
基于局部标记相关性的标记分布学习算法
2023-02-21 13:17田佳洪
计算机工程与设计 2023年2期
黄 俊,田佳洪
(1.安徽工业大学 计算机科学与技术学院,安徽 马鞍山 243032; 2.合肥综合性国家科学中心人工智能研究院,安徽 合肥 230088)
0 引 言
在机器学习[1]的研究中,标记多义性问题受到广泛关注。单标记学习(single-label learning,SLL)和多标记学习(multi-label learning,MLL)[2,3]是解决此问题比较成熟的两种机器学习范式。二者虽然能解决“示例可以被哪个/些标记描述”的问题,但是却不能解决“每个标记可以在多大程度上描述示例”的问题。为了解决这一问题,Geng等[4]提出了标记分布学习(label distribution learning,LDL)。LDL在描述每一个示例时,给描述此示例的每个标记一个描述度,准确地表示出每个标记在示例的描述程度上的差异,强化了标注信息的能力。现有的LDL专用方法大多仅关注学习模型的设计,将模型建立在原始高维特征空间上,并且从全局的角度探索和利用标记相关性。这样做只是简单的让所有特征被所有标记共享,忽略了实际分类学习任务中无关和冗余特征对算法性能的影响。并且,在现实世界的任务中,不同组示例间大多共享不同的标记相关性,很少有标记相关性能全局适用。因此本文提出一种基于局部标记相关性的标记分布学习算法(LDL-LLC),给LDL模型同时引入特征选择和局部标记相关性,试图挖掘出每组局部训练示例中的标记相关性,并学习每个标记的私有特征和所有标记的共享特征,最终达到提高LDL算法性能的目的。
1 相关知识介绍
1.1 标记分布学习
LDL的形式化表述如下。令X∈n×d为训练数据特征空间,D∈n×c为训练数据标记分布空间,LDL是通过建立的目标函数学得一个从X到D的映射,基于该映射可以预测未见示例的标记分布。xi∈X为第i个示例的特征向量,与其对应的为第i个示例的标记分布,其中为第j个标记对第i个示例的描述程度,且每个示例的描述程度总和
为了更好地标注出示例的标记分布,研究者们提出了许多LDL算法。目前,已有的LDL算法主要分为以下3类:①问题转换方法:将LDL问题转换为多个SLL问题,然后利用已有的SLL算法去处理这些SLL问题。这类算法包括PT-SVM和PT-Bayes算法[4]。②算法适应方法:直接修改已有SLL和MLL算法的一些约束条件,使其可以处理LDL问题。这类算法包括AA-kNN和AA-BP算法[4]。③专用方法:直接聚焦标记分布的预测问题,通常由输出模型、目标函数和优化求解3部分组成。这类算法的典型代表包括SA-IIS[4]和CPNN算法[5]。
