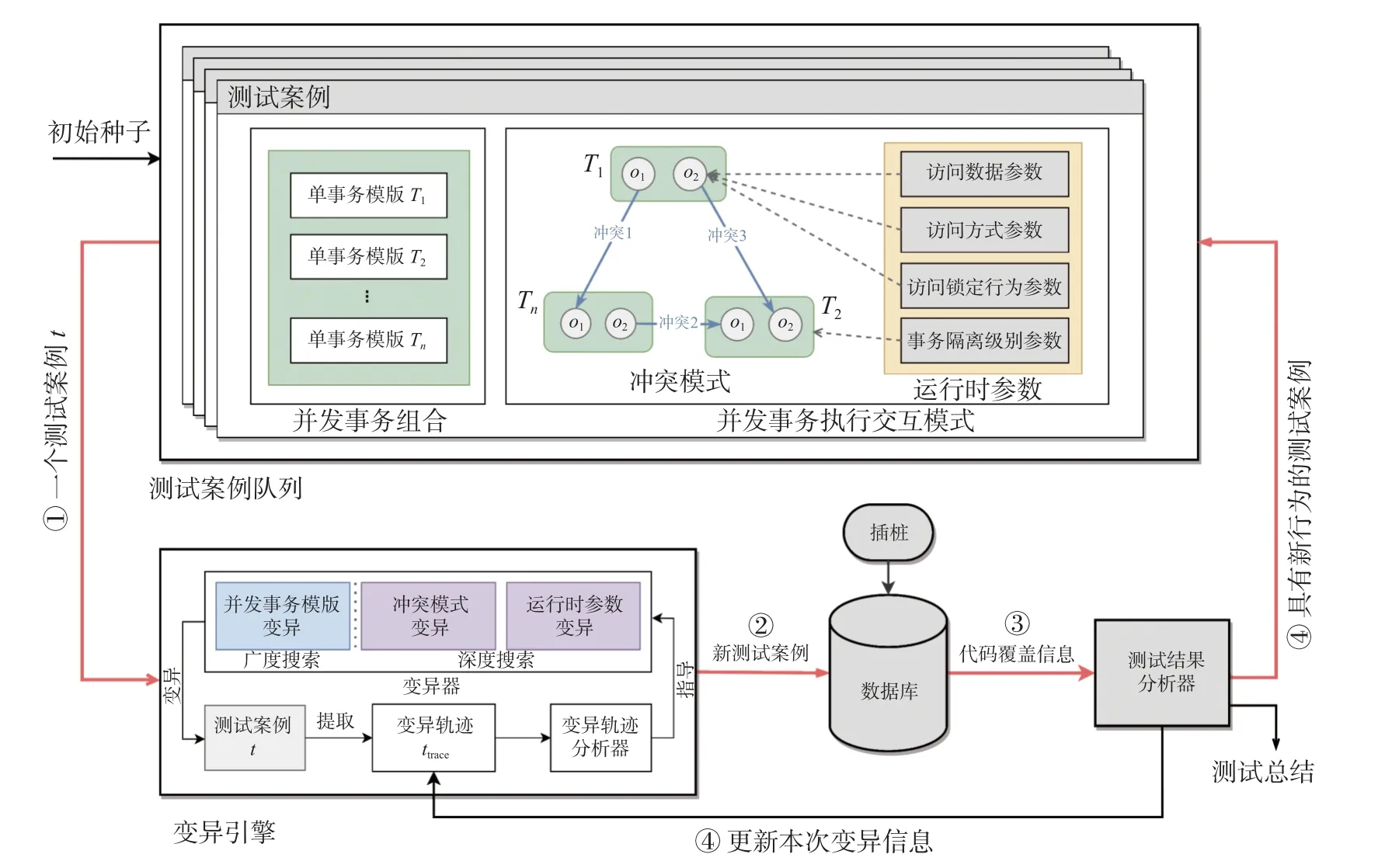
图1 SilverBlade 工作流程Fig. 1 Workflow of SilverBlade
SilverBlade 在模糊测试中引入基于结构化输入, 以及支持深度和广度搜索的变异引擎以在数据库隔离级别的测试空间进行针对性搜索.
2.2 结构化的测试输入结构
本节给出结构化输入结构中并发事务组合和并发事务执行交互模式的定义.
2.2.1 并发事务组合
并发事务测试由包含多个事务的并发事务组合控制, 并发事务组合的定义如下.
定义1令Tc表示一个并发事务组合,Tc={T1,T2,··· ,Tm},Tc由多个单事务模版Ti={o1,o2,··· ,oni}组成, 其中单事务模版Ti包含若干需要顺序执行的数据库操作序列oj(2 ≤j≤ni-1) .记ni为Ti的操作个数,Ti包含的操作中oj是数据库的读操作r或是写操作w,o1是开始操作,oni是提交操作或回滚操作.
如图2 所示, 测试案例 a 的并发事务组合包含了两个单事务模版T1和T2, 此事务组合构建了由这两个事务组成的并发场景.

