
基于持久化内存和共享缓存架构的高性能数据库
2023-09-22 01:09王聪聪胡卉芪
华东师范大学学报(自然科学版) 2023年5期
王聪聪, 胡卉芪
(华东师范大学 数据科学与工程学院, 上海 200062)
0 引 言
在过去的十年中, 云计算技术经历了飞速的发展. 在这一趋势的影响下, 数据库市场的重心已经逐渐从企业内部向云端迁移. 众多商业云数据库, 如亚马逊的Aurora[1]、阿里巴巴的PolarDB[2]等, 已被广泛应用. 云数据库是一种基于云计算平台的数据库系统, 以服务形式提供给用户. 该系统利用云计算中的资源池技术, 将数据库的存储、计算和网络资源进行统一管理和调度, 以提供灵活、可靠、易用且可扩展的数据库服务.
云原生数据库的崛起改变了人们对于数据库设计前景和权衡的理解. 在分布式系统设计中, 对于无共享架构和共享存储架构的选择, 存在着深入的争论. 许多早期的在线事务处理 (on-line transaction processing, OLTP) 系统, 例如Spanner[3]和CosmosDB[4], 都积极推动使用无共享架构以扩展OLTP 系统, 从而超越单一系统的处理能力. 然而, 在云数据库的发展背景下, 这种立场可能已经不再那么明确. 云服务为数据库带来了全新的需求, 例如计算层和存储层的弹性扩展, 以及灵活适应各种负载场景等. 在这些新需求的推动下, 共享存储架构再次受到了重视.
许多云原生数据库如Aurora[1]和Socrates[5], 都已经采用了共享存储架构. 在这一架构中, 首先所有的写入事务都在一个主节点上完成, 其次该主节点将其写前日志 (write-ahead log) 发送到共享存储, 以供次级节点访问. 存储节点利用这些写前日志在后台重建数据页, 而这些重建的数据页可以被次级节点按需读取, 从而以较低的开销可在任何时候生成. 虽然这种设计提供了如热故障切换和弹性负载均衡等重要功能, 但其仍然受到主节点处理能力的限制. 这种限制在OLTP 常见的写入密集型负载场景下尤为明显.
在共享存储架构中简单地添加多个主节点并不能解决这一问题, 因为如果允许多个读写节点同时修改共享存储层, 那么为了保证数据的一致性, 读写节点之间的竞争将使共享存储层成为新的瓶颈.一个可能的解决方案是采用共享缓存架构, 即在共享存储架构中增加一层共享缓存, 从而让多个读写节点可以在共享缓存中修改数据项, ScaleStore[6]、Oracle RAC[7]和NAM-DB[8]都采用了这种设计. 然而, 这种设计需要解决缓存一致性的问题, 主要有两种方式: 一种是节点始终在共享存储中进行读写;另一种是节点间通过缓存一致性协议来保证数据的一致性. 虽然共享缓存架构可以有效满足云计算场景对内存扩展的需求, 但在提高数据库事务的可扩展性方面, 仍有许多待解决的问题, 例如时间戳的扩展瓶颈及事务持久化速度的缓慢等.
时间戳用于在事务中提供快照, 然而在共享缓存数据库中经常使用的全局时间戳存在线程级别的扩展性限制, NAM-DB[8]中采用的向量时间戳利用每个机器的时钟解决了线程级别的扩展性瓶颈,但仍然无法扩展到多台节点上. 此外在共享缓存数据库中, 新的页面会被快速地添加到节点的缓存中,因此共享缓存数据库需要快速地驱逐冷页到存储层, 然而由于页面需要在共享存储层完成持久化, 整个传输过程依然较慢, 如何实现快速持久化是一个重要挑战.
针对上述问题, 本文在共享缓存架构的基础上, 结合新型硬件—持久化内存, 实现了一个具有三层共享架构 (包括内存层、持久化内存层、存储层) 的数据库. 在此架构的基础上, 重新设计了事务的执行流程, 并针对若干关键技术进行优化, 以进一步提升数据库事务执行的性能. 本文的主要贡献有以下两点.