1.2 特征选择
现有的LDL专用方法大多仅关注学习模型的设计,将模型直接建立在原始高维特征空间上,忽略了实际分类学习任务中无关和冗余特征的存在。当训练数据特征空间维度较高时,示例的标注结果就可能会受到无关和冗余特征的影响而变差。
LSE-LDL算法[6]和LDLSF算法[7]是两种将学习模型和特征选择结合起来的算法。LSE-LDL算法为减少噪音特征的干扰,将具有鉴别性的特征编码为潜在语义特征。同时,为了消除无关和冗余特征,对权重参数矩阵采用l2,1范数正则化约束来选择一些与潜在语义特征空间最相关的原始特征。LDLSF算法利用l1和l2,1范数对权重参数进行正则化约束,来学习每个标记的私有特征和所有标记的共享特征。
1.3 局部标记相关性
现有的LDL算法大多从全局角度利用标记间的相关性[9]。然而,在现实世界的任务中,不同的示例大多共享不同的标记相关性,并且标记间的相关性很少能全局适用。GD-LDL-SCL算法[10]将训练数据聚类为m组,并为每组示例设计一个局部相关向量作为每组数据的附加特征部分,在附加特征部分引入局部相关性信息。EDL-LRL算法[11]将训练数据聚类为m组,并利用低秩结构去约束每组示例的预测标记分布矩阵,来捕获局部标记相关性。LDL-LCLR算法[12]对聚类后的每组数据使用流形正则化器约束,来探索和利用局部标记相关性。
上述3种利用局部标记相关性的LDL算法,GD-LDL-SCL算法和EDL-LRL算法没有将标记输出和标记间的相关性紧密的联系起来。LDL-LCLR算法虽然将标记相关性约束在标记输出上,但聚类后的每组训练数据仍使用统一的全局标记相关性矩阵作为度量。
2 基于局部标记相关性的标记分布学习算法
本文提出的基于局部标记相关性的标记分布学习算法(LDL-LLC)属于解决LDL问题的专用方法。在第2节中,2.1将介绍LDL-LLC算法的输出模型,2.2介绍目标函数,2.3介绍优化求解。
2.1 输出模型
假设特征空间和标记分布空间是线性相关的,则输出模型表示为
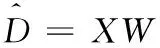
(1)
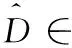
2.2 目标函数
LDL-LLC算法的目标函数由3部分组成:2.2.1损失函数、2.2.2共享和私有特征建模和2.2.3局部标记相关性建模。
2.2.1 损失函数
将损失函数定义为最小二乘损失函数形式,来度量预测标记分布和真实标记分布之间的差距。损失函数表示为
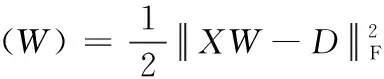
