
基于关键词共现网络的主题词提取算法
2023-04-29 21:59张书谙王曦代继鹏隋毅孙仁诚
复杂系统与复杂性科学 2023年1期
关键词:主题词
张书谙 王曦 代继鹏 隋毅 孙仁诚

摘要:针对主题词提取中关键词提取不准确以及仅考虑单一相关性的问题,提出一种将集成思想与复杂网络相结合的主题词提取算法。首先通过集成算法提取话题数据的关键词,以提高关键词提取的准确性,其次改进传统词共现公式计算关键词的共现度,并建立关键词共现网络,在网络的基础上得到最优连通子图,同时以节点度中心性为权重衡量关键词重要性并从中映射出主题词。最后,使用微博话题数据集进行实例验证,证明该算法是有效的,并优于传统的词共现算法,并在青岛社区话题数据集中进行应用。
关键词:关键词;共现度;共现网络; 主题词; 微博话题
中图分类号: TP391.1文献标识码: A
收稿日期:2021-09-08;修回日期:2021-11-30
基金项目:国家自然科学基金青年科学基金(41706198)
第一作者:张书谙(1998-),女,山东泰安人,硕士研究生,主要研究方向为自然语言处理,复杂网络大数据分析。
通信作者:孙仁诚(1977-),男,山东青岛人,博士,教授,主要研究方向为基于复杂网络的大数据分析。
Subject Words Extraction Algorithm Based on Keyword Co-occurrence Network
ZHANG Shuan1, WANG Xi2, DAI Jipeng1, SUI Yi1, SUN Rencheng1
(1.School of Computer Science and Technology, QingDao University, Qingdao 266071, China;
2.Communication Dispatching Department, Qingdao Emergency Center,Qingdao 266035, China)
Abstract:Aiming at the problems of inaccurate keywords extraction and only considering single correlation in subject words extraction, a subject words extraction algorithm combining integration idea with complex network is proposed. Firstly, the keywords of topic data are extracted through the integration algorithm to improve the accuracy of keywords extraction. Secondly, the traditional word co-occurrence formula is improved to calculate the co-occurrence degree of keywords, and a keywords co-occurrence network is established. Based on the network, the optimal connected subgraph is obtained. At the same time, the importance of keywords is measured by taking the centrality of node degree as the weight, and the subject words are mapped. Finally, the micro-blog