
基于全局语义匹配的篇章级事件抽取方法
2023-07-21 07:50:22皇甫楠邹启杰
计算机技术与发展 2023年7期
高 兵,皇甫楠,邹启杰,秦 静
(1.大连大学 信息工程学院,辽宁 大连 116622;2.大连大学 大连市智慧医疗与健康重点实验室,辽宁 大连 116622;3.大连大学 软件工程学院,辽宁 大连 116622)
0 引 言
在信息飞速发展、互联网技术日趋成熟的时代下,与工作生活息息相关的文本信息相继出现,其中包含有大量事件,如某人某时在某地做了某事,在海量的文本信息中挑选出有价值的事件信息是一大难题。这个提取信息的过程被称之为信息抽取,其核心在于对其中的核心事件进行抽取,称之为事件抽取。在问答系统、文本摘要及信息检索[1]等研究中,事件抽取方法得打了广泛应用。
事件抽取任务的本质是从非结构化和半结构化的文本信息中提取出包括触发词、事件类型、论元及论元角色在内的信息[2],可以帮助用户快速识别出文本数据中包含的重要事件信息。其中,事件触发词为表示某一事件发生的词语,论元表示一个事件的时间、地点、人物等重要信息,论元角色表示事件论元与事件触发词之间的关系。事件抽取任务可以分为事件类型检测和事件论元角色识别两个子任务,且两子任务是相互依赖的。该文的任务集中于论元角色识别。
1 相关工作
事件抽取包括句子级事件抽取和篇章级事件抽取两种方法。然而,基于单句的事件抽取方法存在很大的不足。对于整个文档,如果仅基于单句进行事件抽取,不能有效地解决由多个句子组成的事件以及事件元素分散的问题,并且在现实中所有事件元素信息都出现在一个句子中的情况很少出现。因此,仅基于单个句子的事件抽取,无法从整个文档中抽取完整的事件信息[3]。因此,出现了较多研究关注基于篇章的事件抽取的方法。例如,文献[4]利用文档中不同事件的相关性来判断词的语义,最终实现事件抽取;文献[5]则基于篇章中事件的主题关系特征进行事件抽取;文献[6]提出了一种基于混合神经网络的句子级联合抽取模型;文献[7]提出一种融合上下文事件的时序关系的篇章级事件抽取方法;文献[8]提出基于深度学习的篇章级事件抽取联合模型;文献[9]使用了基于生成对抗网络的逆强化学习方法的事件抽取框架;文献[10]基于Bi-GRU神经网络,定义了三个窗口来学习句子的上下文语义关系特征,来实现篇章事件检测;文献[11]提出了一种将事件句分为三个阶段的管道式方法来实现篇章级事件抽取;文献[12]提出一个篇章级事件抽取模型—Doc2EDAG,通过使用有向无环图实现了篇章级的事件抽取,实现了很好的抽取效果。
