
Object detection in crowded scenes via joint prediction
2023-03-28 08:37HonghuiXuXinqingWangDongWangBaoguoDuanTingRui
Defence Technology 2023年3期
Hong-hui Xu, Xin-qing Wang, Dong Wang, Bao-guo Duan, Ting Rui
Department of Mechanical Engineering, College of Field Engineering, Army Engineering University of PLA, Nanjing, 210007, China
Keywords:Machine learning Object detection YOLOv4 Crowded scenes Computer vision
ABSTRACT Detecting highly-overlapped objects in crowded scenes remains a challenging problem, especially for one-stage detector. In this paper, we extricate YOLOv4 from the dilemma in a crowd by fine-tuning its detection scheme,named YOLO-CS.Specifically,we give YOLOv4 the power to detect multiple objects in one cell. Center to our method is the carefully designed joint prediction scheme, which is executed through an assignment of bounding boxes and a joint loss. Equipped with the derived joint-object augmentation (DJA), refined regression loss (RL) and Score-NMS (SN), YOLO-CS achieves competitive detection performance on CrowdHuman and CityPersons benchmarks compared with state-of-the-art detectors at the cost of little time. Furthermore, on the widely used general benchmark COCO, YOLOCS still has a good performance, indicating its robustness to various scenes.
1. Introduction
Detecting highly-overlapped objects in crowded scenes is widely used in many practical situations, e.g., pedestrian, and vehicle detection. With the development of deep convolutional neural networks (CNNs), great progress has been made in object detection[1-4].Most object detection models follow the proposalbased framework,which can be classified into one-stage[3,4,7-9]and two/multi-stage [1,2,5,6] methods. Due to the prescreening of regions, two-stage detectors achieve excellent detection precision but at the expense of running time. On the contrary, one-stage models simultaneously perform classification and regression tasks,which keep a better balance between efficiency and accuracy.Although proposal-based approaches have achieved state-of-theart performances in some benchmarks, e.g., COCO [15] and PASCAL VOC[16],they are still unsatisfactory in crowded detection because the design of classical algorithms are not friendly to crowded scenes.
Most models take non-maximum suppression (NMS) or its variants[10-14]as the basic means of post-processing after scoring each region to remove redundant detections, which has proved to be effective in many cases.However,NMS is more a manual method independent from the model, the effect of which is closely related to preset hyper-parameters. NMS uses Intersection over Union(IoU)as the basis for processing each bounding box.Setting an IoU threshold for NMS is a dilemma as it trades off precision and recall.When the object overlap in a certain region is too large, many positive samples will be suppressed,resulting in a sharp decline in the effect. The detection results rely heavily on the manual postprocessing (NMS), which is not robust. As shown in Fig. 1(a),there are four persons in total,one on the left is relatively isolated,and the other three are close.Obviously,it needs a bag of trick to get the ideal result,i.e.,Fig.1(b).If the threshold is too loose,one or two objects may be suppressed, resulting in a low recall rate. If the threshold is too strict then high scoring false positives tend to survive and precision may suffer. Briefly, NMS can achieve great results when the object is dispersed, but it is not suitable for crowded scenes.

Fig.1. Detection in crowds. (a) The original image. (b) Ideal detection results. (c) Brief processing of YOLO. (d) One error detection case.
We attempt to promote the detection results in crowded scenes through the improvement of one-stage detectors e.g.,YOLOv4 due to their better comprehensive performances in practical applications.However,it seems inherently difficult for one-stage detectors to address this challenge because most of their detection theories are not suitable for crowded scenes detection. Take the training phases of YOLO series[3,7-9]as an example.Firstly,YOLO divides each image into several grid cells. Simultaneously annotation samples on the image also fall into the corresponding several cells.Each sample is detected by a unique cell containing its geometric center. We term them task cells. Obviously, for any image, the number of task cells is equal to the annotated samples. Then, for any task cell, YOLO generates a group of preset concentric anchor boxes of multiple sizes and calculated the IoU between the ground truth box of the designated sample and each anchor box, respectively.The box with the largest IoU will be selected as the bounding box responsible for its designated object. After that, the model reduces the difference between this box and the truth box within an acceptable range through an iterative training process. Fig.1 illustrates this detection process. (a) is the original image containing four samples. In (b) and (c), we mark the ground truths and geometric center of all samples with four boxes and dots of different colors,respectively.The box and dot of the same color represent the same sample.In(c),supposing the input image is divided into 7×7 grids (Padding parts is not reflected) and three anchor boxes (yellow dashed boxes) of different sizes form a group. Unfortunately,two objects (purple and yellow) fall in the same cell (gray filled grid).Obviously,there is no another appropriate bounding box to fit the purple, which will undoubtedly increase the difficulty in localization. In theory, all anchor boxes can generate bounding boxes to detect objects. It is difficult to detect multiple objects in one grid in many cases due to the complementary relationship of the anchor box set. There is always a mismatch between the partition method using grids as the basic element and the training method based on single object.Besides,highly-overlapped objects will hurt with each other when the model extracts features,which will be confused if objects have similar features,thus hindering the better classification and regression results. As shown in Fig. 1(d),the model may eventually recognize the right three persons as a whole because they are too close, resulting in a low recall.
In this paper, we propose a new joint prediction scheme based on YOLOv4, the representative of one-stage detectors. we term it YOLO-CS.The main contributions of this paper are summarized as follows:
(1) We proposed a joint prediction scheme based on YOLOv4.Specifically, we attempt to detect a set of highly overlapped objects instead of single instance.This approach shows great power in detection for crowded scenes.
(2) We introduce a derived joint-object augmentation to replace the original Mosaic preprocessing scheme of YOLOv4,which provide more highly overlapped positive pairs and hard positives, boosting the generalization ability of model.
(3) We modify the original DIoU-loss and propose a refined loss to punish false positives and locate positives more accurately.
(4) We proposed a tough score, which can better describe the similarity between prediction boxes than IoU. In our approach, it is used as the threshold of the assignment of bounding boxes and postprocessing, achieving a great improvement in detection for crowded scenes.
The rest of this paper is organized as follows. Related works closely related to our proposed model are briefly introduced in Section 2.In Section 3,our proposed method is described in detail.Section 4 further presents implementation details and experimental results.Finally, we summarize our work in Section 5.
2. Related work
2.1. Object detection
Object detection is always the hot topic in computer vision,which aims to classify and locate the object. Current detection models basically follow proposal-based framework and their paradigm is based on three pipelines: generating proposal boxes,scoring each prediction, and removing redundant results. As mentioned above, formally detection models can be roughly divided into the following two categories: two-stage e.g., R-CNN family [1,5,6] and one-stage detectors e.g., YOLO series [3,7-9]and SSD[4].The main difference between them is how to generate proposal boxes.For example,YOLOv4 uses learnable anchors while Faster-RCNN uses region proposal networks (RPNs). More works[2,19] are focused on the extraction of object features. From the perspective of practical application, Yolo should have a better prospect, YOLO should have a better prospect as it can better balance the detection accuracy with efficiency.YOLO series is a typical representative of single-stage detector. Different from two-stage models, YOLO transforms the detection problem into a single regression problem. As mentioned above, every image in the training set is divided into a S×S grid,and each grid is generated B bounding boxes.If the ground truth(GT)center of one object falls in a grid, the grid is responsible for detecting the boundary and confidence score of the object.As the latest achievement in the series,YOLOv4 achieves state-of-the-art performance through the integration of various tricks, which greatly improves the detection accuracy.
