
基于新媒体平台的营销推荐算法机制研究
2023-05-08 00:18胡存梅武照云
安阳师范学院学报 2023年2期
胡存梅,武照云
(1.安徽机电职业技术学院,安徽 芜湖 241002;2.河南工业大学,河南 郑州 450001)
0 引言
新媒体时代推荐系统的诞生与演化旨在解决“信息载体庞大”场景下目标用户精准挖掘兴趣内容。它随着信息时代的到来而诞生,近些年来随着移动互联网技术的快速发展,各大社交平台、电商平台、自媒体终端如雨后春笋一般尽数而出,因此传统的推荐算法已经愈加无法适应现代新媒体浪潮下的场景应用。
结合现有的研究发现,新媒体时代异构平台所衍生的社交网络稀疏性和传统语义模型下噪声数据干扰两个问题尚无较好的解决方案[1-3]。拟通过隐式社交网络与表征学习算法对该问题进行研究,以期优化新媒体平台下营销推荐算法的性能。
1 推荐模型问题描述
随着自媒体等新兴社交方式和网络的快速崛起,用户的冷启动和稀疏性等领域研究也逐渐成为热点方向[1]。现有的研究依然是将传统语义模型与新型自媒体网络特征相结合,对用户及商品的潜在特征进行学习,这类研究能够很好地解决冷启动条件下用户倾向的识别,但同时也存在以下两个问题:
1)用户-商品的互动数据与社交网络稀疏性特点。特别是针对冷启动的用户群体,由于其典型特征就是社交关系信息较少,因此在这里以用户-商品互动数量5作为界定,将低于界定的用户视为冷启动,否则为非冷启动用户,同时定义社交关系的两个阈值分别为5个和10个,以此来描述用户社交关系统计数量如图1所示。

a) 非冷启动用户
由图1可知,在3个公开数据集上特别是数据集密度最小的Epinions中,用户群体的社交关系基本都低于5,有接近80%的冷启动用户统计低于10。即使在数据集密度最大的Last.fm中,低于10的统计数据也大于70%,在Ciao中也有超过半数的用户群体社交关系统计低于10。因此可以看出稀疏性问题的普遍性,其对于传统语义模型而言就会造成冷启动用户隐式特征的判断。
2)传统语义模型下噪声数据对性能影响。在用户的兴趣偏好理解上,传统语义模型的预设条件一般认为用户关系网络下的群体拥有相似的趋向[2],但实际上如果活跃用户的社交关系网络过于庞大和复杂,那么上述假设成立的概率就会大大降低,因此则会产生较多的噪声数据影响语义模型的学习性能,因此需要解决相同兴趣趋向的用户群体定位。
2 新媒体平台下时序推荐算法
2.1 算法框架设计
基于上述传统语义模型下的问题分析,拟采用马尔科夫链(Markov Chains,MC)对社交网络进行时序推荐模型的搭建(Joint Personalized MC-JPMC)。
首先为了降低新媒体等异构社交平台下的用户群体关系稀疏性问题的影响,选取网络表征学习算法进行隐式特征的提取,具体方法为通过将隐式社交关系与用户行为历史相结合进行算法学习[3];其次基于隐特征进行用户相关性较大的群体邻居选取,以此来代替原有的显示社交网络关系,并在此基础上对用户短时间和未来的趋向问题搭建了静态社交增强矩阵和动态社交感知序列。最后在FPMC(Factorizing Personalized Markov Chains)的基础上设计了联合分解框架,以达到趋向商品推荐的目的。JPMC框架设计如图2所示。

图2 JPMC框架设计图
2.2 网络表征学习
由于网络表征学习算法对于图数据的处理能力更强,因此在模型设计中引入网络表征学习进行社交网络的挖掘处理[4],具体设计流程如下:
1)构建隐式社交。基于社交网络中的信任关系具有一定的稀疏问题,因此,利用 PMI (Pointwise Matual Information,PMI)对两个用户主体进行了关联分析,并利用 PMI来测量两个主体出现的概率,其表达式(1)为:
(1)
其中:#(u1,u2) 是用户u1、u2同时交互的商品数量,D=∑(u1,u2)#(u1,u2), # (u1)=∑u2#(u1,u2)则表示和u1交互的商品数量, #(u2)=∑u1#(u1,u2)表示和u2交互的商品数量。
2)网络表征学习。在(1)的基础上利用Node2vec模型,在新的社交网络基础上实现网络特性学习,Node2vec模型设计了一种具有较强灵活性的随机游动策略,它能够将表征学习表达为最大似然优化的目标函数,目标函数如下:
maxf∑n∈VlogPr(Ns(u)|f(u))
(2)
2.3 社交影响建模
在完成网络表征学习的基础上,为了解决长短时的问题,需进行静态社交增强矩阵(SSAM)与动态社交感知序列(DSAS)的构建。
1)SSAM。在邻居群体和用户-商品的互动举证W的基础上,可以得到SSAM:
Wui={1,i与u及网络邻居有交互
0,其他
(3)
上式中wui所表达的是静态社交增强矩阵中用户对于商品的评分,由于设计模型所要解决的是隐反馈推荐,所以这里矩阵的值为布尔值。
2)DSAS。在此基础上,建立了一种基于静态增强矩阵和时间序列信息的动态感知序列,该序列的构造流程见图3。