图2 结构化输入结构的一个实例Fig. 2 An example of a structured input structure
2.2.2 并发事务执行交互模式
并发事务执行交互模式包含操作冲突模式和运行时参数, 如图1 所示. 其中冲突模式的定义如下.
定义2令S表示由并发事务组合Tc={T1,T2,··· ,Tm}中所有事务操作组成的序列组合. 令冲突模式 c 表示一个冲突模式, 其可用图来表述. 其节点表示具体的操作o, 边表示操作之间的依赖关系和冲突关系. 在给定的并发事务模版Tc中,oi ∈Ti,oj ∈Tj, 边 (oi,oj) 规定oi必须在oj之前执行且oi和oj之间存在读–写、写–读或写–写冲突中的一种. 其中S由 c 决定.
一个在PostgreSQL 中测试的测试案例如图2 所示, 图中间的冲突模式表明其在并发事务组合下可能发生的一种冲突情况. 该模式包含了读–写 (read-write, RW) 和写–读 (write-read, WR) 冲突, 其中均涉及数据X. 图2 下方展示了左边的并发事务组合在这种冲突模式下的事务执行顺序. 一个冲突模式图代表一种并发冲突场景, 它表示了事务之间的交互关系, 并定义了事务的执行顺序和依赖关系,不同的并发冲突情况可能会在事务管理机制下表现出不同的行为.
并发事务执行交互模式的另一部分中, 运行时参数包含4 种类型的参数: 访问数据参数、访问锁定模式参数、访问方式参数和隔离级别参数. 它们控制着操作的执行方式并决定了事务的并发行为和执行交互模式. 访问数据参数控制操作数据的分布和状态, 通过调整它可以模拟不同的数据访问场景.例如, 模拟高并发访问同一数据块或访问分布式数据. 访问锁定模式参数定义了事务对共享资源的锁定方式, 决定了锁冲突和竞争情况. 访问方式参数表示了使用的索引和检索方式, 不同的索引和检索方式会影响锁定行为; 隔离级别参数决定了事务的隔离级别以确定事务的数据可见性和隔离程度, 隔离级别将会对并发冲突和数据一致性产生影响. 通过调整这些参数, SilverBlade 可以模拟不同的事务执行策略和测试并发控制机制的实现细节.
运行时参数的实例如图2 右边所示, 访问数据参数设置了冲突操作中所访问的数据X,X是近期具有高访问频率的数据 (记为 h igh_heat ); 访问锁定模式参数表明采用了默认的锁定方式; 访问方式参数表明启用了默认的索引方式 (记为 d efault ); 隔离级别参数将两个事务的隔离级别都设置为可重复读隔离级别 (记为 d efault ).
良好的输入结构对模糊测试至关重要, 因为其影响了模糊测试的有效性和测试覆盖度. 本节设计的测试输入结构为模糊测试提供了数据库隔离级别的有效信息, 并指导模糊测试生成更有针对性的测试用例, 以全面地探索系统的多种行为. SilverBlade 的测试输入结构支持生成不同的并发事务组合和交互模式, 这种设计方式能够更深入地测试事务管理机制中的关键细节, 例如读取可见性判断、锁管理和事务协调. 因此, 合理的输入结构不仅提供了关键的信息和指导, 使模糊测试更具针对性和有效性, 而且能够全面评估数据库隔离级别的行为.
2.3 基于反馈指导变异探索测试空间
本节将讨论如何基于并发事务组合和并发事务执行交互模式两个结构进行变异, 并结合测试反馈信息来指导测试方向, 以全面搜索测试空间并产生新的测试行为. 通过对并发事务组合和交互模式的变异, 模糊测试能够生成多样化的测试用例, 从而覆盖数据库隔离级别下的各种可能执行情况. 与现有基于变异生成的数据库模糊测试工具不同, SilverBlade 的变异搜索方法能够考虑事务的并发执行, 主要包括以下两个方面的内容.
(1) 采用广度和深度的搜索方法有效变异测试案例.
(2) 采用基于反馈指导的自适应变异方法全面搜索测试空间.
2.3.1 基于广度和深度搜索的变异
为了更加全面和有效地探索隔离级别测试空间, SilverBlade 采用了广度搜索和深度搜索两种针对性的搜索策略, 分别用于搜索并发事务组合测试空间和并发事务执行交互模式测试空间. 通过这两种策略的应用, SilverBlade 能够更全面地覆盖可能的测试情况, 并且对隔离级别的测试空间进行更加全面的探索. SilverBlade 采用基于广度搜索的方式对测试案例并发事务组合执行变异, 以生成多样化的并发事务组合场景来探索事务组合测试空间. 具体的变异方式基于已有的测试案例中的并发事务组合, 采用随机执行删除、替换其中包含的事务模版和添加新的事务模版的方法. 其中, 被替换和添加的单事务从测试队列中随机获取. 图3 中展示了一个变异的实例. 原始的并发事务结构包含两个单事务模版, 每个事务模版包含若干操作. 通过基于广度搜索的变异, 原始并发事务组合中的T2被从测试队列中提取的事务模版T23取代, 同时另一个从测试队列中提取的事务模版T892被添加到了新的并发事务组合中.
