
基于通道注意力的神经协同过滤推荐算法
2023-07-21 08:05:40袁卫华戴久乾张志军
计算机技术与发展 2023年7期
包 晨,袁卫华,戴久乾,张志军
(山东建筑大学 计算机科学与技术学院,山东 济南 250101)
0 引 言
随着互联网的迅速发展,各式各样的信息呈现在用户面前,从而产生了信息爆炸的现象。作为解决信息过载的有效工具,推荐系统满足了用户的需求,在电子商务、社交网络等众多领域得到广泛应用。作为经典的推荐算法,协同过滤在推荐系统中发挥着举足轻重的作用,在众多协同过滤技术中,矩阵分解的方法是最常用的,它将潜在用户特征向量和物品特征向量进行内积表示为用户在物品上的交互[1]。
近年来,深度学习在图像处理、自然语言处理等领域取得了突破性的进展,为推荐系统的研究带来了新的机遇[2]。例如,He等人[3]在神经协同过滤的框架上进行改进,将用户的嵌入表示和物品的嵌入表示进行串联,作为多层感知网络的输入向量进行预测。在DeepCF模型[4]中,利用表示学习和匹配函数学习对用户和物品的交互进行建模,使模型在保持有效学习的同时,提高匹配函数的表示能力。这些方法虽然提高了基于匹配函数学习的灵活性,但是忽略了用户和物品之间嵌入维度的相关性,而嵌入维度可以是用户或物品的某个特征,这些特征并非独立的,未能进一步提高模型的泛化能力。
He等人[5]使用注意力机制解决了上述问题,对物品赋予不同重要性来刻画其对用户偏好的影响。LSTM-CFA模型[6]使用协同过滤算法计算用户的兴趣矩阵,再融合LSTM模型,作为模型注意力机制提取文档特征,实现情感分类。Cheng等人[7]考虑到一个用户对不同物品的关注是多方面的,提出了自适应注意力评分预测的方法,计算用户在物品的不同方面的注意力分数。王等人[8]在特征级注意力框架上,学习项目特征的偏好。虽然这些方法在一定程度能帮助用户选择有意向的物品,提高用户的倾向度,但是它们不能对物品的多个特征进行建模,进而不能捕获到用户对一个物品的真实偏好。在实际中,用户往往会对物品的不同特征赋予不同的权重,以刻画用户偏好的多样性。
针对如何提高用户和物品之间嵌入维度的相关性、模型的泛化能力及如何在隐式反馈中精确建模用户对物品的偏好等问题,该文提出了一种新的基于通道注意力的神经协同过滤算法NCFCA,将用户嵌入与物品嵌入之间的相关性整合到模型中。该模型主要包括融入注意力机制的匹配函数表示模块、卷积注意力网络模块和广义矩阵分解模块。
主要工作如下:
(1)在基于匹配函数学习的基础上,利用注意力机制探索物品的多种属性特征对目标用户选择的影响,从而挖掘用户和物品交互的信息。
(2)在卷积神经网络中整合通道注意力机制(ECA-Net)来捕获用户与物品跨通道的交互信息,获取更丰富的语义信息。
(3)将三个不同模块融合到一个推荐模型中,提高了模型的泛化能力。
在两个数据集上进行大量的实验,结果表明NCFCA模型具有出色的性能,并且优于最新的基线方法。验证了模型的有效性和合理性。
1 相关工作
1.1 基于匹配函数学习的协同过滤
在深度学习中,基于匹配函数学习的协同过滤[4]是通过已有的各种输入,在神经网络框架中进行训练来拟合用户和物品的匹配分数。为了更全面地学习用户物品的映射关系,DDFL深度双函数模型[9]将度量函数学习模型(MeFL)与匹配函数学习模型结合到一个统一的框架中。由于用户未来的购买行为可能跟用户过去的信息有关,也可能与用户的认知推理有关,NCR模型[10]将用户过去信息和逻辑运算动态组合,使之变为神经网络模型进行推荐。DeepFM模型[11]用浅层的矩阵分解(MF)模型和深层的神经网络(DNN)模型联合训练,能够同时学习不同阶的组合特征。
上述模型基于不同深度学习方法对用户和物品的初始嵌入进行学习,并未考虑用户对不同物品的偏好程度。针对这种情况,该文在将用户和物品的交互输入向量送入多层感知网络之前,通过前馈注意力层对物品的特征赋予不同的权重,以区分它们的重要性。
1.2 注意力机制
由于注意力机制可以对深度神经网络中不同的部分赋予不同的权重,使模型具有良好的性能,其在计算机视觉、自然语言处理[12]等领域得到了广泛的应用。在推荐系统领域,注意力机制也有了大量的研究[13]。Take等人[14]在隐式反馈协同过滤的框架下融合了深度注意力机制以及内容无关的历史行为权重等,使推荐效果明显提高。He等人[5]发现用户历史记录的长度存在较大差异,提出在协同过滤方法中用平滑用户历史长度来设计注意力网络。DGCF模型[15]主要是研究用户及其嵌入向量如何在动态图上通过协同信息进行表示。Wang等人[16]提出一种多分量图协同过滤方法(MCCF),在用户项目图中研究用户潜在的多种购买动机,以便区分用户细粒度的偏好。
这些模型利用注意力机制在用户购买的历史记录中获取对历史物品的偏好程度。而该文在模型训练时,利用注意力机制对不同物品特征分配不同的权重,对用户倾向的物品分配更高的权重,用于提高模型的性能。
1.3 基于卷积神经网络的推荐研究
在基于CNN的推荐系统研究中,ConvNCF模型[17]中丢弃了NeuMF模型中的串联操作,利用卷积网络来学习用户-物品的联合表示。Yan等人[18]提出一种二维CNN框架(CosRec),该模型用于处理序列化的数据,它将历史物品进行排列组合,然后利用二维CNN提取序列特征。Samuvel等人[19]提出基于面部情绪识别的音乐推荐系统,通过提取一个人不同的面部表情来识别音乐的类型进而将音乐推荐给用户。在新闻推荐中,Tian等人[20]基于CNN来执行从字级对新闻文本内容进行卷积计算,生成新闻内容的嵌入表示。
虽然基于CNN的推荐研究在音乐、新闻、文本推荐方面取得显著的效果,但是在用户项目交互时无法捕捉到更深层次的关联性,而该文通过在CNN模块中加入通道注意力机制来捕获这种关联性。
2 模型和方法
2.1 主要符号
表1总结了文中用到的主要符号及其含义。

