
基于混合机器学习模型的短文本语义相似性度量算法
2023-04-29 17:53:06韩开旭袁淑芳
吉林大学学报(理学版) 2023年4期
韩开旭 袁淑芳

摘要: 为提高短文本语义相似性度量准确性, 设计一种基于混合机器学习模型的短文本语义相似性度量算法. 先对短文本实施预处理, 基于混合机器学习模型构建短文本的字词向量模型, 对短文本进行特征扩展; 然后组合短文本的多样度量特征, 对多样度量特征进行维度规约; 最后通过构建一个集成学习模型, 计算语义相似性结果, 实现语义相似性的度量. 使用“Quora Question Pairs”比赛数据集测试该方法的性能, 测试结果表明, 该方法的准确性较高, 对数损失和度量均方差均较低, 说明该方法的相似性度量准确性较高.
关键词: 混合机器学习模型; 短文本; 文本分词; 语义相似性; 卡方检验; 相似性度量
中图分类号: TP391 文献标志码: A 文章编号: 1671-5489(2023)04-0909-06
Short Text Semantic Similarity Measurement Algorithm Based on Hybrid Machine Learning Model
HAN Kaixu1, YUAN Shufang2
(1. College of Electronics and Information Engineering, Beibu Gulf University,
Qinzhou 535011, Guangxi Zhuang Autonomous Region, China;
2. College of Sciences, Beibu Gulf University, Qinzhou 535011, Guangxi Zhuang Autonomous Region, China)
Abstract: In order to improve the accuracy of short text semantic similarity measurement, we designed a short text semantic similarity measurement algorithm based on a hybrid machine learning model. Firstly, we preprocessed the short text, constructed a word vector model of the short text based on the hybrid machine learning model, and extended the features of the short text. Secondly, we combined the various metric features of the short text, implemented dimensional reduction on the various metric features. Finally, we constructed an ensemble learning model to calculate the semantic similarity results and achieve the semantic similarity measurement. We tested the performance of the method by using the “Quora Question Pairs” competition dataset, the test results show that the accuracy of the method is high, the logarithmic loss, and the measurement mean square error are both low, indicating that the similarity measurement accuracy of the method is high.
Keywords: hybrid machine learning model; short text; text segmentation; semantic similarity; Chi-square test; similarity measurement
短文本虽然文本较短, 但其内容能容纳很微妙的语言表达, 在很多实际应用中, 都需要批量处理短文本数据[1]. 但对于大规模数据, 通常难以分辨短文本的语义相似性, 基于该背景对短文本语义相似性度量问题进行研究.
在自然语言处理技术中, 文本相似性度量一直是研究重点. 文本相似性度量的传统算法更适合在长文本上应用, 对于短文本常无法取得满意的效果, 因此需要对短文本相似性度量进行专门研究. 目前, 关于该问题的研究已有许多成果. 石彩霞等[2]提出了一种准确率较高的短文本语义相似性度量算法, 从短文本的稀疏特性出发, 通过多重检验加权融合实现相似性度量, 并取得了合理准确的计算结果. 本文应用混合机器学习模型对该问题进行研究, 设计一种基于混合机器学习模型的短文本语义相似性度量算法, 以实现更准确的相似性度量.