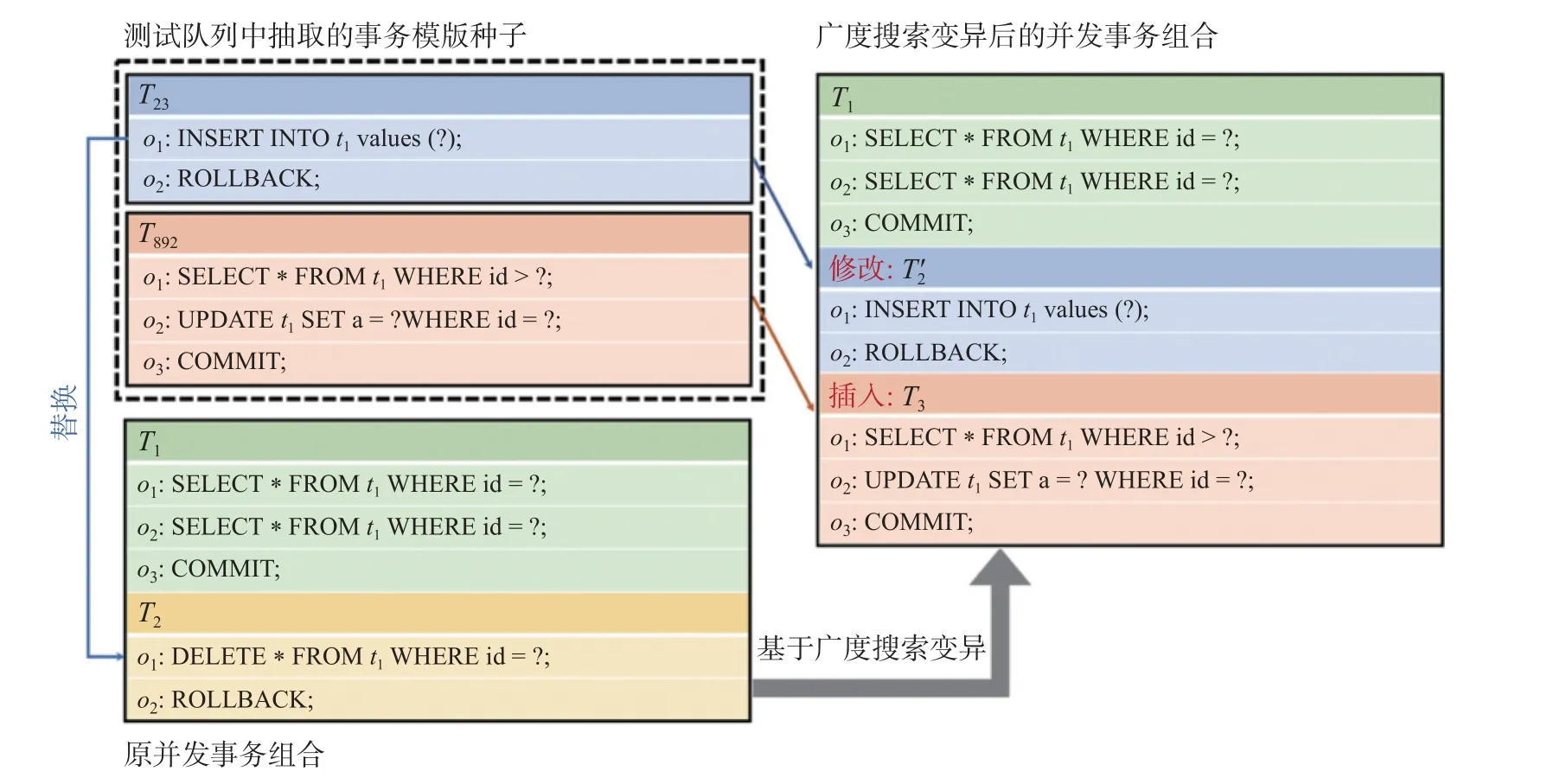
图3 基于广度搜索变异的一个实例Fig. 3 An example of mutation based on breadth search
在基于广度搜索的测试案例变异中, SilverBlade 重新组合一个测试案例的并发事务组合. 对于新增和修改的变异操作, SilverBlade 将队列中现有的测试案例中的并发事务组合与当前测试案例的并发事务组合进行重新组合. 若初始化队列中的测试案例均符合语法和语义的正确性, 在新增或修改并发事务组合时, 变异所生成的新组合事务也能保持语法和语义的正确性. 通过这种方法,SilverBlade 能够改变测试案例的并发事务组合, 确保测试案例的可执行性并广泛探索各种可能的测试情况.
