
一种基于改进CGAN的不平衡数据集成分类算法
2023-09-06 04:29荆晓娜阴艳超
小型微型计算机系统 2023年9期
刘 宁,朱 波,荆晓娜,阴艳超
(昆明理工大学 机电工程学院,昆明 650504)
1 引 言
传统的机器学习分类方法通常假设不同类别的样本数量一致或相当,然而,在实际应用中多数领域所采集到的数据集往往存在着不平衡问题,即某个或某些类别样本的数量显著少于其他类别的样本数量,如故障诊断[1]、金融欺诈[2]、医学诊断[3],网络入侵检测[4]等领域.在数据集不平衡的情况下若直接使用不平衡数据集对分类器进行训练会导致分类器偏向于多数类样本,容易将少数类误判为多数类.事实上,在多数情况下正确区分少数类样本通常具有更重要的意义,前述各应用领域均存在这一特性,因此,在数据不平衡条件下提高对少数类的识别精度显得十分重要,也成为近年来机器学习和数据挖掘研究的重点.
相关研究表明[5],不平衡数据分类的主要困难和挑战并非因数据的不平衡特性造成,而是来自数据本身的分类特性,例如少数类样本数太少且不具有代表性、不同类别样本重叠导致难以形成清晰的分割边界、少数类样本的分布不连续使得类型分割更加复杂.针对以上难点,国内外学者主要从数据处理、算法改进、数据处理与算法改进相结合的方式解决不平衡数据的分类问题.数据处理的主要思想是通过重采样技术构建平衡数据集,使数据集中的各类样本的规模一致或相当.在分类算法改进方面主要通过构造新的算法或对原有的分类算法进行改进提高分类器对少数类样本的识别精度.典型方法如集成学习[6-8]和代价敏感算法等[9,10],前者主要通过某种策略对训练得到的子分类器进行集成.得到一个比单一分类器稳定且泛化能力更好的强分类器.后者则是在算法迭代过程中为少数类样本设置更高的代价损失,该方法虽然也能有效提高不平衡数据的分类效果,但在多数情况下由于难以准确估计出最适合数据集特性的误分类代价,适用性相对较弱[11].因此,本文重点关注数据处理和集成学习两个方面的研究及进展.
数据处理最原始的方法包括随机过采样和随机欠采样,两者虽较易构建平衡数据集,对不平衡数据的分类性能也有所提升,但都存在一定的缺陷,随机过采样容易造成过拟合,产生较多的冗余样本,随机欠采样则有可能损失部分重要的信息.为了克服以上不足,众多学者提出了一系列改进型采样方法.较具代表性的方法如SMOTE[12]及其改进方法[13,14].除此之外,也有学者提出将噪声过滤技术与SMOTE方法相结合,减少或消除合成样本中的噪声样本,如SMOTE-Tomek和SMOTE-ENN,其中SMOTE-Tomek方法通过Tomek links技术移除采样后的重叠样本和噪声样本[15],SMOTE-ENN方法则是利用ENN方法(Edited Nearest Neighbor)对采样后的数据集进行分类,剔除分类错误的样本进而实现数据的深度清洗[16].
Goodfellow等人[17]在2014年提出的生成对抗网络(Generative Adversarial Networks,GAN)能够在不依赖任何假设的情况下实现对复杂数据分布信息的学习,生成还原原始数据分布的新样本,将其作为过采样方法可以提高不平衡数据的分类性能,且在多个不同应用领域中取得初步成效[18-20].CGAN在GAN的基础上增加外部标签信息用以指导生成对抗网络的训练,在一定程度上避免了GAN模型训练过程中容易出现的梯度消失和模型崩溃等问题.文献[21]通过训练CGAN并将其作为过采样方法扩增少数类样本提高少数类样本的分类精度.
