
基于子空间多尺度特征融合的试卷语义分割
2023-07-07 10:20:48夏源祥楚程钱万永菁蒋翠玲
华东理工大学学报(自然科学版) 2023年3期
夏源祥,刘 渝,楚程钱,万永菁,蒋翠玲
(华东理工大学信息科学与工程学院, 上海 200237)
习题整理是一种有效提高学习效率的方法,但由于很多学习者无法直接获取练习资料的电子版资源,所以在习题整理过程中,学习者往往需要花费大量时间誊抄题干,这种方式费时费力,不利于提高学习效率。试卷语义分割技术能实现试卷印刷体和手写体的分离,有效提取习题题干,提升习题整理的效率。
常见的印刷体和手写体分类工作主要在连通元[1-2]、文本行[3]、以及文本区域[4-7]上进行。由于文本区域分类模式能较好地解决连通元模式下印刷体和手写体易粘连、以及文本行模式下同一行中印刷体和手写体不易分类的问题,故目前大多数的方法均是在文本区域层次上进行分类。
随着人工智能技术的发展,各种改进的深度神经网络模型被应用于印刷体和手写体文本区域的分类识别中。比如,将基于维特比解码算法的深度神经网络模型[8]应用于印刷体和手写体的分类任务上,但该方法会因帧特征切割边界不准确而影响分类结果。自Long 等[9]提出全卷积神经网络(Fully Convolutional Network, FCN)用于语义分割以来,针对各类场景需求的语义分割算法被相继提出,如UNet 通过编码器-解码器结构和跳跃连接的设计方法,将低分辨率信息和高分辨率信息结合,从而达到精准分割的目的[10];DeepLab-V3 设计串行和并行的空洞卷积模块,用于挖掘不同尺度的卷积特征,以提升分割效果[11];DeepLab-V3+在文献[11]的基础上添加一个简单而有效的解码模块,通过物体边界信息改进分割效果[12];HyperSeg 对U-Net 网络中的编码器进行改进,使得网络中的编码器既编码又生成解码器的参数,有效提高内存利用率[13],这些研究为不同类型的语义分割问题提供了解决方案。为了提高深度网络中语义分割和目标检测算法的性能,注意力模块也常用于提升深度卷积网络对图像中有效区域的感知能力。Hu 等[14]提出在通道维度上计算注意力特征的SE(Squeeze and Excitation)模块,首先对特征计算每一通道的全局平均特征,其次经过降维再恢复的方式计算注意力特征的权重,使网络利用全局信息有选择地增强有益的通道并抑制无用通道,从而达到提升网络性能的目的。Wang 等[15]提出ECA(Efficient Channel Attention)模块改进了SE 模块中降维计算权重的方法,提出不降维的局部跨信息交互策略,进一步提高网络性能。