
Camouflaged people detection based on a semi-supervised search identification network
2023-03-28 08:38YngLiuCongqingWngYongjunZhou
Defence Technology 2023年3期
Yng Liu , Cong-qing Wng , Yong-jun Zhou
a College of Automation Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, 211106, China
b Science and Technology on Near-Surface Detection Laboratory, Wuxi, 214000, China
Keywords:Camouflaged people detection Search identification network Semi-supervised learning strategy Unmanned aerial vehicles (UAVs)
ABSTRACT Automated detection of military people based on the images in different environments plays an important role in accurately completing military missions. With the equipment gradually moving towards intelligence, unmanned aerial vehicles (UAVs) will be widely used for integrated reconnaissance/attack in the future. The lightweight and compact design of the small UAV allows it to travel through dense forests and other environments to capture images with its convenient mobility. However, as the camouflage has been designed to blend in with surroundings, which greatly reduces the probability of the target being discovered. Moreover, the lack of training data on camouflaged people detection will inhibit the training of a deep model. To address these problems, a novel semi-supervised camouflaged military people detection network is proposed to automatically detect the target from the images.In this paper,the camouflaged object detection dataset(COD10K)is first supplemented according to our mission requirements, then the edge attention is utilized to enhance the boundaries based on search identification network. Further, a semi-supervised learning strategy is presented to take advantage of the unlabeled data which can alleviate insufficient data and improve the detection accuracy. Experiments demonstrate that the proposed semi-supervised search identification network (Semi-SINet) performs well in camouflaged people detection compared with other object detection methods.
1. Introduction
Future intelligent warfare refers to the next-generation war based on creative technology represented by artificial intelligence[1,2]. One of the typical is the use of unmanned systems for autonomous confrontation to detect and strike targets [3-5].However, the excellent camouflage technology often allows military equipment and armed personnels to blend well in the environment [6,7]. This camouflage technique has brought huge obstacles to UAV's military target reconnaissance [8,9]. In recent years, different types of target detection algorithms have emerged and made certain progress,but little attention has been devoted to military camouflaged target detection.
Previous target detection algorithms based on deep learning are often divided into two categories[10,11],one is based on candidate regions to complete target detection such as Faster R-CNN and SPP-Net, and the other is based on regression ideas such as YOLO and SSD. Owing to the real battlefield environments may include desert,woodland,snow,etc,thus the above-mentioned traditional algorithms perform poorly in camouflaged target detection as they fall into the trap of the edges and background of camouflaged targets.
Subsequently, some scholars put forward another research perspective,which is to regard the problem as a camouflaged target segmentation task based on deep learning[12-14].Literature[15]firstly constructed a camouflaged people dataset(CPD)in different environments and proposed the dense deconvolution network(DDCN) by introducing short connections in the deconvolution phase.In order to make full use of semantic information,Literature[16]designed a strong semantic dilation network(SSDN)to detect camouflaged people in an end-to-end architecture. Literature[17,18]proposed a framework that extracts different features of the image and performs non-linear fusion to quantitatively calculate and fuse both local and global saliency maps by the saliency detection method to evaluate the performance of camouflage pattern. Literature [19] constructed a larger and densely labeled camouflaged object dataset COD10K including more than 78 categories and provided a search and identification network(SINet)to detect camouflaged targets.
Due to the following problems,it is still a difficult task to detect military camouflaged people from images:
(1) The texture, size and position of camouflaged targets in different environments change drastically, which poses a challenge to the detection task. For example, the edge features of targets in snow, desert, and woodland are easy to melt into the environment.
(2) Compared with other target detection tasks, it is hard to collect enough labeled data to train a deep model. The famous target detection datasets such as ImageNet and VOC,etc cannot be used.
In order to solve the above problems, we propose a novel deep network Semi-SINet for segmenting camouflaged targets from images in different environments. Our motivation mainly stems from the increasing tendency to use the UAV for target detection in small-scale special operations,but military personnels usually hide themselves in the environment by camouflage. Our research is based on SINet that first extracts feature information of the image through the search module,then uses the identification module to accurately detect the camouflaged target and adds the edge attention module to explicitly enhance the edge detection. What's more, in order to alleviate the impact of the shortage of labeled data, we also introduce a semi-supervised learning strategy based on random sampling to enable the model to take advantage of unlabeled data.
