
基于神经网络结构搜索的卷积神经网络剪枝与压缩方法
2023-03-09 07:55蒲亮,石毅
自动化与仪表 2023年2期
蒲 亮,石 毅
(华中光电技术研究所-武汉光电国家研究中心,武汉 430223)
随着现代战争对无人化和智能化需求的增加,基于深度神经网络的人工智能技术在目标检测和目标跟踪等领域得到了广泛的应用[1-2]。但是,随着深度学习模型越来越复杂,参数和层数越来越多,巨大的存储成本和计算成本严重阻碍了深度学习模型在嵌入式设备上的部署[3-4]。因而,对网络模型的压缩裁剪是完成卷积神经网络模型部署的重要步骤之一[5-6]。
模型压缩剪枝一般分为结构化剪枝和非结构化剪枝2 种[7-9]。在结构化剪枝中,通过对BN 层的缩放因子施加L1 范数正则化训练后,使通道对应的缩放因子产生稀疏化,裁剪符合条件的通道来达到模型压缩,取得一定成效[10-11]。为了进一步提高模型在嵌入式设备上的运行速度,需要开展更加深入的神经网络模型压缩裁剪技术的研究。本文通过新的优化策略-加速近端梯度(APG)、轻量级网络设计、非结构化剪枝和神经网络结构搜索(NAS)等手段相结合,实现对目标分类和目标检测等常见卷积神经网络模型的压缩剪枝,并将压缩剪枝后模型的推断过程在嵌入式架构中实现,为深度学习技术在边缘端设备平台上的实现奠定了基础。
1 剪枝算法
1.1 基于神经网络架构搜索(NAS)剪枝
本文采用神经网络结构搜索(NAS)技术,基于数据和任务驱动的轻量级网络设计,首先训练出一个精度不低但相比常规CNN 参数量和计算量都较小的模型。将NAS 直接应用于具有可变化channel数和层尺寸的网络,通过最小化剪枝后网络的损失来学习channel 的数量,如图1所示。这种剪枝方法包括3 个阶段:
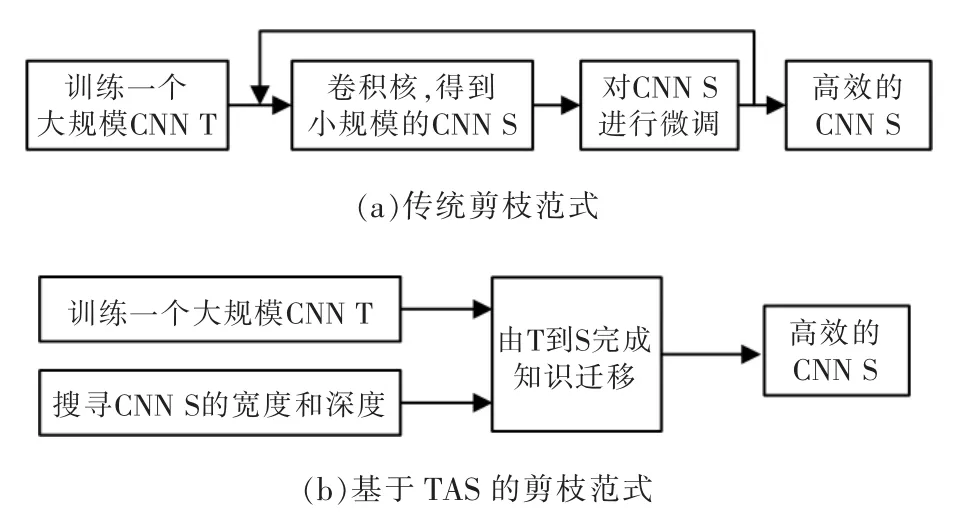
图1 传统剪枝范式和基于TAS 的剪枝范式Fig.1 Traditional pruning paradigm and TAS-based pruning paradigm
(1)用标准分类训练程序训练未剪枝的大型网络;
