
基于Dlib和变种Transformer的哈欠检测方法
2023-03-25 02:07:46廖冬杰
汽车技术 2023年3期
廖冬杰
(1.华东交通大学,南昌 330013;2.江西省先进控制与优化重点实验室,南昌 330013)
主题词:哈欠检测 Dlib 哈欠特征矩阵 变种Transformer YawDD
1 前言
疲劳驾驶是造成交通事故的主要原因之一[1],而打哈欠是驾驶员疲劳初期的主要表现形式之一[2]。因此,研究驾驶员疲劳初期的哈欠特征,从而进行准确检测,对保障道路交通安全具有重要意义。
国内外研究人员针对哈欠检测已进行了大量的研究。马素刚等[3]充分关注人脸的各种特征,以驾驶员面部图片作为输入,通过卷积核进行特征提取,并利用Softmax 分类器判断驾驶员是否打哈欠,但只关注了单帧图像的分类,没有充分利用多帧图像在时间维度上的关联性,可能把讲话、唱歌、大笑等张嘴行为误检测为打哈欠。Mateusz Knapik 等[4]对热成像视频进行人脸区域检测,提出眼角检测算法,实现了人脸对齐,通过检测嘴部区域的快速温度变化判断驾驶员的打哈欠行为,但未考虑大幅度张嘴呼吸以及咳嗽等特殊情况。史瑞鹏等人[5]提出了一种基于多任务卷积神经网络(Multi-Task Convolutional Neural Network,MTCNN)的加速优化算法,对图像中驾驶员是否存在张嘴行为进行分类,以嘴部持续张开时间作为评判驾驶员是否打哈欠的标准,但此类方法分类标准无法准确度量,无法确定嘴部持续张开时间阈值,只能根据经验给出,无法达到最优效果。王超等[6]提出只关注嘴部图像,利用卷积神经网络(Convolutional Neural Network,CNN)和长短期记忆(Long Short-Term Memory,LSTM)网络对视频进行空间和时间的特征提取,从而实现哈欠检测,但是这类方法哈欠检测特征单一,未考虑眼部等特征与哈欠行为的关联,缺乏全面性。
本文基于Dlib 和变种Transformer[7]模型,针对哈欠检测特征单一的问题,同时关注左右眼部、嘴部的特征变化,构建包含直接哈欠特征和隐含哈欠特征的哈欠特征矩阵,有效避免驾驶员嘴部呼吸、咳嗽等嘴部特殊情况的误检;针对无法度量阈值的问题,采用深度学习的方法,利用变种Transformer 模型进行隐含哈欠特征提取,并实现哈欠分类,提高算法的准确性;针对帧与帧之间缺乏联系的问题,引进多头注意力机制和序列编码,以降低检测中大笑、说话等情况的误检可能性。
2 基于Dlib 和变种Transformer 的哈欠检测方法原理
Dlib是一个包含众多机器学习算法、图像处理和数值计算等丰富功能的开源工具箱,广泛应用于人脸识别、分类等领域。Transformer模型是一种自然语言处理模型,由编码器(Encoder)和解码器(Decoder)组成[7],可以完成特征提取,同时捕获远距离的依赖关系,实现分类和生成等功能。本文旨在实现驾驶员哈欠检测,故提出基于Dlib和变种Transformer的哈欠检测方法,其原理如图1所示。