ULSAM(Ultra-Lightweight Subspace Attention Module)模块对特征分组进行基于空间维度的注意力特征计算,采用深度可分离卷积的方式降低了模块的计算参数,该模块为目标检测和图像分割网络带来明显的性能提升[16]。上述注意力模块仅考虑了空间或通道上的注意力权重,对一些细粒度图像的分割具有局限性。scSE(Spatial-Channel Sequeeze and Excitation)模块则兼顾了空间维度和通道维度的注意力特征计算,通过融合两个维度注意力特征的方式,以提高分割网络中的性能,并提升对细粒度图像分割的效果[17],但是,scSE 模块没有考虑多尺度特征空间的相互关系,在实现印刷体和手写体文本区域分类识别的试卷语义分割任务时仍会存在漏检、误检问题。
为了提升试卷语义分割效果,有效分离印刷体和手写体文本区域,本文提出一种基于多尺度子空间特征融合的试卷语义分割算法,该算法基于MaskRCNN 网络构架,在特征金字塔网络(Feature Pyramid Networks, FPN)中,设计SMFF (Subspace Multiscale Feature Fusion)模块计算特征的多维度注意力特征,通过多尺度特征融合,以增强子注意力特征间的关联性和模型对不同尺寸文本区域的感知,提升模型对印刷体和手写体文本区域的分类识别能力。
1 基于SMFF 模块的试卷语义分割
1.1 整体算法架构
本文提出的试卷语义分割算法流程包括2 个步骤,如图1 所示,其中H、W、M分别为特征图的高度、宽度及通道数。
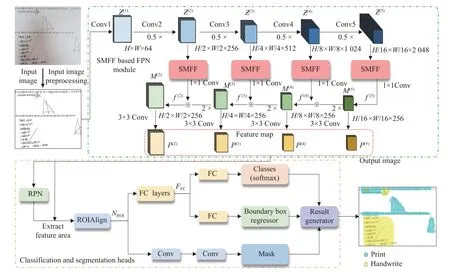
图1 基于SMFF 的试卷语义分割算法Fig.1 Algorithm for semantic segmentation of papers based on SMFF
(1)特征提取:将预处理后的样本图像输入到基于SMFF 模块的特征金字塔(Feature Pyramid Network,FPN)结构中,对ResNet50 网络第2 层~第5 层的输出特征 Z(i),i∈[2,5] 经过SMFF 模块以增强特征信息,然后通过 1×1 卷积将特征图的通道数统一为256,得到特征图f(i),i∈[2,5] 。将特征图f(i)的深层特征经上采样后与浅层特征进行融合得到融合特征图M(i),如式(1)所示:
式中,Upsample(·) 表示步长为2 的上采样,最后M(i),i∈[2,5]经 3×3 卷积获得尺寸大小不同的特征图(Feature Map)P(2)-P(5)。通过FPN 结构能从特征图中捕捉不同尺度的文本区域,在兼顾小尺寸文本区域检测的同时,增强对大尺寸文本区域的感知。
(2)检测和分割:将样本图像中的文本区域输入到区域生成网络(Region Proposal Network,RPN)中,RPN 根据文本区域的位置及大小信息计算合适的预选框,对预选框选择合适的特征图P(k)进行空间映射,如式(2)所示。