(2)通过可变换结构搜索(transformable architecture search,TAS)搜索小型网络的深度和宽度,TAS 的目标是寻找一个网络的最佳规模;
(3)利用简单的知识蒸馏(knowledge distillation)方法,将未剪枝网络中的信息迁移到搜索到的小型网络中。
1.2 基于加速近端梯度(APG)的优化策略的一般化结构化剪枝
在完成NAS 剪枝与轻量化模型设计后,以该模型为baseline,为网络中每一个group/block/channel等level(层级)的结构都赋予一个对应衡量其重要性的参数因子(或为方便直接采用BN 层中的缩放因子),并对这些参数因子施加L1 范数正则化,同时采用加速近端梯度(APG)优化算法,进行稀疏化训练。即是在网络的每个通道输出上、每个残差结构卷积分支上以及一些group 卷积的非identity group 的输出上乘以一个缩放因子。
由于L1 范数不可微,本文采用更好的针对L1范数正则化的近端梯度优化方法,该优化算法的解形式是软阈值函数。根据推导过程发现,要想使用该方法,要进行两次网络前传,代价太大。因此,可采用APG(accelerated proximal gradient)算法。其实,APG 算法只不过比牛顿动量优化算法多出一个投影函数(这个投影函数就是软阈值函数),只需要在牛顿动量算法的优化器中对缩放因子施加软阈值函数即可,软阈值函数的两个参数是学习率和对应缩放因子值。
目标函数为
使用APG 算法更新λ,求解过程为
其中,g(λ)表示为
作进一步的变换:
1.3 基于BN 层的结构化剪枝
BN(batch normalization)层的计算公式为
BN 层的作用是解决训练过程中的内部协变偏移。根据式(12),该操作会将卷积的输出值减去一个均值再除以一个标准差,后面再做一个仿射变换,而且缩放因子γ 和偏移β 都是可学习参数,这样既能防止卷积的输出值变化过大(导致不易收敛),同时又不会将学到的信息完全去除掉。
在CNN 中,卷积层的每一个通道对应着一个缩放因子γ 和偏移β,如果缩放因子γ 很小的话,那么这个通道可以略去,对神经网络的最终输出结果影响不会很大。就是说,γ 可以衡量每个通道的重要性,如果对这个γ 进行优化更新时采用L1 正则化,可以让其产生稀疏解。