(1) 提出了一种解耦事务执行流程的共享架构. 通过利用持久化内存技术, 对共享缓存架构进行了重新设计, 引入了共享持久化内存层, 并对数据库事务的执行流程进行了优化. 本文利用持久化内存层的重做日志回放功能来重新生成页面, 从而消除了从共享缓存层驱逐脏页到存储层的过程. 这一设计有助于消除共享缓存的页面驱逐过程, 并实现快速的持久化.
(2) 提出了分布式向量时间戳技术. 为了解决在共享缓存架构下, 事务时间戳可扩展性的瓶颈问题, 本文利用RDMA (remote direct memory access)的原子更新能力, 设计了分布式向量时间戳技术.这项技术将时间戳分布式地维护在各个节点上, 并提供了一个一致的时间戳快照, 从而在多节点环境下显著提升了时间戳的可扩展性.
1 背 景
本章首先回顾了分布式数据库中的共享存储架构和无共享架构; 其次介绍了云数据库中的共享缓存架构; 最后针对当前共享缓存架构的一些问题提出了本文的架构设计—共享持久化内存架构.
1.1 分布式系统中的共享存储架构和无共享架构
分布式数据库的架构可分为共享存储架构(图1 (a)) 和无共享架构(图1 (b)) 两种. 在共享存储架构中, 所有节点都可以访问数据库的存储层; 然而, 在无共享架构中, 每个节点都有其私有存储, 其他节点无法访问.
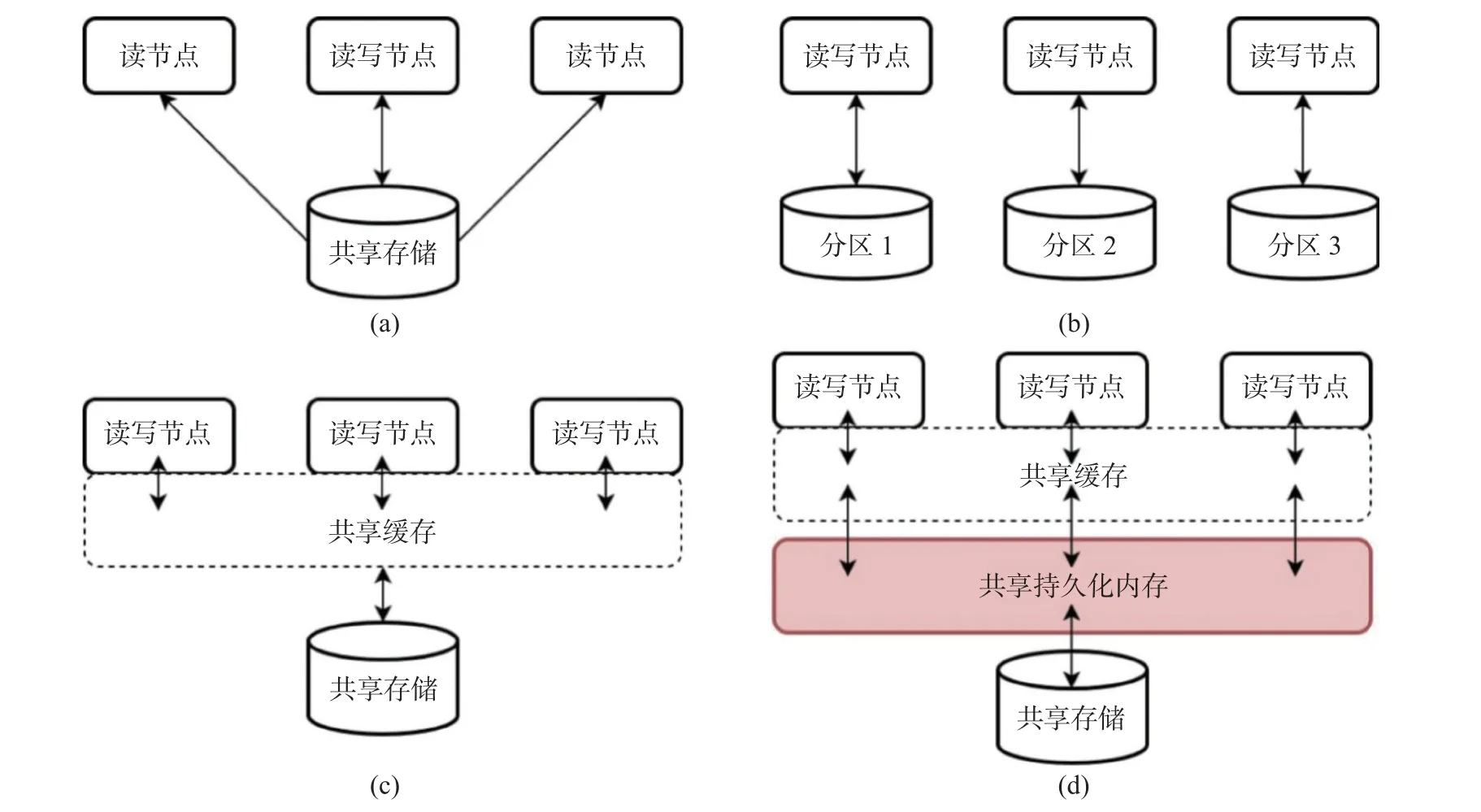
图1 分布式数据库的4 种经典架构Fig. 1 Four classical architectures for distributed databases
许多分布式数据库, 如IBM DB2[9]、AlloyDB[10], 采用了共享存储架构. 这些数据库允许多个节点访问共享存储的读副本, 但通常只有一个读写节点执行更新. 在读密集型负载下, 这种单一更新节点的架构能实现良好的扩展性. 计算与存储的分离架构能满足云计算场景下的快速故障切换和弹性需求, 同时系统的复杂度相对较低. 然而, 这种架构在处理写密集型负载时的扩展性受到单一节点能力的限制.
