
自适应变异麻雀搜索优化算法
2023-03-31 07:42唐延强李成海宋亚飞陈晨曹波
北京航空航天大学学报 2023年3期
唐延强,李成海,宋亚飞,陈晨,曹波
(1.空军工程大学 研究生院,西安 710051;2.空军工程大学 防空反导学院,西安 710051;3.西安卫星测控中心 ,西安 710043)
元启发式算法又称群智能优化算法,是一种模拟自然界中某些生物的行为或受到某种物理现象启发提出的一类仿生学算法,其中心思想是在某个空间平衡全局搜索和局部搜索寻找最优解。由于元启发式算法操作简单、求解高效,吸引了众多学者的关注,目前这些算法被广泛应用于图像处理[1]、训练神经网络[2]、信号处理[3]和特征选择[4]等领域。
近年来相继出现了越来越多的元启发式算法,常见的算法有:粒子群优化(particle swarm optimization,PSO)算法[5]、灰狼优化(grey wolf optimization, GWO)算法[6]、鲸鱼优化算法(whale optimization algorithm,WOA)[7]、樽海鞘群算法(salp swarm algorithm, SSA1)[8]、正弦余弦算法(sine cosine algorithm, SCA)[9]和麻雀搜索算法(sparrow search algorithm, SSA2)[10]等,由于樽海鞘群算法和麻雀搜索算法的英文缩略词相同,本文以SSA1 表示樽海鞘群算法,SSA2 表示麻雀搜索算法。虽然元启发式算法越来越多,但都离不开2 个阶段:探索和开发。探索阶段即算法以高度随机性进行全局搜索,随着迭代次数的增加,算法开始在已探索的区域进行深度开发。因此,保证探索和开发之间的平衡显得尤为重要。若探索阶段比重过大,将会导致收敛速度变慢,相反,将会导致过早收敛,易陷入局部极值点。
针对这些问题,众多学者已经提出一些有效的改进方法:陈忠云等[11]提出一种多子群的共生非均匀高斯变异SSA1,较好的平衡了樽海鞘群的探索和开发能力;刘景森等[12]针对SSA1 求解结果不稳定问题,引入自适应领导者-跟随者调整策略,增强了算法的稳定性;周娇等[13]为避免WOA 早熟收敛的缺陷,采用猫映射混沌序列结合反向解方法取代随机产生初始种群,使WOA 在初始种群多样性及寻解遍历性上有所增强;周璟[14]采用Tent 混沌映射改进了狼群初始化方法,使狼群初始分布更加均匀,加强了算法的全局搜索能力;文献[15]在WOA的惯性权重中引入随机因子,然后将Levy 飞行的随机搜索模式引入算法中,进一步增强了WOA 的全局和局部搜索能力;文献[16]对烟花算法进行基于对立的学习初始化种群,对非最优个体采用自适应t 分布变异,对最优个体采用精英对立学习,减少了算法的运行时间;何庆等[17]采用柯西变异提高算法跳出局部极值点的能力。
SSA2 是2020 年新提出的一种元启发式算法,该算法将搜索群体分为探索者、跟随者和预警者3 部分,其相互分工寻找最优值。虽然易于实现,但如何调节各部分之间的控制参数,以及如何保证3 部分之间可以较好的相互配合是一个必须考虑的问题。目前有一些对SSA2 的改进:吕鑫等[18]将麻雀种群通过Tent 混沌序列初始化,同时通过高斯变异和Tent 混沌扰动对个体进行变异和扰动,克服了SSA2 易陷入局部极值点的缺陷;文献[19]利用重心反向学习机制初始化种群,使种群具有更好的空间解分布,其次在探索者的位置更新部分引入学习系数,提高算法的全局搜索能力,最后使用变异算子来改善加入者的位置更新;文献[20]引入混沌策略来增强算法种群的多样性,并采用自适应惯性权重来平衡算法的收敛速度和探索能力。这些改进措施在一定程度上提高了算法的寻优性能,但都没有更加深入考虑探索者和跟随者之间的关系。基于此,本文提出一种自适应变异麻雀搜索算法(adaptive mutation sparrow search optimization algorithm,AMSSA),首先通过猫映射混沌序列对种群初始化,提高麻雀个体的随机性及遍历性,再通过柯西变异和Tent 混沌扰动对个体进行调整,避免种群过于“集中”或“分散”,最后引入自适应探索者-跟随者数量调整式来平衡寻找全局和局部最优的能力。通过对16 个基准函数进行测试,并进行Wilcoxon 秩和检验分析,验证了本文所提算法的有效性和可行性。
1 麻雀搜索算法
SSA2 的思想来自于麻雀种群的觅食行为和反捕食行为,可抽象为探索者-跟随者-预警者模型。探索者具有较高的能量储备,适应度值高,主要为跟随者提供觅食区域和方向。跟随者跟随适应度值最优的探索者寻找食物以获得自己的能量储备,增加自身的适应度值。部分跟随者也可能不断地监视探索者,从而争夺食物。预警者在意识到危险时会发出警报,同时迅速向安全区域移动来获得更好的位置,处于种群中间的麻雀则随机行走靠近别的麻雀,即反捕食行为。同时若警报值大于安全阈值时,探索者需要将所有的跟随者带离危险区域。
在SSA2 中,假设有N 只麻雀在一个D 维搜索空间中,则每只麻雀的位置为
式中:i=1,2,···, N;d=1,2,···, D;xi,d为第i 只麻雀在第d维的位置。
由于探索者引导着整个麻雀群体的流动,可在任何地方寻找食物,所以其位置更新为

