
聚合高阶邻居节点的异构图神经网络模型研究
2023-09-06 04:29谭鑫媛裴颂文
小型微型计算机系统 2023年9期
谭鑫媛,裴颂文,2
1(上海理工大学 光电信息与计算机工程学院,上海 200093)
2(中国科学院计算机体系结构国家重点实验室,北京100190)
1 引 言
图(Graph)作为计算机数据结构中的一种基础结构,相对其他数据结构更加灵活,因此常被用来描述和建模较为复杂的系统.对图进行多角度、多层次的分析能够帮助用户更深入地了解数据背后所隐含的内容,从而使其可以作用于各业务场景的后续任务中,如节点分类、链接预测、节点相似度分析、节点推荐等.图嵌入(Graph Embedding)将图数据转换到一个低维空间,在这个空间中图的结构信息和属性被最大限度地保留[1],能够解决图数据难以高效输入机器学习算法的问题.
包括GNN和GCN在内的大多数现有的图神经网络都基于一个前提:节点和边的类型是唯一的,即它们的数据是同构图(Homogeneous Graph).然而现实生活中的许多图结构通常具有多种类型的节点和边.因此,越来越多的研究人员开始关注通过异构图(Heterogeneous Graph)神经网络来挖掘数据.异构图所特有的异构性,使它能够蕴含更多的信息,但同时也使它比同构图面临更多的挑战,即如何聚合不同类型的邻居、平衡不同类型节点或边之间的关系.许多异构图嵌入模型为了探索异构图的语义信息,需要依靠元路径(meta-path)、元关系(meta relation)或元图(meta graph),而它们使得模型至多只能聚合一阶同类型邻居节点.MixHop[2]已经证明高阶邻居对图分析任务是非常有用的,然而现有的图嵌入模型常常忽视对于高阶邻居中有效信息的挖掘.当不同目标节点的邻域高度重合时,可能会使输出的嵌入向量过于相似,使节点无法区分,产生过平滑[3]的现象.此外,堆叠多层GCN模块也可能产生过平滑问题.
因此,本文提出一种聚合节点高阶邻居的异构图神经网络HONG(Higher-Order Neighbors Heterogeneous Graph Neural Network).首先引入目标节点基于元路径的k阶邻居子图;其次,提出一种根据k阶邻居子图计算邻居节点重要性得分的方式,与RepPool[4]中的节点代表性形成组合分数,通过该组合分数对k阶邻居子图进行下采样,防止过平滑现象的发生,并结合GCN学习目标节点复杂结构特征;最后使用注意力机制与HAN学习到的低阶语义信息进行融合,得到节点的最终表示.
本文的主要贡献是:
1)提出一种构造节点高阶邻居子图的方法,以及一种面向异构图的池化层HetRepPool(Heterogeneous Graph Pooling with Representativeness),结合GCN生成了异构图高阶邻居节点中的复杂结构信息.
2)提出一种能够聚合高阶邻居节点中复杂结构信息的异构图嵌入模型HONG,实现了异构图节点在低维空间中的表示.
2 相关工作
目前存在的图嵌入方法可分为两类,即浅层嵌入学习和图神经网络[5].node2vec[6]是较为典型浅层嵌入学习方法.图神经网络的概念是由M Gori等人[7]首次提出的,该研究扩展了递归神经网络,使其应用于不规则的图数据,并做了进一步的阐述.随后,有大量关于图神经网络的研究出现.Wu等人[8]将现有的图神经网络分为4类,即递归图神经网络、卷积图神经网络、图自动编码器、时空图神经网络.但是,大多数图神经网络模型都是针对同构图的神经网络.
近年来,越来越多的研究开始专注于挖掘异构图中的丰富信息.异构图中不同类型的边隐含着不同的语义,而聚合语义信息对异构图嵌入来说至关重要.常见的探索不同语义的方法有元路径、元关系、元图等.HGT[9]通过基于元关系三元组分解每条边,使模型在捕获不同关系之间的模式时所用的参数更少或相等.Meta-GNN[10]提出元图的概念,并以此定义目标节点在进行卷积时周围的感受野.由于在探索语义时受到元路径、元关系、元图等的限制,使得模型至多只能聚合目标节点一阶同类型邻居内所蕴含的信息.