在无共享架构中, 数据库被分为多个分区, 每个分区仅由相应的读写节点更新. 该架构通过数据分区将数据分散在各个节点上, 各节点负责对其本地分区进行读写操作. 现有的数据库系统如MongoDB[11]及Cassandra[12]等, 主要依靠两阶段提交来确保分布式事务的原子性. 与共享存储架构的单一读写节点相比, 该架构的可扩展性更好, 其可以通过分区将工作分配到对应的节点上. 与之相反,在处理带有热点的倾斜访问时, 由于对热键的请求都集中在这些节点上, 被频繁访问的少数节点可能成为新的瓶颈. 从弹性扩展的角度看, 由于增加新的节点可能需要对数据库进行重新分区, 该架构的弹性相对较有限.
1.2 云背景下的共享缓存架构
在共享存储架构中, 允许多个读写节点同时对存储层进行更新的情况下, 主要问题在于存储层可能会受到来自不同读写节点的大量请求, 这将成为一个瓶颈, 从而限制存储层和计算层的可扩展性.此外, 每次数据访问都需要进行网络通信以访问存储层, 这会显著增加访问延迟. 针对这些问题, 图1 (c)中的共享缓存架构得以被提出. 在共享缓存架构中, 频繁访问的数据项被存储在共享缓存层, 从而显著降低了访问延迟. 同时, 共享缓存层允许多个读写节点更新数据, 并通过缓存一致性协议来保证数据的一致性. 虽然共享缓存架构在处理倾斜访问时的可扩展性仍然有限, 但在云服务场景中, 它带来了许多优点, 如良好的弹性 (新添加的计算节点的缓存可以在访问过程中逐渐填充), 以及灵活性 (不依赖用户分区, 可以根据不同负载场景自适应数据的分布).
然而, 在共享缓存架构中, 仍然存在许多需要解决的问题, 尤其是在OLTP 云数据库的事务处理场景中. 本文主要列举了以下几点.
