
基于图像描述的实验室气瓶危险场景辨识方法
2023-07-07 10:20:42傅煦嘉周家乐颜秉勇王慧锋
华东理工大学学报(自然科学版) 2023年3期
傅煦嘉,周家乐,顾 震,颜秉勇,王慧锋
(华东理工大学信息科学与工程学院,上海 200237)
实验室是高校师生开展科研与教学活动的重要场所。随着我国高校办学规模的不断扩大,实验室的管理难度也在日益提升。气瓶是实验室中常见的设备,其使用广泛,数量庞大,危险隐蔽性高[1]。在实验室气瓶场景中,常见的隐患有:(1)实验人员操作不当;(2)气瓶存在缺陷或安全附件失效;(3)气瓶放置时没有被妥善固定;(4)可燃气体与助燃气体的气瓶混合存放[2]。因此气瓶的监管是实验室安全管理的痛点,需要有效的措施降低事故的发生概率。
视频监控是高校实验室安全管理的有效手段。通过监控图像,监控人员可以识别出多个气瓶与气瓶含有的气体种类,进而判断两种气瓶相邻放置是否符合安全规范;同时,可以检测出气瓶上是否有固定带,以此判断出气瓶放置在此处是否安全。但该方法存在局限性:(1)视频监控需要工作人员实时盯看,导致耗费大量的人力;(2)由于监控人员的水平参差不齐,无法通过危险场景得知危险源与危险的原因,因此难以及时采取有效的措施。
图像描述是计算机视觉中的常见任务,其利用计算机将输入的图像转换为对应的文本输出,在输出的文本中包含图像的目标类别、目标属性以及目标进行的活动。通过这项技术可以准确描述出视频监控中气瓶、固定带的状态及气瓶间的关系,并据此发现潜在的危险场景,有效解决视频监控面临的局限性。常见的图像描述方法包含3 类[3],分别为模板法、检索法与基于深度学习的方法。其中,基于深度学习的方法效果最好,是该领域研究的主要方向。Vinyals 等[4]采用了经典的编解码结构,并在编码端加入了BN(Batch Normalization)层,加快训练的收敛速度,同时在解码端使用LSTM (Long Short Term Memory)替换循环神经网络引导描述的生成,解决了训练过程中的梯度消失问题;Xu 等[5]首次将注意力机制引入图像描述任务,在生成描述单词时可以聚焦到图片中相应的区域,提升了图像描述的效果;Lu 等[6]引入了哨兵机制,通过整合图片信息与文本信息,实现了对视觉注意力的选择,使得生成的图像描述结果更加流畅;Anderson 等[7]将bottom-up 与top-down 结合得到组合注意力机制,其中bottomup 使用目标检测方法确定图像内每个区域的权重,top-down 使用了两个LSTM 分别用于注意力机制与语言模型,进一步提升了图像描述的质量;Wang 等[8]认为图像内的文本对图像描述的效果有着重要作用,因此提出结合目标检测与OCR(Optical Character Recognition)的CNMT(Confidence-aware Non-repetitive Multimodal Transformers)模型,该方法将识别的文字融入描述语句中,使得描述结果更加符合图像内容。目前,图像描述在内容安全、化学结构识别领域均得到应用,但在实验室气瓶场景中还鲜有使用。