式中:k0=4 ,w和h分别表示预选框的长和宽。表示向下取整。
计算预选框在特征图P(k)上对应的位置,截取相应的特征区域,然后通过感兴趣区域对齐(ROIAlign)进行尺寸归一化,最后将归一化后的特征区域NROI在分类(Classes)、回归(Boundary Box Regressor)以及分割(Mask) 3 条支路上进行处理。NROI首先会经过一个全连接层(Fully Connected Layers, FC)得到特征FFC,在分类支路中,FFC经过一个全连接层(FC)后,使用Softmax 函数对NROI的类别进行预测。在回归支路中,FFC同样经过一个全连接层(FC)对NROI对应的预选框位置进行调整,计算预选框高精度的位置参数。在分割支路中,NROI经过两个卷积层对NROI中的像素点进行分类,决定NROI中每个像素点属于前景或者背景。结果生成器综合3 条支路的输出,得到试卷语义分割结果,对不同类别文本区域采用不同颜色区分,蓝色表示印刷体区域,黄色表示手写体区域。
1.2 改进的子空间多尺度特征融合模块(SMFF)
以ResNet50 网络中第2 层~第5 层的某一层输出特征图为例,将该层输出特征图 Z ∈RH×W×M在通道维度上进行分组,再将分组得到的子特征图通过子空间计算其注意力特征,以减少特征图中的空间和通道冗余。为了增强子注意力特征间的关联性和模型对不同尺寸文本区域的感知,子注意力特征在通道维度拼接后,再进行特征融合。本文采用多尺度卷积的特征融合方式,在卷积核中融入不同扩张率的空洞卷积。空洞卷积与常规卷积方式相比,在参数量相同的情况下,能够获取特征图不同感受野的特征以提高模型性能。
如图2 所示,将特征图 Z 输入到SMFF 模块中,其中M=q×C,q表示SMFF 模块对应的子空间数,C表示子特征图的通道数。将输入的特征图 Z 按通道维度分为q个互斥的子特征图[Z1,Z2,···,Zm,···,Zq],其中每个子特征图有C个通道,将Zm,m=1,2,···,q定义为其中一组子特征图。将子特征图输入到子空间注意力模块(Subspace Attention Module, SAM)中,计算子特征图对应的子注意力特征 Z˜m。然后,将每个子空间注意力模块的计算结果在通道维度上进行拼接(Concat),得到注意力特征图 Z˜ ,如式(3)所示:
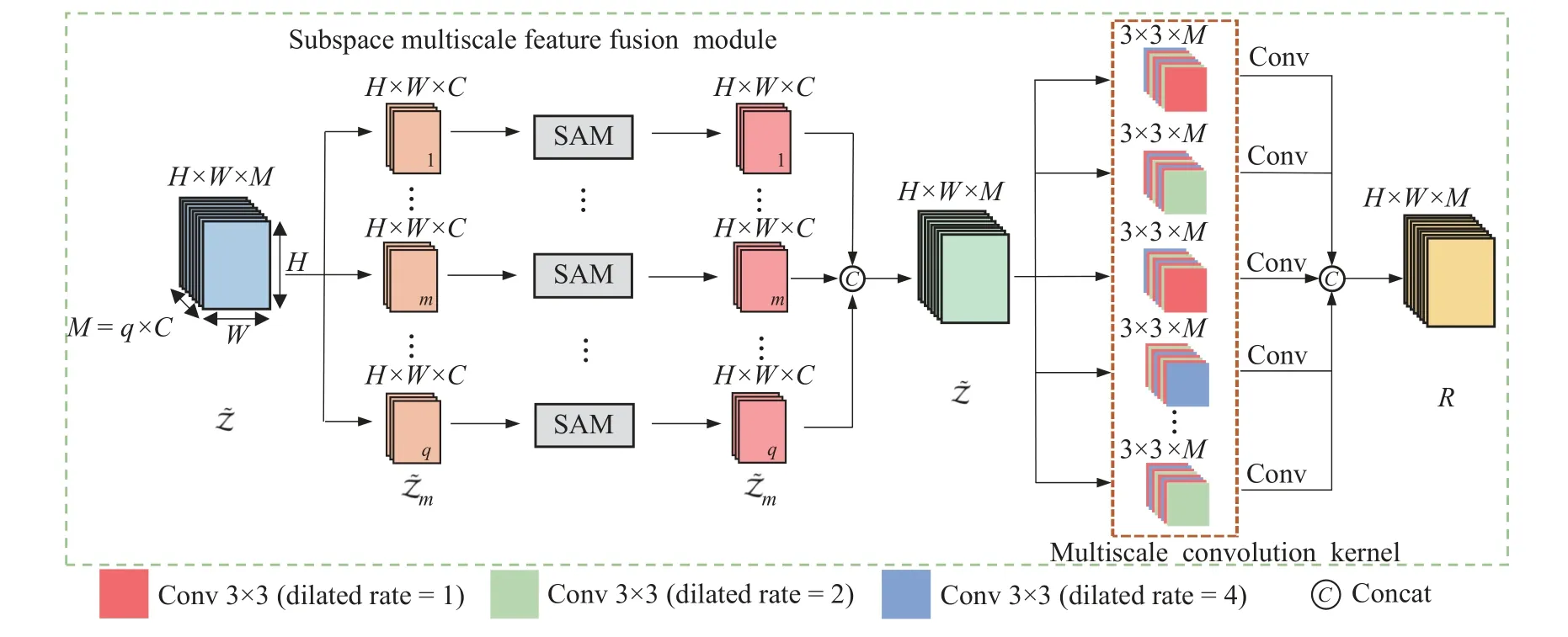
图2 SMFF 模块示意图Fig.2 Diagram of the SMFF module