表1 文中用到的主要符号
2.2 模型结构
模型的总体架构如图1所示。模型包括三个模块,卷积注意力网络(convolutional neural network with ECA-Net,E-CNN)模块用于捕获用户与物品在跨通道中的交互信息;融入注意力机制的匹配函数学习(attention-based matching function learning,A-MLP)模块用于提高深度神经网络的表示能力;广义矩阵分解(generalized matrix factorization,GMF)用于缓解因用户物品交互时产生的数据稀疏问题。
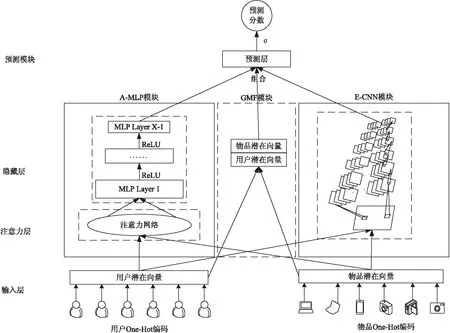
图1 模型的结构体系
2.3 模型初始表示
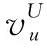
(1)

(2)

2.4 融入注意力机制的匹配函数表示
计算物品的不同特征属性对用户u购买行为的影响,即物品特征属性对用户的重要性。使用注意力函数f∈RK×1:
f(pu,qi)=ReLU(W(pu⊙qi)+b0)
(3)
其中,W∈RK×K表示输入层到隐藏层的权重矩阵,b0为偏置向量,ReLU代表激活函数。注意力网络中值越大,则用户u对物品i的某个特征属性越感兴趣。利用SoftMax函数将得到的注意力权重转换为概率分布,其注意力系数为:
(4)
其中,Ru是用户u和物品i的交互历史集合,α(u,i)∈RK×1表示用户u和物品i的注意力权重。
最后的基于多层感知网络的匹配函数学习部分定义为:
(5)
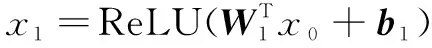
(6)
(7)
(8)
其中,x0∈R2K×1表示多层感知网络的输入向量,{x1,x2,…,xn}表示在隐藏层中对应的输入输出向量,{W1,W2,…,Wn} {b1,b2,…,bn}代表每一层的权重矩阵和偏置向量。xn为最后的预测向量。利用前馈注意力层来学习物品不同特征维度的不同重要性。
2.5 卷积注意力网络
为了加强用户和物品之间的相关性,使用CNN来学习其嵌入维度之间的高阶相关性并减少网络中嵌入层和隐藏层之间的参数。在卷积神经网络加入通道注意力机制来加强用户和物品在网络中的语义信息。ECA-Net注意力网络[21](Efficient Channel Attention for Deep Convolutional Neural Networks)能够避免卷积神经网络中特征维度的降维操作并且能增加通道之间的信息交互。
首先,模型计算用户嵌入和物品嵌入的外积作为它们的交互表示:

(9)
其中,FM∈RK×K,每一个元素可以表示为fmk1,k2=pu,k1qi,k2。通过外积操作得到二维的矩阵,再将该矩阵通过Flatten操作拉成一个维度为K2的向量。
基于CNN的协同过滤研究中通常采用CNN来提取用户和物品之间的高阶交互。该文创新性地将其扩展,在CNN的基础上添加了E-CNN组件。图1中的E-CNN模块由两部分组成。首先,将用户和物品交互表示输入到卷积神经网络中,通过6层隐藏层卷积训练,其中每一层设置64个通道,卷积核为2×2,步长为2,这样每一层得到的结果形状为上一层的一半。其次,当训练到最后一层时,卷积块形状为1×1×64,将ECA-Net注意力网络加入到卷积块之间。在每个卷积块之间通过全局平均池化操作后产生1×1×C的特征图,然后使用一维卷积核进行卷积操作,用Sigmoid函数学习通道注意力,定义通道维度为64维,通道之间的用户和物品信息的交互w:
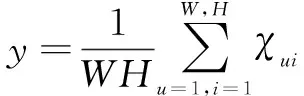
(10)
w=Sigmoid(C1D(y))
(11)
其中,C1D表示一维卷积,y表示全局平均通道池化。在卷积神经网络中,最后一层卷积层的输入定义为一个三维张量并与ECA-Net注意力网络进行结合,在每一个FM中整体的隐藏状态fm为:
h=(fm2u+a,fm2i+b)
(12)

(13)

(14)

(15)

(16)
(17)
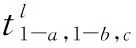
(18)

2.6 广义矩阵分解
由于广义矩阵分解模型[1]使用线性嵌入函数作为表示函数,使用点积作为匹配函数。在NCFCA中添加广义矩阵分解模块(GMF)以缓解深度神经网络在训练时可能导致的数据稀疏性问题。直接对用户u和物品i的嵌入向量进行点乘操作,即预测向量定义为:
z(pu,qi)=pu⊙qi
(19)
其中,⊙表示用户的嵌入向量pu和物品的嵌入向量qi的逐元素乘积。
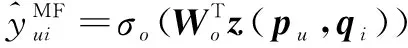
(20)
2.7 三种不同模块的融合
将三个模块E-CNN、A-MLP、GMF学习到的表示进行拼接得到其联合表示,将该向量看作是用户-物品对特征表示,然后将其输入到一个全连接层,使模型能够为联合表示中不同部分的特征分配不同的权重。融合模型的输出定义为:
(21)
(22)
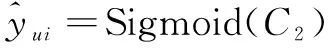
(23)
使用Sigmoid作为全连接层的激活函数。通过公式(21)(22)(23)将三个子模块进行合并,通过学习得到模型的预测分数。
2.8 模型学习

(24)
在模型中使用交叉熵作为损失函数并且使用“Adam”优化器来对模型进行优化。
3 实 验
3.1 数据集介绍
实验使用数据集MovieLens 1M[22]和Lastfm[4]来评估所提模型。MovieLens 1M数据集中有6 040个用户对3 952部电影进行评价,其中每个用户至少对20部电影进行评分,数据集中还有电影类型、电影时长等属性信息。Lastfm是一个关于用户听歌序列的数据集,它有两个文件,听歌记录与用户信息。前者为近1 000位听众截至2009年5月5日的所有音乐播放记录、播放时间,以及音乐名字、艺人名字等辅助信息。
3.2 评价指标
使用命中率(HR)[23]和归一化折扣累计增益(NDCG)[13]来评估模型的排名性能。命中率(HR)是基于召回的度量,在推荐方面的准确性进行衡量,能够直观地测量测试物品是否存在排名列表的前K名中。NDCG是衡量物品排名的质量,对被推荐的物品进行效果评估,分配更高的分数,以达到在前K个物品列表的靠前排名。这两个评估指标都是值越大,表示性能越好。HR和NDCG的定义如下:
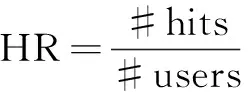
(25)
(26)
其中,#hits表示推荐列表中出现测试物品的用户数量,#users表示物品的总数。pi表示第i个用户的真实访问值在推荐列表的位置,若推荐列表中不存在该值,那么pi→∞。
3.3 对比模型
将NCFCA与下面七种方法进行比较:
BPR[23]:用于隐式反馈的项目推荐,是一种基于样本的优化矩阵分解模型的方法,具有成对排序损失。
DMF[24]:是一种基于表示学习的矩阵分解方法,采用双路径神经网络结构来代替常规矩阵分解中的线性嵌入操作。
MLP[3]:是一种基于匹配函数学习的协同过滤方法,它使用多层非线性网络来建模用户和物品之间的关系。
NAIS[5]:使用注意力机制的基于项目的多层感知器协同过滤推荐模型,模型中设计的注意力网络能够区分在用户购买的历史记录中商品的重要程度。
NeuMF[3]:是一种先进的基于匹配函数学习的矩阵分解方法,它结合矩阵分解方法和深层神经网络来学习交互函数。文中不使用预训练数据。
DeepCF[4]:是一种将表示学习与匹配函数结合的协同过滤方法。文中不使用预训练数据。
BCFNet[25]:在DeepCF的基础上加入平衡模块来缓解深度神经网络中的过拟合问题。文中不使用预训练数据。
3.4 性能比较与分析
表2列出了NCFCA模型以及其他模型比较结果,文中模型最佳结果使用粗体加以表示。