本文针对实验室气瓶安全问题,应用图像描述技术实现实验室气瓶危险场景的辨识,主要贡献包含:(1)提出了一种结合多尺度目标检测与文本检测识别的图像描述方法,实现自动生成气瓶图像对应的描述语句;(2)收集了实验室气瓶图像并制作成数据集,为实验室气瓶危险场景辨识领域的后续研究提供帮助;(3)通过实验表明,本文方法生成的描述语句能够辅助监控人员识别出场景内的危险源与危险因素。
1 算法设计
本文方法的结构由5 部分组成(如图1 所示):(a)气瓶图像内的目标特征提取;(b)气瓶瓶身上的文本检测识别;(c)多模态嵌入空间接收目标特征与识别文本;(d)使用Transformer 模型融合多模态特征,并预测生成气瓶场景描述语句;(e)根据判断规则得出场景危险的原因。
1.1 目标特征提取
需要提取的目标特征包含位置特征与视觉特征,为实现这一目的,先要对图像进行目标检测。目标检测是对输入图像中的感兴趣目标进行定位与分类。Faster R-CNN[9](Faster Region-Based Convolutional Neural Network)具有模型结构清晰、易于修改、检测精度高、实时性强等特点,因此本文选用其作为基础模型。为提高模型对气瓶场景中小尺寸目标物(如固定带)的检测精度,选用ResNet[10]作为Faster RCNN 的骨干网络,并在骨干网络与区域建议池化层(Region of Interest Pooling, ROI Pooling)间添加特征金字塔网络(Feature Pyramid Networks, FPN)[11],实现对多尺度特征图的检测,结构如图2 所示,图中Fc 即Fully Connected Layer,红色框线内部为FPN 实现细节,其中P 代表不同尺度的特征图。
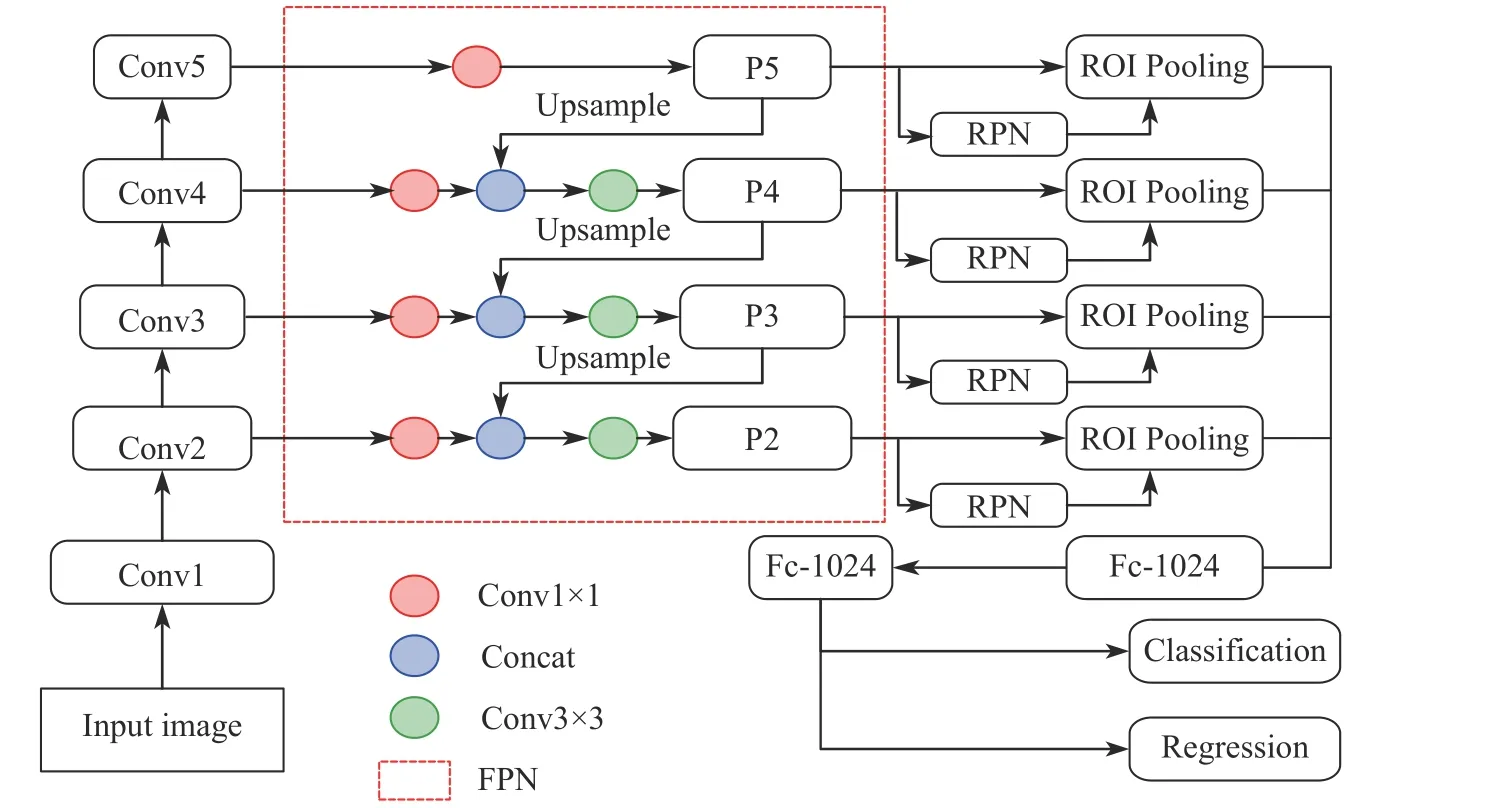
图2 改进的Faster R-CNN 结构Fig.2 Improved Faster R-CNN structure
在对图像内的目标完成提取任务后,本文使用训练好的骨干网络提取目标的视觉特征,用区域建议网络(Region Proposal Network, RPN)提取目标的位置特征将二者输出给多模态嵌入空间。其中,x为边界框的水平坐标,y标志垂直坐标,W为图片的宽,H为图片的高,m表示目标检测网络提取出的第m个实例。
1.2 文本特征提取
