
基于狮群优化极限学习机的数据融合算法
2023-02-21 13:16:22何鸿燊
计算机工程与设计 2023年2期
刘 宏,何鸿燊,何 江
(1.江西理工大学 电气工程与自动化学院,江西 赣州 341000; 2.安徽农业大学 经济管理学院,安徽 合肥 230036)
0 引 言
无线传感器网络中传感器节点体积微小,自身电池容量以及处理数据的能力均有限,网络可以根据传感器节点的能量水平被划分为同构和异构[1]。在异构无线传感器网络(HWSN)的数据融合算法中,如何最小化冗余数据,减少数据传输总量,提高数据准确性,已经成为目前研究的核心问题。由于节点在连续周期内产生数据通常具有较高的时间相关性,基于预测的数据融合方案可以有效地降低冗余数据[2]。
文献[3]提出基于无偏灰色马尔科夫的预测模型,对具有时间相关性的井下温度数据进行预测,但其数据融合效率仍需进行改善;文献[4]针对温室环境建立利用历史样本建立极限学习机模型对温室数据进行预测,但极限学习机的参数随机初始化,将导致模型预测的不稳定。针对以上问题,本文提出一种基于狮群优化极限学习机的数据融合算法(lion swarm optimization-extreme learning machine for data aggregation,LSO-ELMDA),该算法在区域内进行双簇首选举时,综合考虑剩余能量、邻居节点密度以及与汇聚节点之间的距离对融合簇首进行选举,融合簇首选择距离最近且能量充足的节点作为传输簇首,分散簇间数据融合与簇内通信工作能耗;在汇聚节点处建立LSO-ELM预测模型,对历史样本序列进行预测,传输簇首处通过对比预测值与真实值,决定是否传输数据,以延长异构网络生命周期。
1 改进阈值的异构双簇首分簇机制
在异构无线传感器网络(HWSNs)中大部分的能量都被数据通信部分所消耗的情况下,需要一种既关注能量高效又能够缓解网络能量空洞问题的分簇技术,让数据传输效率得以提升。二级异构网络中根据能量级别将节点分为两种类型,普通节点和高级节点。普通节点的初始能量为Enorm=E0; 高级节点在网络中占比为m,初始能量为Eadvan=E0(1+α), 其中α为高级节点的初始能量高于普通节点的倍数;n为节点总数,网络的总能量为
n·E0(1-m)+n·m·E0(1+α)=nE0(1+αm)
(1)