除此之外, SilverBlade 采用深度搜索的方式对测试案例的并发事务执行交互模式结构进行变异,以探索事务执行交互模式的测试空间. 图4 展示了一个原始测试案例变异后可能得到的新测试案例.深度搜索基于固定的并发事务组合, 通过变异冲突模式和运行时参数, 生成多样的新事务执行交互模式, 其中包含两个核心的变异方式, 分别是冲突模式变异和运行时参数变异.
(1) 变异冲突模式. 其变异方式如算法1 所示, 算法MutateConflictPattern (行1—7) 负责对冲突模式进行变异以生成新的冲突模式, 并检查和过滤冗余的新冲突模式以提升测试效率. 对于固定的并发事务组合 (记为c), 核心算法GenerateConflictPattern 负责生成c的新冲突模式, 并用冲突模式图的方式记录新的冲突模式 (记为g). 方法check (行4) 基于子图同构判定算法VF2[24-25]计算新生成的冲突模式g与c并发事务组合已生成的冲突模式集合 (记为s) 中每个图的相似度, 以减少并发事务组合冲突模式的冗余. 在计算相似度时, SilverBlade 考虑节点间操作的语义类型匹配和冲突边的类型匹配以提高计算的准确性. check 采取的方法是在计算新生成的冲突模式与已生成的并发事务历史冲突模式集合s中的每个图的相似度后, 确保若相似度高于预先设定的指定阈值, 则继续进行变异操作,直到相似度降至低于该阈值为止. 其中GenerateConflictPattern (行7—17) 是生成新的冲突模式的核心算法, 首先对事务组合的事务顺序进行随机排序 (行8), 其次按照顺序对c中排列连续的两个事务c1(行12) 和c2(行13) 选取冲突对. 其中, 方法random_choose_conflict 负责确定冲突操作, 其返回由c1和c2操作构成的操作冲突对集合C. 其不仅保证选取冲突模式冲突边的冲突操作不违反c1和c2事务内操作执行顺序的规则, 且保证选取的冲突操作分别来自不同的事务和两个操作都不为读操作.最后, 将冲突对集合C中的每一个冲突对添加到新的冲突模式g中.
(2) 变异运行时参数. 分别变异4 种运行时参数以生成新的组合参数. 一个深度搜索变异的例子如图4 所示, 在变异访问参数时, 冲突操作访问了具有另一种特征的数据Y, 即不同访问热度的数据.在访问模式变异中, 增加新的索引 i ndex1以访问数据. 同样地, 在锁定模式和隔离级别参数中也执行了相应的变异. 变异锁定方式时, 访问数据的锁定模式由默认方式变异为使用行锁(row lock)的方式访问数据. 在变异事务模版所使用的隔离级别时, 将原来的可重复读隔离级别(RR)变异为已提交读隔离级别(RC). 为了确保并发事务组合能够在新的运行时参数下正常运行, 变异的方式需要根据被测试数据库所支持的选项进行相应的调整和变异. 通过对数据库系统的配置、参数和功能进行分析,SilverBlade 根据上述信息对测试案例进行变异, 以确保变异后的运行参数能在当前被测数据库中被正确运行, 这样能够更好地探索数据库隔离级别的潜在问题, 并提高测试案例的可靠性和实用性.

算法1 MutateConflictPattern (t)p输入: 事务组合 , 历史冲突模式集合g输出: 新的冲突模式s(p,s)1: Function MutateConflictPattern 2: While true do g(p) p 3: ← GenerateConflictPattern //根据 生成新的冲突模式g, s 4: If not check( ) then // VF2 检查此冲突模式在此事务组合下是否冗余s,g g s 5: add( ) // 不冗余, 加入此事务组合的冲突模式集合 中g 6: Return // 成功生成不冗余的冲突模式(p)7: Function GenerateConflictPattern(p)8: Reshuffle // 为增加冲突操作组合的多样性, 随机生成并发事务组合的顺序g(p)9: ← build_node ip1 ip1 p 10: For = 0 to length(p) – 1 do// 为 中单事务模版的序列号ip2 ip1 ip2 p 11: For = +1 to length(p) do // 为 中单事务模版的序列号p1 p ip1 p1 p ip1 12: ← .index( ) // 为 中第 个单事务模版p2 p ip2 p2 p ip2 13: ← .index( ) // 为 中第 个单事务模版(p1,p2) p1 p2 14: ← random_choose_conflict // 针对 和 随机生成冲突C 15: For c in C do // 随机生成冲突边(g,(co1,co2)) (co1,co2) g 16: add // 增加新冲突 到新冲突模式 中g 17: Return
综上所述, SilverBlade 在测试空间的两个维度上采用了针对性的搜索策略. 该策略旨在广泛地探索不同的并发事务组合, 从而覆盖更多的并发场景, 并深入挖掘事务执行交互的行为.