图3 动态感知序列
在静态强化矩阵中,将与用户互动的对象按其出现的时间顺序排列,形成一种新的序列。与原有的序列不同,该模式考虑到不同类别的商品间的传递关系,而非原顺序的传递关系;在此基础上,可以分为三种类型:a不同的网络邻居间的商品传递;b将所述网络邻居的商品向所述目标用户的传送;c目标用户与邻居群体间的传递。
2.4 模型优化
选取随机梯度下降对模型进行优化,优化后的模型在每个迭代中会随机抽取一个样本集合,并结合分解模型从DT、DG拉取训练的实例,最后对模型的构建要素进行梯度下降处理,具体优化过程表达如下:

(4)

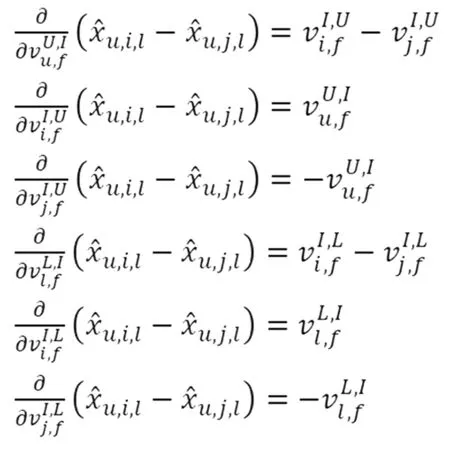
(5)

3 验证分析
3.1 数据集选取
为了充分验证模型的优化效果,文中选取了3个数据集Last.fm、Ciao以及Epinions,这3类数据集的行业领域都具有典型性,其中Last.fm是在线音乐平台,它包含了用户的基本社交数据、音乐收听标签;Ciao是一个在线商品销售平台,它包含了用户对于商品的评价数据,数据时间标签和社交数据;Epinions也是一个用户群体庞大的在线购物平台,包含的数据标签与Ciao类似。
3.2 基线算法与参数设置
选取的基线算法包括Pop、BPR、SBPR、FMC、FPMC和SPMC,模型编码实现采用Python进行开发,对用户、商品的隐式特征向量使用高斯分布进行随机,标准差设定为0.01,最优参数的选取基于网格搜索来实现,同时在[10,1,0.1,0.01,0.001]范围内变换学习率,正则化超参数范围为[10,1,0.1,0.01,0.001],Pop以外的其他模型特征维度设定为60。
3.3 实验结果分析
3.3.1 推荐精度
首先比较并分析了在非冷起动条件下的各种模型的推荐准确率,对3组数据进行了试验,各模型的NDCG@5和Precision@5结果如表1所示,表1中加粗数据代表了所有数据集合的最佳结果,而Inc列则是与该模型比较的最佳基准模型。从试验结果来看,所建立的3组数据比其他的基线法都要好,特别是在 Ciao的数据集方面,这一结论更为显著。在各种基准模型中,SPMC的性能最佳,与SPMC相比,该文的模型平均提高21.6%,预测精度提高了23.2%。