topic data set is used to verify the example, which proves that the algorithm is effective and better than the traditional word co-occurrence algorithm, and it is applied in the Qingdao community topic data set. Key words: keywords; co-occurrence degree; co-occurrence network; subject words; micro-blog topic
0 引言
用户在社交平台提交的数据称为话题数据。主题词是描述一类相似话题的词或短语,一般认为3个主题词可以表征一类话题。在热点话题研究中,主题词提取的质量决定热点话题发现的准确性[1]。
经典的主题词提取方法主要针对长文本,大都采用基于统计的方法。如Witten[2]提出KEA系统,基于词语出现的位置及频率等提取主题词,适用性好,但易产生干扰词。为此,赵英环[3]提出主题词迭代提取算法,提高了准确性。为了将词语与文本信息结合,文献[4-7]等基于语义理解提出相应的主题词提取算法。另外,复杂网络理论也被用来发现文档主题词,文献[8-9]等将语言与复杂网络结合提取主题词。
对于微博话题等短文本数据,由于字数有限,话题中主题词出现的频率低,因此基于统计的方法对短文本的處理不是很适用。为提高短文本中主题词提取的质量,叶成绪[10]利用维基百科知识设计算法筛选主题词并用于微博热点话题发现。另外,一些学者对LDA算法[11]进行改进,张晨逸等[12]针对微博数据建立MB-LDA模型,李继云等[13]提出CGRMB-LDA模型,冯勇等[14]基于时间权重和影响因子提出TIF-LDA算法。另一方面,张孝飞等[15]将语义概念和词共现结合提取微博主题词,考虑了相关词对短文本主题词提取的影响,但需要将短文本扩充为长文本。关键词是表征话题数据的核心词语,实际上,主题词提取的关键在于话题中关键词提取的准确性以及基于词语相关性的主题词发现。上述算法针对各自解决的问题仅考虑单一方面,为了更好地结合这两方面,本文采用集成算法思想与复杂网络理论完成主题词的提取。
考虑到TextRank算法[16]较好地考虑话题数据内词语关联性,TF-IDF算法[17-18]考虑了话题间词语的相关性,因此本文集成多种算法的提取结果,提出话题关键词提取算法;然后通过关键词共现关系构建话题的关键词共现网络,最终在网络中映射出代表某类话题的主题词。
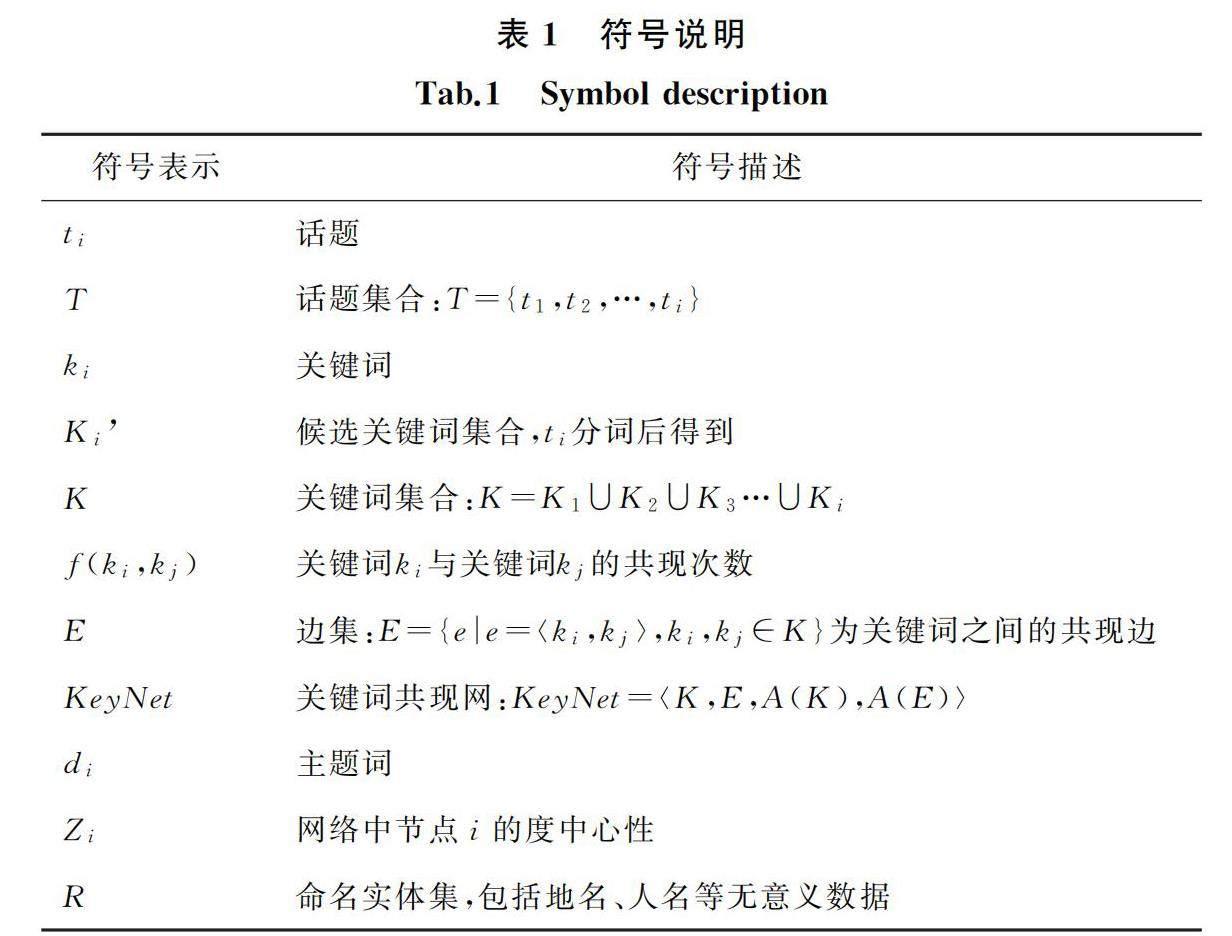
1 符号描述
在表1中给出本文使用的主要符号及其说明。
本文涉及到的部分术语定义如下:
定义1 话题集,由所有的话题数据组成,记为T;T中每一句话称为一个话题ti,其中i=1,2,3…|T|,|T|为话题集中的话题个数。
定义2 关键词集,对ti∈T,可以提取出多个关键词表征该话题,称为ti的关键词集合,记为Ki;在T中提取出的所有关键词称为T的关键词集,记为K,K=K1∪K2∪K3…∪Ki,其中i=1,2,3…|T|。
定义3 共现次数,若关键词ki,kj出现在同一ti中,就说ki,kj共现,关键词共现在某种程度上反映了关键词之间的上下文语义关联。本文用f表示两个关键词共现的次数。
定义4 关键词共现网,记为KeyNet=〈K,E,W〉。K={k1,k2,…,kn}是网络中节点的集合,由关键词组成;E={e|e=〈ki,kj〉,ki,kj∈K}是边的集合,为关键词节点之间的共现无向边;W表示各边的权重,若e=〈ki,kj〉∈E,那么0
