
融合迭代和问题维度的速度约束粒子群算法
2023-08-21 00:51王子航刘建华薛醒思陈宇翔
华东交通大学学报 2023年4期
王子航,刘建华,薛醒思,朱 剑,陈宇翔
(1.福建工程学院计算机科学与数学学院,福建 福州 350118;2.福建工程学院福建省大数据挖掘与应用技术重点实验室,福建 福州 350118)
粒子群优化算法 (particle swarm optimization,PSO)最初是由Eberhart 等[1]和Kennedy 等[2]于1995年提出,通过模拟动物群体的社会行为,比如鸟群的捕食行为,构建一种群体智能优化算法。与其他遗传算法[3]和蚁群算法[4]等智能算法相比PSO 算法具有实现简单且收敛速度快的优势,广泛应用于很多领域,比如函数优化[5],神经网络训练[6],轨迹优化[7]等。PSO算法在运算前期效果较好,在后期存在易陷入局部最优值问题,因此学者们提出了各种各样的改进方法。例如,邓浩等[8]提出了自适应权重参数调整的PSO算法;张德华等[9]提出了具有不同学习策略的PSO 算法;Wang 等[10]则将其他优化算法与粒子群算法结合,得到新的PSO 算法。各种PSO 算法从PSO 不同元素中改进,提升了算法精度与性能。
速度约束是PSO 算法运行过程中的一个步骤操作,目的是防止粒子跳出搜索空间,避免出现不可行解。最早的速度约束策略采用固定值[11],然后出现对PSO 速度边界约束的研究和改进策略,例如,Helwig 等[12]提出并比较了多种用于粒子群优化的速度边界约束处理技术;Jiang 等[13]研究了速度约束策略解决高维问题存在的缺陷并提出了几种解决方案。近年来,有学者提出一些自适应速度约束策略,并提高了算法的性能。例如,Barrera 等[14]提出速度边界随迭代次数而几何变化的策略;Adewumi 等[15]提出在粒子每代计算速度最高值和最低值的绝对值,据此计算速度边界。
随迭代次数而变化的速度约束策略具有自适应性,可以更好地提高算法性能。但是,由于PSO 算法的种群状态不确定,其局部搜索有可能发生在初始阶段,而全局搜索也可能发生在后期,因此速度边界不仅受迭代次数影响,还应该与粒子群的状态有关。Li 等[16]提出一种基于种群状态的自适应速度约束粒子群算法(particle swarm optimization with statebased adaptive velocity limit strategy,PSOSAVL),通过评估种群进化状态值而设置速度约束范围,提高算法性能。但PSOSAVL 算法只是根据粒子之间的距离评估种群进化状态,并没有考虑迭代次数,所以还是存在陷入局部最优的风险。
同时,PSO 算法与求解问题的维度有关,根据维度提出改进算法的策略,可以提高其性能。例如,蒋晓屾等[17]提出,算法粒子每一维采用不同衰减权重,提高了多样性和局部搜索能力;邓志诚等[18]提出一种具有动态子空间随机单维变异粒子群算法,当某维退化且算法性能下降时,该维采用变异,有效地提升算法收敛速度和求解质量。然而,对于PSO算法速度约束与求解问题维度的关系,目前并没有发现文献研究。