总的损失函数如下,第二项即为正则化项:
L1 范数和L2 范数正则化。在模型的训练中,为了防止过拟合,一般都会添加正则化项。由于L2 范数是可微的,所以大多数模型训练都是采用L2 范数正则化,能得到比较平滑的解。
如图2所示,基线模型训练好之后,会产生一些接近0 的缩放因子,这时就可以把与这些接近0的缩放因子对应的通道直接去掉,同时与该通道对应和相连的卷积核都去掉,就得到了剪枝后的模型。
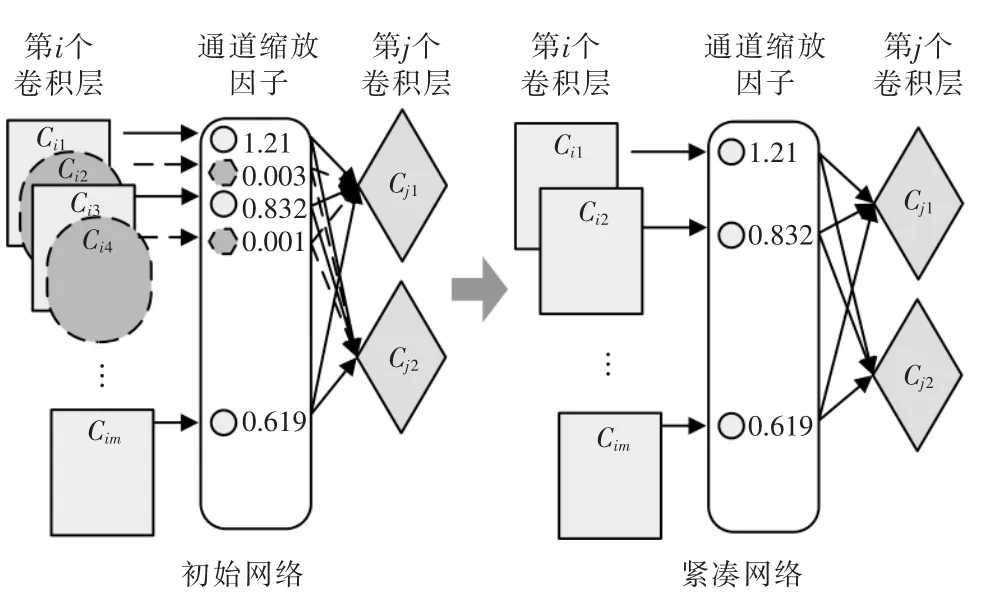
图2 基于BN 层的剪枝范式Fig.2 BN-based pruning paradigm
2 系统组成与实施流程
本文系统由训练数据库、稀疏训练模块和剪枝模块组成,其中,训练数据库存储于上位机可访问的存储器上,稀疏训练模块和剪枝模块运行在多GPU并行计算服务器上,目标检测模型运行在FPGA 等边缘端硬件上。如图3所示。
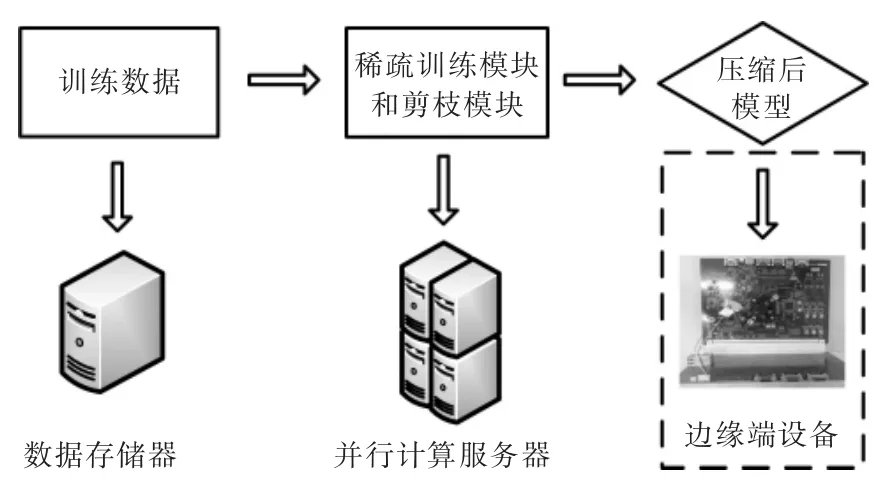
图3 系统组成Fig.3 Components of the experimental system
本文神经网络模型的稀疏化训练和模型的压缩剪枝流程如图4所示,主要可以分5 步:
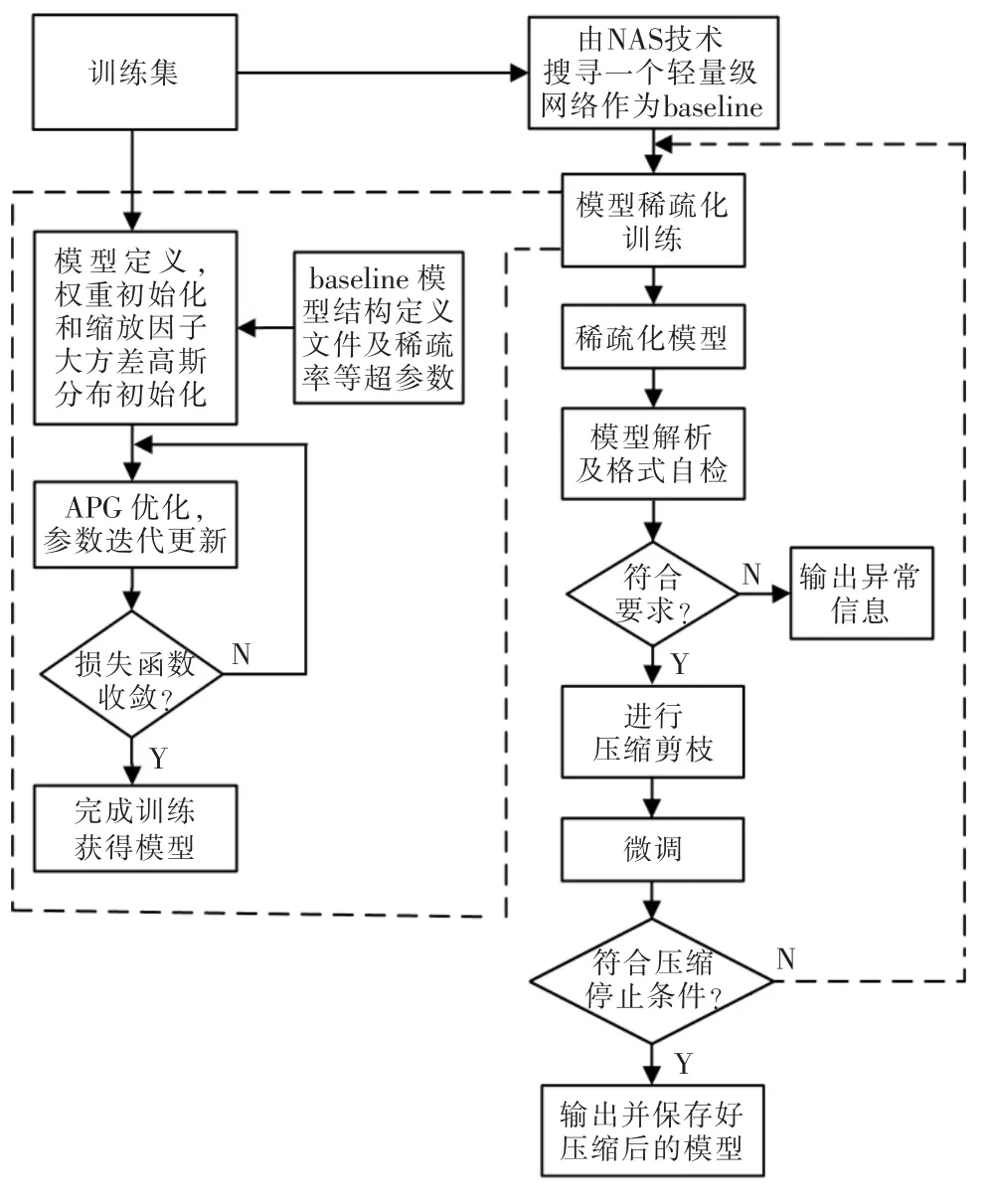
图4 算法流程Fig.4 Algorithm flow chart of the proposed method
(1)采用神经网络结构搜索(NAS)技术、基于数据和任务驱动的轻量级网络设计,首先训练出一个精度不低但相比常规CNN 参数量和计算量都较小的模型;
(2)以步骤(1)中的模型为baseline,为网络中每一个group/block/channel 等level(层级)的结构都赋予一个对应衡量其重要性的参数因子(或为方便直接采用BN 层中的缩放因子),并对这些参数因子施加L1 范数正则化,同时采用加速近端梯度(APG)优化算法,进行稀疏化训练;
(3)对于稀疏化训练完的模型,将模型中那些接近0 的参数因子对应的channel/group/block 进行裁剪;
(4)再微调剪枝后的模型,使其恢复性能;