定义5 话题簇,表达同一类主题的话题称为话题簇,可以从一类话题簇中映射出一个或多个关键词表征该话题簇,这类关键词叫做主题词。
定义6 主题词集,所有话题簇的主题词组成主题词集,记为D。D=D1∪D2∪D3…∪Di,i表示T被分为i类话题簇,Di={d1,d2,…,dj}表示在第i类话题中提取出的主题词集合,j表示每个话题簇中提取的主题词个数为j个。当j=1时,D={d1,d2,…,di}。
定义7 度中心性,指无向网络中当前节点与邻居节点直接连边数量的总和,反映节点在网络中的重要程度[19]。在关键词共现网络中,Z值越大节点热度越高,越能代表话题簇。Zi计算如式(1)中所示:
其中,N为节点总数,zij为节点i和节点j之间是否存在连边,如果连边,则zij=1,否则zij=0。
根据上述定义,给出本文的主题词提取算法的符号描述:{D1,D2,…,Di}=FUN(T),i表示在所有话题数据T中可以得到i个话题簇。
2 基于关键词共现网络的主题词提取算法
该算法基于集成算法和改进的词共现公式提取主题词,既可以提高关键词提取的准确性,又保留了词与词之间的共现关系,同时提取出的主题词具有更强的主题表现力。算法大致分为三步:1)将关键词提取算法集成产生K;2)计算关键词之间的共现关系建立KeyNet;3)调整阈值产生连通子图并映射出主题词。
2.1 关键词提取
关键词是主题词提取的关键。目前较经典的关键词提取算法有TF-IDF算法、TextRank算法和哈工大的LTP关键词提取技术,它们各有优缺点。TF-IDF算法易于理解和实现,考虑整体语境,但它仅以词频衡量词语的准确性,使得频率低的特征词不能被识别;TextRank算法可以有效地查询节点之间的相关性,考虑话题内部词语的相似关系,但没有考虑上下文信息;LTP可以自动分析语句中词语的依存关系,提取出具有关联关系的关键词,但在分词中存在误差,产生一些错误的关联关系。
基于此,本文利用TextRank算法和LTP提取话题中的语义关系,如相似和依存关系,TF-IDF算法提取词频关系,对两种算法补充,避免使用单一算法产生的不准确问题。同时使用百度自然语言处理工具(LAC)进行分词监督,减少误差,并将命名实体识别出来存入停词表P中,得到ti的候选关键词集K′i。最终将3种算法提取的关键词集按一定比例集成得到ti的关键词集合Ki。集成操作H如公式(2)中定义。
算法1 Key_Extract
輸入:话题集合T,权重参数a,b,c
输出:关键词集K
1)对每个话题ti分词,使用LAC工具进行分词监督;2)分词后的词语作为候选关键词,加入候选关键词集Ki'中;3)对Ki'执行TF-IDF算法,得到关键词集KIi;4)对Ki'执行TestRank算法,得到关键词集KRi;5)对Ki'执行LTP技术,得到关键词集KLi;6)执行集成操作H,将KIi、KRi、KLi按照权重为a:b:c的比例集成得到Ki;7)将每个话题ti的关键词集合Ki合并到K中;8)return K。
2.2 建立关键词共现网络
将词语映射到复杂网络,发现词和词之间的联系符合自然语言学特性,可以更好为文本分析提供帮助。另外,关键词共现在某种程度上可以被认为代表一个相关主题,属于一个话题簇。在此基础上,将关键词按照共现关系连接成网,建立关键词共现网络,网络模型如图1所示。
共现关系由共现度体现,它用来描述ki,kj共现的频率。频率越高,关键词之间联系越紧密。节点ki相对于节点kj的相对共现度R(ki,kj)如式(3)中所示。
其中,f(ki,kj)为关键词ki,kj共现的次数,f(kj)为kj出现的总次数。
若ki,kj均是一个话题的特征词,但同时出现次数过少,那么根据R计算出的值会很小,连边时容易被忽略。针对话题内容简短,特征数量少的问题,本文对R进行改进得到共现度计算公式,如式(4)所示。
其中,C(ki,kj)為关键词ki,kj的共现度,f(ki)为ki出现的总次数。