2.3.2 基于反馈指导的自适应的搜索策略
为了有效地测试数据库隔离级别的核心功能, SilverBlade 基于数据库隔离级别实现的核心代码覆盖度增长变化, 指导自动化搜索变异. 为了有效解决适用于不同情况的搜索方式选择问题, 本文提出了一个自适应搜索策略. 为了实现自适应搜索策略, 首先, SilverBlade 定义核心代码为涵盖了与事务关键功能的实现代码. 关键代码的实现模块包括事务管理、并发控制相关的锁机制、多版本并发控制机制以及存储模块等文件夹的源文件. 这些核心代码的功能协同工作, 确保了数据库事务隔离级别的正确进行. 其次, SilverBlade 提出了历史搜索类型和核心代码覆盖平均增长速率, 用于反馈测试案例的自适应搜索. 最后, SilverBlade 使用测试案例变异轨迹来记录测试案例的历史变异信息, 并追踪每次变异后测试案例执行后核心代码覆盖的增长情况, 以指导自适应搜索过程.
自适应搜索策略的核心方法如算法2 所示. 根据测试案例的历史变异信息, SilverBlade 自适应选择搜索方式(记为m)对测试案例进行变异, 变异方式包括深度搜索h和广度搜索e. 针对一个测试案例的变异轨迹 (记为ttrace), 使用GetLastSearchType 检查ttrace最后一次的搜索方式 (行2). 若最后一次的搜索方式是广度搜索, 则返回此次深度搜索h, 以确定在此轮变异中是否采用深度搜索来对测试案例进行变异 (行3); 否则, 算法需要根据测试案例变异轨迹进行下一步判断以确定变异方式(行4—16). 当根据历史覆盖信息选择变异方式时, 首先, 从ttrace中获取最后一次深度搜索、之前连续深度搜索的记录和最后几个连续的深度搜索的次数d. 然后, 根据最后的每一次深度搜索变异得到新覆盖数据计算这几次测试的核心代码覆盖平均增长速率a(行6). 最后, 根据d和a的值判断此轮变异使用何种变异搜索方式. 首先考虑当搜索次数d小于阈值T时, 算法有50%的概率继续进行深度搜索(行9), 否则随机选择搜索方式以提高搜索的随机性 (行11). 反之, 当d大于阈值T时, 算法考虑根据a判断选择的变异类型 (行12—16). 这种情况下, 当a小于阈值∂时, 意味着此测试案例在先前的深度搜索中表现不佳, 此时可以确定此轮搜索选择广度搜索对并发事务组合进行变异, 此时变异产生新的并发事务组合可增加搜索的多样性 (行13—14). 反之, 若a大于阈值∂, 此轮将继续进行深度搜索(行15—16). 通过根据记忆化的变异轨迹信息和新覆盖发现速率的自适应调整, 搜索能够集中在搜索空间中更有价值的区域, 从而使得搜索更加有效和有针对性.

(ttrace)算法2 GetSearchTypeByTrace(ttrace)输入: 测试案例的变异轨迹输出: 此次变异搜索模式m(ttrace)1: Function GetSearchTypeByTrace(ttrace) e 2: If GetLastSearchType == then//==表示表达判断等于m h 3: ←trace 4: Else //检查 最近时间中连续的深度搜索记录(ttrace)5: ← GetDepthSearchTimes //检查trace 最近时间中最后的深度搜索的次数d(ttrace,d)6: ← GetDepthSearchGrowthRate // 检查trace 最后连续的深度搜索平均新覆盖增长率a 7: If d < T 8: If random_pick (0,1) == 0 then m ←e 9: // 继续深度搜索10: Else
3 实验评估
本章旨在通过实验来验证SilverBlade 生成的测试案例对数据库隔离级别的测试效果, 并解答以下两个问题.
问题1: 相比于对比工具, SilverBlade 是否能够生成多样性的测试案例, 以有效覆盖数据库隔离级别核心实现代码?
问题2: SilverBlade 的结构化测试输入结构以及基于深度和广度搜索的变异方式能否提升数据库隔离级别核心实现代码的覆盖率?
3.1 实验准备
(1) 核心代码定义. 根据PostgreSQL (8.0.31) 数据库源代码和文档资料进行分析, 将涵盖了数据库隔离级别实现的模块代码定义为实验的隔离级别测试核心代码. 在PostgreSQL (版本14.4) 中,SilverBlade 定义的核心区域包括事务管理 (transam)、并发控制相关的锁机制 (lmgr)、多版本并发控制机制 (snapmgr 和heap) 以及存储 (buffer 和heap) 模块等文件夹的源文件.
(2) 测试设置. 在代码覆盖指标设置上, SilverBlade 在实验中选择隔离级别核心代码的分支覆盖度作为主要指标, 对隔离级别测试的覆盖范围和效果进行评估. 在比较两个实验的核心代码分支覆盖度时, 较高的分支覆盖度表明测试用例能够触发更多不同的代码路径, 同时也意味着实验涵盖了更多与隔离级别相关的逻辑. 在测试初始种子设置上, 实验中初始种子测试案例的并发事务组合中事务均由Leopard 生成的事务随机抽取而成, 生成的事务涵盖了读取和写入操作. 首先, 保证生成事务内操作符合语法与语义正确. 其次, 保证生成操作均有效. 初始种子测试案例中冲突模式与运行时参数均根据上述并发事务组合生成, 且分别通过本文所述生成方式保证初始种子的正确性.