(1) 数据持久化速度慢. 首先, 因为共享缓存层中的页面是易失性的, 因此数据库可能需要将脏页面或日志写入到存储层. 其次, 数据从共享缓存层到共享存储层的传输速度较慢, 这降低了写入速度.这引发了两个问题: 一是在云场景中, 节点的本地缓存可能会很快被填满, 如果不能快速驱逐冷页面,将导致共享缓存的性能受限; 二是数据库的事务处理流程通常需要先将持久化日志写入到存储层, 如果写入速度慢, 那么可能重新出现事务的可扩展性瓶颈.
(2) 事务时间戳的可扩展性瓶颈. 共享缓存架构没有解决事务时间戳的可扩展性瓶颈. 主要原因有两点: 一是共享缓存层的时间戳管理线程不能随事务数量的增加而增加; 二是在访问时间戳时, 每个计算节点都会对同一个内存区域进行RDMA Fetch & Add 操作, 对同一内存位置的RDMA 原子操作会随并发操作数的增加而增加, 而RDMA 原子操作的同步成本很高.
(3) 维护缓存一致性协议目录的延迟高. 共享缓存通常需要基于目录的缓存失效协议来保证页面的一致性.页面的目录通常存储在不同的存储节点上, 这些目录主要负责管理基于失效的缓存一致性协议的元数据. 尽管以页面粒度组织数据可以减少修改目录的次数, 但由于从共享缓存层访问存储层的延迟较大, 所以记录目录的成本依然较高.
1.3 共享持久化内存架构
新型存储介质持久化内存 (persistent memory, PM) 成功地在共享缓存层和存储层之间架设了桥梁. 2019 年, 英特尔推出了首款商品化的PM 产品—Optane PM. 一些基于CXL (compute express link) 的解决方案也试图通过整合DRAM、闪存SSD 以及兼容内存的互连技术来靠近PM. PM 的优势在于其字节寻址能力、数据持久性以及快速访问速度. 此外, 结合了RDMA (remote direct memory access) 技术后, PM 可以实现低延迟的数据访问. 鉴于以上特性, PM 成为了解决共享缓存架构中现存问题的一种理想选择.
为了解决共享缓存架构存在的问题, 本文提出了TampoDB: 一个在线事务处理 (OLTP) 共享数据库. 该数据库整合了RDMA、DRAM、PM 和SSD 等多种技术. 如图1 (d) 所示, TampoDB 的设计基于三层共享架构, 包括共享缓存层、共享持久化内存层及共享存储层.
(1) 共享缓存层. 共享缓存层位于存储架构的顶层, 有最低的访问延迟, 但又是易失性的. 该层主要用于存储频繁访问的页面.
(2) 共享持久化内存层. 该层是非易失性的, 提供与DRAM 相近的低延迟访问性能, 并通过RDMA 实现快速的网络访问. 在TampoDB 中, 该层用于存储持久化日志、日志回放生成的页面以及缓存目录.
(3) 共享存储层. 位于存储架构的最底层, 其访问速度相较于共享缓存层和共享持久化内存层较慢. 该层用于储存所有的数据页.
2 TampoDB 设计
本章首先全面概述了TampoDB 三层架构的构成与功能, 并解析了三层之间如何协同工作以执行事务; 其次, 详细阐述了TampoDB 是如何执行事务的, 以及如何将事务在共享缓存层和共享持久化内存层之间解耦, 从而加快事务的持久化过程; 最后, 介绍了如何将向量时间戳扩展到多个节点, 并提出分布式向量时间戳技术.
