
基于压缩表示的实例分割方法
2023-04-29 17:53:06李文举李文辉
吉林大学学报(理学版) 2023年4期
关键词:深度学习
李文举 李文辉

摘要: 针对目前实例分割领域掩膜表示高复杂度的问题, 提出一种新的图像实例掩膜表征方法, 使用3个不依赖于任何先验信息的表征单元表示并预测掩膜, 且以非线性解码的形式复原掩膜, 该方法可显著降低图像实例掩膜的表示复杂度和推理运算量. 基于这种表示方法, 构建一个高效的单阶段实例分割模型, 实验结果表明, 相对于其他单阶段实例分割模型, 该模型在保证时间开销基本相同的情况下能获得更好的性能. 此外, 将该表征方法以最小改动嵌入经典模型BlendMask以重建注意力图, 改进的模型相对于原模型的推理速度更快, 掩膜平均精度提升1.5%, 表明该表征方法通用性较好.
关键词: 深度学习; 实例分割; 压缩表示; 表征单元
中图分类号: TP391.4文献标志码: A文章编号: 1671-5489(2023)04-0883-07
Instance Segmentation Method Based on Compressed Representation
LI Wenju, LI Wenhui
(College of Computer Science and Technology, Jilin University, Changchun 130012, China)
Abstract: Aiming at the problem of high complexity in mask representation in the field of instance segmentation, we proposed a new mask representation method for instance segmentation, which used three repsesentation units that did not rely on any prior information to represent and predict mask, and restored the mask in the form of nonlinear decoding. This method could significantly reduce the representation complexity and inference computation of image instance masks. Based on the representation method, we constructed an efficient single-shot instance segmentation model. The experimental results show that compared to other single-shot instance segmentation models, the model can achieve better performance while ensuring that the time cost is basically the same. Additionally, we embed the representation method with minimal modifications into the classic model BlendMask to reconstruct attention maps. The improved model has a faster inference speed compared to the original model, and the average accuracy of the mask is improved by 1.5%, indicating that the representation method has good universality.
Keywords: deep learning; instance segmentation; compressed representation; representation unit
實例分割是计算机视觉领域最重要、 最复杂和最具挑战性的任务之一, 其对图像中的每个实例做像素级分割, 难度远高于目标检测. 近年来, 实例分割技术获得了快速发展[1-3]. 随着一阶段目标检测模型的日渐完善, 实例分割模型大多数基于一阶段目标检测器[4-6]构建, 并取得了较好的效果. 同时, 一阶段目标检测也推动了另一类实例分割架构的发展, 这类架构仅凭对目标检测模型的最小化改动即可实现实例分割, 通常被称为单阶段(single-shot)实例分割[7-8].
对于单阶段实例分割架构, 实例掩膜的表示信息直接从顶层分支输出, 如果没有合适的掩膜信息表示方法, 该架构将会产生巨大的计算开销且无法获得好的性能. 文献[9-11]将二维掩膜预测任务转换为实例轮廓预测任务, 从而用实例轮廓上的点集表示实例信息, 这种转换极大减少了掩膜表示的复杂度, 但由于这种方法为每个实例只预测一个轮廓点集, 其无法处理掩膜被截断或实例存在空洞部分的情况. 为解决上述问题, MEInst[8]采用压缩表示方案, 顶层分支预测二维实例掩膜的低维表征信息. MEInst为每个实例预测一个紧凑的向量, 然后通过一个辅助变换矩阵将向量重建为二维掩膜. 这种方法效率很高但严重依赖于变换矩阵, 而变换矩阵是来自于数据集的先验信息. 先验信息使得这种表示方法不具备通用性, 无法迁移应用到其他实例分割架构中.
针对上述问题, 本文提出一种简单通用的压缩表示方案, 其能使表征过程准确、 高效而不依赖于任何先验信息. 在本文方法中, 每个掩膜用3个紧凑的表征单元表示, 这些表征单元可通过一个无参解码器组装为掩膜. 这种方法在重建过程中不依赖于任何先验信息, 也不引入任何需要学习的参数, 可直接嵌入到一些实例分割架构中获得更好的性能.