图1 哈欠检测原理
本文提出的哈欠检测方法主要包含3个部分:
a.人脸检测和关键点定位。通过基于集成回归树(Ensemble of Regression Trees,ERT)的Dlib 算法进行人脸检测以及68点关键点定位。
b.哈欠特征矩阵构建。根据定位关键点坐标提取眼部、嘴部直接哈欠特征,得到每帧的哈欠特征向量,在时间维度进行堆积,构建包含直接哈欠特征和隐含哈欠特征的视频哈欠特征矩阵。
c.哈欠检测。在得到视频哈欠特征矩阵的基础上,利用变种Transformer 模型进行特征提取和视频分类,完成对视频中是否有打哈欠行为的检测。
3 基于Dlib的哈欠特征矩阵构建
3.1 Dlib人脸关键点定位
Dlib 人脸关键点定位使用了Vahid Kazemi 等人提出的ERT级联回归算法[8],该算法构建了级联的梯度提升决策树(Gradient Boosting Decision Tree,GBDT),使得预测的人脸形状即关键点不断回归到真实位置[9],其基本思想是:每一个GBDT 的每个叶子节点均储存着残差回归量,当输入经过某一叶子节点时,将当前输入和叶子节点储存的残差回归量相加,起到回归作用,所有残差回归量相加后,即可获得预测的人脸形状。与传统算法相比,ERT 算法具有较出色的准确率和检测速度,同时还能够处理数据缺失的问题[8]。ERT 算法核心表达式为:
式中,S为由p个关键点坐标组成的人脸真实形状;∈R2(i=1,2,…,p)为面部图像I的第i个关键点的坐标;为第t次的人脸估计形状;为第t次计算得到的残差回归量。
考虑到Dlib 在人脸检测和人脸关键点检测上的出色能力,本文利用Dlib提供的人脸关键点模型[10]对车内驾驶员的68个人脸关键点进行检测,结果如图2所示,试验证明,Dlib人脸关键点检测算法在车内环境中有着优秀的关键点定位能力。因此,利用Dlib人脸关键点模型分析驾驶员疲劳时的眼部和嘴部哈欠特征是可行的。

图2 车内环境人脸检测关键点
3.2 哈欠特征构建
眼睛和嘴是驾驶员在打哈欠时表现最为突出的部分。本文利用Dlib人脸关键点模型得到人脸关键点,提取眼部的12个关键点坐标信息、嘴部的6个关键点坐标信息,如图3、图4所示,以眼部和嘴部张度作为直接哈欠特征,得到视频帧哈欠特征向量,再按照时间维度堆积,构建包含嘴部持续张开时间、眼睛闭合时间比例(Percentage Eyelid Closure over the Pupil over Time,PERCLOS)等隐含哈欠特征的视频哈欠特征矩阵,从而进行哈欠行为检测。

图3 眼部关键点

图4 嘴部关键点
3.2.1 眼部哈欠特征
根据Soukupová等人[11]提出的观点,驾驶员眼部开合程度的改变可以通过眼部纵横比(Eye Aspect Ratio,EAR)的变化来表征。用pi表示图3、图4 中编号为i的点,左、右眼眼部纵横比Real和Rear的计算公式为:
John Sofia Jennifer 提出,为了定位角度更为宽广的朝向角,不必同时考虑2 只眼睛,仅使用单眼检测即可达到出色效果[12],但本文考虑到驾驶员可能存在揉眼、扭头等行为造成实际仅能检测到1 只眼睛的情况,将左、右眼部纵横比均作为哈欠特征。
3.2.2 嘴部哈欠特征
鉴于人在打哈欠时,嘴部的张合程度会发生明显改变,因此类比于Soukupová提出的眼部纵横比,本文引入一种评估嘴部开合程度的新指标——嘴部纵横比(Mouth Aspect Ratio,MAR)。考虑到不同驾驶员嘴部的厚度差别,根据嘴唇的相关关键点进行特征提取:
式中,RMA为嘴部纵横比。
至此,已经根据人脸关键点模型提取出眼部和嘴部的哈欠特征,将这些特征组合在一起,形成视频帧哈欠特征向量。
3.2.3 特征矩阵构建
基于驾驶员驾驶状态的视频采集图像,提取每个视频帧Real、Rear、RMA特征值,获得单帧的哈欠特征向量Vec:
式中,Reali、Reari、RMAi分别为第i个视频帧的左、右眼眼部纵横比和嘴部纵横比;n为视频所含视频帧数量。
若将特征向量按照时间维度进行堆积,得到视频特征矩阵HQ:
由于存在时间信息,HQ除了包含视频每帧的左、右眼部纵横比和嘴部纵横比等直接哈欠特征以外,还包含嘴部持续张开时间、短时间内是否存在嘴部张度大幅度改变、单位时间眨眼次数、PERCLOS 等隐含哈欠特征,为后续分辨驾驶员是否存在哈欠行为奠定了基础。
4 变种Transformer模型
4.1 Transformer模型
李小平等[13]通过LSTM 对得到的驾驶员疲劳特征矩阵进行分类,从而判断驾驶员是否处于疲劳状态。卢喜东等人[14]通过深度森林方法对方向梯度直方图(Histogram of Oriented Gradient,HOG)特征矩阵进行恶意代码分类。本文选择变种Transformer模型提取HQ的隐含哈欠特征,从而完成对视频中驾驶员是否打哈欠的分类,因为Transformer通过注意力机制可以捕获远距离依赖关系,并可实现循环神经网络(Recurrent Neural Network,RNN)不能实现的并行训练功能,结构如图5所示。