以上研究均基于篇章信息进行事件抽取,但目前篇章级事件抽取方法均仅考虑了局部句子之间的关系特征,而未利用句子在整个篇章中更高层次、更丰富的关系特征。因此,为了提高事件抽取的性能,有效地利用句子在篇章中的全局信息,解决因仅根据局部句子之间的语义关系,而未抽取出完整事件信息的问题,该文提出了基于全局语义匹配的篇章级事件抽取方法。该方法包括事件论元识别和全局推理两个方法。其中,全局推理通过对文档中心句和全部文档句进行语义匹配,找出全部文档句中与中心句强相关的事件句,最后对所有事件句的事件元素进行信息融合得到完整的事件信息。在整个篇章的范围内进行全局推理,充分利用了句子在整个篇章中的语义信息,提高了事件抽取的整体性能。相比于单个句子和段落,提出的方法增强了事件抽取在整个文档中的全局性,减少了事件抽取的冗余,可以有效地将零碎信息整合起来,从而识别出完整的事件信息。
2 基于论元识别和全局推理的方法概述
2.1 事件论元识别
事件论元识别的任务主要是去识别句子中事件的参与者,即在事件中扮演角色的实体。可以将论元识别看作序列标注任务。简单来说,序列标注就是给定一个文本序列,对序列中包含的每个元素进行标记。一般来说,一个序列指的是一个句子,而元素指的是一个句子中的包含词。采用序列标注的方法进行论元识别,不仅可以找到句子序列中每个词的边界,同时还可以确定词所属的类别。图1是事件论元抽取的序列标注示例。
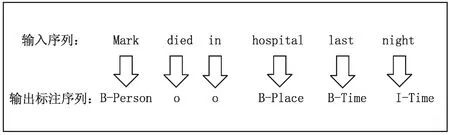
图1 序列标注示例
图1中,将一个文本句子输入到序列标注模型中,采用BIO标记方案将句子中的词转换为标记序列,输出的是序列标注的结果,其中每个标记对应特定的含义。具体来讲, 在BIO标记方法中,B-Begin表示字段的开始;I-Intermediate表示字段的中间;O-Other表示其他,用于标记无关字段;type表示字段的归属类别。在图1的例子中,B-Person表示人名的起始字段,O表示其他字段,B-Place表示地点的开始字段,B-Time表示时间的开始字段,I-Time表示时间的中间字段。因此,将句子序列输入到序列标注模型中,可获得句中的实体及其实体类型即事件论元及事件论元类型。
2.2 全局推理
