
融合语义增强的用户兴趣度预测方法研究
2023-09-06 04:29吴彦文马艺璇邓云泽
小型微型计算机系统 2023年9期
吴彦文,马艺璇,葛 迪,邓云泽
1(华中师范大学 国家数字化学习工程技术研究中心,武汉 430079)
2(华中师范大学 物理科学与技术学院,武汉 430079)
1 引 言
当今社会,网络的普及和社交媒体的发展给用户带来了越来越多的选择,推荐技术的地位日益凸显.有效的推荐可以捕获那些用户可能喜爱的物品,帮助其做出决策,克服信息过载问题.然而,在推荐系统中,数据稀疏问题普遍存在,这一问题往往导致模型性能不佳.基于此,一些学者将社会关系[1]、空间位置[2]等辅助信息引入推荐系统中来克服数据稀疏性问题.
一般情况下,融合了社会关系的推荐被称为社会化推荐.其中,作为输入的用户-项目二部图与社交网络均为图结构,这与图神经网络(Graph Neural Network,GNN)技术天然适配.据相关文献研究,GNN在社会化推荐领域的优势体现在两个方面[3]:其一,GNN适用于大规模数据的处理,可较好地缓解推荐系统存在的数据稀疏问题;其二,GNN通过捕捉图内依赖和迭代聚合邻域信息,更新当前节点表示,可被用来学习推荐系统中用户/物品嵌入.
传统的基于GNN的社会化推荐中[4,5],核心步骤是利用节点在社交网络和用户项目二部图中的消息传播和信息聚合,提取用户/项目嵌入向量,这种方法一定程度上缓解了数据稀疏问题,使模型性能得到提升.然而,现有模型大多只考虑了浅层的语义上下文信息,如果将深层的语义上下文信息引入学习过程中,可以使得学习到的用户偏好和项目属性嵌入表示更加丰富,如图1所示.此外,深层语义上下文信息的提取依赖于良好的语义网络结构,所以优化网络结构十分重要.

图1 浅层上下文与深层上下文对用户偏好的影响Fig.1 Impact of shallow context and deep context on user preferences
为了解决以上不足之处,本文引入了增强语义,基于图结构学习和图神经网络提出了一种融合语义增强的用户兴趣度预测方法(SCGNN).本文的贡献可总结为以下两点:
1)提出了基于图结构学习的语义网络增强方法.基于余弦相似度计算初始化语义网络,利用图学习准确捕捉节点间的语义关系,增加可用的图信息.
2)提出了基于图神经网络的用户兴趣度预测模型.利用节点在信任网络和语义网络的消息传递和特征聚合,学习用户偏好、物品属性嵌入向量,实现深层上下文信息的有效聚合,以提升模型的召回率和归一化累计折损增益.
2 相关工作
通常情况下,推荐系统通过探究用户偏好和物品属性来预测用户对物品的交互得分,其关键问题在于如何通过节点的影响传播来更好地学习用户/物品嵌入向量.然而针对用户偏好和物品属性进行建模时,数据稀疏性往往带来模型性能的下降.因此,一些学者引入了社交信任来缓解这一问题.根据所采用技术的不同,可将社会化推荐算法分为3种:基于矩阵分解的社会化推荐算法、基于注意力机制的社会化推荐算法、基于图神经网络的社会化推荐算法.
基于矩阵分解的社会化算法假设用户和其社交网络中好友具有相似的兴趣,通过社会关系正则化或加权朋友平均来约束用户嵌入学习过程.例如:TrustMF[6]将用户映射到两个空间并优化用户嵌入来检索信任矩阵;TrustSVD[7]通过合并好友决策来建模用户兴趣;虞胜杰[8]等人结合矩阵分解的特征因子分析法处理信任信息与评分信息.相较于传统的协同过滤推荐模型,矩阵分解推荐算法的准确度得到提升,但它均等考虑了所有社交好友的影响,忽略了不同好友对用户兴趣的影响程度各不相同这一事实.