2.2. Objection detection in crowded scenes
Few of work have tried to improve detection performance in crowded scenes.Early works[20-22]mainly applied to pedestrian detection with sliding window strategy.Subsequent works[23-26]tried to extract features through a Deep Neural Network(DNN)and fed them into an improved decision forest.Recently, part of works[27,28]boosts the loss function to address the problem of crowded detection[27].proposes a new aggregation loss,repelling proposals to be closed to the designated ground truth [28]. introduces extra penalty to the original regression loss. Similar to our work [29],presents a multiple prediction scheme based on the FPN-Res 50 baseline [30]. proposed a CSID to address the issue by considering both identity and density information [31]. develops a strict classification criterion to improve the quality of positives. However,these efforts are rarely designed for one-stage framework and most still rely on traditional NMS for post-processing,which is not robust[32].presents a SADet with label smoothing and improvements on NMS and IoU based on one-stage framework,which achieves great performance but efficiency may suffer.
2.3. NMS and IoU
Non maximum suppression (NMS) is a critical post-processing step for object detectors, which is used to remove redundant bounding boxes and improve the precision of detection. However,its processing is very rude. Once IoU (Intersection over Union) is greater than the preset threshold,it will be deleted directly,which causes a low recall rate in crowded scenes. Subsequently, several work to boost NMS are proposed e.g., soft-NMS [38] and softer-NMS [39]. They do not directly discard neighbors but decay the scores of them. Besides, adaptive-NMS [14] design an adaptive threshold,which can be adjusted by the density of predicted boxes.Other works such as [35,36] introduces anther branches for learning the NMS function to remove duplicate results, which brings to a more complex and time-consuming structure though performs greater than NMS.Besides, some works tried to improve IoU as it cannot mirror the real occlusion in many cases, e.g., GIoU[17],DIoU[18]and CIoU[18].Recently[41],proposed a new metric for NMS, where IoU is multiplied by the classification score to be more correlated with the localization. However, it may be powerless in crowded scenes as IoU is still included.
3. Proposed method
We choose YOLOv4 as our baseline and almost no modifications are on the original backbone and neck.For simplicity,we attribute them to feature extraction block. The overall architecture of our method is illustrated in Fig.2,where we can see that our proposed joint prediction scheme is conducted by the improved preprocessing, joint prediction Head and postprocessing. We term this improved YOLOv4 as YOLO-CS. Specifically, In the preprocessing part, we propose a novel augmentation scheme for crowded scenes detection, namely derived joint-object augmentation(DJA).We use it to replace the original Mosaic of YOLOv4.In the Detection Head,we use k anchor groups to fit the object set in cell i, and then apply an Assignment algorithm to distribute these bounding boxes. To execute our joint perdition, the joint loss is proposed to replace the original. Furthermore, we refined the original DIoU-loss to reduce false positives.For the inference phase,Score-NMS is developed as the post-processing, which is a better match for our joint prediction scheme.
3.1. Joint prediction
As the previous analysis, we know that for YOLOv4, each cell corresponds to one ground truth in most cases.It directly damages the performance in a crowded scene. To address this dilemma,we change the original training scheme. Concretely, when multiple samples fall on the same task cell, let this cell detect a group of samples rather than only one of them as before.We term the new scheme joint prediction.In our approach,these objects form a joint set Oi, which can be expressed as:
Where,gjis a ground truth and its central coordinates(xj,yj)falls in the grid i.Oiis the set of these ground truths falls in the grid i.As shown in Fig. 1(c), for the gray filled grid, new strategy will simultaneously fit the two objects(yellow and purple)to preserve all objects.
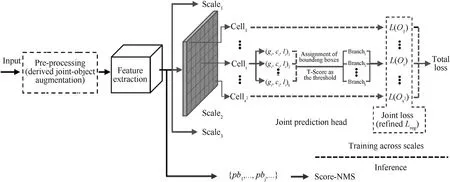
Fig. 2. Architecture of our YOLO-CS.

Fig. 3. Explanations about necessity of our assignment algorithm and tough score.
We have known that an object gjis usually encoded by a class probability pj, a confidence of the existing object cj, and a relative coordinates lj. They constitute a vector (pj,cj,lj)and is fed into the final full convolutional network(FCN)for prediction.By analogy,for a joint object set Oi,we can extend it to a combination of multiple vectors:
Where, kishould denotes the number of objects falls in cell i.Obviously, the kiin different cells are not the same. For simplicity,we set it as a constant k in our approach. (pi,ci,li)jrepresents the object j falls in cell i.To execute our joint prediction,it is not enough to define the object set Oi. As mentioned above, the original YOLOv4 is powerless in the crowded scenes because only one group of anchor boxes cannot infer all objects accurately. To address this dilemma, we also extend the group number of anchor boxes to k and each group is consisting of m anchors. In this way, we can express the anchor set Aiin cell i as:
Where,(a1,…,am)jdenotes the anchor group j falls in cell i,which generates the corresponding bounding box group (b1,…,bm)jfor prediction. At the beginning, we match objects with the anchor groups to avoid mutual interference. As shown in Fig. 2, our approach is convenient to implement by adding k prediction branches. For some cells with less objects, we fill them with background class, ensuring each grid owns k objects.
Finally, assignment of bounding boxes deserves careful consideration.As shown in Fig.3(a),two ground truth boxes(yellow)g1,g2need to be specified by generated bounding boxes(red)i.e.,b1or b2to predict. According to the original principle, a bounding box with the highest IoU is selected to predict the designated ground truth box.Hence,we calculate their IoU and put it in a matrix[IoU].Where,[IoU]ijdenotes IoU between biand gj.We can see that b1has the largest IoU with both two ground truth boxes, it may be misunderstandings. This mistake is not rare in crowded scenes. To solve this problem, a new rule should be adopted to maintain one bounding box blbelonging to one ground truth box gj. A most superficial idea is scoring correlation of each bounding box with all ground truth boxes,then assign it to the ground truth box with the largest score.Table 1 shows this Assignment Algorithm of Bounding Boxes. Specifically, we input a bounding box set B and a ground truth set G, then separately calculate the score of each bounding box blin B relative to all ground truth box in G.The higher the score,the more relevant they are. Finally, we will assign blto the grounding truth box with the highest score. As a result, each ground truth box gjowns a corresponding bounding box set Gbj.