全局推理的主要任务是对句子级事件信息进行推理,得到文档完整的事件信息。经过2.1中的事件论元识别,可以获得文档中每个句子包含的事件元素。而对于一篇文本文档,文档的“中心”应是文档内容的集中体现,而中心句就是能够概括文档主要事件内容的句子,文档是围绕中心句进行展开的。因此,在事件抽取中,将中心句与文档句进行语义匹配,可以很好地找到与之相关的事件句,将事件句的事件信息进行融合则可得到完整的事件信息。因此,为了得到一个事件完整的事件信息,需要对句子的事件信息进行全局推理。
全局推理包括全局语义匹配和信息融合两个方法。通过全局语义匹配的方法找到所有事件句,具体方法为:首先,通过2.1中论元识别的结果判断出文档的中心句,将包含事件元素最多的句子看作文档的中心句,将包含事件元素的句子看作事件句;其次,进行基于语义的相似度判断,对中心句和文档句进行语义匹配找出相关事件句;最后,使用信息融合的方法将所有事件句的事件信息进行融合,得到最终的事件信息。全局语义匹配的方法充分利用了文本的上下文语义信息来判断文档句和中心句是否指代同一事件,从而找出所有的事件句,获得了更好的事件共指判断指标。
全局事件抽取的具体流程示意图如图2所示。
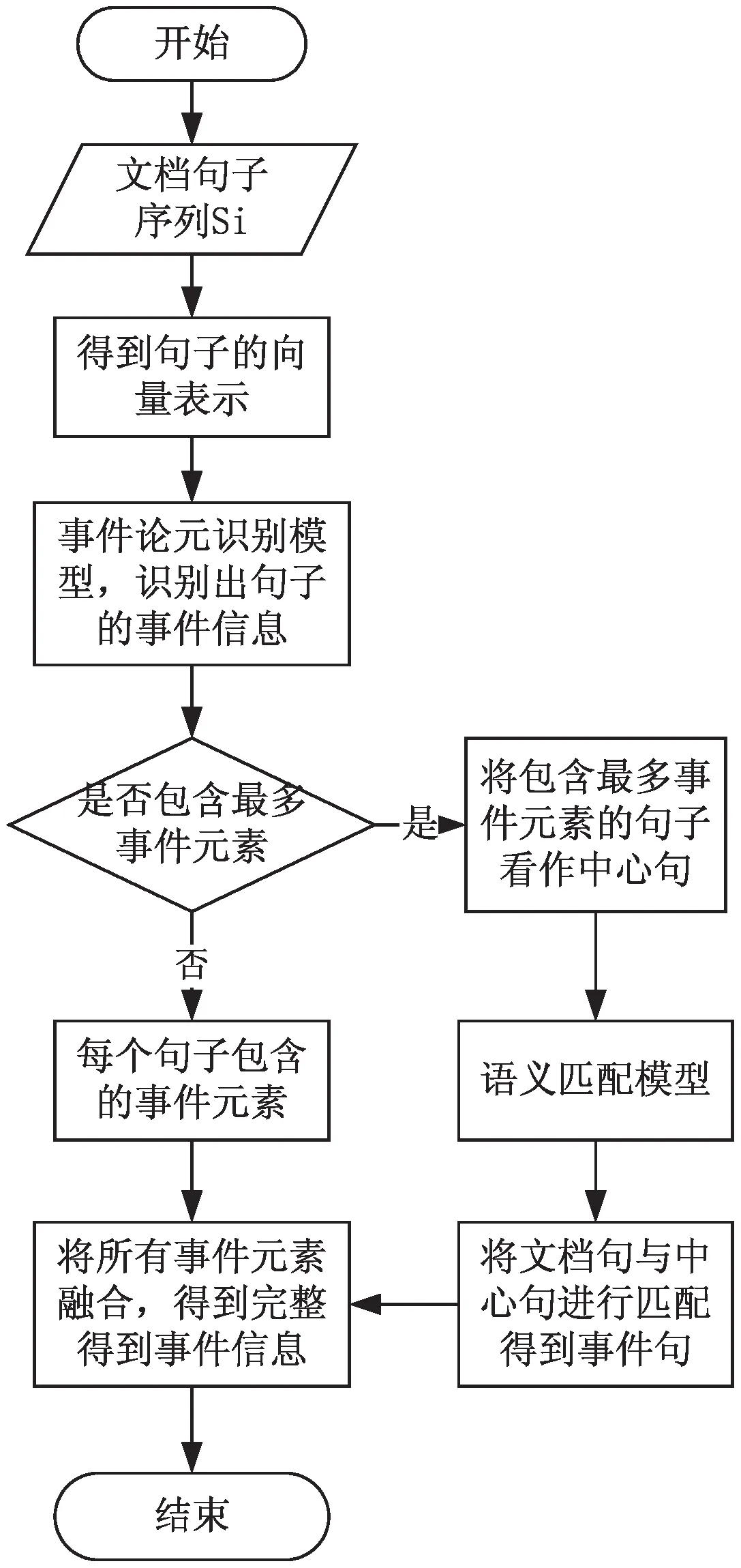
图2 全局事件抽取流程
通过上述的方法,既利用文档上下文的语义匹配得到了整个文档的事件句,也利用事件信息融合方法有效地解决了事件元素分散的问题。
3 基于全局语义匹配事件抽取模型
本节主要介绍上述方法所使用的模型,包括BiLSTM-CRF(Bi-directional Long Short-Term Memory—Conditional Random Field)的序列标注模型进行事件论元识别和利用全局语义匹配模型进行全局推理。通过找到与文档中心句相关的事件句,对句子事件元素信息进行融合得到完整的结构化的事件信息。该模型总体框架如图3所示。
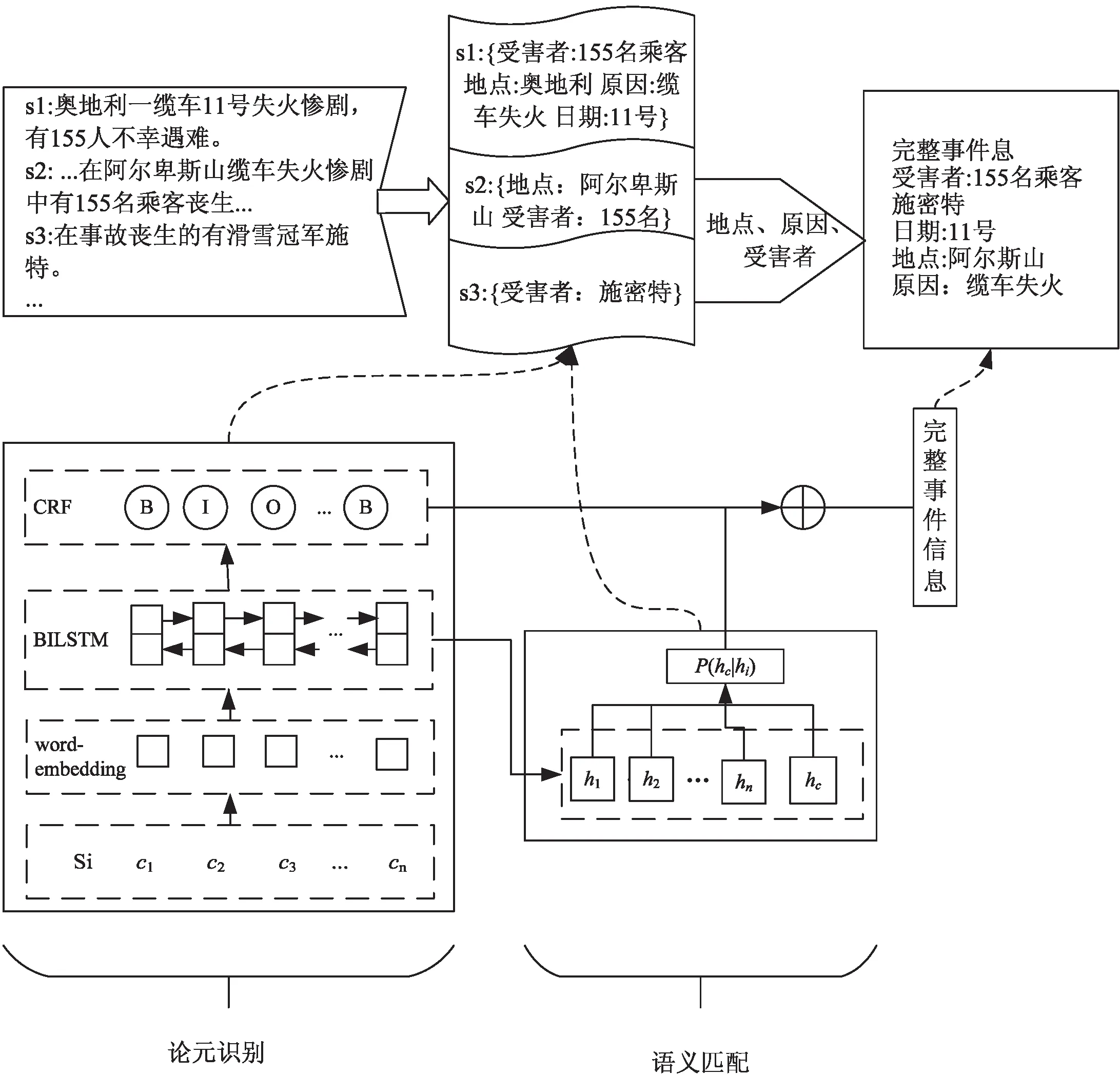
图3 全局语义匹配事件抽取模型
3.1 事件论元识别
事件论元识别模块用于对文档中句子的事件信息进行抽取。先通过嵌入层得到输入句子序列的初始向量表示,再通过BiLSTM神经网络得到嵌入层输出序列的上下文语义向量表示,最后将BiLSTM层的结果输入CRF层,得到序列标注的预测标签结果。