基于注意力机制的社会化推荐算法对上述问题提供了一种解决方案,即采用了注意力机制来计算好友对用户兴趣的影响权重.例如:ARSE[9]使用两个注意力网络融合用户之间的社会影响,建模用户随时间偏移的动态偏好和一般静态偏好;SAMN[10]设计了节点级和类型级两层注意力机制来建模好友的影响,学习用户和项目的嵌入表示;任柯舟[11]等人设计了具有时间遗忘特性和协同特性的两层注意力机制,分别对社交短期、长期兴趣进行建模.基于注意力机制的社会化推荐计算了不同好友对用户的影响程度,更加准确地建模了用户偏好向量.然而,这种方法未能考虑到社交网络和交互矩阵中的高阶关系,且数据稀疏问题依然显著.
基于图神经网络(GNN)的社会化推荐算法,则通过捕捉二部图和社交网络中节点的影响传播,学习用户兴趣和项目属性的嵌入表示.例如:Wu等人[4]提出了经典的Diffnet++社会化推荐算法,利用图神经网络模型分别建模社交影响和用户兴趣的作用过程;Zhang等人[5]则采用了一个双图注意力网络DANSER来建模双重的社交影响;Fu[12]等提出了一种深层上下文感知调制的图神经网络RGNN,通过上下文信息的调制提取特征表示;卫鼎峰等[13]使用图神经网络学习物品的相似性网络、社交网络和用户-物品交互图,得到用户、物品的特征嵌入,在矩阵分解的约束下,通过迭代更新获取最终嵌入.
综上,基于图神经网络的社会化推荐算法通过挖掘图中所蕴含的信息,进一步缓解了数据稀疏问题.但只考虑浅层的语义上下文来学习用户/物品嵌入是不够的,若引入深层语义上下文,那么网络节点特征将更丰富,学习的用户/物品嵌入表示的质量将更高.为此,本文提出了一种融合语义增强的用户兴趣度预测方法,详见本文第3节与第4节.
3 关键技术
3.1 SCGNN总体框架
考虑到语义关系对用户兴趣和物品属性的影响,本文设计了一种融合语义增强的用户兴趣度预测方法(SCGNN),总体思路如图2所示.图2中SCGNN模型的架构分为两部分:

图2 SCGNN总体框架Fig.2 Overall framework of SCGNN
1)基于图结构学习的语义网络增强.初始化基于语义关系的用户语义网络和物品语义网络,使用图结构学习的方式修正节点之间的语义连接来优化网络结构,在保证准确性的前提下最大限度挖掘用户/项目的交互信息特征,以提升推荐模型的训练效率;
2)基于图神经网络的用户兴趣度预测.使用图神经网络进行学习表征时,通过聚合语义网络和信任网络的深层语义上下文进行特征提取,再对各层特征嵌入进行连接操作来构建增强表示,得到融合信任和语义的用户偏好向量和物品属性向量,最后将其作为输入通过多层感知机,从而实现特征的有效融合,获得预测的交互得分.
在上述模型计算过程中,针对社交网络、用户语义网络和物品语义网络的构建,本文引入了3种关系(如图3所示):
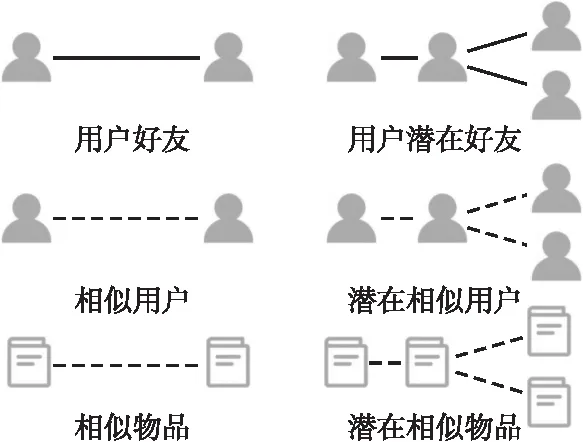
图3 3种关系的定义Fig.3 Definition of the three connections
1)用户间的信任关系,代表两个用户之间的社交信任,通过社交网络体现,社会网络分析理论[14]认为用户个人兴趣受到好友兴趣的影响,向好友兴趣倾斜;
2)用户间的语义关系,代表两个用户兴趣相似,虽然两个用户之间不存在社交关系,但其过往交互历史透露了相似的消费偏好;
3)物品间的语义关系,代表两个物品之间属性相似,虽然两个物品之间不存在直接关联,但其过往的交互历史表明它们被同一批用户所喜爱.
