
面向DNN的高并发NVM文件系统
2023-09-06 04:29马跃明牛德姣
小型微型计算机系统 2023年9期
蔡 涛,王 飞,马跃明,牛德姣,李 雷
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
1 引 言
DNN是当前研究的热点,扩大DNN模型的规模和更多的训练次数是常用的提高准确率的方法,DNN参数的大小已经超过1TB,无法全部存放到GPU的内存中,这给计算机存储系统性能带来了很大的挑战,使其成为影响DNN训练效率的重要因素.NVM是近年来出现的新型非易失性存储器(Non-Volatile Memory),具有近DRAM的读写速度和延迟、以及支持字节粒度访问等特性,常见的包括PCM、FeRAM、RMEM和MRAM等多种类型,特别是Intel已推出了商用的Optane DC等[1-6],这使得NVM成为提高存储系统性能的重要手段;但NVM具有不同于DISK和SSD的特性,给现有I/O软件栈带来了很大的挑战.现有的计算机系统中通常由文件系统管理对数据的访问,通用的文件系统和NVM文件系统需要针对上层多种不同的应用,通常采用以文件为粒度的访问管理方式;而DNN中参数数据量巨大,使用文件粒度管理访问,无法利用处理器中大量计算核心通过多个并发线程提高DNN海量参数的访问效率.同时DNN训练过程中,对DNN参数文件的访问则很规律,在开始训练前需要读取参数文件中保存的海量参数,在结束训练后或训练过程中内存不够时则需要将海量的参数写回到参数文件中.这使得需要针对DNN训练中访问海量参数的特点,设计新型的NVM文件系统,提高访问DNN海量参数的效率.
本文在分析DNN训练中海量参数特性和NVM对I/O软件栈所带来挑战的基础上,设计了面向DNN的高并发NVM文件系统,包括基于并发线程的细粒度锁和基于两层日志的文件并发I/O机制,最后针对Intel的Optane DC在修改NOVA源代码的基础上实现了原型系统,并使用Filebench和Fio在多种不同类型负载下进行了测试与分析,验证所设计算法的有效性.
本文的主要贡献有:
1)针对当前NVM文件系统中文件锁影响读写并发度的问题,设计基于并发线程的细粒度锁,减少读写数据时加锁的粒度,适应多线程同时访问数据的特点,为提高大文件的读写效率奠定基础;
2)针对DNN训练过程中需要反复快速读写大量参数的特点,设计基于两层日志的并发读写策略,利用多核处理器中支持多个线程并发访问的优势,在加速大文件读写性能的同时,有效保证数据的一致性;
3)在NOVA文件系统的基础上,实现了DNNFS的原型,分别使用Filebench和Fio中的多个负载进行了测试与分析,测试结果表明,在使用多线程并发访时相比NOVA最大能提高35.8%的IOPS值和21.6%的I/O带宽.
2 相关研究工作
NVM存储设备具有低延迟、字节可寻址、读写速度接近DRAM的特点.研究人员对这些特征进行了大量研究[7-11].下面首先介绍DNN训练的研究现状,然后再介绍NVM文件系统和存储系统的相关研究.
针对DNN训练的研究如下:Jonghyun Bae等人在论文中提出的FlashNeuron[12]是第一个使用NVMe的DNN训练系统SSD作为后备存储.充分利用有限的SSD写入带宽,FlashNeuron引入了卸载调度程序,它有选择地将一组中间数据卸载到压缩格式的SSD来充分利用有限的SSD写入带宽,并且不会增加DNN测试时间.FlashNeuron跳过CPU直接在GPU和SSD之间进行进程之间的数据传输.Shine Kim等人提出的Behemoth[13]是一个用于超大规模DNN的以Flash为中心的训练加速器.论文中仔细分析了训练超大规模DNN模型时出现的内存容量问题,并利用NAND闪存设备取代昂贵的DRAM设备.同样为了满足DNN训练过程中带宽和寿命要求,作者还提出Flash Memory System(FMS),它提供高带宽和较高的寿命.Jayashree Mohan等人首先分析当今DNN检查点的状态,强调了细粒度检查点的必要性以及实现它所涉及的挑战.作者设计和实现了一个用于DNN的自动、细粒度的检查点框架CheckFreq[14],利用DNN计算模型的训练提供低成本的流水线检查点,最后将恢复时间从几小时缩短到几秒.