池化操作在图像处理中展现出优越的能力,图池也随之发展起来.由于池化和上采样操作无法自然地使用到图数据上,Gao等人[11]提出gPool和gUnpool,使编码器-解码器架构U-Nets应用于图嵌入.RepPool[4]通过节点重要性和节点代表性这两个维度对图进行粗化,使得神经网络可以学习图的层次表示,并用于图分类任务上.KGCN-PL[12]引入池化层得到邻居的差异化权值,实现知识图推荐.然而这些模型都是针对同构图的池化操作,很少有针对异构图的池化操作.
图嵌入模型将图数据表示为低维度向量后,可以更方便地输入其他机器学习方法,来实现具体业务场景下的需求,如Ying等人[13]使用ConvGNNs作为编码器,查找节点的最近邻并进行推荐,Nikolentzos等人[14]使用图级嵌入对化合物、有机分子或蛋白质结构等化学物质进行分类.此外,根据图嵌入模型的输出,可以将其分为3种不同的任务类型:节点级、边级、图级[8].大多图池操作都是用于图级任务上,很少有用于节点级任务的图池.
3 异构图嵌入模型
本节将详细阐述所提出的聚合高阶邻居节点的异构图神经网络HONG,模型总体框架如图1所示,可分为语义学习、结构学习和信息融合3个阶段.
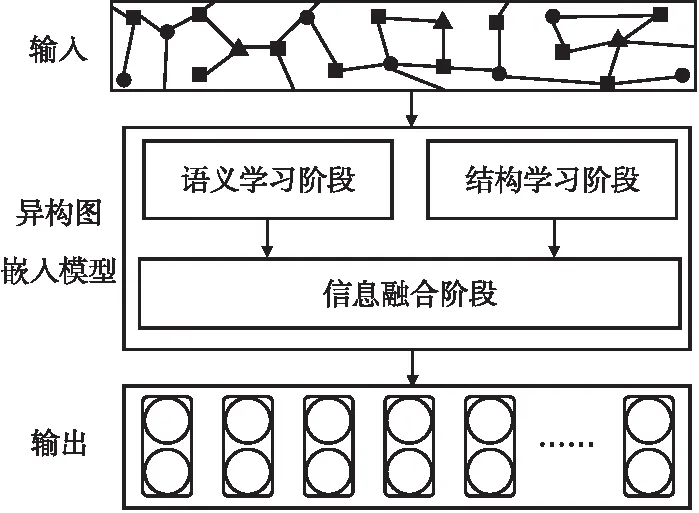
图1 HONG模型整体框架图Fig.1 Overall framework of the HONG
在语义学习阶段,使用通过元路径聚合目标节点直接邻居的HAN模型.HAN将注意力机制用在了节点级和语义级两方面,分别学习节点和元路径的重要性,其细节已在文献[15]详细阐述.本文将该阶段得到的目标节点vi的嵌入向量表示为:
zsem i=HAN(V,E,Q,R,P,Xi)
(1)
在结构学习阶段,使用GCN聚合节点的高阶邻居,学习节点的局部拓扑结构信息;提出并使用面向异构图的池化层HetRepPool,防止过平滑的同时学习更高维的特征.
信息融合阶段,使用注意力机制,平衡语义信息与结构信息,生成最终的嵌入向量.
3.1 问题定义
异构图与同构图的不同之处在于,同构图只拥有一种类型的节点和一种类型的边,而异构图包含多种类型的节点或多种类型的边.异构图与元路径的定义可参考文献[15].