In a nutshell, our contributions in this paper are threefold:
(1) We supplement various annotated datasets of camouflaged military people according to task requirements to expand COD10K and the SINet network is improved to detect military camouflaged people.
(2) An edge attention module is introduced to make better use of low-level features containing edge information, thereby enhancing the segmentation effect of the network.
(3) A semi-supervised learning strategy is proposed to improve SINet, that is, generous unlabeled military camouflaged people images are used to effectively supplement the training data.
As a general method for detecting camouflaged people, the proposed model was tested on the public dataset and the dataset constructed in this paper.In addition,the method is also verified on the images captured by UAVs to prove its potential application in UAV reconnaissance.
2. Related works
2.1. The existing camouflage dataset
The detection of military camouflaged people is a hot issue that has gradually attracted attention,in previous work,Zheng et al.[15]have built a dataset of camouflaged people and expanded the 600 images to 12,000 images for training.However,the detection effect of the network only trained by data augmentation is not satisfactory.Deng et al.[19]have established a dataset called COD10K that includes 10,000 images, covering camouflaged objects in various natural scenes, over 78 object categories. Regarding our mission,the detection of military camouflaged people in different environments requires more labeled datasets,but COD10K contains only a few such images. In this paper, to make our dataset more convincing, it is need to be expanded based on the previous COD10K.
2.2. UAV reconnaissance
UAVs equipped with cameras have been fast deployed to a wide range of applications, including aerial photography, reconnaissance, surveillance, etc. As an ideal platform for object detection,UAV can capture the scene in the view from top through its convenient mobility and the aerial imagery system[20]. However,compared with object detection in ordinary images,there is a significant difference to detect targets from the aerial image taken vertically in UAVs: firstly, angles of targets in aerial images are mostly viewed from the top and oblique, and targets features in aerial images are more difficult to detect; secondly, the size of the target changes with the shooting angle and the target tends to appear as a point or plane as the flying height increases[21,22].In particular,for the task of detecting camouflaged people,the target is easily mixed with the surrounding environment.When the UAV takes aerial photography at a certain height, features of the camouflaged people become less obvious. Fig.1 shows the images taken at different flying altitudes.When the flying altitude reaches 10 m,the scale of the camouflaged target is already small for human observation.
In addition,the application backgrounds assumed in this paper are special operations in environments such as jungles or mountains,which are often affected by the cover of trees.It is difficult to find camouflaged people in high-altitude aerial photography,so it is necessary to enter the environment for close reconnaissance as shown in Fig. 2. The UAV used in this paper is DJI MAVIC 2 with a size of 322 × 242 × 84 mm, which allows it to move freely in the woods for reconnaissance missions.The image obtained in this case is different from the traditional aerial image and the shooting angle is still close to the horizontal shot. The algorithm and dataset constructed in this paper are designed and evaluated by humancentered close-up images taken horizontally.
3. Camouflaged people detection dataset
Due to the limitation of experimental conditions, we collected and added a variety of camouflaged images in other environments from the Internet. The UAV is also used to capture images of camouflaged people in the woods for subsequent feasibility verification. The specific selection principles are as follows:
1) The camouflage style of the dataset should include different backgrounds such as woods, mountains,deserts and snow.
2) The postures of the camouflaged people should include standing, kneeling, lying, standing, squatting, etc.
3) The application environment assumed in this paper is that the UAV is used as pathfinder for small-scale special operations and the flight altitude is basically kept within 5 m.
The specific number of newly added camouflaged people images in different environments is shown in Table 1.Finally,we can get a new and expanded dataset called COD10K+which includes 10,600 labeled images and 1000 unlabeled images. The dataset is resized and annotated according to the same standard.Fig.3 shows some of the newly added dataset images and corresponding pixel-wise ground-truth maps.

Table 1 Number of newly added camouflage people images in different environments.
