
基于近红外光谱的棉花毛籽蛋白质和油分含量快速检测
2023-08-23 07:42马怡婷李鲁侨石钇琦尹红赵天伦陈进红祝水金
棉花学报 2023年3期
马怡婷,李鲁侨,石钇琦,尹红,赵天伦,陈进红,祝水金
(浙江大学农业与生物技术学院/ 浙江省作物种质资源重点实验室,杭州 310058)
棉花纤维是重要的纺织、医疗和军工原料,棉花副产品也是重要的再生资源。棉籽是棉花生产中的重要副产物,每生产1 kg 棉花纤维就会产生1.65 kg 棉籽[1]。棉籽中含有大量的油和蛋白质,分别占棉仁质量的27.83%~45.6%和28.24%~44.05%。因此,棉籽是重要的植物蛋白资源和油料资源[2]。
棉籽蛋白约含90%球蛋白,组成近似于豆类蛋白,营养价值远高于谷物蛋白[3]。因棉籽中蛋白含量高,浸提棉籽油后剩余的棉籽粕可用作动物的蛋白饲料,并广泛应用于食品和发酵行业[4-5]。棉籽蛋白具有优良的成膜溶解性和热加工能力,通过溶液浇注或热压成型方法可将其加工成生物降解塑料,有巨大的利用潜力[6-7]。棉籽仁中油分含量高,提炼出来的棉籽油是重要的优质食用油之一,富含油酸和亚油酸等不饱和脂肪酸,有助于降低血脂和血压[8-9]。
棉籽营养成分的分析对棉花育种、生产以及棉籽产品加工均具有重要的指导意义。目前棉籽油分含量的测定主要采用索氏提取法和气相色谱法,测定总蛋白质含量主要采用凯氏定氮法等化学检测方法[10]。传统的检测方法虽然精确度和灵敏度都较高,但存在费时、费力、检测成本较高且损耗样品等问题。近红外光谱分析技术具有简单快速、无污染、低成本、无损伤、多指标等优点,更适合于大规模样品的无损检测。该技术已广泛应用于农业、医药、食品、林业和能源等领域[11-12]。在棉籽营养品质性状研究中,近红外光谱分析技术也成功应用于水分、棉酚、植酸、蛋白质、油分、氨基酸和脂肪酸含量的校正模型的构建。
汪旭升等[13]、Quampah 等[14]构建了棉仁粉油分含量的近红外光谱校正模型,秦利等[15]建立了棉仁粉总蛋白含量的校正方程,均取得理想效果。然而,这些研究都是基于棉仁粉的快速分析,分析前需要经过硫酸脱绒、剥壳、研磨粉碎等处理。棉籽整粒的蛋白质和油分含量的近红外光谱分析检测也取得了长足进展,韩智彪等[16]、商连光等[17]建立棉籽油分含量近红外光谱无损检测分析模型,徐鹏等[18]、Huang 等[19]和王庆康[20]建立的光籽油分和蛋白质含量的近红外光谱无损检测分析模型也达到了比较好的预测效果,但均以硫酸脱绒后的光籽为对象。棉籽硫酸脱绒成本高,常影响种子生活力,并易污染环境。因此,建立棉花毛籽蛋白质、油分含量的近红外光谱分析模型具有更重要的实践意义。