基于上述的分析,本文提出一种融合迭代和问题维度的速度约束粒子群算法 (PSO with velocity limit combining iteration and problem dimension,VLPSOID)。该算法不仅计算种群进化状态评估值(evolutionary state evaluation,ESE),而且考虑了迭代次数和求解问题的维度。算法首先设计受迭代次数和维度影响的计算公式,将其融合进化状态评估值计算中,再根据进化状态评价估值确定速度约束范围,使用算法速度约束既受迭代变化影响,也受到问题维度影响,具有自适应性,提高了粒子群算法的性能。
1 相关知识介绍
1.1 粒子群优化算法
在每次迭代过程中,粒子群算法计算每个粒子速度,更新自身位置,并且速度受到群体最优位置和自身历史最优位置的影响。标准的PSO 算法的数学描述如下。
假设粒子种群规模为N,问题维度为D;第i 个粒子位置向量xi=(),速度向量vi=(,);第i 个粒子第d 维的速度和位置在t 代的更新如下
式中:t 为当前迭代数;ω 为惯性权重;c1和c2为加速因子;为第t 代第i 个粒子第d 维的速度;r1和r2为介于0 和1 之间的随机数;为第t 代第i 个粒子第d 维的位置;为第i 个粒子第d 维的个体历史最优位置;为整个粒子群第t 代第d 维的全局最优位置。
1.2 进化状态评估策略
进化状态评估策略是评估计算算法粒子种群状态值,判断算法当前搜索状态并改进算法,使用PSO 算法具有自适应性。Zhan 等[19]提出一种自适应粒子群优化算法(adaptive particle swarm optimization, APSO),首次采用进化状态评估(evolutionary state evaluation, ESE)策略改进PSO 算法;后来也有文献提出改进的ESE 策略[20],提高了算法效率。ESE策略考虑了种群粒子分布状态及其适应度值,根据进化状态评估值将种群状态分为4 种类型:探索,开发,收敛以及跳出。种群进化状态评估值定义如下,假定f 为种群进化状态评估值,则f 值通过式(4)和式(5)两步计算得到。
式中:Li为第i 个粒子到其他粒子的平均距离,Lg为全局最佳粒子到其他粒子的平均距离,Lmin和Lmax分别为Li的最大值和最小值。根据式(5),Li值为0和1 之间的值,式(4)是体现一个粒子到其他粒子之间平均距离,式(5)将种群最优粒子平均距离归一化处理,得到种群ESE 值f,然后用于控制粒子速度约束。
但是,式(5)评估种群进化状态值,只是采用全局最优粒子的平均距离,存在陷入局部最优风险。本文提出一种融合迭代和问题维度的自适应进化状态评估策略,改进种群状态评估方法,改进粒子群算法的速度约束,形成一种融合迭代和问题维度的速度约束粒子群算法。
