基于机器学习构建非酒精性脂肪性肝病预测模型
2023-05-15 05:44刘璐朱锦舟刘晓琳王超殷民月高静雯许春芳
肝脏 2023年4期
刘璐 朱锦舟 刘晓琳 王超 殷民月 高静雯 许春芳
非酒精性脂肪性肝病(NAFLD)是以肝细胞内脂肪过度沉积为主要变化的一类病理综合征。近年来,发病率在我国呈增长趋势,在西方发达国家中,非酒精性脂肪肝已经成为慢性肝病当中最常见的一类疾病[1]。我国人口基数大,尽早预测和识别NAFLD高危发病人群,降低NAFLD的发病率具有重要意义[2]。
机器学习为一种新兴的数据计算与统计方法,可以从多维度进行医学数据的分析与挖掘,随着大数据、人工智能等技术在医学领域的交叉发展,目前机器学习已经逐步应用于预防、治疗和监测等方面[3-4]。本研究利用H2O平台AutoML框架构建预测患者发生NAFLD的一系列机器学习模型,为临床实践中NAFLD的预防和治疗提供指导。
资料与方法
一、研究对象
选取2017年1月至2017年12月苏州大学附属第一医院体检中心人员的常规临床资料及实验室检查,影像学资料等,共有4105名体检中心人员。根据2010年中华医学会肝病分会脂肪肝和酒精性肝病学组的临床诊断标准[3],分为未发生非酒精性脂肪性肝病组1209例,发生非酒精性脂肪性肝病组2896例。
纳入人员均签署知情同意书。排除标准:①非酒精性脂肪性肝病以外的肝病;②合并严重的心脑血管疾病;③合并恶性肿瘤;④合并严重内分泌或系统性免疫疾病。本研究获苏州大学附属第一医院伦理委员会批准。
二、方法
查找电子病历系统中相关记录,收集患者入院时的影像学、血清学等临床资料。
收集患者入院时的腹部B超及空腹静脉血。检测项目包括:血细胞常规、生化全套、肿瘤全套及凝血功能等。
三、统计学方法
利用H2O平台(3.36.0.2版)AutoML框架建立一系列针对是否为NAFLD二分类结局的机器学习预测模型。绘制受试者工作特征(receiver operating characteristics, ROC)曲线并建立混淆矩阵,计算敏感度、特异度及ROC曲线下面积(AUC)评价模型区分能力。