
无监督随机优化乘积量化图像检索模型
2023-08-29 01:10周泽峻杜逆索欧阳智
小型微型计算机系统 2023年8期
周泽峻,杜逆索,,欧阳智
1(贵州大学 计算机科学与技术学院,贵阳 550025)
2(贵州大学 贵州省大数据产业发展应用研究院,贵阳 550025)
1 引 言
基于内容的图像检索(Content Based Image Retrieval,CBIR)[1]是计算机视觉领域的一块重要子领域,CBIR以图像语义特征为线索,从图像数据库中检索得到与之“相似”的一些图片,其过程可细化为特征提取阶段和相似性计算阶段,之后加入重排机制对结果进行调优,从而增加检索的精度.CBIR在电子商务,公安系统,电子图书馆等领域应用广泛.
在CBIR的特征提取阶段,使用无监督的方法提取到的特征具有语义性不足的问题.早期通过SIFT(Scale-Invariant Feature Transform)[2]、Bow(Bag of Word)[3]、VLAD(Vector of Locally Aggregated Descriptors)[4]等方法提取图像的低级特征,如颜色、纹理、形状等特征来进行检索,但受限于这些特征包含的内容信息过少,导致实际检索效果并不佳,而且人工分析在特征使用过程中起主导作用,增大了前期工作量.得益于深度学习的发展,利用神经网络通过无监督的方式进行特征提取,相较于传统的方法极大地增强了提取到特征的语义信息,而且其具有无监督自学习的特性.基于富含语义信息的特征进行最近邻检索(Nearest Neighbor,NN),适用于图片数量爆发增长的互联网时代,可以有效地提高图像检索的精度.尽管特征的语义信息已显著的增强,但由于神经网络无监督自学习的特性,导致通过神经网络提取到的特征解释性不佳,即无法凸显出特征的语义信息,因此如何加强特征的语义信息是亟待解决的问题[5,6].
为了进一步提升特征的语义性,研究者们在CBIR特征提取阶段引入了注意力机制对特征进行了信息处理.注意力机制可以对图像特征进行信息筛选,以得到更高质量的图像特征.例如,Wu等[7]通过一个卷积核大小为 3×3 的卷积层及softmax层预测不同特征的权重,然后计算不同特征的重要性实现信息筛选,然而该方法在计算不同特征重要性的时候需要标签的参与,难以运用到无监督模型中.Tony等[8]将二阶注意力[9]应用于图像检索任务,二阶注意力使任一特征与所有特征建立联系,通过特征之间的信息融合产生新特征,但是把任一特征与所有特征建立联系会导致融合后的特征信息过于冗余,把语义相关性不高的特征进行融合,会对最终得到的特征语义信息有一定的影响.因此如何通过注意力机制在无监督的条件下增强图像特征的语义信息是需要考虑的问题.
另一方面,在CBIR的相似性计算阶段,逐条比对的方法所消耗的时间会随着图像数量的增多而增长.随着互联网图片的爆炸式增长,早期最近邻检索使用的逐条比较方法会消耗大量的时间,即基准图片与数据库图片一一进行相似性计算,然后排序得到结果,如K近邻(K-Nearest Neighbor,KNN)检索[10],这种线性复杂度的检索方式破坏了用户的使用体验.因此,研究者们把目光聚焦到了近似最近邻检索(Approximate Nearest Neighbor,ANN)上,例如Tao等[11]基于相似图像特征近似的特点,利用聚类等方法对数据库中的数据进行了分类或编码,通过基准图片的特征预测其所属类别或进行相似性计算,返回类别相同的部分图像或者距离较近的若干图像作为检索结果,牺牲一定范围的精度以提高检索的效率.目前近似最近邻检索中比较受关注的方法有基于哈希(Hash)的近似最近邻检索算法[12,13]与基于乘积量化(Product Quantization,PQ)的近似最近邻检索算法[14,15].Erkun等[16]和杨粟等[17]通过对提取到的特征进行哈希函数映射得到了对应的二元码,将欧式空间的距离计算转化到汉明空间,在一定程度上加快了计算的速度,但是其本质仍是逐个比较,因此随着数据量的增加,其检索速度会相应的减慢.