近红外光谱检测技术的核心是定量校正模型,选择合适的建模方法能够很大程度地优化近红外光谱检测模型[21]。本研究分别采用支持向量机(support vector machine,SVM)[23]、随机森林(random forest,RF)[24]和线性偏最小二乘法(partial least square method, PLS)[25]3 种建模方法建立蛋白质和油分含量的校正模型,为棉花毛籽蛋白质和油分含量的估测提供一种快速、无损、低成本的分析方法,用于棉花毛籽品质的快速精确评价,为棉花种子品质育种研究、棉籽营养成分评价技术优化和相关检测仪器设备的研发提供技术支持。
1 材料与方法
1.1 试验材料
2020 年将本实验室多年自交保存的426 份陆地棉品种资源种植在海南省三亚市崖州区,以收获的成熟种子为试验材料。为保证样品的均一性和稳定性,采用开水烫种法精选棉花毛籽。将毛籽用开水浸烫并搅拌1 min (水温90 ℃左右)后,加入3 倍体积的凉水搅拌均匀(最终水温40 ℃左右),挑选深褐色和深棕红色的健籽于38~40 ℃烘干,水分平衡2 d 后,放入密闭容器中备用。
1.2 近红外光谱采集
利用NIRFlex-N500 傅立叶变换近红外光谱仪(瑞士步琦公司)采集挑选的棉籽样品的光谱图,采集光谱的波数范围为4 000~10 000 cm—1,每4 cm—1采集反射强度(reflection, R),共计1 501 个光谱点,重复扫描64 次后取平均值。每份棉籽样品分3 次装入测量池中,保证每次待测样品上样的紧实度相近,扫描均在25 ℃±0.5 ℃条件下进行。扫描后获取光谱数据,计算每份样品的3 次光谱数据的平均值,并将反射强度转化为lg(1/R),得到棉籽样品的原始光谱图。
1.3 样品蛋白质和油分含量参考值测定
将上述完成光谱扫描后的样品,进行浓硫酸脱绒,水分平衡2 d 后,放入密闭容器中备用。利用FOSS 多功能近红外分析仪NIRS DS 2500 进行扫描,近红外光谱分析仪的采集波长范围为400~2 500 nm,本研究采用的数据是波长1100~2 498 nm 范围内光谱数据, 数据间隔为2 nm,测样方式为漫反射,仪器类型为光栅扫描型。样品杯装满棉籽后,用压块压实后进行扫描,每个样品测定2 次,扫描获得所有样品的近红外光谱。得到的光谱数据经过预处理之后代入Huang等[19]建立的整粒棉籽(光籽)油分含量和蛋白质含量的近红外光谱校正模型,得到蛋白质含量和油分含量,作为参考值。