2.1 设计概述
TampoDB 的整体架构如图2 所示. 事务的执行主要在共享缓存层进行, 持久化日志和页面的回放则在共享持久化内存层完成, 而共享存储层主要用于存放冷页面. TampoDB 在共享缓存层和共享持久化内存层中, 都会维护同一个逻辑页面的两个物理页面. 图中的箭头展示了事务执行的过程. 对于事务执行过程中需要访问的页面, 首先需要判断该逻辑页面是否存在于共享缓存层. 如果逻辑页面不在共享缓存层, 那么事务则需要访问共享存储层以获取所需页面, 同时, 该页面的副本也会被添加到共享缓存层和共享持久化内存层. 如果逻辑页面在共享缓存层, 但对应的物理页面并未在共享缓存层, 那么就会触发一次缓存未命中. 这时, 后台线程会将该逻辑页面存在于共享持久化内存层中的物理页面换入共享缓存层, 以便事务能重新读取. 在事务执行过程中产生的重做日志将会被持久化到PM 层中的日志区域, 并由后台线程回放, 生成共享持久化内存层中的页面. 当共享持久化内存的空间受到压力时, 已完成回放的冷页面将被驱逐到共享存储层中.
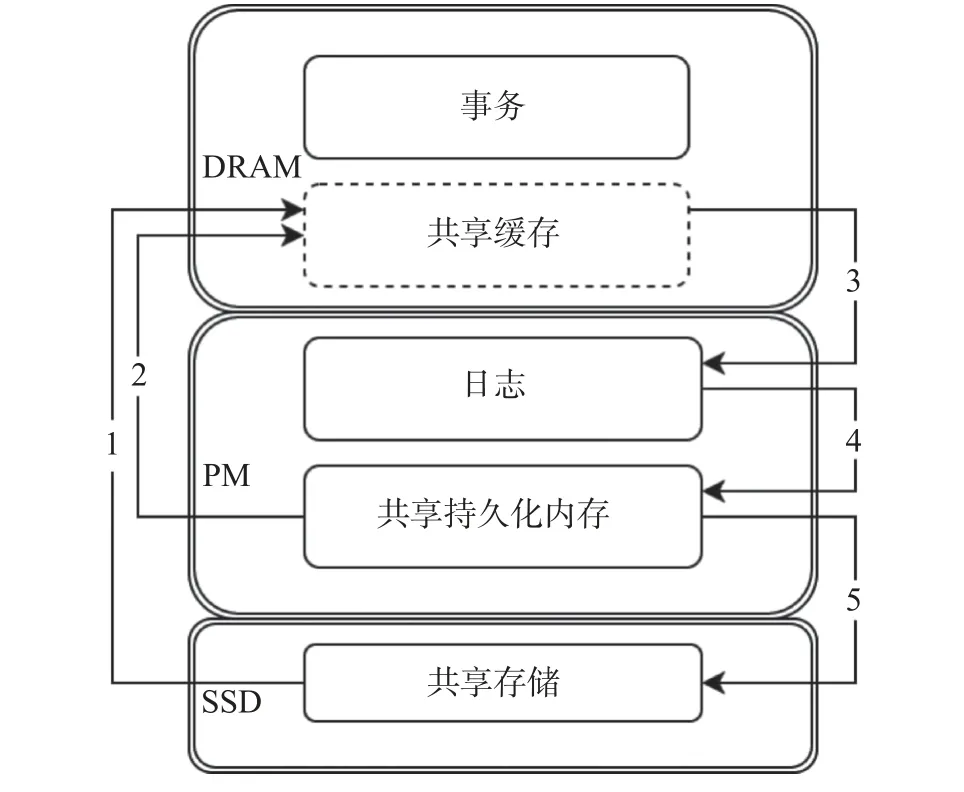
图2 TampoDB 的架构概览Fig. 2 Overview of TampoDB architecture
2.2 解耦的事务执行流程
TampoDB 的事务执行可以分为3 个阶段: 执行、持久化和回放.
(1) 执行. 在事务开始时, 会为其分配一个时间戳. 对于事务请求的每个页面,页面读取器将其读取到本节点的缓存中. 事务完全在本地执行, 由事务管理器将事务执行中产生的私有数据保存在本地.每个已提交的事务都会产生一个重做日志, 它将被临时存储在一个线程本地的日志缓冲区中, 以避免线程之间的争用.
(2) 持久化. 已提交的事务将其在日志缓冲区中的重做日志写入到本节点的持久化内存中, 此步骤由后台线程完成. 每个节点都将其私有日志文件写入, 从而确保事务的原子性和持久性.