基于乘积量化的近似最近邻算法可以有效缓解随着图片数量的增长检索时间增多的问题.基于乘积量化的近似最近邻算法通过分割向量,然后对其进行K均值聚类(K-means)从而得到对应的码书(CodeBook),即将高维向量分割成多个低维向量,在节省了存储空间的同时,又通过子向量到质心的方式对距离进行非对称距离计算,并通过排除不同子向量的不同类别提高了计算的效率[14].但在乘积量化方法中使用的K-means算法得到的聚类中心是局部最优的[18],在量化过后对检索精度有一定的影响,因此在检索的离线训练过程需要考虑如何缓解K-means算法可能带来的精度损失.
针对上述问题,提出基于卷积注意力模块的无监督随机乘积量化图像检索模型.首先,通过在CBIR的特征提取阶段采用卷积注意力模块(Convolutional Block Attention Module,CBAM)[19]来对无监督特征提取过程进行控制,使得到的特征语义信息更丰富从而提高检索的精度.然后将特征提取阶段得到的语义图像特征使用优化乘积量化方法对特征进行处理,从而缓解了大规模数据集上使用逐条比较的最近邻检索速度慢的问题.最后针对乘积量化中使用的K-means存在的局部最优的问题,以其平均精度作为参考,通过重复实验取最优的方法,使得PQ中码书子向量的聚类中心是接近全局最优的,提高了检索的精度.
因此,本文的贡献主要有以下两点:
1)在无监督深度乘积量化图像检索中,采用CBAM,增强检索任务中特征提取阶段提取特征的语义信息,使相似图像提取到的特征在进行相似度计算时可以取得更优的值.通过实验证明,增加的CBAM有效的提高了检索的精度.
2)提出一种基于优化乘积量化算法的随机优化,缓解了乘积量化过程中K-means算法的局部最优问题,提高检索精度的同时也提高了检索效率.
2 乘积量化图像检索模型
假设数据库中包含N个图片I,给定一个查询图片q,相似性图片检索致力于从N个I里找到与q相似的一些图片.
本文模型首先在预先训练好的VGG网络中加入CBAM层,通过调整后的VGG网络提取得到初步增强后的图像特征,然后通过UPH[17]的方法根据图像特征构建出图像的语义结构矩阵,并以此语义结构矩阵来训练神经网络,接着使用训练好的神经网络提取得到最终的语义特征,对得到的语义特征向量使用随机优化的乘积量化算法得到供检索使用的码书C,最后通过非对称距离计算方式计算特征之间的距离,根据对应的排除机制与计算的距离得到最终的检索结果.
根据上述步骤,本文所提出的模型结构如图1所示,主要包含两个模块:1)基于CBAM的特征提取模块.使用基于CBAM的深度学习方法进行无监督的特征提取;2)随机优化的乘积量化模块.通过随机优化乘积量化算法进行特征的编码,然后根据编码进行相似度计算.
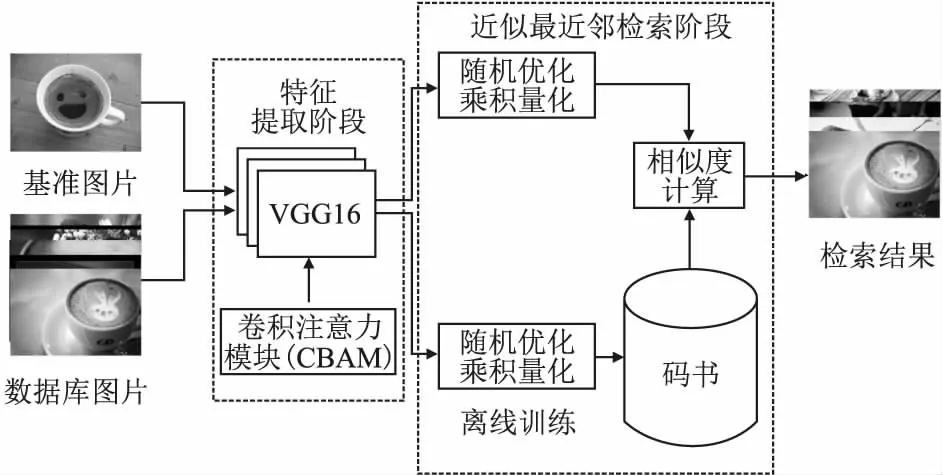
图1 模型框架图
2.1 基于CBAM的特征提取模块
特征提取是图像检索流程中关键的一环,提取到的图像特征的质量决定了相似性计算阶段的准确率.因此,图像检索中特征提取使用的方法的选择尤为重要.神经网络提取到的特征在图像检索领域的表现要远高于传统的特征提取方法,神经网络提取特征即通过神经网络无监督的自学习,通过其中的不同层对特征进行线性识别与整合,最终得到充满语义性的图像特征[5,6].