(2)
式中:D∈n×c是真实标记分布矩阵, 1c×1和1n×1为元素都是1的列向量, 0n×c∈n×c为元素都是0的矩阵。
2.2.2 共享和私有特征建模
对W采用l1范数正则化约束来增强W的稀疏性,以学习标记私有特征。同时,对W采用l2,1范数正则化约束来确保W的每一行是稀疏的,以学习所有标记的共享特征。为了避免两种范数正则化对变量W进行约束时,会相互干扰,影响了特征选择的效果。将W拆分为M和V两个部分,一部分采用l1范数正则化进行约束,另一部分采用l2,1范数正则化进行约束。最后,将M和V的求和约束为W。 共享和私有特征建模表示为

(3)
式中:M∈d×c为选择每个标记私有特征的权重参数矩阵,V∈d×c为选择所有标记共享特征的权重参数矩阵。
2.2.3 局部标记相关性建模
现实世界的任务中,不同的示例大多共享不同的标记相关性,并且很少有标记相关性是全局适用的。假设训练数据可以被划分为m组 {G(1),G(2),…,G(m)}。 为了便于实现,使用k-means作为聚类方法,将训练数据聚为m组。同一组示例共享相同的标记相关性,并引入局部流形正则化器将每组示例间的标记相关性直接约束在标记输出上[13]。局部标记相关性建模表示为
(4)
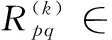

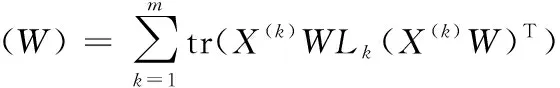
(5)
式中:Lk=P(k)-R(k)∈c×c为第k组训练数据的拉普拉斯矩阵,其中,R(k)∈c×c为第k组训练数据的标记相关性矩阵,P(k)∈c×c为对角矩阵,对角线元素是R(k)×1c×1, 1nk×1∈nk×1为元素都是1的列向量, 0nk×c∈nk×c为元素都是0的矩阵。
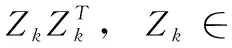
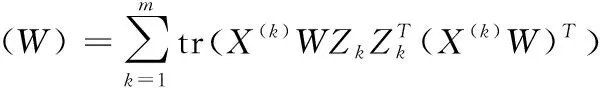
(6)
2.2.4 目标函数总式
LDL-LLC算法的目标函数由损失函数L(W)、 共享和私有特征建模F(W) 和局部标记相关性建模R(W) 组成。表示如下
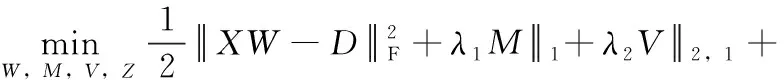
(7)
式中:λ1、λ2和λ3是平衡参数。
LDL-LLC算法的目标函数总式共有4项。第一项是损失函数,用来测量预测的标记分布和真实标记分布之间的距离;第二项用来学习每个标记的私有特征;第三项用来学习所有标记的共享特征;最后一项探索和利用了局部标记相关性。
2.3 优化求解
目标函数式(7)有多个变量,采用交替迭代的方法求解。每次迭代只更新一个变量,其它变量固定为它们每次迭代后的最新值。