(5)模型微调后如果能回到baseline 的精度或下降在5%以内,则返回到步骤(2),进行下一轮模型压缩剪枝,否则结束该程序。
3 实验及结果分析
3.1 算法数据集概况
本文目标分类数据集有cifar、ImageNet,目标检测数据集有voc、coco 等。ImageNet 有超过1000 万张图片,一般使用经过“修剪”后的1000 个非重叠类的列表。目标分类常用Top-1 Accuracy 和Top-5 Accuracy 来评价模型的好坏。PASCAL VOC2007 和2012 数据集总共分4 个大类,总共20 个小类。目标检测模型的优劣则一般使用mAP(平均精确率均值)这个指标来进行评价。
3.2 算法运行环境
(1)上位机平台
上位机网络模型的训练需要利用大量数据样本进行迭代运算,计算量巨大,故在配备了10 个计算GPU 的并行计算工作站上进行,其配置如下:
CPU:2×Intel Xeon E5-2683 V3 2.0G;
GPU:10×NVIDIA GeForce1080ti;
内存:512 G(32 G×16)DDR4 2400 RegECC(最大支持1.5 T);
硬盘:8×2 T SSD;
显示器:27.9 英寸4 K;
网路:Intel I350 双千兆网口+1×千兆管理网络接口;
电源:2000 W 80PLUS 2+2 高效冗余电源。
(2)嵌入式平台
神经网络模型的代码在嵌入式平台上运行,主要包括:
①智能图像处理SOC 平台ARM 部件
Cortex-A53 4 核处理器;
典型工作频率1.5 GHz;
A53 每个核中都包含32 KB 的指令cache 和32 KB 的数据cache,L2Cache 大小均为512 KB。
②智能SOC 硬件平台
FPGA SOC:Xilinx XCZU9EG;
内存:4 G 64 bit DDR4;
闪存:32 G。
3.3 实验结果