针对NVM文件系统和NVM存储系统的研究如下:Jian Xu等人提出NOVA[15],一个用于混合易失性/非易失性主存的日志结构NVM文件系统.它扩展了现有的日志结构文件系统技术,以利用混合内存系统的特性.NOVA保持每个inode的单独日志以提高并发性,以及将文件数据存储在日志之外以最小化日志大小并重新减少垃圾收集成本.NOVA的日志提供元数据、数据和mmap原子性,并专注于简单性和可靠性,在DRAM中保持复杂的元数据结构以加速查找操作.Intel公司的Dulloor等人设计了一种新型的轻量级POSIX文件系统PMFS[16],通过使用CPU的load/store指令来实现对NVM存储设备的直接访问.同时,PMFS利用NVM支持DAX的机制直接管理存储设备,避免了块驱动和页缓存层的额外开销;PMFS利用CPU的分页和内存排序功能减少日志的粒度和支持更大的页面,以最大程度地减少TLB条目的使用并加快虚拟地址的查找.PMFS还提供了mmap接口,无需借助任何缓冲区将文件数据直接映射到虚拟进程空间,从而使得应用程度能够以内存的方式读取和写入文件数据,在保证一致性的同时提高内存映射和访问的效率.Zheng S等人设计出一种使用混合NVM和Disk的分层文件系统Ziggurat[17]来构建接近独立NVM性能的大容量存储系统.Ziggurat利用一种感知算法,根据应用程序的访问模式、写入数据的大小以及应用程序在写入完成前暂停的可能性将数据写入到NVM、DRAM或者Disk中;Ziggurat会在后台计算每个文件的“热度”,并将其中冷数据从NVM迁移到Disk中;Ziggurat还将多个数据块合并为较大的顺序写入来更好地利用Disk的优秀的顺序写入的特性.Ren Y等人设计了CrossFS[18],这是一个跨用户级、固件和内核分解的跨层直接访问文件系统用于扩展I/O性能和提高并发性的层.CrossFS旨在利用主机级和设备级计算能力.CrossFS引入基于文件描述符的并发控制,映射每个一个硬件级I/O队列的文件描述符来同时处理跨文件描述符的不相交访问.CrossFS将文件描述符同步到I/O队列的问题转换为请求排序问题.为了保证崩溃的一致性跨层设计,CrossFS利用字节可寻址用于I/O队列持久性和设计的非易失性存储器轻量级固件级日志机制.Kadekodi R等人提出了SplitFS[19],一种用于持久内存(PM)的文件系统较最先进的PM文件系统,显着减少了软件开销.SplitFS呈现用户空间库文件系统和现有内核PM文件系统之间的分离.用户空间库文件系统通过拦截来处理数据操作POSIX调用、内存映射底层文件,以及使用处理器加载和存储服务读取和覆盖.元数据操作由内核PM文件系统(ext4 DAX)处理.Dong M等人提出了一个叫做Coffer[20]的新抽象,它是个集合隔离的NVM资源,在其上面构建一个用户空间中的高性能和受保护的NVM文件系统.将NVM保护与管理分开通过保险箱,以便用户空间库可以完全控制NVM在一个保险箱内,让内核保证保险箱之间的严格隔离;作者构建一个NVM文件系统架构,将NVM的高性能带到未修改的应用程序并促进开发高性能且灵活的用户空间NVM文件系统库.Chen Y等人提出了KucoFS[21],一个内核和用户态协作文件系统.它由两部分组成:一个具有直接访问接口的用户级库和一个内核线程,它通过切换页表中的权限位来执行元数据更新和强制写保护.KucoFS实现了用户态的直接访问和内核态的细粒度写保护并且进一步探索了它对多核的可扩展性.对于元数据的可扩展性,KucoFS通过采用索引卸载技术重新平衡内核和用户空间之间的路径名解析开销.为了数据访问效率,它协调内核和用户空间之间的数据分配,并使用范围锁写和无锁读来提高并发性.蔡涛等人为了提高非易失性存储系统并发执行访问请求的能力,针对存储设备中的读写访问请求、文件数据和元数据的不同特性,设计了基于区间锁的文件数据并发写策略、基于读-拷贝修改的文件数据读写并发策略和基于最小自旋锁的元数据同步策略,以提高访问请求执行的并发度;实现了利用非对称锁的高并发非易失存储系统原型[22].罗盛美等人基于SSD存储介质的写入特性,提出了面向分布式文件系统元数据的数据管理机制和更新方法[23],包括元数据内存页面的重新组织和管理、多次变化数据的迭代更新、元数据写入方式的进一步优化等.所提方法减少了元数据更新的写入频次和实际写入量,减少了随机写操作,提高了元数据写入性能.舒继武等人针对传统存储系统的构建方式不适用于非易失主存,无法发挥出非易失主存的性能优势,并且容易造成一致性开销高、空间利用率低、编程安全性低等问题分析了基于非易失主存构建存储系统面临的挑战[24],在系统软件层次分别综述了空间管理机制、新型编程模型、数据结构、文件系统和分布式存储系统等方面的研究进展,并展望了基于非易失主存构建存储系统的未来研究方向.
3 基于并发线程的细粒度锁
现有NVM文件系统通常需要应对上层多种不同应用混杂的场景,通常使用基于文件的锁处理访问冲突,在用于管理DNN参数文件的读写进程时,会出现难以利用处理器中的大量计算核心,通过多线程并发减少访问海量参数所需时间开销的问题.
如图1所示,在DNN训练进程读写参数文件时,NVM文件系统需要对参数文件加锁,以阻止可能存在其他线程对DNN参数文件的访问,保障DNN参数文件数据和元数据的一致性;但这会导致别的DNN训练线程无法访问参数文件,从而不能利用多核处理器解决DNN训练过程中访问海量参数效率的问题.