It is reasonable to take IoU as the criterion, but there will be some mistakes.As shown in Fig.3(b),there are two objects,which are denoted by two ground truth boxes(yellow)i.e.,g1and g2.Note that we ignore the boy in the lower right corner because it is independent of the discussion here. In addition, three bounding boxes b1,b2and b3are generated to match the above two ground truth box g1and g2.Similarly,we first use a matrix to represent the IoU between bounding boxes and ground truth boxes. We can see that all bounding boxes have larger IoU with g1. If purely comparing IoU, all ground truth boxes will be taken away by g1while g2has nothing, which is unreasonable. At least, b3is more likely to be responsible for g2. This mistake is given by pure IoU,which cannot represent the similarity between boxes.Based on the above analysis, we modify the way of scoring, named tough score(T-Score), which can be expressed as follow:

Fig. 4. Visualization of proposed T-Score.
Where, Rbland Rgjdenotes the aspect ratio of the bounding box bland the ground truth box gj.In addition to IoU,we add another core geometry factor of the ground truth box, i.e., aspect ratio to the scoring indicators.Combined with IoU,it can reflect the suitability of the bounding box and the ground truth box more comprehensively.Simultaneously,IoU is treated as a threshold.Only bounding boxes which satisfy both IoU>0.6 and 0.5<<2 are entitled to scores,or they will be discarded.That is,bounding boxes with high IoU and similar aspect ratio are qualified to be selected into the corresponding bounding box set Gbj. Besides, we increase sensitivity of model to aspect ratio by multiplying the corresponding item by 10. Furthermore, we associate weights of each item with IoU,that is,the aspect ratio of boxes with larger IoU decides more.This series of settings support the model to distinguish bounding boxes more easily while much more unqualified boxes are eliminated by this strict criterion at the beginning, improving the efficiency of our model.
Fig. 4 is the HSV colormap of our T-Score. (a) is the stereogram while (b) is the top view. For a vivid illustration, the area that has been set to 0 is not represented. We can see the T-score between 0 and 1 whose extremum is 1 when and only when IoU = 1. Besides,high Tough-Scores are concentrated in the area with large IoU and similar aspect ratio. Hence, the T-score can well satisfy our demanding for assignment of bounding boxes.Look back the above Fig.3(b),the matrix[Score]is updated by our proposed T-Score.We can see Score(b1,g2)and Score(b2,g2)are both equal to 0 because IoU< 0.5. Besides, considering the aspect ratio, Score(b3,g2) surpasses Score(b3,g1). Consequently, g1obtain b1and b2while g2gets b3, which fits more into our cognition.

Fig. 5. The flowchart and results of Derived Joint-object Augmentation.
3.2. Joint loss
The original loss function of YOLOv4 can be given by the following formula:
Where,Lregis the loss of regression i.e.,CIoU-loss.Lconfis the loss of confidence, which consists of two parts: the loss of confidence in the bounding box of the existing object and the object that does not exist.Lclsis the classification loss of the cell where the object exists.We adjust this loss function to satisfy our new scheme, that is,driving the model to fit the joint object set Oi.We call it joint loss,which can be expressed as:
That is,objects falling on the same grid are treated as whole,i.e.,the ground truth set G. Our model is trained to min the gap between the bounding box set B and the ground truth set G.In theory,this strategy will produces n!/k! matches, which is inefficient.Fortunately, bounding boxes have been allocated by the Assignment Algorithm of Bounding boxes.On this premise,it just needs to be tried nk times. Then we can easily filter out the proposal box responsible for the its designated ground truth box. Suppose the image is divided into s2grids, and the total loss of model can be updated as follows:
Follow the original design, the loss of classification and confidence still use binary cross entropy. We mainly modify the regression function Lreg, named refined regression loss (RL),repelling the model to locate all objects accurately,which is a core in detecting in a crowded scene.The original CIoU loss focuses only on the proposal box,drive it to the ground truth box while ignoring other bounding boxes, which may bring redundant results,confusing the prediction for adjacent objects. To address this dilemma,based on the original CIoU loss,we add two penalty term i.e., intra-penalty and inter-penalty. Intra-penalty is designed to repel the proposal box from other bounding boxes falling in the same bounding box set Gbj, which support the model to reduce unreasonable detection results. Inter-penalty term is designed to keep bounding boxes designated for different objects away from each other, relieving the interference caused by high-overlapped objects.
To better explain our refined regression loss, we first give the following definition.For a bounding box set Gbj,it is easy to find out the proposal box and we term it gb(1)ij. Other bounding boxes are redundant results for designated object,which is denoted by gb(2)ij.gb(2)ijcan be seen as an average bounding box, which is obtained from averaging the size parameters of these redundant boxes.Furthermore, we take the arithmetic mean of the whole Gbjand term it.The refined regression loss can be illustrated as follow:
The refined regression loss is consisting of three parts.The first is the original regression term, which is calculated by CIoU Loss,and the latter two items are intra-penalty and inter-penalty successively. As can be seen, intra-penalty is mainly to separate the proposal box from other bounding boxes, and inter-penalty is to keep any two bounding box sets designated for different objects away from each other. They are all implemented by punishing the overlap.Where,α,β are parameters to balance the weight of each term.Instead of using IoU directly, we proposed a f[•] to calculate the two added penalties, which is defined as:
Using this formula to get the derivation of θ, that is:
When θ∊(0,1), f[θ]′is always greater than zero, which means that the larger the overlap area (IoU), the heavier the punishment will be given to the latter two items, which greatly meets the demand of our refined regression loss.Besides,f[θ]′will grow with the increase of IoU,which is help to speed up the training of our model.
3.3. Data augmentation
During training phase, we use multiple groups of anchors to seize more highly overlapped objects, executing our joint prediction by the designed joint loss. There are still few problems with this scheme though it seems to work. The difficulty of crowded scenes detection lies in the complex possibility of occlusion,which requires a generalization ability to accept different degrees of overlap. If annotated samples can depict these possibilities to the greatest extent,the problem will be solved.Besides,we need more highly-overlapped object pairs to ensure the implementation of our proposed scheme, which is a challenge to the dataset. Even for CrowdHuman,the average of pairwise overlap between two human instances(larger than 0.5 IoU)is only 2.4.CityPersons is less(0.32).Moreover, to improve the accuracy, we adopt a T-Score, which further reduces the number of valid samples i.e,highly-overlapped objects. The original YOLOv4 uses CutMix and Mosaic data augmentation to train the model more fully.CutMix randomly cut a certain region of one original image and mix it to another image while Mosaic simply mixes four complete training images into one new image, which may not accessible in crowded scenes as these operations may introduce more invalid samples instead.To provide more valid training pairs, we proposed a new data augmentation,named, Derived Joint-object Augmentation (DJA). It purely retains regions where the object pairs with IoU larger than 0.4 while others are discarded to eliminate the interference of invalid samples.If the retained region is occluded by other ground truth boxes, DJA will randomly cut a rectangular region from the occluded part, which simulates the occlusion and is more in line with the reality.The area of this region is 30%of the occluded part.Different with the original CutMix and Mosaic,DJA preserve highly overlapped regions,which enlarge the training samples and strengthen our joint-prediction scheme. Furthermore, selective occlusion for highly overlapped regions brings more hard positives, which can improve the generalization ability of our model.
