
基于改进Transformer的结构化图像超分辨网络
2023-05-16 11:06:24吕鑫栋李娇邓真楠冯浩崔欣桐邓红霞
浙江大学学报(工学版) 2023年5期
吕鑫栋,李娇,邓真楠,冯浩,崔欣桐,邓红霞
(太原理工大学 信息与计算机学院,山西 太原 030024)
图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域.人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息.人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义.近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1]的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2],已有不少学者提出可以利用图像的结构化特征进行图像重建.Ma等[3]利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征.Zhang等[4]提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征.局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系.徐永兵等[5]提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量.上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上.
基于深度学习的结构化图像SR算法可以归纳为以下2个方面.1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6]提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7]提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8]提出利用渐进式上采样来逐步获取高倍率的人脸图像.这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高.2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程.Chen等[9]提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果.与文献[9]使用先验信息类似,Zhang等[10]提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理.对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络.Yin等[11]提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建.Kim等[12]利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份.刘朋伟等[13]利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像.基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上.
针对上述SR方法存在的问题,提出一种基于改进Transformer的结构化图像超分辨率网络(structured image super-resolution network based on improved Transformer,TransSRNet):1)融合沙漏块构成的空间注意力单元和Swin Transformer构成的残差Transformer块对图像进行超分辨重建.沙漏块负责提取图像映射过程中的结构化信息并生成注意力矩阵,使得空间注意力模块重点关注具有结构化信息的区域,而Transformer弥补了沙漏块在关注图像结构化特征时对全局上下文表征能力的不足,二者在功能上相互补充;2)利用通道注意力层ECA模块减少网络对冗余通道的关注;3)联合像素损失、SSIM损失和风格损失对网络进行训练.本研究提出的网络一方面利用Transformer的自注意力机制提高重建效果的真实度;另一方面,沙漏块结构可以不受特定结构化图像先验信息的约束,即使在不同的结构化图像数据集上,也能保持较好的重建效果.
1 相关工作
1.1 沙漏块网络
Newell等[14]提出利用沙漏块(hourglass block,HB)进行人体姿态估计.HB是对称结构,在下采样过程和上采样的过程中的网络层存在一一对应的关系.HB将多个卷积层紧密相连,有利于处理多尺度的结构化信息,能够有效地处理和整合跨尺度的特征,HB网络结构如图1所示.利用卷积层将特征分辨率逐步缩小;在对称层之间进行跳跃连接,在跳跃连接中对原来尺度的特征进行卷积;得到低分辨率特征后,网络开始进行上采样,并逐渐结合不同尺度的结构化特征信息,将2个不同的特征集进行逐元素相加后得到输出特征.人脸图像超分辨重建网络FSRNet[9]使用HB构建先验预测子网络,对人脸几何先验信息进行预测,从而辅助人脸图像的恢复.
1.2 Transformer
Transformer[15]的多头自注意力层和前反馈MLP层堆叠起来容易捕捉单词之间的远程相关性.受到Transformer在自然语言处理(natural language processing,NLP)领域的激励,人们尝试着探索和利用Transformer在各种视觉任务中的优势,以强调提取全局特征的重要性.Dosovitskiy等[16]提出的Vision Transformer,它将16×16图像块视为序列,并通过一个唯一的类令牌预测图像的类别.Swin Transformer[17]表现出巨大的潜力,因为它整合了CNN和Transformer的优势.一方面,由于局部注意机制,Swin Transformer具有CNN处理大尺寸图像的优势;另一方面,Swin Transformer具有Transformer的优点,可以用移位的窗口对长期依赖关系进行建模.
1.3 通道注意力机制
近年来,通道注意机制在提高深度卷积神经网络性能方面体现出巨大的潜力.Hu等[18]提出SENet利用全连接层预测通道注意力权重,减少对冗余通道的关注.Wang等[19]指出SENet中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依赖关系,增加网络复杂度.为了平衡性能与网络复杂度,Wang等还提出一种高效通道注意力(effificient channel attention,ECA)模块,该模块只涉及很少参数,却能带来明显的绩效提升.ECA模块利用一维卷积实现不降维的局部跨通道交互,同时开发了一种自适应选择一维卷积核大小的方法,以确定局部跨通道相互作用的覆盖范围.
2 网络框架设计
2.1 网络总体结构
TransSRNet的整体架构如图2所示.它由5个部分组成:编码器、空间注意力模块、自注意力模块、特征融合模块和解码器.网络的输入和输出分别为ILR、ISR,具体操作如下.
