
移动机器人声源定位与跟踪摄录系统开发
2023-08-22 07:47王一群李兴旭杨鸿波陈雯柏
实验室研究与探索 2023年5期
王一群,李兴旭,杨鸿波,刘 琼,陈雯柏
(北京信息科技大学自动化学院,北京 100096)
0 引 言
机器人听觉系统是一种利用声学传感器采集声音信号与外界环境完成感知与交互的方式。声源定位是指利用声音信号,经过处理和计算获得声源位置的技术。由于声音信号和光信号存在着本质上的区别,机器人听觉系统在障碍物遮挡、能见度低等不利于视觉系统的工况下仍可有效工作,常独立或辅助机器人视觉系统完成定位、导航、避障等工作[1]。
对于发声目标检测应用,基于声音信号相比图像方法,有着先天优势,常用于军事、工业和日常生活。如对汽车违法鸣笛抓拍[2-4],车辆与飞机等通过噪声来源定位[5-7],工业异常工件检查[8-9],管道气体泄漏点检测[10],智能监控[11]。上述声源定位应用中的传感器阵列多为固定安放,传感器位置移动中追踪声源的研究较少。
本文将设计一种通过声音信号实现跟踪拍摄的轮式机器人,并在室内室外进行机器人追踪声源功能试验,分析性能与抗干扰能力,为机器人听觉系统相关研究提供参考。
1 系统整体设计
1.1 研究背景
图1 所示为常用目标跟随拍摄方式,而目前市面上支持目标跟随拍摄的智能设备主要分固定式[见图1(a)]和手持式[见图1(b)]2 种。固定式云台因位置固定,限制被拍摄者仅能在小范围内移动。手持式云台需要借助人力完成跟随。近年来无人机航拍(图1(c)成为摄影师们的新宠,但仍存在着无法室内使用、成本高昂、续航时间短和噪音大等问题。因此,成本低廉的轮式跟随拍摄机器人存在一定市场。

图1 常用目标跟随拍摄方式
1.2 系统架构
本文提出的移动机器人声源定位与跟踪摄录系统主要分为音视频采集、目标检测和控制跟随3 个部分。音视频采集部分调用硬件设备(麦克风阵列、摄像头)获取并保存音频和数字图像信号,以供后续算法使用。目标检测通过基于到达时间差的声源定位方法(Time Difference of Arrival,TDOA)实现,完成对发声目标位置的解算,包含2 个步骤:①估计目标所发出声音到不同麦克风之间的时间差,再根据时间差和几何关系解算出发声目标相对于麦克风阵列的位置;②控制跟随部分将利用解算出的位置信息,控制舵机与电动机工作使小车靠近且跟随目标移动。
2 声源定位算法
常见的声源定位算法有基于最大输出功率的可控波束形成定位方法(Steered Beamforming,BS)、基于高分辨率估计的定位方法(High Resolution Spectral Estimation,HRSE)和TDOA。
本文考虑到机器人跟踪发声目标属于近场模型,且硬件计算能力有限,因此选择使用TDOA。
2.1 基于到达时间差的声源定位算法
处于不同位置的2 个麦克风接收到来自声源的声音信号,如图2 所示。各麦克风接收到的音频信号x1(t)和x2(t)由下式表示:

图2 声源与各麦克风空间位置关系示意图
式中:S为声源信号;m1与m2为在不同时刻到达各麦克风且带有加性噪声;t为传播时间;τ1和τ2分别为声源到达2 个麦克风的延迟时间。由式(1)可得麦克风之间的时延
通过测量获得传感器间距L,结合τ 与t,可计算出声音在空气中传播的方向:
式中:c为声音在空气中的传播,本文取c=340 m/s;β为智能车作极坐标中心面对两个声源的中心线的夹角,正值表示声源在车左侧,反之则在右侧。
TDOA算法将声源定位的问题转化为求不同麦克风接收时延的问题,时延估计的精度将直接影响到声源定位的精度。
2.2 时延估计
时延估计(Time delay estimation,TDE)方法中得到最广泛应用的是广义互相关算法(Generalized Cross Correlation,GCC)和自适应最小均方法(Least Mean Square,LMS)[12-13]。考虑到机器人对实时性的要求,本文选择了计算量较小且能保证一定精度的GCC 方法。广义GCC表达式如下:
式中:Ψ12(ω)为加权函数;Gx1x2(ω)为信号互功率谱。
2.3 语音端点检测
端点检测是指从一段音频信号中确定目标声音信号的起始点和结束点位置,利用语音端点检测只对有目标声音的信号片段进行处理,可以减少数据输入及系统的运行时间,并抑制噪声对系统的干扰。
端点检测常用方法有短时能量法、谱质心和频谱扩展度法等[14]。其中,短时能量法是在时域层面进行端点检测,有着运算量小、简单易理解的优点,适合本次实验。
采集N帧语音信号,计算第i帧语音信号yi(n)的短时能量
式中,yi(n)为当前时刻采样的数值,其中n=1,2,…,l,l为帧长。
当前音频信号短时能量大于所设定的阈值时即可认为环境中存在目标,阈值的选择直接影响到静音检测的效果。图3 中蓝色区域是由算法判断存在语音的区间。若阈值设定过低,算法易受噪声干扰产生误判,如图3(a)多数片段被判定为存在语音;若阈值设置过高,部分音量较小的语音信号片段会被漏判。
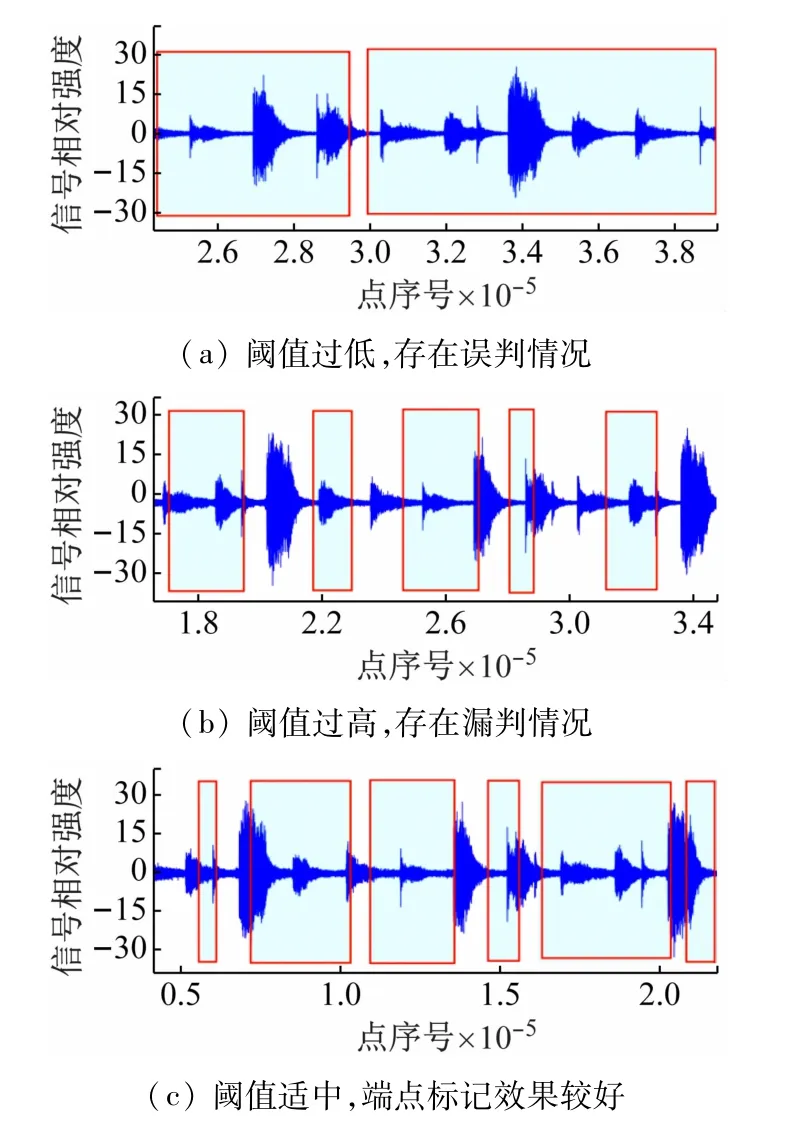
图3 不同阈值的语音端点检测效果比较
3 实验部分
3.1 平台搭建
(1)主控板。本文搭建的设备主控板采用德州仪器公司的工业派(见图4),包含AM5708 处理器、C66x系列数字信号处理器(DSP)和丰富的接口,适合作为本次设计的实验平台进行算法验证、功能测试、应用开发等环节。
图4 主控板
(2)麦克风阵列。选择T型四声道麦克风阵列采集声音信号,该麦克风阵列顶部有3个麦克风处在同一水平线上、间距6 cm,底部有1 个麦克风,如图5 所示。顶部3 个麦克风也可在实验中单独作为线型麦克风阵列使用,以简化实验实现流程[15-16]。麦克风信噪比为59 dB(A),灵敏度为-22 dBV/Pa,最大输出阻抗为400 Ω。实验背景的短视频录制、主直播等应用场景一般要求距离摄录设备8 m内、移动缓慢和持续发声、T型麦克风阵列的精度能够满足设计需求。

图5 基于麦克风阵列的跟随摄录设备实物
(3)运动底盘。系统使用TI-RSLK 机器人套件,运动底盘结构为前轮舵机转向-后轮电动机驱动形式,轮径68 mm。直流电动机采用脉冲宽度调制(Pulse Width Modulation,PWM)波调整转速,带有AB 相编码器,减速比1∶20。电池组由18 650 节锂电池及充放控制板组成,额定电压12 V,额定容量10 000 mAh,能够满足长时间的供电要求。
3.2 软件设计
使用多线程技术、(ARM+DSP)异构架构完成程序设计,程序交叉编译后以应用的形式运行在板卡上的Linux-Rt系统中。主任务循环中对输入数据进行静音检测、声源定位运算,并根据解算方位结果通过比例导数(Proportional Derivative,PD)控制算法控制运动底盘向目标移动。程序结构如图6 所示。