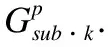
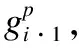
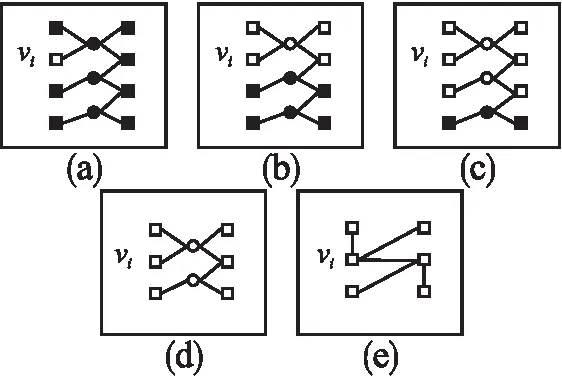
图2 生成子图的过程Fig.2 Process of generating subgraphs
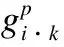
Z=F(V,E,Q,R,P,Gsub·k,Asub·k,X)
(2)
其中,模型所得到的最终嵌入Z∈Rn×d,d是嵌入维度.
3.2 结构学习
为了能够学习目标节点高阶邻居中更高维的结构信息,需要池化操作保留数据中最为突出的特征.本文使用GCN配合所提出的HetRepPool学习异构图高阶邻居的结构信息,该阶段的框架如图3所示.具体地说,就是将一个HetRepPool组件放在GCN组件之后,将得到的结果再输入到一个GCN组件中,并如此重复数次.
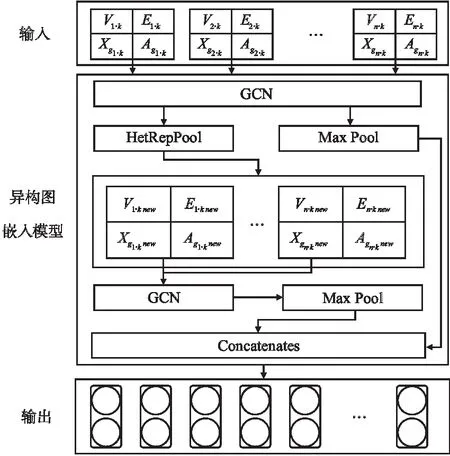
图3 结构学习阶段框架图Fig.3 Framework of structural-level learning
1)构造子图
卷积操作在图像处理领域上,常用来学习整张图片的信息.相应地,GCN在图结构上,也常用来卷积全图,继而为图级任务所服务.因此,首先需要通过构造目标节点的子图,使GCN通过卷积子图而非全图,来实现节点嵌入.
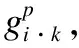
(3)
(4)
其中,Vi·k是gi·k是中节点的集合,Ei·k是gi·k中边的集合.由于gi·k是根据元路径所生成的子图,所以Vi·k中的每一个节点类型与目标节点类型相同.根据子图gi·k可以轻易得到邻接矩阵Ai·k,Xi·k则在矩阵X中选取与Vi·k对应的特征向量并组成新的矩阵.
2)节点选择
为了学习目标节点高阶邻居中的有效信息,并尽可能保留目标节点的结构信息,需要选取对目标节点而言重要的节点.本文认为在异构图中,对目标节点而言,各种语义下反复出现的邻居节点对目标节点而言具有更高的重要性,因此本文提出的异构图节点重要性分数通过语义层面进行评估.此外,为了在使用GCN时能够学习到更高阶的结构特征,需要覆盖尽可能多的子结构,防止池化后的图向某一子结构倾斜,而使用了代表性分数.HetRepPool通过重要性分数与代表性分数形成的组合分数选择节点.
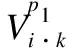
(5)
如果一个节点的语义代表性得分较高,且其邻居的语义代表性得分也很高,则意味着该节点包含更丰富的信息,更为重要.具体地说,公式(6)与公式(7)描述了k阶邻居子图中节点重要性的计算.节点vj的重要性得分sj为:
(6)
其中,N(vj)是节点vj的直接邻居,m(vt)的定义如下:
(7)
其中,xt是节点vt的输入特征,即特征矩阵Xi·k的第t行.m∈Rd是一个可学习的向量,将xt投影到m(vt).