1.4 样品集划分
采用光谱- 理化值共生距离算法(sample set partitioning based on joint X-Y distance sampling,SPXY)[22]按照3∶1 的比例将样品划分为包含320 个样本的校正集和包含106 个样本的预测集。SPXY 算法是由Galvao 等[22]首先提出的,从经典的Kennard-Stone(KS)算法扩展而来,SPXY将光谱和理化值特征参数一起考虑来计算样品之间的距离,保证最大程度描述样本分布,有效地覆盖多维向量空间,增加样本间的差异性和代表性,提高模型稳定性。
1.5 样品原始光谱预处理
光谱预处理用Unscrambler V9.7(CAMO,挪威)软件。用Savitzky-Golay(SG)平滑法、一阶导数(first derivative, 1D)、二阶导数(second derivative, 2D)、变量标准化(standard normal variate,SNV)、多元散射校正法 (multiplicative scatter correction, MSC)、基准化(baseline)、去趋势化(detrend)中的1 种或几种结合的方法对原始光谱数据进行预处理,以消除干扰信息。
1.6 建模方法及评价指标
采用SVM、RF 和PLS 3 种方法建立校正模型进行对比分析。采用Matlab R2021a 软件进行近红外光谱校正模型的构建和检验。
通过预测决定系数(coefficient of determination,R2)、均方根误差 (root mean square error,RMSE)和剩余预测偏差(residual prediction deviation,RPD)评价模型。其中,预测决定系数和剩余预测偏差值越大,均方根误差值越小,模型的预测性能和稳健性越好。RPD 是预测集的样本标准差与均方根误差的比值。
1.7 未精选棉花毛籽的蛋白质含量和油分含量的近红外光谱分析