2.3.1 更新变量Z
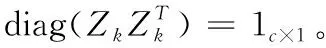
将将变量W,M,V固定,式(7)可简化为m个优化问题,其中第k个问题表示为
(8)
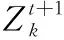
利用MANOPT工具箱[13]对式(8)在欧几里得空间上用线性搜索实现梯度下降求解,来对Zk进行更新。式(8)的梯度表示如下
(9)
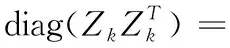
(10)

2.3.2 更新变量W
将变量M,V,Z固定,通过增广拉格朗日乘子法[7]构造出含有变量W的增广拉格朗日函数,使得目标函数总式中含有变量W的约束条件转换为无约束的形式。对于非负约束XW≥0n×c, 使用投影算子将XW中不满足条件的元素转换为0。转换形式后,求解问题表示为
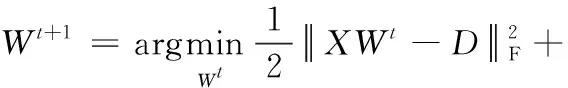
(11)
式中: 〈·,·〉 为两个矩阵的点积, Γ1∈d×c和Γ2∈n×1为拉格朗日乘子,ρ>0为正项的惩罚标量。
使用有限内存拟牛顿法(L-BFGS)[14]对式(11)进行求解。L-BFGS的计算主要与一阶梯度有关,式(11)一阶梯度表示如下
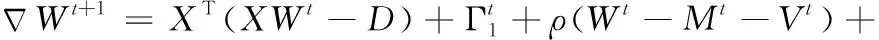
(12)
2.3.3 更新变量M
将变量W,V,Z固定,通过增广拉格朗日乘子法构造出含有变量M的增广拉格朗日函数,使得目标函数总式中含有变量M的约束条件转换为无约束的形式。求解问题表示为
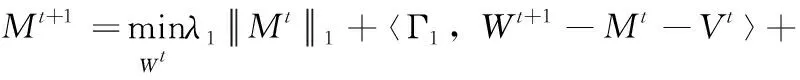
(13)
式(13)可以改写为
(14)
改写后的式(14)有一个闭合解,可以直接进行求解。
2.3.4 更新变量V
将变量W,M,Z固定,通过增广拉格朗日乘子法构造出含有变量V的增广拉格朗日函数,使得目标函数总式中含有变量V的约束条件转换为无约束的形式。求解问题表示为
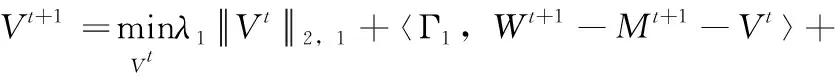
(15)
式(15)可以改写为
(16)
改写后的式(16)有一个闭合解,可以直接进行求解。
2.3.5 更新乘子Γ1和Γ2
拉格朗日乘子Γ1和Γ2可以直接更新,更新公式表述如下
(17)
(18)
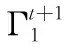
本文提出的LDL-LLC算法的总体过程见表1。

表1 LDL-LLC算法
3 实 验