基于这种表示方法, 本文构建一个单阶段实例分割模型CRMask. CRMask在FCOS[5]的基础上添加了一个负责预测表征单元的掩膜分支, 实例掩膜由解码器对表征单元解码得到. 通过实验考察CRMask的性能, 在数据集COCO(common objects in context)上的实验结果表明, CRMask与具有相似架构的实例分割模型相比性能提升明显. 在不做任何特殊处理的情况下, 使用ResNet101-FPN作为骨干网络的CRMask掩膜的AP(average precision)能达到35.4%, 在相同条件下比MEInst提高1.5%. 由于本文表示方法的特性, 其可以灵活嵌入到一些实例分割架构[12-13]中, 为考察其通用性, 本文尝试将其嵌入到BlendMask[13]中, 只对BlendMask做最小改动, 用表征单元替换模型中的注意力图. 实验结果表明, 相对于原始模型, 嵌入后的模型具有更快的推理速度和更好的性能.
1 本文方法设计
1.1 总体架构
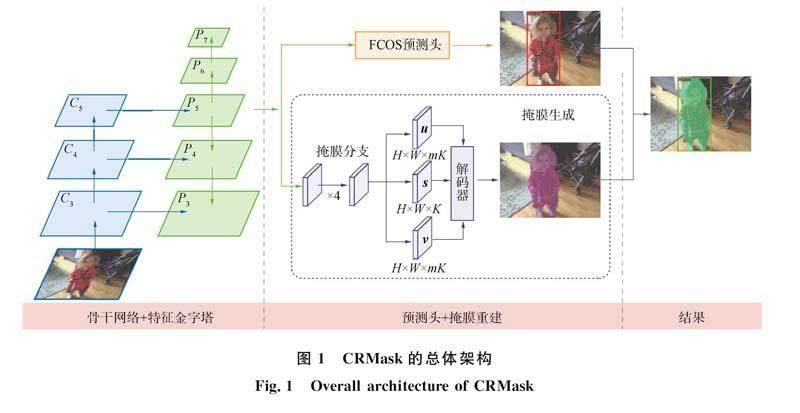
考虑到FCOS简洁、 高效和便于拓展的特点, 本文模型以FCOS为基础构建. 先在FCOS已有的分类和边界框回归分支的基础上, 并行添加一个掩膜分支以预测表征单元, 然后应用解码器用于组装表征单元以得到最终的掩膜. 模型的总体架构如图1所示, 其中左侧表示骨干网络和FPN(feature pyramid network)结构, 中间上部是FCOS中的预测头结构, 下部是本文的掩膜预测部分, 右侧是可视化结果.
1.2 压缩表示
注意到矩阵运算形式简洁、 运算高效且能在一定程度上重建高维信息, 如在维度衰减中矩阵运算被广泛用于特征分解和重建. 同时, 注意到一个矩阵可通过奇异值分解(SVD)分解为3个组件矩阵, 即奇异值矩阵、 左奇异矩阵和右奇异矩阵, 而仅使用组件的部分结构即可基本重建原始矩阵. 基于此, 本文设计一个具有类似结构的表示方法.
1.5 BlendMask++
本文表示方法不依賴于任何先验信息, 基于该方法的模型直接从预测头输出紧凑的表征单元, 并由解码器将其组装成为预测结果, 使得其可被即插即用地应用于其他需要生成密集二维信息的实例分割模型. 考虑到BlendMask[13]融合了自底向上和自顶向下方法, 其顶层分支为每个样本点预测多个注意力图, 本文将压缩表示方法嵌入到BlendMask的顶层分支以探究其通用性能, 被嵌入改进的模型称为BlendMask++.
为获得可信的结果, 嵌入过程中遵循最小改动原则. 为与BlendMask一致本文取消了掩膜分支, 表征单元和原模型中的边界框回归、 中心度预测等子分支一同直接从回归分支获得, 然后用解码器组装表征单元获得注意力图取代原注意力图. 嵌入结构如图3所示, 底层特征来自于底层分支的预测结果.