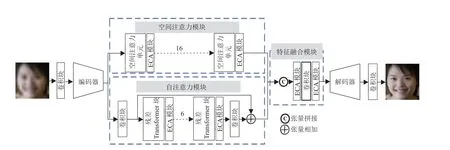
图2 TransSRNet结构图Fig.2 TransSRNet structure diagram
1)深层特征提取:使用双三次插值对低分辨图像进行上采样得到网络输入ILR;从输入图像ILR中,使用卷积层提取包含丰富结构信息的浅层特征.浅层特征作为编码器的输入,进一步提取深层特征.
2)建立映射关系:深层特征作为空间注意力模块和自注意力模块的输入,分别提取局部特征和全局特征.在获得局部和全局特征后,使用特征融合模块进行特征融合,该模块先对局部特征和全局特征在通道维度进行Concat拼接,然后依次经过ECA模块、卷积层和ECA模块得到融合特征.
3)图像上采样重建:融合后的特征送入解码器进行图片恢复,随后通过卷积层输出RGB的三通道图像ISR.
2.2 空间注意力模块
空间注意力旨在提升关键区域的特征表达,本质上是将原始图片中的空间结构化信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成结构化特征的注意力权重并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域.
使用沙漏块构建空间注意力单元,空间注意力单元结构如图3所示, 整体采用残差结构,图中H、W、C分别为特征图的高、宽、通道数.沙漏块中下采样卷积是一个步长为2的卷积层,上采样卷积则是先进行最近邻插值,再进行卷积操作,有助于避免棋盘形伪像.以第j个空间注意力单元为例,空间注意力单元的输入特征和输出特征分别为Ij-1、Ij:

图3 空间注意力单元结构图Fig.3 Spatial attention unit structure diagram
式中:FCB()为一个由批量归一化层、LeakyRelu激活函数和卷积层组成的卷积块,目的是从输入特征中提取包含更高维度信息的特征Iatt;FHB()为沙漏块结构;⊗为矩阵乘;φ ()为sigmoid函数,用来生成注意力权重矩阵.
空间注意力单元采用可以在结构化图像上捕捉多尺度的结构化特征信息,通过将空间注意力单元堆叠在一起,使得重要的空间结构化特征不断增强,从而输出像素级的预测.编码器和解码器也采用类似的结构,编码器和解码器结构如图4所示.编码器中的下采样卷积与沙漏块中下采样卷积相同,解码器中的上采样卷积与沙漏块中上采样卷积相同.
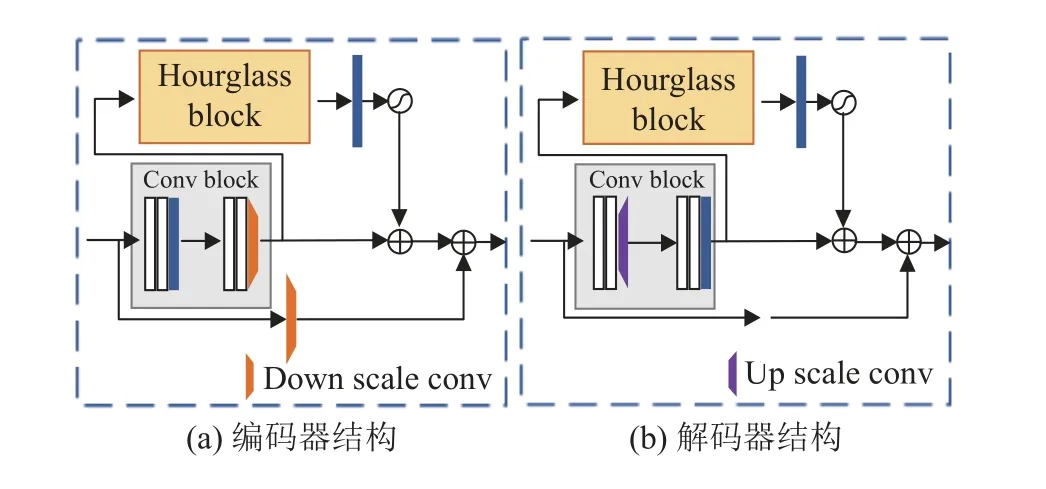
图4 编码器和解码器结构图Fig.4 Encoder and Decoder structure diagram
2.3 自注意力模块
使用Swin Transformer构造自注意力模块,残差Transformer块结构如图5所示,残差Transformer块是由Swin Transformer块和卷积层构成的残差块.MSA为多头自注意力层,MLP为多层感知机.假设第i个残差Transformer块的输入特征为Ii,0,那么第i个残差Transformer块中第j个Swin Transformer块的输出特征为
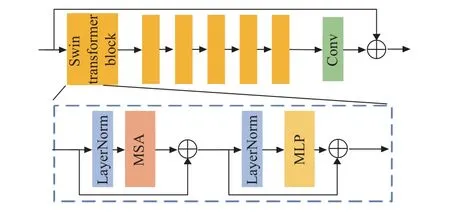
图5 残差Transformer块结构图Fig.5 Residual Transformer block structure diagram
式中:FSTBi,j()为第i个残差Transformer块中的第j个Swin Transformer模块.第i个残差Transformer块的输出特征向量为
式中:Ii,J为第i个残差Transformer块中最后一个Swin Transformer块的输出特征,为一个卷积核大小为3*3的卷积层.Swin Transformer通过将自注意力计算限制在不重叠的局部窗口中,同时允许跨窗口连接,移位的窗口方案带来更高的效率.这种分层体系结构具有在各种尺度上建模的灵活性,并且相对于图像大小具有线性计算复杂性.对于输入特征X的传播过程为
式中:M SA()为多头自注意力层,M LP()为多层感知机.