2 融合迭代和问题维度的速度约束粒子群算法
本算法采用了融合迭代和问题维度的自适应进化状态评估策略,其方法是先由式(4)和式(5)计算f 值;然后让其受当前迭代次数t 和求解问题维度D 影响,得到新的状态评估值f^,如式(6)。这里s(t)和h(D)分别表示受到迭代次数t 和问题维度D 影响的公式,各自采用了不同影响策略,影响着原始种群状态评估值f。s(t)为迭代策略,h(D)为维度策略
式中:η 为影响系数,η∈(0,1),控制两个策略对原始种群状态评估值f 的影响程度。
2.1 迭代策略
PSO 算法要尽可能地在前期处于探索状态,在后期处于开发状态。当种群状态评估值采用式(5)计算f 值时,应考虑迭代次数t 对其影响,目的是使f 值在前期相对较大,在后期慢慢变小。这样算法在前期全局搜索能力较强,能够搜寻更大空间,容易跳出局部最优点;算法在后期局部搜索能力增强,重点搜索有希望的局部区域。因此,本小节设计一个迭代策略,使其影响种群状态评估值f,使其值随着迭代递减。
本文设计迭代策略s(t)如式(7),tmax为最大迭代次数。图1 则表示s(t)是随迭代t 指数递减的图像。如图1 所示,s(t)在迭代前期,值相对较大,而随迭代变化,s(t)值缓慢下降,最后值为1。指数递减比线性递减下降更快,容易使f 值突变,全局搜索能力下降快,其变化范围从e 到1。
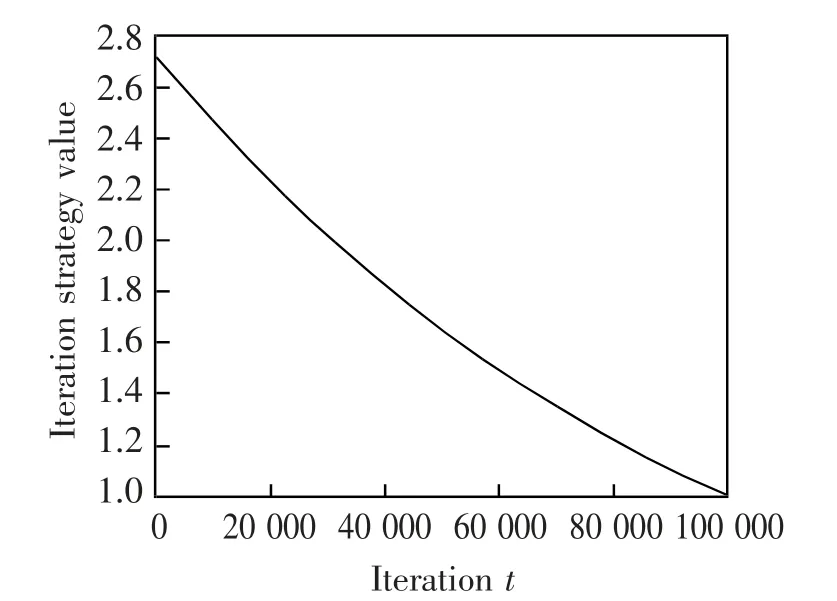
图1 迭代策略值随迭代次数的变化Fig.1 Change of iteration strategy value with iteration
2.2 维度策略
随着问题维度增大,PSO 算法计算成本增加,搜索效率降低。由于在更新高维的粒子位置时,粒子每个维度都同时到达最佳位置的概率降低,粒子更可能远离最佳位置,降低算法性能。因此PSO 算法会受到问题维度的影响,本节设计维度策略,使种群状态评估值f 受求解问题维度D 影响,其值随维度D 增加而增加,增强算法的全局搜索能力。
本文设计策略函数h(D)如式(8)所示,其变化如图2 所示。在低维时,h 值变化比较大,而随着维度增加,h 值变化慢慢变平缓,最终趋于稳定。
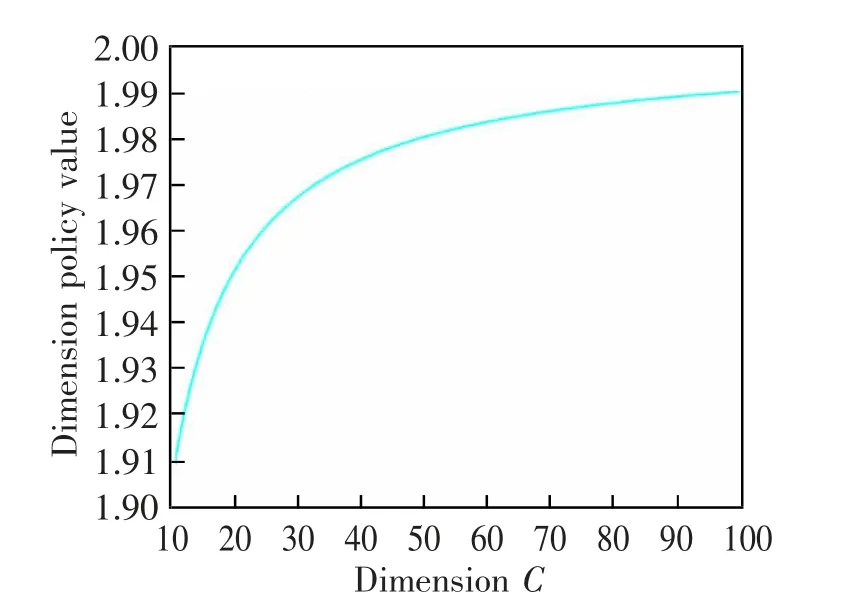
图2 维度策略值随问题维度的变化Fig.2 The change of dimension policy value with the problem dimension
2.3 种群进化状态评价方法
在式(6)的基础上,融合迭代策略和维度策略到ESE 值f 中,得到新ESE 值,其计算如下
式中:η 为影响系数,用于控制两种策略影响ESE 值的程度,η∈(0,1),具体取值由实验方法决定;t 为迭代次数;tmax为最大迭代次数;D 为求解问题维度。