选取1.1 试验材料中的118 份陆地棉材料,手工去除杂质后(即不进行开水烫种精选棉花毛籽)按照1.2 的方法采集近红外光谱数据,利用1.4 中的SPXY 算法将118 份材料按照3∶1 的比例划分为包含89 个样本的校正集和包含29个样本的预测集,按照1.6 的方法构建近红外光谱校正模型,与精选棉花毛籽的模型进行比较,研究开水烫种精选棉花毛籽对蛋白质和油分含量近红外光谱快速分析的作用。
2 结果与分析
2.1 棉花毛籽原始近红外光谱图分析
对426 份棉花毛籽样品进行近红外光谱扫描,得到原始光谱图(图1)。可以看出,光谱曲线整体较为平滑均匀,在4 000~10 000 cm—1全光谱范围内,426 份棉籽样品光谱的变化趋势基本保持一致,在4 760 cm—1、5 200 cm—1、6 800 cm—1和8 280 cm—1附近有明显的吸收峰。虽然在未经任何预处理的原始光谱中很难直接判断出光谱是否存在噪声信息,但是可看出原始光谱中存在一定的基线漂移和基线偏移。
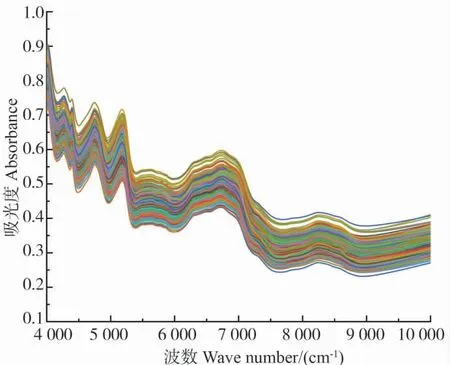
图1 整粒棉花毛籽原始近红外光谱图Fig.1 The original NIR spectra of the cottonseed
2.2 样本蛋白质和油分含量数据集适用性分析
采用SPXY 方法,分别以1.3检测的蛋白质含量或油分含量为y变量,近红外光谱值为x变量,将样本划分为包含320 个样本的校正集和包含106 个样本的预测集,校正集和预测集的蛋白质含量和油分含量的统计值如表1 所示。可以看出,棉花毛籽中蛋白质含量平均为44.616%,变化范围为30.107% ~56.776%,油分含量平均为32.399%,变化范围为24.260% ~41.768%,说明样本集中样品蛋白质和油分含量分布范围广。校正集样本的蛋白质含量和油分含量范围涵盖了预测集样本的含量范围,并且均存在较广泛的变异,说明样品集划分合理,有助于建立稳健可靠的预测模型。
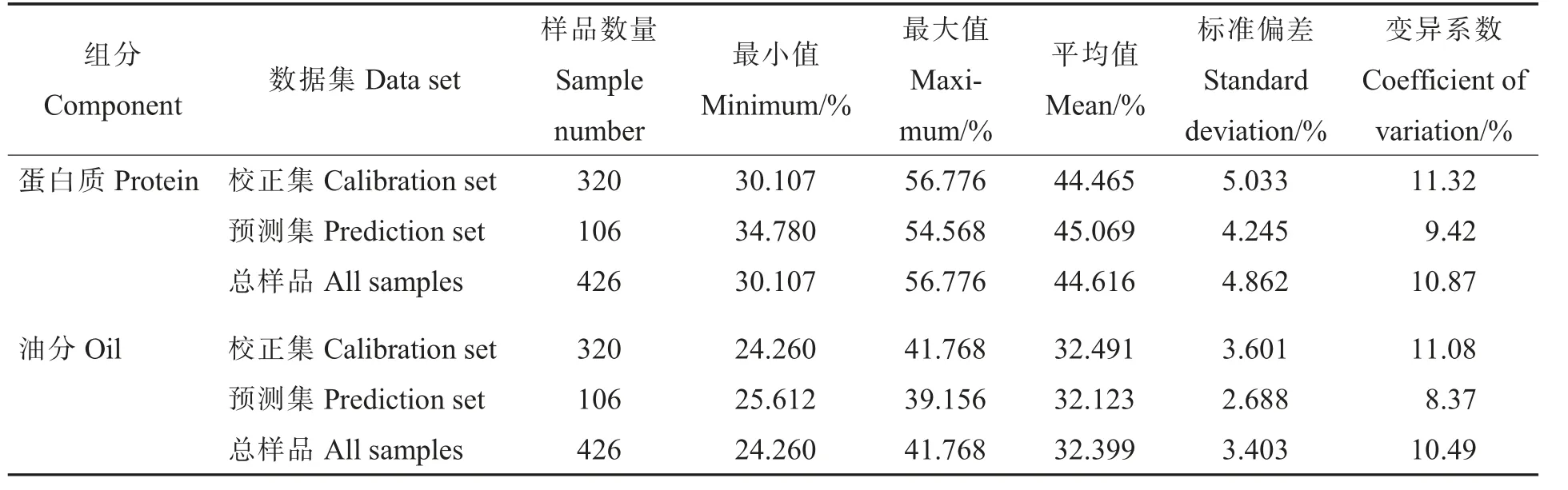
表1 校正集和预测集的蛋白质含量和油分含量的统计值Table 1 Statistical values of protein contents and oil contents for both calibration and prediction sets
2.3 光谱预处理效果对比