B.节点代表性:由于仅根据重要性选择节点可能会使所选节点局限于子图中的某些子结构,而忽略其他子结构,但这些具有偏向性的信息聚合已经在语义学习部分完成了.因此除节点重要性分数外,为了学习到更高阶的结构特征,还需要代表性分数使选取的节点覆盖更多子结构,即选取那些远离已选节点的节点,以此保证能学习到子图中更丰富结构信息.
在选择节点时需要对节点逐一进行选择.具体地说,假如已经选择了一组节点,其索引集表示为idx,则候选节点vj的代表性得分δj为:
δj=f(h(vi,vj),i∈idx)
(8)
其中,h(·)是测量vi于vj之间距离的函数,f(·)是定义vj与已选择的所有节点之间的距离函数.根据经验,将h(·)定义为vi与vj与之间的最短路径,f(·)定义为vj与idx各节点的最小成对路径较为有效.因此,公式(8)可写作:
(9)
这使得越靠近已选节点的候选节点获得的代表性分数越低,而距离已选节点越远的候选节点获得的代表性分数越高.
C.节点选择算法:通过结合节点重要性分数与代表性分数,可以得到节点选择的分数γj:
γj=g(sj,δj)
(10)
其中,g(·)是组合重要性分数与代表性分数的函数,可以选择设置为线性组合、神经网络等.本文设置γj=sj×δj.
在进行节点选择时,首先计算重要性分数sj,并选取重要性分数最高的节点作为初始选择节点,其索引存入idx集合.其次,计算其余节点对已选节点vi(i∈idx)而言的代表性分数δj.接下来,将重要性分数与代表性分数合并得到γj,选择γj最大的节点vj,并将其索引存入idx中.将上述过程重复(α-1)次,节点将以贪婪算法的思想逐一进行选择,最终会得到包括初始选择节点在内共α个节点.
3)粗图生成
在完成节点选择后,将根据所选节点idx生成一个池化后的粗子图.对粗子图进行卷积操作,能够学习到图中更高阶的信息.通过特征矩阵和邻接矩阵可以确定一个粗子图.本文生成粗子图特征矩阵和邻接矩阵的方式与文献[4]类似,因此不再赘述.本文使用Xgi·knew表示新生成粗子图的特征矩阵,使用Agi·knew表示新生成粗子图的邻接矩阵.
4)图卷积
HetRepPool剔除掉了图结构中的冗余信息,保留下来更重要、更具有结构代表性的节点,之后还需要学习这些节点之间的关系.GCN[16]的本质就是提取图的结构特征,因此本文使用GCN对原始子图和粗化后的子图进行学习,接着使用Max Pool对卷积后的结果进行降维.
如果将第1次粗化后的子图表示为g′i·k,则GCN首先对原始子图gi·k进行卷积并降维,再对池化后的子图g′i·k进行卷积并降维.得到的结果可表示为:
z′str i·k=MAXPool(GCN(gi·k))
(11)
z″str i·k=MAXPool(GCN(g′i·k))
(12)
其中,GCN(·)是GCN模块,其计算方式与文献[16]相同.MAXPool(·)是最大池化层.z′str i·k是对原始子图使用图卷积并降维后的结果,z″str i·k是对一次粗化后的子图使用图卷积并降维后的结果.结构学习阶段所学习到k的阶子图的最终表示为:
zstr i·k=Concatenates(z′str i·k,z″str i·k)
(13)
其中,Concatenates(·)表示拼接函数,将z′str i·k与z″str i·k与按行拼接,得到最终的结构学习输出zstr i·k.
3.3 最终的嵌入表示
在通过语义学习阶段和结构学习阶段后,得到目标节点vi的语义表示zsem i和拓扑结构表示zstr i·k,使用注意力机制将两者进行融合,生成vi最终的嵌入表示:
zfinal i=β·zsem i+(1-β)·zstr i·k
(14)
其中,β是可学习的注意力向量.用Z表示HONG模型的最终输出结果,zfinal i即为Z的第i行.