本文针对两级能量异构模型设置双簇首机制,将数据融合与通信传输工作分散于簇内不同两个簇首节点,达到均衡网络能量消耗的效果。为了减轻节点负载,对SEP协议中簇首选择概率以及阈值公式进行改进,以选举融合簇首,然后分析簇内节点的能量信息与传输代价对传输簇首进行选举。融合簇头负责融合来自簇内各个节点所感知的物理量数据;传输簇头则负责将经过融合簇头融合后的数据发送给Sink节点。首先由剩余能量、地理位置和节点密度对阈值公式进行改进,综合确定融合簇首[5]。普通节点与高级节点当选融合簇首的概率分别为
(2)
(3)
对SEP中阈值公式进行改进,增加权重因子
(4)

改进后的阈值公式分别为
(5)
(6)
所有节点随机分配0到1之间的值,如果小于给定的阈值,则选定该节点成为融合簇首。在融合簇头选取完毕之后,各个融合簇头将根据收到报文消息中的信息,选择剩余能量值最大、距离自己最近的成员节点作为自己的传输簇头。
2 LSO-ELM算法
2.1 狮群算法
狮群算法(LSO)中一共包括3种角色:狮王、母狮和幼年狮[6]。狮群进行分工协作捕猎,不同角色的狮子进行不同方式的位置更新:母狮在捕猎过程中会相互配合,一旦发现最佳食物,该位置就会立刻被狮王占领,幼年狮子成年后会受到驱逐,被驱逐的狮子需要朝最佳位置靠近。狮群算法之中的多种更新方式使得其对于高维复杂函数问题求解都具有良好的全局收敛速度,最终输出狮王的位置,得到最优解。

(7)
(8)
(9)
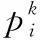
扰动因子αf、αc与最大活动步长step分别表示为
(10)
(11)
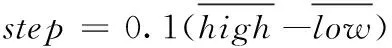
(12)
2.2 极限学习机
极限学习机(ELM)是一种特殊的前馈神经网络,同时也是一种具备单隐层的学习算法。相较于传统的前馈神经网络需要设置大量训练参数的繁杂,极限学习机只需要设定网络的结构,在隐含层节点的输入权重ωi和偏差bi随机初始化之后,不需要再做更新改变[7]。极限学习机具有设定参数少,不涉及迭代操作,泛化能力较强和预测精度高的优点,其网络结构如图1所示。
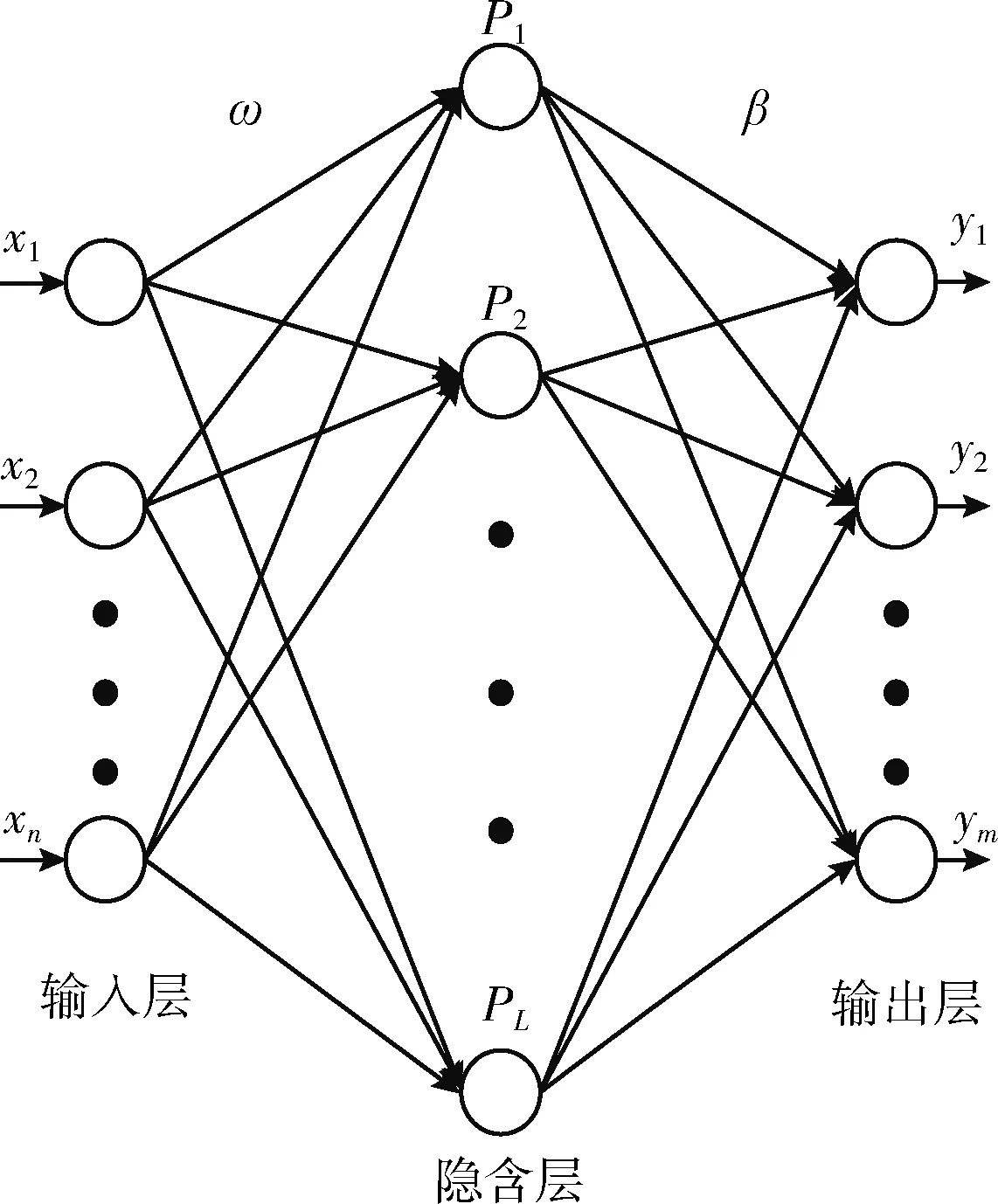
图1 极限学习机网络结构
假设样本集大小为N个,训练样本表示为(xi,ti),i=1,2,…,N; ELM模型的输出表达式为
(13)
(14)
(15)