针对光谱样本数据的消噪和基线校正需求,分别采用SG 平滑、SNV、MSC、一阶导数、二阶导数、基准化和去趋势化等单独或组合共10 种方法对光谱数据进行预处理,并以PLS 算法构建模型评价光谱预处理的效果结果见表2、表3。可见,预处理可以消除光谱中部分无效信息,使构建的校正模型参数较未处理的模型参数有不同程度提升,提高了模型的预测性能。其中,经MSC+1D 预处理后构建的棉花毛籽蛋白质含量校正模型和经MSC 预处理后构建的棉花毛籽油分含量校正模型表现较好,本研究中棉花毛籽蛋白质含量建模采用MSC+1D 预处理,油分含量建模采用MSC 预处理。
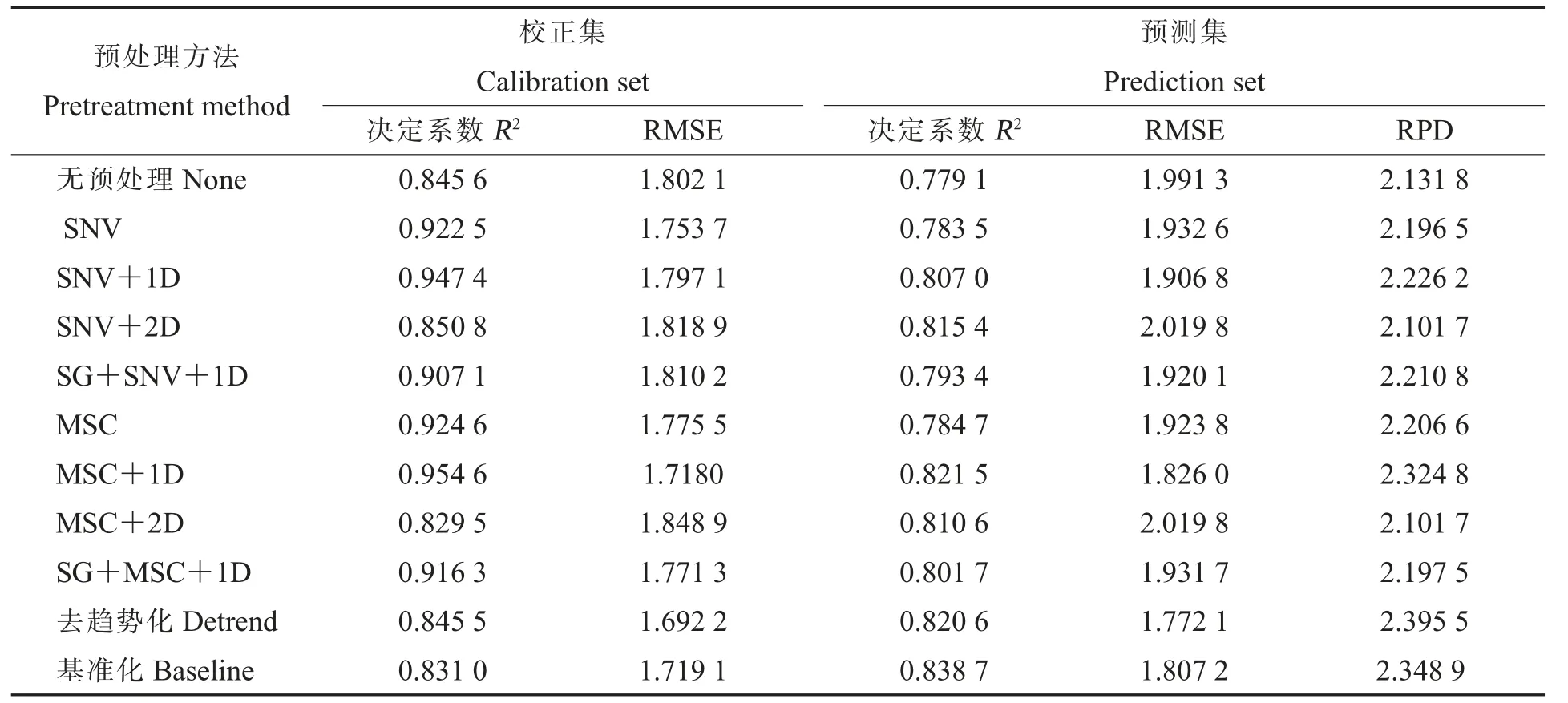
表2 不同预处理后基于PLS 建立的棉花毛籽蛋白质含量模型的参数Table 2 Parameters of protein PLS model for fuzz cottonseed established by different pretreatment methods
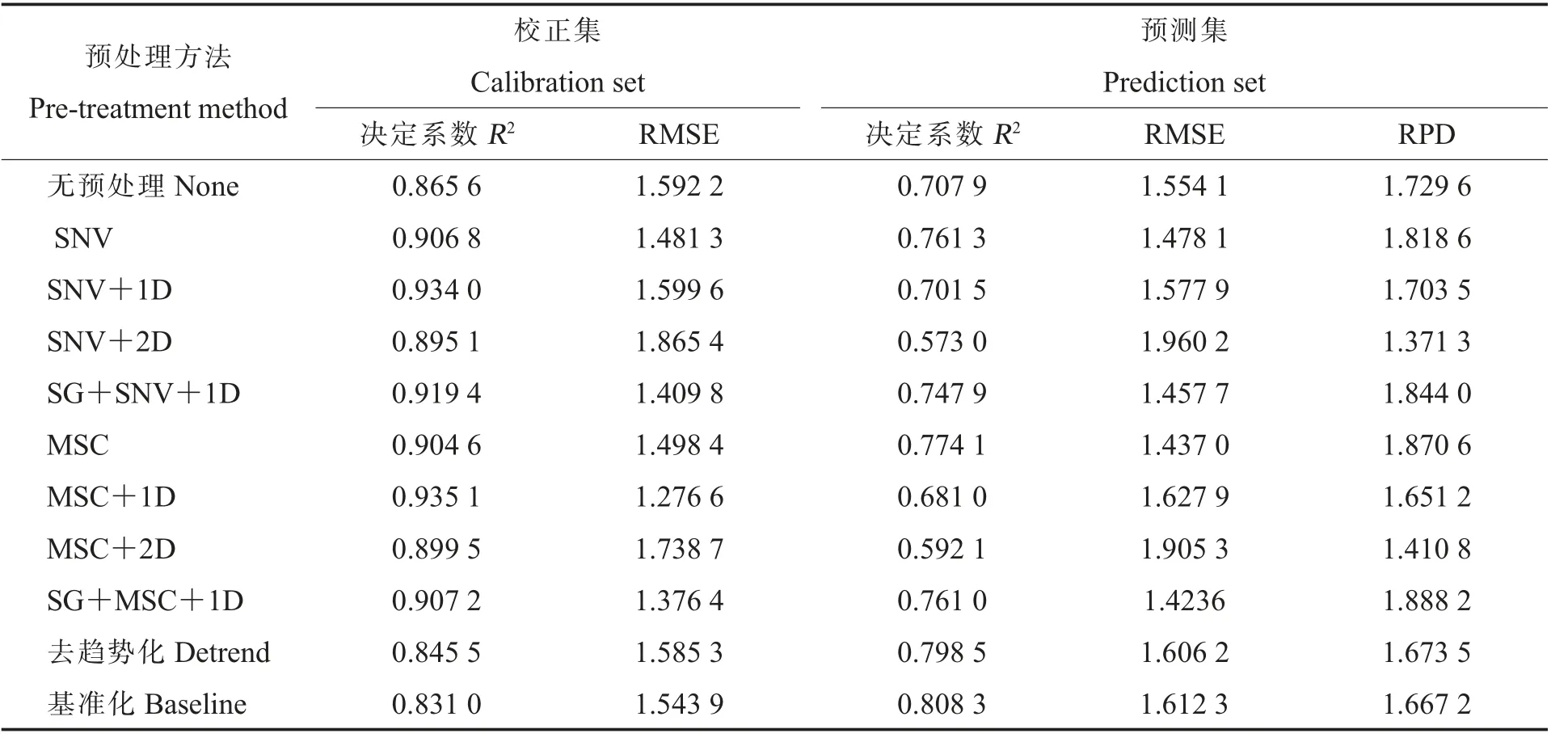
表3 不同预处理后基于PLS 建立的棉花毛籽油分含量模型的参数Table 3 Parameters of oil PLS model for fuzz cottonseed established by different pretreatment methods
2.4 蛋白质和油分含量的不同建模方法性能比较结果
利用SVM、RF 和PLS 方法分别建立棉花毛籽蛋白质含量和油分含量的预测模型,模型的相关评价指标见表4。在蛋白质含量和油分含量预测中,PLS 模型和SVM 模型在校正集的拟合效果较好,决定系数均大于0.8,但是在预测集的拟合效果不理想,都存在过拟合的现象;RF 模型在校正集和预测集的拟合效果都非常好,决定系数均大于0.9,预测集剩余预测偏差均大于3,模型的泛化能力强。说明基于RF 方法建立的预测模型能较好地应用于近红外光谱检测棉花毛籽蛋白质含量和油分含量。基于近红外光谱利用RF法构建的棉花毛籽蛋白质含量和油分含量的校正模型的预测值与真实值之间的相关性如图2~3,可以看出,大多数样本点均匀地分布在对角线上或两侧,说明该模型具有较好的预测效果,可以替代传统的化学测定方法。
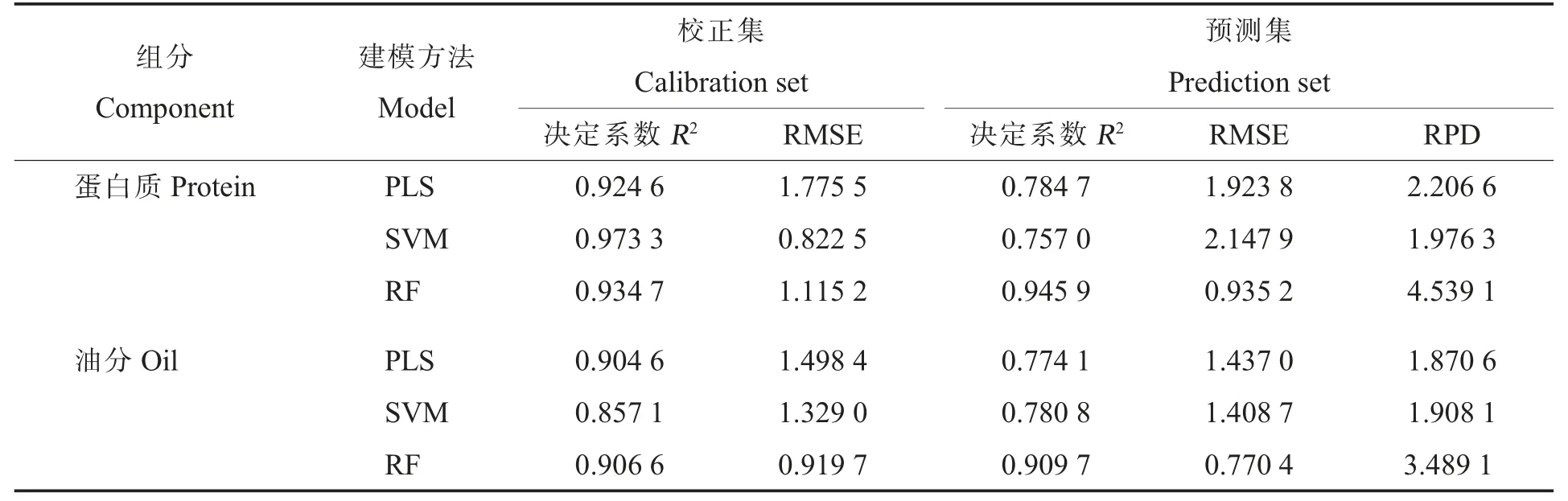