文献[22]提出的自适应增强(Adaptive Boosting,Adaboost)方法作为集成学习的经典方法,在机器学习的不同领域中有着广泛的应用.随着Adaboost技术的不断发展,如何将其与数据采样技术相结合进一步提升不平衡数据中少数类样本的识别精度成为一个新的研究热点.如文献[23]提出的SMOTEBoost方法和文献[24]提出的RUSBoost方法,与SMOTEBoost方法相比,RUSBoost该方法可以降低训练的时间复杂度,但由于随机欠采样所获得的数据可能会造成重要样本信息的丢失,因此该方法在处理样本容量较大的数据集更具优势.以上将数据采样技术和Adaboost方法相结合的方式可以在不同程度上提高不平衡数据的分类性能,通常也能比使用单个方法获得更好的分类性能,然而,在这个过程中如何进一步提高采样后的样本质量,以及如何对Adaboost方法进行改进使其更好的处理不平衡数据仍需要进一步关注和研究.
虽然以上研究及现存的不平衡数据分类算法在处理不平衡数据时亦可取得不错的分类效果.但也暴露出一定的问题.在数据处理层面,既有的SMOTE及其改进方法较随机过采样方法有了明显的提升,但本质上都是从少数类样本的局部邻域出发,通过线性插值的方式合成新的样本,没有充分利用数据的分布信息,导致生成的新样本不能较好地模拟真实数据的分布特征,对不平衡数据的分类性能提升有限.GAN及其相关模型能够不依赖任何先验假设,通过数据驱动的方式实现对复杂数据分布信息的学习,生成类似原始数据分布特征的合成样本,将其作为过采样方法处理不平衡数据十分有利,然而这些模型在训练过程中都存在一个问题,即需要带标签的样本数量达到一定规模才能有效学习数据的分布特性,若不平衡数据中少数类样本规模较小或样本量绝对稀少则难以保证模型充分学习到少数类样本的分布特征,从而降低生成样本的质量.在算法层面,现有的分类算法并非为处理不平衡数据设计的,如何对现有的分类算法进行改进,使其能更好的适应不平衡数据也是不平衡数据分类任务的一个难点.
针对上述问题,本文同时从数据层面和算法层面对不平衡数据分类方法进行改进,提出了一种基于改进CGAN的不平衡数据集成分类方法(ICGANBoost,Improved CGAN Oversampling Method and Adaboost).一方面,首先采用SMOTEENN方法扩增既有的少数类样本并使其达到一定规模,使CGAN模型可以充分学习到少数类样本的分布信息,提高生成样本的质量.另一方面,通过改进原始Adaboost方法,将不平衡数据分类的常用评价指标F1值引入弱分类器权重的计算过程中,使改进后的Adaboost方法能更好的适用于不平衡数据的分类.本文方法在8组公开数据集与其他经典方法的对比实验结果表明,本文所提出的过采样方法能有效学习少数类样本的分布特性,根据分布学习结果产生的新样本对少数类样本进行扩补充后,可使少数类样本分布连续性得到增强,生成的少数类样本也更具代表性,避免了传统SMOTE方法从局部领域出发得到的样本易出现在边界附近导致类型重叠.所提出的集成分类模型能获得更好的分类效果.
2 相关理论
2.1 SMOTE与SMOTEENN
SMOTE方法的主要思想是从少数类样本点的局部邻域出发,在少数类样本与其K近邻样本之间采用随机线性插值法合成新的少数类样本,样本合成公式为:
xnew=xi+ε×(xj-xi)
(1)
其中xnew为合成的少数类样本,xi为第i个少数类样本,xj为第i个少数类样本的第j个近邻样本;ε为[0,1]之间的随机数.
SMOTEENN方法在SMOTE方法的基础上添加数据清洗功能,首先采用ENN方法对SMOTE采样后每一个样本进行标签预测处理,然后保留预测标签与真实标签相同的样本.与SMOTE方法相比,由于该方法对采样后的数据进行清洗,能够清除一定数量的噪声样本,通常也能获得更好的分类性能,也因此成为一种广受关注的SMOTE改进方法.
2.2 GAN与CGAN
GAN是2014年基于零和博弈理论提出的一种生成式模型,该模型由生成器G和判别器D两部分组成,在训练过程中,生成器可将输入的多维随机噪声转化为接近真实数据分布的生成样本,判别器则对输入的数据进行判断,判断输入的数据是真实数据还是生成数据.随着训练的进行,G和D的性能不断加强并最终达到平衡点,理论上可以生成与真实数据无限接近的生成样本.GAN模型的结构如图1所示,目标函数为:

图1 生成对抗网络结构图Fig.1 Framework of generative adversarial network

(2)
式中:x为真实样本,Pr为真实样本分布;Pz为随机噪声;z为随机噪声为,G(z)为生成样本.D(x)为输出概率.