在多头自注意力层和多层感知机之前添加LayerNorm(LN)层,2个模块均采用残差连接.在多头自注意力层中,首先将输入特征划分为不重叠的N2个本地窗口,分别计算每个窗口的局部自注意.对于特征X,查询矩阵Q、键矩阵K和值矩阵V、K和V为
式中:o,κ和υ为需要训练更新的权重参数矩阵.
与绝对位置编码相比,经典的Transformer[15-16]使用确定性的位置编码或可学习的位置编码.相对位置编码[20]能够在局部内容之间学习更强的“关系”,在大规模数据集训练的情况下,带来重要的性能提升,并得到广泛的应用[21].本研究中的Transformer添加相对位置编码,通过局部窗口内的自注意机制计算出注意力矩阵.注意力矩阵为
式中:d=C/M,C为特征X的通道数,M为多头自注意力层中的自注意力头数;E为可学习的相对位置编码,作为偏置项加入到注意力图中.
为了实现窗口之间的交互,交替使用正则窗口划分和移位窗口划分来实现跨窗口连接,其中移位窗口划分就是在划分前将特征移动(N/2,N/2)个像素.多层感知机利用全连接层和GELU非线性激活函数做进一步的特征转换.
2.4 ECA模块
使用ECA模块关注空间注意力模块和自注意力模块中的通道重要性差异,同时在特征融合时减少对冗余通道的关注.ECA模块结构图6所示,图中GAP为全局平均池化层.假设ECA模块的输入特征为Iin,那么ECA模块的输出特征为

图6 ECA模块结构图Fig.6 ECA module structure diagram
式中:Iin在 经过全局平均池化层FGAP()后,利用一维卷积F1DConv()在局部相邻通道之间建立连接关系,局部跨通道交互范围的大小由一维卷积的卷积核大小决定.
卷积核大小与ECA模块输入特征Iin的通道维度大小呈正相关.一维卷积的输出特征经过sigmoid函数得到通道注意力权重,ECA模块的输入特征与通道注意力权重进行元素相乘后得到输出 特 征Iout.
2.5 优化器与损失函数
使用Adam优化器,参数β1= 0.90,β2=0.99.学习率衰减策略选择线性衰减.联合多个损失函数对网络进行训练.联合损失函数为
式中:α 、 β、γ 为各自损失对应的权重.在图像转换问题中,像素损失是一种基于输出图像与真实图像之间的差值方法,计算2幅图片中所有对应位置的像素点之间的平均绝对误差,最小化差值就会使得2幅图像越相似,定义为
式中:H、W、C分别为图像的高度、宽度和通道数,Ii,j,k为图像I位于(i,j,k)上的像素值.像素损失采用L1损失(平均绝对误差)来约束SR图像在像素值上与HR图像足够接近.与像素损失类似,SSIM损失是为了改善超分辨图像的SSIM而设计,原理如下:
式中:S SIM()为SSIM的计算.SSIM损失通常用于生成细节更精细、视觉质量更好的超分辨图像.Gatys等[22]提出风格损失,并用于图像样式传输.在某种程度上,这种损失与感知损失相似,因为都是特征层面上的损失功能.超分辨重建图像ISR和真实高分辨图像IHR都被输入到一个预先训练的VGG(visual geometry group)网络中,以获得它们相应的特征FSR和FHR,计算Gram矩阵,这些矩阵用于计算损失,定义为
式中:G()为获取特征Gram矩阵的操作.使用以上3个损失联合训练可以从多个角度加速网络的收敛,进一步提高网络性能.