模型使用以ImageNet数据集预训练过的VGG[20]神经网络初步提取图像特征,利用注意力机制的思想,在VGG网络的卷积层之后添加CBAM层,控制生成特征的细节层次,CBAM包含了通道注意力(channel attention)与空间注意力(spatial_attention)两阶段,如图2所示,通过类似于学习的方式自动获取每个特征空间的重要程度,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征.第1步使VGG卷积层最后一层的输出进入通道注意力进行处理,第2步把通道注意力的输出加入到空间注意力中,得到的输出即为CBAM的输出,第3步通过加入了注意力机制的VGG初步提取的特征向量(fc7卷积层的输出)来计算成对训练样本的余弦距离,第4步通过UPH[17]的语义矩阵构建方法根据计算得到的余弦距离构建语义相似性矩阵,第5步在VGG的基础上,添加了全连接层,把得到的高维特征,映射为Kbit的二元码,第6步根据二元码计算的成对样本汉明距离矩阵Hij,如式(1)所示,使用此汉明距离矩阵构建好的语义相似性矩阵构建损失函数,如式(2)所示,第7步根据损失函数训练神经网络,最后得到训练好的神经网络,保留其对应的参数信息,在接下来的流程中使用该神经网络提取图像对应的二元码特征.
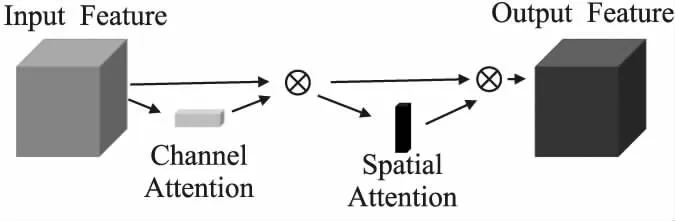
图2 卷积注意力模块
(1)
其中bi为对应样本的二元码,K为二元码的位数.
(2)
其中Sij为语义相似性矩阵,m为本轮训练输入样本个数.Hij为汉明距离矩阵.
2.2 随机优化的乘积量化模块
PQ即乘积量化,是为相似性图像检索设计的近似最近邻算法[14],通过分块的思想把得到的图像特征进行分解,得到多个低维子空间的笛卡尔积,然后单独对每一个子空间使用K-means方法[15]进行量化,使每一个子向量分为对应的K个类中的一个,使用类别数作为码书对应位置的值,所有样本的子空间量化完成后,得到完整的码书,以此码书作为检索的基础,在每一次子空间计算的时候可通过子空间的值排除值不相等所有其他样本,在数据库图片数量较多时大大加速了检索过程,通过精度损失较小的非对称距离计算公式,如式(3)所示,得到基准样本与数据库样本的距离,对距离进行排序最终得出检索结果,其中q(I)为对I图像的特征向量进行乘积量化得到的聚类中心,d(q,I)为使用距离计算公式计算得到的距离,实验选取的距离计算方法为余弦距离.
(3)
优化的乘积量化(Optimized Product Quantization,OPQ)[15],在乘积量化的基础上,使用量化失真作为目标函数来评估乘积量化器的最优性,通过优化目标函数来减少乘积量化的量化失真,目标函数如式(4)所示,自由参数由子码本(C1,…,CM)和空间分解R组成,其中,C为子码本,R为空间分解.R的附加自由参数允许向量空间旋转,从而放松对码字的约束.因此,与预先固定的R相比,优化的乘积量化器可以减少量化失真.