Mirza等人[25]在GAN的基础上提出了CGAN,与GAN相比,CGAN增加了外部标签信息用以指导生成对抗网络的训练,不仅可以同时对多个类别样本的信息进行学习,在一定程度上也避免了GAN模型训练过程中容易出现的梯度消失和模型崩溃等问题.CGAN的目标函数在GAN的基础上做了修改,新的目标函数如公式(2)所示:
Ez~Pz{log[1-D(G(z|y))]}
(3)
2.3 Adaboost方法
Adaboost方法作为Boosting技术的代表算法,通过训练多组弱分类器并采取某种策略将其组合达到更好的分类效果.该方法的独特之处在于其不会随着迭代次数和样本复杂度的增加而发生过拟合,Freund等人在文献[26]中的实验结果表明,随着训练轮数的增加,训练误差将趋近于零,测试误差会继续下降并收敛至某一界限,Adaboost方法具体步骤如算法1.
算法1.AdaBoost算法
输入:训练数据集S={(x1,y1),(x2,y2),…,(xi,yi)},i=1,2,…,n,yi∈{1,-1},迭代次数T,基分类器为g;

Step 1.初始化样本权重分布:D1=(w11,w12,…,w1n);w1i=1/n,i=1,2,…,n.
Step 2.Fort=1 toT
a)根据当前训练样本的权值分布训练基分类器gt(xi)
b)计算当前分类器在训练集上的分类误差:
(4)
c)计算当前弱分类器在最终分类器中所占的权重:
(5)
d)更新样本权值分布,其中Zt为归一化因子:
(6)
Step 3.组合基分类器并输出分类结果:
(7)
2.4 不平衡数据分类评价指标
针对不平衡数据分类性能的评价,整体的分类精度并不能较好的评价一个分类模型的优劣,因此本文采用F1值、AUC和G-mean这3个指标对不平衡数据的分类性能进行评价.
1)F1值,精确率和召回率的调和平均,是不平衡数据分类评价常用的评价指标:
(8)
其中,pression和recall分别表示准确率和召回率.
2)G-mean值,用于度量分类器在两类数据上的平均性能:
(9)
其中,TPR和TNR分别表示真实正类率和真实负类率.
3)AUC值,用于衡量分类性能的综合指标.
(10)
其中,FP、FN分别表示负类样本被误判为正类,正类样本被误判为负类的样本数量,N和M分别表示数据集中正类样本和负类样本的数目.
3 本文方法
3.1 基于改进CGAN的过采样方法
条件生成对抗网络(Conditional Generative Adversarial Networks,CGAN)可以在不依赖先验假设的情况下实现对复杂数据分布特征的学习,生成类似原始数据分布的高质量样本,以此作为一种过采样方法对不平衡数据处理十分有利.然而,当不平衡数据集中少数类样本较少或绝对稀少时难以保证CGAN充分学习其分布特性,从而造成生成的样本质量欠佳.基于此,本文首先从数据方面对不平衡数据进行处理,对CGAN做以改进,提出了一种混合SMOTEENN与CGAN的不平衡数据处理方法,该方法首先从既有的少数类样本出发,采用SMOTEENN方法快速生成多个少数类样本,使少数类样本达到一定的规模,保证CGAN能充分学习到少数类样本的分布特征;然后在此基础上训练出能够较好学习到少数类样本分布特征的CGAN模型;最后利用CGAN模型中的生成网络重新生成指定数量的新样本增大少数类样本的规模并构建最终平衡数据集.整个方法的具体步骤如算法2所示.