在7个LDL真实数据集上,使用6种评价指标将本文提出的LDL-LLC算法与6种现有LDL算法进行比较。
3.1 数据集
采用7个LDL真实数据集:S-JAFFE、S-BU_3DFE、Emotion6、M2B、SCUT-FBP、Natural Scene和Movie。其中,S-JAFFE、S-BU_3DFE和Emotion6是面部表情识别数据集,M2B和SCUT-FBP是面部美容评估数据集,Natural Scene是自然场景识别数据集,Movie是电影评级数据集。7个LDL真实数据集详细信息见表2。
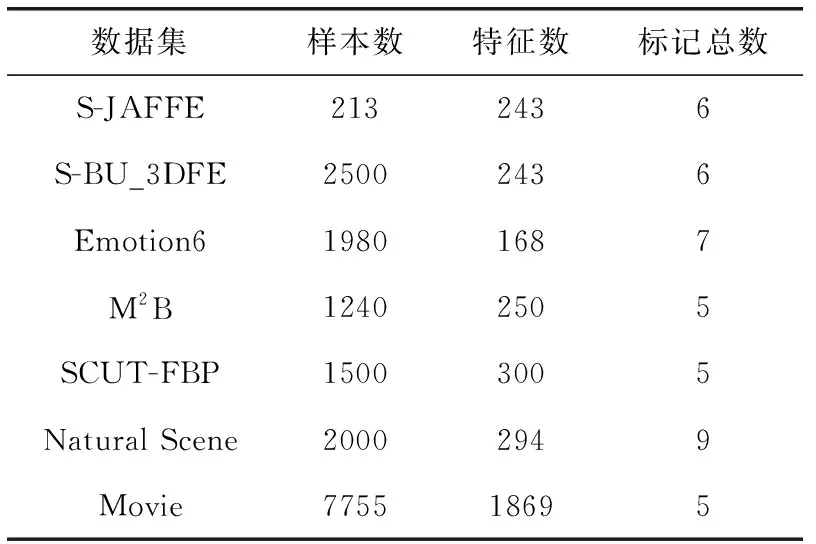
表2 实验选用的标记分布数据集描述
前两个数据集S-JAFFE和S-BU_3DFE是对两种广泛使用的面部表情图像数据库JAFFE和BU_3DFE的扩展。S-JAFFE包含213张特征维度为243的表情灰度图。60个人根据6种基本情绪标记(即:快乐、悲伤、惊讶、恐惧、愤怒和厌恶),用5个级别的分数对每张图像打分。每个情绪标记的平均得分作为其描述程度来生成一个标记分布。同样,SBU 3DFE包含2500张表情灰度图,每一张图像由23个人以相同的方式打分。
第三个数据集Emotion6是包含1980张人脸图像,采用梯度直方图法同时提取人脸图像的特征,并采用PCA技术将其特征维度降到168维[15]。Emotions6数据集中有7种情绪标记,除了S-JAFFE和S-BU_3DFE数据集中的6种基本情绪标记外,进一步引入中立情绪标记,用对7种情绪的投票来生成标记分布。
第四个数据集M2B和第五个数据集SCUT-FBP分别包含1240张像素大小为128×128的面部图像和1500张像素大小为350×350的面部图像,每次随机显示一张面部图像,评估者被要求从5个不同层次评估其面部美丽的吸引力,最后,由每个层次吸引力水平的百分比生成每张面部图像的标记分布。
第六个数据集Natural Scene包含2000幅自然场景图像,每一张图像有9个场景标记(即:植物、天空、云、雪、建筑、沙漠、山、水和太阳)。10位人工标注员根据每张图像与9个场景标记的相关度进行独立决策降序排序,最后,通过非线性规划过程转化为标记分布。
第七个数据集Movie包含7755部电影,每一部电影包含从1星到5星的5个电影评级,相当于5个标记。将每部电影各评级上评分人数占总评分人数的比值作为各标记上的描述程度,来生成每部电影示例的标记分布。
3.2 评价指标
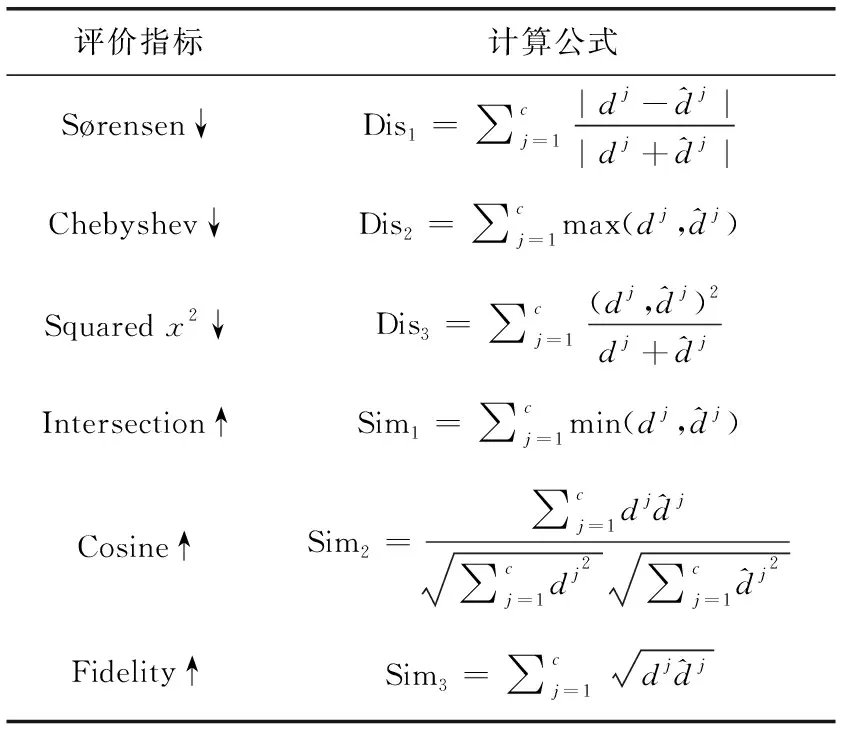
表3 标记分布学习的评价指标
3.3 实验设置