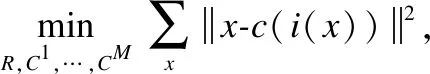
(4)
随机优化的乘积量化(Stochastic Optimized Product Quantization,SOPQ)在原本优化乘积量化的基础上,通过聚类中心重复选取的方法,缓解了K-means局部最优解的问题.实验中每检索一张图片,都对聚类中心进行了重新训练,使得到模型精度接近使用K-means后的数学期望值Avg_mAP,然后通过重复训练乘积量化子空间特征向量的聚类中心,在得到大于Avg_mAP的精度时,保留此聚类中心作为应用时的聚类中心,相对缓解了K-means算法带来的不确定性.
模型根据2.1节中得到的神经网络,第1步提取所有数据库图像的Kbit二元码图像特征,第2步根据PQ的思想,把这些二元码分为4个子空间,依次计算子空间的值,如表1所示的示例.通过K-means的聚类算法为子空间特征向量找到256个聚类中心,子空间对应的值即为其距离最近的聚类中心编号.依次对4个子空间进行处理,得到完整的码书.根据SOPQ的思想,重复进行第2步,得到相对最优的聚类中心,第3步根据此聚类中心构建码书,进行图片检索,得到的精度作为模型最终的结果.

表1 码书示例
检索过程第1步把给定的特定示例q加入到训练好的VGG神经网络中得到其对应的二元码特征,第2步根据此二元码特征与码书通过式(3)计算出对应的距离,第3步对计算得到的距离进行排序后返回排行前1000的检索结果,第4步根据图像检索中的mAP计算公式,如式(5)所示,得到当前给定示例图像的mAP值,在5000张测试图片mAP计算完成后取平均数得到最终的模型精度,其中AP为不同召回率上的正确率的平均值,N为测试图片的张数.
(5)
3 实 验
本节把模型在大规模数据集NUS-WIDE上的表现与先进的无监督图像检索模型进行了比较,同时通过消融实验证明了创新部分的有效性.
3.1 数据集
实验使用了相对大规模的NUS-WIDE数据集来进行实验.NUS-WIDE是一个多标签的数据集,包含269648个样本,每个样本都有基于81个概念的多个标签,且分辨率大小不一致,实验选取了其中具有代表性的21个概念,共190834张图片,且将每张图像的分辨率重置为了224×224,在选取的子数据集中选取了10000张图片用作训练,又选取了5000张作为测试,通过5000张测试图像在全部190834张数据库图像检索得到的平均mAP_1000值作为最后的实验结果.
3.2 实验环境与参数
本研究所有的实验均在Ubuntu Server 18.04操作系统,显卡为NVIDIA TITAN-XP 12G×1,内存为32GB×4的计算机上进行,使用TensorFlow1.8.0实现所提出模型,CUDA版本为9.0.176,CUDNN版本为7.4.1,学习率设置为0.001,batchsize设置为24,使用动量优化法优化模型,在神经网络训练的过程中,采用VGG16预训练模型加速收敛.
3.3 结果分析比较
为了验证模型的有效性,与先进的无监督图像检索模型进行了比较,包括DSH(Density Sensitive Hashing)[21]、SGH(Stochastic Generative Hashing)[22]、DeepBit(Learning Compact Binary Descriptors)[23]、SSDH(Semantic Structure-Based Unsupervised Deep Hashing)[16]、DVB(Deep Variational Binary)[24]、DistillHash[12]、SGAH(Strengthened Generative Adversarial Hashing)[13]、UPH(Unsupervised Parallel Hash)[17],结果如表2所示,其中DSH、SGH是浅层无监督模型,DeepBit、SSDH、DVB、DistillHash、SGAH、UPH是深度学习无监督模型.