(3) 回放. 系统对持久化日志进行回放, 并将其应用到共享持久化内存的页面中. 由于计算节点可能访问任何页面, 因此单个页面的更改会分散在多个本地日志中. 因此, 在回放过程中, 各节点的本地日志首先会发送到一个节点进行合并后再发送回各节点. 每个节点根据重做日志, 修改持久化内存中的页面数据. 回放也在后台进行.
TampoDB 能够利用持久化的重做日志在后台执行回放, 将更新同步到共享持久化内存中的页面.因此, 在事务执行过程中, 一旦完成持久化步骤, 就可以认为事务已经持久化. PM 层和DRAM 层被映射到同一地址空间, 事务执行过程中, 所有对日志数据的访问都会被重定向到共享缓存中的地址.事务在共享缓存层和共享持久化层之间是完全解耦的, 满足事务执行中对页面访问的较低延迟需求的同时, 又提升了共享缓存层脏页驱逐的效率, 因为事务持久化过程中不需要对共享缓存层进行脏页驱逐.
2.3 分布式向量时间戳
数据库通常使用一个全局计数器为事务提供全局时间戳 (global timestamp, GTS), 该时间戳代表了事务的执行顺序. 然而, GTS 机制不仅增加了事务之间的通信量, 还导致事务并发控制的扩展性存在较大瓶颈.
向量时间戳 (vector timestamp, VTS) 为每个计算服务器或线程维护提供一个逻辑时钟. 事务开始时需要获取最新版本的VTS 作为读取时间戳, 获取提交时间戳则相对简单, 只需将对应计算服务器的逻辑时钟递增1 (内存服务器也需要同步). 由于事务间的时间戳是独立的, 长时间运行的事务不会阻止读取时间戳的前进, 从而消除了线程级别的时间戳扩展性瓶颈. 然而, 目前的VTS 机制无法扩展到多台服务器, 因为这会导致不同工作线程之间无法获取一致的快照. VTS 机制受限于单个服务器带来的显著问题是VTS 的网络通信压力集中在单个节点上, 尽管使用RDMA 原子更新操作延迟较小, 但是性能下降和可扩展性瓶颈依然存在.
将VTS 扩展到多台服务器引入了一个新问题. 在单台时间戳节点上, 计算节点读取到的VTS 满足单调递增的关系. 但在多台服务器中读取VTS 会使其不再满足此特性, 因此需要添加一些约束, 以使不同计算节点读取到的时间戳重新满足递增的关系. 一个自然的想法是让所有计算节点按照相同的顺序访问每台时间戳服务器. 如果访问每台时间戳服务器的访问延迟是相同的, 这就可以保证多台服务器之间读取到的VTS 按照最初的访问顺序是满足单调递增的. 但由于每台时间戳服务器的访问延迟是不可控的, 必须添加额外的约束, 使多台服务器之间读取到的VTS 按照最初的访问顺序保持单调递增. 因此, 针对VTS 存在的问题本文提出了分布式向量时间戳 (discribute vector timestamp,DVTS), DVTS 在VTS 的基础上添加了两个约束规则以支持多节点间的扩展.
规则一: 所有计算节点在获取时间戳时, 必须按照固定的顺序访问时间戳服务器, 例如 (时间戳服务器1、时间戳服务器2、时间戳服务器3······) .
规则二: 每个计算节点在当前时间戳服务器读取的VTS 产生的偏序关系要和前一个访问的时间戳服务器读取的VTS 产生的偏序关系一致, 即若对于时间服务器n有an≤bn, 则有ai≤bi,∀i≤n.
相对于VTS 单个服务器的网络通信瓶颈, DVTS 利用RDMA 读取和原子更新操作将时间戳的更新和读取过程中的网络开销分布在多台服务器中, 避免单一服务器的通信瓶颈. 此外, 由于时间戳分布在不同节点的不同内存区域, RDMA 远程更新时避免了对统一内存区域的争议. 此外DVTS 可以实现在多台服务器之间的扩展, 具有更好的可扩展性.
