
基于YOLOX-S的车窗状态识别算法
2023-04-29 12:53:09黄键徐伟峰苏攀王洪涛李真真
吉林大学学报(理学版) 2023年4期
黄键 徐伟峰 苏攀 王洪涛 李真真


摘要: 通过对YOLOX-S模型引入可变形卷积神经网络和焦点损失函数(Focal loss), 解决原YOLOX-S模型车窗识别准确率较低的问题. 首先, 通过在YOLOX-S模型的主干特征提取网络中引入可变形卷积神经网络, 对卷积核中的各采样点引入偏移量, 以便在原始图像中提取到更具有表征的信息, 从而提高车窗识别的精准度; 其次, 使用Focal loss替代原模型中的二元交叉熵损失函数, Focal loss能缓解正负样本不平衡对训练的影响, 其在训练过程中更关注难样本, 从而提高了模型对车窗目标的识别性能; 最后, 为验证改进算法的性能, 实验收集并标注15 627张图片进行训练和验证. 实验结果表明, 改进后的车窗识别算法的平均目标精度提高了3.88%.
关键词: 车窗识别; YOLOX-S模型; 可变形卷积神经网络; 焦点损失
中图分类号: TP391文献标志码: A文章编号: 1671-5489(2023)04-0875-08
Car Window State Recognition Algorithm Based on YOLOX-S
HUANG Jian1, XU Weifeng1,2, SU Pan1,2, WANG Hongtao1,2, LI Zhenzhen1
(1. Department of Computer, North China Electric Power University (Baoding), Baoding 071003, Hebei Province, China;
2. Hebei Key Laboratory of Knowledge Computing for Energy & Power, Baoding 071003, Hebei Province, China)
Abstract: We solved the problem of low accuracy in car window recognition of the original YOLOX-S model by introducing deformable convolutional neural networks and Focal loss function (Focal loss) to the YOLOX-S model. Firstly, by introducing deformable convolutional neural networks into the backbone feature extraction network of the YOLOX-S model, offsets were introduced for each sampling point in the convolutional kernel to facilitate the extraction of more representative information from the original image, thereby improving the accuracy of car window recognition. Secondly, using Focal loss instead of binary cross entropy loss function in the original model, Focal loss could alleviate the impact of imbalance between positive and negative samples on training, and it paid more attention to difficult samples during the training process, thereby improving the recognition performance of the model for car window targets. Finally, in order to verify the performance of the improved algorithm, 15 627 images were collected and annotated for training and validation in the experiment. The experimental results show that the average target accuracy of the improved car window recognition algorithm increases by 3.88%.
Keywords: car window recognition; YOLOX-S model; deformable convolutional neural network; Focal loss
目前, 基于深度學习的神经网络技术已广泛应用于各领域. 依靠其强大的特征提取能力, 深度学习算法在目标检测识别方面取得了较高的精度. 目标检测可识别图像中特定物体的类别和图像中的位置, 已广泛应用于智能交通等领域中的车辆、 标识和人脸检测[1-3]中. 随着我国城市化水平的不断提升, 高速公路网的覆盖范围不断扩大, 为有效提高工作效率, 高速公路已采用了全新的收费管理模式, 广泛设置了ETC门架系统, 这为自动、 智能的人员排查和人员管理技术的实施提供了基础条件. 在高速公路上实现智能人员排查和人员管理的关键是准确识别车内人员, 而准确识别车内人员的前提条件是识别人员所乘车辆的车窗开关状态, 车窗状态检测算法通过锁定车辆自动识别车窗的开关状态, 因此, 准确、 高效的车窗状态检测算法是实现智能人员排查和人员管理的前提.
现有的检测算法R-CNN[4],Fast R-CNN[5],Faster R-CNN[6],SSD[7],YOLO等, 由于大量的训练數据积累和模型更新, 在主流数据集上相对传统方法均有较高的准确率和召回率. 深度学习的目标检测算法根据其检测思想的不同可分为两阶段算法和单阶段算法. 两阶段目标检测算法先对输入图像处理产生候选区域, 然后再对候选区域进行检测. 两阶段网络具有较高的精度, 但需要先提取候选区域再进行检测, 处理时间比单阶段网络高, 典型的代表性算法有Faster R-CNN[6],Mask R-CNN[8],Cascade R-CNN[9]和Sparse R-CNN[10]等. 由于两阶段目标检测算法不适用于对实时性要求较高的应用场景, 因此为进一步提高目标检测实时性, Redmon等[11]提出了将目标检测转化为回归问题的简化算法模型, 在提高检测速度的同时提高检测精度, 并提出了一系列基于位置回归的单阶段目标检测模型, 如YOLO和SSD模型等.