3.4 损失函数与训练方法
本文将最终的嵌入向量用于节点分类任务,并根据分类的结果对节点的嵌入向量表示进行训练.对于全监督分类任务,本文选择最小化预测值与真实值之间的交叉熵:
(15)
其中,C是分类器的参数,V是节点索引集,Yi是节点的真实标签,Z是节点的嵌入.本文通过反向传播与早停法优化模型.
4 实验与分析
4.1 数据集
本文使用了网络上公开的异构图数据集(1)https://github.com/Jhy1993/Datasets-for-Heterogeneous-Graph,并分别从3种不同领域的数据集中提取出一个子集.
1)ACM.本文提取出一个包含1110篇论文、2467位作者、38个主题的ACM子集,其中论文具有3种标签:数据库、无线通信、数据挖掘.使用的元路径为{PAP,PSP}.从中随机选取600篇论文作为训练集,150篇论文作为验证集,360篇论文作为测试集.
2)DBLP.本文提取出一个包含5158篇论文、960位作者、20个会议、5122个术语的DBLP子集,其中作者具有3种标签:数据库、数据挖掘、机器学习.使用的元路径为{APA,APCPA,APTPA}.从中随机选取550位作者作为训练集,150位作者作为验证集,260位作者作为测试集.
3)Douban Movie.本文提取出一个包含1541部电影、2266名演员、811位导演的Douban Movie子集,其中电影可分为3类:动作片、喜剧片、戏剧片.使用的元路径为{MAM,MDM}.从中随机选取800部电影作为训练集,200部电影作为验证集,541部作为测试集.
4.2 实验基准
本文将所提出的HONG模型与其他基准实验进行了比较,以验证HONG的优越性.
GCN[16]是半监督的图卷积网络,主要针对同构图.本文将GCN用于异构图的所有元路径,并取最佳性能.
GAT[17]通过多头注意力机制为每个邻居节点分配权重,主要针对同构图.本文将GAT用于异构图的所有元路径,并取最佳性能.
GraphSAGE[18]通过学习从节点的局部邻域采样和聚合特征的聚合函数来生成节点的嵌入表示,主要针对同构图.本文选择的聚合方式为LSTM,并将GraphSAGE用于异构图的所有元路径,取最佳性能.
HetGNN[19]利用重启的随机游走策略和Bi-LSTM来对异构图节点进行编码,可以通过游走得到不同类别的邻居.
HAN[15]是一种同时采用节点级注意和语义级注意的半监督异构图神经网络.
GAHNE[20]面向异构图,在图卷积的基础上进行了改进,可以聚合来自不同单一类型子网络的语义表示.本文选择的聚合方式为池化.
HONG是本文所提出的聚合节点高阶邻居的异构图神经网络模型.
4.3 参数设置
对于语义学习阶段,本文将学习率设置为0.005,正则化参数设置为0.001,语义层面注意向量的维度为64,注意头的数量为8,注意力的dropout为0.6.对于结构学习阶段,设置两层GCN与池化,GCN隐藏层维度为64;在进行节点选择时,最大选择节点数为当前子图中节点总个数的30%.构造子图时的邻居阶数k=3.
训练时,采用Adam优化器进行优化,最大训练数设置为150.并使用早停法(Early Stopping),耐心值设置为50.
为了公平比较,所有算法的最终嵌入维度都被设置为256.
4.4 节点分类任务
当HONG模型被训练好后,就可以通过前馈得到输入图的节点嵌入向量.本文使用KNN分类器对节点进行分类,以验证嵌入模型的有效性.其中,KNN的参数K设置为5,并使用Macro F1分数和Micro F1分数作为评价指标,分数越接近1则代表模型的精确率越高.