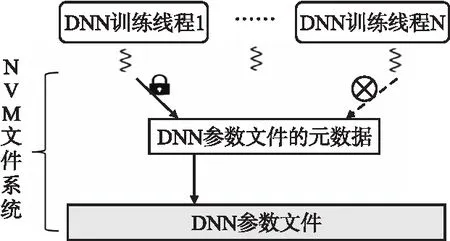
图1 DNN训练多线程访问参数文件时的问题Fig.1 Problems with DNN training multiple threads to access parameter files
本文针对DNN训练过程中读写参数文件规律性强的特点,设计基于并发线程的细粒度锁,提高访问DNN参数文件的并发度,从而为利用多核处理器提高DNN训练过程中访问海量参数的效率提供支撑.
3.1 基于并发线程细粒度锁的结构
首先,使用4元组(PID,Start_Add,End_Add,Next_Lock)表示基于并发线程的细粒度锁,其中,PID是DNN训练线程的标识符,Start_Add是封锁区域在参数文件内的起始地址,End_Add是封锁区域在参数文件内的结束地址,Next_Lock是指向下一个基于并发线程细粒度锁的指针.
同时给每个DNN参数文件构建基于并发线程细粒度锁的执行队列和等待队列,在DNN参数文件的元数据中保存基于并发线程细粒度锁执行队列和等待队列的首地址.
3.2 加锁和解锁的过程
当DNN参数访问进程调用NVM文件系统中的读写函数访问DNN参数文件时,首先NVM文件系统检查当前DNN参数访问线程的数量,确定每个DNN参数访问线程所对应的DNN参数文件区间.接着,NVM文件系统为每个DNN参数访问线程生成对应的基于并发线程细粒度锁.虽然DNN参数访问线程读写参数文件非常规律,不会出现读写冲突的情况,但还存在其他的上层应用有可能访问DNN参数文件;因此NVM文件系统需要检查DNN参数文件是否被别的应用加锁,如DNN参数文件已被加锁,则将基于并发线程细粒度锁加入DNN参数文件的等待队列中,并阻塞对应的DNN参数访问线程;否则将基于并发线程细粒度锁加入DNN参数文件的执行队列中,并开始访问DNN参数文件中对应的数据.
当某个DNN参数访问线程结束后,则将对应的基于并发线程细粒度锁从执行队列中删除;在DNN参数文件中细粒度锁执行队列为空后,唤醒被阻塞的其它应用访问请求.当访问DNN参数文件的其它应用结束后,则唤醒基于并发线程细粒度锁等待队列中的DNN参数访问线程,并将相应的细粒度锁从等待队列中迁移到执行队列中.
NVM文件系统中接收到其他应用访问DNN参数文件的访问请求时,检查DNN参数文件的细粒度锁执行或等待队列是否为空,如果为空则在对DNN参数文件加相应锁后执行相应的访问请求;否则该访问请求需要等待直到细粒度锁执行或等待队列为空.
4 基于两层日志的文件并发I/O机制
DNN训练过程中需要反复快速读写大量参数,本文在基于并发线程细粒度锁的基础上,设计两层日志结构,支撑多个并发线程读写DNN参数文件,从而提高DNN训练过程中读写海量参数的效率.
4.1 两层日志和参数文件元数据的结构
为了支撑并发读写保存海量DNN参数的文件,首先在NVM文件系统中设计两层日志,包括DNN参数文件日志F_log和DNN参数文件段日志P_log.
DNN参数文件日志用来记录对该DNN参数文件所有并发DNN参数访问线程的情况,每个DNN参数文件日志项对应一个DNN参数访问线程,其结构如图2所示.
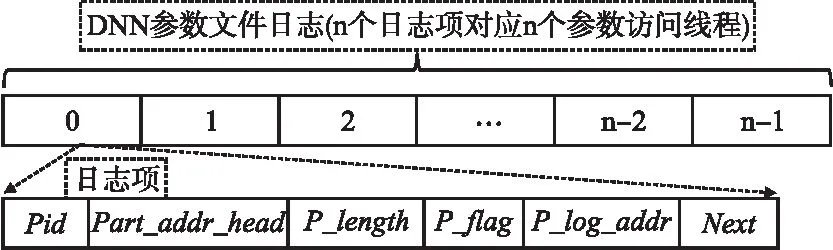
图2 DNN参数文件日志及其日志项Fig.2 DNN parameter file log and its log entries
DNN参数文件日志项包括Pid、Part_addr_head、P_length、P_flag、F_log_addr和Next6个部分,Pid是对应DNN参数访问线程的标识,Part_addr_head是该DNN参数访问线程所访问DNN参数文件中参数分段的首地址,P_length是该DNN参数访问线程所访问DNN参数分段的长度,P_flag用于DNN参数访问线程对相应参数分段的访问是否完成(0代表未完成,1代表已完成),P_log_addr是指向该DNN参数文件日志项对应DNN参数文件段日志的地址,Next是指向下一个DNN参数文件日志项的指针.