YOLO系列检测算法属于单阶段类检测算法, 其在基于深度学习的检测算法中具有速度优势, 但YOLOv1[11]和YOLOv2[12]的检测精度较低, 难以满足实际工程对精度的需求, 而精度较高的YOLOv3[13]检测速度却无法满足实际工程对时间的要求, YOLOv4[14]和YOLOv5[15]在检测精度和速度之间取得了平衡, 但平均目标精度有待提高. 文献[16]提出的解耦头(Decoupled head)[17\|18],Anchor-free[19\|20]和SimOTA[21]极大提高了平均目标精度. 目前在实际应用中, 针对车窗状态检测已有许多研究成果, 王亮亮等[2]提出了基于车窗特征的快速车辆检测算法, 通过识别车窗代替目标物进行检测, 从而提高被遮挡车辆的检出概率; 汪祖云等[22]提出了基于车窗区域代替完整车辆的出租车检测方法, 同时基于检测到的车窗区域实现对驾驶室的精确定位. 但在高速公路检测站等公共环境中为避免排队和拥堵, 对于车窗识别算法有更高的要求, 需要一种更快速、 精准的算法.
针对上述问题, 本文提出一种基于YOLOX-S改进的车窗识别算法. 首先, 利用可变形卷积神经网络[23]从原始图像中提取更多的特征信息, 在卷积核中对每个采样点的位置添加一个偏移量, 实现对当前位置的随机采样, 从而不局限于之前的规则格点; 其次, 由于传统的交叉熵损失函数并不能有效应对正负样本极度不平衡的情况, 即负样本占多数时, 导致训练易收敛到负样本, 从而无法有效学习正样本, 引用焦点损失函数(Focal loss)[24]替换模型中二元交叉熵损失函数(Binary cross entropy loss), 从而有效缓解正负样本不平衡的问题, 集中训练难以分类的样本, 提高模型在稀有类目标检测的准确性. 通过收集的到15 628张图片对改进算法进行了验证, 实验结果表明, 改进后的车窗识别算法取得了较高的平均精度均值(mean average precision, mAP).
1 预备知识
1.1 YOLOX模型
YOLOX模型是单阶段目标检测算法之一, 它将目标区域预测和目标类别预测集成到一个单一的神经网络模型中, 实现了快速、 高精度的目标检测和识别, 目前已成为工业场景中最实用的物体检测模型之一. YOLOX模型分为标准网络结构(包括YOLOX-S,YOLOX-M,YOLOX-L,YOLOX-X,YOLOX-Darknet53)和轻量级网络结构(包括YOLOX-Nano和YOLOX-Tiny). 由于YOLOX-S具有出色的检测性能和速度, 因此本文以其为基准模型.