表2 基于NDCG@10和HR@10的不同方法的结果比较
可以看出,在神经网络模型中,MLP模型的性能仅优于传统的基于表示学习方法的模型DMF,因为其模型用深度神经网络的非线性特性来学习用户和物品的嵌入表示。NAIS模型引入注意力机制对比MLP模型在效果上性能有所提升。NeuMF模型为了提高网络的表达能力,利用用户和物品的嵌入表示进行串联,然后作为多层感知器模型的输入进行预测,整体上该模型性能有所提升。DeepCF模型结合表示学习和匹配函数学习的协同过滤方法,增强了用户物品特征交互的能力,但数据集较小时会到导致模型性能变差。BCFNet模型加入平衡模块来缓解深度神经网络中的过拟合问题,但模型性能并不是很好,笔者认为可能是数据未进行初始化训练导致的。
NCFCA模型利用深度卷积神经网络提取用户物品的高阶特征之外,使用先进的通道注意力网络来捕获用户和物品在通道之间的信息交互。跟DeepCF模型相比,文中模型在两个数据集上分别提高了大约2.50%、2.63%和2.18%、1.60%。这充分表明引入通道注意力机制的CNN能更好地学习用户物品嵌入维度之间的相关性。
3.5 参数分析
3.5.1 TOP-K的影响
Top-K推荐性能随K不同取值的变化趋势如图2所示。其中HR@K的精度用左纵坐标轴表示, NDCG@K的精度用右纵坐标轴表示。