2.4 进化状态评估值决定速度约束的策略
2.4.1 速度约束的计算方法
假定μ 为PSO 速度约束值(VL)与其搜索最大位置(xmax)比例值,μ∈(0,1),而速度约束VL 限制在速度下边界和上边界[VLmin,VLmax]之间。
2.4.2 超参数设置方法
α 和β 为两个超参数设置基于原则为,当f^值越大时,PSO 算法种群倾向于全局搜索,粒子速度约束边界变大;而当越小时,种群倾向于局部搜索,粒子速度约束边界收缩。当时,VL 达到最大值VLmax,此时μ=μmin;当=0 时,VL 达到其最小值VLmin,此时μ=μmax。μmin,μmax分别为VL 与xmax的最大比例和最小比例。假设μmin和μmax已知,根据式(11)可得式(12),推导求解α 和β 值。当给定速度约束VL 的比例最大值μmax和比例最小值μmin时,可以根据式(12)设置式(11)的超参数α 和β 值。
2.5 融合迭代和问题维度的速度约束PSO 算法
本节PSO 算法速度约束公式为式(3),其速度边界值VL 采用式(11)计算。式(11)VL 由进化状态评估ESE 值f^决定,而f^值融合了迭代次数和问题维度的影响,得到一种融合迭代和问题维度的速度约束PSO 算法。
当PSO 算法求解的问题维度D 和其当前迭代次数t 已知,并设置好μmin和μmax时,可以用本文提出的相关策略及其公式,求解速度约束值VL 及其范围值[-VL,VL],其算法具体过程的伪代码见算法Calc_VL,本文提出PSO 算法流程的伪代码见算法Calc_Best。
2.6 时间复杂度分析
根据算法Calc_VL 和算法Calc_Best,VLPSOID算法的时间成本主要是:计算种群状态,更新粒子的速度和位置。对于算法Calc_VL,时间成本主要为式(4),需要计算粒子之间的距离,涉及粒子之间每个维度,N 个粒子之间要相互计算,所以时间复杂度为O(D*N2)。对于算法Calc_Best,由于每次迭代调用算法Calc_VL,最后时间复杂度为O(tmax*D*N2)。算法Calc_Best 在更新粒子速度和位置时,时间复杂度为O(tmax*D*N)。综上所述,VLPSOID 算法的最终时间复杂度为O(tmax*D*N2),主要时间成本花费在计算粒子之间的距离,原因是需要计算算法种群的状态评估值(ESE)。
3 实验分析
本节实验分析方法用PSO 算法求解CEC2013中的28 个基准测试函数[21],测试对比VLPSOID 算法与其他相关PSO 算法的性能。28 个函数的信息如表1 所示,共分为3 类:f1~f5为单峰函数;f6~f20为多峰函数;f21~f28为复合函数。与之对比算法有:基于种群状态的自适应速度约束粒子群算法(PSOSAVL),基于分层自主学习的改进粒子群优化算法(HCPSO)[22],具有拓扑时变和搜索扰动的混合粒子群优化算法(HPSO)[23],以及标准PSO 算法;各算法的实验参数设置采用原始论文的数据,如表2所示。