图6 程序结构框图
(1)声源定位实现。TDOA算法的程序实现主要分2 步:①TDE,即用互相关算法估计声源信号到达麦克风阵列中各麦克风的时间差;②根据τ,按照几何关系解算出声源目标关于麦克风阵列的方位信息。
主进程中创建一个线程调用Linux pcm模块完成对多声道音频信号的采集,将连续的模拟信号转为离散数字信号存储在缓冲区,等待运算线程读取作为后续算法输入并保存为WAV 格式音频文件。针对语音信号频率特点和对硬件性能的综合考虑,设置采样频率f为44.1 kHz,取2 048 个采样点为一帧,即帧长l=2 048。
互相关算法的程序实现流程如图7 所示,将2 个含有各时间点音频信号幅值的数组通过离散傅里叶变换转换至频域进行共轭运算再加权求和得到中间结果,通过傅里叶反变换获得结果数组H(j),j=1,2,…,2l。通过程序查找,获得结果数组中峰值Hmax及自变量j的值a:

图7 互相关算法软件实现流程
以s为单位的时延τ的计算式如下:
式中:r为算法获得的时延结果值;f为采样率。
算法计算获得时延数值结果r=-5 时,经计算时延τ 约为-11.338 μs,表明声音先到达右侧麦克风。根据(3)式,2 个麦克风间距L为6 cm,可获得目标β=-18.737 9°(右侧)。
为了更好地利用硬件资源、提升实时性,将端点检测算法放在DSP 核心中进行,并将最终结果回传到ARM端。
(2)控制跟随。由于舵机硬件特性,控制过程中不存在累积误差,所以本实验中简化PID 控制算法中的积分项,采用PD 控制器控制舵机转角实现跟随任务,即:
式中,out 为控制器的输出值;Kp与Kd分别为控制器的比例与微分系数;err为本次角度误差;err_last 为上次计算周期所得误差。
在控制中,目标值将一直设置为0(即期望控制车体始终正对前方的发声目标)。out 通过线性变化后为当前时刻舵机的控制量即PWM 占空比值,用于控制舵机和电动机。
4 验证与分析
4.1 时延估计对比测试与分析
实验中选择经典GCC 算法(即Ψ12(ω)=1)与GCC-PHAT算法作对比。在声源位置固定相距麦克风阵列右侧15°距离3.5 m、室内环境下,经典GCC 和GCC-PHAT实测计算结果见表1 所列。

表1 经典GCC和GCC-PHAT实测计算部分结果
由表1 可见,GCC-PHAT的计算结果稳定,数值主要集中在-4 附近;而经典GCC 的r值在-650~1 697之间浮动,无法表征目标的准确位置,其结果误差大。主要是经典GCC算法对噪声敏感,在低信噪比条件下的互相关结果会出现峰值不集中且相对真实值偏移的现象。而GCC-PHAT 算法的误差主要来源于环境中其他噪声的干扰,当目标声源并未发声时(例如人说话过程中会有间断),将不含语音音频信息的环境声作为声源定位系统的输入,导致无法获得正确的目标声源定位结果,这也体现了增加语音端点检测处理环节的必要性。
4.2 场景测试与分析
在多个场景中用自然人声和蓝牙音箱(型号coowoobs100)播放说书音频作为声源,距离小车2~6.5 m 情况下测试,如图8 和9 所示。环境中存在的噪声类型有:大型空调外机运行噪声、人群活动声、汽车驶过的噪声还有来自自身通过固体传导形式到达麦克风阵列的舵机电动机噪声。系统测试结果见表2 所示。测试得出,基于TODA 和GCC-PHAT 算法的声源定位方案具有一定的抗干扰能力。

表2 测试结果总结

图8 多场景测试实拍

图9 小车视角画面
5 结 语
本文提出的移动机器人声源定位与跟踪摄录系统设计能够多个场景下根据声音信号完成跟随和拍摄,并经实验测试。结果表明,该实验系统支持720p(30f/s),480p(60f/s)录像及48K 四声道音频;能在8 m远进行跟随;平均单次采集时间仅为8.5 ms。可满足短视频博主等对低成本、可移动的跟随摄录设备的需求,具有一定的实用价值,可为基于机器听觉的各种机器人环境感知和交互研究提供参考。
同时,实验可作为教学设计,有助于提升自动化类专业学生对“信号与系统”“数字信号处理”“自动控制原理”等专业知识的综合应用能力、独立解决工程问题的能力和创新实践能力,为面向多学科融合的自动化类人才的培养奠定基础。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
复旦学报(自然科学版)(2019年3期)2019-07-19
电子制作(2019年23期)2019-02-23
电子测试(2018年23期)2018-12-29
测控技术(2018年6期)2018-11-25
小学科学(2016年12期)2017-01-06
噪声与振动控制(2016年5期)2016-11-09
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
做人与处世(2015年19期)2015-09-10