文本特征的提取需要先对文本实现定位,而后识别文本框内文本的语义,提取包括字符识别的结果及其置信度。由于气瓶瓶身具有竖立、斜放、平躺3 种姿态,所以瓶身上的文字同样具有多种方向。同时,瓶身文字多呈规则矩形,因此,本文选择了旋转文本检测网络(Rotation-Based Text Detection)[12]作为文本检测的模块,旨在能够从输入图片中分离出带有文本的文本框,然后送入CRNN(Convolutional Recurrent Neural Network)[13]模块完成文本识别。
文本检测模块结构如图3 所示,旋转文本检测网络沿用了Faster R-CNN 的思想,并为候选区域网络的候选框添加了方向参数,提出了旋转候选区域网络(Rotation Region Proposal Network, RRPN)。为平衡计算效率与收敛速度,锚框的方向参数设定为6 个值,大小基准设为8×8、16×16、32×32,每种框分别采用1∶1、1∶2、1∶5 这3 种长宽比。最后,不同大小的正样本候选框与特征图一起输入旋转区域建议池化层(Rotation Region of Interest Pooling, RROI)统一为固定尺寸,而后映射到特征图上,最后经过全连接层得到目标的类别。
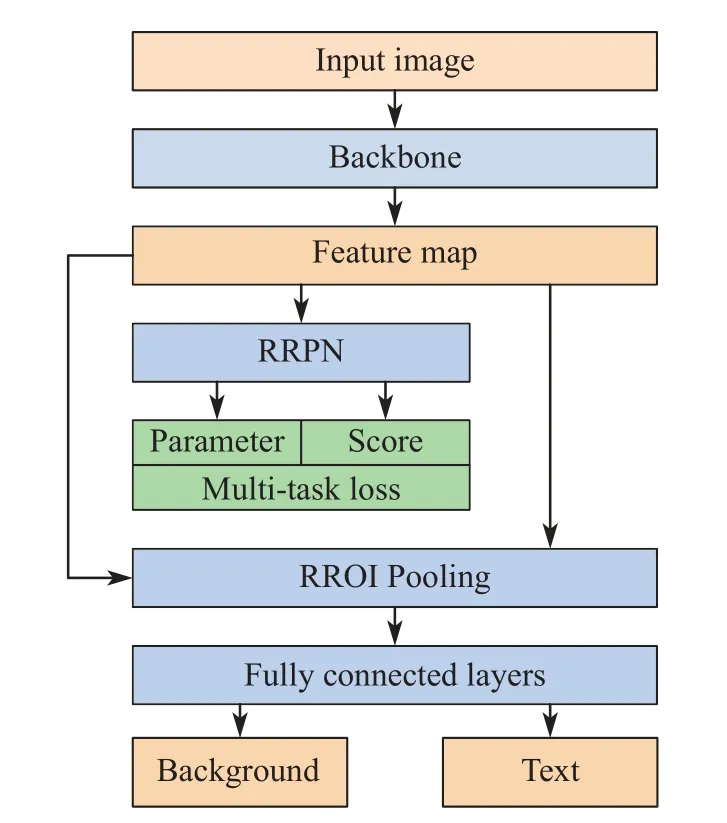
图3 文本检测网络流程图Fig.3 Flow chart of the text detection network
气瓶图像经旋转文本检测网络后,可以得到一组精确的文本框,而后将所有文本框输入CRNN 文本识别网络,得到气瓶图像的目标文本内容。文本识别网络结构如图4 所示。
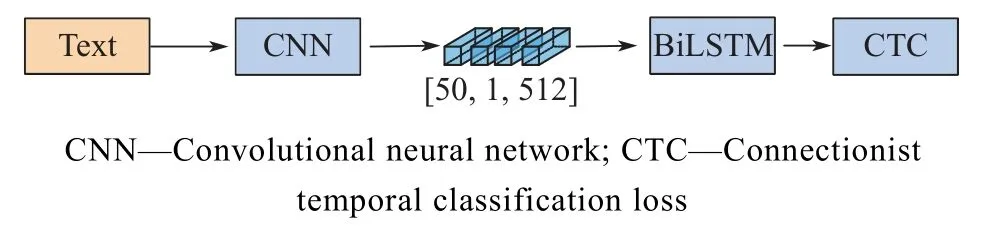
图4 文本识别网络结构Fig.4 Text recognition network structure
提取的文本依次经过卷积层、循环层与转换层。卷积层选用改进的VGG(Visual Geometry Group Network)网络,该结构用于提取带有字符的图片切片的卷积特征,为加快模型的收敛速度,在模型的第三、第五与第七个卷积层后加入批次标准化层;之后,循环层接收卷积层的输出进行文本预测。由于气瓶瓶身文字不清晰,本文选用了BiLSTM[14]网络,该方法可以提高模糊字符的识别率;最后,循环层的输出经过log_softmax 函数得到输出。log_softmax[13]见式(1),相比较于普通softmax,log_softmax 拥有保持数值稳定的特点,可以加快运算速度。
通过旋转文本检测网络检测出文本的位置信息与视觉信息,而后将定位的文本送入CRNN 文本识别网络识别出文本内容与文本置信度,最后将两个网络的输出一起输入多模态嵌入空间的OCR 嵌入层。
1.3 多模态嵌入空间