表4 棉花毛籽蛋白质含量和油分含量不同校正模型的评价指标比较Table 4 Comparison of different models for protein content and oil content in cottonseed with fuzz

表5 校正集和预测集的未精选棉花毛籽蛋白质和油分含量统计值Table 5 Statistical values for protein content and oil content of unselected cottonseed with fuzz in the calibration set and prediction set

图2 基于RF 模型的棉籽蛋白质含量的预测值与参考值的相关性Fig.2 The correlation between predicted value of RF model and reference value of protein content in cottonseed
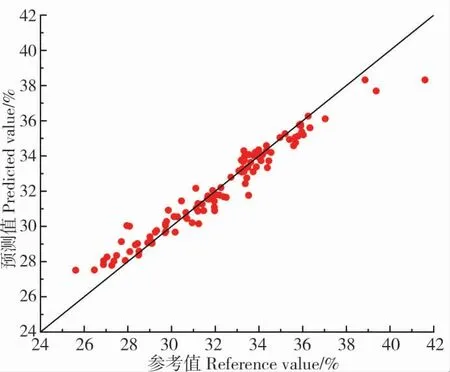
图3 基于RF 模型的棉籽油分含量的预测值与参考值的相关性Fig.3 The correlation between predicted value of RF model and reference value of oil content in cottonseed
2.5 未精选棉花毛籽的蛋白质含量和油分含量的近红外光谱分析
118 份未精选棉花毛籽样品中蛋白质含量为33.171%~56.776%,平均为41.097%,标准偏差为3.712%,变异系数为9.03%;油分含量为26.136%~40.769%,平均为33.650%,标准偏差为2.923%,变异系数为8.68%。校正集样本的蛋白质含量、油分含量范围涵盖了预测集样本的含量范围,样品集划分合理,可以用来建立预测模型。
未精选棉花毛籽的蛋白质含量建模采用MSC+1D 预处理,油分含量建模采用MSC 预处理。将预处理后的光谱数据作为输入变量,分别采用SVM、RF 和PLS 方法建立的蛋白质含量和油分含量的模型评价指标见表6。相比精选棉花毛籽的建模结果,未精选棉花毛籽的建模效果大幅度下降,其中蛋白质含量和油分含量的RF 模型在预测集的决定系数分别下降了22.99%和25.52%。说明开水烫种法精选对于毛籽蛋白质含量和油分含量的近红外光谱建模效果有明显提升作用。