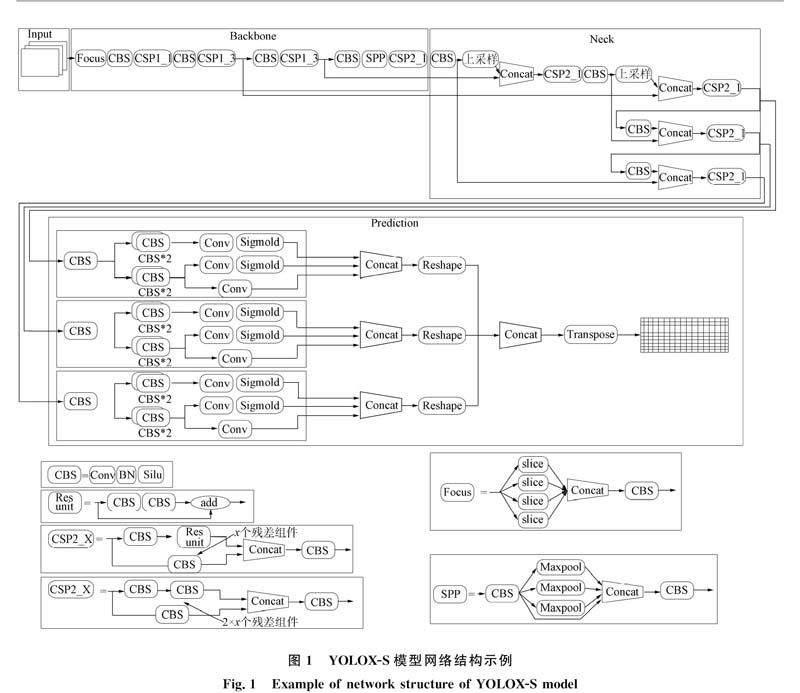
YOLOX-S由YOLOv5-S改进而得, 由4部分组成: Input,Backbone,Neck和Prediction, 其中Backbone由CSP网络和Focus结构组合构成. 在下采样过程中, 先使用切片操作的方法保证信息不丢失, 然后通过卷积操作得到特征图.
Neck是目标检测算法模型框架中具有承上启下作用的关键部件, Neck部分采用特征金字塔网络和路径聚合网络(FPN+PAN)的结构, 从不同的主干层对不同检测层进行特征聚合, 加强了网络的特征融合能力. 从主干网络提取的各层特征还需要送入Neck进行加工处理后才能送入Head, 以便后者更好地做出分类预测和回归预测. YOLOX的Neck部分是特征金字塔网络模式, 使富于空间信息的低层特征通过主干网络逐步抽象得到富于特征信息的高层特征图.
Prediction部分采用准确率更高、 收敛速度更快的解耦头, 并且引入Anchor-free机制, 实现与Head部分的完美结合. 最后采用简化的SimOTA方法求解最优解, 完成最终预测. 预测头对分类、 回归和类别判断这三者预测的路径各不相同. 解耦头就是预测头采用多个不同的头解耦输出, 使各任务关注任务自身所需要的特征信息, 这种方法可以有效避免任务之间的干扰, 提高模型的性能. 如果预测头不采用解耦头, 则在原图顶部的Conv2D_BN_SiLU模块输出结果将只会接入一个卷积层, 由后者输出预测结果, 从而导致任务之间的相互影响, 降低模型的性能.
Anchor-free, 即无锚框方法. 与采用基于锚框的YOLOX预测头的假设版本相比, 无锚框的YOLOX版本在预测时的参数量大幅度减少. 实际上, YOLOX也有锚框, 以YOLOX-Darknet53为例, 最终输出结果是85×8 400的特征向量, 后面的8 400扮演的角色即为锚框, 这些锚框需要与原图像上所有的目标框进行关联, 从而筛选出正样本锚框.
SimOTA是一种目标检测中的正样本分配算法, 可用于YOLOX网络中的预测头. 在标签分配过程中, SimOTA采用了中心先验法确认正样本候选区域, 然后通过计算各样本对真实目标(ground truth, GT)的分类和回归损失, 获得与当前GT的交并比(IOU)前10的样本. 其核心是动态调整k值, 可以根据不同的目标大小和密度自适应地调整, 而不需要手动设置. 即对每个GT, SimOTA会计算其与所有样本的IOU, 并将这些IOU值从大到小排序. 然后将前dynamic_k个样本的IOU值求和取整, 得到一个动态k值, 表示这个GT周围的样本密度. 最后, SimOTA会选择每个GT损失最小的前dynamic_k个样本作为正样本. 图1为YOLOX-S模型的结构.
1.2 可变形卷积神经网络
在目标检测任务中, 需要适应目标形态的差异. 为解决该问题, 通常使用形变不变性或增强数据集的方法. 这些方法虽然能够容纳已知固定类型的形变, 但在实践中很难应对复杂的形变. 卷积神经网络通常使用特征点采集特征图中固定位置的数据, 这种方式的几何形变建模能力主要来自数据集的扩展、 网络层数以及人工设计的模型. 但其仍无法解决复杂变形的检测问题.