3 实验与分析
3.1 实验配置
3.1.1 数据集及参数设置 实验过程使用CelebA数据集[23]进行训练,从Helen数据集[24]中随机选取200张作为测试集进行测试.另外使用癌症影像档案(the cancer imaging archive, TCIA)网站公开的TCGA-ESCA食道癌和TCGA-COAD结肠腺癌的CT数据集,共计26522张图像进行放大因子分别为2、3、4、8的训练.将1000张图片进行测试,实验设置批处理大小为16,迭代次数设置为20,网络初始化方式设置为xavier,并确定学习速率为2×10-4,学习率衰减策略选择线性衰减.实验在一台单独的 Tesla V100 GPU上进行训练和评估,所有代码都是用Pytorch和Python编写和测试的.
3.1.2 数据集预处理 对人脸数据集进行预处理,使用多任务卷积网络(multi-task convolutional neural network,MTCNN)[25]检测人脸并粗略地裁剪出人脸区域,通过双三次插值将大小调整为128×128,并用作HR训练集.通过对HR图像进行下采样得到LR(16×16)训练集,产生大约202 K的图像对.对CT图像数据集进行预处理则需要将27522张DCM格式的CT图像转换为PNG格式,通过双三次插值调整图像大小为256×256,并将26522张图像作为训练集.为了避免过拟合,通过随机水平翻转、图像缩放(缩放比例在1.0~1.3)进行数据增强.
3.1.3 评价指标 在实验中使用评价指标图像峰值信噪比(peak signal to noise ratio,PSNR)和图像结构相似度(structural similarity,SSIM)进行量化评估.PSNR是有损变换(如图像压缩、图像修补)中最常用的重构质量度量之一.对于图像超分辨率,PSNR是通过图像之间的最大像素值(L)和均方误差(MSE)来定义的.给定具有N个像素的真实高分辨率图像h和重建图像s,h和s之间的PSNR 定义为
式中:在图像像素使用8个bit位表示的情况下,L=255.
PSNR仅与像素级的均方误差相关,只关心相应像素之间的差异,PSNR是目前SR模型中使用最广泛的评估标准.SSIM用来测量图像之间的亮度、对比度和结构的差异.对于具有N个像素的真实高分辨率图像h和重建图像s,SSIM定义为
式中:μs为图像s的平均值,σs为 图像s的方差,μh为图像h的平均值,σh为图像h的方差,ωs,h为图像s和图像h的协方差.
3.2 消融实验及模型分析
消融实验使用CelebA数据集进行放大因子为8的训练,使用Helen数据集进行测试,分别进行以下实验,目的是确定在网络重建性能达到最佳时的空间注意力单元数量和残差Transformer块数量;探究空间注意力模块和自注意力模块各自对重建性能的影响;探究联合不同的损失函数进行训练对重建性能的影响;探究利用通道注意力机制进行特征融合时,不同的通道注意力模块对重建性能的影响.
为了确定在网络重建性能达到最佳时的空间注意力单元数量N,实验在移除自注意力模块和ECA模块的条件下进行,实验结果如图7所示.三角形点为PSNR值,圆形点为SSIM值.结果表明,随着空间注意力单元数量的增加,PSNR、SSIM逐渐增加,性能增益逐渐饱和,并在空间注意力单元数量为16时到达峰值.因此,在其余实验中空间注意力块设置为16.由此可见,由沙漏块构成的空间注意力单元经过堆叠后可以对局部空间信息有效进行有效建模.过多的空间注意力单元反而会导致网络性能下降,原因在于过多的空间注意力单元会造成信息的冗余,从而影响网络性能.