DNN参数文件分段日志用来记录每个DNN参数访问线程的进展情况,其结构如图3所示;DNN参数文件段日志中仅包含8字节的Tail_ptr,Tail_ptr表示对应DNN参数访问线程在参数分段中所完成读写操作的位置.
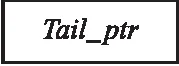
图3 DNN参数文件段日志P_log中的日志项Fig.3 Log entries in DNN parameter file segment log P_log
在构建DNN参数文件日志和DNN参数文件段日志这两层日志的基础上,还需要修改DNN参数文件的元数据,如图4所示,在现有的元数据基础上DNN参数文件的元数据中增加Process_num、F_log_addr和F_flag3部分;其中Process_num表示并发访问当前DNN参数文件的DNN参数访问线程数量,F_log_addr是指向DNN参数文件日志的指针,F_flag用来标识DNN参数文件的访问是否已经完成(0代表未完成,1代表已完成).

图4 DNN参数文件元数据Fig.4 DNN parameter file metadata
4.2 基于两层日志的文件并发读写策略
在两层日志和对参数文件元数据修改的基础上,为了支撑多个并发DNN参数访问线程提高DNN海量参数的访问效率,本文设计基于两层日志的文件并发读写策略.
DNN训练程序在读写参数前:首先根据DNN参数访问线程的数量n,将DNN参数文件均分为n个参数段,每个DNN参数访问线程负责访问其中的一个参数段中的数据,并将DNN参数文件元数据中的Process_num设置n、F_flag设置为0;接着,创建DNN参数文件日志,将其地址写入DNN参数文件元数据中的F_log_addr中,再为每个DNN参数访问线程构建一个DNN参数文件日志项,并将对应DNN参数段的起始地址和长度分别写入DNN参数文件日志项的Part_addr_head和P_length中,并将P_flag设置为0;然后,为每个DNN参数访问线程创建一个DNN参数文件段日志,将其中的Tail_ptr设置为对应DNN参数文件段的首地址,并将DNN参数文件段日志的地址写入对应的DNN参数文件日志项中P_log_addr;最后将n个DNN参数访问线程对应的DNN参数文件日志项通过Next指针连接起来构成链表,并启动DNN参数访问线程开始工作,再将DNN参数文件日志和DNN参数文件元数据写回到NVM中.
多个DNN参数访问线程并发工作过程中:不同的DNN参数访问线程各自访问对应的DNN参数段,从而提高对DNN参数的访问效率;同时每隔一段时间,以cacheline为单位,将DNN参数文件分段日志写入NVM中,以保存DNN参数访问线程的工作进度,避免DNN训练程序出错后重新访问之前已访问过的DNN参数.
当一个DNN参数访问线程结束后:将对应的DNN参数文件日志项中的P_flag设置为1,将P_log_addr的值设置为NULL,并将DNN参数文件日志项写回到NVM中,并删除其对应的DNN参数文件分段日志.
所有的DNN参数访问线程均结束后:将DNN参数文件元数据中的F_flag设置为1,F_log_addr设置为NULL,并写回到NVM中,同时删除DNN参数文件日志.
4.3 基于两层日志的文件一致性保证策略
由于DNN参数数据量的巨大,DNN参数访问线程在执行过程中遇到存储系统故障等问题后,需要避免在存储系统恢复后从头访问DNN参数,本文设计基于两层日志的文件一致性保证策略,其主要步骤如下:
步骤1.在存储系统故障等消除后,首先从DNN参数文件元数据中获取DNN参数文件日志的入口地址.
步骤2.检查DNN参数文件日志中所有日志项的P_flag值是否为0,判断每个日志项对应DNN参数访问线程是否已经安全完成,如未完成则继续相应的DNN参数访问线程,并转到步骤3;如所有DNN参数文件日志项的P_flag值均为0,则跳到步骤6.
步骤3.针对未完成的DNN参数访问线程,根据DNN参数文件日志项中的P_log_addr访问其对应的DNN参数文件段日志,如果其中的Tail_ptr值不为空,则继续DNN参数的访问过程,并跳到步骤5;否则转到步骤4.
步骤4.如果DNN参数文件段日志中的Tail_ptr值为空,则表明该DNN参数文件段的访问已经结束,但出现故障前未安全修改DNN参数文件日志和DNN参数文件元数据;则将DNN参数文件日志项中的P_flag设置为1,将P_log_addr的值设置为NULL,并将DNN参数文件日志项写回到NVM中,并删除其对应的DNN参数文件分段日志.
步骤5.检查DNN参数文件日志中是否还有其他未完成访问的DNN参数文件段,如没有,则转到步骤6;否则转到步骤2.
步骤6.将DNN参数文件元数据中的F_flag设置为1,F_log_addr设置为NULL,并写回到NVM中,同时删除DNN参数文件日志,并完成DNN参数的访问过程.
5 测试与分析
5.1 原型系统与测试平台
本文针对Intel的Optane DC,在NOVA的基础上,实现面向DNN的高并发文件系统原型(DNNFS).首先修改NOVA中的文件元数据,实现基于并发线程的细粒度锁模块;再修改文件的读写流程,实现基于两层日志的并发I/O模块和一致性模块;其结构如图5所示.