其中,L为隐含层节点个数;ωi为第i个隐含层节点和输出层之间的输入权重;βi为第i个隐含层节点和输出层之间的输出权重;令β=[β1,β2,…,βL]L×mT,T=[t1,t2,…,tN]N×mT式(15)可以直接表示为:Hβ=Y, 其中H为隐含层的神经元输出阵;g(x) 为无限可微的激活函数。输出权值可以通过最小二乘法解来得到
β*=H+T
(16)
其中,H+为广义逆矩阵,H+=(HHT)-1HT。
2.3 LSO-ELM算法
虽然ELM相比传统前馈神经网络在概念上更为简单、计算效率更高,但在使用ELM的过程中隐藏层的输入权重ωi和偏差bi的随机生成会导致人为设置的输入权重和偏差次优,这使得系统输出具有不稳定和精度下降的缺陷。为了改善预测模型的性能,提高精度,引入狮群算法对极限学习机的输入权重与偏差参数进行迭代寻优。算法流程如下:
(1)确定输入权重和偏置的范围,随机初始化ELM输入权重与偏置的初值;设定狮子总数、成年狮比例、最大迭代次数。
(2)输入训练样本,选择RMSE作为适应度函数,保证在迭代过程中产生的参数能够使得极限学习机预测结果的均方根误差最小。
(3)以输入权重与偏置作为狮子的个体位置向量,维度为 (n+1)L, 其中n为输入层节点数、L为隐含层节点数。
(4)按照狮王、母狮和幼年狮的位置更新公式分别更新狮群的个体位置并重复5次,更新狮王的个体位置为最优位置,每间隔5次代数后重新排序确定各角色狮子的个体位置。
(5)计算适应度值,确定均方误差是否满足要求或迭代次数达到所设最大迭代次数,不满足则回到第(4)步;满足则进行第(6)步。
(6)对最优个体进行输出,获得最优的输入权重和偏差。
LSO-ELM算法流程如图2所示。
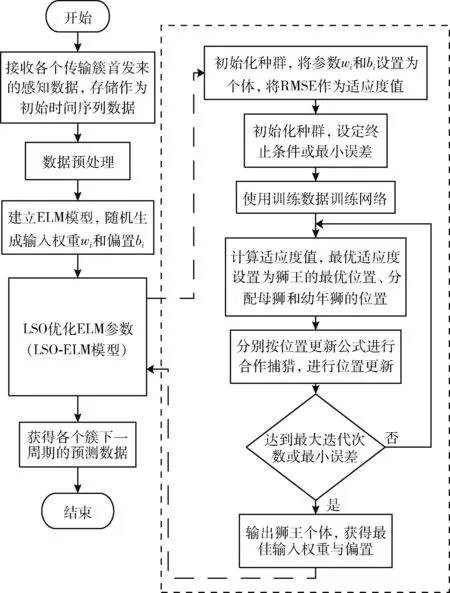
图2 LSO-ELM算法流程
3 基于狮群优化极限学习机的数据融合算法
3.1 数据预处理
由于传感器精度误差以及随机故障等因素影响,每个传感器节点采集到的数据序列中难以避免会出现带噪声或不完全的误差问题。这些被采集的测量数据中一旦出现由误差导致的异常数据,将对所设预测模型的精度产生不良影响,会导致预测结果误差变大,最终使数据融合算法的可靠性下降。考虑到多数实际应用如温室、农田的监控中节点所感知物理量(如种植园中温度、湿度、光照等)数据时间序列均呈现为周期性规律变化,具有二次多项式的趋势,为了消除异常数据、减少噪声及误差对最终融合结果的影响,汇聚节点在根据历史数据序列建立预测模型之前需要对历史数据进行预处理:首先采用拉依达准则去除异常数据,然后采用三次指数平滑对数据进行处理[8]。