Fig. 5(a) is the flowchart of our proposed Derived Joint-object Augmentation. In step ①, IoU between all objects are calculated and object pairs (yellow and purple boxes in column 1) with IoU greater than 0.4 i.e., valid samples are selected. Meanwhile, its corresponding occlude part is determined (shadow region in column 2).In step ②,invalid areas are removed while the occlude part is randomly cut out of a specific rectangle. Finally, we execute a scale jittering operation, which randomly jittering the remaining area m times with a amplitude [δw,δh] , where
δw~Uniform(-w,w),and δh~Uniform(-h,h),w and h are width and height of remaining area. During the process of jittering, we ensure that the size of the positive area does not exceed the original input image. Fig. 5(b) are two original images and corresponding results after processing of DJA. For simplicity, there is only one object pair with IoU greater than 0.4 in both two images. Meanwhile, extra results given by the scale jittering operation are not reflected.Supposing an extremely crowded scene,where there are n eligible object pairs. In this way, the image derives to an m×n group. They will be fed into our YOLO-CS. In CrowdHuman, the average of pairs whose IoU is greater than 0.4 is 4.89.It means that DJA can generate several times of valid object pairs. Abundant samples are enough to withstand our T-Score threshold.
3.4. Score-NMS
NMS is an independent branch during inference.If it is still used as postprocessing to determine the result, our scheme will be meaningless. Theoretically, our model can obtain the unique positive in the crowded scene if it fits the designed joint loss well.Besides,due to the strict admission criteria for ground truth boxes,our proposed method has the ability to get prediction boxes with high scores, i.e., large IoU and extremely similar aspect ratio with truths. On this premise, we modify the post-processing, named Score-NMS. That is, we used our T-Score rather than IoU as the threshold to determine whether one prediction box retain or not.As mentioned above, our T-Score more suitable for similarity measurement between two boxes. Besides, usage of T-Score can keep the consistency of training and inference.
Supposing{pr1,pr2,…}is a set of prediction boxes,in which prjis the box with the highest classification score. For any prediction box pri, if
Then, pri→0.
As mentioned above, our T-score can better represent the probability that two prediction boxes are responsible for one ground truth.Hence,prediction boxes with high scores need to be suppressed. As highly overlapped objects are widespread in crowded scenes,we set the threshold Ntto a larger value to improve the tolerance of much more prediction boxes. Note that we have conducted a set of strict schemes i.e., T-Score for assignment of bounding boxes and refined regression loss to drive the prediction boxes designated for the same object to gather very closely,higher threshold in post-processing will not bring great damage to the precision.
4. Experiments and results
In the section, experiments we have conducted on CityPersons[40], CrowdHuman [37], and MS COCO dataset to evaluate the performance of the proposed joint prediction scheme will be introduced in details,including the setting of involved datasets,the implementation details of contrast experiments and ablation experiments, the experimental results and analysis.
4.1. Datasets setting
Experiments to verify the effectiveness of our proposed method is mainly conducted on three datasets, i.e., CrowdHuman, City-Persons and MS COCO.CityPersons and CrowdHuman datasets are widely used benchmarks to evaluate the performance of detector in crowded scenes. CityPersons includes ~3k5 images with ~ 20 k manually annotated persons and 6768 ignore region annotation while CrowdHuman contains about 15 k images with~340 k person and ~99 k ignore region annotations. Furthermore, we conduct experiments on COCO to comprehensively evaluate the robustness of our proposed scheme in various scenarios. Fig. 6 shows more details about the three benchmarks, where green columns denote the overlap with an IoU threshold of 0.5 and blue columns denotes density, i.e., the number of objects per image. We can see that the overlap region per image of CrowdHuman is much larger than the other two. As for COCO, its density is bigger than CityPersons, but has a smallest overlap region (only 0.02 per image). That is,CrowdHuman, CityPersons and COCO correspond to heavily,moderately, and slightly overlapped situations respectively, which can comprehensively test the performance of our scheme.Certainly, we should pay more attention to performance in crowd scenes, so most of the contrast and ablation experiments will be conducted on CrowdHuman.For the two benchmarks,the training set is used for training and the validation and testing sets are involved in evaluation.
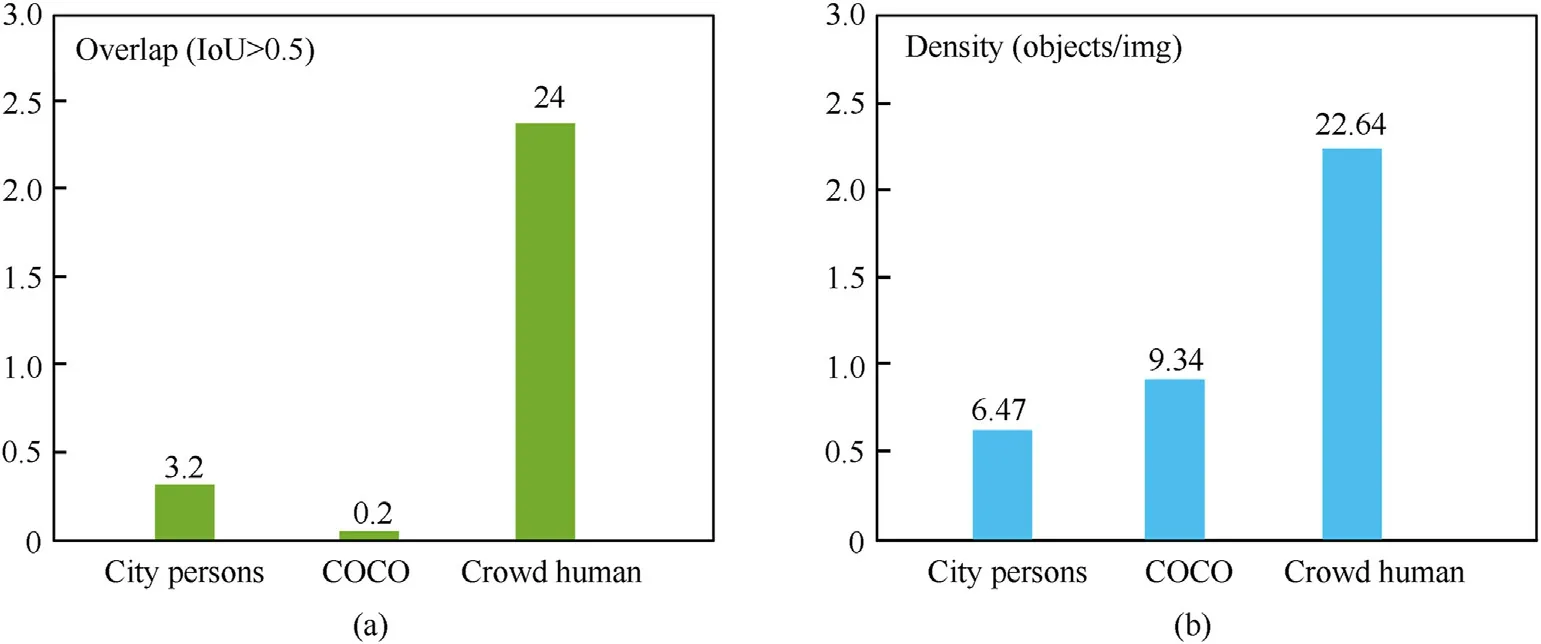
Fig. 6. Comparison between CityPersons, COCO and CrowdHuman.