(a)ML-1M数据集下的Top-K推荐排名 (b)Lastfm数据集下的Top-K推荐排名图2 评估Top-K推荐排名
在MovieLens 1M数据集上,随着K值的增加,NCFCA及其他算法性能逐渐增加,且NCFCA性能优于其他三种方法;当K大于5时,NCFCA的Top-K推荐性能与其他三种算法相比有了比较显著的提高。如图2(a)所示,当K等于10时,模型NCFCA的HR相比DeepCF、BCFNet、NeuMF分别提高了大约1.82%、1.79%和2.42%,在NDCG指标上相对提高了大约1.73%、1.44%和2.27%。
在Lastfm数据集上,如图2(b)所示,文中模型相对于其他模型也有较好的表现。这说明文中模型在卷积块之间添加通道注意力模块后交互变得更有关联性,能够更加准确地捕获交互的特征表示。
3.5.2 不同嵌入维度对模型性能的影响
在加入一层通道注意力时验证NCFCA中不同嵌入维度对模型性能的影响。
表3显示了模型在嵌入维度取值为[8,16,32,64,128]的性能对比。可以看出,在维度为32时,模型性能略微下降的原因可能是模型在训练过程中出现了过拟合现象。在维度大小为64时,模型在两个数据集上的性能最佳。在维度大小为128时,模型性能开始下降,其主要原因是网络的复杂化影响了模型的性能。通过合适的嵌入维度模型能更加有效地挖掘用户与物品丰富的语义信息,更加精准地捕获用户和物品的特征表示,使模型具有良好的表达能力。
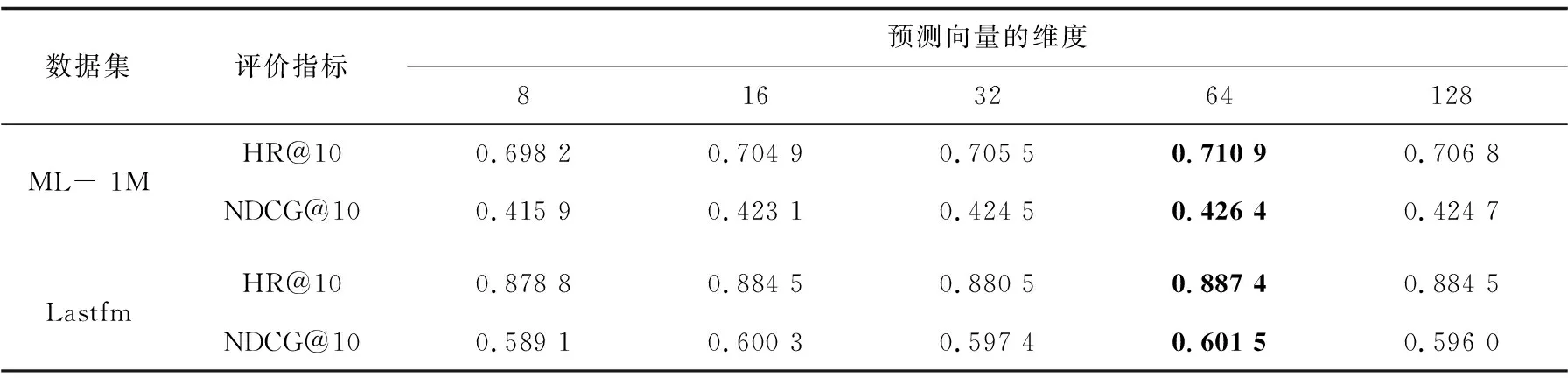
表3 NCFCA模型在不同嵌入维度下的性能
3.6 消融实验
3.6.1 不同通道注意力层数对模型性能的影响
该文进一步研究了通道注意力层数对模型的影响,分别在[0,1,2,3,4,5,6]层通道注意力进行实验,将模型表示为NCFCA-0到NCFCA-6,其中0层表示不使用通道注意力。
如图3所示,NCFCA使用一层通道注意力(NCFCA-1)时,在HR@10时其效果都优于其他的通道注意力模型NCFCA-0,NCFCA-2到NCFCA-6。
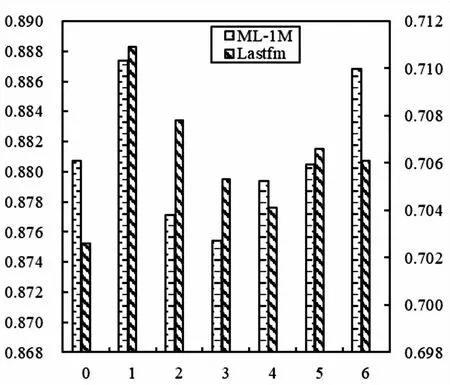
图3 基于HR@10的通道注意力层数对模型性能的影响
随着通道注意力层数的增加,HR@10呈下降趋势。这可能是因为,随着通道注意力层数的增加,卷积神经网络中的神经元参数也会随之增加,可能会导致网络变得复杂化,降低了网络的泛化能力,因此在加入多层通道注意力时并没有得到预期的效果。
3.6.2 不同模块的效果
模型在两个数据集上与不同模块进行对比,在HR@10上的结果如图4所示。NCFCA模型中的E-CNN、A-MLP以及GMF三个模块是能够独立训练的。可以看出,结合之后的模型(NCFCA)性能是优于其他三个模块的。GMF在单独训练时性能表现最差,这个因为仅仅利用内积来拟合用户的兴趣会限制模型的表达能力。从侧面也体现了文中模型的有效性。

图4 基于HR@10的不同模块的效果
4 结束语
该文提出了一种结合深度学习和高效通道注意力机制的神经协同过滤算法,其在电影数据集和音乐数据集上的隐式反馈问题进行处理。模型中的基于匹配函数表示学习的注意力网络分配不同的权重对不同类型物品对用户选择的影响;而在另一部分则通过卷积神经网络对用户和物品的交互信息中提取高阶特征,并在卷积神经网络中加入高效通道注意力机制对网络的特征维度进行降维操作以及增加通道之间信息的交互。在MovieLens 1M、Lastfm数据集上进行实验验证,该模型对提高推荐精度有着一定的效果。在今后的工作中,将考虑在其他神经协同过滤模型中扩展本模型,进一步提高推荐系统的质量。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
电子制作(2019年11期)2019-07-04 00:34:38
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