2 改进麻雀搜索算法
2.1 猫映射混沌初始化种群
混沌作为一种非线性的自然现象,以其混沌序列具有遍历性、随机性等优点,被广泛用于优化搜索问题。为了保持种群的多样性,使个体之间尽可能均匀分布,本文采用混沌序列初始化策略代替SSA2 算法中随机生成种群的方法。目前在优化领域形成了多种混沌映射,包括Logistic 映射、Tent映射和猫映射等。Logistic 映射作为一种典型的混沌系统,其序列的概率密度函数由于服从切比雪夫分布,映射点呈现出中间密度低,两边密度高的特点,导致遍历不均匀性,影响算法的搜索效率。文献[21]提出Tent 映射的遍历均匀性和收敛速度皆优于Logistic 映射,然而Tent 映射易在小循环周期和不动点上出现问题,只有最优解仅为边缘值时才可求得最优解。针对Logistic 映射和Tent 映射的缺点,本文通过猫映射来生成SSA2 算法的初始种群。猫映射表达式为

2.2 Tent 混沌和柯西变异扰动策略
2.2.1 Tent 混沌扰动

2.2.2 柯西变异
柯西变异来源于连续型概率分布的柯西分布[23],主要特点为0 处峰值较小,从峰值到0 下降缓慢,使变异范围更均匀,变异式为
式中:x 为原来个体位置;mutation(x)为经过柯西变异后的个体位置;u 为(0,1)区间内的随机数。
2.3 改进探索者位置更新公式

m 值的选取影响着麻雀探索者对于全局和局部搜索之间的平衡关系。从图1 可以看出,每条曲线都是前期收敛速度快,后期收敛速度慢,为了选取最合适的m 值,选取Schaffer 函数对该参数进行测试,Schaffer 函数的特点是在全局最优点3.14 范围左右存在大量的局部极小点,函数强烈振荡。经过7 次改变m 值,每次进行50 次寻优计算取平均值,得出m 值对SSA2 算法的影响如表1所示。可以看出,由于SSA2 算法本身良好的寻优性能,可以避过Schaffer 函数的局部极小点,寻找到最佳值0,因此,m 值对SSA2 算法的影响主要体现在收敛次数上,当m 值增加时,平局收敛次数先减少后增加,m 值为2 时平均收敛迭代次数最小。由表1 可知,m=2 时,参数c 可以使SSA2 算法的探索能力和觅食能力达到较好的平衡,此时探索者可在前期充分广泛搜索目标,后期着重对最优位置进行挖掘。