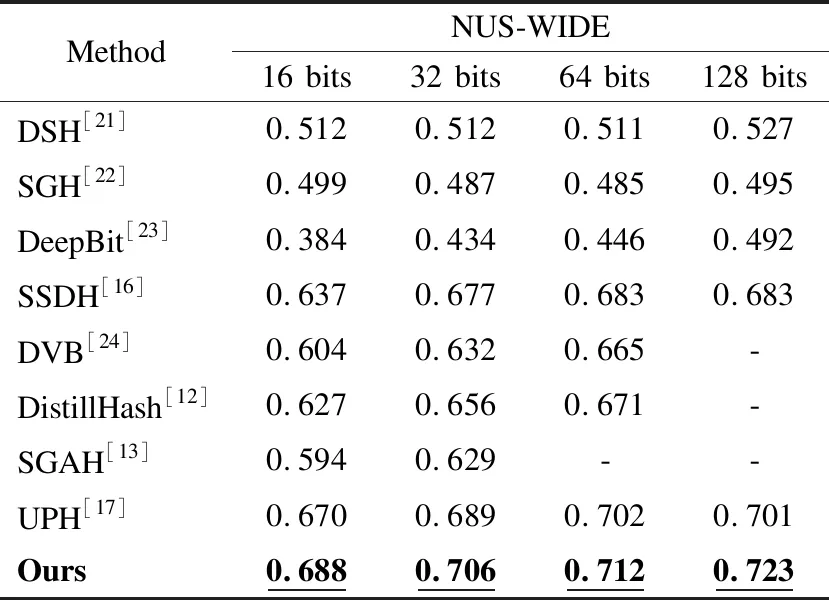
表2 NUS-WIDE数据集上不同模型mAP对比
从表2中可以看出,本模型相较于表现最好的浅层无监督模型DSH在16bits、32bits、64bits、128bits上的mAP值分别要高17.6%、19.4%、20.1%、19.6%,相较于经典的浅层无监督模型SGH在16bits、32bits、64bits、128bits上的mAP值分别要高18.9%、21.9%、22.7%、22.8%,相较于表现最好的深度学习无监督模型UPH在16bits、32bits、64bits、128bits上的mAP值分别要高1.8%、1.7%、1.0%、2.2%,相较于经典的深度学习无监督模型SSDH在16bits、32bits、64bits、128bits上的mAP值分别要高5.1%、2.9%、2.9%、4.0%.从上述结果可得,本文模型在图像检索任务上表现良好,分析其原因是加入的CBAM通过类似于学习的方式自动获取每个特征空间的重要程度,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征,对图像特征语义进行了增强,在一定程度上可以增强检索的精度.同时,使用的随机优化乘积量化算法,在剔除掉一部分无关数据之后,能略微增加检索的精度.
为了验证本模型在相似性图像检索应用上的效率,与具有高效检索性能的模型SSDH在NUS-WIDE数据集上的16bits、32bits、64bits、128bits进行了检索速度比较,结果如图3所示,可以看到基于哈希的最近邻图像检索模型SSDH的检索时间随着比特位的增加检索时间会不断的增长.与其相比,本模型在不同比特位下的检索时间比SSDH缩短了3.73%、35.29%、44.06%、60.94%,并且图像的检索速度在4种水平下十分接近,使得在实际应用时可以根据精度需求以及存储需求选择对应的比特位,而不会影响检索时间.从上述结果可得,本模型在加快图像检索速度方面表现优良,分析其原因是本模型在相似度计算阶段中采用的乘积量化算法首先会根据子空间的值剔除部分数据,然后再计算数据间的相似度,而传统的哈希图像检索模型在相似度计算阶段采用的是以输入图像的哈希码与整个数据库数据的哈希码逐个比对的方法,因此本文模型所需要计算的数据量远小于传统的哈希图像检索模型,极大加速了检索的进程.