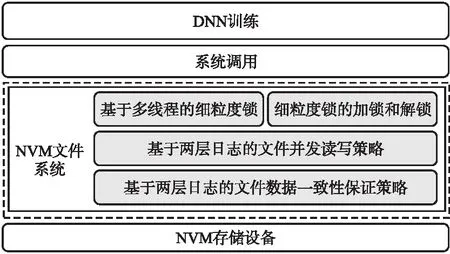
图5 基于两层日志文件系统的NVM存储系统Fig.5 NVM storage system based on a two-layer journaling file system
使用一台服务器构建原型系统的测试环境,该服务器的详细配置如表1所示.分别挂载NOVA和DNNFS,数据块的大小设置为4KB;首先使用Filebench中的Webserver、Varmail和Fileserver负载,模拟文件系统的典型运行环境测试I/O的吞吐率;再使用Fio,测试多个I/O线程并发顺序和随机读写的I/O带宽.每次测试前均重启服务器和禁用缓存以消除缓存对测试结果的影响,每项测试均进行10次并平均值作为测试结果.

表1 原型系统测试环境的软件配置Table 1 Software configuration of prototype system test environment
5.2 多线程并发顺序读写测试
首先使用Fio测试多线程并发顺序读的带宽,Fio使用libaio异步I/O引擎,队列深度为2,并发线程数分别为1、6和12,每次I/O大小分别为4KB、16KB和256KB,数据量的大小为50GB,测试时间为60s,结果如图6所示.
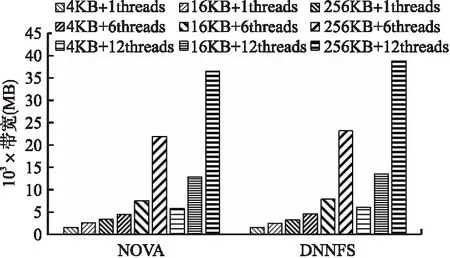
图6 改变线程数量和块大小的Fio顺序读测试结果Fig.6 Fio sequential read test results with varying thread count and block size
从图6中的测试结果可以发现,使用多个并发读线程时,与DNNFS相比NOVA文件系统的顺序读带宽提高了3.5%~6.2%,这说明采用细粒度锁和基于两层日志的并发I/O机制能有效提高读取文件的性能;当采用单个读线程时,DNNFS相比NOVA损失了3%左右的读带宽,这是由于细粒度锁和基于两层日志并发I/O机制所带来的额外时间开销.随着单次访问粒度的增加,DNNFS和NOVA的读带宽均相应提高,同时DNNFS相对NOVA所提高的读带宽也随之增加,在6个并发读线程时从3.5%增加到5.8%,在12个并发读线程时从4.8%增加到6.2%,这是由于使用大访问块后减少了访问次数从而提高了读带宽;同时在增加单次访问块大小时,DNNFS相对NOVA所提高的读带宽比例也更高,这进一步说明了DNNFS具有并发读带宽高的优势;但在并发读线程数为12时,使用256KB大小的访问块相比16KB访问块DNNFS读带宽所提高的比例出现了下降,这说明增大访问块对提高读带宽的作用在降低.在增加读线程数量时,DNNFS和NOVA也均能提高读带宽,在所有测试中均是采用12个并发线程时读带宽最高;但当并发读线程数从6增加到12时,DNNFS和NOVA读带宽所提高的比例出现了下降,但DNNFS读带宽提高的比例始终高于NOVA,这说明增加并发读进程能提高读带宽,但也会带来额外的管理开销.
采用相同的配置,测试多线程并发顺序写I/O带宽,结果如图7所示.
从图7可以看出,使用多个并发写线程时,总体来说,DNNFS具有更高的顺序写带宽提升,相比NOVA的顺序写带宽提高了12.1%~21.6%,这说明采用细粒度锁和基于两层日志的并发I/O机制能有效提高读取文件的性能;当采用单个写线程时,DNNFS相比NOVA损失了3%左右的写带宽,这是由于细粒度锁和基于两层日志并发I/O机制所带来的额外时间开销.随着单次访问粒度的增加,DNNFS和NOVA的写带宽先增高后下降,当线程数从1增加到6时,NOVA和DNNFS的写带宽均有提升,同时DNNFS相对NOVA所提高的写带宽也随之增加,在6个并发写线程时从12.1%增加到17.2%.当并发写线程数从6增加到12时,NOVA和DNNFS的写带宽有随着块粒度大小有不同的趋势趋势,在4KB块大小、12并发线程时,DNNFS提高了22%的写性能,在16KB块大小、12并发线程时,DNNFS下降了37%的写带宽,在256KB块大小、12并发线程时,DNNFS下降了34%的写带宽,这是因为多个线程在访问同一数据块时会造成访问冲突,因此会相应的降低带宽,但总的来说,随着块大小和线程粒度逐渐增加时,DNNFS相对NOVA在写带宽的提升比例更大,下降的比例更小.这表明在顺序写的负载中,由于多个并发写线程的冲突,DNNFS中设计的细粒度锁和基于两层日志的并发I/O机制能有更好的写带宽表现.