1 算法设计
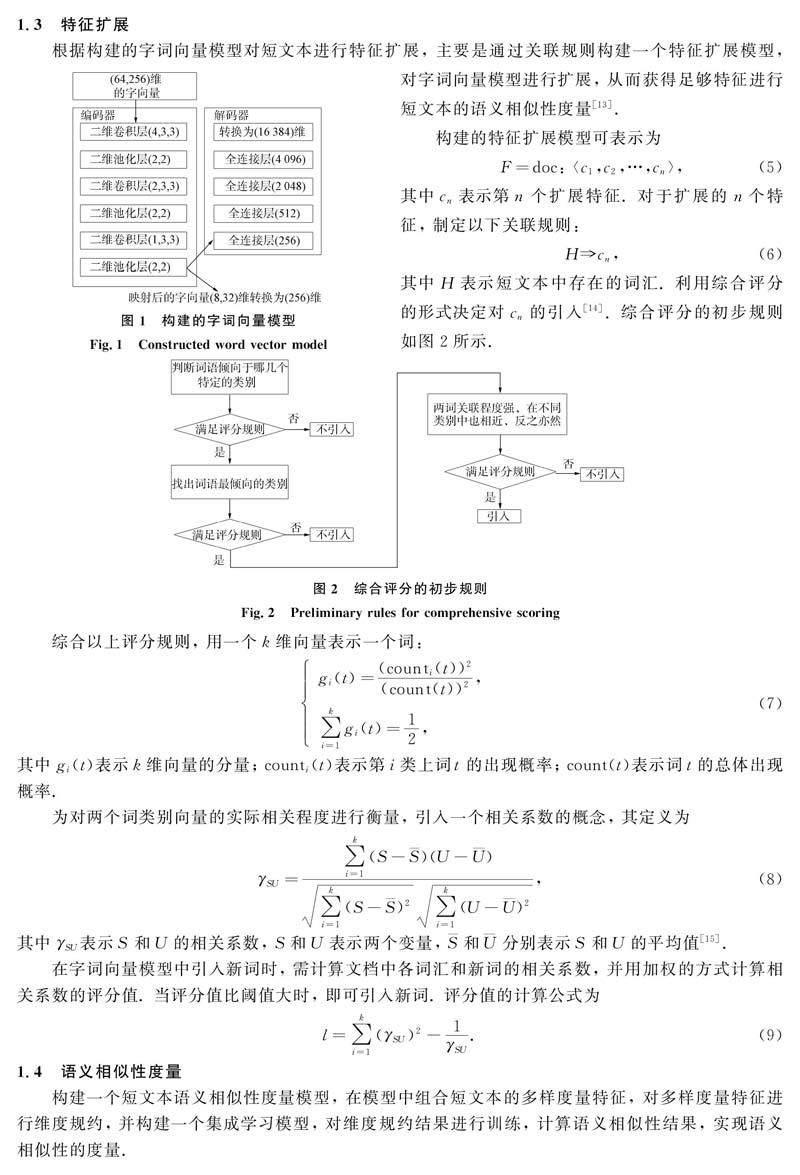
1.1 短文本预处理
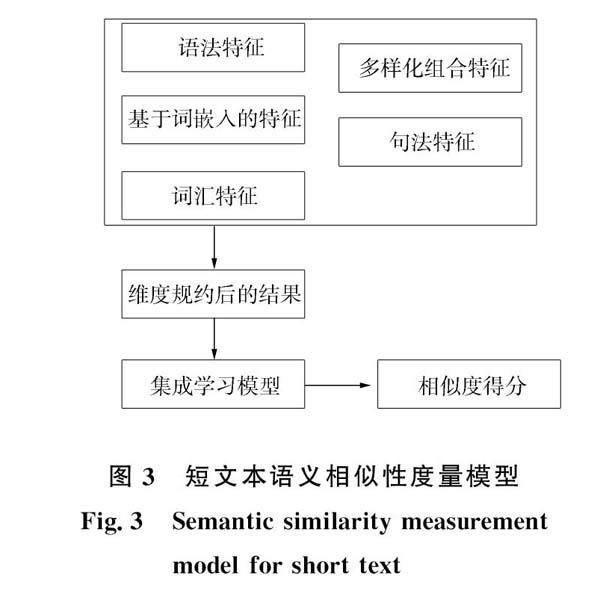
2.3 实验结果与分析
首先将数据集中的数据平均分成5份, 在每份数据中随机划分出80%作為训练集, 剩下的数据作为测试集. 在不同的提取特征数量下分别对训练集和测试集的Accuracy数值进行测试, 测试结果如图4所示. 由图4可见, 在不同的提取特征数下, 本文方法的Accuracy数值都较高, 说明该方法的短文本语义相似性度量准确率较高. 在提取特征数为3时, 训练集和测试集的Accuracy数值最高.