表1 CEC 2013 测试函数Tab.1 CEC 2013 benchmark functions

表2 用于比较的算法以及参数Tab.2 Algorithms and parameters for comparison
3.1 影响系数η 的敏感性分析
VLPSOID 算法式(9)的影响系数η 控制迭代次数和问题维度对原始ESE 值f 的影响强度,η∈(0,1)。但η 具体取值表现为影响敏感程度,本节采用实验方法分析,根据η 取不同值时,分析VLPSOID 算法优化部分函数的实验性能,寻求一个最优η 取值。
实验的种群粒子数为30 个,最大迭代次数为20 000 次,实验选择的优化函数是f3,f8,f13,f18,f23,f286 种函数,函数维度分别为20,40,60,80,100 维;η 取[0,1]之间均衡地取不同的10 个值,实验比较同一函数在同一个维度,其函数适应度值的大小。实验结果如表3 所示,在η 取不同值时,算法计算函数在不同维度时的最优值。
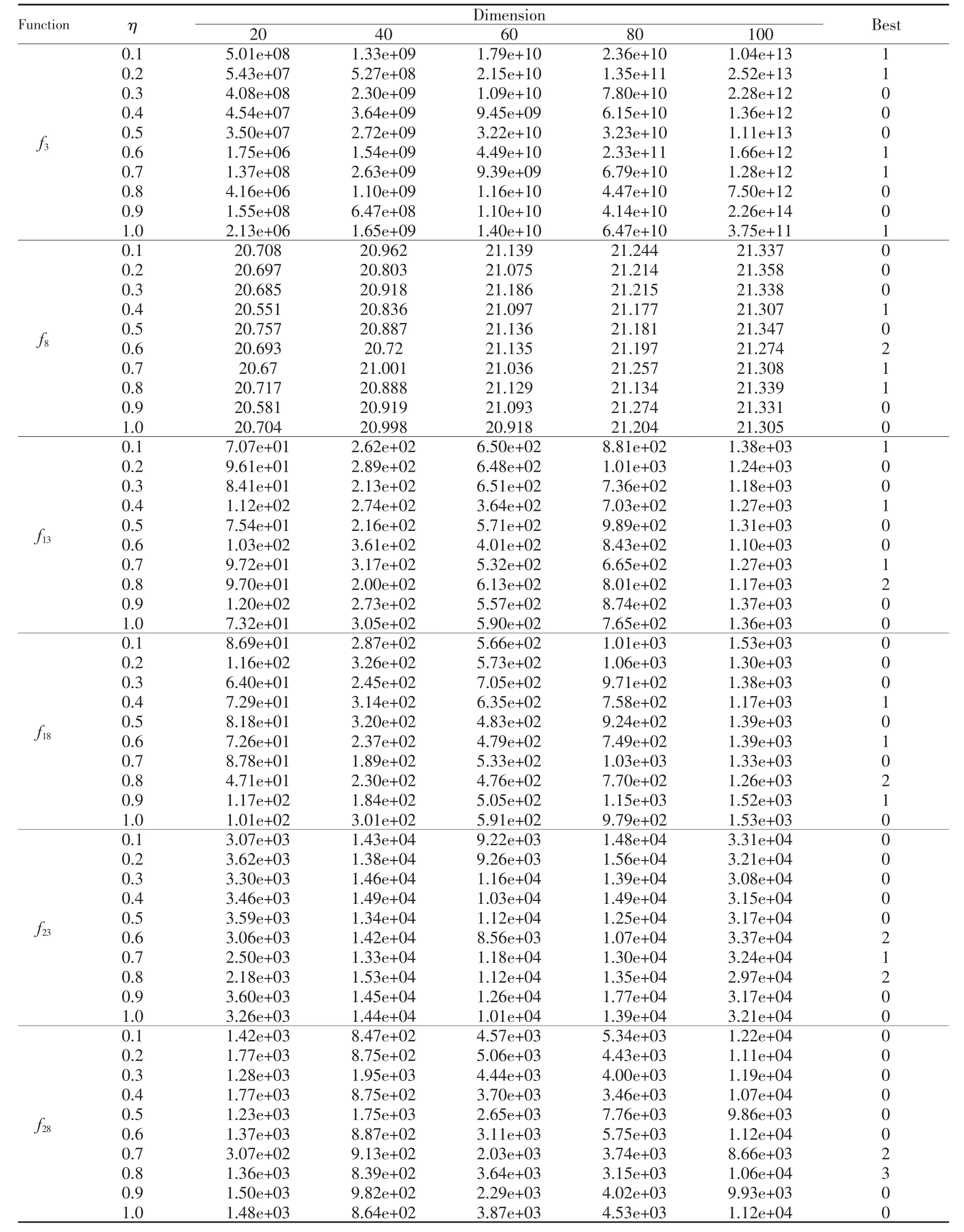
表3 不同维度的最优值结果Tab.3 The best result with different η in different dimension
算法处于不同维度时,采用不同的η 值对结果的影响也是不同的。最终统计了所选6 个函数的结果,得到总结果表。由总结果表得到,当η 值分别取0.6,0.7,0.8 时,取得较好解的次数分别为6 次,7次,10 次。相比较其他值,当η 值为0.6,0.7,0.8 时,算法取得的结果更为突出。因此,为了能够整体提升算法的性能,本文建议影响系数η 取值范围在[0.6,0.8]。
3.2 对μmin 和μmax 的敏感性分析
算法的μmin和μmax是分别表示VL 与位置最大值μmax的最小比例和最大比例,决定式(12)计算超参数α 和β 值。本节针对部分测试函数,采用实验方法,分析其取值的敏感度。实验的测试函数为f12,f18,f23,f26;函数的维度为50 维,算法种群大小为30 个,最大迭代次数为50 000 次。实验方法是,先固定μmin为0.5,测试μmax取[0.4,1.0]范围内不同值时,算法求解函数最优值,实验结果如表4 及图3左侧所示。然后,固定μmax为0.7,测试μmin取[0.1,0.7]范围内不同值时,算法求解函数最优值,实验结果如表5 及图3 右侧所示。
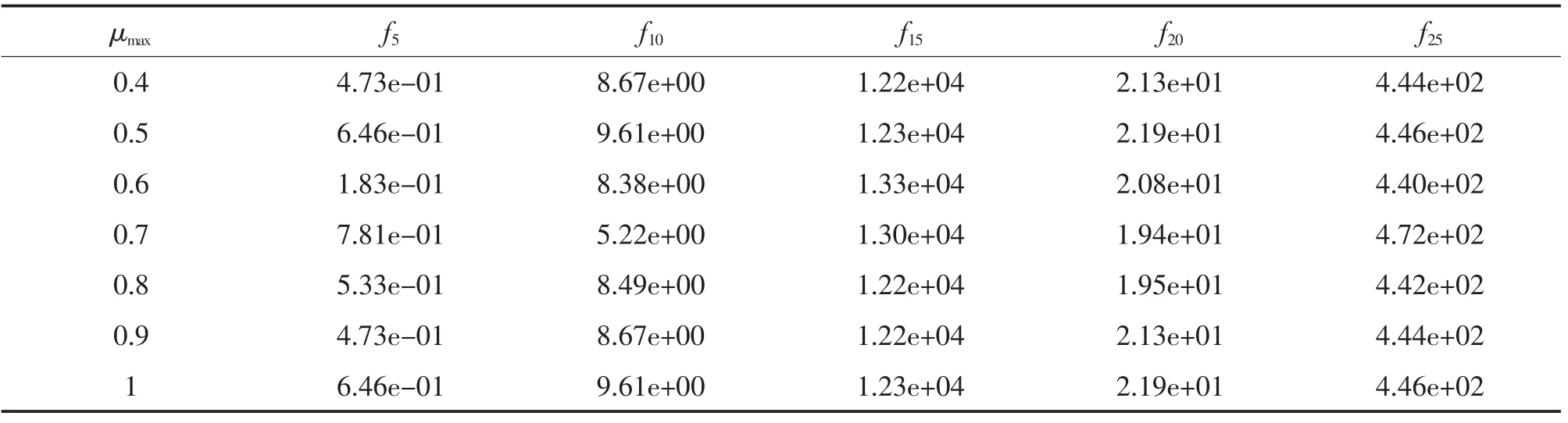
表4 不同μmax 值求解函数的最优值(μmin=0.5)Tab.4 The best value for different μmax(μmin=0.5)
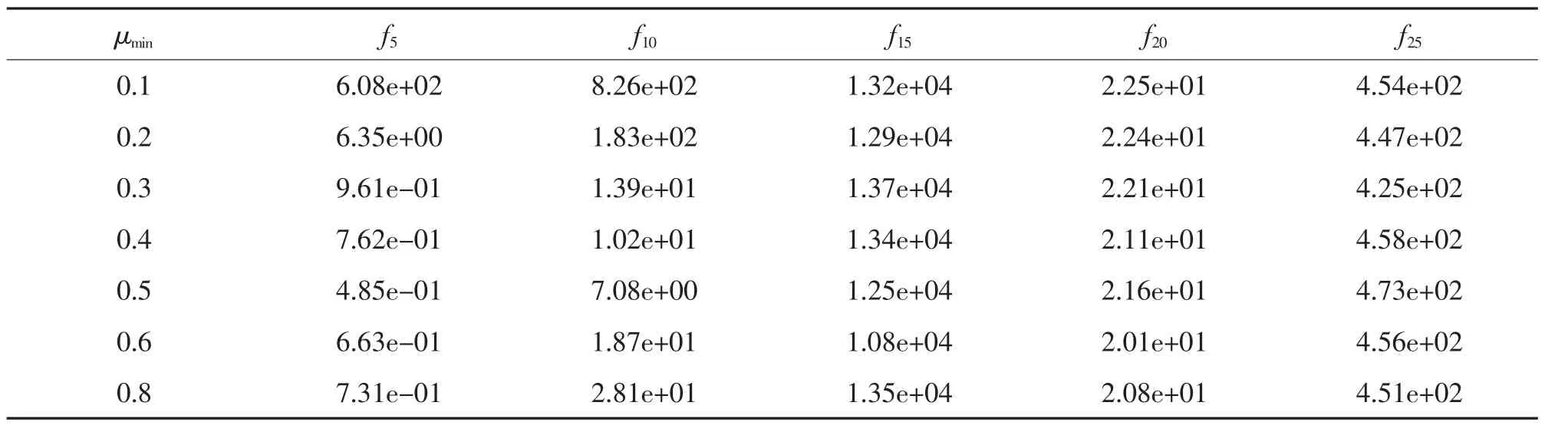