在默认情况下, BlendMask++所有超参数及设置与原始的BlendMask保持一致, 即特征图的分辨率设置为56, 注意力图的分辨率设置为14, 特征数量设置为4, 在特征数量不为1时取消Sigmoid非线性. 为适应更小的注意力图, 设置K=3. 在训练时除本文设备使用两块显卡外, 其他所有训练细节均与BlendMask完全一致, 实验结果列于表1, 其中AP表示平均准确度, AP50和AP75分别表示IoU阈值为05和075时的AP, APS,APM和APL分别表示像素面积小、 中、 大时的AP. 由表1可见, 相对于BlendMask, BlendMask++不仅有更好的性能, 而且推理速度也比BlendMask更快, 表明压缩表示方法的通用性能更好.
2 实 验
本文在数据集MS-COCO[14]上评估模型的性能, 数据集COCO是由微软出资标注的大型数据集, 其中train2017中包含约11.5万张图像, val2017中包含5 000张图像. 本文实验中的全部模型均在train2017上训练, 在val2017上做评估, 最终结果在test-dev上测试获得.
2.1 训练设置
本文使用ResNet50-FPN[15]作为骨干网络并使用其在ImageNet[16]上的预训练权重, 模型使用随机梯度下降(SGD)优化器, 设置Momentum超参数为0.9, 权重衰减超参数为0.000 1[17-18]. 训练在2块2080Ti显卡上进行, 设置批处理数量为8, 对模型进行5.4×105次迭代, 即约36个epoch. 初始学习率为0.005, 在到达3.6×105次迭代和4.8×105次迭代时分别将其衰减10倍, 其他所有参数都与FCOS保持一致. 此外, 设式(5)中的λ1=1, λ2=2.
2.2 消融实验
2.2.1 表征单元的维度
单元维度K表示表征单元的信息容量. 更大的K能确保表征单元学到更多的信息, 从而表示更复杂的掩膜, 但也会导致拟合更困难. 通常情况下, 标签掩膜都接近于满秩, 但表征单元的重建掩膜秩为K. 更低的秩阻碍了模型的表示能力, 从而导致不准确的重建掩膜.
本文在模型中尝试了一系列K值, 实验结果表明CRMask具有很好的健壮性, K并未显著影响模型的性能. 实验结果列于表2. 由表2可见, 当K=5时模型取得最佳性能, 表明本文的架构能学习到如何以有限的信息容量最大化地利用表征单元以表示掩膜的主要信息. 在本文模型默认情况下设K=5.
2.2.2 非线性解码
解码器中在矩阵相乘之后应用了Sigmoid函数以引入非线性. 为分析非线性的作用, 本文在模型中部署了一个线性解码器用于对比. 首先, 去掉解码器中的Sigmoid函数, 然后使用均方误差(MSE)损失函数代替交叉熵(BCE)损失函数, 优化目标是用线性解码后的掩膜在数值上逼近M, 实验结果列于表3. 由表3可见, 引入非线性解码器相对于线性解码器能实现0.8%的AP提升, 显然非线性具有更大的优势. 因此, 实例分割本质上是像素级别的类别预测问题, 更适合作为分类任务, 而编码器-解码器架构能很好地适应这种需求.
2.2.3 更大的感受野
通過在预测头部分引入可变性卷积(DCN)[19]考察增大感受野对CRMask的影响. 与MEInst一致, 将预测头的最后一层卷积层替换为可变性卷积层, 实验结果列于表4. 由表4可见, 相对于原始模型, 使用DCN的模型AP提升了0.6%, 并在除APS外的指标上均实现了更高的性能. 与MEInst应用DCN实现了1.5%的AP提升相比, 本文模型中应用DCN只实现了有限的性能提升. 表明CRMask能高效地保留和融合特征信息, 从而不依赖于显式的大感受野.