针对卷积神经网络适应目标不规则形状的问题, 需引入可变形卷积的方法. 该方法通过在传统卷积采样点的基础上增加二维偏置实现采样网络的自由变形, 从而使卷积神经网络能适应目标的不规则形状. 这种偏置值通过增加卷积层获得, 能定位具有不同局部形态的对象. 该过程需要的参数和计算量较少, 因此可使用梯度反向传播算法进行端到端训练. 通过可变形卷积, 可得到一个简单的多层模型, 以适应目标物体形状的多样性.
传统卷积使用规则网格R在固定位置对输入特征图进行采样, 并使用权值ω对采样值进行加权求和, 其中网格R定义膨胀参数和感受野. 一般定义大小为3×3、 膨胀参数为1的卷积核R为R={(-1,-1),(-1,0),…,(0,1),(1,1)}.(1)特征图的标准卷积可表示为y(P)=∑Pn∈Rx(P+Pn)×ω(Pn),(2)其中P為特征图的原始位置, R为每个分块的索引编号, Pn是对R中所列位置的枚举, x(P+Pn)表示原始图, ω(Pn)表示权重. 由式(2)可知, 标准卷积操作只是对输入图像固定的位置进行加权操作, 其缺少形变建模的能力. 然而可形变卷积通过引入偏移量ΔPn增强卷积核在各采样点Pn的位置, 其特征图位置P可表示为y(P)=∑Pn∈Rx(P+Pn+ΔPn)×ω(Pn).(3)
通过设计网络学习偏移量, 可将固定位置的采样改为可形变位置的采样, 如图2所示. 该网络的工作原理如下: 在输入到输出的特征图计算中, 表示特征图两个方向的二维偏置首先由上部分卷积层计算, 使用与标准卷积核相同大小的卷积核对输入进行偏置映射, 通过对有偏置的输入进行普通卷积得到输出特征图. 输入特征图与有偏置输出结果的空间维数相同, 并且在训练网络执行时更新学习到的输出特征普通卷积的权重和可变形卷积偏移量的权值. 为获得实际的像素偏移值, 使用双线性插值运算进行计算.
2 模型设计
采用本文基于改进的YOLOX-S模型进行车窗识别, 第一部分改进是将可变形卷积神经网络应用于YOLOX-S模型的Backbone, 其主要优势是从图像中提取更多的特征信息. 另一部分改进是将筛选目标框的损失函数Binary cross entropy loss改变为Focal loss, 以解决正负样本不平衡的问题.
2.1 具有可变形卷积神经网络的YOLOX-S模型
YOLOX-S提取图像特征采用传统卷积神经网络, 其受卷积核和感受野大小的约束, 网络模型对物体几何形变的能力取决于数据本身的多样性. 本文利用可变形卷积神经网络对YOLOX-S进行改进, 在不增加额外标注信息和训练成本的情况下, 提高网络对空间变形的适应性, 从而提高YOLOX-S模型的目标识别精度.
YOLOX-S模型使用CSPDarkNet作为主干提取网络, 包含多个卷积层和模块(CBS模块、 CSP1_X模块、 CSP2_X模块等), 其中CBS模块包含3个核心组件: 卷积神经网络、 批归一化和Silu激活函数, 通过替换CBS模块中卷积神经网络为可变形卷积神经网络将CBS模块改为DBS模块, 然后将CSP1_X模块和CSP2_X模块中部分CBS模块替换为DBS模块. 通过引入可变形卷积神经网络, YOLOX-S模型能更好地适应目标物体的不规则形状, 从而提高目标检测的准确率和鲁棒性. 同时, 可变形卷积神经网络还能减少网络的参数量和计算量, 提高网络的运行效率. 图3为引入部分可变形卷积神经网络的YOLOX-S模型组成元件结构示例.
2.2 焦点损失函数的引入
目前, 单阶段检测器产生误差的主要原因是正负样本的不平衡[24]. 因为它们可以探测到所有位置, 单阶段检测器可以很容易地探测到候选框的总数. 在所有候选框中, 没有目标的候选框远多于有目标的候选框. 由于大多数都是简单易分的负样本(属于背景的样本), 并且大多数负样本在训练中没有意义, 使得训练过程不能充分学习到样本类别的信息, 导致模型退化. 因此, 本文引入Focal loss解决正负样本数量不均衡的问题.