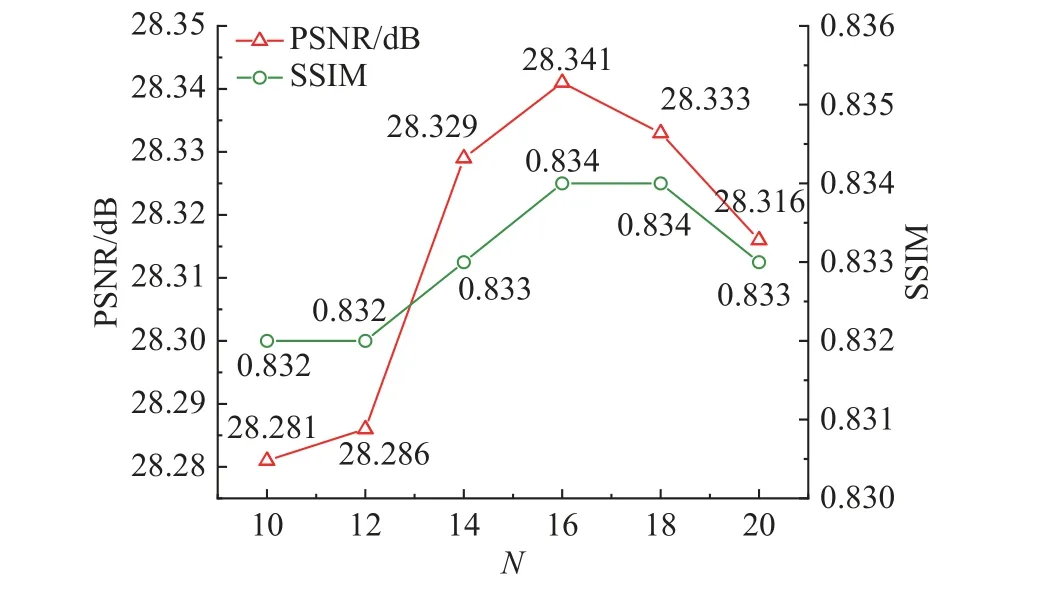
图7 不同空间注意力单元数量对PSNR、SSIM的影响Fig.7 Effects of different numbers of spatial attention units on PSNR and SSIM
为了确定在网络重建性能达到最佳时的残差Transformer块数量,实验在空间注意力单元数量设置为16的前提下进行.表1展示不同残差Transformer块数量对模型性能的影响.结果表明,随着残差Transformer块数量增加,PSNR和SSIM也逐渐增加.当残差Transformer块数量数为6时到达峰值,在其余实验中,残差Transformer块数量设置为6.添加一定数量的残差Transformer块可以使得网络利用自注意力机制对全局上下文进行关注,从而对全局信息建立映射关系,由此可以验证自注意力机制对结构化图像超分辨重建的有效性.
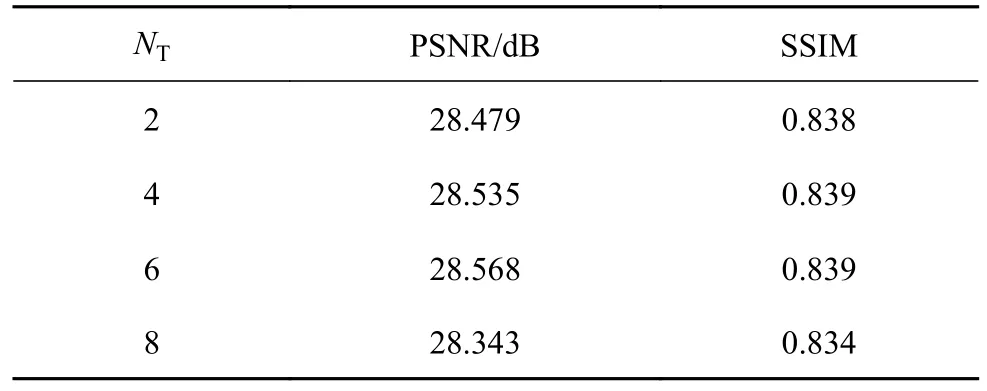
表1 不同残差Transformer块数量对PSNR、SSIM的影响Tab.1 Effects of different numbers of residual Transformer blocks on PSNR and SSIM
为了探究空间注意力模块和自注意力模块各自对重建性能的影响,进行3个实验,实验结果如表2所示.其中模型1(Model1)是去除自注意力模块,保留空间注意力模块后的网络模型;模型2(Model2)是去除空间注意力模块,保留自注意力模块后的网络模型;模型3(Model3)是同时保留空间注意力模块和自注意力模块后的网络模型.在这些实验中,空间注意力块中的空间注意力单元数量设置为16,自注意力模块中残差Transformer块数量设置为6.分析实验结果可以得出以下结论: 1)从实验2、3中可以看出,去除空间注意力模块后,重构性能严重下降,因为网络缺少对图像局部结构化信息的建模能力; 2)从实验1~3中可以看出,添加自注意力模块可以通过捕获全局信息来约束局部信息生成,从而提高网络性能.
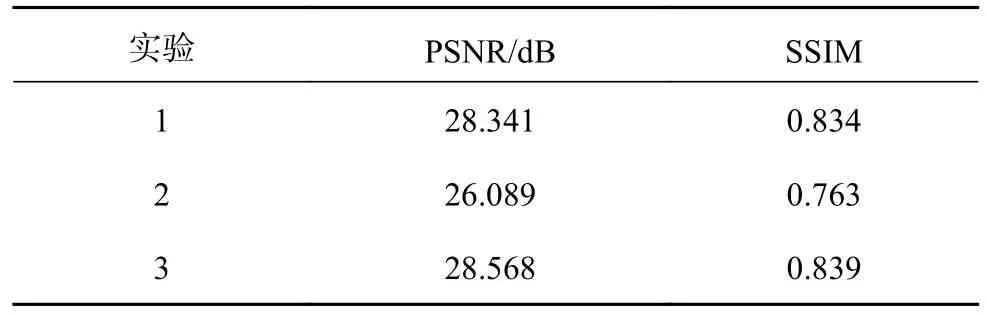
表2 保留不同注意力模块对PSNR、SSIM的影响Tab.2 Effects of retaining different attention modules on PSNR and SSIM
为了探究联合不同的损失函数进行训练对重建性能的影响而进行的实验结果如表3所示.从表3中观察到联合风格损失进行训练可以对PSNR评价指标有一定程度的提升.这是由于风格损失使用Gram矩阵来代替协方差矩阵,使得生成图片与真实图片的特征统计数据相近.联合SSIM损失进行训练能够尽可能地提升SSIM指标,这是因为SSIM损失时刻关注图像之间的结构相似性差异.