表1是将各模型训练完成并作用于测试集上的表现.可以看出,HONG聚合了更高阶的邻居,在分类任务中的准确率较HAN而言,不但没有下降,反而有所提升.由此可证明,所提出的HONG能够显著改善节点嵌入的结果,并进一步证明了高阶邻居中存在有效信息.
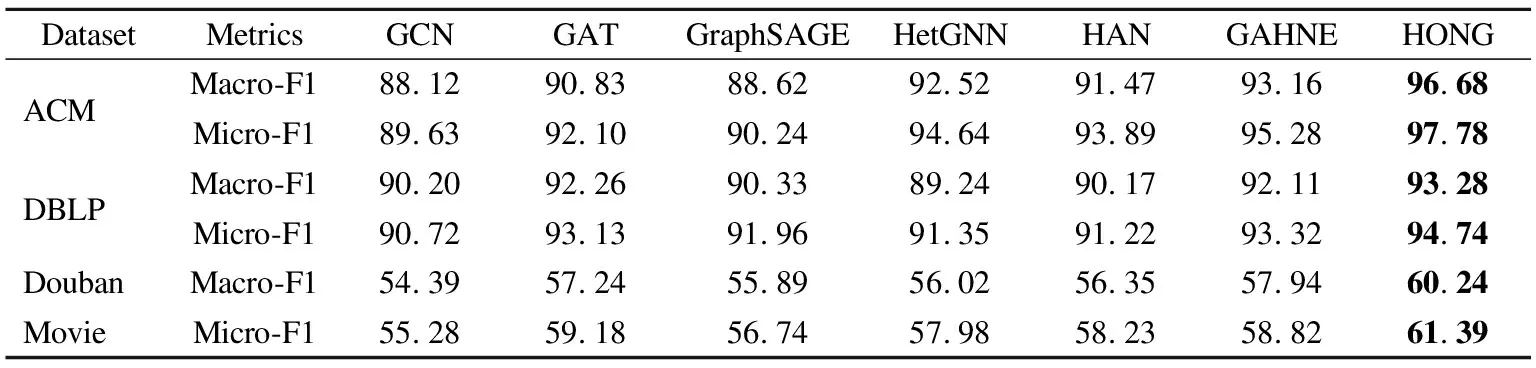
表1 节点分类任务的结果(%)对比Table 1 Quantitative results(%)on the node classification task
4.5 节点聚类任务
本文使用KMeans方法,将模型所得到的嵌入向量用到了聚类任务上.其中,KMeans的参数K设置为数据集的标签种类数,即节点实际的种类数,并使用NMI及ARI对聚类结果进行评价.NMI是标准化互信息,用于度量聚类结果的相近程度;ARI是调兰德指数,反映划分的重叠程度.NMI或ARI的结果越接近1,说明聚类的结果越好.
各模型在测试集上执行聚类任务的结果如表2所示.可以看出,HONG在聚类任务上比其他基准模型表现得更好.这表明了高阶邻居对于节点嵌入表示的重要性.