此外,将潜在的用户好友、相似用户、相似物品作为深层的语义上下文,可以使得提取的用户兴趣和物品属性具有更丰富的信息.这3种关系的引入用于表达社交网络、用户语义网络和物品语义网络的含义,为网络的表示和优化提供了基础.
为了计算方便,表1列出了本文涉及的数学定义.
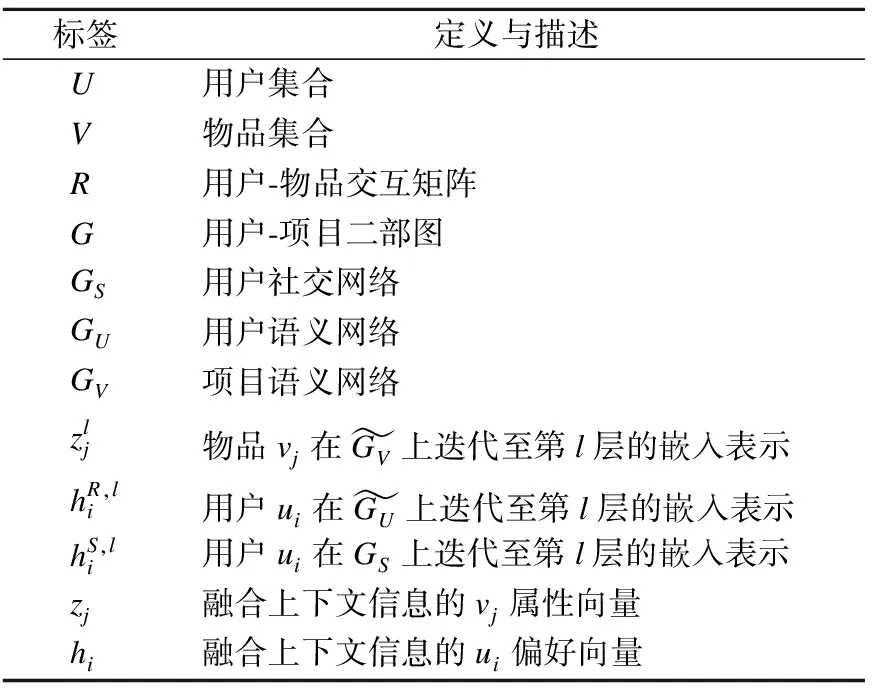
表1 模型的相关数学定义Table 1 Related mathematical definition of the model
3.2 基于图学习的语义网络增强研究
针对输入的用户-项目二部图G={U,V,E},U={u1,u2,…,uM}和V={v1,v2,…,vN}分别表示用户集合和物品集合,E代表用户和物品节点之间存在的连线集合.然而,用户节点之间、物品节点之间存在的语义关联是不可见的.因此,这一部分的首要任务是初始化语义网络GU和GV.
可以使用余弦相似度计算来判断节点之间是否语义相连,从而初始化语义网络.对于任意物品vj和用户ui,将交互矩阵R的第j列列向量ej作为vj的初始化特征向量,将RT的第i列列向量ei作为ui的初始化特征向量,余弦相似度计算过程如下:
(1)
(2)
对于每个物品(用户)节点,随机选择批量节点进行相似度计算,使得最相似的n个物品(用户)作为语义关联的对象,来缓解数据规模巨大而导致的计算复杂问题,基于此构建初始化的语义网络GV和GU.此计算过程将导致GV和GU包含许多噪声信息且具有一定程度的信息丢失,为了改善这一问题,采用图结构学习的方式,通过相似度权重分配进行迭代优化,得到训练子图G′V和G′U.具体计算过程如下:
sim′(vj,vm)=cosine(wiqj,wiqn)
(3)
sim′(ui,um)=cosine(wupi,wupm)
(4)
其中,wi和wu是神经网络的权重,qj和pi是物品和用户的节点特征向量,cosine是余弦相似度计算函数.