表6 未精选棉花毛籽蛋白质含量和油分含量的校正模型的评价指标比较Table 6 Comparison of models for protein content and oil content of unselected cottonseeds with fuzz
3 讨论
轧花后的棉籽常带有短绒,用浓硫酸脱去短绒的棉籽称为光籽,剥去种壳后的棉仁磨成粉为棉仁粉。传统的检测方法是对棉仁粉进行化学测定,其中蛋白质含量测定采用凯氏定氮法,油分含量测定采用索氏抽提法,这些方法测定时间长,对仪器设备要求高,测定成本高,且会破坏样本、无法再用于其他研究,特别是棉花育种相关研究。近红外光谱技术已普遍应用于多种作物种子相关性状的快速测定[26-30],在棉籽中成功地实现了棉仁粉和光籽的营养成分含量建模和测定[15-20]。然而,无损的光籽也需进行浓硫酸脱绒处理,而棉籽脱绒费时费力,容易污染环境,且可能影响种子活力。因此,基于近红外光谱无损快速地检测棉花毛籽的营养品质更具有实用价值。
近红外光谱建模的基础是样本的实际含量。黄庄荣[10]建立的光籽蛋白质和油分含量快速测定法,其近红外光谱校正模型中预测集的决定系数分别为0.959 和0.950,剩余预测偏差分别为4.871 和4.429,预测精度高、稳定性好,完全可以代替化学方法测定的蛋白质和油分含量。本研究采用Huang 等[19]的方法对棉花选光籽样本进行测定,蛋白质含量为30.107%~56.776%,平均为44.616%;油分含量为24.260%~41.768%,平均为32.399%,与Huang 等[19]测定的棉籽样本蛋白质含量和油分含量数据大致相同。
利用近红外光谱测定棉花毛籽营养成分的困难在于棉籽较大,在填充样品时不可避免地留有很大的空隙,而且其坚硬的外壳和紧密的短绒影响光的穿透,且肉眼难以识别未成熟的种子和干瘪的种子。以上因素都给近红外光谱数据带来了大量无用的干扰信息,导致信噪比降低,影响建模效果,降低预测精度。为了克服这些困难,本研究采用开水烫种法挑选健籽,既不影响种子的完整性又能保证种子活力,采用MSC 或MSC+1D 预处理后,有效减少材料本身、测量环境、操作等对光谱数据的影响,提取保留了有效信息。