表3 联合不同损失函数对PSNR、SSIM的影响Tab.3 Effect of joint different loss functions on PSNR and SSIM
为了探究通道注意力机制的特征融合、不同的通道注意力模块对重建性能的影响,在基础网络分别添加SE模块和ECA模块.实验结果如图8所示.图中BL为基础网络,SE为基础网络中添加SE模块后的网络,ECA为基础网络中添加ECA模块后的网络,划线柱形为PSNR指标值,空心柱形为SSIM指标值.从图8中看出, SE模块使得PSNR值和SSIM值有一定的提升.ECA模块对网络性能的提升效果要优于SE模块,主要原因是ECA模块中的一维卷积比SE模块中的全连接层更能够有效地提取通道特征,减少冗余特征对网络性能的影响.

图8 SE模块和ECA模块对PSNR、SSIM的影响Fig.8 Effects of SE module and ECA module on PSNR and SSIM
通过以上实验可以得出结论:提出的TransSRNet经过堆叠适当数量的空间注意力单元和残差Transformer块能够一定程度上,提高对结构化图像的重建效果.该网络以空间注意力模块为主要模块和自注意力模块为辅助模块,对LR到HR建立映射关系,多损失联合训练和ECA通道注意力模块的加入也可以进一步提升超分辨重建性能.
3.3 与已有算法的对比
为了探讨TransSRNet对不同结构化图像数据集的重建性能,将所提方法与当前优秀的重建算法进行比较,包括基于生成对抗网络的SRGAN[2],利用梯度图关注图像结构特征的SPSR[3],基于先验信息约束的人脸超分辨率重建网络FSRNet[9]和EIPNet[12],这些方法与本研究的实验条件相似,在TCGA-ESCA 食道癌、TCGA-COAD结肠腺癌CT图像数据集上进行对比试验.通过实验可以验证TransSRNet能够对不同类型的结构化图像保持良好的重建效果.
表4展示在Helen测试数据集上进行放大因子为2、3、4、8的超分辨率重建实验结果,表中最优指标为加粗字体,TransSRNet在PSNR和SSIM指标上明显优于其他对比方法.在这些对比结果中,可以发现基于人脸先验信息约束的FSRNet方法和EIPNet方法并没有比所提的TransSRNet重建效果好,导致这一结果的主要原因在于人脸先验信息约束的模型性能够受先验信息预测准确度的影响,不准确的先验信息会严重影响重建效果.

表4 不同方法在Helen数据集上的对比结果Tab.4 Comparison results of different methods on Helen dataset
图9展示不同方法在Helen测试数据集上进行放大因子为2、3、4、8的主观效果对比图.可以从放大因子为8的实验中发现,由于SRGAN未考虑图像结构信息,SRGAN对人脸图像的重建效果较差.与SRGAN相比,SPSR可以恢复出图像的大致轮廓,这是因为SPSR利用梯度信息和梯度损失帮助生成器网络关注图像的几何结构,FSRNet和EIPNet重建的结果则相对较好.与TransSRNet重建结果相比,FSRNet和EIPNet对眼睛和嘴唇的重建产生不同程度的失真,TransSRNet的重建结果更好地保留结构信息.

图9 在Helen数据集上放大因子为2、3、4和8的主观效果对比图Fig.9 Comparison of subjective effects with upscalefactors of 2, 3, 4 and 8 on Helen dataset
FSRNet和EIPNet是用于人脸图像这一特定领域的超分辨重建算法,并不适用于医学图像超分辨重建.另取RNAN算法[4]和基于非局部稀疏注意力的图像超分辨率网络(NLSN)[26]进行对比实验.表5展示不同方法在医学CT数据集上的超分辨率重建实验对比结果,表中最优指标为加粗字体.从表5中可以看出,TransSRNet在放大因子为3、4、8时的评价指标优于其他算法,在放大因子为2时的评价指标略低于NLSN算法,由此可以证明TransSRNet能够对不同类型的结构化图像数据集保持相同的重建效果,原因在于TransSRNet的沙漏块只需要考虑图像的结构信息,不需要考虑特定类型结构化图像的先验知识,而且该网络利用Transformer的自注意力机制,提高了对结构化图像重建效果的自然度和逼真度.