式中,Rc,x,y是输出特征图 R ∈RH×W×M中的一层特征;c=1,2,···,M为输出通道的序号;x=1,2,···,H和y=1,2,···,W均为特征图的空间位置坐标。Wc,n,i,j对应第c个卷积核中第n层的参数,i,j为卷积的空间位置坐标,n=1,2,···,M为输入通道的序号,表示注意力特征图∈RH×W×M第n通道的特征,Dr(c,n),Dr ∈RM×M代表第c个卷积核中第n层对应的空洞卷积的扩张率。
1.3 子空间注意力模块(SAM)
SAM 模块通过对空间维度和通道维度的注意力权重进行融合,提高模型的试卷语义分割性能。如图3 所示,子特征图 Zm输入到SAM 模块中的空间维度支路(Spatial branch)和通道维度支路(Channel branch)上计算注意力权重。在空间维度支路中,为了避免常规卷积参数量较大的问题,本文采用深度可分离卷积计算子特征图的通道注意力权重张量。子特征图 Zm首先会经过逐通道卷积(Depthwise Convolution, DC),将子特征图的每一层特征分别与一个尺寸大小为 1×1×1 的卷积核进行卷积,其次选用大小为 3×3 、填充像素为1 的最大池化层maxpool3×3,1对逐通道卷积的结果进行池化,最后,经过卷积核尺寸为 1×1×C、个数为1 的逐点卷积(Pointwise Convolution, PC)操作,计算子特征图的空间注意力权重∈RH×W×1,其中s表示空间维度支路,如式(5)所示:
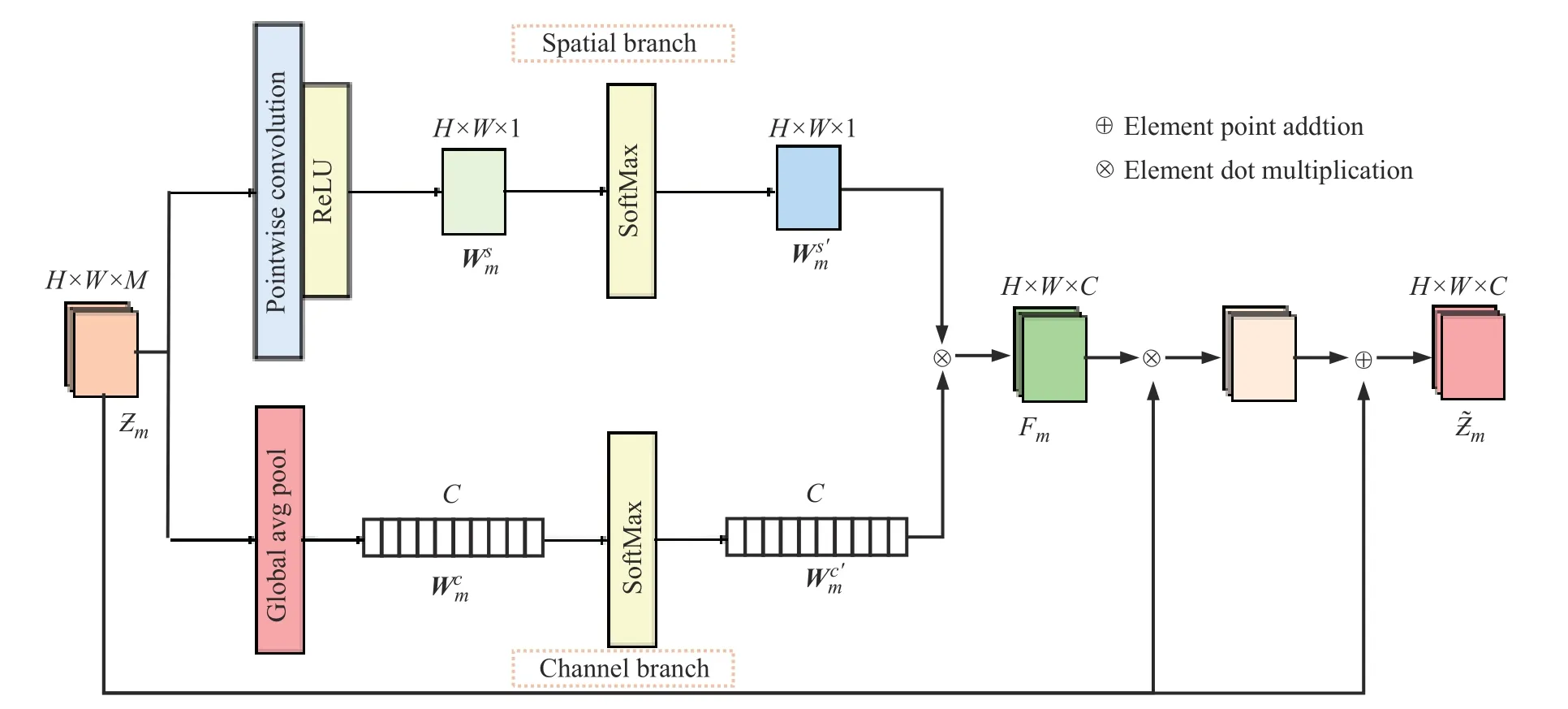
图3 SAM 示意图Fig.3 Schematic diagram of subspace attention module
为了保证注意力权重张量的有效性,通过Softmax函数对进行归一化,得到归一化的空间注意力权重∈RH×W×1,其中s′表示在空间维度支路进行归一化操作,如式(6)所示:
在通道维度支路中,对子特征图 Zm中的每一层特征进行全局平均池化操作,得到子特征层的通道注意力权重∈RC,c表示通道维度支路,将通道注意力权重通过Softmax函数得到归一化的通道注意力权重∈RC,c′表示在通道维度支路进行归一化操作,如式(7)所示:
将特征注意力权重张量 Fm与子特征图 Zm进行元素级相乘,计算得到的结果再与子特征图 Zm进行元素级相加,得到子注意力特征,如式(9)所示:
1.4 多尺度卷积
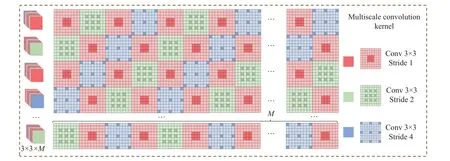
图4 多尺度卷积核示意图Fig.4 Schematic diagram of multiscale convolution kernel
