
基于特征降维和机器学习的覆膜冬小麦LAI遥感反演
2023-06-20 04:40谷晓博程智楷周智辉李汶龙杜娅丹
农业机械学报 2023年6期
谷晓博 程智楷 周智辉 常 甜 李汶龙 杜娅丹
(西北农林科技大学旱区农业水土工程教育部重点实验室, 陕西杨凌 712100)
0 引言
叶面积指数(Leaf area index,LAI)决定了作物对太阳辐射能量的拦截率,与作物生产力及产量密切相关,快速、准确评估作物LAI可为精准农业的建设、管理和调控提供科学依据[1-2]。传统实地测量LAI的方法具有破坏性,并且缺乏实时性和空间分布准确性[3]。相较于卫星遥感,低空无人机遥感具有较高空间分辨率;同时,操作简单,成本较低,更加适合农田尺度的作物信息采集[4]。目前无人机搭载的传感器主要包括可见光[5-6]、多光谱[7-8]、高光谱[9-10]和热红外相机[11-12]等。尽管传感器种类繁多,但相比而言,可见光波段所含与作物相关信息量较少[13]。高光谱影像过多的波段会造成信息冗余,数据量过大对计算机性能要求过高,其高昂的价格也不适用于普通大田作物监测[14]。热红外遥感在冠层温度的提取上仍有很大困难[15]。多光谱影像不仅在可见光基础上增加了红边和近红外波段,并且操作流程简单,成本低。
地膜覆盖技术能增温保墒,有效提高作物产量和水分利用效率,且成本较低。中国是世界上地膜用量最多、覆盖面积最大的国家[16],地膜用量从1991年的3×105t大幅增加到2017年的1.47×106t,地膜覆盖面积已达到1.84×107hm2,之后缓慢回落,2019年仍达到1.38×106t,总覆盖面积1.76×107hm2,约占农作物总播种面积的10.7%[17],准确监测覆膜冬小麦生长状况有利于调整施肥策略,发展绿色可持续的精准农业。地膜和土壤背景与冬小麦冠层光谱特性有较大不同[18],覆膜会对无人机遥感监测作物长势造成干扰,但目前研究主要集中在背景干扰项较少的情况下进行,关于无人机遥感对地膜覆盖下作物生长状况监测的研究还鲜有报道。
利用统计学方法,建立实测作物生长参数和遥感植被指数(Vegetation indices,VIs)之间的拟合回归模型是预测作物LAI的常用手段。近年来随着计算机领域的发展,许多先进的机器学习算法被用来建立LAI-VIs反演模型,监测作物生长状况。例如,支持向量机、随机森林、梯度上升和人工神经网络等[2,8,11]预测作物LAI的效果良好,相较于传统统计模型,这些算法能够深度挖掘作物生长信息和遥感数据之间的联系,对于机器学习模型而言,输入特征维度数量会影响模型预测精度和泛化能力[19],但大多研究未考虑植被指数的筛选或采用单一的简单特征降维方法[20-22]。随着植被指数种类的不断增加,如何快速选择在不同生长环境等多因素干扰下对模型训练有利的特征变量有待进一步研究。