图1 c 变化曲线Fig.1 Variation curves of c

表1 参数 m 对SSA2 的影响Table 1 Influence of parameter m on SSA2
2.4 探索者-跟随者自适应调整策略
在SSA2 算法中,探索者和跟随者的数目比例保持不变,这会导致在迭代前期,探索者的数目相对较少,无法对全局进行充分的搜索,在迭代后期,探索者的数目又相对较多,此时已不需要更多的探索者进行全局搜索,而需要增加跟随者的数量进行精确的局部搜索。为解决这个问题,本文提出探索者-跟随者自适应调整策略,该策略在迭代前期,探索者可以占种群数目的多数,随着迭代次数的增加,探索者的数目自适应减少,跟随者的数目自适应增加,逐步从全局搜索转为局部精确搜索,从整体上提高算法的收敛精度。探索者和跟随者数目调整式为
式中:pNum 为探索者数目;sNum 为跟随者数目;b 为比例系数,用于控制探索者和跟随者之间的数目;k 为扰动偏离因子,对非线性递减值r 进行扰动。
2.5 改进后麻雀搜索算法
AMSSA 流程如图2 所示。
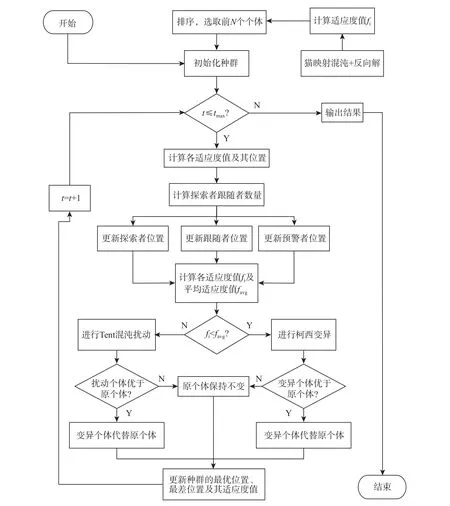
图2 AMSSA 流程Fig.2 Flow chart of AMSSA
3 本文所提算法性能测试
为验证本文所提算法的寻优能力及可行性,将AMSSA 与PSO、GWO、WOA、SSA1、SSA2 算法同时在16 个基准函数上进行对比测试。
3.1 测试函数
具体基准函数如表2 所示。其中f1~f6为高维单峰函数,f7~f11为高维多峰函数,f12~f16为低维多峰函数。高维单峰函数只有一个全局最优点,没有局部极值点,主要为了测试函数的收敛速度。多峰函数有多个局部极值点,从高维和低维2 种角度出发,用来观察函数在不同维度跳出局部极值点的性能。

表2 基准函数Table 2 Benchmark function
3.2 结果分析
3.2.1 收敛精度及稳定性分析
在MATLAB R2016b 环境下对6 种算法进行仿真对比实验,为了避免偶然误差过大,在实验中选取各基准函数独立运行40 次,取最佳值、平均值和标准差作为评价指标,实验中设定种群规模为30,最大迭代次数为500,最终得到表3。

表3 基准函数测试结果对比Table 3 Comparison of benchmark function test results
首先,在6 个高维单峰函数中,AMSSA 在求解f1、f2和f3函数时寻找到理论最优值0,f1和f3函数标准差也为0,除此之外只有SSA2 在求解f1时得到最优值0;其次,在求解f4和f5函数时,AMSSA 得出的最优值、平均值和标准差比其他5 种算法提升了至少2 个数量级;在求解f6函数时,虽然提升程度不高,但最优值和稳定性仍高于其他算法。在5 个高维多峰函数中,对于f7的求解,6 种算法的寻优能力基本相同,AMSSA 并未表现出算法的优越性;对于f8和f10的求解,在WOA、SSA2 中已经可以达到最优值,改进后AMSSA 中保持了原算法的性能;对于f9的求解,AMSSA 并未突出其优越性,同SSA2 一样,在达到某个极值点后就跳不出该极值点,但标准差为0,稳定性强;高维多峰函数中只有对f11的求解突出体现了AMSSA 算法寻优性能的提高。对于5 个低维多峰函数,除f16外,f12~f15在6 种算法的求解下均可以达到最优值,说明在低维条件下算法可以更好的寻优;在f12中,SSA2、AMSSA相较于其他4 种算法稳定性不足,但AMSSA 比SSA2稳定性高;f13中AMSSA 的稳定性仅次于WOA;f14和f15中AMSSA 的稳定性最好;在f16中,只有GWO、SSA2 和AMSSA 这3 种算法寻找到最优解,稳定性依次增加。
通过分析说明,对于每一种算法,单峰函数的求解精度比多峰函数要高,低维函数比高维函数的求解精度要高,但不论单峰多峰、高维低维函数,AMSSA 相比于其他5 种算法,不仅在寻优准度上有相对应的提升,并且稳定性更优。
3.2.2 收敛曲线分析
为了直观地比较6 种算法的收敛速度,再分别用6 种算法对16 个基准函数进行实验,结果如图3所示。