算法2.SMOTEENN_CGAN
输入:原始不平衡数据集
输出:数据平衡化处理后的平衡训练集
Step 1.归一化不平衡数据集D并将其划分为训练集S和测试集T,记训练集S中少数类样本和多数类样本的数量分别为N0、N1,以及构建最终平衡数据集所需合成样本的数量syn_Num=N1-N0
Step 2.从训练集S中随机选择一个少数类样本xi,根据欧式距离搜索每个少数类样本xi的k近邻样本.
Step 3.生成一个[0,1]之间的随机数ε,从xi的k近邻样本中随机选取一个样本xj,根据公式(1)合成新样本.
Step 4.将合成的新样本xnew加入训练集的少数类样本中,判断训练集S是否达到平衡,若训练集S达到平衡则执行Step5,否则重复步骤step 2,Step 3.
Step 5.采用ENN算法对训练集S进行分类,删除分类错误的样本,得到训练集S′.
Step 6.分别记S′中的少数类样本及标签为S0′、y0,随机生成batch_size个服从高斯分布的多维噪声集合Z,同时从样本集S0′中抽取batch_size个正类样本X.
Step 7.基于噪声Z、真实样本X和标签y0分别训练判别网络和生成网络,根据优化目标计算二者的损失.
Step 8.判断CGAN模型是否收敛,若模型收敛则保存该模型并执行Step 9,否则重复Step 6,Step 7.
Step 9.随机生成syn_Num个服从高斯分布的噪声集合Z1,将其和样本标签一同作为生成网络的输入即可生成syn_Num个符合原始数据分布特性的少数类样本.
Step 10.将生成的syn_Num个少数类样本与原始训练集S合并即可得到最终平衡训练集S″.
3.2 基于F1值计算弱分类器权重的Adaboost方法
原始Adaboost方法根据公式(4)所得到的分类错误差计算当前弱分类器的权重,通过公式(5)和公式(7)可以看出分类误差较低的弱分类器在最终分类器中占有更高的权重.然而,基于公式(4)所得到的分类误差是依据训练样本的整体分类情况所得到,当数据集不平衡时,该分类误差难以体现出不同类别样本的分类情况及数据的不平衡分布.
F1值作为不平衡数据分类中最常用评价指标,相较于其他评价指标能更好的体现出分类器对不平衡数据的分类性能,因此本文通对Adaboost方法进行改进,提出一种基于F1值的弱分类器权重计算方法,使改进后的Adabosot方法能更好的适应不平衡数据的分类,改进后分类错误率的计算公式如下:
(11)
其中,F1t为当前弱分类器gt(x)在训练集上得到的F1值.
(12)

3.3 基于改进CGAN的不平衡数据集成分类方法
原始不平衡数据集经过算法2处理后会得到一个平衡数据集,然后采用3.2节所提出的基于F1值计算弱分类器权重的Adaboost方法对算法2所获得的平衡数据集进行训练即可得出本文提出的ICGANBoost算法,其详细步骤及相关python代码如算法3所示.
算法3.ICGANBoost
输入:数据集{(x1,y1),(x2,y2),…,(xi,yi)},i=1,2,…,n,yi∈{1,-1},迭代次数T,基分类器为g;

1.trainX,testX,trainY,testY=getData();
2.synN=Counter(trainY[-1])-Counter(trainY[1]);
3.synSample=genSamples(class_for,synN);
4.addL=np.ones(syn_Sample,1);
5.trainXY=np.concatenate((trainX,trainY),axis=1);
6.synXY=np.concatenate((synSample,addL),axis=1);
7.totalXY=np.concatenate((trainXY,synXY),axis=0);
8.newX=totalXY[:,0:-1];
9.newY=totalXY[:,-1];
10.allPre= np.zeros((len(testX),1));
11.InitializeD[i]=1/(n+synN)fori=1,…,n+synN;
12.fortin range(T):
13.g.fit(newX,newY,D);
14.trainPred=g.predict(newX);
15.testPred=g.predict(testX);
16.F1=metrics.f1_score(newY,trainPred);
19.D=calWeight(newY,trainPred,beta,D);
20.allPre+=beta*testPred;
21.returnG(x)=np.sign(allPre);
1)首先对原始数据进行归一化处理并将其划分为训练集trainX、测试集testX、标签trainY和标签testY;调用算法2训练好的SMOTEENN_CGAN模型生成synN个少数类样本(第1~3行).