本研究以无人机多光谱遥感数据为基础,对出苗期、越冬期、返青期、拔节期、抽穗期和灌浆期覆膜冬小麦LAI进行监测,利用监督分类剔除背景,使用相关系数法、主成分分析、决策树排序和遗传算法4种特征降维方法筛选植被指数,得到最优特征子集,并耦合偏最小二乘、岭回归、支持向量机、随机森林、梯度上升和人工神经网络6种机器学习算法建立覆膜冬小麦LAI反演模型(LAI-VIs),以期为西北地区覆膜冬小麦田间管理提供科学依据和技术支持。
1 材料与方法
1.1 试验设计
研究区(图1)位于陕西省杨凌区西北农林科技大学旱区农业水土工程教育部重点实验室(34°17′38″N,108°04′08″E,海拔521 m)。该区属于温带大陆性气候,多年平均气温12.9℃,年平均降水量602 mm(主要集中于7—9月),蒸发量1 510 mm。研究区内地势平坦,种植方式以玉米和小麦轮作为主。冬小麦在2021年10月18日播种,2022年6月7日收获,种植品种为“小偃22”。为增强反演模型在异质性农田上的普适性,本研究在40 m×20 m的垄沟覆膜冬小麦种植区域内,选择 30个面积均为4 m×4 m的冬小麦样区进行研究。
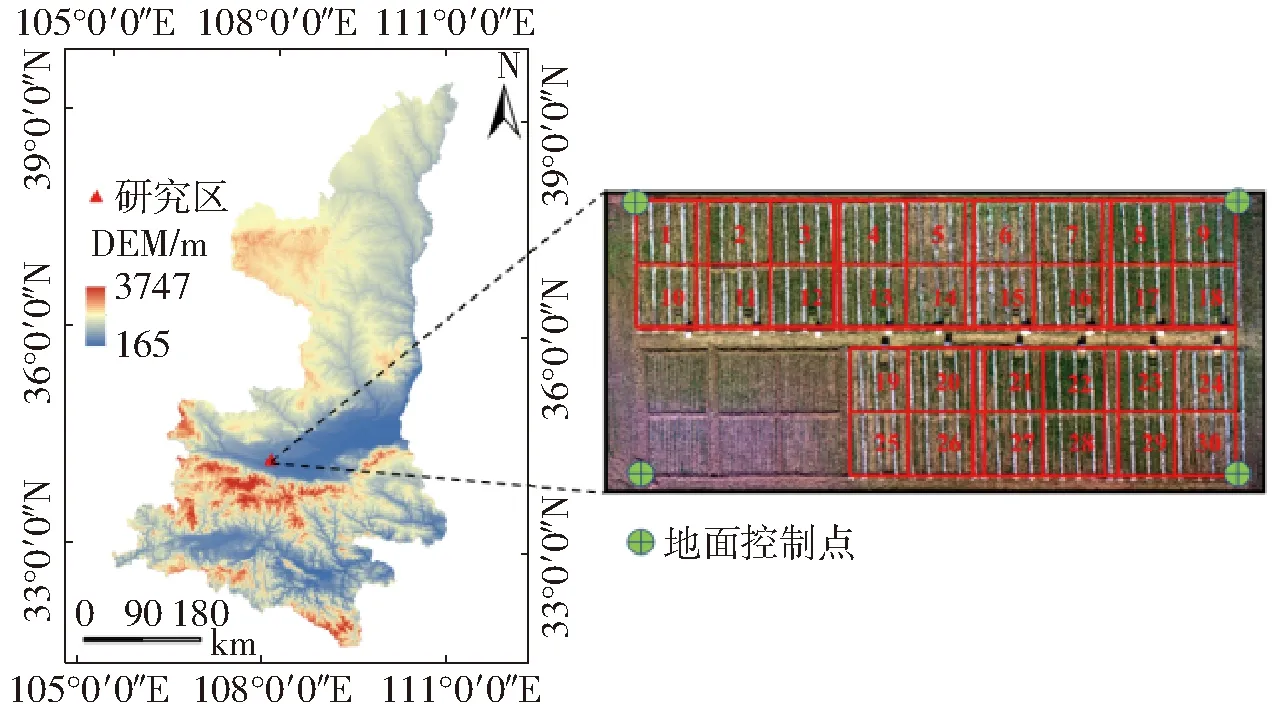
图1 研究区位置和小麦田无人机影像Fig.1 Location of study area and UAV image of wheat field
1.2 数据获取
1.2.1地面实测数据
在冬小麦出苗期(2021年11月23日)、越冬期(2022年1月13日)、返青期(2022年3月6日)、拔节期(2022年3月30日)、抽穗期(2022年4月20日)和灌浆期(2022年5月11日)进行地面采样。每个样区选取10株长势均匀且具有代表性的冬小麦,利用长宽系数法计算单株叶面积,即二者乘积之和乘以折算系数(0.75),最后根据单位面积株数求得该小区冬小麦LAI,计算式为
(1)
式中ρ——单位面积株数,cm-2
m——测定株数
n——第i株冬小麦的总叶片数
Lij、Bij——每片叶片完全展开时的最大叶长和叶宽,cm
1.2.2无人机遥感数据获取及预处理
使用大疆精灵4多光谱版一体化无人机于每次地面采样试验同期获取冬小麦冠层多光谱影像数据。该无人机配有6个2.9英寸影像传感器,其中1个彩色传感器用于常规可见光成像,5个用于多光谱成像的单色传感器:蓝((450±16) nm)、绿((560±16) nm)、红((650±16) nm)、红边((730±16) nm)和近红外((840±26) nm),单个传感器有效像素可达到208万。考虑无人机电池飞行时间和测区面积以及计算机性能因素,设计飞行高度20 m,航向重叠率80%,旁向重叠率80%,多光谱相机镜头垂直向下正射作物冠层,数据采集选取晴朗无云或少云无风的天气,具体飞行时间和气象信息见表1。为生成准确的作物反射率信息,共设置4个地面控制点位于小麦田四角(图1),将获得的无人机影像和控制点的坐标数据导入Pix4Dmapper软件对遥感图像进行拼接和控制点的手动配准校正,然后利用ENVI软件合成5波段图像,使用两块固定反射率校正板(反射率25%、50%)进行辐射定标,得到各波段地物反射率。