使用拉依达准则对不合理数据进行判断并剔除:分别计算汇聚节点存储的历史序列样本数据的均值与标准差,满足式(17)的输入样本为合理数据
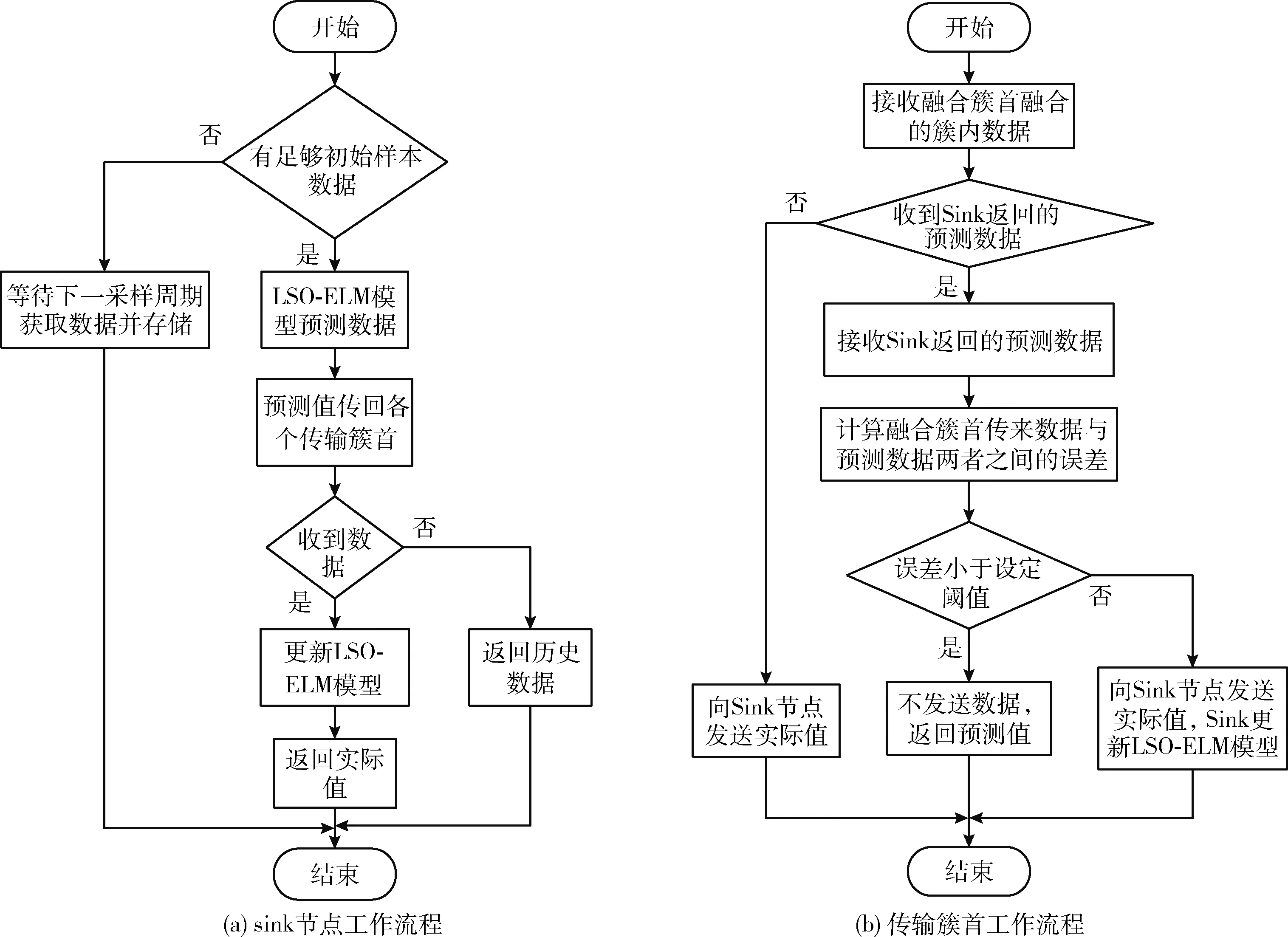
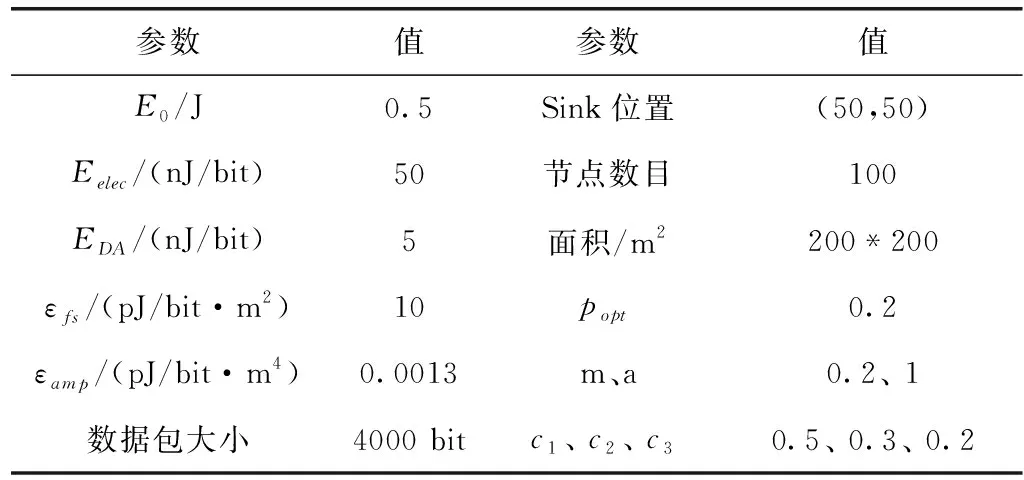
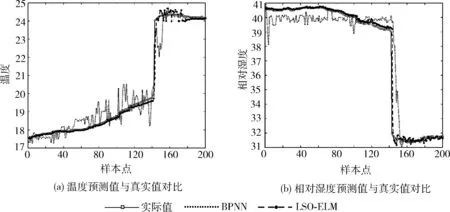
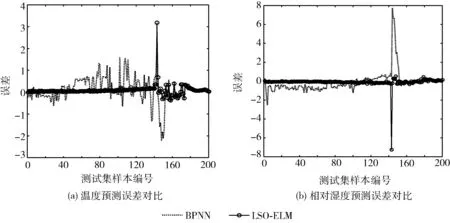
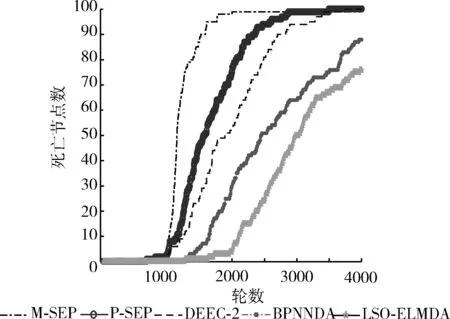
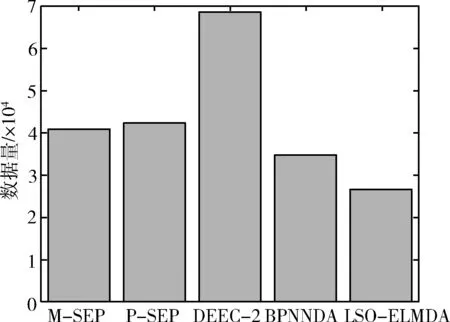
μ-3σ (17) 第二步引入三次指数平滑模型对输入数据进行处理,递推如下 (18) (19) (20) 在实际应用中,大量部署无线传感器节点会使得监控场地中节点密度过大,数据采集的过程中出现大量冗余信息,在无线传感器网络中节点的无线收发大约消耗占比九成的能量。为了降低无线收发部分的能量消耗,在测量比如温度、相对湿度这类时间相关性很大的无线传感器网络应用场景中可以针对历史时间序列数据建立基于预测的数据融合机制,避免冗余数据的传输,以达到降低传输数据包总数的目的,在保证数据准确性的同时,节省数据传输的能耗,延长网络的存活时间。所以,本文引入一种基于狮群优化极限学习机的数据融合算法(data aggregation algorithm based on extreme learning machine with lion swarm optimization,LSO-ELMDA),达到降低二级异构无线传感器网络通信成本、减少冗余数据传输的效果。 为了节约能量,在成簇阶段分别选举两枚功能不同的簇首:传输簇首与融合簇首。对监测区域的传感器节点进行双簇首分簇,成簇稳定之后,簇内的成员节点将感知的数据发送给融合簇首,而传输簇首则只负责与汇聚节点的通信,不进行物理量的感知,融合簇首对簇成员数据做出简单融合,由传输簇首将数据包传输至Sink节点,同时向Sink节点发送簇内成员节点信息表。Sink节点处将构建LSO-ELM预测模型,通过训练样本数据获得最佳输入权值和阈值参数,在对存储的历史数据进行不合理数据剔除与三次指数平滑预处理后,应用狮群算法进行参数调校的极限学习机对历史时间序列数据进行预测,由Sink节点将预测值返还给传输簇首节点。