图3 基准函数平均收敛曲线Fig.3 Average convergence curve of benchmark function
图3 所示可以清晰地表达各算法在寻优过程中 适 应 度 值 的 变 化 情 况。图3(a)~图3(f)中AMSSA 的收敛速度较快,这是因为加入猫映射混沌初始化的结果,并且除图3(b)外,AMSSA 的收敛精度远远高于其他算法。图3(b)中AMSSA 的收敛精度仅次于WOA,这与表3 中的数值刚好对应。其次,图3(a)~图3(f)中可以清晰的看出有断层现象和AMSSA 跳出局部极值点的特征,而PSO、GWO、WOA、SSA1 基本陷入局部极值点就再未能跳出。在图3(g)~图3(k)高维多峰函数的5 幅图中,图3(g)中AMSSA 陷入局部极值点后未跳出,这也与表格中f7函数相对应,图3(h)、图3(j)和图3 (k)中表现出AMSSA寻优精度和收敛性能明显优于其他算法。同时,图3(h)和图3(j)中AMSSA的曲线未显示完全,这是因为已经达到最佳值0,算法性能优异。在图3(l)~图3(p)低维多峰的5 幅图中,图3(l)、图3 (m)、图3 (n)和图3 (o)中每种算法皆能够寻找到最优解,图3(p)只有AMSSA、SSA2和GWO 寻找到最优解,并且AMSSA 收敛速度最快。图3(o)中由于f15函数对每种算法来说都易寻找到最优点,所以迭代开始每种算法都立刻找到最优点,图形只有一条竖直的线。
3.2.3 Wilcoxon 秩和检验分析
文献[24]提出,对于改进算法性能的评估,应该进行统计检验。换而言之,仅基于平均值和标准偏差值来比较算法优劣还不够,需要进行统计检验以证明所提算法比其他算法具有显著的改进优势。通过对每一次的结果进行独立比较,来体现算法的稳定性和公平性。本文采用Wilcoxon 秩和检验在5%的显著性水平下进行判断AMSSA 的每次结果是否统计上显著与其他5 种算法的最佳结果不同,当p 值小于5%时,拒绝假设,说明对比算法具有显著性差异;否则接受假设,表明对比算法的寻优能力整体上相同。表4 给出了16 个基准函数下AMSSA 与其他5 种算法之间的秩和检验p 值,因为当2 个对比算法都达到最佳值时,无法进行比较,所以表4 中NaN 表示“不适用”,即不能进行显著性判断,R 为显著性判断的结果,“+”、“-”、“=”分别表示AMSSA 性能优于、劣于和相当于对比算法。
从表4 中可以得出,大部分p 值远远小于5%,这说明AMSSA 的优越性比其他5 种算法在统计上是显著的。在AMSSA 与SSA2 对比,f13~f16函数中R 值为“-”,这是因为本身SSA2 寻优性能较好,AMSSA 与SSA2 皆能寻找到最佳值,只是在平均值的体现上有所不同,AMSSA 在低维多峰函数上的寻优性能有一定的提升,但提升空间不大。

表4 Wilcoxon 秩和检验p 值Table 4 p-value for Wilcoxon’s rank-sum test
3.2.4 模型消融实验
由于AMSSA 的各种添加机制导致其寻优性能比较好,但具体哪一种添加机制起作用,是否有某一种添加机制不起作用还未知,为了表明各种机制的作用,使实验更具说服力,本文进行了AMSSA 模型的消融实验。分别以SSA、自适应SSA(ASSA)、变异SSA(MSSA)与AMSSA 在16 个基准函数上做对比实验,最终结果如表5 所示,其中Mean 为平均值,Std 为标准值。
从表5 中可以看出,在高维单峰函数f1~f6中:除f6外,其他函数中的ASSA 与MSSA 皆对寻优性能起到了一定作用;在f6中,虽然ASSA 与MSSA相较于SSA 没有提升效果,但二者结合后,AMSSA的稳定性最高。在高维多峰函数f7~f11中:函数f7的测试结果与f6类似,稳定性提升,但寻优性能提升效果不大;函数f8~ f10中所有算法都可以找到最优值;函数f11中,ASSA 和MSSA 的效果都比SSA2 好,同时AMSSA 的效果最好。在低维多峰函数f12~ f16中,由于每种算法可以无限接近最优值,因此AMSSA 性能提升不大,而且在f13中,ASSA、MSSA 和AMSSA 的性能不如SSA2。