2)将生成的少数类样本synSample及所赋标签与原始训练集trainX及标签trainY合并即可得到平衡训练集newX及其标签newY,然后对newX中的每个样本平均分配相同的权值.(第4~12行).

4)由当前弱分类器在测试集上的预测值及在最终分类器所占权重可以得出前t个弱分类器在测试集上的加权预测值allPre,然后更新训练样本的权值分布(第18~20行)
5)重复执行步骤2)和步骤3),达到迭代次数T时输出集成分类器的预测值,结束循环.(第21行)
4 实验结果及分析
本文实验硬件环境为Intel(R)Core(TM)i5-8250U CPU@1.60GHz,运行内存为8G,软件环境为windows10操作系统,实验工具采用python3.7.4,深度学习框架选取Tensorflow2.0.0和Keas2.3.1.
4.1 实验数据与设计
为验证本文方法的有效性和实用性,实验采用8组不同应用背景的KEEL数据集,实验前首先对含有多类别的数据集划分为多数类和少数类,然后对不同数据集进行归一化处理,将每组数据集取样本数量的70%作为训练集,其他30%作为测试集,最后取5次实验结果的平均值作为本文方法及相关对比算法的最终结果进行对比分析.将本文数据集中多数类样本标记为-1,少数类样本标记为1.不同数据集信息如表1所示.

表1 数据集基本信息Table 1 Basic information of datasets
实验设计思路:根据当前不平衡数据集,首先分别以采样效果展示和数据对比的形式将SMOTEENN_CGAN方法同其他经典过采样方法进行比较,验证将其作为过采样方法的有效性,然后对本文所提出的ICGANBoost集成分类方法同其他集成分类方法进行比较,证明该集成分类方法对不平衡数据进行分类更具优势.
4.2 SMOTEENN_CGAN方法验证与分析
4.2.1 不同过采样方法采样效果对比分析
为了证明将SMOTEENN_CGAN作为过采样方法处理不平衡数据的有效性,首先通过python3.7的sklearn包随机生成一组多数类样本数500,少数类样本规模较小且样本数量为50的人工不平衡数据集,其次分别采用SMOTE、Borderline-SMOTE、ADASYN、CGAN(直接使用原始数据对CGAN进行训练)以及本文过采样方法对数据集进行过采样处理并将采样效果进行可视化展示.以上不同过采样方法的效果对比如图 2所示.
图2给出了原始数据集以及采用不同过采样方法的生成样本可视化对比图.其中图2(a)是原始数据集的分布图,可以看出原始数据集中少数类样本规模较小且边界附近存在少量的噪声样本;图2(b)是SMOTE方法采样后不同类别样本的分布图,可以看出SMOTE方法从局部邻域出发并通过线性插值的方法合成新样本,合成的新样本与原始样本差异较小,存在较多的重叠样本且生成的部分样本会落在多数类区域中,不利于分类器的训练;图2(c)和图2(d)分别是Borderline-SMOTE和ADASYN过采样效果图,两者都更侧重于边界区域的少数类样本,易受到边界样本的影响,导致在边界附近生成更多的噪声样本;图2(e)和图2(f)分别是在模型参数相同的前提下对CGAN和SMOTEENN_CGAN模型进行训练并将其作为过采样方法扩增少数类样本的效果对比图,总体来看,两者所生成的新样本与真实样本分布基本一致但又不完全相同,能够有效减缓经典过采样方法出现的样本重叠等问题,体现了将生成对抗网络及相关模型作为过采样方法处理不平衡数据问题的有效性.但和图2(f)相比,由于原始数据中少数类样本规模的限制,CGAN模型没有充分学习到少数类样本的分布特征,最终导致所生成的少数类样本比较发散,在样本边界附近会产生噪声数据,降低生成样本的质量.而本文方法所生成的样本能较好的模拟原始数据的分布特征,基本都在原始样本的分布区域中,且没有噪声样本的产生,说明本文方法首先通过SMOTEENN对原始样本进行扩增,使少数类样本量达到一定规模,然后再训练CGAN模型可以使其充分学习到少数类样本分布特征,生成与原始样本差异更大、所提供信息更多的新样本.