5.3 多线程并发随机读写测试
接着,使用Fio测试多线程并发随机读的带宽,Fio使用libaio异步I/O引擎,队列深度为2,并发线程数分别为1、6和12,每次I/O大小分别为4KB、16KB和256KB,数据量的大小为50GB,测试时间为60s,结果如图8所示.
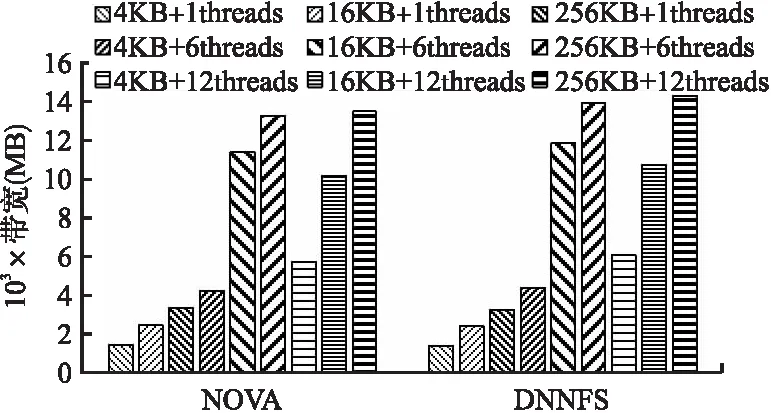
图8 改变线程数量和块大小的Fio随机读测试结果Fig.8 Fio sequential read test results with varying thread count and block size
从图8中的测试结果可以发现,使用多个并发读线程时,与DNNFS相比NOVA文件系统的顺序读带宽提高了3.6%~5.9%,这说明采用细粒度锁和基于两层日志的并发I/O机制能有效提高读取文件的性能;当采用单个读线程时,DNNFS相比NOVA损失了3.7%左右的读带宽,这是由于细粒度锁和基于两层日志并发I/O机制所带来的额外时间开销.随着单次访问粒度的增加,DNNFS和NOVA的读带宽均相应提高,同时DNNFS相对NOVA所提高的读带宽也随之增加,在6个并发读线程时从3.5%增加到5.7%,在12个并发读线程时从5.7%增加到5.9%,这是由于使用大访问块后减少了访问次数从而提高了读带宽;同时在增加单次访问块大小时,DNNFS相对NOVA所提高的读带宽比例也更高,这进一步说明了DNNFS具有并发读带宽高的优势;在并发读线程数为12时,使用256KB大小的访问块相比4KB访问块DNNFS读带宽所提高的比例有所下降,这说明增大访问块对提高读带宽的作用在降低.在增加读线程数量时,DNNFS和NOVA也均能提高读带宽,在所有测试中均是采用12个并发线程时读带宽较高;但当并发读线程数从6增加到12时,DNNFS和NOVA读带宽所提高的比例出现了下降,但DNNFS读带宽提高的比例始终高于NOVA,这说明增加并发读线程能提高读带宽,但也会带来额外的管理开销.
同样对多线程随机写I/O性能进行测试,测试参数的设置和随机读相同,测试结果如图9所示.
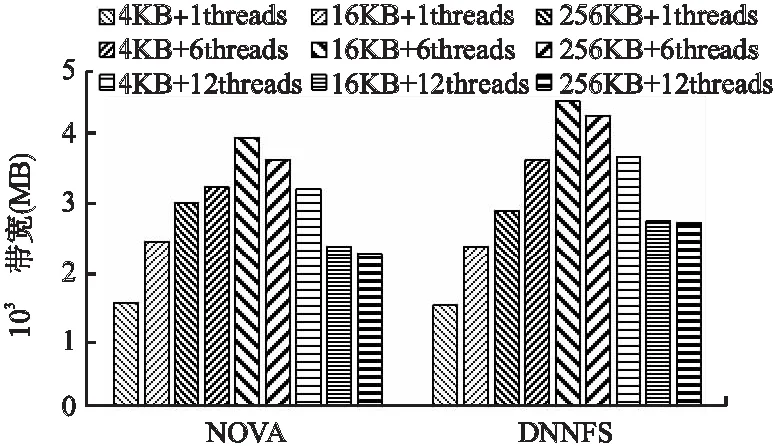
图9 改变线程数量和块大小的Fio随机写测试结果Fig.9 Fio sequential write test results with varying thread count and block size
从图9中可以看出,使用多个并发随机写线程时,总体来说,DNNFS具有更高的随机写带宽提升,相比NOVA的随机写写带宽提高了12.3%~20.3%,这说明采用细粒度锁和基于两层日志的并发I/O机制能有效提高并发随机写文件的性能;当采用单个写线程时,DNNFS相比NOVA损失了2.2%左右的读带宽,这是由于细粒度锁和基于两层日志并发I/O机制所带来的额外时间开销.随着单次访问粒度的增加,DNNFS和NOVA的写带宽先增高后下降,当线程数从1增加到6时,NOVA和DNNFS的写带宽均有提升,同时DNNFS相对NOVA所提高的写带宽也随之增加,在6个并发读线程时从12.3%增加到17.6%.当并发线程数从6增加到12时,NOVA和DNNFS的写带宽有随着块粒度大小有不同的趋势趋势,NOVA随着并发线程数的增加,写带宽下降了1%~40%,而DNNFS在4KB块大小、12并发线程时,提高了1.5%的写性能,在16KB块大小、12并发线程时,DNNFS下降了39%的写带宽,在256KB块大小、12并发线程时,DNNFS下降了36%的写带宽,这是由于使用大访问块后带来了写访问冲突的影响,但总的来说,随着块大小和线程粒度逐渐增加时,DNNFS相对NOVA在写带宽的提升比例更大,下降的比例更小.这表明在顺序写的负载中,由于多个并发写线程的冲突,DNNFS中设计的细粒度锁和基于两层日志的并发I/O机制能有更好的写带宽表现.