We carried out three groups of experiments,i.e.,experiments on CrowdHuman, CityPersons and MS COCO. Ablation analysis and comparison are used to evaluate our proposed scheme. For experiments on CityPersons, training set is used for training and the val set is used for valuation.For experiments on CityPersons, we train our detector on the training set, and evaluate it on both the validation and the testing sets.For the experiments over the MS COCO dataset,following the common practice of[35,36],the union of the 80 k training set and 35 k val set are used for training,and the 5 k val set is used for valuation.
4.2. Evaluation metrics
Following the standard evaluation metric,log-average Miss Rate over False Positive Per Image (FPPI) ranging in between 0.01 and 100 (denoted as MR-2following) is used to evaluate the performance of the detectors. MR-2is positively correlated with false positives so lower MR-2indicates better performance. Besides,Averaged Precision (AP) and Recall are also used in our experiments.AP covers the comprehensive performance of precision and recall while Recall represents the proportion that true positives in all positive samples.
4.3. Implementation details
For fair comparison,we follow the default configurations in the structure of YOLOv4 [9], and use the original YOLOv4 as the baseline. During the training phase, we used the SGD optimizer with a momentum of 0.9 and an L2weight decay of 0.0005.The batch size is 32 and subdivisions is 16.Each training runs for 50 epochs,using a stepwise learning decay:10-4by epoch 5,10-3by epoch 10,10-4by epoch 30,10-5by epoch 50.Multiscale training and test are not applied; instead, longer sides of input images are resized to 618 pixels, and the shorter sides are also adjusted to maintain the aspect ratio for both training and test. We then extended these resized images to 618×618 pixels by zero padding.By convention,we initialize the backbone networks of our model with the weights pre-trained on ImageNet [43]. Unless otherwise specified, we set the hyper-parameters of the proposed model in following Table 2.

Table 1 The proposed Assignment Algorithm of Bounding Boxes.
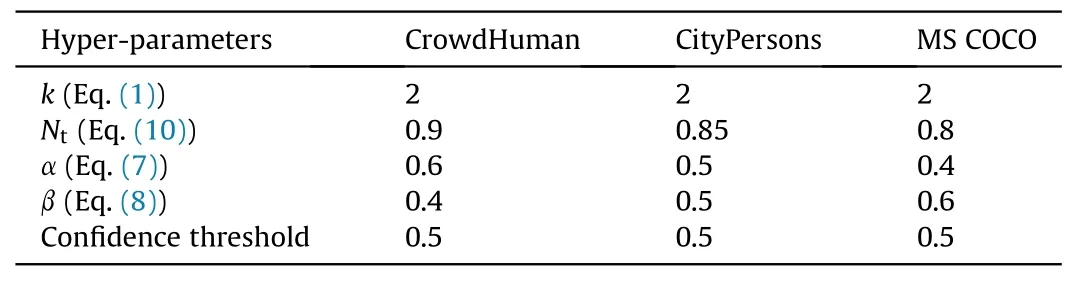
Table 2 Default hyper-parameter settings in our experiments.
4.4. Ablation study
To analyze the impact of each component on the final experimental results, we firstly conduct comprehensive ablation studies over CrowdHuman and CityPersons datasets.The results are shown in Table 3. Furthermore, we simply extend our research on City-Persons dataset and the results are shown in Table 4.Our proposed components, i.e., the assignment algorithm of bounding boxes,derived joint-object augmentation, refined regression loss, and Score-NMS are denoted as Assignment, DJA, RL and SN, respectively.Every line represents one combination,which is composed of the corresponding component of ‘√‘.
4.4.1. Results on CrowdHuman
By comparing the first two lines in Table 3,we can see that the proposed joint prediction scheme achieves greater performance than the baseline with MR-2decreased by 1.11%, AP increased by 2.76% and Recall increased by 0.18%, which demonstrates the effectiveness of our method in crowded scenes.Compared with AP and MR-2,joint does not significantly improve the recall rate.Thisis because we use T-Score instead of IoU as the threshold for the assignment of bounding boxes, which may ignore some hard positives, reducing the sensitiveness of our model to these positives and resulting in the low recall rate.Hence,the result is acceptable.In addition, our proposed components are mutually reinforcing in improving the performance of the model, not restrict each other.On this premise, we conduct the ablation study on these three proposed components i.e., derived joint-object augmentation,refined regression loss and Score-NMS.
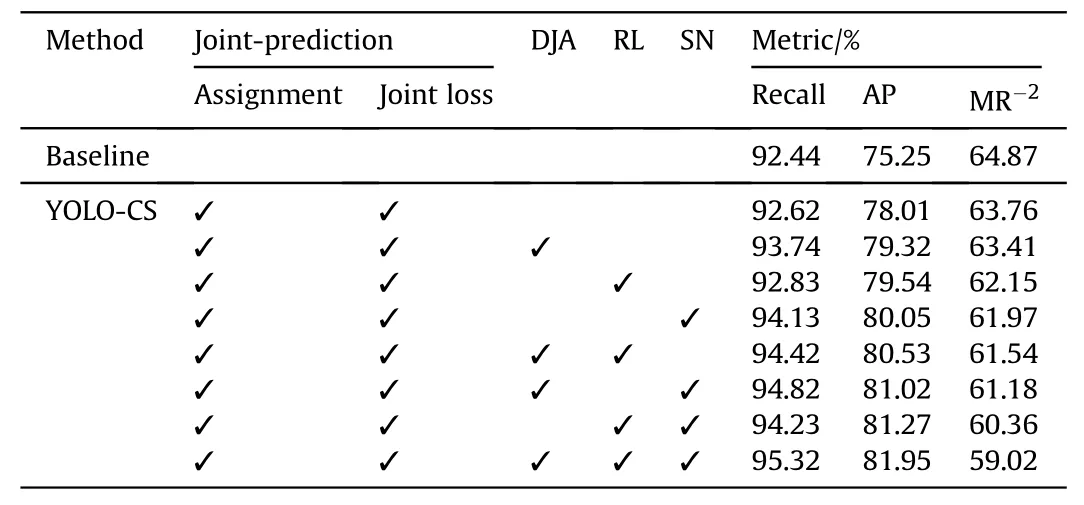
Table 3 Ablation results on CrowdHuman.