2.2.4 精度和速度平衡
对模型输入更大的图像尺寸能得到更准确的结果, 同时计算速度也更慢. 在测试时通过限制图像短边的尺寸获取不同的图像输入尺寸, 每个输入尺寸都用相同的模型运行, 运行的FPS(frame per second)在单块TITAN Xp上测量, 运行结果列于表5. 由表5可见, 在输入尺寸为400时本文模型能实现26.9%的AP同时达到实时的速度. 随着输入尺寸的减小, APS迅速减小而APL基本不变, 这也证明了小物体的分割效果对图像输入尺寸更敏感.
2.3 性能对比
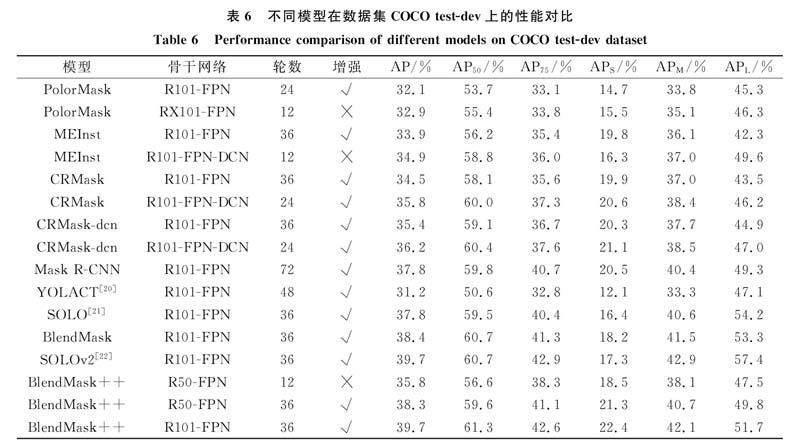
本文在数据集COCO test-dev上评估CRMask和BlendMask++的性能, 并分别与其他采用相似方法的模型进行对比. 考虑到MEInst在预测头的最后一层应用了DCN, 为方便比较, 本文在CRMask的基础上用相同方法部署了CRMask-dcn, 实验结果列于表6, 其中R101-FPN表示使用特征金字塔的ResNet-101架构, RX101-FPN表示使用FPN的ResNeXt-101架构, R101-FPN-DCN表示使用FPN并嵌入可变性卷积结构的ResNet-101架构, R50-FPN表示使用特征金字塔的ResNet-50架构.
未经过任何特殊处理, CRMask相对于其他框架具有较好的性能结果. 在骨干网络为ResNet-101-FPN时, CRMask-dcn的AP达到362%, 远超出同类方法的结果. 相对于BlendMask, BlendMask++实现了显著的性能提升, 总体性能基本与SOLOv2一致. 此外, 本文方法对小物体的分割效果较好, BlendMask++在小物体上的掩膜AP可达22.4%, 但对于大物体的分割效果相对较差.
综上所述, 针对目前实例分割领域掩膜表示高复杂度的问题, 本文提出了一种新的掩膜压缩表示方法. 该方法使用3个紧凑的表征单元表示掩膜, 并使用一个无参解码器重建掩膜. 基于这种方法, 本文构建了一个实例分割架构CRMask, 尽管架构简单, 但CRMask达到了较好的性能, 在单块TITAN Xp显卡上, CRMask可以在推理速度达到16.4帧/s的情况下实现33.0%掩膜AP. 此外, 本文将表示方法嵌入到BlendMask中重建注意力图, 改进的模型相对原始模型获得了更快的推理速度和更高的性能. 在使用ResNet101-FPN的情况下, BlendMask++掩膜AP达到了39.7%, 性能和SOLOv2一致, 是在同等条件下实例分割模型的最高性能.
参考文献
[1]HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN [C]//2017 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2017: 2961-2969.
[2]LIU S, QI L, QIN H F, et al. Path Aggregation Network for Instance Segmentation [C]//2018 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2018: 8759-8768.
[3]HUANG Z J, HUANG L C, GONG Y C, et al. Mask Scoring R-CNN [C]//2019 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2019: 6409-6418.