5.4 Webserver负载测试
首先在服务器上挂载NOVA和DNNFS文件系统,然后使用Filebench中的Webserver负载,模拟用户访问Web服务器的情况进行测试.设置测试文件数量为1000个,每个目录中包含20个文件,每次I/O大小为4KB,I/O操作中读写访问请求的比例为10:1,测试时间为60s,线程数量为1、2、4、6、8、10、12和14,测试吞吐率IOPS(Input Operations Per Second)值,结果如图10所示.
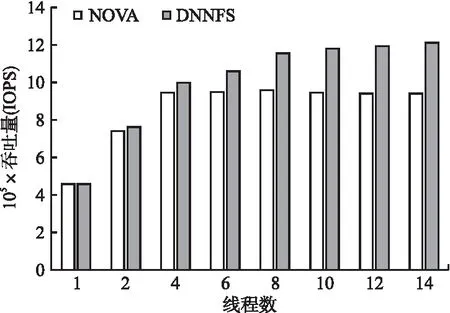
图10 改变线程数量的Webserver负载测试结果Fig.10 Webserver load test results with varying number of threads
从图10中可以看出,在Webserver负载下,DNNFS相比NOVA,在2个线程时,IOPS提升了3.3%,这是因为Webserver中的大部分请求是读访问请求,还不能充分发挥DNNFS基于并发线程细粒度锁以及两层日志的并发读写策略的优势.当线程数为8时,NOVA的IOPS达到了最大峰值;随着线程数的继续增加,IOPS会略微下降,这是因为随着线程增加会产生越来越多的文件锁冲突,影响了访问请求的执行效率.DNNFS在线程数为4时的IOPS值就超过了NOVA的IOPS最大值,在线程数为8时,相比NOVA提升了20.5%,同时在线程数为12时,提高IOPS值的比例最高达到了28.4%;这表明DNNFS中设计的基于并发线程细粒度锁能够减少读写数据时加锁的粒度,为提高大文件的读写效率奠定基础;以及基于两层日志的并发读写策略,利用多核处理器中不同线程并发访问的优势来加速大文件读写吞吐量.
5.5 Varmail负载测试
接着,使用Filebench的Varmail负载,模拟Email服务器的使用情况.设置文件数量为1000,每个目录中创建的文件个数为20,每次I/O大小为4KB,I/O操作中读写访问请求的比例为1:1,测试时间为60s,测试线程数量为1、2、4、6、8、10、12和14时的吞吐率IOPS值,结果如图11所示.
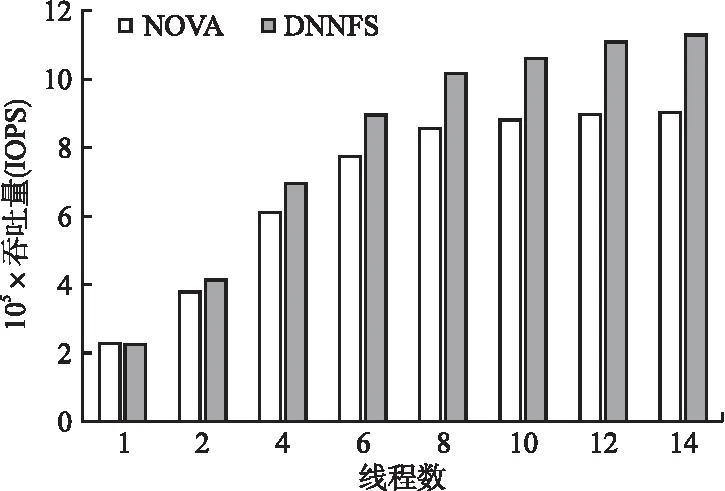
图11 改变线程数量的Varmail负载测试结果Fig.11 Varmail load test results with varying number of threads
从图11可以看出,总体上,DNNFS呈逐渐上升趋势,IOPS值始终高于NOVA.Varmail 在Varmal负载测试下,超过2线程时DNNFS的IOPS值相比NOVA均有所提高.在线程数小于8时,NOVA的IOPS值随着线程数增加而逐步提高,在8线程时达到峰值性能,随着线程数再提高,性能几乎持平.DNNFS相比于NOVA随着线程数的吞吐量都有所增加,DNNFS在6线程时就达到了NOVA的最大IOPS值.在线程数为2时,DNNFS相比NOVA提升了10.2%,同时在线程数为14时,提高IOPS值的比例最高达到了25.5%;这表明DNNFS中设计的基于并发线程细粒度锁能够减少读写数据时加锁的粒度,提高了大文件的读写效率;基于两层日志的并发读写策略也可以利用多核处理器中不同线程来提高并发读写吞吐量.