在神经网络中,嵌入层通常具有3 种用途[15]:(1)找到输入的最近邻向量;(2)用作模型的输入;(3)挖掘输入变量之间的关系。本文多模态嵌入空间接收图像态实体与文本态实体,并结合上一时刻的预测结果,将3 者映射到同一空间,得到了拥有丰富语义的映射结果,并将其输出给Transformer 模型用于单词的生成。
为了得到目标嵌入特征,多模态嵌入空间接收目标的视觉特征与位置特征,然后将视觉特征与位置特征输入目标嵌入空间(Object Embedding),如式(2):
为了得到文本嵌入特征,多模态空间接收文本的内容、文本置信度、文本视觉信息与位置信息,采用如下操作:(1)根据文本内容,提取300 维FastText[16]词向量特征与字符级别的金字塔直方图特征;(2)根据文本的视觉信息,使用与目标嵌入空间相同的目标检测器提取文本的视觉特征;(3)提取字符的位置信息与置信度,并将所有信息映射到OCR 嵌入空间(OCR Embedding),如式(3):
其中:W为要学习的映射矩阵;为输出的文本嵌入特征。
为得到上一时刻结果的嵌入特征,多模态嵌入空间接收上一时刻的输出单词,若单词来源为文本检测识别,则输出单词的文本特征;若单词来源为单词表,则输出单词对应的权重,最后得到结果。
根据多模态嵌入空间内的3 个模块,生成了目标特征、文本特征与上一时刻预测的特征,而后将3 者送入下一阶段的预测模型。
1.4 基于Transformer 的多模态融合预测
经多模态嵌入空间处理后得到了3 种模态的信息,而单词的预测依赖于多模态信息的融合。
Transformer[17]由多头注意力模块与前馈神经网络组成,其多头注意力模块可以将不同模态的信息统一,通过注意力机制完成模态间的交互融合,完成文本信息与图像特征的对齐,因此本文选取该结构完成序列化生成任务,其结构如图5 所示。
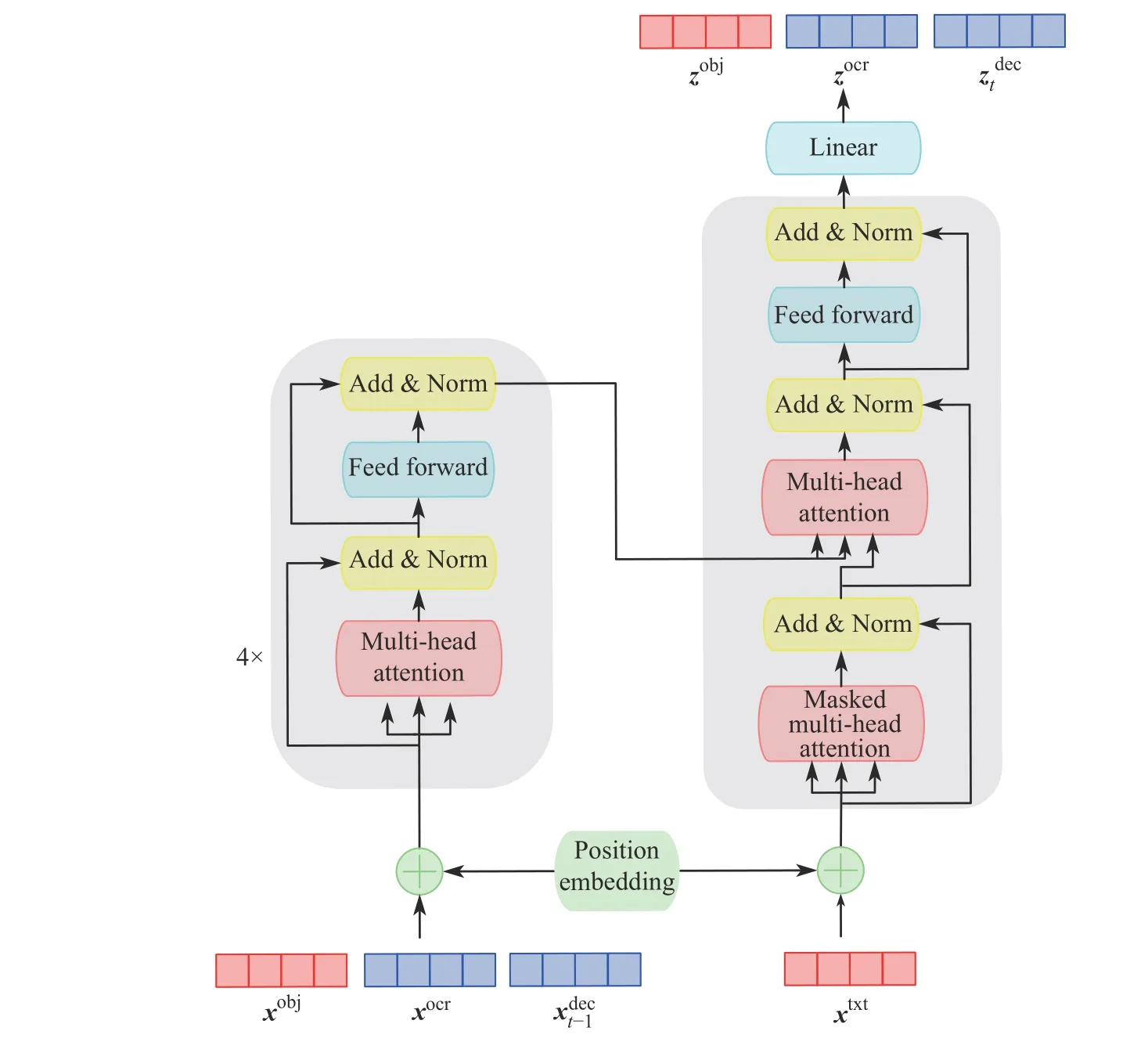
图5 基于Transformer 的多模态融合预测Fig.5 Multi-modal fusion prediction based on Transformer
通过多头注意力模块,每种模态的实体可以关注任意模态的其他实体,这使得通过相同的一组Transformer 参数可以实现模态内与模态间的关系建模,在预测输出时可以为更需关注的模态施加更高的权重。在训练过程中,将目标嵌入特征、文本嵌入特征与上一时刻的预测结果的嵌入特征一齐作为Transformer 编码端的输入,解码端输入单词的文本嵌入向量xtxt,如式(4):
其中:zobj、zocr、为各模态的特征向量。然而,t时刻的预测单词可能来源于单词表或是视觉文本。因此,可以通过式(5)预测该时刻输出来源为单词表不同单词的概率,通过式(6)预测来源为不同视
其中:Wvoc为词嵌入矩阵;Wocr为OCR 嵌入矩阵。
1.5 气瓶危险场景判断
模型生成描述语句后,本文判断的场景包含两类,如表1 所示。