(5)
(6)
3.3 基于图神经网络的用户兴趣度预测方法

步骤1.计算融合增强语义的物品属性.
(7)
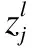
步骤2.计算融合增强语义的用户兴趣向量与基于信任的社交影响向量.
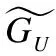
(8)

(9)
步骤3.计算最终的用户兴趣向量
(10)
步骤4.构建用户兴趣和物品属性的图增强表示
在每个特征聚合器中进行多次迭代传播过程后,得到U和V的嵌入集合.对于每一个用户ui和每一个物品vj,将其在CGNN中每层得到的嵌入向量拼接起来,形成的最终图增强表示为:
(11)
(12)
步骤5.计算交互得分
由于用户对候选项的决策同时依赖于用户偏好与项目属性,因此基于用户和项目的图增强嵌入来计算交互得分,最终的用户ui对物品vj的交互得分yi,j为:
yi,j=MLP(hi,zj)
(13)
3.4 模型训练
为了学习模型参数,需要指定一个目标函数进行优化.对于隐式反馈,最广泛使用的损失函数是交叉熵,定义如下:
(14)
本文采用了小批量自适应矩估计的方法来优化目标函数,其优势在于训练阶段学习速率可以自适应,减轻了选择合适学习速率所带来的不便.在优化神经网络模型时,采用dropout策略来缓解过拟合问题.
4 实 验
4.1 实验数据集及预处理
本文采用Ciao和Epinions两个公开数据集进行实验(https://www.cse.msu.edu/~tangjili/datasetcode/truststudy.htm),它们是用于社会化推荐研究的典型数据集,包含丰富的评分、社交信息,具体统计细节如表2所示.
对数据集进行如下处理:只要存在用户-项目评分、用户-用户连接,那么交互矩阵和社交矩阵的对应位置值置为1,作为隐式反馈;训练集、验证集和测试集的划分遵照1∶1∶8的比例,分别用于参数的学习、超参数的调整以及性能的判断.
4.2 实验设置和参数
本文采用Recall@K和NDCG@K作为评价指标来评估本文模型与基线模型的推荐性能,其中K的含义是用户与之交互概率最高的K个物品,本文设置K的范围为{5,10,15}.采用PyTorch进行模型的实现,使用Xavie[15]来初始化模型参数.相关的超参数设置如下:学习率α为0.001,训练批量大小设置为4096,嵌入向量的维度d为64,语义邻居的个数设置为20,语义网络的连接权重λ设为0.9,GNN的层数l是3,LeakyReLU函数的斜率设置为0.2.
4.3 实验结果与分析
4.3.1 对比方法
为了对比本文提出模型推荐性能的提升,本文选择以下4种推荐模型作为基线方法,在两个数据集中针对召回率和归一化累计折损增益两个评价指标进行对比实验.
·TrustMF[6]:一种基于矩阵分解的社会化推荐模型,将用户映射到两个空间并优化用户嵌入来检索信任矩阵;
·TrustSVD[7]:另一种基于矩阵分解的社会化推荐模型,将朋友嵌入引入到目标用户的预测评分中;
·SAMN[10]:一种基于注意力机制的社会化推荐模型,设计了节点级和类型级两层注意力机制来建模好友对用户兴趣的影响;
·DiffNet++[4]:一种基于图神经网络的社会化推荐模型,并在推荐中同时考虑了社会影响扩散和潜在的协作兴趣扩散.