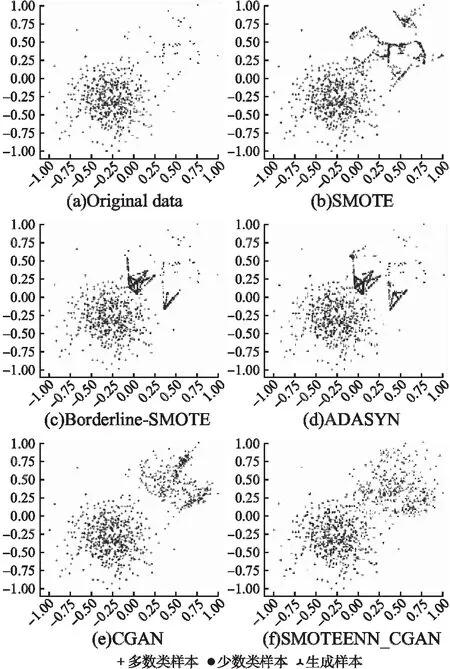
图2 不同过采样方法生成样本对比图Fig.2 Visual comparison of synthetic data of different oversampling methods
然而,仅凭直观的可视化展示还不足以证明本文过采样方法在不平衡数据分类处理方面的有效性和泛化性,下文将进一步对CGAN改进前后的合成样本质量进行评估,并基于上述评价指标和8组公开数据集对不同采样方法的分类性能进行比较.
4.2.2 基于JS散度的生成样本质量评估
Kullback-Leibler Divergence(KL散度)又称为KL距离,是在信息熵的基础上建立起来的,可将其看成数据分布的一种“距离”.设P={p(x1),p(x2),…,p(xn)},Q={q(x1),q(x2),…,q(xn)}为连续区间D中两个不同的概率密度函数,则P和Q之间的KL距离如公式(13)所示:
(13)
其中:P(x)>0,Q(x)>0,由公式(13)可以看出,KL值越小,P和Q的概率分布越相似.
由于KL距离不具备对称性,且不满足三角不等式,因此Lin等人[27]在KL距离的基础上提出JS散度并用其评估两个随机变量概率分布之间的相似度,JS散度计算公式见式(14):
(14)
由公式(14)可以看出,JS散度越小,P和Q的分布越相似,因此本文采用JS散度对CGAN改进前后所生成的少数类样本进行评估,用其验证CGAN改进后所生成的少数类样本质量更高,可以更好的模拟原始数据的分布特征.
在4.2.1节的基础上,首先采用SMOTEENN_CGAN和CGAN模型随机生成与少数类样本规模相同的少数类样本,然后计算生成样本与原始样本不同特征值下的JS散度,表2为5次实验结果及平均值,其中PiQi(PiSi)表示原始少数类样本第i个特征值与CGAN(SMOTEENN_CGAN)模型生成样本的第i个特征值的JS散度.

表2 基于JS散度的生成样本质量评估Table 2 Generative sample quality assessment based on JS divergence
由表2可以看出,改进后的CGAN模型所生成的样本在不同特征值下与原始样本的JS散度均更小,说明本文方法生成的少数类样本能更好的模拟原始少数类数据分布特征,所生成的样本质量更高.
4.2.3 不同过采样方法分类性能对比分析
将本文所提出的过采样方法与OR(原始数据)、SMOTE、ADASYN、CGAN在8组公开数据集对F1值、G-mean和AUC评价指标进行比较.实验中均采用CART决策树作为分类器,设置CGAN的迭代次数为3000,步长为0.0002,生成网络和判别网络均采用全连接神经网络、隐藏层采用LeakyRelu激活函数、输出层分别采用tanh和sigmoid激活函数.实验结果如表3所示(粗体表示最优值).

表3 基于不同过采样方法得到的分类器评价指标Table 3 Metrics of classifier based on different oversampling algorithms.