传输簇首通过判断预测数据与真实数据之间的误差大小是否超过设定阈值,决定是否需要将感知的新数据发送至Sink节点进行数据更新,在预测误差允许的范围内,能够减少数据的传输总量,保持数据精度,同时节约下重复发送冗余数据的能量。LSO-ELMDA算法将数据的融合和与汇聚节点之间的通信两个环节分开在两个簇首节点,达到延长寿命的效果。 算法流程如图3所示。 图3 Sink节点与传输簇首节点工作流程 本文实验在MATLAB平台运行,实验分为两个部分。第一部分利用已有数据集对LSO-ELM模型进行训练与测试,验证预测模型的可行性。考虑异构无线传感器网络在现实诸如温室大棚、农田等方面的应用,实验数据集选用安徽农业大学实习基地,位于安徽合肥的长丰国家级现代农业产业园之中的“红颜1983”草莓种植棚监测的数据集,在验证二级异构网络的情况下选择草莓种植棚中的实时温度数据与实时相对湿度数据,提取1000个连续采样点,以前800组数据作为训练集,后200组数据则用于测试集。首先对样本数据中异常数据进行删除、然后进行三次指数平滑以及归一化等预处理。为了使狮群算法优化极限学习机模型预测精度与收敛情况达到均衡的最佳状态,隐含层根据试凑法设置100个节点,激活函数选用sigmoid函数。 实验第二部分则针对二级异构无线传感网络进行LSO-ELMDA算法模拟仿真,实时的数据经过源源不断的周期采集,初始时间序列数据的个数设定为50,误差阈值设定为0.25个单位值。仿真实验LSO-ELMDA算法与异构M-SEP算法[9]、P-SEP算法[10]、DEEC-2算法[11]以及BPNNDA算法进行对比,在MATLAB平台上通过对比观察二级异构无线传感器网络的死亡节点数目、传递数据包总数目两方面情况,验证基于狮群优化极限学习机的数据融合算法在二级异构网络中的性能。仿真参数设定见表1。 表1 仿真参数设置 为了更好评价LSO-ELM模型的性能,将LSO-ELM模型与BPNN模型[12]在同一数据集训练下进行测试比较,温度与相对湿度的预测结果对比如图4所示。其中图4(a)显示“红颜1983”草莓种植园内的温度实际值、BPNN预测模型与LSO-ELM预测模型对比曲线。在狮群算法的参数调校下,LSO-ELM模型拟合结果逼近真实值,在前100个样本点预测曲线的情况基本与真实值重合,而BPNN模型的预测结果前160个样本点波动较大,且在样本点真实数值发生变化时,预测结果的跳动幅度相对LSO-ELM模型过大即预测误差更大,可以得出LSO-ELM模型总体温度的预测效果优于BPNN预测模型;图4(b)则表示为草莓种植园内相对湿度实际值、BPNN预测模型与LSO-ELM预测模型的对比曲线,其中LSO-ELM预测结果与实际相对湿度曲线吻合度较好,但BPNN模型精度较低,前150个样本点预测结果误差较大,预测结果无法满足高精度的数据收集场景,对比显示LSO-ELM模型相对湿度预测效果要优于BPNN模型。 