本文依照文献[18]的研究结果,采用[1,2,1,4]扩张因子顺序构建多尺度卷积,与其他扩张因子顺序构建的多尺度卷积相比,[1,2,1,4]的顺序保证了卷积中感受野的过度平滑,避免了不平滑的卷积可能会减少特征之间的相关性,使网络性能下降的问题。在图4 中示出的红色、绿色、蓝色方块分别代表扩张率为1、2、4 的空洞卷积。在同一个卷积核中,卷积核每一层均由扩张率不同的 3×3 空洞卷积组成,扩张率沿通道维度按照扩张因子为[1,2,1,4]的顺序交替循环。输出特征图 R 中的每一特征层Rc,x,y均为注意力特征图 Z˜ 与对应的第c个卷积核的计算结果,因此,多尺度卷积核的个数由输出特征图 R 的输出维度决定。在不同的卷积核中,同一空洞卷积层的扩张因子沿 R 的通道维度也按照[1,2,1,4]的顺序交替循环。
1.5 损失函数
在试卷语义分割网络中,将损失函数L定义为各预测支路损失的总和,3 个预测支路损失比重均设置为1,如式(10)所示[19]:
其中:Lcls、Lreg、Lmask分别代表分类支路、回归支路以及分割支路的损失。
Lcls的损失函数定义如式(11)所示:
其中:p表示分类支路预测得到类别概率分布,p=(p0,p1,···,pu,···,pk);u表示目标真实类别的标签。pu表示目标被预测为u的概率。
Lreg的损失函数定义如式(12)所示:
其中:tu表示预测框对应类别u的回归参数;v表示对应目标真实框的回归参数;和vl分别表示预选框和真实框的第l个回归参数,每个框对应的回归参数共4 个,即l∈[1,4] 。
smoothL1损失函数是对L1 范数损失函数进行平滑处理,在 |x|<1 范围内采用L2 范数损失范数,以弥补L1 范数损失函数在该范围中不易求解的缺点,smoothL1损失函数具有稳健性,且方便求解。
通常对分类和回归损失进行如式(14)所示的组合计算[20]:
分割支路是根据分类支路的结果进行分割的结果。Lmask使用平均二值交叉熵损失函数,如式(15)所示,对每个像素点进行分类,采用Sigmoid 函数对像素点进行前景和背景的判定。
式中:yi和分别表示第i个像素点二值化后的预测值和真实值。
2 实验设置与结果分析
本实验的软件环境为OpenCV 及Pytorch 深度学习框架,硬件环境为Intel Core i7-7700K CPU 以及NVIDIA GeForce GTX 1 080 8G 显卡。
2.1 数据来源
本实验数据来源于实际试卷的拍照图像,通过对试卷图像数据集进行预处理,包括图像去噪、图像二值化和尺寸归一化,共选取1 831 幅图像作为样本进行实验。按照7∶3 的比例对图像进行分组,随机选取1 281 个样本图像作为训练集,550 个样本图像作为测试集。
2.2 评价指标