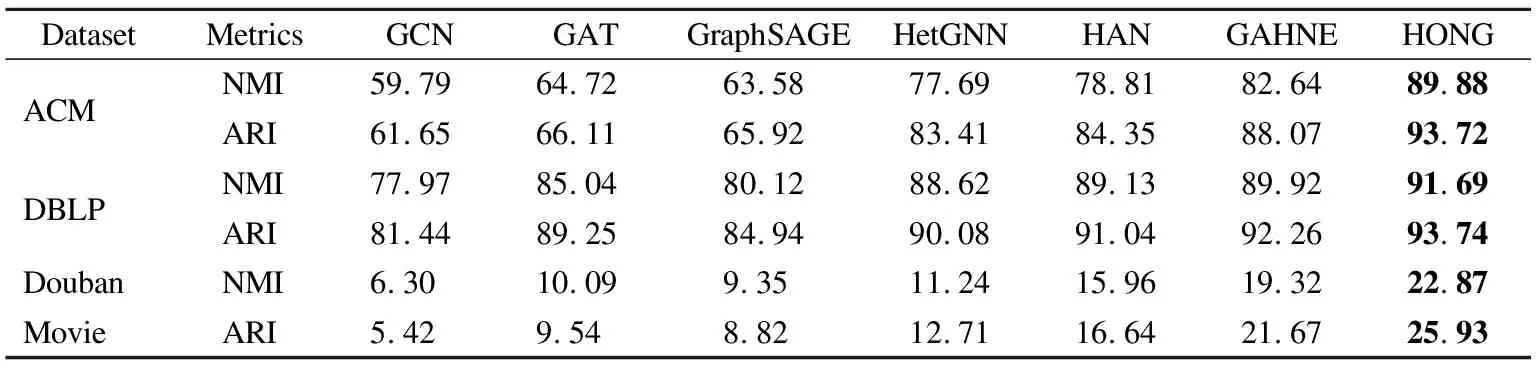
表2 节点聚类任务的结果(%)对比Table 2 Quantitative results(%)on the node clustering task
4.6 消融实验
为了验证HONG模型中HetRepPool组件的有效性,本文还将HONG与仅结合了GCN的HAN的模型(没有使用HetRepPool)进行了对比,并称之为HAN-GCN.它是HONG的变体,消除了HetRepPool而仅使用GCN,以验证HetRepPool的有效性.
图4是训练过程中,HAN、HAN-GCN、HONG三者分别作用在ACM验证集的损失函数变化.其中横坐标为训练批次,纵坐标为损失函数的值.由于实验中使用了早停法,得到的实际训练次数会有所不同.突出的黑色点表示:1)通过早停法得到的训练最佳结果;2)达到迭代最大次数后得到的最佳训练结果.可以看出,HONG的损失函数值最小,且比HAN收敛更快.
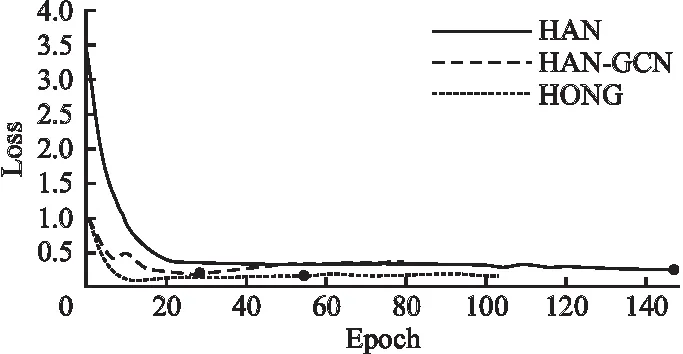
图4 训练时损失函数的变化Fig.4 Changes of loss during training
图5是训练过程中,HAN、HAN-GCN、HONG三者作用在ACM验证集数据上的Micro F1分数的变化.图中横坐标为训练批次,纵坐标为Micro F1得分.不难看出,在验证集上执行分类任务时,使用HONG得到的精度最高.由于实验过程中Macro F1分数的变化趋势与Micro F1基本一致,因此图5仅展示了Micro F1得分变化趋势.
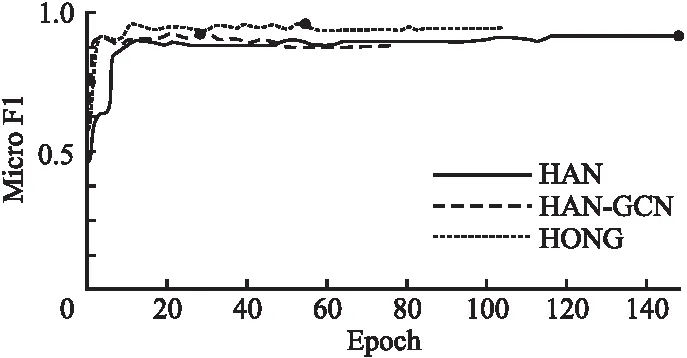
图5 训练时Micro F1的变化Fig.5 Changes of Micro F1 during training
综合图4、图5的结果,可以得出,HONG比HAN、HAN-GCN都取得了更好的训练成果.由此可证明本文所提出的HetRepPool组件的有效性.