表1 无人机飞行时间和气象信息Tab.1 UAV flight time and weather information
由于地膜和土壤背景与作物冠层光谱特性不同,为防止混合像元对反演精度的影响,使用基于支持向量机的监督分类对遥感影像进行地物分割,通过目视解译手动划分地膜、土壤和冬小麦3种地物类型构成训练集,设置核函数为径向基函数(Radial basis function,RBF),剔除地膜和土壤背景后得到各小区冬小麦冠层平均反射率。并选择50种常用的植被指数,考虑到近红外波段相较于可见光波段蕴含更多的植被生长信息[23],共有可见光大气阻力指数(Visible atmospheric resistance index,VARI)、归一化差异绿度植被指数(Normalized difference greenness vegetation index,NDGI)、绿红植被指数(Green red vegetation index,GRVI)、归一化绿红差异指数(Normalized green red difference index,NGBDI)、过绿指数(Excess green,ExG)、可见光差异植被指数(Visible differential vegetation index,VDVI)、过红指数(Excess red,ExR)共7种可见光植被指数[24-26]和最优植被指数(Optimal vegetation index,VIOPT)、增强型叶绿素植被指数(Transformed chlorophyll absorption in reflectance index,TCARI)、叶绿素吸收比植被指数(Modified chlorophyll absorption in reflectance index,MCARI)、结构不敏感色素指数(Structure insensitive pigment index,SIPI)、增强型归一化植被指数(Enhanced normalized difference vegetation index,ENDVI)、归一化绿指数(Normalized green index,NGI)、归一化红指数(Normalized red index,NRI)、比值增强植被指数(Ratio enhanced difference vegetation index,REDVI)等43种包含近红外波段的植被指数[27-32]。
1.3 特征降维方法
特征降维包括特征提取和特征选择两种方式。特征提取是从已有特征中计算出新的特征集合,例如主成分分析法和线性判别方法。特征选择是指从已有的特征中选择出多个有效特征,构成最优特征子集,通常分为过滤法(Filter)[33]、嵌入法(Embedded)[34]和包装法(Wrapper)[35]。为分析各种特征降维方法对模型精度的影响,本研究选择主成分分析[36]、相关系数法[30]、决策树排序[37]和遗传算法[24]4种特征降维方法对植被指数进行筛选。