图5 Transformer模型结构
图5 中,编码器部分的输入为词向量矩阵,考虑到单词间的顺序,为每个词向量添加了位置编码,计算公式分别为:
式中,P(s,2i)、P(s,2i+1)分别为句子中第s个单词偶数维度/奇数维度的位置编码;dmodel为位置编码的维度。
将经过位置编码的词向量矩阵作为自注意力(Self-Attention)层的输入,得到查询矩阵、键矩阵和值矩阵,如图6所示。

图6 矩阵实现自注意力机制示意
图6 中,X为位置编码后的词向量矩阵;x1、x2分别为经过位置编码第1个和第2个单词的词向量;WQ、WK、WV为训练好权重的线性变换矩阵;Q、K、V分别为X的查询矩阵、键矩阵和值矩阵。
Q与KT相乘,得到词向量与其他词向量之间的关联性,为了维护梯度的稳定性,除以,通过Softmax 函数得到该词向量与其他词向量关联性的权重,再与词向量包含的信息V相乘,可得:
式中,A(Q,K,V)为自注意力层输出;dK为键矩阵K的维度。
为了学习到更多独立信息,充分关注不同子空间,引进多头注意力机制[7],设hi为第i个子空间的自注意力层输出,将m个子空间的hi进行横向拼接得到多头拼接矩阵,通过线性变换矩阵Wo将多头拼接矩阵变换成与X相同形状:
考虑到网络中可能出现的退化问题,将X与M进行连接,再进行层标准化,得到前馈神经网络输入Of:
式中,LayerNorm为层标准化函数。
将Of通过由线性层、线性整流函数(Rectified Linear Unit,ReLU)层和线性层构成的前馈神经网络进行残差连接和层标准化,结束模型的编码器部分,公式为:
式中,Os为前馈神经网络的输出;Ot为编码器部分的输出;W1、b1分别为第1层线性层的参数矩阵和偏置;W2、b2分别为第2层线性层的参数矩阵和偏置。
Ot经过模型的解码器部分,连接一个线性层,通过Softmax进行分类,完成整个Transformer模型的构建。
4.2 Transformer模型的改进
由于Transformer 的解码器部分主要完成生成类功能,而疲劳驾驶哈欠检测只需要实现哈欠特征的分类任务即可,故本文提出一种只使用编码器部分的变种Transformer模型。其基本思想是:在继承Transformer模型编码器部分的基础上,对输入嵌入、位置编码以及输出层进行了改进,整体结构如图7所示。

图7 变种Transformer模型结构
图7 中,模型的输入不再是词向量矩阵,而是经过Dlib 检测算法构建的如式(7)所示的疲劳特征矩阵HQ,如图8所示,设为序列编码的维度,利用维的矩阵W*,得到线性变换Ⅰ的输出:

图8 HQ变换示意
为了充分考虑各视频帧之间的时间先后顺序,将进行序列编码:
式中,S(q,2j)、S(q,2j+1)为视频中第q帧视频帧偶数维度、奇数维度的序列编码。
根据式(10),得到其他视频帧包含的该视频帧信息,通过式(11)和式(12),多个子空间充分挖掘学习视频帧相关信息,之后根据式(13)~式(15),得到变种Transformer模型编码器部分的输出,通过图9所示的变换,利用维的线性变换矩阵Wα得到线性变换Ⅱ的输出O:
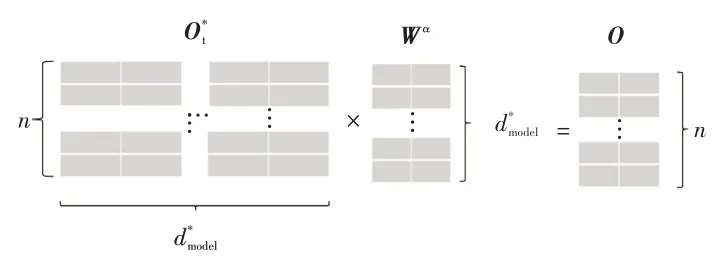
图9 变换示意
如图10所示,利用(n×1)维的矩阵Wβ对O的转置矩阵OT进行线性变换,得到线性变换Ⅲ的输出Oμ:

图10 Oε 变换示意
最终分类结果为:
式中,Ans为视频分类结果;为Oμ的转置矩阵。
本文提出的变种Transformer 模型充分考虑视频帧之间的关联性,且引入序列编码使得视频帧时间维度得以关联,通过多头注意力机制和多层线性变换,可以实现对哈欠特征矩阵的分类。
5 试验验证与分析
为了验证所提出方法的有效性,本文基于YawDD数据集[15]进行训练和测试,与其他方法进行准确率的对比:
式中,Ac为准确率;TP、FP分别为被模型预测为哈欠的哈欠视频、其他视频数量;FN、TN分别为被模型预测为其他的哈欠视频、其他视频数量。
5.1 数据集构建
YawDD 数据集是一个公开的视频数据集,视频分辨率均为680×480,帧率为30 帧/s,包含2 个子数据集,分别由固定在后视镜下方的摄像头拍摄的视频和由固定在组合仪表上方的摄像头拍摄的视频组成[15]。考虑到角度问题以及人脸关键点定位精准度,本文主要以第2 个子数据集为研究对象。该子数据集中的每个视频包含不同的驾驶员,且驾驶员在同一个视频里面包含讲话、大笑、唱歌、打哈欠等行为,不能直接用来进行驾驶员哈欠检测,因此本文采用人工重构数据集的方法对数据集进行处理,得到新的数据集DX-YawDD:即将每个视频中出现的打哈欠视频片段单独裁剪出来,作为哈欠数据集,将每个视频的其他视频片段按照每段视频3~10 s 进行随机切割,得到新的视频集,作为其他数据集。经过处理后,DX-YawDD 数据集中共包含71 个哈欠数据集视频,344个其他数据集视频。
5.2 试验环境
本文试验环境配置如下:服务器处理器为Intel Core i7-9750H CPU @ 2.60 GHz,安装内存为8 GB,在Windows10环境下,在Pytorch深度学习框架下搭建了基于Dlib 和变种Transformer 哈欠检测模型,使用数据集DX-YawDD 进行模型训练和性能测试。其中,模型测试集共有125个视频,包括随机选取的22个打哈欠视频和103个其他视频,剩下的49个哈欠视频和241个其他视频组成模型训练集。
5.3 试验结果
基于训练数据集,选择变种Transformer模型的损失函数为交叉熵损失函数,采用随机梯度下降优化器,学习率为0.001,动量为0.99,得到图11所示的损失函数曲线。
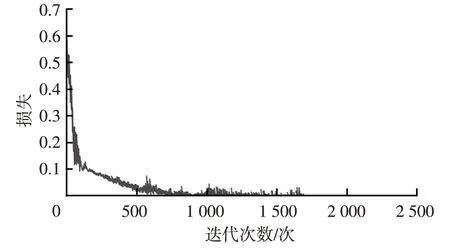
图11 训练损失函数曲线
由图11可知,当训练1 700次时,损失函数收敛,此时模型训练的准确率为100%。模型在测试数据集上的哈欠检测结果如表1所示,准确率达到96.8%,召回率为95.5%,表明本方法哈欠漏检率较低。
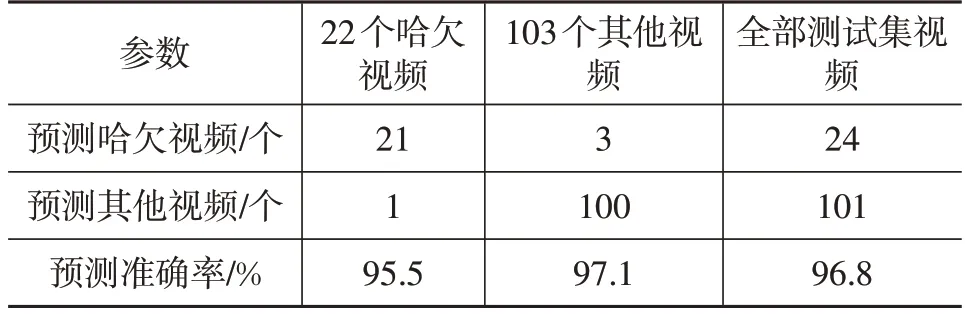
表1 测试集哈欠检测结果
将本文方法与其他哈欠检测算法基于DX-YawDD数据集进行对比验证,不同算法的哈欠检测准确率如表2所示。