其次分别对训练集和测试集的Log loss数值进行测试, 测试结果如图5所示. 由图5可见, 本文方法训练集和测试集的Log loss数值均较低, 说明该方法在语义相似性度量中的对数损失较低, 度量性能较好.
最后对设计方法的度量均方差进行测试, 测试结果列于表2. 由表2可见, 通过该方法进行短文本语义相似性度量后, 训练集和测试集的度量均方差都较低, 表明本文方法的度量准确率较高.
综上所述, 本文在对短文本语义相似性度量问题进行研究的过程中, 应用了混合卷积神经网络学习模型和全连接神经网络学习模型的混合机器学习模型, 设计了一种基于混合机器学习模型的短文本语义相似性度量算法, 经过测试其在Accuracy,Log loss和度量均方差3個指标上均较优, 提高了短文本相似性度量准确率, 有一定的应用价值.
参考文献
[1]郑志蕴, 吴建萍, 李钝, 等. 一种基于短文本相似度计算的知识子图融合方法 [J]. 小型微型计算机系统, 2020, 41(1): 6-11. (ZHENG Z Y, WU J P, LI D, et al. A Knowledge Subgraph Fusion Method Based on Short Text Similarity Calculation [J]. Small Microcomputer Systems, 2020, 41(1): 6-11.)
[2]石彩霞, 李书琴, 刘斌. 多重检验加权融合的短文本相似度计算方法 [J]. 计算机工程, 2021, 47(2): 95-102. (SHI C X, LI S Q, LIU B. Short Text Similarity Calculation Method Based on Weighted Fusion of Multiple Tests [J]. Computer Engineering, 2021, 47(2): 95-102.)
[3]赵雅欣, 郑明洪, 石林鑫, 等. 面向电力审计领域的两阶段短文本分类方法研究 [J]. 西南大学学报(自然科学版), 2020, 42(10): 1-7. (ZHAO Y X, ZHENG M H, SHI L X, et al. Research on Two-Stage Short Text Classification Method for Electric Power Auditing [J]. Journal of Southwest University (Natural Science Edition), 2020, 42(10): 1-7.)
[4]寇菲菲, 杜军平, 石岩松, 等. 面向搜索的微博短文本语义建模方法 [J]. 计算机学报, 2020, 43(5): 781-795. (KOU F F, DU J P, SHI Y S, et al. A Search-Oriented Approach to Semantic Modeling of Microblog Short Texts [J]. Chinese Journal of Computers, 2020, 43(5): 781-795.)
[5]唐善成, 张雪, 张镤月, 等. 融合中文字形和字义的字向量表示方法 [J]. 科学技术与工程, 2021, 21(32): 13787-13792. (TANG S C, ZHANG X, ZHANG P Y, et al. A Word Vector Representation Method Integrating Chinese Character Shape and Character Meaning [J]. Science Technology and Engineering, 2021, 21(32): 13787-13792.)
[6]陶玥, 余丽, 吴振新. CoTransH: 科技文献知识图谱中语义关系预测的翻译模型 [J]. 情报理论与实践, 2021, 44(11): 187-196. (TAO Y, YU L, WU Z X. CoTransH: A Translation Model for Semantic Relationship Prediction in Knowledge Graphs of Scientific and Technological Documents [J]. Information Theory and Practice, 2021, 44(11): 187-196.)
[7]叶俊民, 罗达雄, 陈曙. 基于短文本情感增强的在线学习者成绩预测方法 [J]. 自动化学报, 2020, 46(9): 1927-1940. (YE J M, LUO D X, CHEN S. Online Learner Performance Prediction Method Based on Short Text Sentiment Enhancement [J]. Journal of Automation, 2020, 46(9): 1927-1940.)