由表3的实验结果可以看出,本文过采样方法在数据集pima、haberman、page-bloks和glass2上的3个评价指标均优于其他过采样算法.尤其在少数类样本规模较小的数据集haberman(少数类样本个数为81)和glass2(少数类样本个数为17)上表现突出,以此可以证明本文过采样方法处理不平衡数据尤其是在少数类样本数较少的不平衡数据集上表现更有优势.和原始CGAN过采样方法相比.F1值平均提高了6.3%,G-mean值平均提高了2.3%,AUC值平均提高了5.6%.虽然在个别数据集中没有达到最好的分类效果,但差距也在可接受的范围内,如在ecoli1数据集中本文方法所取得的F1值和G-mean略低.但其AUC值最高提高了8%,在wine_red数据集中得到的G-mean和AUC值略低.但其F1值取得了最高值.分析其原因可以发现:一方面可能与原始数据的结构特征有关系.原始数据中可能存在类重叠样本.在生成新样本时可能会引入部分噪声样本;另一方面可能是CGAN模型的训练参数选择不是很恰当.模型超参数的选择与数据集有很大关联.
4.3 ICGANBoost集成学习方法验证与分析
将本文提出的ICGANBoost集成学习分类方法与其他集成学习方法在以上公开数据集做比较,进一步验证本文所提出的将改进CGAN的过采样方法与改进的Adaboost方法相结合的方式可进一步提升不平衡数据的分类性能,本节实验的弱分类器同样采用CART决策树,迭代次数设置为20.考虑到Adaboost方法不会随着训练次数的增加而发生过拟合,文中直接在训练集和测试集上开展实验,实验结果如表4所示,表4中的Ada+表示3.2节所提出的基于F1值计算弱分类器权重的Adaboost方法,SMOTE和RUS分别表示先用过采样和欠采样获得平衡数据集,然后采用Adaboost方法训练所获得的平衡数据集; ICGAN表示先使用SMOTEENN_CGAN方法生成少数类样本,再用得到的平衡数据集训练Ada+分类器.
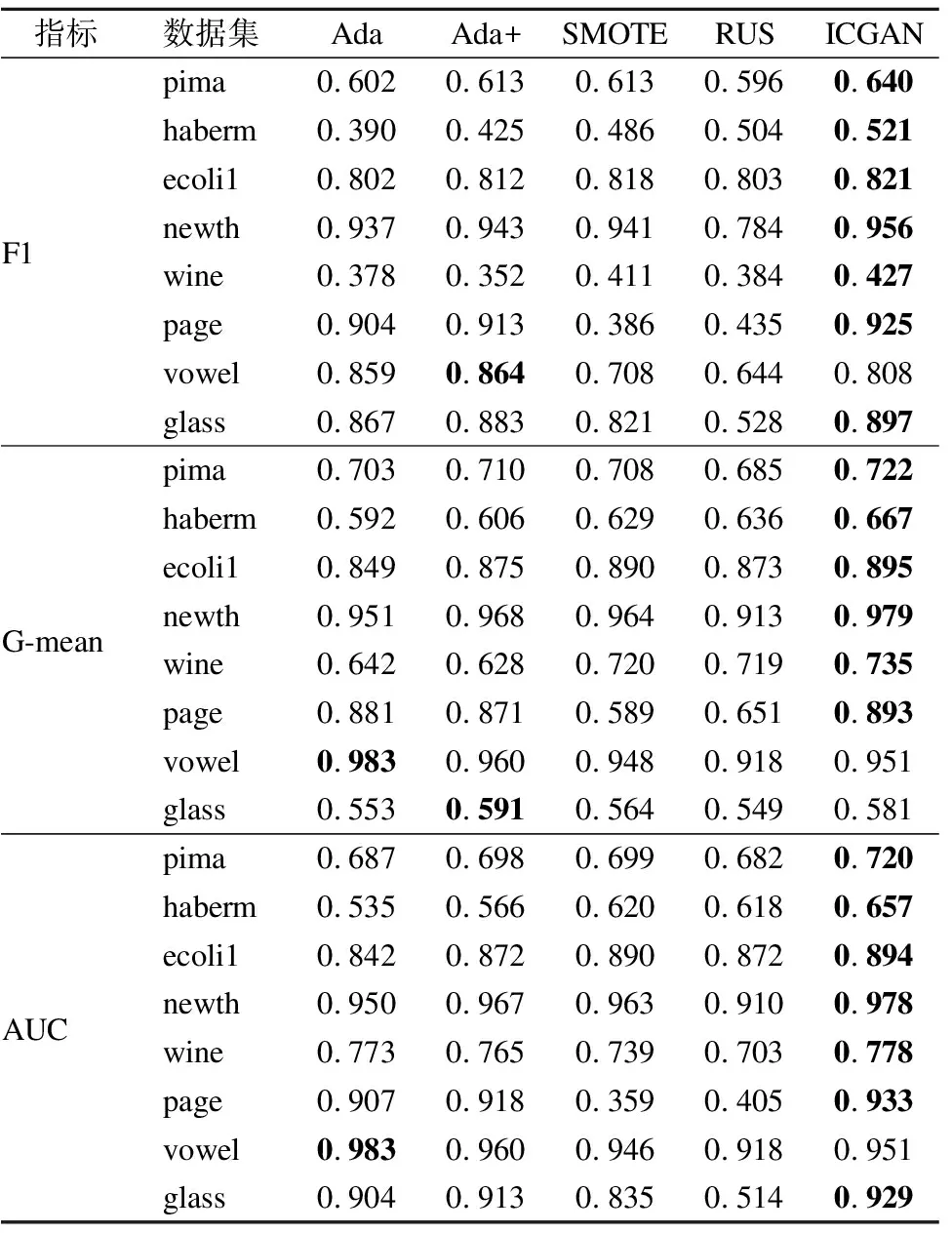
表4 基于不同集成学习方法得到的分类器评价指标Table 4 Metrics of classifier based on different ensemble learning method.