表5 不同μmin 值求解函数的最优值(μmax=0.7)Tab.5 The best value for different μmin(μmax=0.7)
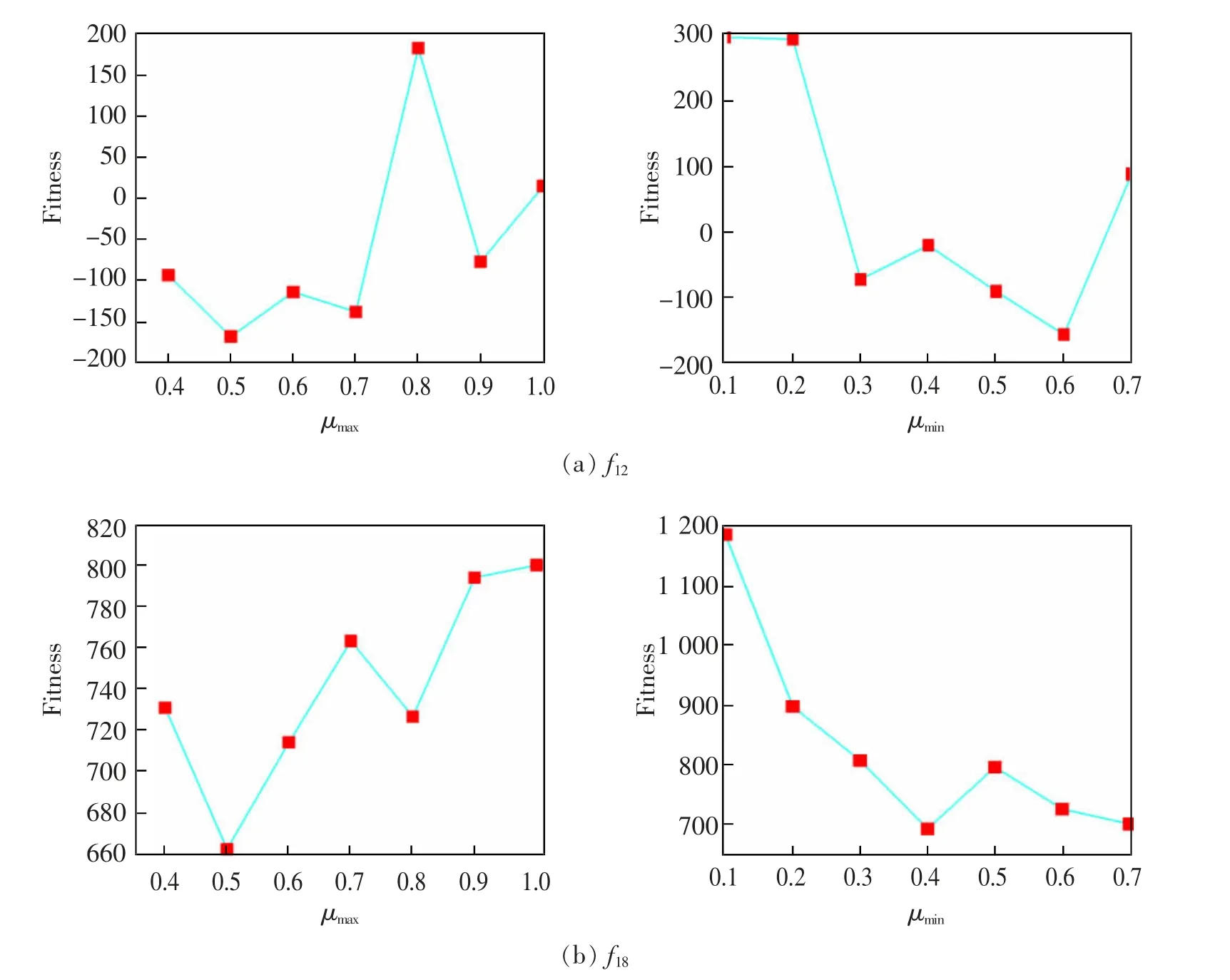
图3 函数适应度随μmax 和μmin 变化的曲线Fig.3 Curve of fitness as a function of μmax and μmin
观察表4 数据,本文算法对μmax的取值不敏感并且不同的μmax取值都提供了较为满意的结果,因此可以得出结论,本文算法对于变化的μmax具有健壮性。根据表4 以及图3 左侧的结果,建议μmax取值范围[0.6,0.7]。观察表5 数据,算法对μmin取值有一定的敏感性,当μmin取过小时,算法的优化效果变差,从图3 各子图的右侧图,也可得到验证。因此,应避免μmin取0.1 和0.2 值。观察表5 和图3 左侧,μmin取值范围应该在[0.5,0.6]之间最佳。综上所述,VLPSOID 对于变化的μmax具有鲁棒性,而对μmin值具有敏感性。本文建议在[0.6,0.7] 内选择μmax,在[0.5,0.6]内选择μmin。
3.3 迭代策略影响VLPSOID 算法的分析
本小节将式(6)的迭代策略s(t)式去除,称算法为VLPSOD,并与VLPSOID 的性能比较分析。实验对28 个基准函数优化计算,两个算法分别独立运行10次,比较两个算法求解函数的平均最优适应度。实验设置种群粒子数为30 个,函数维度为30 维,算法迭代次数为10 000 次。实验结果如表6 所示。

表6 VLPSOD 算法与VLPSOID 实验对比Tab.6 Comparison between VLPSOD and VLPSOID
根据表6,与VLPSOID 算法相比,去除迭代策略的VLPSOD 算法性能出现降低。28 个测试函数,VLPSOD 在18 个函数中的表现要差于VLPSOID 算法(全部的5 个单峰函数,15 个多峰函数的9 个,8 个复合函数的4 个),表明VLPSOID 要优于VLPSOD。这说明迭代策略能使算法在前期增强全局搜索能力,后期增强局部搜索能力,促进算法寻优能力。因此,迭代策略能提高算法优化效果和性能。
3.4 维度策略影响VLPSOID 算法的分析
针对维度策略影响VLPSOID 算法性能分析,本节将式(6)的维度策略h(D)去除,称算法为VLPSOI,并与VLPSOID 的性能比较分析。实验选择的优化函数是f3,f8,f13,f18,f23,f286 种函数, 两个算法分别独立运行10 次,比较两个算法在求解不同维度的函数的平均最优适应度。实验设置种群粒子数30 个,函数维度分别设置为30,60,90 维,算法迭代次数为50 000 次。实验结果如表7 所示。

表7 VLPSOID 算法与VLPSOI 实验对比Tab.7 Comparison between VLPSOID and VLPSOI