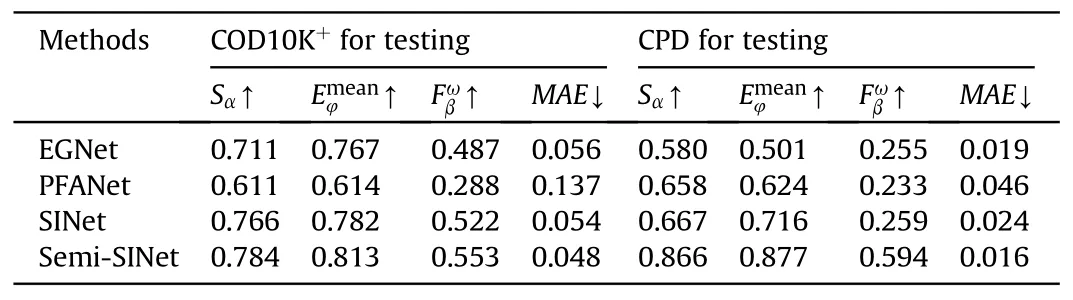
Table 2 Quantitative results of different methods on two datasets.

Fig.1. Images taken at different flying altitudes.

Fig. 2. Camouflage reconnaissance mission using the UAV.
4. Proposed camouflaged people detection model
The purpose of military camouflage is to integrate personnels into the environment and prevent being discovered by the enemy to increase the possibility of survival on the battlefield. Therefore,the task of camouflaged target detection is much more difficult than traditional missions. However, humans can still find those finely disguised targets in most cases as the human visual system can make full use of the low-level features and high-level semantic information of objects[23].Inspired by this,we focus on extracting the semantic information of the target for camouflaged people detection. In this paper, we propose a Semi-SINet framework for the detection of military camouflaged personnel, which mainly contains three parts, one is used to search for camouflage targets,one is used to accurately detect targets and the other is utilized to take advantage of unlabeled samples to improve performance.Fig. 4 shows the framework of search and identification network.For an input camouflage image, the Search Module is first used to extract deep features to obtain a set of features {rfsk,k = 1,2,3,4}.The extracted features are then sent to the Identification Module to obtain the camouflage maps Csand Cipredicted by the network.Finally,the predicted camouflage target map is compared with the ground-truth (GT) map in the training set to optimize the loss function, and further obtain the optimal detection model.

Fig. 3. Camouflaged military personnels in different environments.
4.1. Search module
In the Search Module,SINet draws on the human visual system and introduces the receptive field module to incorporate more discriminative feature representations. The latest research [23]demonstrates that the low-level layer outputs contain more spatial information to build object boundaries and the deeper layer outputs contain more abundant semantic features to locate objects.For an input image I, we first use the ResNet-50 model [24]for feature extraction to obtain a set of features{xk}4k=0.In order to retain more information in the image, we adopt the same settings as the original SINet, that is, the resolution of each layer is, where W, H represent the width and height of the image respectively.In this paper,the extracted features are divided into three levels: low-level {x0,x1}, middle level {x2}, high-level{x3, x4}. Then the features are combined by concatenation, upsampling, and down-sampling operations to preserve the image details as much as possible. The dense connection strategy is adopted in the network,specifically,a total of three concatenation operations are performed including{x0,x1},{x2,x3,x4}and{x3,x4}.It is worth noting that the receptive field(RF)module represented in Fig. 3(b) has been added to the network to incorporate more discriminative feature representations. The fused features are all sent to the RF module for enhancement as inputs,and then a set of enhanced features {rfsk,k=1,2,3,4}are obtained.
4.2. Edge attention
In the previous dense link strategy, we have given enough attention to deep features such as deep features{x3}and{x4}have been fused at least twice. In other words, the shallow features are ignored to a certain extent. However, some researchers [25,26]studied the use of edge features to assist training and obtained beneficial effects that edge information can give constraint relations during feature segmentation. Since there is adequate edge information preserved in low-level features,we input the low-level feature with suitable resolution(concatenated{x0}and{x1}in this paper) into the edge attention module.
As shown in the dotted box called EA in Fig.4,the concatenated feature is fed into the convolutional layer with one filter to produce the edge map Se.It is rather remarkable that the same convolution is firstly repeated three times to extract more features and increase the nonlinear fitting ability of the network.In order to measure the difference between the produced edge map Seand the edge map Gegenerated by ground-truth map, the Binary Cross Entropy (BCE)loss function Ledgeis designed as follows:
where(x,y)represents the coordinate of each pixel in the truth map,Gerepresents the edge ground-truth map, Serepresents the predicted edge map, w and h represent the width and height of corresponding map, respectively.