式(4)中,C(ki,kj)的结果比R相对较大一些,更可能产生连边。其次,R中R(ki,kj)一般不等于R(kj,ki),最终结果不是一个确定的数,而在本文的公式中,共现度是一个确定值。KeyNet建立算法如下:
算法2 KeyNet_Establish
输入:关键词集K,初始连边阈值p
输出:关键词共现网络KeyNet
1)对K中的关键词ki,两两计算共现度Wkikj=C(ki,kj);2)判断共现度Wkikj是否大于初始阈值p;3)若Wkikj大于p,则关键词ki、kj之间连边,连边权重为Wkikj,且e=
2.3 主题词提取算法
KeyNet包含多个连通子图,连通子图之间是独立的,通过调整连边阈值可以使划分的连通子图效果达到最优。观察K可以发现,同一类话题中关键词成对出现的概率较大,表达的主题相关,共现度更高。这说明连通子图内部话题之间是有关联的,每个连通子图代表一个话题簇。连通子图模型如图2所示。
定义C表示节点在KeyNet中的重要程度,C为与当前节点相连的所有节点的共现度之和。若节点i与节点j和k都有连边,则Ci=C(ki,kj)+C(ki,kk)。在连通子图内部,节点的C值越高,越能代表该话题簇。基于此,首先计算连通子图中节点的度中心性,并以此为权重与C值相乘,得到节点的加权C值,然后进行排序,选出排名靠前的节点所代表的关键词作为该话题簇的主题词。在图2中,不同的椭圆框表示产生不同的连通子图,节点的大小表示该节点C值的大小,节点越大,表示该节点C值越大,更容易作为该话题簇的主题词提取出来。主题词提取算法如下:
算法3 D_Extract
输入:关键词共现网络KeyNet,每个话题簇中主题词个数h
输出:主题词集合D
1)修改KeyNet网络的连边阈值,得到最优连通子图集合N;2)统计连通子图个数n=N,以此作为话题簇的数量;3)对于每个连通子图,计算每个节点的度中心性Zi和重要程度Ci;4)将Zi与Ci相乘得到每个节点的加权C值;5)按照加权C值的大小对每个连通子图中节点的重要性从大到小排序;6)在排序后的每个连通子图中抽取前h个关键词作为该话题簇的主题词集Di;7)将每个话题簇的最终主题词合并,得到整个话题集的主题词集D={D1,D2,…,Dn};8)return D。
3 实验
为验证算法有效性,设置以下实验。首先使用微博话题数据集验证算法的有效性,然后在青岛社区话题数据集上进行实例应用。实验均使用Anaconda3和Pycharm进行开发,所用编程语言为Python。话题数据一般都带有Emoji表情、颜文字、特殊字符、网址等无关信息,这些信息没有实际意义,并且可能导致分词错误。因此,使用规则过滤库对话题数据进行预处理,保证实验顺利进行。
3.1 算法有效性验证
3.1.1 数据集及实验介绍
因微博数据带有分类标签,易对实验结果进行判断,所以使用它验证算法的有效性。该数据集囊括了12个主题的微博数据,包括用户发起的话题信息、转发信息和评论信息等。共进行4次实验,每次实验随机选取10个主题,在每个主题中选取100条话题数据,每次共1 000条数据。
在KeyNet中通过调整阈值产生最优的连通子图,在产生的所有连通子图中得到最终的10个话题簇,并选择C值最大的主题词代表该话题簇,记录实验结果,将选出的主题词与标签词语进行比较。为了科学地评价算法的效果,使用查准率P作為实验的衡量指标,计算公式如式(5)所示。
其中,TP为提取的与原标签一致的词语,FP为提取的与原标签不一致的词语。
3.1.2 集成比例与阈值确定