[8]高云龙, 吴川, 朱明. 基于改进卷积神经网络的短文本分类模型 [J]. 吉林大学学报(理学版), 2020, 58(4): 923-930. (GAO Y L, WU C, ZHU M. Short Text Classification Model Based on Improved Convolutional Neural Network [J]. Journal of Jilin University (Science Edition), 2020, 58(4): 923-930.)
[9]汤凌燕, 熊聪聪, 王嫄, 等. 基于深度学习的短文本情感倾向分析综述 [J]. 计算机科学与探索, 2021, 15(5): 794-811. (TANG L Y, XIONG C C, WANG Y, et al. A Review of Short Text Sentiment Analysis Based on Deep Learning [J]. Computer Science and Exploration, 2021, 15(5): 794-811.)
[10]饶毓和, 凌志浩. 一种结合主题模型与段落向量的短文本聚类方法 [J]. 华东理工大学学报(自然科学版), 2020, 46(3): 419-427. (RAO Y H, LING Z H. A Short Text Clustering Method Combining Topic Model and Paragraph Vector [J]. Journal of East China University of Science and Technology (Natural Science Edition), 2020, 46(3): 419-427.)
[11]刘娇, 李艳玲, 林民. 胶囊网络用于短文本多意图识别的研究 [J]. 计算机科学与探索, 2020, 14(10): 1735-1743. (LIU J, LI Y L, LIN M. Research on Capsule Networks for Multi-intent Recognition of Short Texts [J]. Computer Science and Exploration, 2020, 14(10): 1735-1743.)
[12]繆亚林, 姬怡纯, 张顺, 等. CNN-BiGRU模型在中文短文本情感分析的应用 [J]. 情报科学, 2021, 39(4): 85-91. (MIAO Y L, JI Y C, ZHANG S, et al. Application of CNN-BiGRU Model in Sentiment Analysis of Chinese Short Texts [J]. Information Science, 2021, 39(4): 85-91.)
[13]张博, 孙逸, 李孟颖, 等. 基于迁移学习和集成学习的医学短文本分类 [J]. 山西大学学报(自然科学版), 2020, 43(4): 947-954. (ZHANG B, SUN Y, LI M Y, et al. Classification of Medical Short Texts Based on Transfer Learning and Ensemble Learning [J]. Journal of Shanxi University (Natural Science Edition), 2020, 43(4): 947-954.)
[14]孙洋, 粟栗, 张星, 等. 基于子语义空间的挖掘短文本策略方法 [J]. 电信科学, 2020, 36(3): 83-92. (SUN Y, SU L, ZHANG X, et al. Strategy Method for Mining Short Text Based on Sub-semantic Space [J]. Telecommunications Science, 2020, 36(3): 83-92.)
[15]宋明, 刘彦隆. Bert在微博短文本情感分类中的应用与优化 [J]. 小型微型计算机系统, 2021, 42(4): 714-718. (SONG M, LIU Y L. Application and Optimization of Bert in Microblog Short Text Sentiment Classification [J]. Small Microcomputer System, 2021, 42(4): 714-718.)
[16]王生生, 张航, 潘彦岑. 改进的和积网络自动编码器及短文本情感分析应用 [J]. 哈尔滨工程大学学报, 2020, 41(3): 411-419. (WANG S S, ZHANG H, PAN Y C. Improved Sum-Product Network Autoencoder and Short Text Sentiment Analysis Application [J]. Journal of Harbin Engineering University, 2020, 41(3): 411-419.)
(责任编辑: 韩 啸)
收稿日期: 2022-04-15.
第一作者简介: 韩开旭(1984—), 男, 汉族, 博士, 讲师, 从事机器学习和自然语言处理的研究, E-mail: frog0696@163.com. 通信作者简介: 袁淑芳(1988—), 女, 汉族, 硕士, 助理研究员, 从事机器学习的研究, E-mail: ysf20210605@126.com.
基金项目: 国家自然科学基金面上项目(批准号: 61374127)和广西高校中青年教师科研基础能力提升项目(批准号: 2021KY0434; 2020KY10019).
吉林大学学报(理学版)2023年4期