表1 NDCG和Precision指标下推荐准确率
通过对3个不同的数据集的实验,可以看到,Last.fm数据集中,与其他两组比较,Last.fm的性能最佳;而对于Epinions和Ciao这两个较少的数据,推荐的精度都出现了显著的降低,特别是在Ciao的基线模型中推荐的精度较低;然而,模型在这两项指标上都得到了极大的提高,这表明 JPMC模型在用户的反馈信息中仍能保持较高的推荐精度。
在所有的基线模型中,Pop和FMC模型的预测精度都很低,这是由于它们不能从个体的角度去学习用户的喜好,也没有考虑到不同的数据类型。然而,可以看到,在 Ciao的数据中,与FMC和Pop模型相比,所有的基线模型都没有显著提高,这表明了稀疏的用户-项目数据和社交网络对用户的影响有限,而JPMC模型则表现出了更好的效果。
在比较了一些基本模型的试验结果后还发现,在比较BPR与SBPR模型的时候,SBPR在Last.fm和Epinions中都有显著的提高,这表明在相对稠密的社交网络环境中,该方法可以提高模型的推荐精度;通过对 BPR模型与 FPMC模型的对比发现 FPMC模型在3个数据集合中的预测精度均高于 BPR模型,这说明考虑时序信息有助于提高模型的预测精度;结果表明,时序信息在模型中的作用也会因稀疏问题而降低;通过对 FMC与 FPMC模型的对比,发现 FPMC模型的性能要好于 FMC模型, BPR模型在 Ciao和Last.fm中的性能也要好于 FMC,这表明了对个体化用户偏好的学习是非常重要的;将 SPMC、 SBPR与 FPMC模型进行比较,结果表明,将社交网络与时间序列相结合,可以提高模型推荐的正确性。
3.3.2 用户冷启动
在研究用户冷启动问题时,典型的做法是选择与商品交互数目少于5的用户作为冷启动用户,由于模型中每个用户至少需要4个反馈数据,导致获得的冷启动用户较少,因此根据之前的研究,为每个用户保留N个最近的反馈来模拟冷启动环境,其中N是阈值,分别设定为5和10,特征维度大小设定为60,其他参数与前面实验一致,在3个数据集上对所有模型进行实验,实验结果如表2所示。
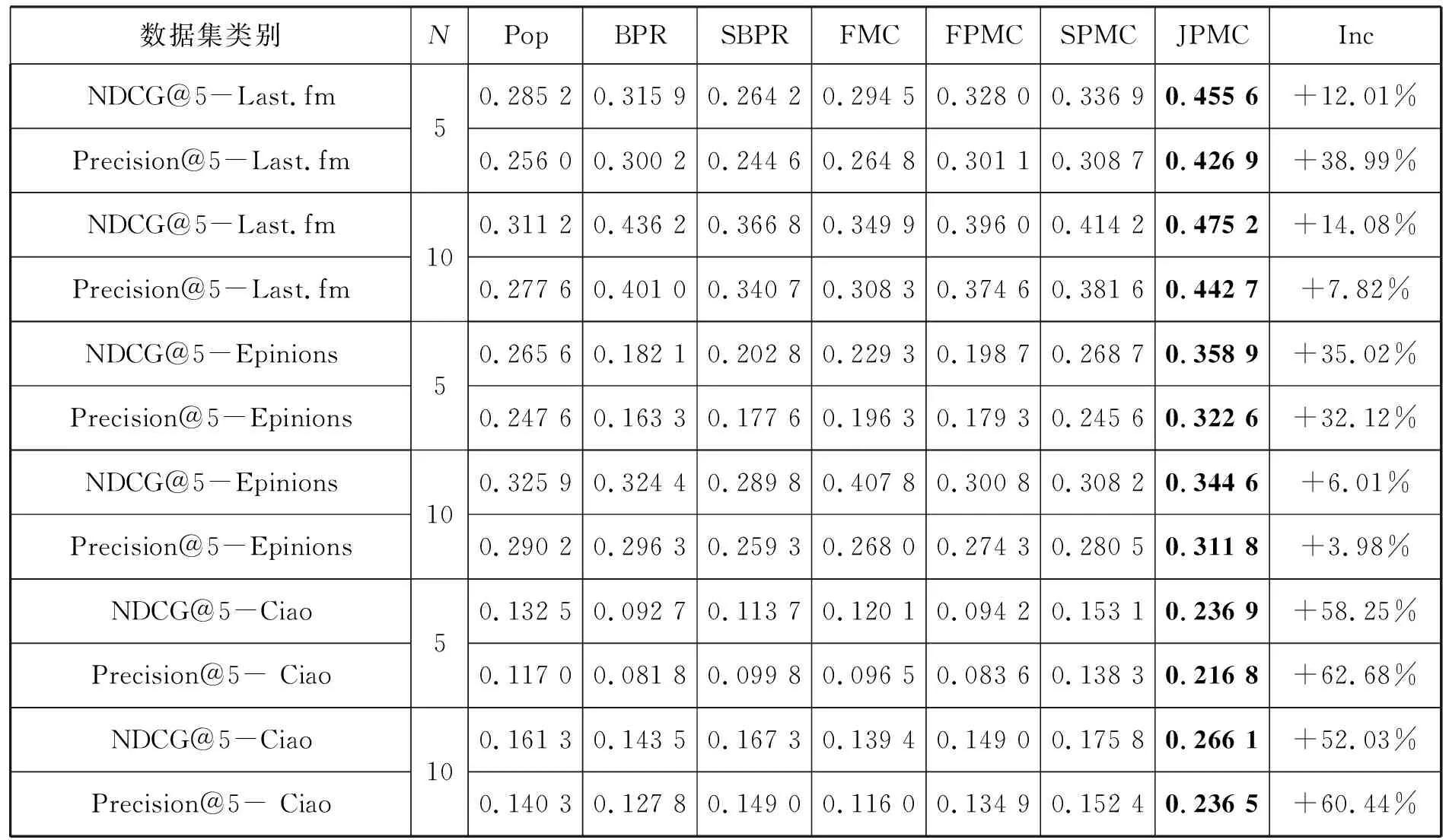
表2 冷启动条件下NDCG和Precision指标
从3个数据集可以看出,JPMC模型与其他的基线模型相比有了显著的提高,特别是在设定了5个阈值后,预测精度得到了较好的提高。从表2的结果也可以看出: FPMC和 SPMC模型在分析Lst.fm和 Ciao两个基线的性能方面都要好, SPMC模型在处理用户的冷启动方面表现最好,这说明社交网络和时间信息对降低系统的影响很大;从 Epinions数据中可以看出, SPMC模型在5个阈值下的预测精度较高,而在10个阈值下, SPMC模型的性能较好,表明在实际的冷启动条件下,将社交网络与时间序列信息相结合,可以更好地提升推荐的准确性;另外,在Last.fm上,与 Pop和 BPR模型相比, FPMC和 BPR模型的推荐准确率得到了显著的提高,而在 Epinions和 Ciao的用户反馈和社交网络数据都比较稀薄的 Epinions和 Ciao两个数据集,即使是在10个阈值下, Pop和 BPR模型的推荐精确度也优于其他的基线模式,这表明社交网络和时间信息对于提高冷启动问题并没有那么有效。
3.3.3 稀疏冷启动
为了证明模型在社交网络的稀疏性场景下仍然能够有效的解决用户冷启动问题,在用户冷启动场景下进一步对社交关系数分别少于5和10的用户的实验结果进行对比和分析,模型的参数与上述实验一致,在3个数据集上对所有模型进行实验,实验结果如表3所示。