在MaskRCNN 网络中,网络对目标检测的结果进行语义分割,目标检测的准确率对语义分割的结果具有一定的影响因素,因此本文实验均从目标检测和语义分割两个任务进行对比。本文采用平均准确率作为主要评价指标,其中AP 代表采用不同交并比(IoU)阈值(0.50∶0.05∶0.95)下的平均准确率总和的均值。AP50代表IoU 阈值为0.50 的平均准确率,AP75代表IoU 阈值为0.75 的平均准确率;使用APs代表面积较小(A<322)的目标物体的平均准确率,APm代表面积中等(322<A<962)的目标物体的平均准确率,APl代表面积较大(A>962)的目标物体的平均准确率。由于本实验数据集中的文本区域面积均较大,在实验中仅对APm和APl进行比较。此外,对模型的处理时间进行比较,计算网络模型对测试集样本图像的平均处理时间,并将其作为评价指标之一。
2.3 注意力模型对比
为了验证本文提出的模块对试卷语义分割任务的有效性,本文将MaskRCNN 网络(MR)、MaskRCNN结合CCNet[21](MR-CC)、MaskRCNN 结合SE[14](MR-SE)、MaskRCNN 结合 scSE[17](MR-sc)、MaskRCNN 结合ECA[15](MR-ECA)、MaskRCNN 网络结合ULSAM[16](MR-UM)的模型的实验效果与本文算法进行对比,结果如表1 所示。
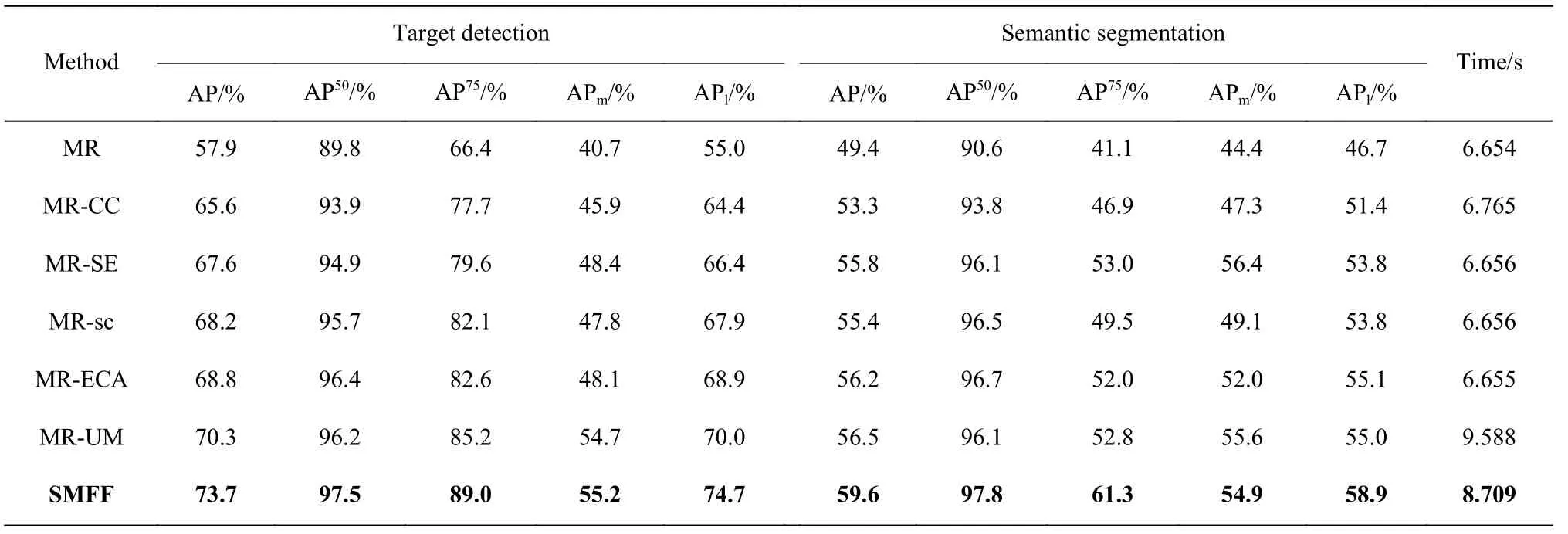
表1 注意力模型的效果对比Table 1 Comparison of the effect of attention model
从表1 可以看出,与MR 进行对比,SMFF 目标检测的AP 提升了15.8%、语义分割的AP 提升了10.2%。与结合了最新注意力模块的MR-ECA 和MR-UM 相比,SMFF 目标检测的AP 分别提升了4.9%和3.4%。语义分割的AP 分别提升了3.4%和3.1%。由实验结果可知,注意力模块对MR 网络的性能提升有效,本文提出的SMFF 模块与其他注意力模块相比,对目标检测和语义分割任务的性能提升最显著。在处理时间方面,SMFF 和MR-UM 由于模型更加复杂,需要的处理时间比其他算法更长,SMFF在处理时间上比MR-UM 略快一些,且效果更好。
2.4 特征融合对比
为验证特征融合在试卷语义分割任务上的有效性,本文对比了特征融合PSConv[18](MR-PS)、DWConv[22](MR-DW)、MixConv[23](MR-Mix)在MaskRCNN 网络中的性能,如表2 所示。由表2 可知,SMFF 模块对注意力特征图以更细粒的角度进行多尺度特征融合,相比其他3 种特征融合的方式,它在试卷语义分割任务上的性能提升更加明显。本文算法与使用多尺度特征融合方式的MR-Mix 和MR-PS 进行对比,目标检测的AP 分别提升了8.7%和9.1%;语义分割的AP 分别提升了和7.2%和6.1%。与其他基于特征融合改进的MaskRCNN 网络在处理时间上进行比较,SMFF 的处理时间相对较长,但效果更好。