5.6 Fileserver负载测试
使用Filebench的Fileserver负载,模拟文件服务器中文件共享和读写操作等情况.设置文件数量为10000,每个目录中创建20个文件,每次I/O大小为4KB,I/O操作中读写访问请求的比例为1:10,测试时间为60s,测试线程数量为1、2、4、6、8、10、12和14时的吞吐率IOPS值,结果如图12所示.
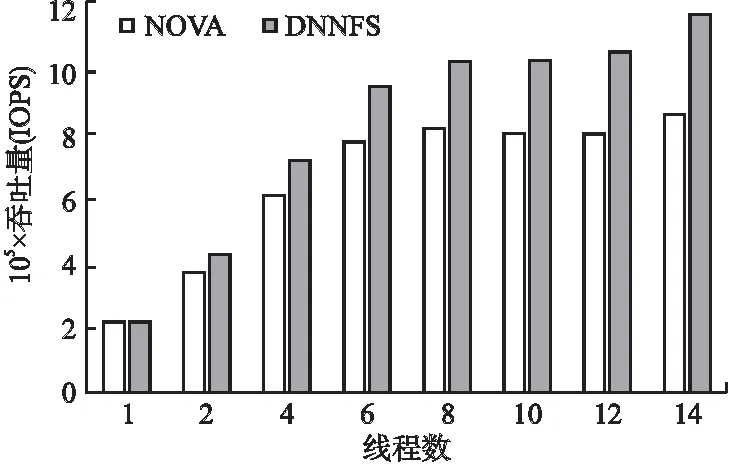
图12 改变线程数量的Fileserver负载测试结果Fig.12 Fileserver load test results with varying number of threads
从图12可以发现,Fileserver负载下,与Webserver和Varmail负载下的测试结果类似,DNNFS可以有效提升I/O性能,总体上,相比PMEM的IOPS值提高了15.4%~35.8%.在NOVA中,当线程数为8时达到了IOPS的最大值,此时随着线程数的增加,IOPS值开始略微下降,在同样情况下DNNFS的IOPS仍有小幅的性能提升,这是由于Fileserver中读写比例为1:10,主要是写负载,DNNFS中设计的基于并发线程细粒度锁有效的减小了锁的粒度,提高了读写大文件时的并发度;同时基于两层的日志结构以及基于两层日志的并发读写策略可以利用多核处理器中不同线程来进行并发读写.在DNNFS中,当线程数为6时,IOPS值就超过了NOVA中的IOPS最大值;并在线程数为14时,DNNFS较NOVA最大提升了35.8%的IOPS值.总的来说,在Fileserver负载下,DNNFS较NOVA更适用于多核处理器中多线程下访问请求冲突较多的情况.
6 总 结
增加DNN的参数数量和训练次数是有效提高模型准确率的有效方式,但这导致DNN训练过程中需要频繁读写海量参数,成为影响DNN训练效率的重要问题.NVM具有读写速度快的优势,能有效提高DNN训练中访问海量参数的效率.但现有的NVM文件系统是针对多种上层应用混杂的情况设计,通常基于文件粒度来管理数据访问,存在难以利用处理器中多个计算核心并发读写DNN海量参数提高训练效率的问题.
本文针对如何利用并发线程提高DNN训练中海量参数访问效率的问题,在分析NVM特性和对存储I/O软件栈带来的挑战基础上,设计了基于并发线程细粒度锁机制,通过修改文件元数据,缩小加锁粒度,为利用多核处理器提高DNN训练过程中访问海量参数的效率提供支撑;同时设计了基于两层日志的文件并发I/O机制,利用两层日志结构支撑多个海量参数访问线程的并发读写,同时能有效保证DNN参数访问中的数据一致性;此外在Intel的Optane DC设备基础上修改NOVA的源代码,实现了面向DNN高并发NVM文件系统的原型DNNFS,使用Filebench和Fio中的多种负载进行了测试与分析,结果表明相比NOVA,DNNFS能有效的提高并发线程读写数据的IOPS值和I/O带宽.
猜你喜欢
红外技术(2022年11期)2022-11-25
北京航空航天大学学报(2022年8期)2022-08-31
高技术通讯(2021年1期)2021-03-29
当代陕西(2019年14期)2019-08-26
电脑与电信(2018年11期)2018-02-16
环球市场(2017年36期)2017-03-09
信息安全研究(2016年3期)2016-12-01
中学数学杂志(初中版)(2016年5期)2016-11-01
测绘科学与工程(2014年2期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