表3 社交稀疏性下NDCG和Precision指标
为验证模型在社交网络稀疏情况下仍能很好地解决用户的冷启动问题,通过对不同社交成员数量小于5人和10人的试验进行了比较,得出了与以上实验结果相符的结论。从实验结果可以看出,与其他基线模式相比,该模型的预测精度得到了显著提高,特别是Ciao数据集的性能得到了明显的提高。
对比基准模型,SPMC和FPMC模型的性能优于其他基线模型,但SBPR模型的性能低于表2;此外还发现在 Epinions的数据中,FPMC模型的性能最好,这也说明了社交网络的稀疏特性会使模型无法很好地模拟用户的喜好,从而制约了用户的冷启动问题;同时,考虑时序信息可以进一步加深模型对受社交网络影响的使用者偏好的学习,所以有必要考虑到社交网络对使用者的动力偏好的影响。
3.3.4 特征维度影响
为研究隐式语义模型中的隐含特征维数 d的大小对模型的影响,以10~100为基础,对 JPMC和基线模型进行了试验,并给出了相应的实验结果如图4所示。

图4 特征维度-JPMC指标结果
从图4中3种数据集合下不同类型模型的不同指数,得出了更大的d值总能使该模型得到更好的效果,这是由于属性维度越大,用户的潜在特征就越能体现出更好的特性;同时该研究的JPMC模型在各种类型的d值上都是最佳的,这也说明了该模型在各个属性维度上的有效性。此外,还可以看到:在Epinions数据集上,两个指标的稳定性要好于另外两个,这表明了在多个特征维度下,对于大量的、稀疏的数据集合,隐式语义模型的预测精度是稳定的。
4 结语
提出了一种结合个体化马尔科夫模型(JPMC),其改进程度与已有的工作相比较,在推荐精度和解决用户的冷启动问题上,有着明显的优越性。该模型首先利用Node2vec算法对用户的隐含特性进行分析,并在此基础上选取与其相似度较高的邻域。在原有的社交网络中,建立了互信关系;在此基础上,基于网络邻域的概念,构造了一个动态的感知序列。通过结合的联合分解结构,可以捕捉用户的长时和短时的喜好,从而提高了基于社交网络的模型的推荐准确度,特别是在冷启动的时候,能够更好地解决社交稀缺性问题。
猜你喜欢
英语世界(2023年6期)2023-06-30
重庆大学学报(2022年6期)2022-06-23
意林彩版(2022年2期)2022-05-03
客联(2021年2期)2021-09-10
高技术通讯(2021年3期)2021-06-09
科学(2020年5期)2020-11-26
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
舰船电子对抗(2016年5期)2016-12-13