为增强机器学习模型的可解释性,呈现变量在模型中的重要性及分布情况,进行SHAP分析(shapley additive exPlanations)、部分依赖图(partial dependence plots)以及局部可解析性算法(local interpretable model agnostic explanation, LIME lime包0.5.2)等可视化分析。P<0.05为差异有统计学意义。
结 果
一、两组一般资料比较
4105例患者中,未发生非酒精性脂肪性肝病组2896例,发生非酒精性脂肪性肝病组1209例。2组一般资料比较见表1。

表1 2组一般资料比较
二、AutoML框架下建立机器学习模型
将收集的资料经预处理后载入H2O平台AutoML框架中,个案比例按照0.8∶0.2随机分组为训练集(例)及验证集(例)。而后进行AutoML特征选择、运算建模。
AutoML框架下自动建模最长时设置为120 s,共建立了28个机器学习模型。根据机器学习主要的5种算法,建立了各类5类最优模型,即:梯度提升机(gradient boosting machine,GBM)、极致梯度提升(eXtreme gradient boosting, XGBoost)、逻辑回归、随机森林(distributed random forest, DRF)以及深度学习(deep learning, DL)。
基于训练集,得到最佳模型为GBM(GBM_5_AutoML_20220114_134957),Gini值为0.80,R2为0.42,LogLoss为0.45。模型中重要性绝对值排名前五的变量为:三酰甘油、天冬氨酸转氨酶、高密度脂蛋白、铁蛋白及血糖。见图1。
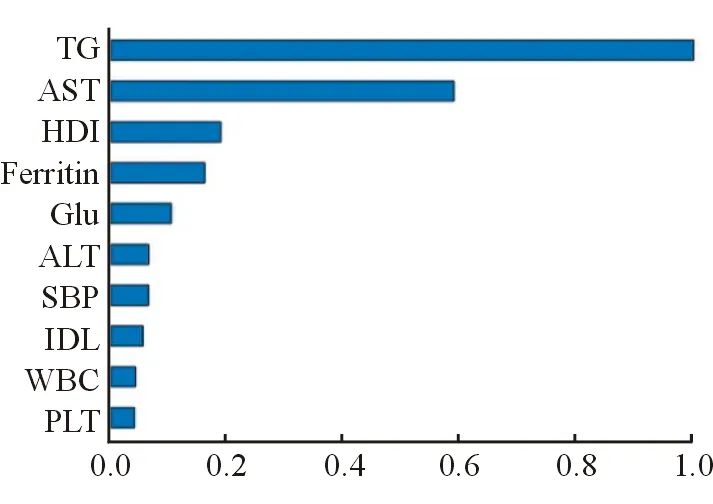
注:TG为三酰甘油;AST为天冬氨酸转氨酶;HDL为高密度脂蛋白;Ferritin为铁蛋白;Glu为血糖;ALT为丙氨酸转氨酶;SBP为血管收缩压;IDL为低密度脂蛋白;WBC为白细胞计数;PLT为血小板计数
三、变量在模型中作用的可视化实现
在GBM模型中,重要变量的SHAP特征见图2。可以看到三酰甘油、天冬氨酸转氨酶、高密度脂蛋白、铁蛋白和血清葡萄糖等五个变量在结局二分类中的分布,三酰甘油、天冬氨酸转氨酶、铁蛋白及血清葡萄糖体现其标准化数值与发病呈正相关趋势;而与高密度脂蛋白呈负相关。