4.3. Identification Module
The purpose of the Identification Module is to use a set of features {rfsk,k=1,2,3,4} extracted by the Search Module to locate and detect the camouflaged target. In this module, the Partial Decoder Component (PDC) [27] represented in Fig. 3(c) is firstly used to integrate the extracted features as follows:
where Csrepresents the calculated coarse camouflage map and{rfsk= rfk,k = 1,2,3,4}.
In order to enhance the initial camouflage map, the Search Attention(SA)module[24]is applied to eliminate interference.The input of the SA module comes from the middle-level feature {x2}and the Csobtained in the previous step, then the SA module outputs the enhanced camouflage map Ch:
where fmaxrepresents the maximum function to strengthen the camouflage area, g (∙) represents the typical normalized Gaussian filter,the standard deviation σ is set to 32 and the kernel size λ is set to 4. Similar to the search phase, we still firstly send the acquired features to the RF module for enhancement, and then further use the PDC module for aggregation. Finally, two camouflage object maps Ccsmand Ccimcan be obtained through up-sampling.The cross entropy loss LCE[25] is used as our loss function to train the network. As shown in Eq. (1), a loss function Ledgeis designed for edge supervision, so the total loss function can be constructed as follows:
4.4. Semi-supervised module
The problem of lack of training dataset has already been mentioned in Section 2, in order to accurately detect the military camouflaged targets, our dataset has been used to expand the original COD10K dataset, but the labeling is time-consuming and labour-intensive. The remaining problem is that with the continuous acquisition of actual battlefield images and changes in combat clothing, images in the training set also need to be continuously updated. For the purpose of solving the above problems, we propose a semi-supervised learning strategy[28-31]to improve SINet,which leverages generous unlabeled military camouflaged images to effectively augment the training dataset. The process of semisupervised learning is shown in Algorithm 1.

Algorithm1 Semi-SINet
Our proposed method is based on a random sampling strategy.Specifically, we first generate the pseudo labels for unlabeled military camouflaged images and expand the training dataset. Then a two-step method is adopted in this section to train the model through the expanded training set. The flowchart of a semisupervised learning network Semi-SINet is shown in Fig. 5.
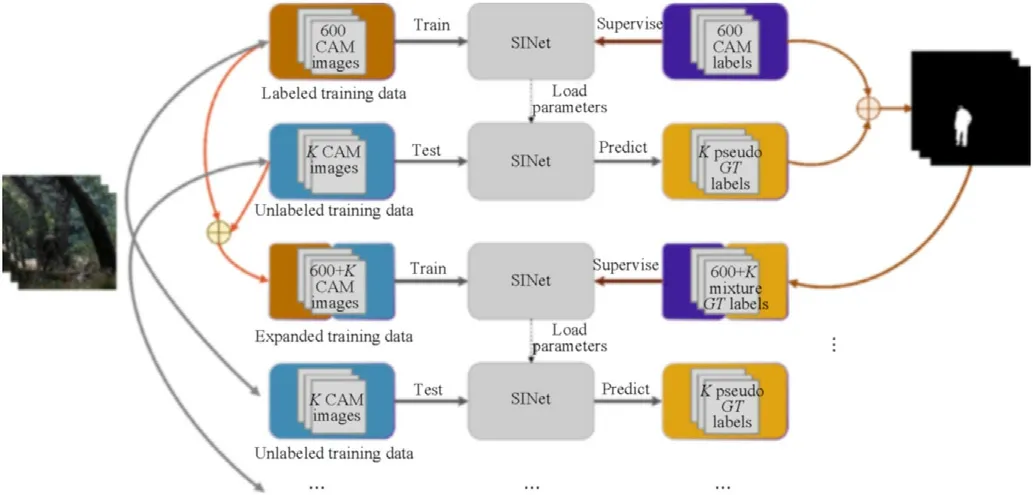
Fig. 5. The flowchart of a semi-supervised learning network.

Fig. 6. Detection results of images captured by the UAV.

Fig. 7. Visual comparison of military camouflaged people detection results.