图4 预测值与真实值对比 图5表示两种预测方案下的预测误差对比曲线。草莓种植园中温度预测与真实值的误差如图5(a)所示,相对湿度与真实值的误差对比如图5(b)所示,能够更为直观表示狮群算法进行参数调校的ELM预测模型的预测结果优于BPNN预测模型,可以看出LSO-ELM模型的预测结果误差曲线相对BPNN更接近零值,波动幅度较小。在第二部分仿真中,当误差超过所设定的阈值0.25个单位时,将使用传感器节点感知的真实值数据对预测时间序列样本进行重构、更新模型,重新计算下一周期预测值,避免对二级异构无线传感器网络中LSO-ELMDA算法的数据可靠性产生影响。 图5 预测误差对比 图6为5种针对二级异构设计的算法随着网络运行死亡节点数目的变化趋势对比情况。由于LSO-ELMDA算法在二级异构网络中采用双簇首机制,对阈值公式增加剩余能量、节点密度与传输距离权重因子进行改进,成簇之后融合簇首进行簇内数据初步融合,传输簇首只负责进行数据传输不进行物理量感知,而M-SEP、P-SEP、DEEC-2这3种算法均未设计节能的数据融合方案,未针对冗余数据进行处理,数据无线收发的能耗过大所以网络寿命相对较短;而BPNNDA算法中由于BPNN模型的预测误差较大,在设定阈值为0.25时大于误差阈值的样本点数目较LSO-ELM模型多,发送感知的真实值数据的次数比LSO-ELMDA算法多,通讯能耗大于后者,所以网络寿命相对LSO-ELMDA算法较短。通过对比,LSO-ELMDA算法由于传输簇首根据阈值判断每个簇数据包传输与否,在误差阈值设定为0.25的情况下能够有效地避免重复数据的传输,节省冗余数据被传输时所消耗的能量,能够大幅度提高能量效率,延长整个二级异构网络的寿命。 图6 死亡节点对比 图7反映5种二级异构无线传感器网络算法在同等条件下汇聚节点所接受数据包数量的对比情况。二级异构M-SEP算法、P-SEP算法与DEEC-2算法在数据传输中未针对冗余数据进行改进,汇聚节点接受数据包总数分别为4.09×104、4.22×104与6.87×104。