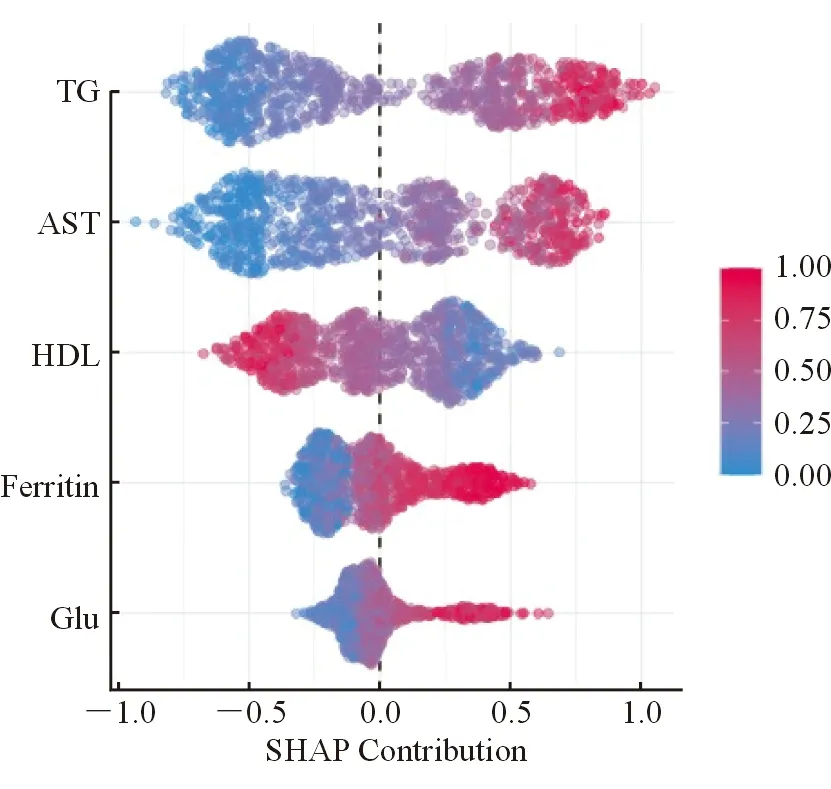
注:TG为三酰甘油;AST为天冬氨酸转氨酶;HDL为高密度脂蛋白;Ferritin为铁蛋白;Glu为血糖
图3为LIME可视化,显示是随机抽取的6个样本(未发生非酒精性脂肪性肝病4例,发生非酒精性脂肪性肝病2例)中重要变量对个体预测的作用。

注:随机样本中(label p0表示未发生非酒精性脂肪性肝病,p1表示发生非酒精性脂肪性肝病),显示重要变量在个体预测中作用
图4显示的是重要性前四的变量在GBM模型中的部分依赖图,可以看出四个变量与预测结果基本上呈现的是上升趋势。

注:部分依赖图显示排名前五位的变量对GBM模型的预测结果的边际效用
四、多个预测模型及评分系统在验证集中的区分能力
如表2所示,采用上述获得的多个算法最优模型绘制预判是否发生非酒精性脂肪性肝病的ROC曲线并建立混淆矩阵。在训练集中表现最佳的GBM模型,在验证集中特异度为0.818,敏感度为0.715,AUC为0.766,优于其他4个算法。
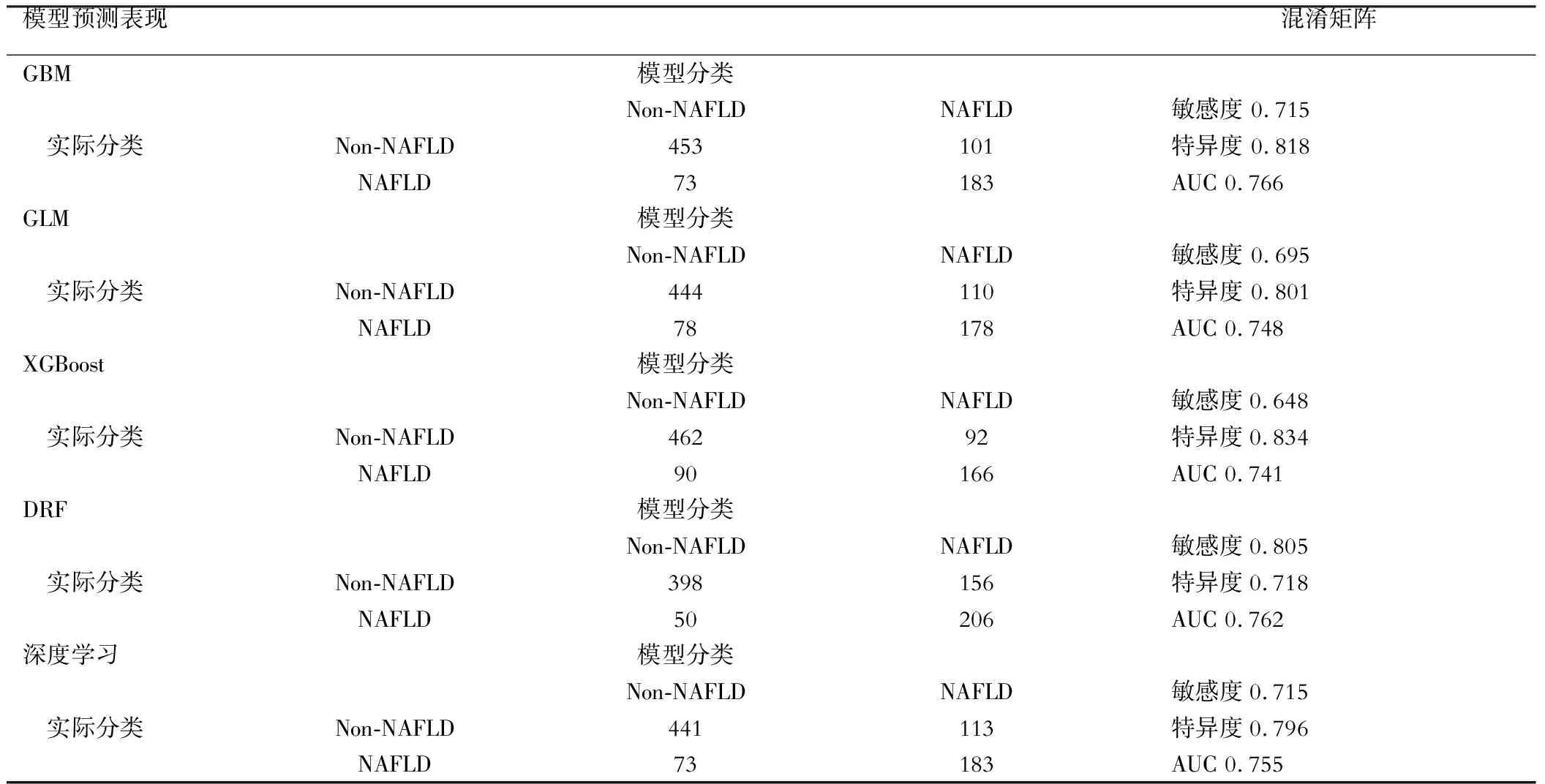
表2 各机器学习模型在验证集上的表现
讨 论
在临床实践中,利用较为常见、易于操作的检查方法获得临床资料,建立一个可靠的预测非酒精性脂肪性肝病的风险是量化工具,能够为患者和医务工作者提供最为科学直观的信息极为重要[5]。在脂肪肝的各类预测模型中,应用机器学习的方法已经成为研究应用中的一个重要方向[6]。
目前,国内外研究报道了基于机器学习建立非脂肪性肝病相关的预测模型。Goldman等[7]构建了来源于TAMCIS数据库的非酒精性脂肪性肝病及肝脏纤维化的发病率模型;香港也有文献报道通过常见的体检数据建立筛查排除脂肪肝的机器学习模型[8];国内有学者利用机器学习语言构建非酒精性脂肪性肝病模型的报道,如杨磊等[9]报道了利用机器学习构建支持向量机来预测非酒精性脂肪性肝病的发病率有较好的效果;雷丽等[10]利用机器学习建立了脂肪肝Joint联合预测模型。