5. Experiments and results
5.1. Experimental settings
The current camouflage dataset is scarce, although some researchers [16] have proposed some techniques including rotation,scale, etc. to complete data augmentation, the improvement of detection effect still be apparent not enough. COD10K is currently the largest camouflage dataset, and the characteristics of camouflage objects are all hidden in the surrounding environment,which is same for animals or humans.Although the detection target in this paper is only for military camouflaged personnel, COD10K is still used as the basic dataset to improve the generalization of the model.But there are only dozens of camouflaged people dataset in COD10K which is insufficient for the task requirements in this paper. So, we added 600 images of camouflaged people in different environments and meticulously annotated them according to the same requirements. All images are resized to 352 × 352 before training and we select another 1000 camouflage images as the unlabeled training data described in Algorithm 1, the number of randomly selected K is set to 5. The expanded dataset COD10K+is spilt into 6360 images for training and 4240 images for testing.
Our module Semi-SINet is implemented in PyTorch. The Adam optimizer is employed for training and the learning rate is set to 1e-4. The network training is based on early stop strategy, which takes about 110 min to converge over 40 epochs with a batch size of 36. Our experimental platform is Intel i9-9900 k CPU, NVDIA RTX2080Ti 16 GB GPU.
5.2. Evaluation indexes
In order to evaluate the performance of our proposed method,it is compared with EGNet [25], PFANet [23], and the original SINet[19]. The following four indexes are used to compare with other methods, including Structure Measure [32], FωβMeasure, Enhancealignment Measure [33], and Mean Absolute Error. Thus, the similarity/dissimilarity between the final prediction map Spand ground-truth map G can be measured as follows:
(1) Structure Measure (Sα): This was proposed to measure the structural similarity between a prediction map and groundtruth map, which is defined as follows:
where α is a balance factor between object-aware similarity Soand region-aware similarity Sr.
(2) Enhanced-alignment Measure(Eφmean):This was designed to evaluate both local and global similarity between the two binary maps:
where w and h respectively represent the width and height of the ground-truth map,and(x,y)represents the coordinates of the pixel.φ is the enhanced alignment matrix.
(3) Comprehensive evaluation index (Fωβ): The accuracy and recall can be comprehensively measured by the following formula:
where β and ω are different weights.
(4) Mean Absolute Error (MAE): The pixel-wise error between Spand G can be measured as follows:
5.3. Comparison of experimental results
To evaluate the performance of camouflage detection, we compare the proposed Semi-SINet with three classical models in the deep learning, i.e., EGNet, PFANet, SINet. Quantitative results are shown in Table 2. ↑&↓denote larger and smaller is better,respectively.As can be seen,the proposed Semi-SINet outperforms other methods in terms of Sα, Fωβ, and MAE. When we use the CPD dataset [15] for testing, each indicator has been improved significantly.This shows that the improvements conducted in this paper for the detection of camouflaged people are effective. We also use the COD10K+dataset for testing and there is a certain improvement in performance, which proves that it does not affect the generalization of the model.Overall,the proposed method performs better than three other models.
5.4. Ablation studies of our Semi-SINet
In order to verify the performance of the improvements,several comparative experiments are carried out as shown in Table 3.100 images of camouflaged people are randomly selected as the test set.
1) Effectiveness of COD10K+:Firstly,two different training sets are used to explore the contribution of the expanded dataset. The 1st and 2nd rows of the table show the results of using COD10K and COD10K+as the training set,respectively.The result clearly shows that the expanded dataset COD10K+can enable our model to accurately detect camouflaged people.
2) Effectiveness of EA:Secondly,we investigate the importance of the edge attention (EA) module. By comparing the 1st and 3rd rows of Table 3,it can be observed that EA module increases the performance of SINet in most indicators. It proves that the salient edge information is useful for the camouflaged object detection task.
3) Effectiveness of Semi-supervised strategy: To demonstrate the advantages over SINet, the Semi-supervised strategy is introduced to assist network training. The performance is shown in the 4th row of Table 3. Compared with the baseline model, it demonstrates that the proposed method is beneficial to improve the detection effect.
4) Effectiveness of COD10K++ EA: We also investigate the importance of the combination of COD10K+and EA. By comparing the 1st and 5th rows of Table 3, we can find that all metrics have been improved and the combination is beneficial for boosting performance.

Table 3 Ablation studies of our Semi-SINet.
5) Effectiveness of COD10K++ EA + Semi-supervised strategy:Finally, we investigate the importance of the overall improvement of the proposed method in this paper.The result of the 6th row is better than any other set of results, which proves the superiority of our method to detect camouflaged people.