1.4 模型构建与精度验证
1.4.1模型构建
选择5种常见且性能良好的机器学习算法进行建模分析,分别为偏最小二乘法(Partial least squares,PLSR)、岭回归(Ridge regression,RR)、支持向量机(Support vector machine,SVM)、随机森林(Random forest,RF)、梯度上升(Extreme gradient boosting,XGBoost)和人工神经网络(Artificial neural network,ANN)算法[21-22,27-28,30],以上模型均基于Python 3.6的Scikit-learn机器学习库构建。
1.4.2精度验证
为了尽可能避免出现严重过拟合现象,在模型训练过程中采用十折交叉验证(Cross-validation)的方法训练模型,并结合网格搜索(Grid search)来获取模型的重要参数。
采用决定系数(Coefficient of determination,R2)、均方根误差(Root mean square error,RMSE)和平均绝对误差(Mean absolute error,MAE)[23]评价模型精度和误差,R2越接近1,RMSE和MAE越接近0表示预测值和实测值之间的误差越小,模型反演精度越高。
2 结果与分析
2.1 LAI统计特征
总体上,覆膜冬小麦LAI均值从出苗期至抽穗期随着生育期的推移而增大,在抽穗期达到峰值,为5.36,而抽穗-灌浆期冬小麦LAI逐渐降低(图2,图中不同小写字母表示处理间差异显著(P<0.05))。经方差分析,除出苗期和越冬期外,各生育期冬小麦LAI之间均存在显著性差异(P<0.05)。覆膜冬小麦LAI数据总体样本、训练集和测试集划分结果如表2所示。共采集180个LAI样本,为使模型得到充分的学习和训练,并测试模型精度,参考先前研究[23,38],按照比例8∶2划分训练集144个,测试集36个,LAI总体变化范围为0.20~10.10,数据集LAI变异系数均不小于0.90,说明实测冬小麦LAI变异性较强,能够为模型精确反演提供数据基础。
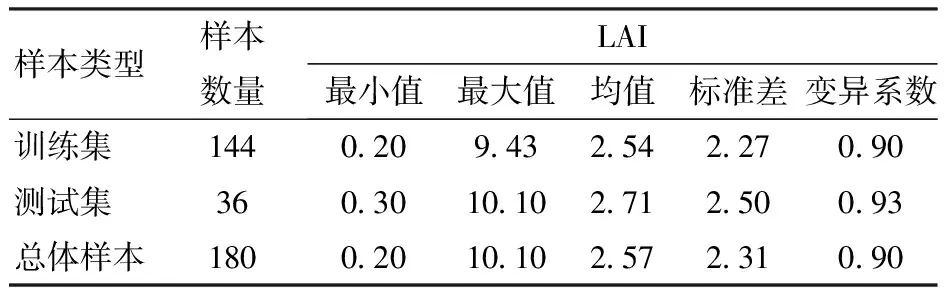
表2 数据集分割结果Tab.2 Data set segmentation results
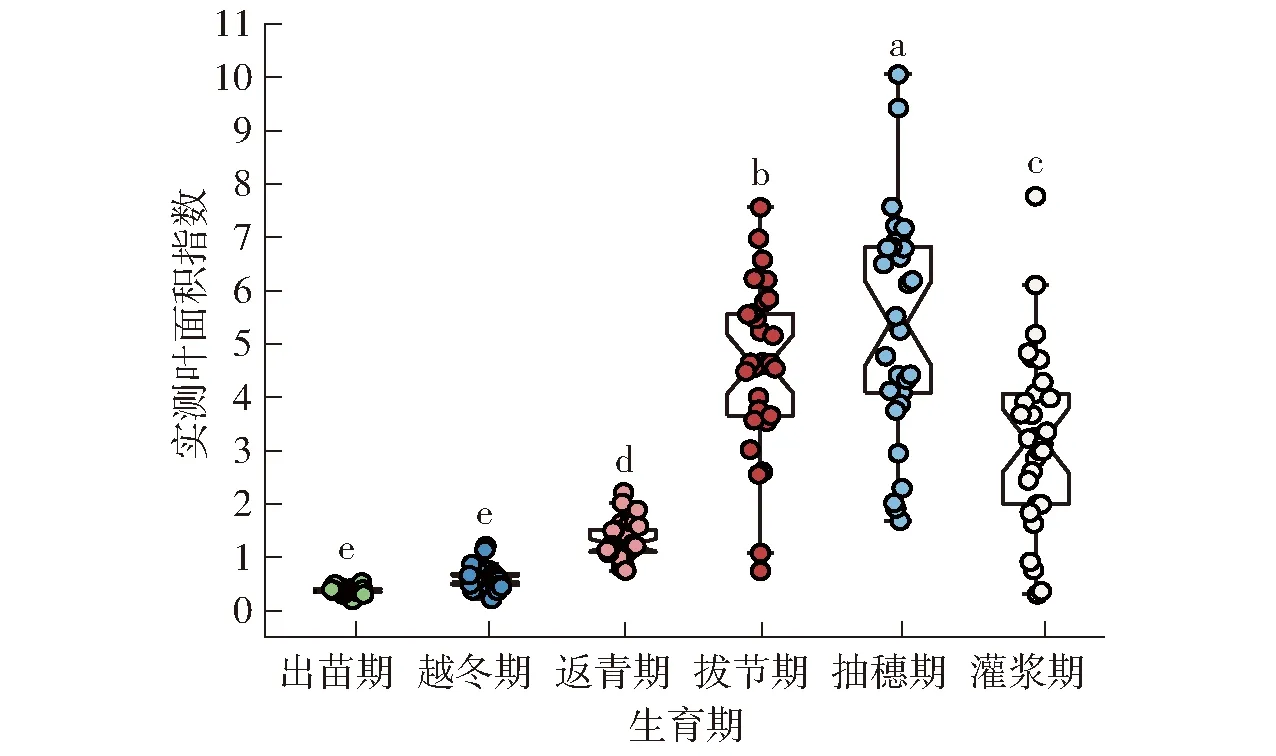
图2 覆膜冬小麦不同生育期叶面积指数变化趋势Fig.2 Trend of leaf area index in winter wheat at different growth stages
2.2 剔除背景前后波段反射率变化
基于支持向量机的监督分类剔除地膜和土壤背景后,重新提取作物冠层光谱反射率和未剔除前反射率进行对比。从图3可以看出,在剔除背景前后,反射率均随波长增加呈先增后降,最后明显升高的趋势,在可见光区域呈现“绿峰红谷”现象,近红外波段730 nm和840 nm的冬小麦冠层反射率则明显高于可见光波段。随着生育期的推移,从出苗期至拔节期,冬小麦反射率总体呈逐渐降低趋势,而拔节期至灌浆期,则呈逐渐上升趋势。