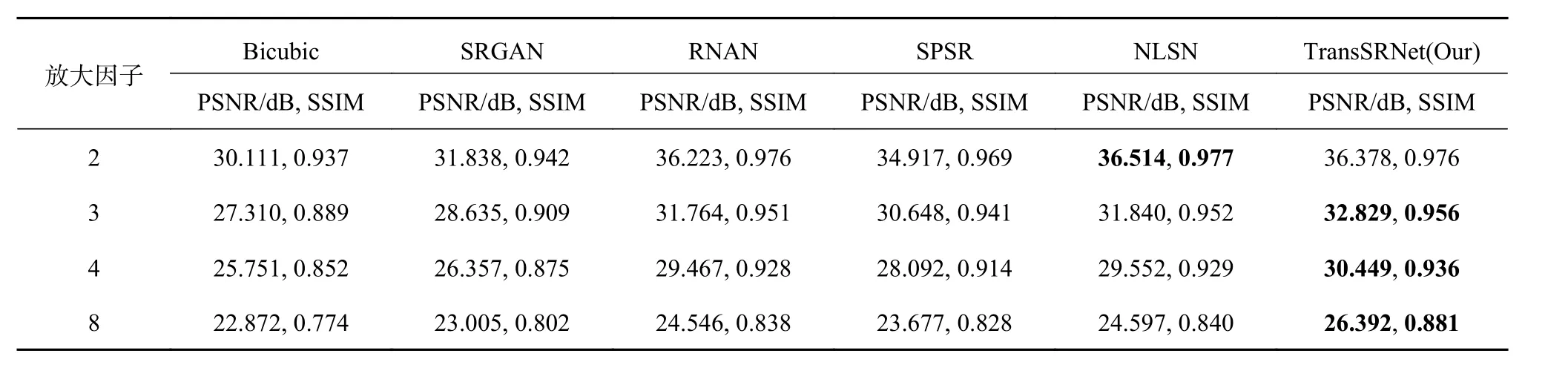
表5 不同方法在医学CT数据集上的对比结果Tab.5 Comparison results of different methods on medical CT dataset
图10~13分别展示不同方法在医学CT数据集上放大因子为2、3、4、8时的重建效果对比图.其中,图10~13的第1幅图片为TCGA-ESCA食道癌图像、第2幅图片为TCGA-COAD结肠腺癌图像,图像下方的数字为该图像和对应HR图像之间的PSNR值和SSIM值,可以看出TransSRNet在放 大因子为3、4、8时的评价指标上优于其他方法.
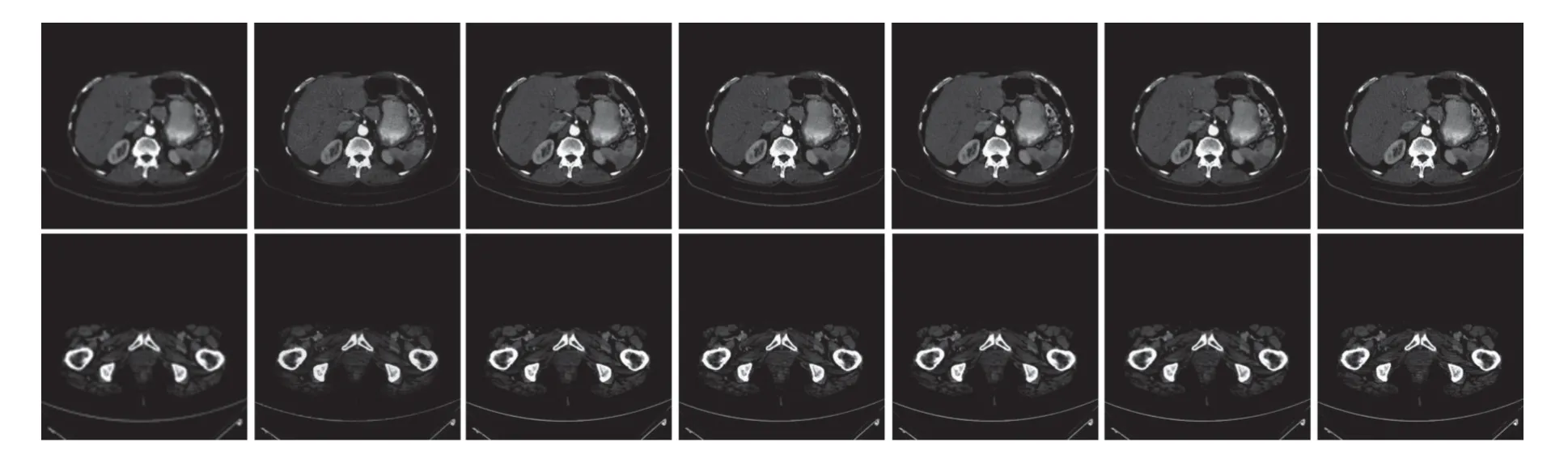
图10 在医学CT数据集上放大因子为2的主观效果对比图Fig.10 Comparison of subjective effects with upscale factor of 2 on medical CT dataset

图11 在医学CT数据集上放大因子为3的主观效果对比图Fig.11 Comparison of subjective effects with upscale factor of 3 on medical CT dataset
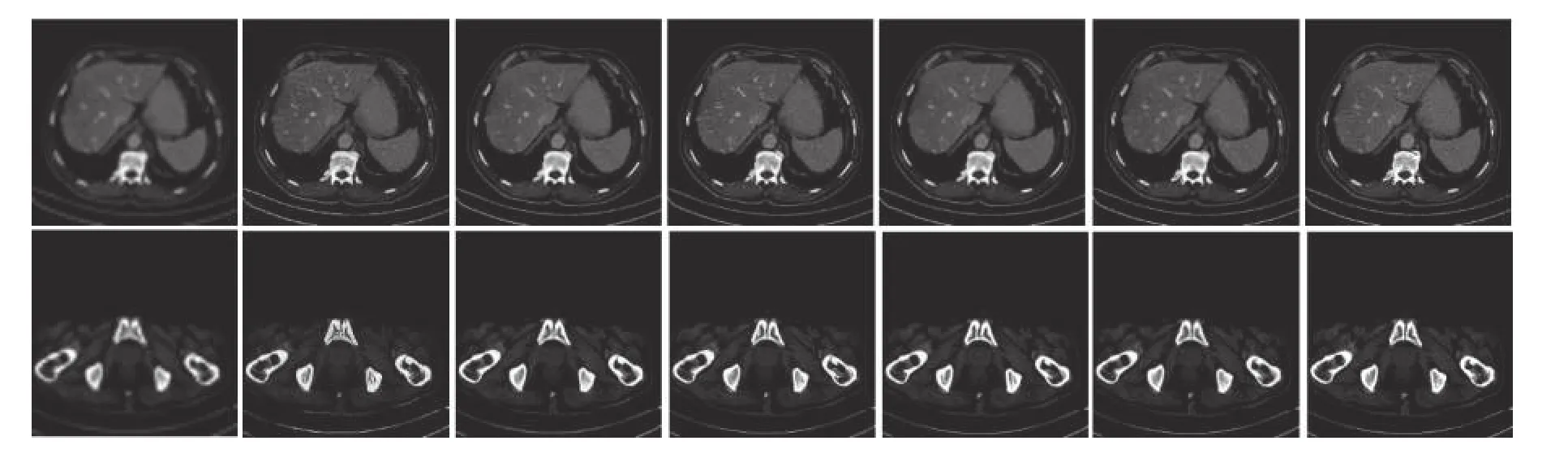
图12 在医学CT数据集上放大因子为4的主观效果对比图Fig.12 Comparison of subjective effects with upscale factor 4 on medical CT dataset