表1 气瓶危险场景分类Table 1 Classification of cylinder dangerous scene
当描述语句中出现not secured 或without securing时,判断为第1 类危险场景;当描述中同时出现可燃性气体与还原性气体时,判断为第2 类危险场景。其中,常见的可燃性气体包括氢气、乙炔、氨气等,常见的助燃性气体如氧气。
2 实验分析
为验证本文所提方法的可行性,本文选用Linux 搭建实验平台,选用Ubuntu18.04 作为操作系统,GPU 选用NVIDIA GeForce GTX 2080Ti,CUDA10.1,CUDNN7.6,显存为11 GB,CPU 选用Xeon(R) Silver 4110 CPU @ 2.10 GHz,内存为16 GB。实验使用Pytorch深度学习框架进行模型的训练和测试,使用目标检测模型与文本检测识别模型对实验室气瓶图像提取特征,利用Transformer 多模态融合预测生成图像描述。
2.1 实验数据
当前图像描述的相关研究主要使用公共数据集,如COCO[18],Flickr8k,Flickr30k 等,包含多张日常图片,每张图片配有5 句人工标注的描述语句。但目前鲜有关于实验室气瓶的图像描述数据集,因此,本文通过自行现场采集、网络爬虫等方法进行数据集的收集工作,共计1000 张图片,训练集与验证集的比例为7∶3。数据集覆盖两种场景,其中包含安全场景550 张,危险场景450 张。安全场景中包含气瓶被固定图片470 张,气瓶可相邻放置图片80 张,危险场景中包含气瓶未固定图片380 张,气瓶不可放置图片70 张。
(1)气瓶图像检测数据集制作
为满足气瓶图像特征提取的需求,按照COCO公共数据集的标注格式对所有图片进行标注,本文标注的类别包含气瓶(Cylinder)、固定架(Carrier)、固定带(Strap)与气瓶柜(Cabinet),使用LabelImg 工具进行标注,而后以json 文件格式存储,图片标注实例如图6 所示。

图6 气瓶图像标签示例Fig.6 Example of cylinder image label
(2)气瓶文本检测识别数据集制作
常用的图像文本检测识别数据集有ICDAR2013、ICDAR2015[19]等,其中ICDAR2015 包含1000 张训练图片与500 张测试图片。因此,本文对气瓶图片进行文本标注,首先用LabelImg 工具标定文本位置,生成标定文件,然后编写python 脚本,将标定文件的格式转化为ICDAR2015 的格式:“x1, y1, x2, y2, x3, y3,x4, y4,label”,分别表示文本框的4 个顶点的位置以及对应的文本。
(3)气瓶图像描述数据集制作