4.3.2 对比实验结果
对比结果如图4所示,可以观察到本文模型相较于其他方法取得了最佳推荐性能.综合两个数据集的实验结果可以看出,与基于矩阵分解的社会化推荐算法TrustMF和TrustSVD相比,SCGNN的召回率和归一化折损累计增益平均提升了17%和29.9%;与基于注意力机制的社会化推荐算法SAMN相比,SCGNN的召回率和归一化折损累计增益平均提升了5.9%和2.44%;与基于图神经网络的社会化推荐算法DiffNet++相比,SCGNN的召回率和归一化折损累计增益平均提升了3.55%和2.21%.

图4 对比实验结果Fig.4 Comparative experiment results
4.3.3 SCGNN中各参数对实验结果的影响
首先,就用户嵌入、物品嵌入的大小对模型性能的影响进行分析,如果嵌入维度是d,那么图增强嵌入向量的维度为(l+1)*d,l为GNN的迭代层数.图5显示了两个数据集中嵌入维度d对Recall@15和NDCG@15的影响.总体来说,随着嵌入维度的增加,召回率和归一化折损累计增益相应提升.当d从8增至32时,召回率和归一化折损累计增益显著提升,从32增至64时,模型性能缓慢提升而计算复杂度增大.因此,选择合适的嵌入维度来平衡模型的性能与效率十分重要.

图5 嵌入维度d对Recall@15、NDCG@15的影响Fig.5 Impact of embedding dimension d on Recall@15 and NDCG@15
为了探究GNN传播层数l对模型性能的影响,我们在l={1,2,3}的范围进行实验,结果如图6所示.可以看到,增加层数l可以在一定程度上提升召回率和归一化折损累计增益.
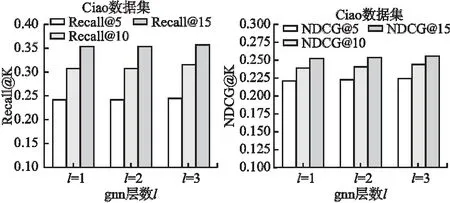
图6 Ciao数据集下GNN的层数l对Recall@K和NDCG@K的影响Fig.6 Impact of the number of layers of GNN under the Ciao dataset on Recall@K and NDCG@K15
最后,分析语义网络权重λ对推荐性能的影响,将λ的范围设置为{0.1,0.3,0.5,0.7,0.9}进行实验,实验结果如图7所示.随着λ的递增,Recall@15和NDCG@15先减后增.

图7 语义网络权重参数λ对Recall @15和NDCG@15的影响Fig.7 Influence of semantic network weight parameter λ on Recall @15 and NDCG@15
当参数调整为0.1或0.9时,推荐性能较佳,且λ=0.9时的模型性能优于λ=0.1时的模型性能.
5 结 论
数据稀疏的存在将导致推荐性能下降,基于GNN的社会化推荐作为一种解决方案,可以在一定程度上缓解这一问题.而多数模型只考虑浅层语义上下文,若引入深层语义上下文,则能捕捉到更丰富的用户/项目嵌入表示.基于此,本文提出了一种融合语义增强的用户兴趣度预测模型,首先使用图结构学习增强语义网络,然后使用关系感知图神经网络迭代聚合语义网络和信任网络中的多跳邻居信息,以提取用户兴趣、项目特征向量的增强表示.两个公开数据集上进行的大量对比实验的结果表明,在召回率和归一化累计增益两个指标下,本文提出的模型优于所有基线方法.
在接下来的工作中,本文将继续优化图结构以应对数据稀疏问题,同时进一步改进用户兴趣度预测模型以提升该模型的准确度.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
少先队活动(2021年5期)2021-07-22
疯狂英语·初中天地(2021年11期)2021-02-16
开放教育研究(2020年2期)2020-03-31
中国非营利评论(2019年1期)2019-06-18
少年漫画(艺术创想)(2019年2期)2019-06-06
现代语文(2016年21期)2016-05-25
体育科技(2016年2期)2016-02-28
学习月刊(2015年7期)2015-07-09
小天使·一年级语数英综合(2015年8期)2015-07-06