图13 在医学CT数据集上放大因子为8的主观效果对比图Fig.13 Comparison of subjective effects with upscale factor 8 on medical CT dataset
4 结语
本研究提出一种基于改进Transformer的结构化图像超分辨网络,该网络利用Swin Transformer对全局信息进行关注,并且与沙漏块构成的空间注意力模块做特征融合,在关注局部结构化特征的同时保持对全局信息的一致性,在一定程度上提高了重建效果的保真度,可以应用于不同类型的结构化图像数据集.本研究还利用ECA模块的通道注意力机制,减少网络对冗余特征的关注,通过大量消融实验证明TransSRNet的有效性.TransSRNet存在一定局限性,虽然TransSRNet在一些评价指标上取得较好的表现,从网络参数量和计算量的角度出发,所提的TransSRNet还有待优化,因此在保证重建性能的前提下如何优化网络结构、减少训练参数量,将成为下一步的研究重点.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
河北理科教学研究(2021年4期)2021-04-19 13:34:44
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
计算机教育(2020年5期)2020-07-24 08:53:00
自动化学报(2019年6期)2019-07-23 01:18:32
动漫星空(2018年9期)2018-10-26 01:17:14
计算机工程(2015年8期)2015-07-03 12:20:35
河南科技(2015年8期)2015-03-11 16:23:52
发明与创新(2015年33期)2015-02-27 10:40:09