观察表7 可知,与完整VLPSOID 算法相比,去除维度策略的VLPSOI 性能出现下降的趋势。能够明显地看出VLPSOI 在这6 个测试函数的表现中差于VLPSOID,这说明,去除了维度策略,算法在高维空间寻优能力变差,导致性能降低。维度策略能提高算法的优化效果和性能。
3.5 VLPSOID 算法的性能分析
针对分析本文提出的VLPSOID 算法性能,将其与表2 列出的4 种算法在28 个测试函数上实验比较,每个测试函数独立运行50 次,得到其平均最优适应度值(Mean)及其标准方差(standard deviation, Std.)。实验参数设置如表8 所示,实验结果如表9 所示。

表8 实验的参数设置Tab.8 Experimental parameters
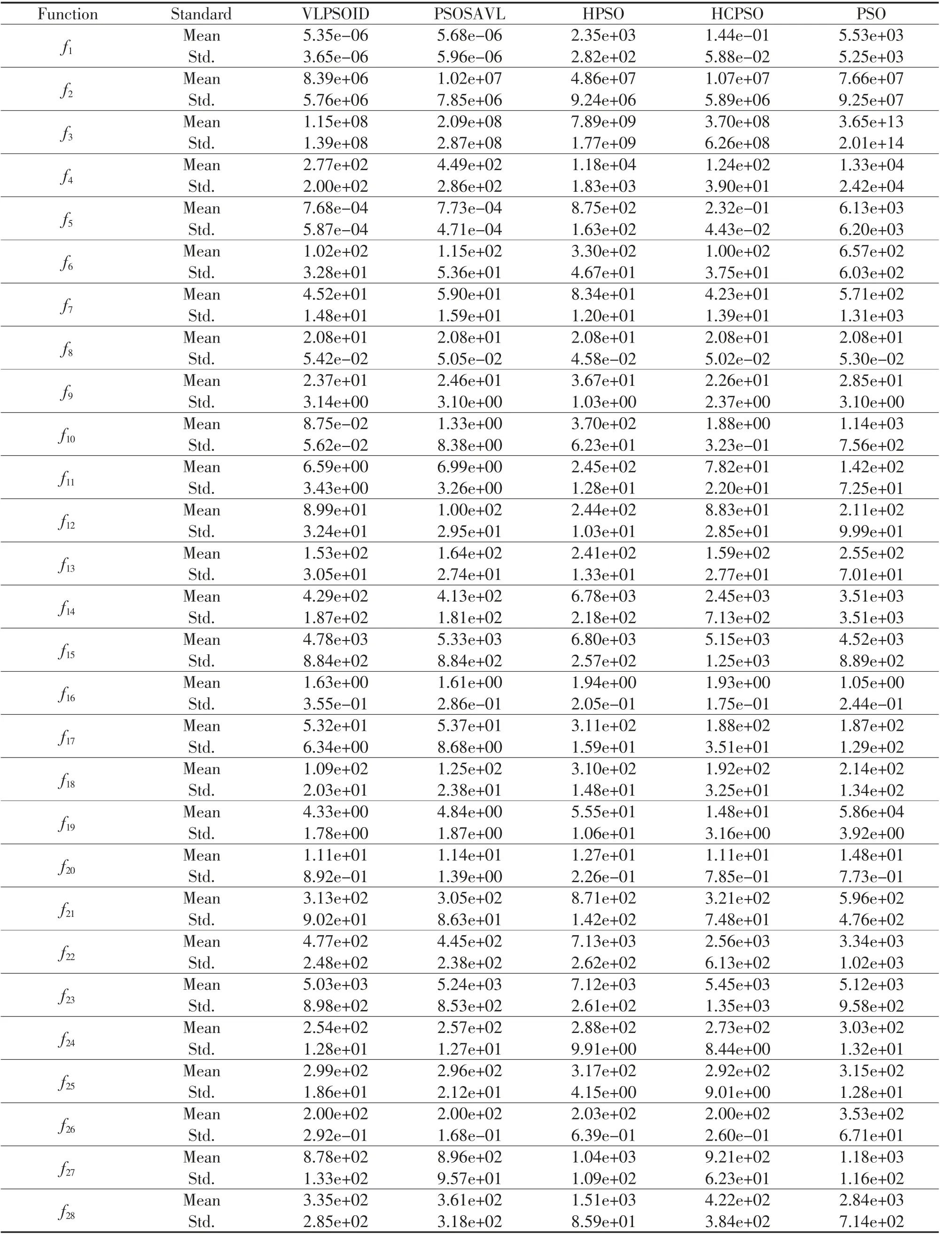
表9 基准测试函数的实验结果Tab.9 Experimental results of function tests
根据表9,相比其他算法,VLPSOID 在28 个函数中有14 个函数均值和方差表现为最好,其中5个单峰函数有4 个,15 个多峰函数中有6 个,8 个复合函数中有4 个;其他算法表现最好的HCPSO也只在28 个函数中有7 个;因此,在相比较的算法中,VLPSOID 的性能为最佳的算法。
虽然在28 个测试函数中,只有14 个函数效果优于其他算法,采用弗里德曼检测方法可知,VLPSOID 算法无论是在单峰函数、多峰函数和复合函数的检验值,还是在综合的检验值,在比较的算法中排名最好,说明其综合性能最佳。
为了更好地验证VLPSOID 算法性能有效性,针对表9 的实验数据,做t 检验方法验证。t 检验自由度和显著性水平设置分别为49 和0.05,最终结果如表10 所示。其中,粗体表示本文算法好于对比算法,灰体表示本文算法表现较差。
从表中可以看出,与PSOSAVL 算法相比,算法性能只有在f14,f16,f21,f22,f25,f26这6 个函数上处于劣势,其余函数则明显处于优势;而对比HPSO算法,可以看出VLPSOID 算法效果显著;与HCPSO 算法相比,本文算法在7 个函数上效果差于对比算法。最后,与PSO 算法对比可以看出,本文算法只有在f8,f15,f16函数上处于劣势。总体结果是,在28 个函数的对比中,本文算法好于PSOSAVL、HPSO、HCPSO 和PSO 的函数个数分别为22、28、21、25。综上所述,本文算法在对比算法中有一定的竞争能力。
3.6 算法的收敛性分析
为分析算法的收敛状态,采用VLPSOID 与其他几个算法优化6 个基准测试函数,演示了每个算法计算测试函数的适应度随迭代变化的曲线,结果如图4。其中,6 个函数分别是,单峰函数选取一个函数,多峰函数选取3 个函数以及复合函数选取两个函数。实验参数设置种群维度为30 维,种群大小为30 个,迭代次数为150 000 次。