具体实现过程为:首先,在嵌入层中,将输入句子序列通过word2vec模型转换为句子的初始向量表示。文档是基于句子的,由多个句子组成。定义一个文档集为D=[s1,s2,…,sm],其中m指文档中包含的句子数。而句子是基于字符的,由多个字符组成。文档集合D中第i个句子序列定义为si={c1,c2,…,cn},其中n表示该句子序列中包含的字符个数。则句子si通过嵌入层转换为初始向量si={w1,w2,…,wn}:将句子序列中的字符c转化为向量w。
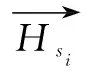
(1)
(2)
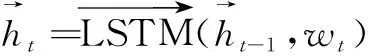
最后,将BiLSTM层得到的语义向量输入到CRF层进行序列标注,输出句子si预测标签序列,序列si={c1,c2,…,cn}对应输出的预测标签结果为y={y1,y2,…,yn}。输出的预测标签结果为score得分最高的序列,预测序列的得分函数公式如式(3)所示:
(3)
其中,P为BiLSTM的输出矩阵,Pij表示序列中第i个标记的标记j的分数。A为分数的转换矩阵,因此,Aij表示从第i个标签tagi到第j个标签tagj的转换分数。
3.2 全局语义匹配
全局语义匹配模块用于更新文档事件句,先通过论元识别模块抽取到句子级事件信息判断出中心句,再与文档句进行语义匹配得到所有事件句。
首先,通过3.1中嵌入层得到文档中每个句子的初始向量表示,再通过BiLSTM网络得到句子在文档中的上下文语义向量表示,最后进行事件的共指判断。根据文档句的上下文语义关系与中心句的语义相似度来判断文档句与中心句的共指程度,最终得到与中心句相关的事件句。其中语义相似度计算采用余弦相似度计算公式。余弦相似度使用文档中心句与文档句的上下文语义向量进行计算,这些夹角的余弦值的大小就代表了文本的相似程度。相似度的取值大小区间为[0,1],相似度越高,R(Hc,Hi)的值越靠近1;相似度越低,R(Hc,Hi)的值越靠近0。具体计算公式为:
(4)
式中,Hc代表中心句的上下文语义向量,Hi代表文档句的上下文语义向量,R(Hc,Hi)代表计算过后的余弦值。
而余弦值究竟应该达到多大这些文档句才可以被归类为事件句。其比较规则为:若R(Hc,Hi)>a,则Hi,Hc相似;否则,不相似;a为相似度阈值。
3.3 信息融合
通过3.2节中的共指判断获得了所有与中心句相关的事件句,并通过3.1获得了文档中每个句子的事件提取结果。为了得到完整的事件信息,需要利用信息融合算法,将描述事件相同但包含事件元素不同的句子信息进行融合。将分散的事件信息融合成完整的、结构化的事件信息,具体的算法实现步骤如下所示:
Algorithm1:融合算法
Input:输入句子的事件元素列表List=[{x1},{x2},…,{xN}],N为所有的事件句的个数
Output:输出融合以后的事件元素列表List1=[…]
1:forxin List:do
2: ifxnot in List1 then
3: List1.append(x)//将x添加到List1中
4: end if
5:end for
6:return List1//输出结果
该策略可以将所有的事件句中分散的事件元素进行融合得到完整的事件信息。将根据事件的中心句匹配到的事件句,即分布在篇章不同段落中对事件不同的事件描述句,进行事件元素融合,得到完整的结构化的事件信息。
4 实 验
在MUC-4事件提取数据集上验证了所提模型的效果,并与之前的工作进行了对比分析。
4.1 数据集、实验参数与评价方法
(1)数据集介绍。
MUC-4事件提取数据集由1 700篇文档组成。为了与其他结果进行对比,使用1 300份文档进行训练,200份文档(TST1 TST2)作为开发集,200份文档(TST3 TST4)作为测试集。
(2)评价标准。
使用准确率P、召回率R以及F1值来评估提出的全局事件抽取模型性能。三个评测指标的具体计算公式如下所示:
(5)
(6)
(7)
其中,TP代表模型预测和实际都为正例的数据数量,FP代表模型预测为正例但实际为负例的数据数量,FN代表模型预测为负例但实际为正例的数据数量。
(3)参数设置。
实验使用Windows系统,编程环境Python3.6。在训练模型参数时,优化函数使用SGD算法,字向量维度为100,BiLSTM隐藏层数量为200,批处理大小为5,epoch设置为20,Dropout选用0.4。
4.2 基线系统对比
本节将提出的抽取方法与已有的抽取方法进行对比。选择以下基准系统进行对比。
(1)TIER[13]是一种多阶段方法。将文档分为三个阶段:首先使用分类器确定文档类型,然后识别文档中与事件相关的句子和事件论元。
(2)Coherence-Extract[14]是一种自下而上的事件提取方法,首先独立地识别候选事件论元角色,然后利用这些信息以及语篇属性来建模语篇衔接。