为确定共现度阈值,分别使用0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6进行实验。同时,为了确定集成比例对实验结果的影响,使用TF-IDT: TextRank: LTP为1∶1∶2,1∶2∶1,2∶1∶1以及1∶1∶1进行实验,其中1∶1∶2表示在集成过程中LTP方法的影响较大。在阈值与集成比例的不同组合下,共进行4组实验,计算P值,并取平均值,实验结果如表2中所示。为便于分析,将实验结果绘制成折线图如图3所示。
通过图3,可以看出不同阈值下实验结果的波动性很大,另外,不同的集成比例对结果也有影响,3种算法的集成比例分别为1∶1∶2时效果较好。在集成比例为1∶1∶2下,选择0.5作为阈值所产生的效果最好,且查准率的平均值达到峰值0.83。经多次实验得到在微博数据集上较好阈值范围为0.4到0.5之间。
3.1.3 对比实验
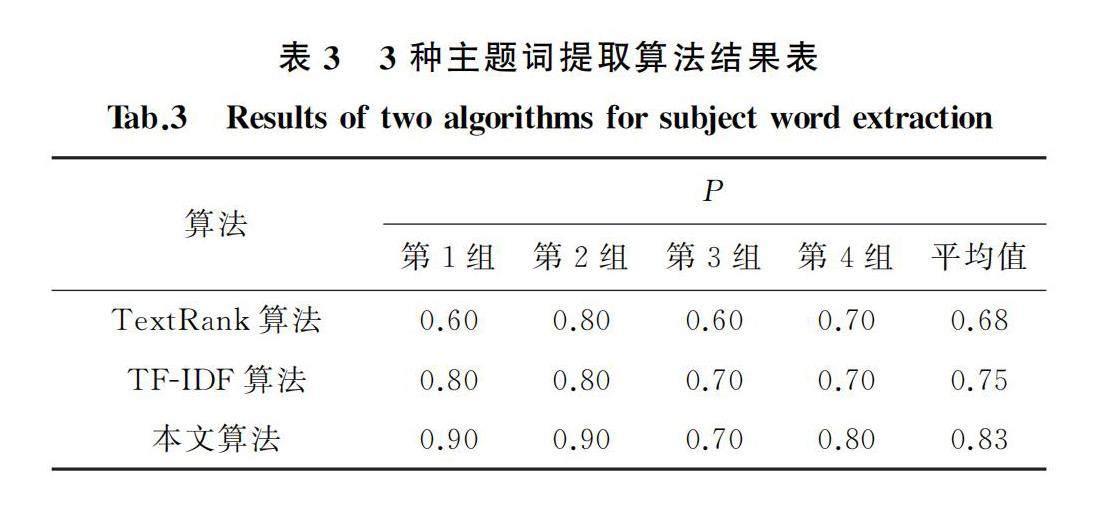
使用阈值0.5,在相同数据条件下将TextRank算法、TF-IDF算法与本文算法进行对比,使用查准率验证主题词提取的准确性。4组实验的结果及平均值如表3所示,任选一组实验的提取效果进行展示如表4所示。
从表3中看到,TextRank算法平均P值为0.68,TF-IDF算法为0.75,而本文为0.83,这证明相同实验数据环境下本文算法比传统算法效果要好。在表4中,可以直观地看出每种方法在话题簇中提取出的主题词。由此得到,本文的方法对主题词的提取是有效的,同时提高了话题簇划分的准确性。
3.2 基于社区话题数据的实例应用
现在越来越多的社区采用线上管理,用户提交话题到后台,由管理人员筛选并处理用户关心的事件。借助本文的方法可以帮助管理人员将话题归类并得到代表一类话题的主题词,然后根据主题词对用户亟待解决的问题进行大致了解。以便管理人员后期选择用户所关注的热点话题,更好地解决社区事务。
在青岛市部分社区话题数据集上进行应用,寻找青岛市民所关心的话题主题,数据集的时间范围是2019年12月到2020年7月。从数据集中随机抽取2 000条数据,建立其关键词共现网络如图4所示,该无向网络的节点数为1 526,边数为4 986条。
由于阈值对本文算法的结果影响较大,因此要首先确定当前数据的共现度阈值。在当前数据集上进行多次实验并调整阈值,得到当共现度为0.45时,话题簇能被很好地区分开来。选取最终10个话题簇并进展示,如图5所示,每个话题簇提取的主题词个数为5,选出的主题词集以及它们的C值如下所示。
1)(′疫情′, 6.56), (′义务′, 1.93), (′力度′, 1.58), (′巡逻′, 1.57), (′汗水′, 1.56);
2)(′志愿者′, 5.54), (′防疫′, 1.46), (′修补′, 1.43), (′马路′, 1.35), (′报名′, 1.12);
3)(′垃圾′, 4.83), (′打扫′, 1.45), (′清除′, 0.77), (′生活′, 0.77), (′管理′, 0.56);
4)(′清理′, 3.48), (′居民′, 2.36), (′扰民′, 2.09), (′杂物′, 1.89), (′东头′, 1.56); 5)(′老人′, 2.88), (′地址′, 2. 60), (′请问′, 2.53), (′公摊′, 1.77), (′复工′, 1.16);
6)(′垃圾桶′, 2.29), (′推到′, 1.21), (′旁边′, 1.15), (′外溢′, 1.05), (′边上′, 1.04); 7)(′消毒′, 2.01), (′解除′, 1.45), (′办公室′, 1.20), (′通知′, 1.17), (′私家车′, 1.03);
8)(′口罩′, 1.83), (′居家′, 1.53), (′捐赠′, 1.18), (′防御′, 1.14), (′运动′, 1.09);
9)(′水果′, 1.56), (′广告′, 1.29), (′有人′, 1.06), (′游客′, 1.05), (′摆摊′, 0.56);