Table 4 Comparison of results(mAP/%)with different hyper-parameters of the classification loss function.
1) Derived Joint-object Augmentation
By comparing the data in first three rows, we can see that our derived joint-object augmentation is more suitable for crowded scenes than the original preprocessing.It helps our proposed YOLOCS achieve significant improvement with recall increased by 1.12%,MR-2decreased by 0.35%and AP increased by 1.21%,which proves that DJA can highlight more hard positives and reduce missed objects.Fig.7 gives the visualizations of feature maps after processing by our YOLO-CS. (a) is two original images. (c) are the corresponding results given by complete YOLO-CS while(b)is the results without DJA.Obviously,features of objects in(c)are more vivid and consistent with truths,which is useful to located objects accurately.Meanwhile,for hard positives(overlapping persons in two original images), DJA also separate them better, magnifying the discrimination between the two similar objects and effectively improving the performance on recall. In short, derived joint-object augmentation expands the number of positive samples and highlights hard positives, which effectively compensates for the defect that the recall is not significantly improved due to the strict joint prediction.
2) Refined Regression Loss
We evaluate the refined regression loss by experimental results of row 1, 2 and 4 in Table 3. The addition of RL improves the performance with recall increased by 0.21%,MR-2decreased by 1.61%and AP increased by 1.53%. Compared with DJA, RL cannot bring more hard positives but mainly reduces the number of false positives by refining the existing bounding boxes to realize the optimization of MR-2and AP. Hence, it cannot raise the recall as DJA.Fig. 8 is the visual comparison of predicted bounding boxes generated by baseline and YOLO-CS.(a)are two original images.(b)and(c)are corresponding results generated by YOLOv4 and YOLOCS, respectively. The above results have not been post-processed.We can see that boxes that predicting the same object in YOLOCS are closer to each other than baseline. It is because we have implemented strict training criterion and applied refined regression loss to our joint loss,which drives the results tend to groundtruths. Besides, there are fewer predictions (red) lying in between two adjacent objects in YOLO-CS, which is undoubtedly more friendly to post-processing because these red boxes are likely to remain in NMS and damage the performance of our model.Briefly,DJA brings more hard positives while IL eliminates many false positives. They jointly give impetus to the overall performance of YOLO-CS.
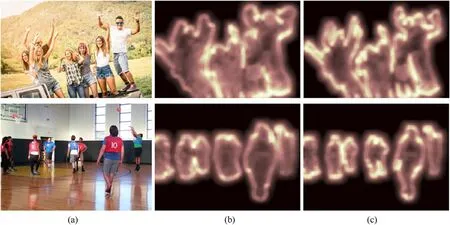
Fig.7. Visual comparison between complete YOLO-CS and YOLO-CS without DJA.(a)are two original images.(b)and(c)are corresponding results given by YOLO-CS and YOLO-CS without DJA, respectively.
In addition, we attempt to modify the hyperparameters of the refined regression loss to observe their impact on the results,which are shown in Table 4. First, we fix Ntand modify the other two parameters.We can see that different parameter sets may achieve a greater discrimination. Briefly, larger α achieves better results. In high-density CrowdHuman, intra-penalty is more prominent than inter-penalty so the latter should be given more weight to keep their balance. When a = 0.6,β = 0.4, RL helps the model achieve best performance. If continuing to decreasing α , the performance becomes worse instead, probably too large α brought a new imbalance.Then we fix α and β and observe the effect of Nt.When the Ntis 0.90, our model yields the best performance on AP and MR-2.As for the recall,it is positively related to Ntin theory,which is also confirmed by our results. Notice that Ntreaches 0.9, the recall tends to be stable. Hence, it is worthless to pursuit a perfect recall at the cost of great damage of AP and MR-2. Generally, α =0.6,β=0.4 and Nt=0.9 is a suitable match. It should be pointed out this parameter set is purely applicable to the CrowdHuman dataset.From Table 4,we can also conclude that every dataset owns its appropriate hyperparameters. As for α and β, in the general benchmark COCO, the inter-penalty item is significantly less than the intra-penalty because there are few crowded scenes.Therefore,we should give inter-penalty item more weight to balance with intra-penalty. CrowdHuman is just the opposite. Besides, there is no demand to increase Ntat the risk of introducing more false positives to improve the recall because most objects are dispersed in COCO.

Fig.8. Visual comparison of predicted bounding boxes without post-processing.(a)are two original images.(b)and(c)are corresponding results generated by YOLOv4 and YOLOCS, respectively.

Table 5 Comparison between the performance of the baseline with different losses.

Table 6Comparison between the performance of the baseline with different NMS.
Furthermore, we compare the performance of Refined Regression Loss with several methods,including YOLO-CS with smooth L1[4], IoU [42], GIoU [17] and Distance-IoU [18] losses, which are presented by S-L1,LIoU,GIoU,respectively in Table.As YOLOv4 uses CIoU-loss, YOLO-CS with CIoU-Loss equal to YOLO-CS without IL and the result have listed in row 7 of table.We only used MR-2to evaluate their ability to suppress false positives. As shown in Table 5,our proposed IL is far ahead of other existing loss,achieving great improvements of 3.65%, 3.26%, 3.21%, 2.60% and 2.16% MR-2decreased compared with smooth L1, IoU, GIoU and DIoU losses,respectively. Obviously, our RL is more suitable for detection in crowded scenes.
3) Score-NMS
The results of row 1,2 and 5 in Table 3 indicate the great power of our proposed Score-NMS,which greatly improves the performance of YOLO-CS with recall increased by 1.51%, MR-2decreased by 1.79%and AP increased by 2.04%.The result also reflects the role of postprocessing in crowded scenes detection. As shown in Fig. 8,prediction boxes designated for different objects generated by our YOLO-CS can be easier to distinguish.Meanwhile,our T-Score can magnify the slight difference because it can better describe the similarity between overlapping boxes. Hence, we can raise the threshold T-score without hesitation to preserve more ground truths, which bring few false positives.
Similarly, we compare the performance of Score-NMS with the original DIoU-NMS under different thresholds.DIoU-NMS use DIoU as threshold and our score-NMS is the proposed T-score.AP is used as the evaluation as it weights both recall and precision.The results are illustrated in Table 6, where we only intercepted their best performance areas.The extremum of DIoU-NMS is in(0.4,0.6)while our Score-NMS lies in (0.75,0.95). As shown in Table 6, when threshold is 0.65,results of NMS and DIoU-NMS are both best with 76.27% and 80.53% AP, respectively while our proposed achieve great performance with 81.95% AP when Score is 0.90. Score-NMS achieving great improvements of 4.68% and 1.42% compared with NMS and DIoU-NMS.
Finally, we analyze the bottom four lines of the table. The performance of any combination of two modules is better than one of them.We can see that the Score-NMS is relatively powerful,which gives a comprehensive improvement to the model so combinations involving Score-NMS perform better.Meanwhile,RL focuses on the promotion of MR-2and AP, while DJA effectively improves the recall rate.