表2 不同算法哈欠检测准确率
由表2可知,本文算法的检测准确率为96.8%,高于其他检测算法。这是因为本文算法综合考虑了眼部、嘴部的哈欠特征,构建了包含有直接、隐含哈欠特征的视频特征矩阵,利用变种Transformer模型进行特征提取和分类,关注了各视频帧之间的联系,捕捉到远距离视频帧之间的依赖特性,提高算法的准确性。
6 结束语
针对现有驾驶员哈欠检测时,哈欠特征单一、分类阈值无法度量、视频图像中帧与帧之间缺乏联系等问题,本文提出了基于Dlib 和变种Transformer 算法,通过公开数据集YawDD 进行测试,本文算法的哈欠检测准确率高达96.8%,可以应用于驾驶员疲劳驾驶初期哈欠检测任务,对避免驾驶员疲劳驾驶,保障人员和道路安全具有积极作用。
同时,利用本文算法进行哈欠检测时,虽然多方面考虑了人脸特征点对于哈欠检测的作用,但还存在面部特征挖掘不充分等缺陷,下一步可以通过3D 卷积等方法进行挖掘,避免显式的哈欠特征提取,进一步简化算法,提高准确率与鲁棒性。
猜你喜欢
儿童时代·快乐苗苗(2023年7期)2023-09-20 09:27:50
青年文摘(2022年11期)2022-12-10 02:12:57
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
青年文摘(2021年7期)2021-12-12 19:22:34
今日农业(2021年8期)2021-11-28 05:07:50
中学生博览·文艺憩(2020年12期)2020-12-23 09:37:52
黄河之声(2020年19期)2020-12-07 18:32:31
新课程·下旬(2019年3期)2019-05-08 08:06:34
农业工程学报(2018年10期)2018-06-05 06:54:58
知识就是力量(2018年1期)2018-02-08 00:37:18