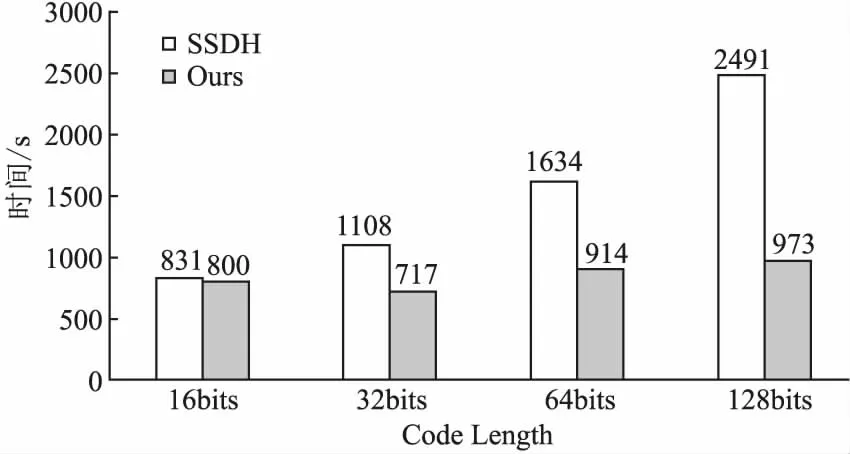
图3 与SSDH模型时间开销的对比
3.4 消融实验
为了证明创新部分的有效性,对于创新的部分,进行了如下消融实验,如表3所示,其中E表示模型中没有CBAM与随机优化乘积量化模块,E + CBAM表示模型中没有随机优化乘积量化模块,Ours表示加入CBAM与随机优化乘积量化模块.
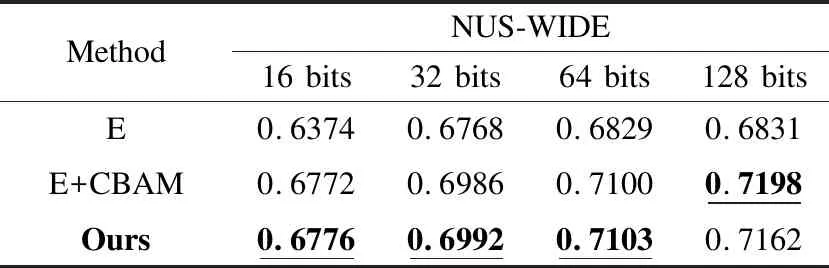
表3 消融研究对比
从表3可以看到,加入CBAM的模型相较于基本模型的mAP值在16bits、32bits、64bits、128bits分别增加了3.98%、2.18%、2.71%、3.67%,本模型相较于基本模型的mAP值在16bits、32bits、64bits、128bits分别增加了4.02%、2.24%、2.74%、3.31%.在小bits位的实验中,mAP值最高的是加入了CBAM与随机优化乘积量化的模型,这是因为CBAM在可以有效的增强提取特征的语义信息,使特征拟合效果更好,在相似度计算时可以提高精度,同时加入的SOPQ模块,会在小幅度提升精度的同时大幅加速高bits位的检索速度,这是因为SOPQ算法在进行检索时会剔除大部分无关的数据,能在提升精度的同时大幅度加速检索的进程.同时可以发现在128bits时加入随机优化乘积量化的模型,结果会略低于直接添加CBAM的模型,这是因为随着bits的增大,乘积量化的量化损失被相应的扩大,导致模型的精度低于本来的精度.因此,通过上述结果分析说明CBAM对特征的语义增强有较好的效果,同时结合图3中的实验结果,可以得出随机优化乘积量化可以在低bits位时小幅度提升精度的情况下,极大的加速的检索的进程,减少了检索的时间.
4 结 论
针对无监督相似性图像检索中的特征语义性不足,以及乘积量化中的K-means的局部最优解的问题,提出了一种基于CBAM的无监督随机优化乘积量化图像检索模型.模型使用基于CBAM的卷积神经网络无监督的自学习图像特征,然后通过随机优化乘积量化算法对图像特征进行量化得到对应的码书.在大规模数据集NUS-WIDE上,通过与其他模型的实验结果比较分析,表明本模型检索精度有所提高,同时,大大减少了检索所需时间.通过本模型检索,无需提供有标签的原始图片,且训练过程无需图片标签参与,因此,适用于图片爆发增长的大数据时代,对于大规模图像检索有一定的实际应用意义.
猜你喜欢
小学生学习指导(中年级)(2021年3期)2021-04-06
学生导报·东方少年(2019年23期)2019-12-30
意林图解作文(小学版)(2019年6期)2019-07-16
数学年刊A辑(中文版)(2018年1期)2019-01-08
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
专利代理(2016年1期)2016-05-17
噪声与振动控制(2015年4期)2015-01-01
数学年刊A辑(中文版)(2014年2期)2014-10-30
轴承(2010年2期)2010-07-28