由表4的实验结果可以看出,基于F1值计算弱分类权重的Adaboost方法在多个数据集中较原始Adaboost方法有一定的提升,和原始Adaboost方法相比.Ada+在8组数据集上的F1、G-mean和AUC值平均分别提高了0.82%、0.69%、0.98%.说明通过将F1值引入到弱分类器权重更新的方式可以给不平衡数据分类性能较好的弱分类器赋予更高的权重,使得改进后Adaboost方法更适应不平衡数据的分类.而 ICGANBoost集成学习分类模型在多个数据集中有了明显的提升,其在上述评价指标中最高分别提高13.1%.9.3%和12.2%.以此证明本文所提集成方法的有效性;综合表2和表3可以看出,集成后的各分类指标相比于单一分类器有一定的提升,说明将数据采样和集成学习相结合的方式在处理不平衡数据分类任务时可以获得更好的分类效果.
5 结 论
CGAN作为过采样方法处理不平衡数据时易受到少数类样本规模的限制,在数据规模偏小的情况下难以有效学习其分布特征,导致生成的样本质量欠佳.针对上述问题,本文以CGAN和集成学习为基础,同时在数据层面和算法层面对不平衡数据处理方法进行改进,提出了一种基于改进CGAN的不平衡数据集成分类算法:第1阶段首先采用SMOTEENN方法快速生成少数类样本,使少数类样本达到一定规模,保证CGAN能充分学习到少数类样本的分布特征,提高合成样本的质量;第2阶段对原始Adaboost方法进行改进,将F1值引入弱分类器权重的计算过程中,使改进后的Adaboost方法更好的适用于不平衡数据的分类.最后用改进后的Adaboost方法训练平衡数据集得到集成分类模型.以F1值、AUC和G-mean作为评价指标,在8组公开数据集上的对比实验结果表明,所提方法可以显著提高不平衡数据的分类精度.未来的研究工作将从两个方面展开:1)如何对本文方法涉及的模型参数做进一步优化,提高算法的运行效率;2)如何将该方法与实际应用场景相结合,解决实际应用当中的不平衡数据分类问题.
猜你喜欢
China Report Asean(2022年8期)2022-09-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
物联网技术(2020年12期)2021-01-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
电子测试(2018年1期)2018-04-18
初中生世界·七年级(2017年9期)2017-10-13
汽车零部件(2017年4期)2017-07-12
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