4.7 可视化
为了更直观地进行比较,本文将HONG模型得到的节点嵌入向量进行可视化.模型训练时的参数设置同4.3节所述,并将训练好的模型用于ACM数据集的测试集,使用t-SNE[21]投影到二维空间中,根据节点的真实标签进行着色,如图6所示.

图6 HAN与HONG结果的可视化Fig.6 Visualization of HAN and HONG results
图6(a)是HAN结果的可视化,图6(b)是HONG结果的可视化,其中不同灰度的点代表着不同的真实标签.本文所用ACM数据子集共有3种标签.不难看出,HONG相较于HAN有着更为明显的边界,这表明它能为节点计算出更好的嵌入表示,效果更佳.
4.8 参数分析
本节研究了HONG模型在ACM数据集节点分类任务中的参数敏感性,并将实验结果(Micro F1分数)报告于图7中.
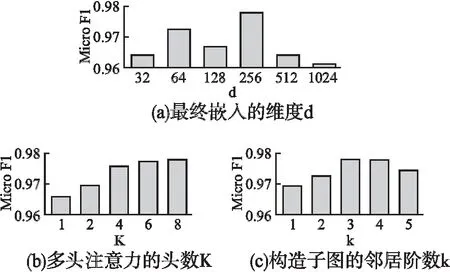
图7 HONG模型参数实验Fig.7 Parameter experiments of HONG
1)最终嵌入的维度d.本文研究了最终嵌入的维度d对HONG模型的影响,结果如图7(a)所示.总体来看,模型在分类实验上的准确率最初会随嵌入维度的增大而有所提升,之后会随嵌入维度的增大而减小.这是因为HONG在语义学习阶段需要一个合适的维度对语义进行编码,过大的维度可能会产生冗余.
2)多头注意力的头数K.改变语义学习阶段注意力头数K,HONG模型的实验结果如图7(b)所示.不难看出,注意力头数K的增加能够改善HONG在节点分类任务上的结果,但当K达到一定数值后,对HONG的改善幅度将会越来越小.需注意,当注意力头数K被设置为1时,是单头注意力而非多头注意力.
3)构造子图的邻居阶数k.本文研究了构造子图时使用不同邻居阶数k对HONG模型的影响,结果如图7(c)所示.最初,HONG模型在分类任务上的性能会随着邻居阶数k的增加而提升,之后会随着k的增加而降低.这是因为,当子图邻居阶数k达到一定值后,会使不同目标节点子图所覆盖的节点大量重合,难以区分.
5 结论及未来工作
本文提出一种面向节点级任务的异构图神经网络模型HONG,该模型不仅能聚合节点基于元路径的直接邻居,还能聚合节点的高阶邻居,学习复杂的结构特征.模型在3个真实异构图数据集上的节点分类任务及节点聚类任务均取得了优于其它基线模型(GCN、GAT、GraphSAGE 、HetGNN、HAN、GAHNE)的表现:在节点分类任务上的Micro F1平均提升了3.88%,Macro F1平均提升了4.13%;在节点聚类任务上的ARI平均提升了12.66%,NMI平均提升了12.02%.下一步,将在语义学习阶段使用其他异构图神经网络模型(如Meta-GNN)与HetRepPool相融合,并考虑通过剪枝、矩阵压缩等方法,对该网络模型进行压缩.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
数学物理学报(2021年1期)2021-03-29
数学物理学报(2020年6期)2021-01-14
哈尔滨轴承(2020年1期)2020-11-03
同济大学学报(自然科学版)(2019年2期)2019-04-02
数学物理学报(2018年5期)2018-11-16
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
电子科技大学学报(2016年2期)2016-08-31
通信电源技术(2016年6期)2016-04-20