表5 模型消融实验结果Table 5 Experimental results of model ablation
3.2.5 AMSSA 时间复杂度分析
假设算法中种群规模为 N ,维度为 D,最大迭代次数为 itermax,随机初始化种群参数时间为s1,求个体适应度值的时间为j(D);探索者数量为pNum,每一维更新时间为s2;跟随者数量为sNum,每一维更新时间为s3;预警者每一维更新时间为s4。因此初始阶段时间复杂度为:T1=O(s1+N(j(D)+Ds1));探索者更新时间复杂度为:T2=O(pNum×s2D);跟随者更新时间复杂度为:T3=O(sNum×s3D);预警者更新时间复杂度为:T4=O((N-pNum-sNum)s4D)。综上,SSA 总的时间复杂度为:T =T1+(T2+T3+T4)itermax=O(D+j(D))。
在AMSSA 中,假设猫映射混沌所需时间为u1,排序选择时间为u2,因此,初始阶段时间复杂度为:T11=O(s1+N(u1+j(D)+Ds1)+u2);探索者和跟随者个数更新式为u3,则探索者更新时间复杂度为:T22=O(pNum×s2D+itermaxu3);跟随者更新时间复杂度为:T33=O(sNum×s3D+itermaxu3);预警者更新时间复杂度为:T44=O((N-pNum-sNum)s4D)。在柯西变异和Tent 混沌扰动过程中:设求解平均适应度值favg时间为u4,计算扰动式时间和柯西变异式时间分别为u5、u6。麻雀适应度值与平均适应度值比较和择优更新目标位置的时间分别为u7、u8,则这个阶段的时间复杂度为:T55=O(u4+u5+u6+N(j(D)+u7)+u8)。综上,AMSSA 的时间复杂度为:T1=T11+(T22+T33+T44+T55)itermax=O(D+j(D))。由于T1=T,表明AMSSA 的时间复杂度没有增加。
综和本节分析,通过模型消融实验证明所提的每一种策略都对AMSSA 算法最终的性能有所帮助,通过时间复杂度分析说明AMSSA 的时间复杂度与SSA2 等价,通过AMSSA 在3 类函数上的实验得出,虽然AMSSA 相较于SSA2 在低维多峰函数中的寻优性能不明显,但在高维单峰和高维多峰函数中寻优性能比其他5 种算法高出至少2 个数量级,收敛速度也有明显的提升,稳定性增强,充分说明AMSSA 算法的各种性能总体上优于其他5 种算法,表明了AMSSA 的优越性和可行性。
4 结 论
本文在标准麻雀搜索算法的基础上,引入了混沌映射和柯西变异及探索者跟随者数量的自适应调整策略,提出一种自适应变异麻雀搜索优化算法AMSSA。
1)首先,猫映射混沌加快了种群初始化的收敛速度;其次,自适应探索者-跟随者调整策略使算法前期着重寻找全局最优,后期着重局部寻优整体上提高了收敛精度;最后,Tent 混动扰动和柯西变异使算法跳出局部极值点,这使得AMSSA 相较于SSA2 寻优精度更高,搜索能力更强。
2)选取16 个基准测试函数与其他5 种算法进行比较,并进行Wilcoxon 秩和检验对算法显著性水平进行验证。实验表明,AMSSA 寻优性能提升较明显,具有良好的开拓能力,鲁棒性强,表现出良好的实时能力。
下一步考虑将AMSSA 与其他改进的SSA 做对比,并将其应用到图像分割、人脸识别等实际工程中,用于解决工程优化领域中的约束优化、多目标优化等问题,从而验证AMSSA 在实际工程中的优越性。
猜你喜欢
测控技术(2018年4期)2018-11-25
中国广播(2017年9期)2017-09-30
电信科学(2017年6期)2017-07-01
—— 瓮福集团PPA项目成为搅动市场的“鲶鱼”
当代贵州(2017年24期)2017-06-15
诗潮(2017年5期)2017-06-01
发明与创新(2016年33期)2016-08-21
大社会(2016年3期)2016-05-04
数学年刊A辑(中文版)(2015年3期)2015-10-30
中南财经政法大学学报(2015年5期)2015-04-07
科学中国人(2015年25期)2015-02-28