在上位机上,输入已有目标检测神经网络模型结构文件和训练数据集,进行稀疏训练和模型剪枝,运行结果如图5所示。对比压缩剪枝后和压缩剪枝前的模型准确率、参数量和计算量压缩率,压缩剪枝前的模型准确率为80.49%,模型参数文件大小为43.7 MB,计算量BFLOPS 为6.915。压缩剪枝后模型准确率为80.55%,模型参数文件大小为3.9 MB,计算量BFLOPS 为1.105。压缩剪枝后模型准确率提高0.06%,参数量下降91.1%,计算量下降84.0%。通过本文提出的压缩剪枝算法,在参数量和计算量大幅下降的同时准确率与压缩前模型保持相同水平。

图5 基于嵌入式硬件平台剪枝后的目标检测模型运行结果Fig.5 Experimental results of the target detection model with our proposed method,which was based on embedded hardware platform
进一步,将压缩剪枝后的模型部署在嵌入式硬件平台中,用压缩后的模型进行前向推理。统计模型运行时间,发现除去图像预处理时间,单帧图像处理时间(CNN 主干网络处理时间与网络后处理时间之和)最大值小于40 ms,处理速度达到25 帧以上。
4 结语
本文通过研究基于BN 层的结构化剪枝、基于加速近端梯度(APG)优化的一般化结构化剪枝、基于数据和任务驱动的轻量级网络设计以及基于神经网络结构搜索(NAS)剪枝等关键算法技术,完成了对目标分类和目标检测等常见卷积神经网络模型的压缩剪枝,实验表明压缩剪枝后模型准确率不变,参数量下降91.1%,计算量下降84.0%。最后将压缩剪枝后模型的推断过程在嵌入式架构中实现,为深度学习在边缘端设备平台上的实现奠定了基础。
猜你喜欢
保健医苑(2022年5期)2022-06-10
怀化学院学报(2021年5期)2021-12-01
成都信息工程大学学报(2021年6期)2021-02-12
安阳工学院学报(2020年4期)2020-09-11
计算机应用(2020年5期)2020-06-07
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学杂志(2018年5期)2018-09-19
中国校外教育(下旬)(2017年8期)2017-10-30
天津诗人(2017年2期)2017-03-16
东北师大学报(自然科学版)(2014年1期)2014-02-27