本研究中未精选棉花毛籽的近红外光谱校正模型效果都不理想,和精选毛籽的建模结果差距较大。这主要因为开水烫种法精选饱满成熟的种子,降低了均匀度、饱满度、短绒对光谱采集的影响,剔除了近红外光谱数据中夹杂的部分噪声、光散射等干扰信息。说明开水烫种法精选是棉花毛籽近红外光谱建模过程中至关重要的一步,这为棉花毛籽其他营养品质的近红外光谱快速分析提供借鉴。常规的棉籽精选都是在硫酸脱绒后进行光籽筛选,会破坏种子的完整性,本研究采用开水烫种法挑选健籽,可保证种子完整性和活力,不会影响后续播种,且简单、直观、速度快。
棉花毛籽化学成分组成丰富,近红外光谱中包含其他的化学组分信息,数据复杂且重叠,含有较多非线性信息、噪声和异常值。RF 法可以充分利用线性的和潜在的非线性信息进行建模,对异常值和噪声具有很好的容忍度,模型泛化能力强,预测准确率较高且不容易出现过拟合[31]。PLS法不考虑光谱数据与化学成分之间的非线性关系,只根据光谱数据与化学成分之间的线性信息预测输出,非线性信息数量较多,就容易导致模型过度拟合。而当优化参数选择不正确、光谱数据不均匀时,SVM 法也可能会出现过拟合的问题,对大数据样本的模型泛化能力不理想。本研究比较了基于上述3 种方法构建的模型在近红外光谱检测棉花毛籽蛋白质和油分含量中的效果,结果显示基于RF 法建立的预测模型效果最好。因此,综合考虑模型的适配度和准确性,RF模型更适用于棉花毛籽蛋白质含量和油分含量的快速检测。
4 结论
本研究利用开水烫种法筛选成熟饱满的棉籽(毛籽)采用SPXY 算法对样品集进行划分,分别运用MSC 和MSC+1D 的预处理方法,基于RF 法构建了棉花毛籽中蛋白质含量和油分含量的近红外光谱校正模型,模型的决定系数大于0.9,预测集的均方根误差小于1、剩余预测偏差大于3,能较好地用于棉籽蛋白质含量和油分含量的近红外光谱检测,可替代传统方法。研究结果不仅可为棉花种子品质育种和棉籽加工、生产与销售中营养成分估测提供了1 种绿色高效的快速评价方法,还可为其他作物种子营养成分的无损分析提供技术借鉴。
猜你喜欢
机械工程师(2021年6期)2021-06-18
——全棉籽的加工与利用
中国畜牧杂志(2020年8期)2020-12-18
华北农学报(2020年4期)2020-08-29
国学(2020年1期)2020-06-29
陕西农业科学(2019年11期)2019-12-25
科学与财富(2019年15期)2019-10-21
数学物理学报(2017年6期)2018-01-22
摄影之友(影像视觉)(2017年1期)2017-07-18
山西农业科学(2016年1期)2017-01-05
中国棉花加工(2016年5期)2016-12-09