根据实验要求,仿照COCO 图像描述数据集的格式对气瓶图像进行标注,由于目前没有自动标注工具,因此采用手动方法对每张图像标注5 句描述,每个语句都有唯一id 号,最终以json 格式的文件保存标注结果,每张图片对应1 个图片id 号与5 个语句id 号。
2.2 气瓶图像目标检测
由于气瓶图像数据集数量有限,故在训练Faster R-CNN 前对数据进行数据增强,增强方法包括添加高斯噪声、随机旋转、亮度调整等,以此增强模型的精确性与鲁棒性。同时,为提升检测精度,本文采用迁移学习的方法,首先加载模型的预训练权重,而后在气瓶数据集上进行微调,训练时的部分网络参数设置如表2 所示。

表2 部分网络参数Table 2 Parameters of part network
模型在训练集微调后再测试集评估性能。为验证模型改进的效果,进行了消融实验,将Faster RCNN 设为baseline,并将其与改进模型对比。评估指标采用平均准确率(MAP)与4 类目标的准确率(AP),实验结果如表3 所示。场景1 表示气瓶未被固定,场景2 表示气瓶相邻放置,场景3 表示数据集覆盖的全部场景。在场景1 中,气瓶主要在固定架上,且部分固定架没有固定带,因此相比于整体数据集,精度有所降低,但FPN 的添加使得尺寸较小的固定带的检测精度提升了10%;在场景2 中,固定架数量较少,实验不具有表现性,因此不进行展示。通过表3 结果证明,改进目标检测网络可以更精确地检测出目标实例。
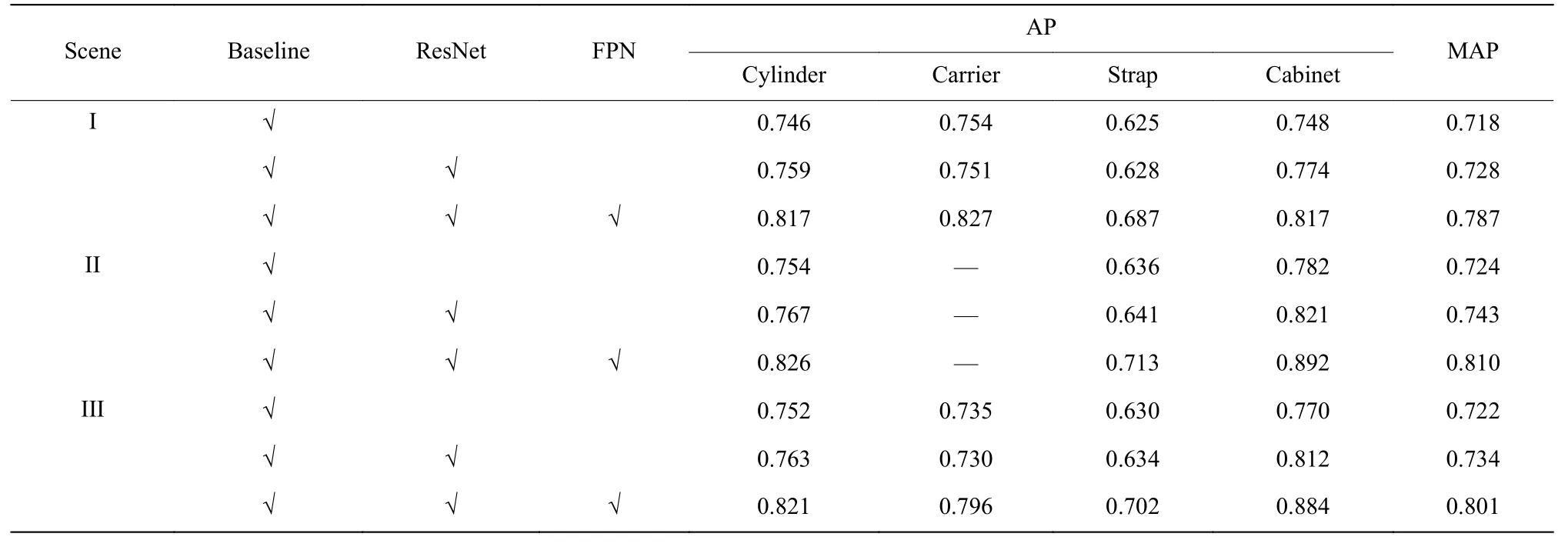
表3 在气瓶场景中不同目标检测算法的对比Table 3 Comparison of different object detection algorithms in cylinder scene
为了能够更加清晰地验证目标检测模型在气瓶数据集上的效果,将测试图片进行可视化,其结果如图7 所示。图7(a)示出了单独气瓶的检测效果,图7(b)、图7(c)示出了气瓶摆放在不同场景下的检测效果。图7(d)示出了多个气瓶场景的复杂场景。实验结果表明,本文方法可以适用于实验室气瓶场景,为后续生成描述奠定了良好基础。

图7 气瓶场景检测实验效果Fig.7 Results of object detection in cylinder scene
2.3 气瓶文字检测识别
在RRPN 中会生成大量旋转候选框,然而这些候选框内含有较多负样本,如果学习所有矩形框的参数会严重增加计算消耗。所以将候选框分为正样本与负样本,分类规则如表4 所示(其中IoU 为交互比,GT 为标签真实值),最后只有正样本参与模型的训练。本文将模型首先在ICDAR2015 进行训练得到预训练权重,然后在自制气瓶图像数据集上微调,初始学习率设置为0.005,学习衰减率为0.0001。模型的检测识别效果如表5 所示。通过检测效果证明,旋转文本检测模块可以对水平、倾斜多种姿态的文本实现定位,而通过识别效果证明CRNN模型可以在气瓶场景中识别瓶身上的表示气体类别的文字。