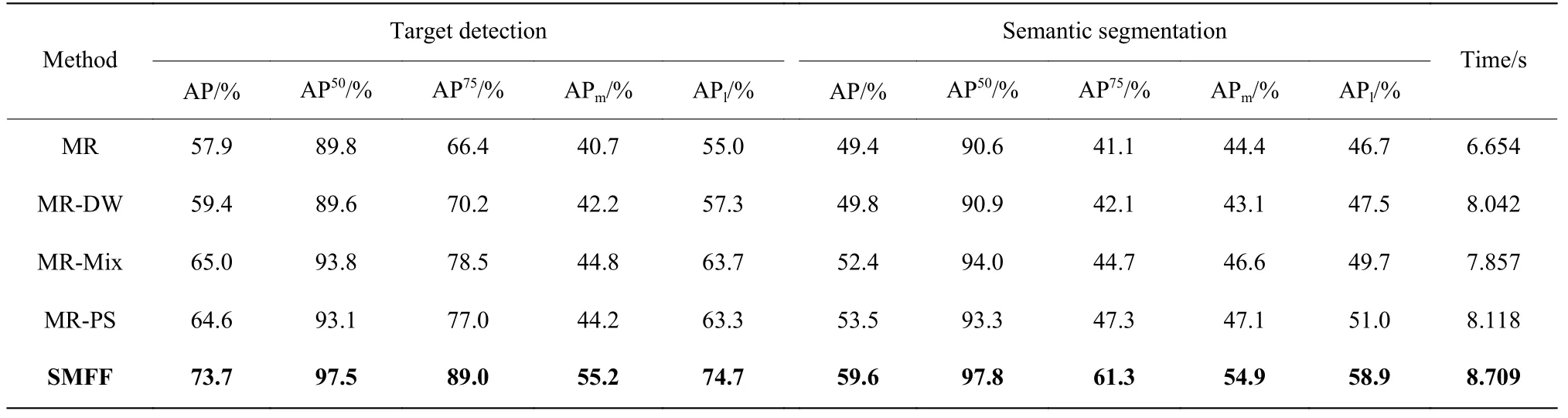
表2 特征融合模型的效果对比Table 2 Comparison of the effects of feature fusion model
2.5 分组及消融实验对比
本文与同样使用子空间思想的ULSAM(UM)算法进行了分组数选取的对比实验,实验结果如图5 所示。
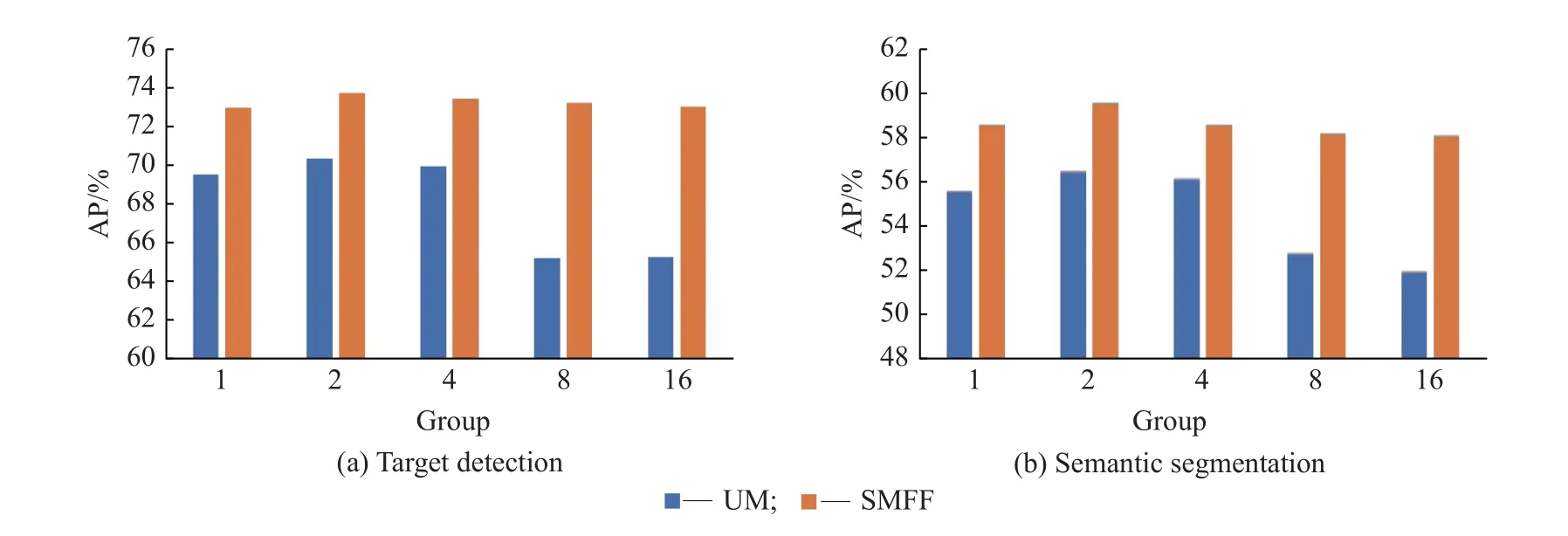
图5 UM 与SMFF 的分组对比Fig.5 Grouping comparison of UM and SMFF
从图5 中可知,SMFF 模块与UM 在同组的对比中,其在目标检测和语义分割上的指标均优于UM,说明SMFF 模块相比UM 在试卷语义分割任务上的性能更好。UM 的子空间数超过最佳分组数后,网络性能的提升会随子空间分组数的增加反向下降相比,但SMFF 模块在各分组数实验中目标检测和语义分割的指标变化更小,说明本文算法的性能更稳定。
为验证特征融合对子空间性能提升的有效性,本文对SMFF 模块进行了消融实验,实验结果如表3所示。基于子空间思想的MR 网络的目标检测和语义分割的AP 分别提升了12.1%和7%。SMFF 模块在子空间的基础上增加特征融合,与仅使用子空间思想的网络相比,其目标检测AP 提升了3.7%,语义分割AP 提升了3.2%,说明特征融合能够进一步提升网络的性能。在处理时间方面,尽管在MaskRCNN网络中每增加一个模块,网络的处理时间都会长一些,但是网络的性能却可以得到较大提升。
如图6 所示,在试卷常见的题型,包括选择题、填空题、计算题上进行实验,比较了SMFF 模块与其他模块在试卷语义分割上的效果(蓝色和黄色分别表示印刷体和手写体的分割结果)。在图6 所示的实验效果对比中,MR、MR-UM 和MR-PS 等模型在试卷语义分割中均出现不同程度的漏检,如紫色标注的部分。在红色标注的部分,MR-PS 和MR-UM 的结果中出现大范围的误检,将同一个部分同时判定为印刷体和手写体,而基于SMFF 模块的网络相比其他3 种网络的处理效果则更好,基本没有漏检问题,也没有出现大范围地误检问题。
在基于文本区域的印刷体与手写体分类算法中,文献[5]和文献[6]通过提取文本区域的时频域特征,采用简单的机器学习方法进行分类,文献[7]通过马尔可夫随机场对文本区域的特征进行分类,文献[8]通过维特比解码算法的网络模型对文本区域的帧特征进行分类。将本文提出的算法与上述算法进行实验对比, 处理时间对比结果如表4 所示,算法效果图如图7 所示。从实验结果可以看出,文献[5]的处理时间最短但是其实际分类效果最差;本文算法相比文献[6-8]在处理时间和处理效果上都更好一些。文献[5-8]的分类算法在实现印刷体和手写体分离时会出现大量的误检和漏检问题,从而导致题干区域无法完整保留,答题内容清除不干净。本文提出的算法能够准确地分离印刷体区域和手写体区域,有效解决其他算法出现的问题。