4.4.2. Results on CityPersons
We also conduct ablation experiments on CityPersons and COCO datasets to evaluate our proposed method in moderately and slightly overlapped situations. As shown in Table 7, our proposed module is still valid. The function of each module is similar to CrowdHuman, among which, the Score-NMS is still decisive.Compared with CrowdHuman,each metric in CityPersons is better as detection for CityPersons is easier. Meanwhile, in CityPersons,our methods cannot improve as much as that in CrowdHuman.It is reasonable because our methods are more suitable in heavily crowded scenes.
4.5. Comparison with previous works
To determine the performance of our proposed method, we conduct a set of contrast experiments with previous works,including one-stage two-stage and anchor-free methods. The original YOLOv4 is used as the baseline to ensure the convenience of experiments.
4.5.1. Results on CrowdHuman
As mentioned above, CrowdHuman has a highest overlap region, which can test the effectiveness of our method to the great extent.For fair comparison,we follow the evaluation metric used in CrowdHuman,and all the experiments are only used the full body region annotations.The main results are presented in Tables 8 and 9. As shown in Table 9, compared with the original YOLOv4, we receive significant improvements with recall increased by 2.68%,MR-2decreased by 5.85%and AP increased by 6.70%at the cost ofonly 3.4 FPS and 4.8 M parameter amount,which demonstrates the superiority of our modification for YOLOv4 on crowded scenes.From point of view in Ref.[9],our Score-NMS meets the definition of bag of specials while other modules e.g., DJA and RL belongs to bag of freebies, which cause little damage on the efficiency during inference. Furthermore, our YOLO-CS outperforms most one-stage detectors in Table 1 with 59.02% MR-2and 82.14% AP. In terms of efficiency, using 4 GTX 1080TI with 10 GB memory, YOLO-CS can reach 45.2 FPS, which is almost twice as much as some two-stage detectors e.g., POTO [45]. That is to say, though our accuracy is suboptimal(lower than some two-stage methods e.g.,PedHunter),our YOLO-CS achieves the sate-of-the-art comprehensive performance compared with other existing crowded scenes detectors.Moreover,we can see that two-stage detectors perform better than one-stage on the whole, which is in line with common sense. As mentioned in Section 2, crowded scenes are natural obstacles for one-stage detectors because most of them have no modules equivalent to RPN in Faster R-CNN to pre filter redundant proposal boxes. Hence, it is not demanding for our YOLO-CS to outperform two-stage detectors on both efficiency and accuracy.
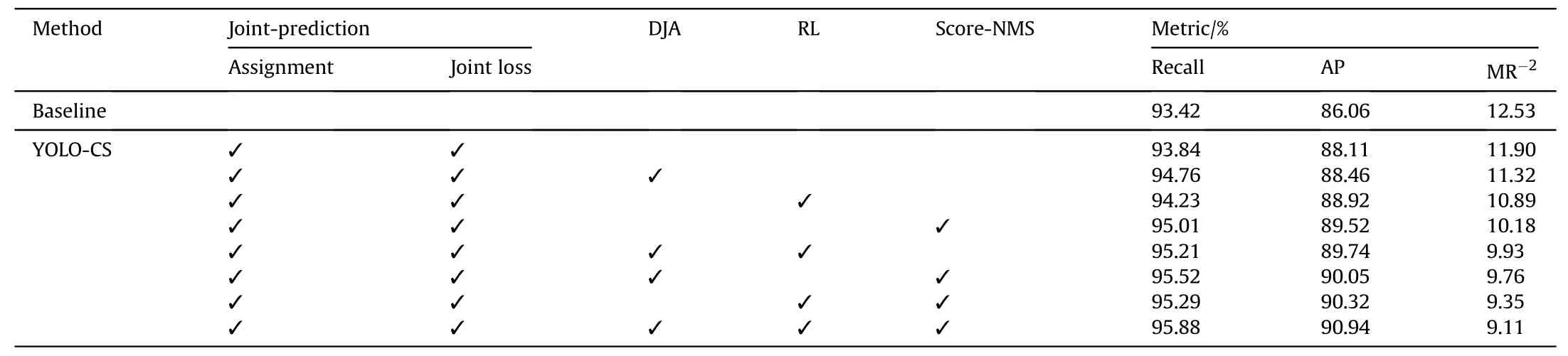
Table 7 Ablation results on CityPersons.
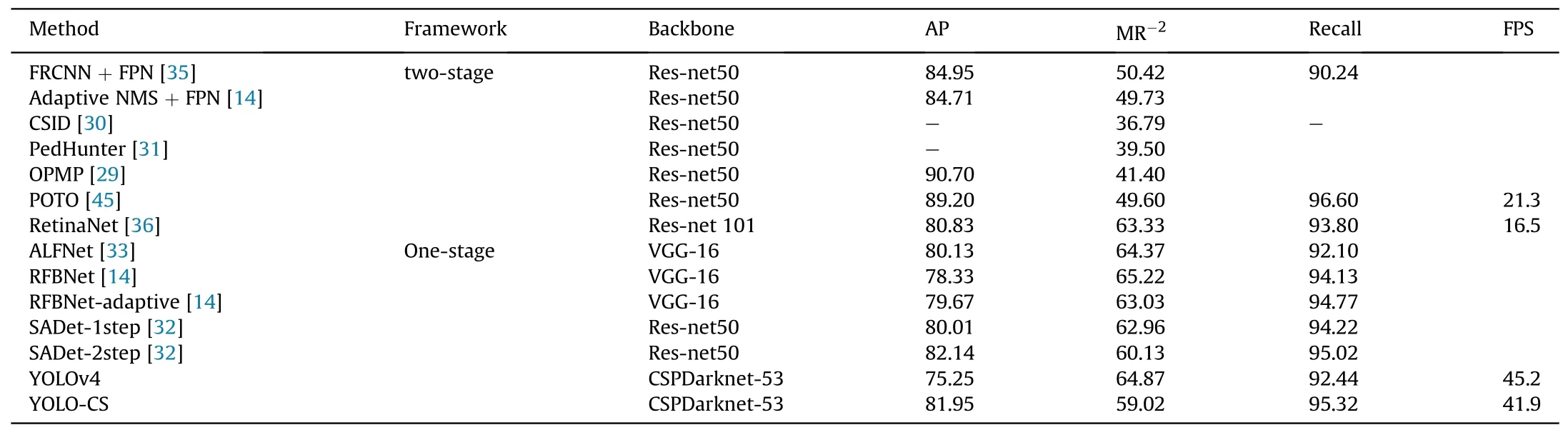
Table 8 Comparison between YOLOv4-CS and other method on CrowdHuman.

Table 9 Comparison between YOLOv4-CS and baseline.