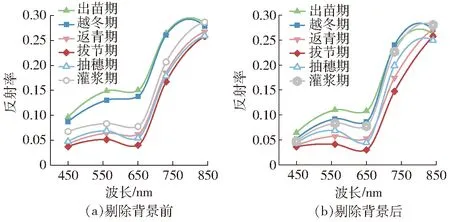
图3 不同生育期波段反射率曲线Fig.3 Band reflectance curves at different growth stages
对比图3a、3b发现,剔除背景使冬小麦在出苗期和越冬期冠层反射率降低,尤其是在可见光区域,变化范围分别从0.09~0.15和0.08~0.14下降至0.06~0.11和0.05~0.09,是因为裸露的土壤和地膜背景对可见光的反射率均比作物冠层反射率高,在剔除地膜和土壤背景后造成冠层光谱反射率下降。越冬期后,剔除背景前后反射率变化范围和趋势近似相同,表明在高植被覆盖度下,地膜和土壤背景对光谱反射率的影响较小。
2.3 LAI反演模型精度评价
2.3.1特征降维结果
通过主成分分析从50种植被指数中提取出新的主成分特征,计算得到各主成分方差贡献率(表3),选取累计方差贡献率大于80%的主成分作为输入特征变量,故选择累计方差贡献率为88.39%的主成分1、2进行LAI反演。
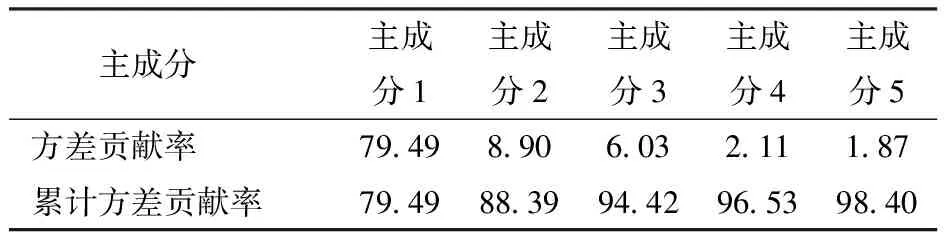
表3 主成分分析方差贡献率Tab.3 Principal component analysis variance contribution rate %
计算50种植被指数和LAI的相关系数,绘制相关系数热图(图4)。从图4可以看出,大多数植被指数与LAI具有正相关性,其中VIOPT与LAI相关性最强,相关系数达到0.68,选择相关系数不小于0.5的植被指数作为输入特征变量。GRVI、NGBDI、ExR、VDVI、EXG、TCARI、MCARI、SIPI、ENDVI、NGI、NRI 11种植被指数与LAI相关系数小于0.5,这些多为可见光植被指数,说明可见光波段与冬小麦LAI的相关性不如近红外波段。
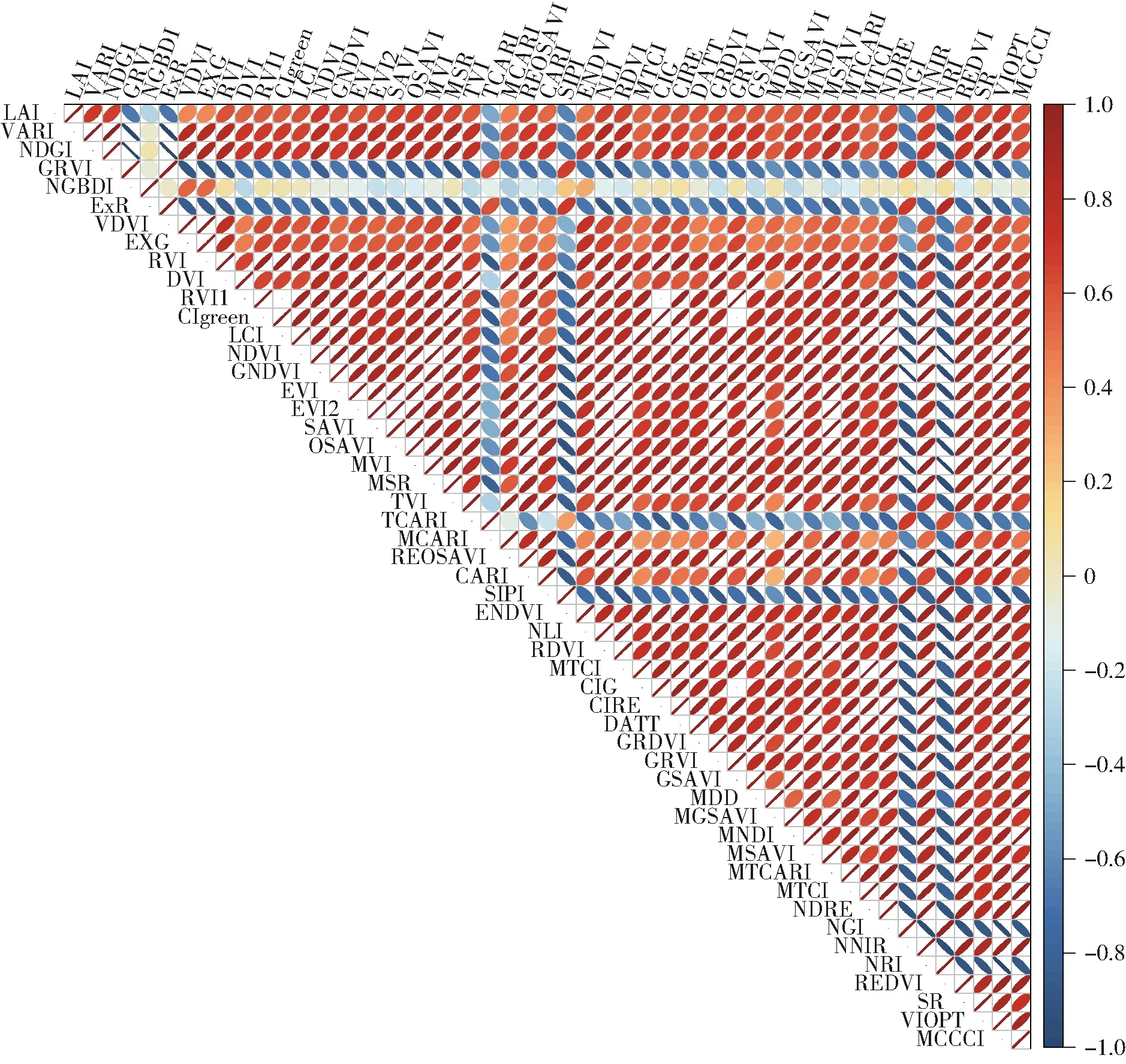
图4 植被指数与叶面积指数相关系数热图Fig.4 Heat map of correlation coefficients between vegetation index and leaf area index
考虑到决策树采用Bagging的随机放回取样方法,模型运行的结果往往不一致,为得到更加具有代表性的结果,设置决策树模型运行50次,选择累计重要性大于50%的9个植被指数作为输入变量,并对特征重要性进行排序(图5)。从图5可以看出,特征重要性均值最高的植被指数为SIPI,达7.42%,最低为REDVI,达4.22%,说明各植被指数对于模型重要度的占比较为均匀,并不存在特征重要性占比明显高于其他变量的植被指数。