表4 正负样本判定规则Table 4 Positive and negative sample rule

表5 气瓶文本检测识别实验结果Table 5 Experimental results of text detection and recognition of cylinder
2.4 实验室气瓶图像描述生成
2.4.1实验设置 本文使用上述训练完成的目标检测模型提取每张图片内得分最高的10 个物体,并将文本检测识别模型提取的文本数量也设置为10。参考CNMT 模型参数设置,本文将多模态嵌入空间的维度设置为768,最大解码步骤设置为30。为在气瓶图像数据集上取得更好效果,模型首先在TextCaps[20]上预训练,而后在得到的权重上进行微调,优化算法使用Adam[21],学习率设置为0.0001,Batchsize 设置为16,最大训练迭代次数设置为500,在第200 次迭代与第300 次迭代时将学习率下降90%。
2.4.2评价标准 图像描述任务中常用的评价指标有:BLEU、ROUGE、CIDER 等[22]。BLEU 得分是通过计算生成描述与真值的重复N元数组的个数评估模型效果,高阶的BLEU 得分可以衡量出句子的流畅度;ROUGE 的基本思路与BLEU 类似,区别在于BLEU 计算的是准确率,而ROUGE 计算的是召回率;CIDER 是BLEU 和向量空间模型的结合,通过比较生成结果与真值的相似性来评价生成语句的效果。本文采用以上3 种评价指标对实验结果进行客观的定量分析,同时以人工评测的方式作为辅助,判断生成描述语句的质量。
2.4.3 实验结果分析 在气瓶图像描述数据集上,将本文模型与经典的图像描述算法Soft-Attention、Adaptive 等进行对比实验,并通过评价指标来评估算法的效果,实验结果如表6 所示。
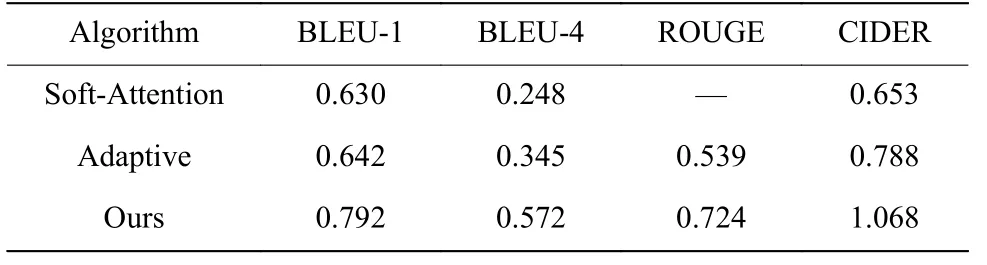
表6 本文算法与其他算法对比Table 6 Comparation between our method and other algorithms
从表6 可见,在气瓶图像数据集上,本文算法的提升效果比较明显,其原因在于在气瓶图像内,只有目标物对生成描述较为重要,而额外的背景会对描述生成造成负面影响;本文模型使用目标检测模型提取关键对象的特征作为后续输入,避免了额外信息的干扰;此外,气瓶瓶身上的文字对描述语义有着重要的意义,常规模型往往会忽视这些信息。本文模型提取了图片内的文本信息,并将其与目标特征、语义特征共同作为注意力模块的输入,构建了丰富的多模态空间,使得每一时刻预测生成的单词更加合理。
2.5 描述语句危险分析