本研究通过H2O平台的AutoML框架,在训练集数据中建立了五种最优模型,并在验证集中证实了基于GBM算法的集成模型是最佳模型,优于逻辑回归、随机森林、XGBoost,以及深度学习模型。在构建模型过程中,本研究发现三酰甘油、天冬氨酸转移酶、高密度脂蛋白、铁蛋白、血糖水平是重要变量,这也与近年来国内外报道的研究结果相类似。其中,血清中三酰甘油水平较高,使得肝脏内三酰甘油的合成与分泌失衡,三酰甘油累积在肝脏内,导致脂肪肝的发生[11]。高密度脂蛋白是将胆固醇从外周组织逆向转运到肝脏进行代谢的载体,从而减少包括内皮组织在内的外周胆固醇累积,因此高水平的HDL与NAFLD的发病率呈负相关。当肝脏脂肪含量不断累积,使肝细胞受到破坏,影响肝脏细胞的正常代谢活动,继而血清水平的肝酶水平升高[12, 13]。有研究表明,NAFLD的发病机制可能与机体铁含量增加有关,但铁蛋白与NAFLD的发病机制尚不明确,可能铁蛋白参与肝细胞内的氧化应激过程,刺激自由基和过氧化物的形成,导致细胞的蛋白质和DNA受到损伤,继而导致了肝细胞的进一步破坏[14]。此外,血糖水平在NAFLD的发生与发展过程中也占据着重要作用,肝脏作为体内葡萄糖代谢的主要调控与贮存器官,当肝脏出现损伤时,血糖水平会因此受到影响。有文献报道,与健康人群相比,脂肪肝人群中,血糖水平显著升高。而血糖升高又会影响肠道活动,如降低肠道蠕动,破坏肠道屏障功能,使肠黏膜通透性增加,内毒素吸收增多,进一步加重脂肪肝的进展[15, 16]。
本研究通过H2O平台自动化机器学习,建立发生NAFLD的一系列预测模型,可为高危人群预测发生NAFLD提供有意义的量化参考。但本研究为单中心研究,仍需多中心的外部验证进一步评估模型效果。
利益冲突声明:所有作者均声明不存在利益冲突。
猜你喜欢
科学(2022年4期)2022-10-25
肝博士(2022年3期)2022-06-30
昆明医科大学学报(2021年8期)2021-08-13
肝博士(2021年1期)2021-03-29
食品与生物技术学报(2021年6期)2021-01-15
中国粮油学报(2020年10期)2020-11-05
知识就是力量(2020年3期)2020-05-20
医学综述(2020年8期)2020-02-16
天津科技大学学报(2015年3期)2015-04-16
西南军医(2015年2期)2015-01-22