图5 植被指数特征重要性排序Fig.5 Rank of feature importance of vegetation index characteristics
遗传算法在特征选择中可以对不同的模型选择出最优特征子集,其筛选结果如图6所示。从图6可以看出,RF、XGBoost和ANN分别选择7、10、13种植被指数,数量普遍多于PLSR、RR、SVM统计模型。4种机器学习算法均选择VIOPT指数,结合图4可知,该指数与LAI相关系数达到0.68,在50种植被指数中与LAI相关性最强,进一步说明VIOPT是LAI反演模型构建的关键特征变量。
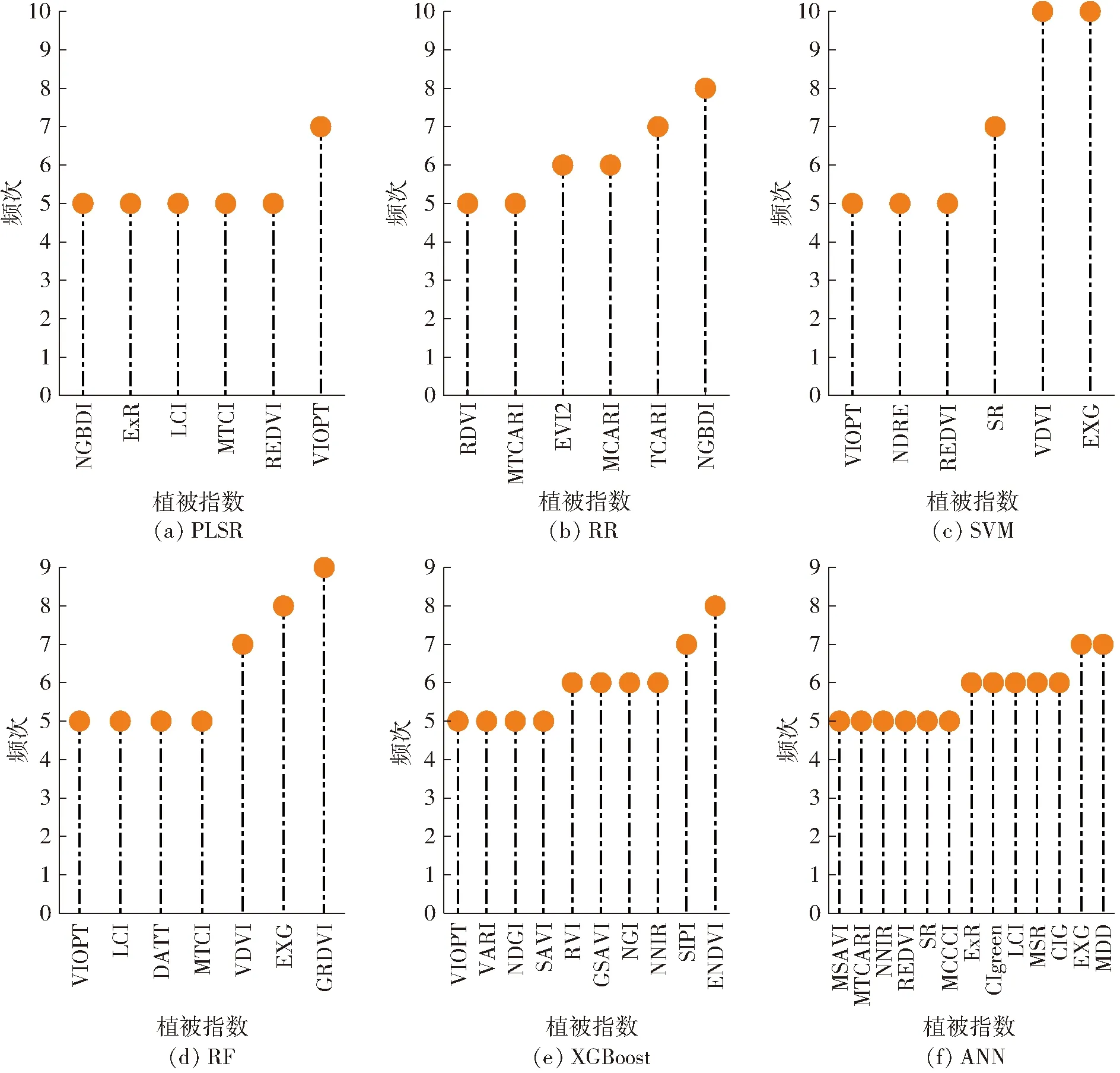
图6 不同反演算法结合遗传算法筛选结果Fig.6 Different inversion algorithms combined with genetic algorithms used to screen results
2.3.2LAI估算模型反演效果

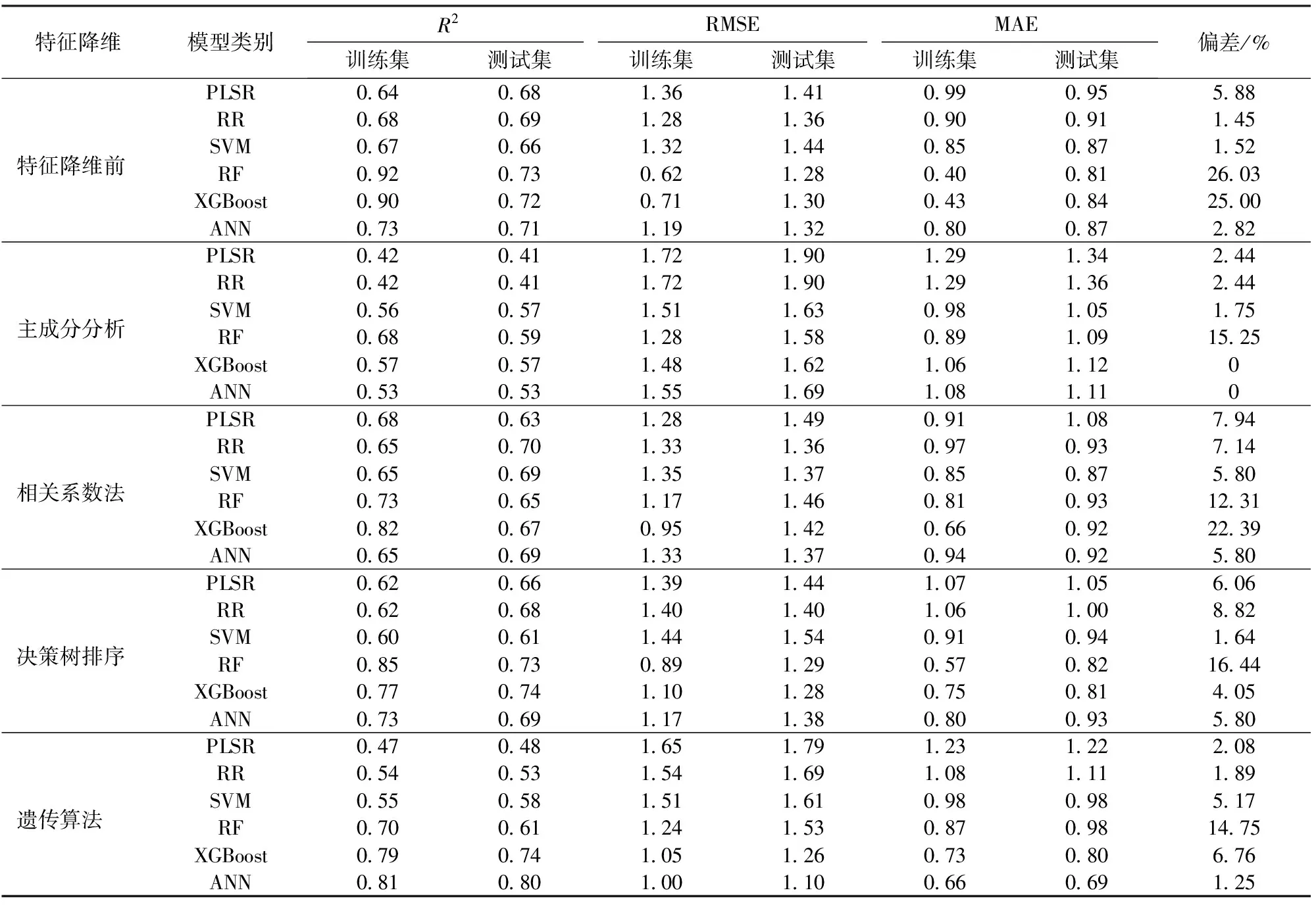
表4 覆膜冬小麦LAI反演精度评价Tab.4 Evaluation of LAI inversion accuracy of winter wheat covered with film
特征降维前,RF在训练集(R2=0.92,RMSE为0.62,MAE为0.40)和测试集(R2=0.73,RMSE为1.28,MAE为0.81)上得分最高,其次为XGBoost和ANN,在训练集和测试集上R2均高于0.71,而PLSR、RR、SVM 3种统计方法R2最大值为0.69。PLSR、RR、SVM在训练集和测试集上偏差分别为5.88%、1.45%和1.52%,RF、XGBoost偏差则高达26.03%和25.00%,表明传统统计模型稳定性更好,复杂机器学习算法预测能力强,但稳定性较差。
特征降维后,主成分分析和相关系数法优化效果较差,主成分分析后的PLSR和RR在训练集和测试集上的R2甚至低于0.50,相关系数法筛选后除XGBoost外,其余5种模型偏差均有所增加,稳定性下降。基于决策树特征重要性排序后的植被指数构建LAI反演模型,发现PLSR、RR和SVM反演精度略有下降,但增强了RF和XGBoost两种基于树模型机器学习算法的稳定性,相较于特征降维前偏差降低9.59、20.95个百分点。而遗传算法+ANN模型训练集精度R2=0.81,RMSE为1.00,MAE为0.66,测试集精度R2=0.80,RMSE为1.10,MAE为0.69,偏差仅为1.25%,说明其反演精度高且稳定性良好,为覆膜条件下冬小麦LAI最优反演模型。
对比遗传算法和不同机器学习的耦合反演效果可以看出(图7),相较于特征降维前,PLSR、RR和SVM 3种统计方法反演效果较差,甚至误预测出部分负值,训练集和测试集的反演精度R2均低于0.60,RF、XGBoost和ANN的反演效果得到明显改善,尤其是XGBoost和ANN模型达到了最佳状态。对比决策树排序+RF反演精度,遗传算法+RF模型训练集从R2=0.92,RMSE为0.62,MAE为0.40下降至R2=0.70,RMSE为1.24,MAE为0.87,测试集从R2=0.73,RMSE为1.28,MAE为0.81下降至R2=0.61,RMSE为1.53,MAE为0.98,说明决策树排序更适用于RF这种基于树模型的机器学习算法。