(3)Multi-Granularity Reader[15]是一个新的多粒度阅读器,动态融合了在不同粒度的事件信息(句子级、段落级)。
(4)多粒度融合模型[16]提出了多粒度门控融合的篇章级事件检测模型,通过构造单句和段落级别两个维度的特征,通过门控机制将正向与逆向、单句与段落的特征进行权重融合。
其中,基线系统(4)相比于基线系统(1)(2)(3)具有更好的准确度和召回率。表1中的最后一行显示了利用文中系统获得的结果。在表1中报告了平均结果。为了详细了解模型对于每个事件角色的抽取,还在表2中报告了每个事件角色的结果。
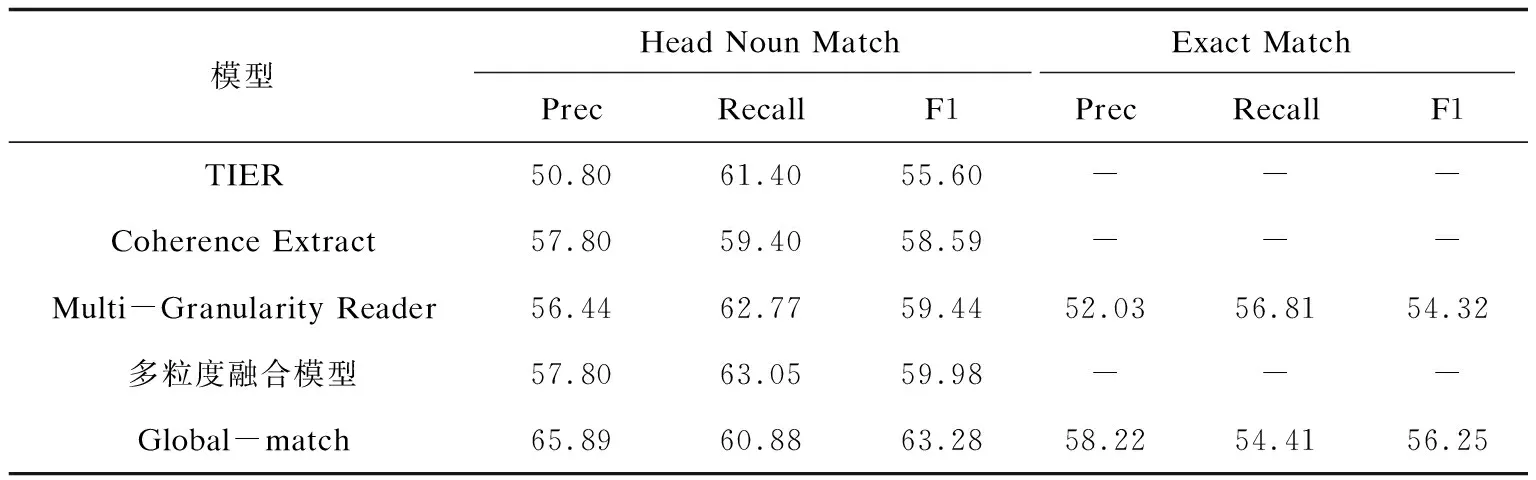
表1 平均结果 %
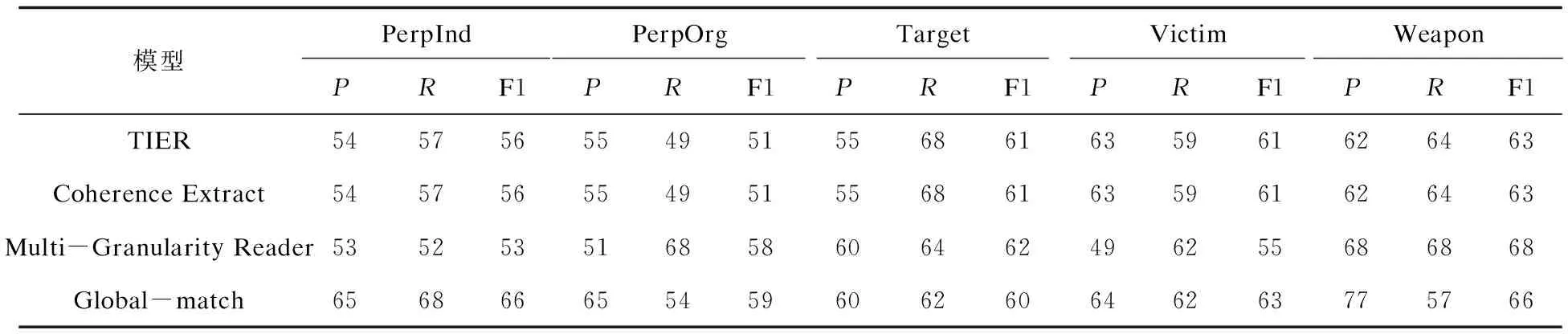
表2 各事件抽取结果 %
表1中,基线系统(3)(4)的结果优于基线系统(1)和(2)的结果,这证明了使用BiLSTM-CRF的序列标注模型标记序列实现事件抽取的方法在抽取效果上优于传统方法的人工构建特征抽取的方法。而相比基线系统(3)和(4),提出的全局事件抽取的模型在准确率和F1值上均有提升,在按头名词进行匹配上F1值提升了3.30百分点,在精准匹配上F1值提升了1.93百分点,证明了使用全局推理的抽取方法优于仅针对句子级或段落级的局部的抽取方法。在表2中,针对每个事件角色抽取结果中,Target、Weapon两种事件角色抽取的结果没有超过基线系统(3)但优于基线系统(1)和(2)。分析认为由于基线系统(3)中使用了多粒度阅读器,考虑了句子级和段落级的特征,而句子在段落级的上下文语义依赖关系,要强于句子在整篇文档中的依赖关系。所以句子在段落级可得到更丰富的上下文特征,从而影响单个事件抽取的结果。虽然使用段落级的特征能得到更全面的特征信息从而提高单个事件的召回率,但是模型准确率相应降低了。
综上所述,基于全局语义匹配的篇章级事件抽取模型在综合指标上均超过了基线模型,但在每个事件角色结果中有些事件角色没有超过基线模型。但篇章级抽取性能会受到句子级事件识别结果和句子在文档中的上下文语义关系匹配结果的影响。如果句子级在事件论元识别中的效果不好,没有将句子中的事件元素识别出来;或者文档的上下文语义关系不完全,则会最终影响篇章级的事件抽取性能指标。
4.3 使用不同的相似度阈值比较