在对比下可以直观地显示LSO-ELMDA算法所减少的传输冗余数据包数量;实验中BPNNDA算法由于预测精度较低,与设定误差阈值的对比显示预测误差较大,在与LSO-ELMDA算法同等条件时数据包需不断地向汇聚节点传输以对预测模型进行重构更新,接收的数据总量较LSO-ELMDA算法高,汇聚节点接受数据包总量约为3.47×104。通过对比显示,LSO-ELMDA算法能够大幅降低数据包的传送,汇聚节点接受数据包总量约为2.66×104,因为算法在汇聚节点处引入LSO-ELM预测模型后,当预测数据与感知数据的误差不超过阈值时,传输簇首将不发送数据包至汇聚节点,减少网络冗余数据包的传递,直接将预测值作为下一周期的数据使用,能够降低各簇与汇聚节点之间数据包传输总量,整体网络所传输的数据包总数目被削减。 图7 接收数据对比 数据融合算法是无线传感器网络中对多个传感器节点采集的数据去除信息冗余,提高采集效率,使数据更加简洁、准确的重要解决方案。针对草莓种植园场景下的二级异构无线传感器网络,考虑将HWSNs双簇首数据传输机制与基于预测的数据融合方案相结合,对融合簇首的选举阈值公式针对剩余能量、邻居节点密度和与汇聚节点的距离3个因素增加权重因子,同时设定传输簇首分担与汇聚节点之间通信的负载,并引入一种基于狮群优化极限学习机的数据融合算法,采用狮群算法对极限学习机进行参数寻优,提高预测模型的性能,在对历史时间序列数据进行剔除异常值以及三次指数平滑预处理之后,对数据进行预测,设定误差阈值使用预测值代替真实值,避免冗余数据的传输,达到降低通信能耗的目的。仿真结果表明:该算法能够保证数据可靠性,有效降低网络冗余数据的传输,使网络数据传输量大幅降低,降低节点传输功耗,并具有较强的容错能力。
3.2 数据融合算法流程
4 实验仿真
4.1 实验参数选择
4.2 仿真结果
5 结束语
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
测控技术(2018年10期)2018-11-25 09:35:26
自动化学报(2018年2期)2018-04-12 05:46:21
河北遥感(2017年2期)2017-08-07 14:49:00
制造技术与机床(2017年4期)2017-06-22 11:17:32
电信科学(2016年11期)2016-11-23 05:07:56
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
通信电源技术(2016年6期)2016-04-20 06:21:36