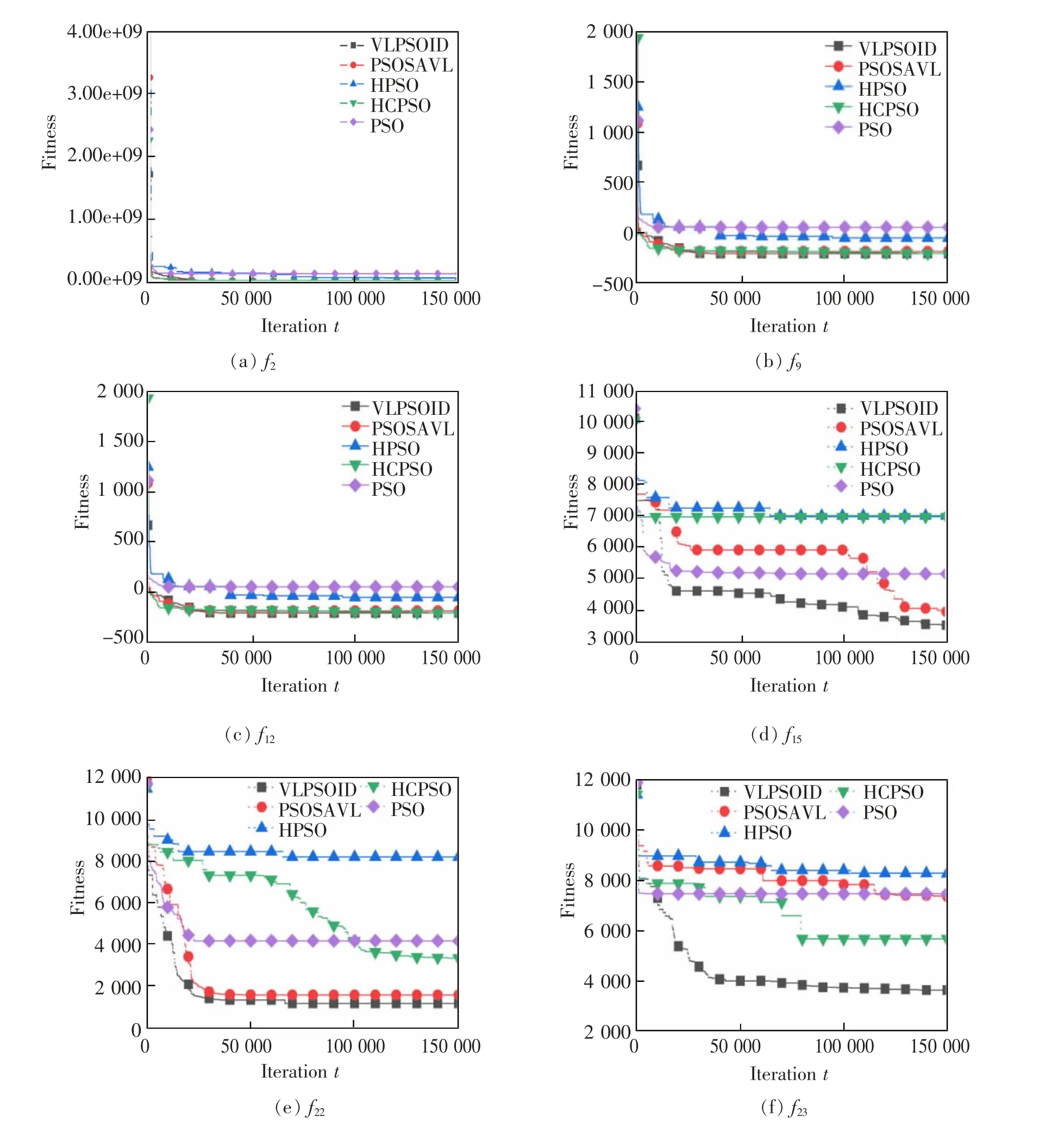
图4 不同算法的函数适应度随迭代变化图Fig.4 Convergence curves of six test functions
由图4(a)可知,VLPSOID 在单峰函数中与其他算法中表现相当。由图4(b)、图4(c)和图4(d)中可知,VLPSOID 算法在多峰函数中表现良好,大约迭代到一万代时,就能找到较好的解,收敛速度快且精度较高。从图4(e)和图4(f)能明显得出,对于复合函数,VLPSOID 算法在前期下降速度相对于其他算法快,且在后期其精度也能得到保证。综上所述,VLPSOID 不管在单峰函数还是多峰函数,其收敛速度较快且精度较高。
3.7 算法的运算时间评估
为了进一步验证VLPSOID 在寻优速度上的优势,在相同环境下,将各算法在CEC2013 测试集28个函数中分别独立运行10 次,记录达到指定精度时算法的平均运行时间,并规定,如果迭代次数超过200 000 次后仍未达到指定精度,则用空白表示。最终结果如表11 所示。
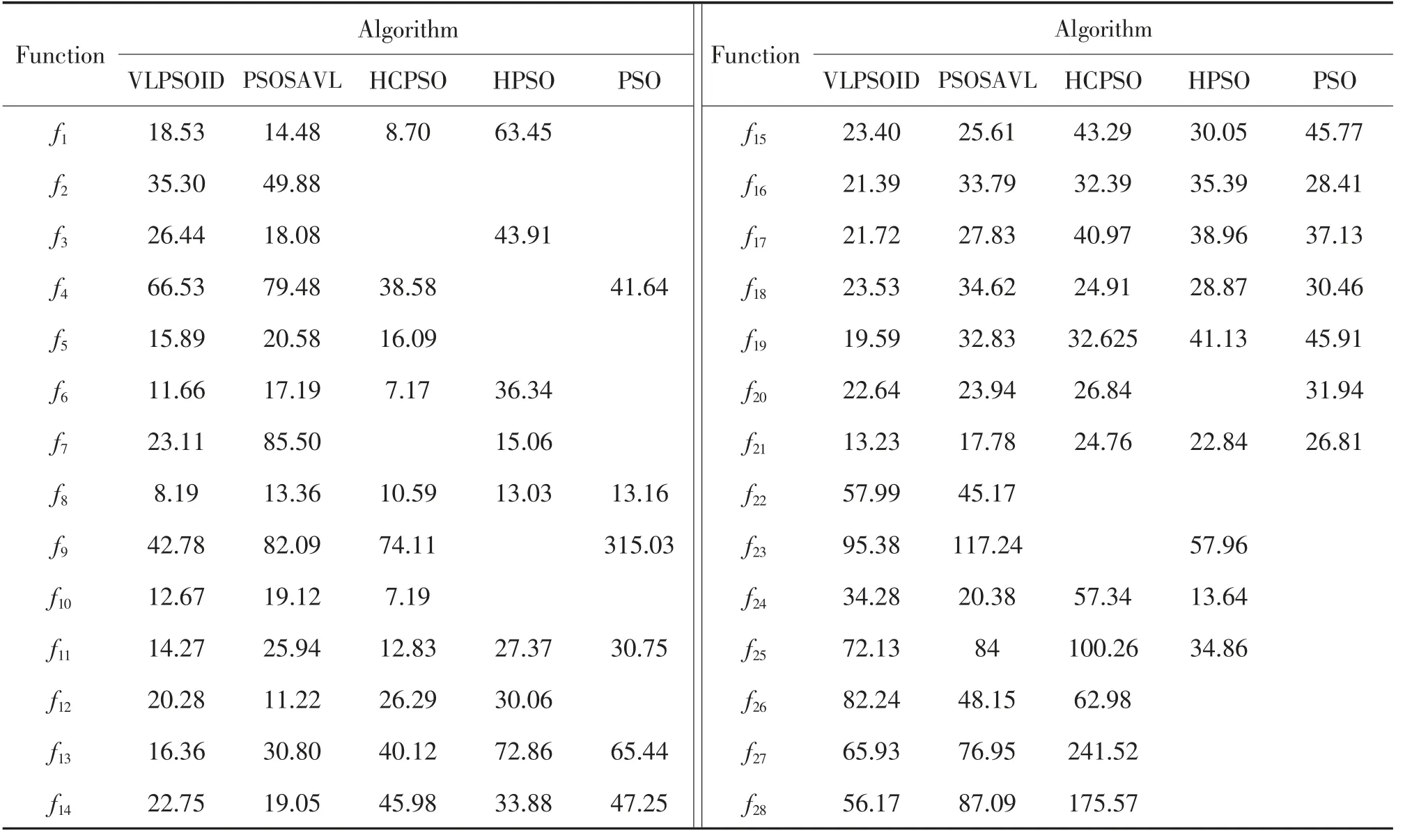
表11 算法达到指定精度的运算时间Tab.11 Running time of algorithm to achieve specified accuracys
由表11 看出,相较于对比算法,VLPSOID 的在5 个单峰函数和复合函数中表现稍差,而在多峰函数中,VLPSOID 的总体排名较为靠前。在本文中,由于VLPSOID 在每一代都需要对粒子的距离进行计算,从而计算算法种群的状态评估值,因此在此阶段需要额外的计算时间,会导致算法在部分测试函数中没有表现出其寻优速度的优势。但从表10 结果中可以看出,VLPSOID 在收敛精度有着出色的表现,因此一些时间上的损耗是可以接受的。
4 结论
1)VLPSOID 算法在前期具有较好的全局搜索能力,在后期具有较强的局部搜索能力,算法对问题维度具有扩展性。
2)在CEC2013 测试函数上,算法无论在单峰函数、多峰函数,还是复杂函数上,具有更好性能,更具有适用性,并具有解决不同维度问题的能力。
猜你喜欢
今日农业(2022年15期)2022-09-20
加油站服务指南(2021年4期)2021-07-21
数学年刊A辑(中文版)(2020年1期)2020-05-19
测控技术(2018年10期)2018-11-25
红土地(2018年7期)2018-09-26
浙江工业大学学报(2017年5期)2018-01-22
人生十六七(2015年6期)2015-02-28
物理与工程(2014年4期)2014-02-27
当代畜禽养殖业(2014年10期)2014-02-27
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