10)(′日常′, 1.55), (′通行证′, 1.08), (′假期′, 1.08), (′婴儿′, 1.07), (′防护′, 1.07)。
如果在每个话题簇的主题集中选择C值最大的1个作为最终的主题词,根据本文所做的实验结果可以看出,青岛市民所关心的话题为疫情、志愿者、垃圾、清理、老人、垃圾桶、消毒、口罩、水果、日常等。
4 结论
本文提出了一种基于关键词共现网络的主题词提取算法,不仅可以考虑词语之间的相关性,准确率也得到了提升。首先通过集成算法提取关键词,并对共现度公式进行改进计算关键词之间的共现度,以此为权重建立关键词共现网络,在一定的集成比例下,找出产生连通子图的最优网络状态,并以度中心性为权重计算节点的C值,以此为根据对关键词进行排序,选出前k个关键词作为该话题簇的主题词。实验表明,该主题词提取算法是有效的,并优于传统的主题词提取算法。在该方法中,对没有标签的数据集选择阈值进行最优连通子图判断时,需要通过人工识别的方法对话题数据进行大致分类,然后判断效果。在后面的研究中,希望找到一种能自动对话题数据识别分类的方法,并将该方法用到热点话题的发现研究中去。
参考文献:
[1]程肖. 网络舆情热点主题词提取研究[D]. 杭州:杭州电子科技大学,2010. CHENG X. Research on extraction of hot topic words of network public opinion[D]. Hangzhou: Hangzhou Dianzi University: 2010.
[2]WITTEN I H, PAYNTER G W, FRANK E, et al. KEA: practical automatic keyphrase extraction[C]// Proceedings of the 4th ACM Conference on Digital Libraries. New York : ACM Press, 1999: 254-255.
[3]趙英环,郭贵锁. 基于主题词迭代提取的信息检索算法[J]. 华南理工大学学报(自然科学版), 2004, 32(S1): 77-80. ZHAO Y H, GUO G S. Information retrieval algorithm based on subject word iterative extraction[J]. Journal of South China University of Technology (Natural Science), 2004, 32(S1): 77-80.
[4]唐培丽,王树明,胡明. 基于语义的汉语文献主题词提取算法研究[J]. 吉林大学学报,2005, 23(5): 535-540.
TANG P L, WANG S M, HU M. Research on semantic based Chinese literature subject word extraction algorithm[J]. Journal of Jilin University, 2005, 23(5): 535-540.
[5]程涛,施水才,王霞,等. 基于同义词词林的中文文本主题词提取[J]. 广西师范大学学报(自然科学版), 2007, 25(2): 145-148. CHENG T, SHI S C, WANG X, et al. Extraction of Chinese text subject words based on synonym forest[J]. Journal of Guangxi Normal University (Natural Science), 2007, 25(2): 145-148.