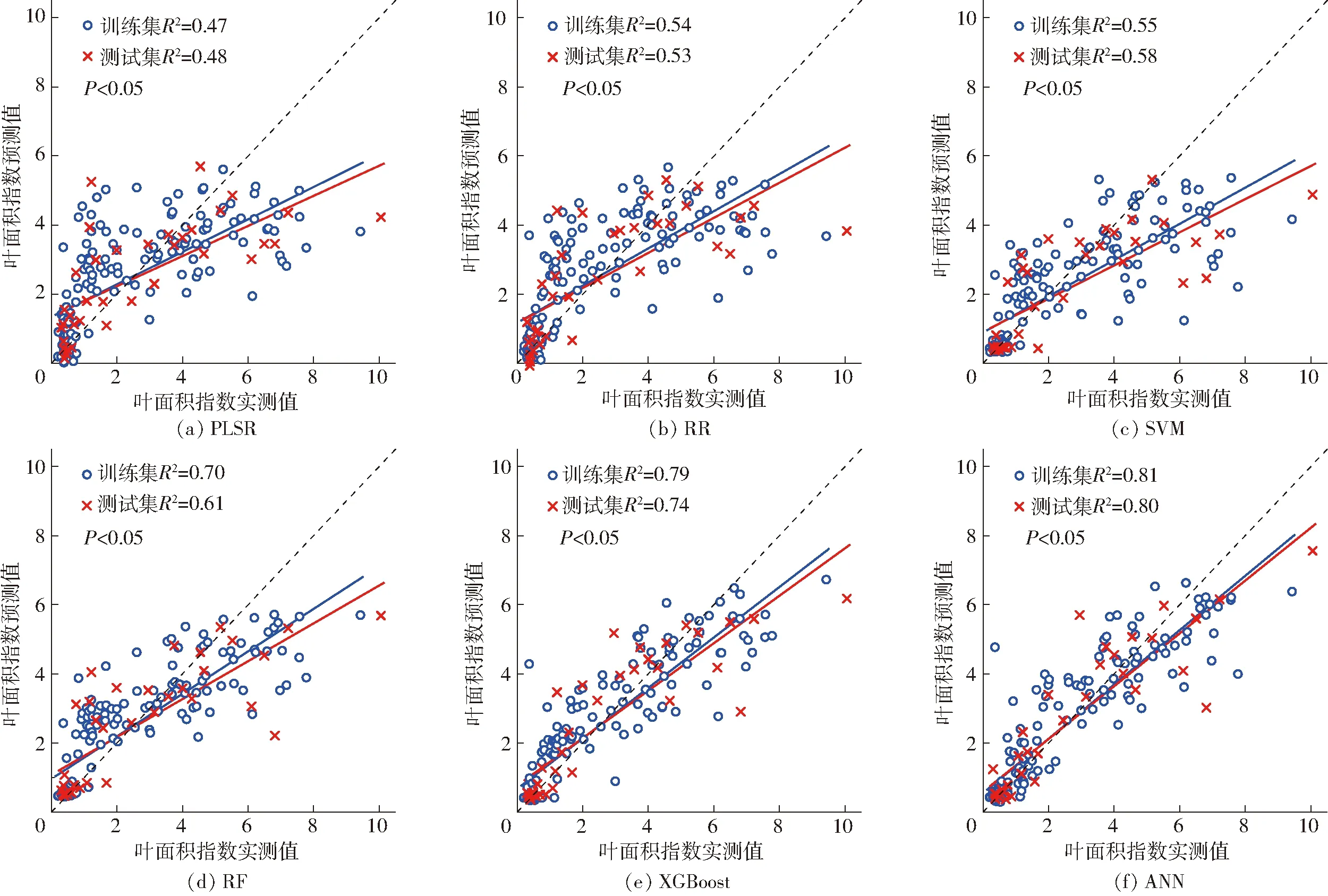
图7 遗传算法筛选后覆膜冬小麦叶面积指数反演效果Fig.7 Inversion effect of leaf area index of winter wheat screened by genetic algorithm
3 讨论
本研究利用无人机多光谱遥感数据反演覆膜冬小麦LAI,在剔除背景后基于4种特征降维方法和6种机器学习算法建立了24个覆膜冬小麦LAI反演模型,分析不同组合的反演精度,发现不同输入特征变量和算法对反演效果影响较大。
3.1 剔除背景前后各波段反射率变化
本研究剔除背景前后冬小麦冠层反射率总体呈“高-低-高”现象,从出苗期至拔节期,冬小麦反射率总体呈逐渐降低趋势,而拔节期至灌浆期呈逐渐上升趋势。与前人研究对比可发现,在小麦营养生长阶段,LAI和叶绿素含量增加,作物光合能力增强,对可见光的吸收能力增强,冠层反射率降低,一般至抽穗期达到最小值[39]。灌浆期冬小麦养分和干物质由营养器官向籽粒转运,LAI和单位面积叶绿素含量降低,可见光反射率升高[40],且小麦穗粒和麦秆的多重散射会提高近红外波段反射率[41],但在图3b剔除背景后灌浆期近红外波段反射率仍低于出苗期,原因可能为:①抽穗-灌浆期试验区域杨柳絮较多,部分附着在麦穗或叶片上,影响了小麦群体的反射率。②本研究中无人机获取数据的飞行高度为20 m,分析无人机影像数据后确定无人机可用于覆膜冬小麦LAI遥感监测;但参考前人研究[28,42]并结合试验区杨柳絮干扰,可推测20 m不是反演覆膜冬小麦LAI的最佳无人机飞行高度,在后续研究中需针对性设计试验并寻找最佳的飞行高度,以利于覆膜冬小麦LAI反演。此外,本研究通过监督分类剔除土壤和地膜背景后,出苗-越冬期波段反射率较剔除前下降,主要由于试验采取垄沟覆膜的种植方式,地膜和土壤背景对光谱反射率的影响主要在生长前期,在越冬期后,冬小麦冠层覆盖度提高,背景对波段反射率的影响逐渐减小,这也进一步证实了在作物生长前期,采用无人机遥感监测作物生长状况剔除背景的必要性。
3.2 不同特征降维和机器学习模型差异
对比特征降维前LAI反演效果可知,主成分分析能提高模型稳定性,但降低了反演精度,原因是主成分分析假设特征变量方差越大则信息量越大,排除方差和信息量小的无关噪声特征以提升稳定性,但完全不考虑因变量的影响,会导致部分方差较小但对模型反演影响较大的特征被排除,造成模型精度欠佳[36]。相关系数法只能表征两变量间的线性相关程度,植被指数和LAI之间的关系是复杂非线性的,且部分植被指数间的强相关性(图4)会造成模型精度降低。