表4 印刷体和手写体分类算法处理时间对比Table 4 Comparison of processing time between printed and handwritten classification algorithms
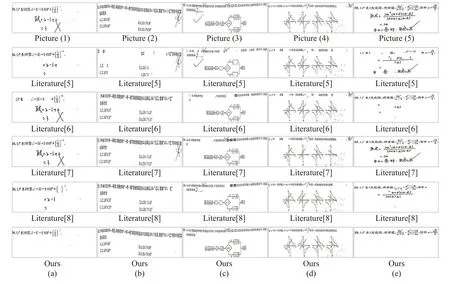
图7 算法效果对比Fig.7 Comparison of algorithm effects
使用者拍摄的试卷图像经过本文所提出的试卷语义分割方法处理后的结果如图8 所示。从图中可以看出,本文提出的方法能够有效分割印刷体和手写体区域,完整地保留题干区域。
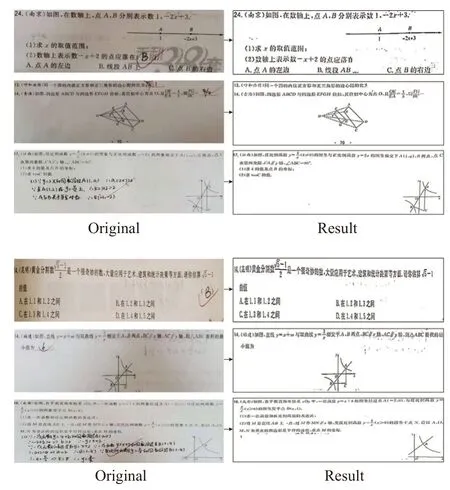
图8 实验效果展示Fig.8 Present of experimental results
3 结 论
本文提出子空间注意力特征融合(SMFF)模块并将其嵌入MaskRCNN 网络中,在子空间中通过不同维度计算特征图的注意力权重,减少空间和通道的冗余,并通过特征融合更好地提取注意力特征的细节信息。实验结果表明,在试卷语义分割的印刷体和手写体区域的分类任务上,本文算法比MaskRCNN网络模型的效果更好;与其他文献[5-8]提出的算法相比,本文算法出现漏检和误检的现象更少。在目标检测和语义分割的性能指标上,本文算法也优于其他基于常见特征融合(PSConv、DWConv、MixConv)或注意力模块(CCNet、SE、scSE 等)的网络模型,在试卷语义分割任务上表现出更好的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
美与时代·美术学刊(2020年7期)2020-10-13 12:24:04
校园英语·月末(2020年4期)2020-06-08 12:54:41
时代英语·高一(2017年3期)2017-06-13 13:19:08
时代英语·高一(2017年3期)2017-06-13 11:41:39
时代英语·高一(2017年3期)2017-06-13 11:37:48
传媒评论(2017年3期)2017-06-13 09:18:10
时代英语·高一(2017年3期)2017-06-13 07:13:14
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中学生天地(C版)(2016年4期)2016-09-16 03:19:02