[6]李芳芳,葛斌,毛星亮,等. 基于语义关联的中文网页主题词提取方法研究[J]. 计算机应用研究, 2011, 28(1): 105-107. LI F F, GE B, MAO X L, et al. Research on extraction method of Chinese web page main inscription based on semantic Correlation[J]. Computer Application Research, 2011, 28(1): 105-107.
[7]王立霞. 基于语义的中文文本关键词提取算法[J]. 计算机工程, 2012, 38(1): 1-4.
WANG L X. Semantic based keyword extraction algorithm for Chinese text[J]. Computer Engineering, 2012, 38(1): 1-4.
[8]赵鹏,蔡庆生,王清毅.一种基于复杂网络特征的中文文档关键词抽取算法[J]. 模式识别与人工智能,2007, 20(6): 817-831.
ZHAO P, CAI Q S, WANG Q Y. A Chinese document keyword extraction algorithm based on complex network features[J]. Pattern recognition and artificial intelligence, 2007, 20(6): 817-831.
[9]刘通. 基于复杂网络的文本关键词提取算法研究[J]. 计算机应用研究, 2016, 33(2): 365-369. LIU T. Research on text keyword extraction algorithm based on complex network[J]. Computer Application Research, 2016, 33(2): 365-369.
[10]叶成绪,杨萍,刘少鹏. 基于主题词的微博热点话题发现[J]. 计算机应用与软件,2016, 33(2): 46-50. YE C X, YANG P, LIU S P. Micro-blog hot topic discovery based on subject words[J]. Computer Applications and Software, 2016, 36(2): 67-71.
[11]BLEI D, NG A, JORDAN M . Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(4/5): 993-1022.
[12]张晨逸,孙建伶,丁轶群. 基于MB-LDA模型的微博主题挖掘[J]. 计算机研究与发展,2011, 48(10): 1795-1802. ZHANG C Y, SUN J L, DING Y Q. Micro-blog topic mining based on MB-LDA model[J]. Computer Research And Development, 2011, 48(10): 1795-1802.
[13]李继云,黄昀,陈捷. CGRMB_LDA: 面向隐式微博的主题挖掘[J]. 计算机应用,2016, 36(S1): 67-71. LI J Y, HUANG J, CHEN J. CGRMB_LDA: topic mining for implicit micro-blog[J]. Computer application, 2016, 36(S1): 67-71.
[14]冯勇,屈渤浩,徐红艳,等. 采用可变时间窗口的TIF-LDA微博主题模型[J].小型微型计算机系统,2018, 39(9): 2067-2071. FENG Y, QU B H, XU H Y, et al. TIF-LDA micro-blog theme model with variable time window is adopted[J]. Small Microcomputer System, 2018, 39(9): 2067-2071.
[15]张孝飞,陈航行. 基于语义概念和词共现的微博主题词提取研究[J]. 情报科学,2021, 39(1): 142-147.
ZHANG X F, CHEN H X. Research on micro-blog subject word extraction based on semantic concept and word co-occurrence[J]. Information science, 2021, 39(1): 142-147.
[16]MIHALCEA R, TARAU P. TextRank: bringing order into texts[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg : ACL, 2004: 404-411.
[17]LI J Z, FAN Q N, ZHANG K. Keyword extraction based on tf/idf for Chinese news document[J]. Wuhan University Journal of Natural Sciences, 2007, 12(5): 917-921.
[18]FAN H L, QIN Y B. Research on text classification based on improved TF-IDF algorithm[C]//2018 International Conferenceon Network, Communication, Computer Engineering(NCCE2018). Chongqing: Atlantis Press, 2018: 516-521.
[19]覃悅. 基于中心性的算法在复杂网络分析中的应用及对比研究[D]. 天津: 天津财经大学, 2020. TAN Y. Application and comparative study of centrality based algorithms in complex network analysis[D]. Tianjin: Tianjin University of Finance and Economics, 2020.
(责任编辑 李 进)
猜你喜欢
中国生物制品学杂志(2021年12期)2021-12-21
中国医学计算机成像杂志(2020年6期)2020-03-14
老年医学与保健(2017年6期)2017-02-06
中国骨与关节杂志(2016年12期)2016-01-23
结核与肺部疾病杂志(2015年4期)2015-07-18
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年2期)2015-02-21
沈阳医学院学报(2014年4期)2014-12-27
疑难病杂志(2014年12期)2014-04-16