决策树筛选只适用于基于树模型的RF和XGBoost算法,能有效提高模型泛化能力,对其他机器学习算法无优化作用。遗传算法作为一种进化算法能有效改善RF、XGBoost和ANN模型反演效果,遗传算法优化后的ANN模型也成为覆膜条件下冬小麦LAI最优反演模型。此外,4种机器学习算法的遗传算法筛选结果中都包含VIOPT指数,主要是由于VIOPT指数考虑光照条件、土壤背景和测量平台振动引起的测量噪声等多因素对反演效果的干扰[43],能有效克服混合像元对冬小麦冠层反射率的影响,在覆膜冬小麦LAI估算中具有巨大潜力。VIOPT的高频次出现也表明遗传算法具有良好的全局搜索能力和稳定性,对于多种机器学习算法均能筛选出对模型构建极为重要的植被指数。
对比6种反演模型的反演效果可知,在特征降维后呈现RF、XGBoost和ANN反演精度更高的现象,这与NARMILAN等[30]的研究结果一致,表明先进的机器学习算法能有效提高遥感反演精度。PLSR、RR和SVM偏差更小,虽然其具有较高的稳定性,但受限于模型预测能力,特征降维不能提高这3种方法的LAI反演精度。此外,不少学者在作物LAI遥感监测的研究中引入了机器学习方法来构建模型[20,28,38],并取得了较好的反演效果,但大多未考虑特征变量的选择或使用简单的阈值法筛选植被指数,并对不同的模型均使用同一种方法选择出的植被指数作为输入特征。本研究采用特征降维和机器学习的耦合算法是对已有研究的进一步优化,更加提升了无人机多光谱反演作物生长状况模型的预测能力和精度。
本研究仅使用“小偃22”冬小麦一年的数据,且无不覆膜的冬小麦样区作为对照,未来应考虑不同品种冬小麦在覆膜条件下LAI的反演效果,并增加不覆膜样区进一步验证剔除背景对模型反演的重要性。无人机飞行高度也会影响冠层反射率提取精度,还应设置不同飞行高度,探究覆膜冬小麦LAI遥感反演的无人机最佳飞行高度。
4 结论
(1)覆膜冬小麦LAI遥感反演中剔除生长前期地膜和土壤背景能使冠层反射率降低,更接近真实值,有利于模型反演精度的提升。
(2)主成分分析和相关系数法无法提高覆膜冬小麦LAI模型的反演效果,决策树筛选适用于基于树模型的RF和XGBoost算法,能有效提高模型泛化能力,遗传算法对XGBoost和ANN优化效果明显,最优反演模型为遗传算法优化的ANN,测试集R2为0.80,RMSE为1.10,MAE为0.69,偏差仅有1.25%。
猜你喜欢
车主之友(2022年4期)2022-08-27
中国农业信息(2022年1期)2022-05-25
农业机械学报(2021年11期)2021-12-07
大气科学(2021年1期)2021-04-16
海峡姐妹(2019年12期)2020-01-14
农业机械学报(2019年6期)2019-06-27
水土保持研究(2018年5期)2018-10-12
中国农业信息(2018年2期)2018-07-28
农业环境科学学报(2017年2期)2017-03-20
西藏科技(2015年1期)2015-09-26