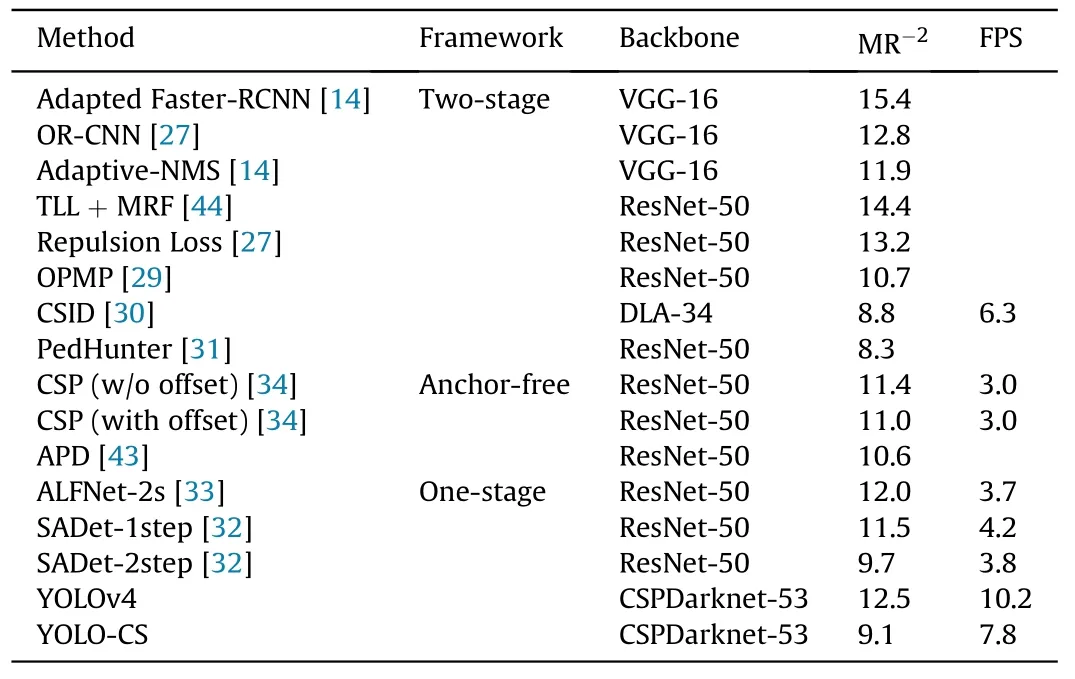
Table 10 Comparison between YOLOv4-CS and other methods on CityPersons.
4.5.2. Results on CityPersons
Similarly, we compared our YOLO-CS with other detectors on CityPersons benchmark,including two-stage,anchor-free and onestage detectors. Follow the metric in most work, we only used MR-2to evaluate the performance of our proposed method and the result is given in Table 10. FPS is also reported to conduct a more comprehensive evaluation. For MR-2metric, our YOLO-CS consistently presents the best or comparable performance,surpassing all mentioned one-stage detectors, which is similar to the result on CrowdHuman dataset. In comparison with FPS, YOLO-CS also achieved attractive result. Besides, we can further conclude that anchor-free methods perform better than most one-stage detectors in crowded scenes.It may be because anchor-free methods reduce the dependence on anchor boxes and related processing e.g.,NMS,which support them do better in crowded scenes instead.Briefly,in moderately crowded scenes, our YOLO-CS can also achieve strong competitiveness.
4.5.3. Results on COCO
As shown in Fig.6,the density of COCO is very low,which is not the focus of our work. Hence, we should be more tolerant of its performance.However,it is necessary to test the robustness of our proposed scheme for more occasions. Furthermore, CrowdHuman and CityPersons are single-class datasets,where mainly intra-class overlap problems exit. On the contrary, COCO is a multi-class dataset with scenes of inter-class overlap, which can measure the comprehensive performance of YOLO-CS combined with the above experiments.For fair comparison,we retrain YOLOv4 with our own implementation under the same setting and get the same result with [9] roughly. In addition, we introduce the result of Faster R-CNN and RetinaNet from Ref. [8], which are both widely used basic detectors. All data are lists in Table 11. APS, APMand APLdenote the AP of small, moderate, and large objects respectively.From the result in Table 11,our YOLO-CS withstand the scene which is quite different from the other two datasets. Compared with YOLOv4, our YOLO-CS obtain more than 1% improvement, e.g., AP increased by 1.3%, AP50increased by 1.9% and AP75increased by1.1%. For large objects, YOLO-CS achieve the most significant improvement with 2.4%,which may be because larger objects are more likely to overlap.The results demonstrate that our YOLO-CS is not only effective on crowded scenes,but robust in multiple classes and general scenes.

Fig. 9. Visualizations of the results.

Table 11 Comparison between YOLOv4-CS and other methods on COCO.
4.6. Visualization of detection results
We visualize some detection results of our experiments in Fig.9,where row 1,2 and 3 are from CrowdHuman,CityPersons and COCO benchmarks, respectively. Red dashed boxes represent missed cases while red solid boxes are false positives. Boxes with other colors represent success cases.Although our YOLO-CS has achieved great performance,it still cannot finish the task in some cases,such as the miss person in row 1 column 1, the missed person in row 2 column 3 and the mistakenly-detected train in row 3 column 3,which leaves room for our work to improve. On one hand, our model still relies on NMS-based postprocessing although our Score-NMS has well balanced the precision and recall, which may damage the stability of performance. On the other hand, since crowded scenes are not friendly to the usage of anchors, anchorfree based detector may be one breakthrough of object detection in crowded scenes in the future.
5. Conclusion
In this paper, a joint prediction scheme based on YOLOv4 is proposed to address the dilemma in crowded scenes detection,that is, we attempt to detect a set of objects in one cell with multiple anchor groups.Specifically,we present an assignment of bounding boxes,delivering most appropriate results to every object and then train the model with a joint loss. During inference, we use Score-NMS to screen detection results. For better performance, we propose a derived joint-object augmentation and refine the regression loss.The former mainly raise the recall by enlarging positive pairs,the latter eliminates more false positives by repelling the model to locate objects more accurately.With above approaches,our model achieves great performance on challenging benchmarks e.g.,CrowdHuman and CityPersons. Besides, the experiment on COCO suggests that our model is robust to various scenes.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
The authors acknowledge the China National Key Research and Development Program (No. 2016YFC0802904), National Natural Science Foundation of China(61671470)and 62nd batch of funded projects of China Postdoctoral Science Foundation (No.2017M623423).

- Defence Technology的其它文章
- Trans-scale study on the thermal response and initiation of ternary fluoropolymer-matrix reactive materials under shock loading
- An improved SLAM based on RK-VIF: Vision and inertial information fusion via Runge-Kutta method
- Shock response of cyclotetramethylene tetranitramine (HMX) single crystal at elevated temperatures
- A super resolution target separation and reconstruction approach for single channel sar against deceptive jamming
- Camouflaged people detection based on a semi-supervised search identification network
- Angular disturbance prediction for countermeasure launcher in active protection system of moving armored vehicle based on an ensemble learning method