为了根据规则判断描述的场景是否含有危险因素,本文选取了一些生成语句进行定性分析,结果如图8 所示。图8(a)示出的场景包含两个气瓶,其中一个在气瓶柜内,另一个则在气瓶柜外,本文模型抓住了不同的气瓶与气瓶柜之间的空间关系,其描述语句中包含not secured by 与without securing 关键词,描述出了气瓶没有被固定带安全固定的状态,可以根据语句判断该场景存在的风险;图8(b)示出的场景中存在有绿色气瓶与被遮挡的固定架,此外,也检测出了未被固定这一危险信息;图8(c)示出的场景中摆放了两个几乎重叠的气瓶,本文方法检测出气瓶的个数以及两个气瓶的前后关系,且两个气瓶均被固定,没有出现危险的词汇,因此可以判定为安全场景;图8(d)示出的场景中的气瓶柜中有两个被固定的气瓶,并检测出了气瓶的气体种类,在该场景中,N2与He 均为惰性气体,因此根据规则判定该场景安全。此外,为证明OCR 识别对本文所提方法的意义,本文分析每条描述语句中的每个单词来源。经分析,语句中的CO2、N2、O2 等表示气瓶储存气体类别的单词均来自于文本识别,这表明视觉文字的识别对描述的生成有着重要的作用。

图8 气瓶图像描述示例Fig.8 Examples of image caption in cylinder scene
3 结 论
本文针对实验室气瓶安全场景,提出了一种结合目标检测、文本检测识别的图像描述生成方法,首先使用Faster R-CNN 检测图像中气瓶等目标物,同时通过文本检测识别模块提取瓶身上的文字,而后将二者与上一时刻输出送入多模态嵌入空间,最后根据多模态输出结果,利用Transformer 预测生成语句。实验结果表明,本文方法在各项指标都取得了良好的结果,CIDER 达到了1.068;从描述结果分析,模型可以恰当地表达出图像内的内容,且从生成的语句中可以清晰地分析出场景内是否含有危险信息,辅助监控人员获悉危险场景的危险源与危险原因,进而采取有效措施预防危险的发生。然而,由于数据集中图片数量的局限性,模型的适配场景十分有限。接下来,将进一步扩大气瓶数据的收集,并进一步改进模型,提高模型的普适能力,以降低事故发生概率。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
劳动保护(2018年8期)2018-09-12 01:16:20
纤维复合材料(2018年4期)2018-04-28 08:45:48
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
中国质量万里行(2014年12期)2014-12-20 17:48:40
计算物理(2014年2期)2014-03-11 17:01:39
语文知识(2014年4期)2014-02-28 21:59:52
劳动保护(2014年1期)2014-01-02 03:15:25