在具体实现中, TampoDB 为时间戳服务器的每个时间戳维护一个 (tmin,tmax) 可见性区间,tmin和tmax分别代表前一个时间戳服务器访问当前时间戳服务器时间戳的最小和最大版本. 这个区间记录了访问前一个时间戳服务器所生成的时间戳的可见性范围, 时间戳的可见性区间之间满足单调递增的关系. 每个服务器会从当前最新的时间戳开始向前遍历, 直到找到符合可见性区间范围的时间戳为止.
3 主要组成部分
本章首先描述了TampoDB 架构由哪些主要组成部分构成(图3); 其次详细描述了主要组成部分的功能及实现.

图3 TampoDB 的组成部分Fig. 3 Components of TampoDB
DRAM 层主要用于处理事务, 由事务管理器负责执行.页面读取器负责在事务执行过程中获取所需的页面, 可能需要从本节点或远程节点进行获取. 在后台, 分布式向量时间戳会持续生成满足递增关系的向量时间戳, 并在事务管理器首次访问时进行分配. 日志写入器负责将事务执行过程中产生的重做日志首先写入日志缓冲区, 以便事务执行过程中的访问; 其次, 由专门的后台线程将数据日志和元数据日志写入PM 的日志区域.页面的回放也在后台进行, PM 中的持久化日志的更改会被同步到共享持久化内存中的页面上.
TampoDB 采用了一种基于目录的缓存一致性协议, 这种协议能在页面粒度上提供一致性. 根据缓存一致性协议,页面根据其所有权被分为3 种状态: 独占、共享、失效. 协议通过失效动作来确保页面的一致性, 例如每当某个节点打算修改一个页面时, 这个节点就会向跟踪当前缓存此页面的节点的目录并发送失效请求, 从而使页面由独占或共享状态转换为失效状态. 每个节点都充当一些页面目录的存放节点, 并负责管理存储在其本地PM 中的目录. TampoDB 使用页面ID 定位到目录,页面ID 共有64 位, 前8 位记录节点ID, 后56 位记录该页对应目录的偏移量. 目录主要包含缓存一致性协议中的元数据. 如上图所示,页面P2 被本节点以独占模式持有, 而页面P1 则被节点0 和1 以共享模式缓存.
页面读取器对页面的访问包括本地节点访问和远程节点访问两种方式. 在本地节点访问时,页面读取器首先会查找位于DRAM 中的页表, 以判断页面是否存在于本地缓存中.页表中还额外记录了页面的所有权信息、页锁状态以及驱逐信息.页面的所有权分为节点独占和节点共享两种. 每个工作线程在访问页面之前, 必须先检查所有权是否正确: 写入页面需要在独占模式下进行, 而读取页面则可以在共享模式或独占模式下进行. 在确认所有权正确后, 就可以对页面进行加锁并进行访问. 而在进行远程节点访问时, 如果页面不在本节点的缓存中, 就需要向该页面的目录节点发送请求. 目录节点的消息处理程序在收到请求后, 也需要先检查页面的所有权是否正确. 如果所有权正确, 它会修改缓存目录, 将该页面的目录和页面数据发送给请求节点.
4 实 验
本章展示了TampoDB 在优化事务执行流程和时间戳后的性能表现. 通过与NAM-DB 进行对比,评估了 TampoDB 在不同负载场景下的吞吐表现. NAM-DB 是一个两层的 (计算层和内存层) 共享内存数据库, 其不依赖于缓存一致性协议而是通过RDMA 单边读和写分别读取和更新远程数据, 以此来保证数据的一致性. 此外NAM-DB 在事务执行中采用向量时间戳并使用结合RDMA 的SI 协议以进一步提高事务可扩展性.
4.1 实验环境
实验在两台相同配置的服务器上进行, 操作系统为CentOS Linux release 7.9.2009, 服务器硬件配置为 Intel(R) Xeon(R) Silver 4 110 CPU @ 2.10 GHz 16 核心, 32 线程; 内存容量为512 GB; 持久化内存容量为2 TB; SSD 容量为8 TB.