5.5. Visual analysis
In this section,different images are selected for testing and the results are visualized to prove the universality of the detection model. In Section 4.5.1, images captured by the UAV in woods are used for the feasibility analysis of UAV reconnaissance. In Sections 4.5.2 and 4.5.3,two groups of camouflage images are selected from four different backgrounds to intuitively show the detection effects of different methods. The cases where there is only a single target or multiple targets in the images are tested separately to illustrate the effectiveness of the detection model.
5.5.1. Detection of images captured by the UAV
In order to verify the feasibility of the UAV to conduct camouflaged people reconnaissance, we randomly selected three images of people in different poses captured by the UAV in the woods environment for testing. As shown in Fig. 6, the camouflaged people are accurately detected from a complex background environment. It is proved that the poposed method can complete the detection task from the images taken by the small UAV in the reconnaissance environment.
5.5.2. Detection of single target
In this section, we use different methods to detect a single camouflaged personnel in four different environments (sand,wood, rock, snow) and visualize the results. Besides, the size and posture of the target to be detected are different from each other.As shown in Fig.7,the original image of each group appears in the first column, the second column represents the Ground Truth of the target area, the third to fifth columns are the experimental results produced by the comparison method, and the sixth column is the results of the proposed method. PFANet's results are not satisfactory as there are large areas not been detected.EGNet improves the results,but the performance is still not promising and there is false detection when performing rock camouflage detection. SINet has made progress in detail detection,but the result is still insufficient when the camouflage edge is not obvious. The result of our Semi-SINet is closer to the ground-truth map and better than other methods, which proves the superiority of single military camouflaged people detection.

Fig. 8. Visual comparison of military camouflaged people detection results.
5.5.3. Detection of multiple targets
In this section, camouflage images with multiple targets are used for the experiment and visualization.As shown in Fig.8,there are a large amount of background interference in the results of PFAnet and EGNet.The detection results of SINet also contain some noise points and missed detection such as the desert and mountain.Besides, all the comparison methods have omissions for the detection of small targets. When performing the task of woods camouflage detection, a small camouflage target needed to be detected is missed. Our proposed method has the effect closest to Ground truth and it not only detects large targets but also takes care of small targets.In summary,since the Semi-SINet method uses the edge attention module and different levels of convolution feature combinations,the proposed method can better detect camouflaged targets.
6. Conclusions
Aiming at the key issues of camouflaged target reconnaissance and detection in special operations environment, a novel network Semi-SINet based on semi-supervised strategy is proposed to detect camouflaged people. Considering several factors relative to camouflage effectiveness, we first expanded the dataset according to task requirements and utilized explicit edge-attention to improve the identification of camouflaged targets. Due to the current shortage of datasets and continuous updates of camouflage patterns, a semi-supervised strategy is used to take advantage of the unlabeled data.Experimental results of the public dataset verify the versatility of the model,and the test results of images taken by the UAV verify the feasibility for UAV near-ground camouflage reconnaissance. In this paper, three typical target detection methods were selected to carry out an experimental comparison on our COD10K+dataset.Quantitative results and visualization effects have demonstrated that the proposed Semi-SINet outperforms the current detection models and advances the state-of-the-art performances.The proposed method can accurately and quickly detect camouflaged people, which enriches the application scenarios of UAVs under small-scale special operations and has a broad military application prospect.
Since our experiment is based on images captured by the UAV or collected on the Internet rather than real-time detection,we plan to further enrich the COD10K+and develop a real-time camouflaged people detection system based on the UAV.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
The authors would like to acknowledge the Project of Science and Technology on Near-Surface Detection Laboratory (Grant no.TCGZ2019A006) to provide fund for conducting experiments.

- Defence Technology的其它文章
- Trans-scale study on the thermal response and initiation of ternary fluoropolymer-matrix reactive materials under shock loading
- A novel modification method for the dynamic mechanical test using thermomechanical analyzer for composite multi-layered energetic materials
- An improved SLAM based on RK-VIF: Vision and inertial information fusion via Runge-Kutta method
- Shock response of cyclotetramethylene tetranitramine (HMX) single crystal at elevated temperatures
- A super resolution target separation and reconstruction approach for single channel sar against deceptive jamming
- Angular disturbance prediction for countermeasure launcher in active protection system of moving armored vehicle based on an ensemble learning method