[4]LIN T Y, GOYAL P, GIRSHICK R B, et al. Focal Loss for Dense Object Detection [C]//2017 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2017: 2980-2988.
[5]TIAN Z, SHEN C H, CHEN H, et al. FCOS: Fully Convolutional One-Stage Object Detection [C]//2019 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2019: 9627-9636.
[6]REDMON J, DIVVALA S K, GIRSHICK R B, et al. You Only Look Once: Unifed, Real-Time Object Detection [C]//2016 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2016: 779-788.
[7]LONG J, SHELHAMER E, DARRELL T. Fully Convolutional Networks for Semantic Segmentation [C]//2015 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2015: 3431-3440.
[8]ZHANG R F, TIAN Z, SHEN C H, et al. Mask Encoding for Single Shot Instance Segmentation [C]//2020 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2020: 10223-10232.
[9]XU W Q, WANG H Y, QI F B, et al. Explicit Shape Encoding for Real-Time Instance Segmentation [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2019: 5167-5176.
[10]XIE E Z, SUN P Z, SONG X G, et al. PolarMask: Single Shot Instance Segmentation with Polar Representation [C]//2020 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2020: 12193-12202.
[11]PENG S D, JIANG W, PI H J, et al. Deep Snake for Real-Time Instance Segmentation [C]//2020 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2020: 8530-8539.
[12]WANG Y Q, XU Z L, SHEN H, et al. CenterMask: Single Shot Instance Segmentation with Point Representation [C]//2020 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2020: 9313-9321.
[13]CHEN H, SUN K Y, TIAN Z, et al. Blendmask: Top-Down Meets Bottom-Up for Instance Segmentation [C]//2020 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2020: 8570-8578.
[14]LIN T Y, MAIRE M, BELONGIE S J, et al. Microsoft Coco: Common Objects in Context [C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755.
[15]HE K M, ZHANG X Y, REN S Q, et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2016: 770-778.
[16]DENG J, DONG W, SOCHER R, et al. Imagenet: A Large-Scale Hierarchical Image Database [C]//2009 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2009: 248-255.
[17]WU Y X, KIRILLOV A, MASSA F, et al. Detectron2 [CP/OL]. (2019-09-05)[2022-02-12]. https://github.com/facebookresearch/detectron2.
[18]TIAN Z, CHEN H, WANG X L, et al. AdelaiDet: A Toolbox for Instancelevel Recognition Tasks [CP/OL]. (2020-01-23)[2022-02-12]. https://github.com/aim-uofa/AdelaiDet.
[19]DAI J F, QI H Z, XIONG Y W, et al. Deformable Convolutional Networks[C]//2017 IEEE International Conference on Computer Vision (ICCV). Washington D.C.: IEEE Computer Society, 2017: 764-773.
[20]BOLYA D, ZHOU C, XIAO F Y, et al. Yolact: Real-Time Instance Segmentation [C]//2020 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2019: 9157-9166.
[21]WANG X L, KONG T, SHEN C H, et al. SOLO: Segmenting Objects by Locations [C]//European Conference on Computer Vision. Berlin: Springer, 2020: 649-665.
[22]WANG X L, ZHANG R F, KONG T, et al. SOLOv2: Dynamic and Fast Instance Segmentation [C]//Advances in Neural Information Processing Systems. [S.l.]: Curran Associates, 2020: 17721-17732.
(責任编辑: 韩 啸)
收稿日期: 2022-03-07.
第一作者简介: 李文举(1997—), 男, 汉族, 硕士研究生, 从事计算机视觉的研究, E-mail: liwj237@163.com. 通信作者简介: 李文辉(1961—), 男, 汉族, 博士, 教授, 博士生导师, 从事计算机图形学、 图像处理和多媒体技术的研究, E-mail: liwh@jlu.edu.cn.
基金项目: 吉林省科技发展计划项目(批准号: 20230201082GX).
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
吉林大学学报(理学版)2023年4期