4.2 读密集负载场景检测性能
为了对比TampoDB 在读密集负载场景下的性能, 本文使用YCSB 1B 记录 (300 GB)的负载, 设置90%读取和10%写入访问分布在2 台节点上, 图4 显示量均匀(uniform)和倾斜(zipf-1)访问下的吞吐量表现, 在均匀访问时二者性能接近, 然而在倾斜访问时由于更多的数据会分布在TampoDB 本节点缓存, 因此性能表现显著优于NAM-DB.

图4 TampoDB 在读密集负载场景下的吞吐Fig. 4 Throughput of TampoDB in read-intensive workload scenarios
4.3 写密集负载场景检测性能
为了对比TampoDB 在写密集负载场景下的性能, 本文同样使用YCSB 1B 记录 (300 GB)的负载, 设置90%写入和10%读取访问分布在2 台节点上, 图5 显示了均匀(uniform)和倾斜(zipf-1)访问下的吞吐量表现, 在两种情况下TampoDB 表现均优于NAM-DB, 在均匀访问的情况下写入速度依然提升了25%. 由于NAM-DB 在写入时使用RDMA 原子写的方式, 在倾斜访问时由于竞争严重导致性能下降. 在数据均匀分布时, 由于NAM-DB 需要在事务写集更新前将日志写入到内存服务器, 而TampoDB事务执行时对页面更新和日志持久化是解耦的, 因此写入性能依旧优于NAM-DB.
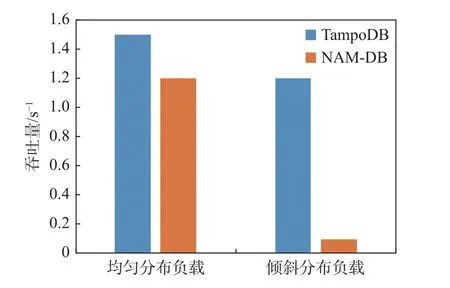
图5 TampoDB 在写密集负载场景下的吞吐Fig. 5 Throughput of TampoDB in write-intensive workload scenarios
4.4 分布式向量时间戳性能测试
为对比分布式向量时间戳在不同负载场景下的性能表现, 本文同样使用YCSB 1B 记录 (300 GB)的负载, 设置在2 台节点上, 图6 显示了在TampoDB 中使用VTS 和DVTS 分别在读密集和写密集负载下并且数据均匀分布的吞吐量表现. DVTS 在读密集访问和写密集访问负载下相较于VTS 吞吐量分别提高了16%和13%. DVTS 将单台时间戳服务器的读写请求分布到两台时间戳服务器上, 减少了单台服务器的时间戳通信开销.

图6 分布式向量时间戳在读写密集负载下的吞吐Fig. 6 Throughput of DVTS in read-intensive and write-intensive workload scenarios
5 结 论
本文针对共享缓存架构中的数据持久化速度慢、事务时间戳的可扩展性瓶颈、维护缓存一致性协议目录的高延迟等问题, 基于共享缓存架构设计了TampoDB. 为了解决持久化速度慢的问题,TampoDB 添加了一个共享持久化内存层, 并将事务的执行和持久化过程进行了解耦. 此外,TampoDB 还重新设计了分布式向量时间戳, 并利用PM 加速了缓存目录的修改, 从而提高了事务的可扩展性. 实验证明, TampoDB 能高效地执行事务. 当前的研究主要集中在持久化日志方面, 而在后续的研究中, 共享缓存架构下的数据迁移和驱逐策略也是值得探讨的问题.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
河南水利年鉴(2020年0期)2020-06-09
小学生(看图说画)(2017年6期)2017-11-06
汽车零部件(2017年3期)2017-07-12
自动化博览(2017年2期)2017-06-05
电脑知识与技术(2016年14期)2016-06-30
现代工业经济和信息化(2016年12期)2016-05-17
电子设计工程(2014年19期)2014-02-27