3 实 验
3.1 数据集
本文实验所用数据均来自摄像头采集视频, 利用Opencv将视频分割成图片[25]. 从中选取合适的图片共15 627张, 将图片分为前车窗开启、 前车窗关闭、 后车窗开启、 后车窗关闭4类状态进行人工标注. 标注的工具是LabelImg软件, 该软件会生成Pascal Voc格式的XML标记文件. 在训练前, 对图像进行预处理, 参考数据集coco格式, 裁剪训练和测试的图像尺寸为880×720, 并将数据集分为训练集和测试集. 其中训练图像为14 065张, 测试图像为1 562张, 如图4所示.
3.2 实验环境及参数的设置
实验环境和基本配置如下: 深度学习框架采用Pytorch, 操作系统采用Ubuntu 18.04, 处理器为Intel(R) Xeon(R) Gold 6133 CPU @ 2.50 GHz, 运行内存为64 GB, 显卡为Tesla V100 32 GB, 编程语言采用Python.
实验采用YOLOX-S框架集成的mixup和mosaic两种数据增强方法, 使得数据集更丰富, 采用多尺度训练方法, 其中输入分辨率为880×720的图片, batch训练大小设置为32, 初始学习率为0.05, 开启半精度训练, 且训练轮次为1 000.
3.3 实验结果与分析
为检验本文提出的改进YOLOX-S模型在目标检测精准度上的性能, 从所有数据中随机抽取100张[KG*8]图片进行测试, 并确认测试图片不在训练集中, 测试结果示例如图5所示, 其中左上图识别结果为后车窗关闭状态, 左下图为前车窗关闭状态, 右上图识别结果为前车窗关闭状态, 右下图为前车窗关闭状态. 本文在车窗数据集上分别比较了原始YOLOX-S模型、 引入Focal loss的YOLOX-S模型、 引入部分可变形卷积的YOLOX-S模型和本文模型的4种目标检测方法. 评价指标采用mAP和mAP50_90, mAP是多类别的平均AP值, 常用于评估目标检测算法的性能, mAP50_90表示交并比阈值在0.5~0.9上的平均mAP. 测试结果列于表1. 由表1可见, 本文模型平均精度最高, mAP达95.59%.
为对比可变形卷积对提取图像特征信息的影响, 本文实验将YOLOX-S模型中所有的卷积神经网络替换为可变形卷积神经网络, 结果列于表2. 由表2可见, 替换所有的卷积神经网络为可变形卷积神经网络会导致模型过拟合, 从而使精准度下降.
综上所述, 为提高车窗检测的精度, 本文在YOLOX-S模型中引入了可变形卷积神经网络, 使模型可更好地学习目标的形态差异, 从而提升了模型的识别精度. 此外, 由于模型训练中预测框正负样本难以平衡, 本文引入Focal loss替换YOLOX-S模型中区分前景和背景的Binary cross entropy loss. 实验结果表明, 添加可变形卷积的YOLOX-S模型平均目標精度(mAP)提高了0.59%, mAP50_90提高了1.23%. 通过引入Focal loss使mAP提高了3.53%, mAP50_90提高了3.16%. 融合二者的新型YOLOX-S模型的mAP提高了3.88%, mAP50_90提高了3.60%. 表明本文模型提升了目标检测的精准度.
参考文献
[1]陈辉东, 丁小燕, 刘艳霞. 基于深度学习的目标检测算法综述 [J]. 北京联合大学学报, 2021, 35(3): 39-46. (CHEN H D, DING X Y, LIU Y X. Review of Target Detection Algorithm Based on Deep Learning [J]. Journal of Beijing Union University, 2021, 35(3): 39-46.)
[2]王亮亮, 王国栋, 赵毅, 等. 基于车窗特征的快速车辆检测算法 [J]. 青岛大学学报(自然科学版), 2019, 32(3): 1-7. (WANG L L, WANG G D, ZHAO Y, et al. Fast Vehicle Detection Algorithms Based on Window Characteristics [J]. Journal of Qingdao University (Natural Science Edition), 2019, 32(3): 1-7.)