(3) 实验平台. 实验将在一台配置了6 个Intel(R) Core(TM) i5-8500 处理器的64 位Ubuntu 22.04 操作系统的机器上进行. 每个处理器的时钟频率为3.00 GHz, 并且该机器拥有总计16 GB 的内存. 本文将选择在这个平台上使用PostgreSQL (版本14.4) 来执行所有实验, 测试所用插桩工具基于GCC 的GCOV (11.3.0 版本) 实现, 其中测试反馈的分支覆盖信息为GCOV 所提供的信息.
(4) 对比工具. 实验选用BenchBase (使用TPC-C 和Smallbank 的并发事务负载) 作为对比工具.BenchBase 是支持并发事务测试的负载生成工具, 并提供了TPC-C 和Smallbank 的事务负载, 能够生成并发的事务负载. 实验使用BenchBase 生成的并发事务负载在数据库支持的隔离级别下进行测试,从而对比和评估BenchBase 与SilverBlade 在测试隔离级别核心代码区域表现的差异.
3.2 实验内容
为了回答问题1, 首先选择BenchBase 作为SilverBlade 的对比测试工具, 其中使用的负载包括TPC-C 和Smallbank, 以对比SilverBlade 与BenchBase 在生成多样性测试案例方面的能力, 并评估它们在覆盖数据库隔离级别核心实现代码方面的效果. TPC-C 和Smallbank 负载均支持读写操作,TPC-C 和Smallbank 是两个常用的负载模型, 它们都支持事务并发, 其事务包含若干读写操作.BenchBase 支持生成的并发事务测试案例, 并能够模拟真实世界的并发数据库操作, 同时也能对数据库多样化的事务行为和交互方式进行测试. 为了确保BenchBase 作为对比实验的可行性和有效性, 实验保证其能够有效生成并发事务负载. 因此, 将实验中BenchBase 的terminal 参数设置为4, 并遵循两种负载测试配置中的默认值来设定其他参数.
两个对比组的实验持续了4.5 h. 两个工具对数据库代码的测试覆盖度如图5 所示. 图5 中核心代码区分支覆盖表明SilverBlade 的覆盖度相较BenchBase 的TPC-C 和Smallbank 两个测试更高, 且SilverBlade 分支覆盖增长速率比BenchBase 两个对比测试更高. 相比BenchBase 生成的两种并发事务负载, SilverBlade 有效提升了数据库隔离级别核心代码的覆盖度.
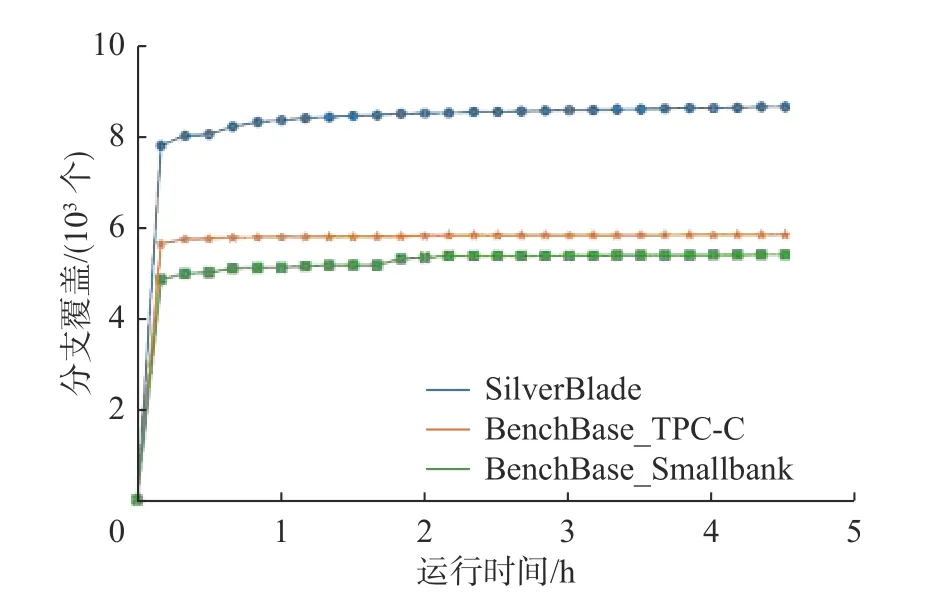
图5 SilverBlade 与BenchBase 测试结果对比Fig. 5 Comparison of SilverBlade and BenchBase test results
数据显示, 在总的核心代码分支覆盖中, SilverBlade 的实验覆盖了更多内部实现代码, 比BenchBase 的TPC-C 和Smallbank 并发事务负载测试的结果分别提升了48.5%和60.6%. 为了进一步分析试验结果, 详细分析了测试数据库的覆盖度文件, 对对比实验的测试效果进行深入分析, 结果如表1 所示. 其中access/transam 负责事务管理, 包含事务管理器的核心部分, 具体负责处理数据库中的事务操作、并发控制; access/heap 负责数据访问及存储管理模块, 其中包含数据库隔离级别的多版本并发处理实现关键内容; storage/lmgr 负责数据库锁管理, 包括并发事务获取锁、释放锁、死锁管理以及锁实现等与实务隔离级别相关的关键内容. 表1 中的数据表明SilverBlade 在测试中覆盖更多关键区域之中的代码分支, 这表明SilverBlade 能够生成更多样化的测试案例.