从2.2方法可知,通过计算中心句和文档句的相似度,可以得到与中心句相关事件句,将包含事件元素的句子称为事件句。根据余弦相似度计算,采用阈值可以对文档句进行分类。将大于阈值的句子过滤出来看作事件句,以实现对整篇文档的精确抽取,从而提高事件抽取的性能。而阈值如何确定,不同阈值的实验结果对比如表3所示。
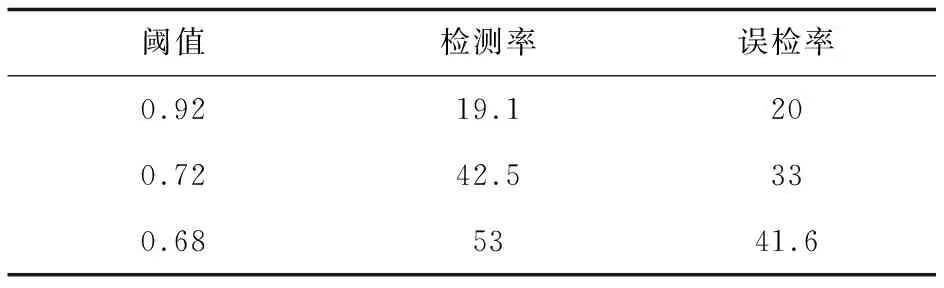
表3 各阈值比较结果 %
其中,检测率表示根据阈值从文档句中匹配出句子的概率,误检率表示匹配出的句子中不是事件句的概率。从表中可以看出,如果以0.92作为阈值,虽然误检率较低,但只能将少部分与中心句相关的句子过滤出来,匹配不完整;如果以0.72作为阈值,则可以将与中心句相关的事件句都匹配出来;如果以 0.68或更低的值作为阈值,能将与中心句相关事件句都匹配出来,但是也过滤出了一些不包含事件元素的无关句子,误检率高。
综上所述,若相似度阈值设置过大,虽然误检率低,但是也会导致一些目标句无法检测出来。若阈值设置过小,虽然检测率高能找到目标句,但是也会找到很多无关的句子。因此,根据实验结果,阈值设置为0.72时,效果最好。
5 结束语
该文主要介绍了关于事件抽取的方法,相比于句子级事件抽取,篇章级事件抽取则可以很好地解决句子级事件抽取中信息分散的问题,具有很好的研究意义。而目前篇章级事件抽取缺少对于句子在整个文档中语义关系的全局性的关注。因此,为了获取完整的事件信息,同时充分利用句子在整个文档中的语义关系,该文在句子级事件抽取的基础上,对中心句和文档句进行语义匹配得到完整的事件句,最后进行融合得到完整的事件信息。通过实验证明了所提方法的有效性。篇章级事件抽取技术虽然可以很好地解决事件元素分散的问题,但是还是会受到一部分句子级事件抽取结果的影响。因此,在未来的工作中,将进一步研究如何调整模型,使篇章级事件抽取模型的的结果不会受到句子级抽取结果的影响。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
中国新闻周刊(2021年26期)2021-07-27 04:02:12
金桥(2018年4期)2018-09-26 02:24:54
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中国卫生(2014年5期)2014-11-10 02:11:26
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05 07:44:12