[3]田强, 贾小宁. 基于深度残差网络的车标识别 [J]. 吉林大学学报(理学版), 2021, 59(2): 319-324. (TIAN Q, JIA X N. Vehicle Logo Recognition Based on Deep Residual Network [J]. Journal of Jilin University (Science Edition), 2021, 59(2): 319-324.)
[4]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 580-587.
[5]GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2015: 1440-1448.
[6]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[7]LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot Multibox Detector [C]//European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
[8]HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 386-397.
[9]CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into High Quality Object Detection [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2018: 6154-6162.
[10]SUN P Z, ZHANG R F, JIANG Y, et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals [EB/OL]. (2021-04-26)[2022-02-01]. https://arxiv.org/abs/2011.12450.
[11]REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 779-788.
[12]REDMON J, FARHADI A. YOLO9000: Better, Faster, Stronger [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 7263-7271.
[13]REDMON J, FARHADI A. Yolov3: An Incremental Improvement [EB/OL]. (2018-04-18)[2022-02-10]. https://arxiv.org/abs/1804.02767.
[14]BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection [EB/OL]. (2020-04-23)[2022-01-20]. https://arxiv.org/abs/2009.10934.
[15]JOCHER G. Yolov5 [EB/OL]. (2020-08-09)[2022-01-10]. https://github.com/ultralycs/yolov5.
[16]GE Z, LIU S, WANG F, et al. Yolox: Exceeding Yolo Series in 2021 [EB/OL]. (2021-08-06)[2022-02-20]. https://arxiv.org/abs/2017.08430.
[17]SONG G L, LIU Y, WANG X G. Revisiting the Sibling Head in Object Detector [EB/OL]. (2020-03-17)[2022-01-20]. https://arxiv.org/abs/2003.07540.
[18]WU Y, CHEN Y P, YUAN L, et al. Rethinking Classifification and Localization for Object Detection [EB/OL]. (2020-04-02)[2022-02-01]. https://arxiv.org/abs/1904.06493.
[19]TIAN Z, SHEN C H, CHEN H, et al. FCOS: Fully Convolutional One-Stage Object Detection [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2020: 9626-9635.
[20]ZHOU X Y, WANG D Q, KRHENBHL P. Objects as Points [EB/OL]. (2019-04-16)[2022-02-20]. https://arxiv.org/abs/1904.07850.
[21]GE Z, LIU S T, LI Z M, et al. Ota: Optimal Transport Assignment for Object Detection [EB/OL]. (2021-03-26)[2022-01-20]. https://arxiv.org/abs/2103.14259.
[22]汪祖云, 廖惠敏, 黃训平, 等. 基于车窗区域定位的出租汽车驾驶员蓄须行为的自动检测技术研究 [J]. 交通运输研究, 2018, 4(4): 41-47. (WANG Z Y, LIAO H M, HUANG X P, et al. Automatic Detection Technology of Taxi Driver Is Beard Based on Car Window Area Location [J]. Transport Research, 2018, 4(4): 41-47.)
[23]DAI J F, QI H Z, XIONG Y W, et al. Deformable Convolutional Networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 764-773.
[24]LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection [EB/OL]. (2018-02-07)[2022-02-01]. https://arxiv.org/abs/1708.02002.
[25]李菊霞. 基于深度学习的二值图像目标轮廓识别算法 [J]. 吉林大学学报(理学版), 2020, 58(5): 1189-1194. (LI J X. Binary Image Target Contour Recognition Algorithm Based on Deep Learning [J]. Journal of Jilin University (Science Edition), 2020, 58(5): 1189-1194.)
(责任编辑: 韩 啸)
收稿日期: 2022-06-18.
第一作者简介: 黄 键(1993—), 男, 汉族, 硕士研究生, 从事计算机视觉的研究, E-mail: 220192221099@ncepu.edu.cn. 通信作者简介: 徐伟峰(1982—), 男, 汉族, 博士, 从事计算机视觉和空管系统的研究, E-mail: weifengxu@163.com.
基金项目: 国家自然科学基金(批准号: 61802124)、 全国高等院校计算机基础教育研究会项目(批准号: 2019-AFCEC-125)和中央高校基本科研业务费专项基金(批准号: 2021MS089).
吉林大学学报(理学版)2023年4期