表1 SilverBlade 与BenchBase 3 个核心代码分区覆盖结果Tab. 1 The coverage results of the three core code partitions of SilverBlade and BenchBase
SilverBlade 支持根据覆盖信息不断变异测试案例, 以推进测试探索数据库隔离级别测试空间. 为了进一步分析这一特性, 详细分析了测试数据库的覆盖度文件, 对两个工具的测试效果进行深入分析.相比于没有反馈机制的BenchBase 工具, 在测试中, SilverBlade 不仅表现出更多的核心代码分支被触发和覆盖, 而且表现出了更大的隔离级别相关代码增长速度 (表1). 将实验开始到第10 分钟和实验开始到第4.5 小时的覆盖度增长进行对比, 结果如表2. 结果显示在此时间区间, SilverBlade 经过核心代码覆盖指导变异测试进行的核心代码区的分支覆盖增长了851 个, 而BenchBase 的TPC-C 和Smallbank分别仅增长193 个和547 个.

表2 SilverBlade 与BenchBase 核心代码覆盖增长结果Tab. 2 The core code coverage growth results of SilverBlade and BenchBase
综上分析表明, SilverBlade 在关键区域的覆盖度更高且覆盖增长率更高, 这表明SilverBlade 能够有效生成多样性的测试案例, 更全面地探索隔离级别相关逻辑, 从而获得了更高的代码覆盖度. 对比实验表明SilverBlade 在生成多样性测试案例方面的优势, 并展示其在数据库隔离级别核心实现代码覆盖度方面的表现. 通过深入覆盖核心实现代码, SilverBlade 能探索更多数据库隔离级别测试空间路径, 可为数据库测试人员提供更好的测试案例.
为了回答问题2, 本文验证SilverBlade 的设计在模糊测试中的效果, 进行了对比实验. 将原始实验记为SB, 将对比实验记为SB-, 其涉及停用结构化输入结构队列、基于广度和深度的搜索变异引擎功能. 两组对比实验初始种子是由Leopard 生成的语法和语义正确的事务, 与SB 不同的是, SB- 将其发送给被测试的PostgreSQL 以模拟数据库并发执行, 同时SB- 不会对测试案例进行变异来更新测试队列以推进测试进行.
图6 展示了这两种方法在实验运行4.5 h 后的实验结果, 结果显示, 实验SB 相对于实验SB- 在核心代码整体分支覆盖方面有显著提升, 覆盖度增加了39%. 进一步分析测试结果, 将一部分数据库隔离级别关键源文件的覆盖数据进行统计, 如图7 所示. 在支持隔离级别的多版本并发控制机制(图7(a)和图7(d))、事务管理 (图7(b)) 和锁实现的代码区域 (图7(c))方面中, 数据显示SB 相对于SB- 具有更高的覆盖率, 并且随着时间的增长, 测试覆盖率呈上升趋势. 这表明了, SB 相对于SB- 在生成多样化的测试案例覆盖数据库隔离级别核心代码中具有明显优势.
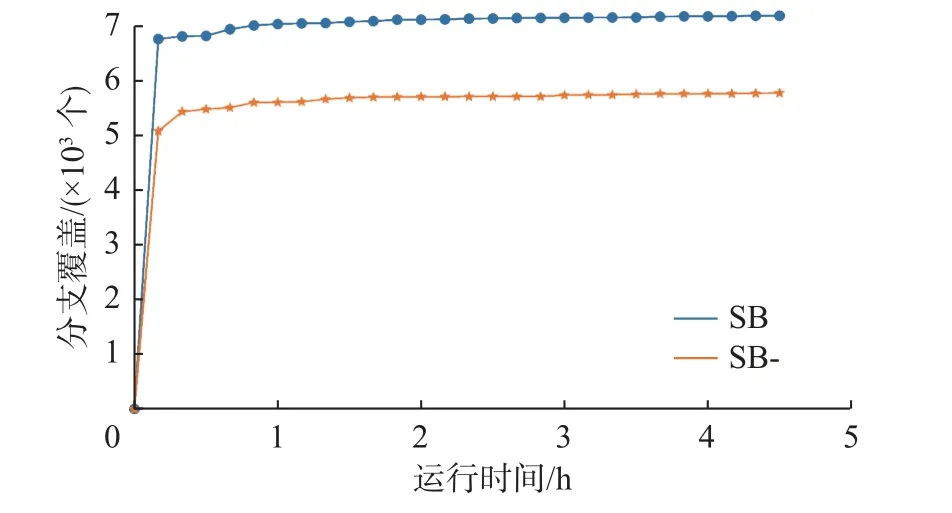
图6 SB 与SB- 核心代码区覆盖结果对比Fig. 6 Comparison of core code area coverage results between SB and SB-
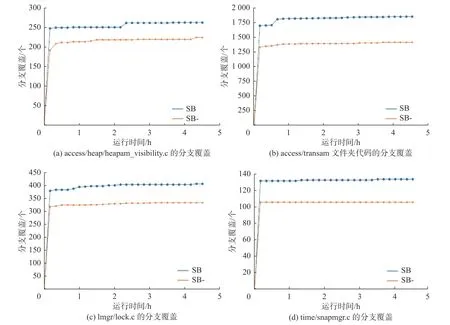
图7 SB 和SB- 核心代码覆盖差异对比例子Fig. 7 Example of SB and SB- core code coverage comparison
数据显示, 实验SB 相较于实验SB- 在覆盖隔离级别核心区域上更有优势, 这归因于其支持结构化输入的测试队列以及基于广度和深度搜索的变异引擎. 首先, 实验SB 采用了结构化输入结构的测试案例, 与实验SB- 的随机并发事务测试相比, 它能更准确地模拟具体的并发冲突模式, 并满足隔离级别的要求. 这使得实验SB 能够测试数据库在并发环境下的真实行为, 对更多的数据冲突和隔离级别实现的关键细节进行测试. 相比之下, 实验SB- 仅将初始种子的事务随机发送给数据库并发执行,
无法保证是否存在冲突以及是否能够涵盖数据库隔离级别实现的关键细节, 所以其覆盖隔离级别核心代码的效率更低. 其次, 实验SB 启用了变异引擎对测试案例进行并发事务组合和执行方式的变异.通过分析测试覆盖度反馈, 实验SB 能够判断具有新行为的测试案例, 并实时更新测试队列. 于是, 在后续的测试中, 这些具有新行为案例可以继续被选择进行变异和测试, 这样的机制可以推动测试的进一步进行. 相比之下, 实验SB- 不支持自适应变异的能力, 可能导致其测试案例的重复或缺乏多样性,从而限制了隔离级别核心代码测试覆盖度的提升速率.
综上所述, 以上测试结果表明, SilverBlade 能够对数据库隔离级别核心代码模块进行有效测试,并在与对比工具进行对比实验时, 测试结果数据显示SilverBlade 在隔离级别关键区域的测试覆盖率方面表现更佳. 实验表明SilverBlade 能够生成多样性的测试案例以更广泛地覆盖数据库隔离级别核心实现代码 (问题1). 同时, 实验也说明, 通过采用结构化测试输入结构、基于深度和广度搜索的搜索策略, SilverBlade 在并发事务组合和并发事务执行交互的测试空间中进行更高效和全面的搜索. 这种方法有效地提升了隔离级别核心代码区的测试覆盖度 (问题2).
4 结论与展望
综上所述, 本文研究了数据库隔离级别内容模糊测试, 并实现了工具SilverBlade. 首先, 通过结构化测试结构的设计, SilverBlade 生成多样化的并发测试案例, 并模拟这些案例的事务执行交互, 从而提高了数据库隔离级别测试的覆盖度.
本文所提出的工具SilverBlade 支持深度和广度搜索的变异方式, 这样的方法使得测试能够更全面地搜索数据库隔离级别的测试空间. 广度搜索变异方式引入多样性的事务组合, 深度搜索变异方式增加了事务执行交互的多样性, 以更好地模拟具有读取和写入操作序列的并发事务执行. 通过二者结合, 可以促进测试生成多样的事务并发场景, 从而对数据库隔离级别核心代码进行全面的测试.
实验结果表明, 与传统对比工具相比, 本文设计的原型系统SilverBlade 在测试数据库隔离级别时具有更好的测试能力. 通过提高测试覆盖度, SilverBlade 能够更全面地探索数据库隔离级别测试空间,这更有助于开发人员发现并纠正在传统测试方法中可能被忽视的潜在隔离级别问题. 本文所提出的模糊测试方法通过提高测试覆盖度, 为数据库隔离级别的评估和改进提供了新的视角.
未来的研究方向计划进一步扩展和优化SilverBlade 模糊测试方法, 以进一步提高SilverBlade 测试能力. 可以探索更多的测试案例生成技术, 如基于更新颖模型的生成方法或符号执行技术, 以生成更多的有代表性的测试案例. 此外, 可以考虑利用人工智能技术与动静态分析的方法相结合, 以提高对数据库隔离级别智能化的全面检测能力.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
基层中医药(2021年8期)2021-11-02
河南水利年鉴(2020年0期)2020-06-09
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