为了验证本文提出的LDL-LLC算法的性能,将其与6种常用的LDL算法进行对比,分别是:问题转换方法PT-Bayes,算法适应方法AA-BP,专用方法SA-IIS、CPNN、LDL-LCLR和LDLSF,6种对比算法的参数设置和搜索范围均与原文一致。其中,LDL-LCLR算法的参数λ1、λ2、λ3、λ4、k和ρ分别被设为10-4、10-3、10-3、4和1。LDLSF算法的参数λ1、λ2和λ3从 {10-6,10-5,…,10-1} 中搜索选取,正项的惩罚标量ρ设置为10-3。
本文提出的LDL-LLC算法的参数λ1, 它的作用是约束l1范数正则化对权重参数的影响,λ1取值越大,意味着模型会更注重拟合l1范数正则化学习每个标记特有特征的特性。为了防止过拟合,λ1从 {10-6,10-5,…,10-1} 中搜索选取。同理,约束LDL-LLC的参数λ2和λ3也从 {10-6,10-5,…,10-1} 中搜索选取,令使用最小二乘法度量真实标记分布和预测标记分布间距离的损失函数占据主导地位。参数m是k-means方法对训练数据进行聚类后的组数,m从 {1,2,3,4,…,9} 中搜索选取。正项的惩罚标量ρ设置为10-3,变量Z的列数u设置为3。W初始化为单位矩阵,M和V都初始化为对角矩阵,所有对角元素都为0.5,其它变量初始化为0。
3.4 实验结果与分析
在每个数据集上,都进行10次5折交叉验证。具体来说,就是将数据集随机划分为10份,选取其中的8份作为训练集,剩下的2份作为测试集,重复10次该过程。表4和表5分别展示了Chebyshev和Cosine评价指标上本文提出的LDL-LLC算法和6种对比算法在7个LDL真实数据集上的实验结果,并对表中每一行的最优数据进行加粗。
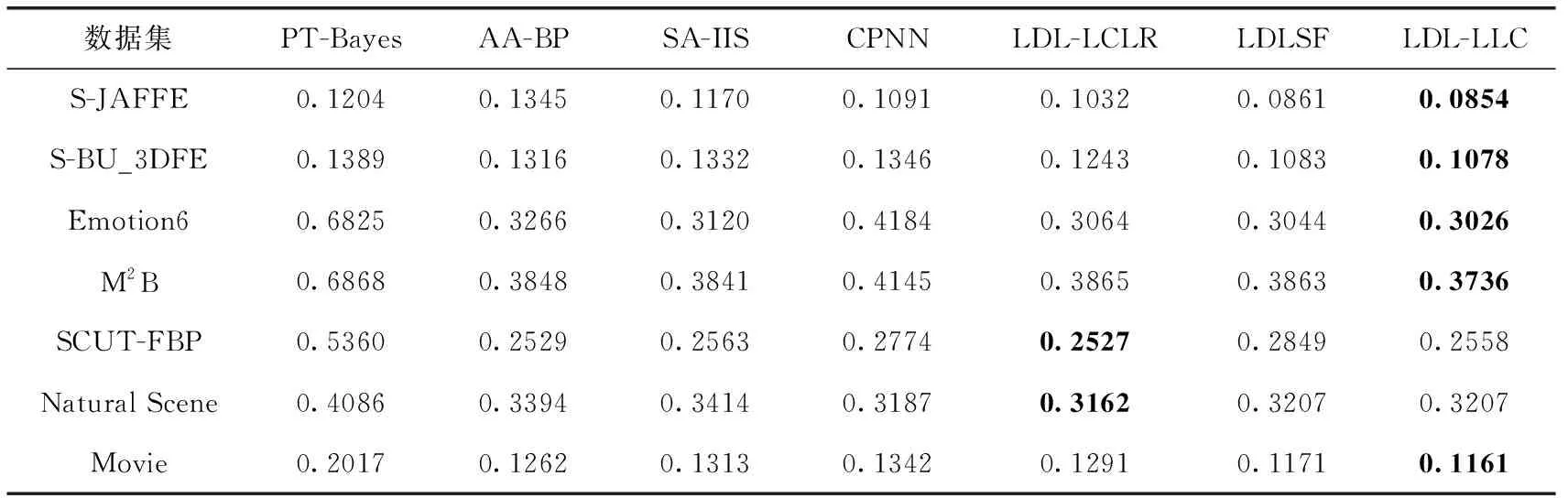
表4 标记分布方法Chebyshev距离比较
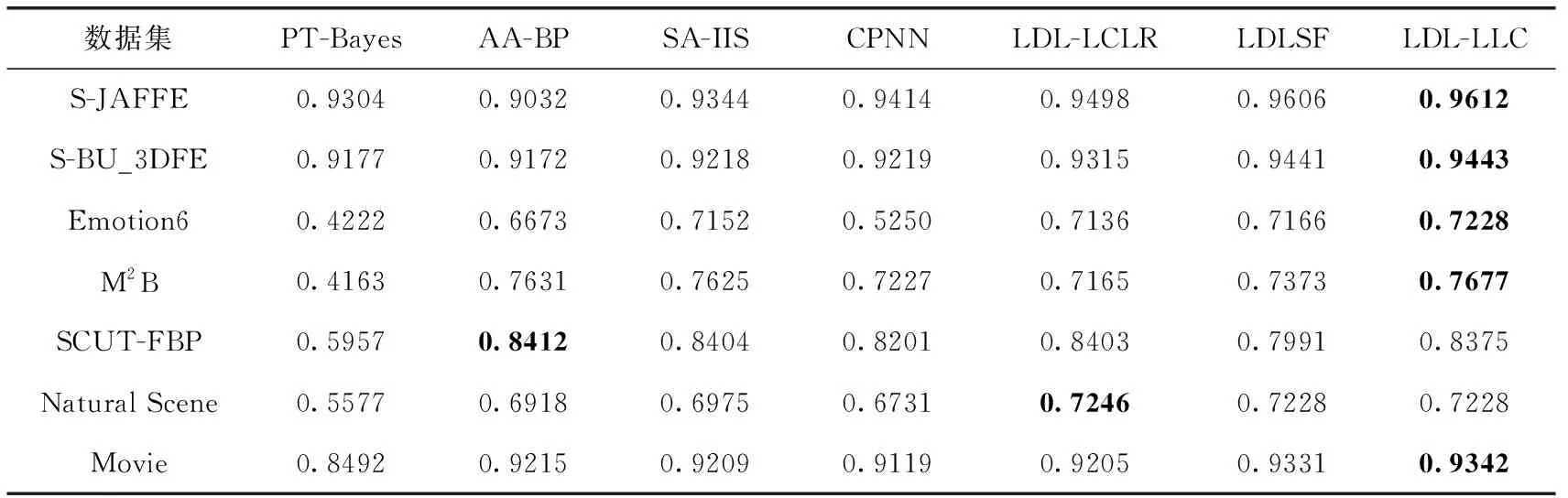
表5 标记分布方法Cosine相似度比较
为了更直观分析7种算法在性能的差异,表6展示了每种评价指标的Friedman统计量FF和相应的临界值,每种评价指标在α=0.05显著水平下的Friedman检验都拒绝“全部对比的算法具有相等的预测性能”这一原假设。
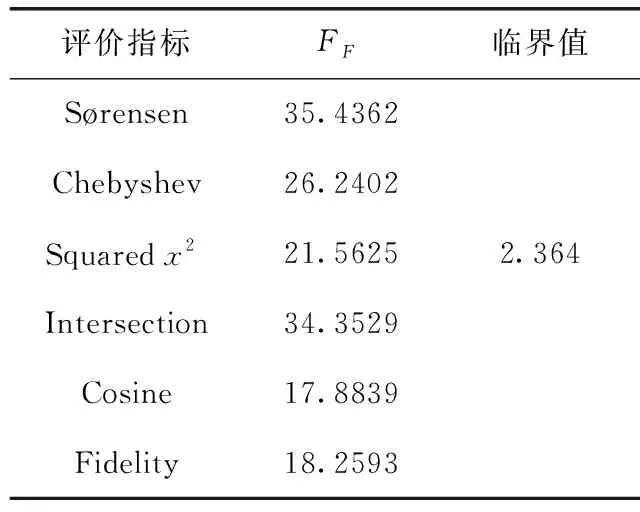
表6 Friedman检验统计值和临界值
图1绘制了每种评价指标上显著性水平α=0.05的临界差分图。在每张临界差分图中,每个算法的位置表示它在对应评价指标上性能的平均排名,位置靠右的算法性能越好。如果两种算法在所有数据集上的平均排名相差至少一个临界值域(CD=3.4014),则两种算法之间的性能就会显著不同。反之,两种算法之间性能差异不显著,使用粗线连接。由图1可得到如下结论:
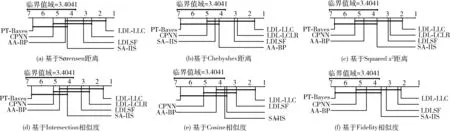
图1 每个评价指标下所有算法的临界差分
(1)7种LDL算法总排名为:LDL-LLC>LDLSF>LDL-LCLR>SA-IIS>AA-BP>CPNN>PT-Bayes。本文提出的LDL-LLC算法始终处于临界差分图的最右端,表明了LDL-LLC算法性能的优越性。
(2)LDL-LLC、LDLSF、LDL-LCLR、SA-IIS算法的平均排名优于AA-BP和PT-Bayes算法,原因在于算法适应方法AA-BP是直接修改BP算法的一些约束条件来扩展BP算法,用神经网络的输出作为标记的描述程度。问题转换方法PT-Bayes将处理单标记学习问题的贝叶斯算法计算出每个标记上的后验概率作为对应标记的描述程度。AA-BP和PT-Bayes算法通过改造现有的BP算法和贝叶斯算法后,虽然能处理LDL问题,但是效果不如直接聚焦标记分布的预测问题设计的专用方法:LDL-LLC、LDLSF、LDL-LCLR和SA-IIS算法。
(3)LDL-LLC、LDLSF、LDL-LCLR算法的平均排名优于CPNN和SA-IIS算法,原因在于LDL-LLC、LDLSF、LDL-LCLR算法对标记相关性进行了挖掘和利用,借助这些隐藏在标记空间中的额外信息,来提升LDL算法的性能。
(4)LDL-LLC算法的平均排名优于LDLSF和LDL-LCLR算法,原因在于:①LDLSF算法挖掘和利用的是全局标记相关性,但是在现实世界的任务中,不同的示例大多共享不同的标记相关性,很少有标记相关性是全局适用的。并且LDLSF算法在计算标记间的相关性时,直接计算训练标记矩阵各列之间的皮尔逊相关系数,用计算出的系数来衡量两两标记间的相关性。但是一些标记在训练数据中可能只有很少的正面示例,因此由训练标记矩阵求出的标记相关性可能会不可靠。②LDL-LCLR算法虽然将训练数据进行了分组,在每组数据上挖掘和利用标记间的相关性。但是LDL-LCLR算法用全局标记相关性来度量每组训练数据标记间的相关性。并且LDL-LCLR算法的模型建立在原始高维特征空间上,忽略了实际分类学习任务中存在无关和冗余特征的事实。③本文提出的LDL-LLC算法通过引入局部流形正则化器,不去预先指定任何标记相关性矩阵来生成流形正则化器中的拉普拉斯矩阵,而是将每组训练数据的拉普拉斯矩阵当成变量去迭代更新,更全面的挖掘和利用了局部标记相关性。同时,利用l1和l2,1范数对权重参数进行正则化约束,来学习每个标记的私有特征和所有标记的共享特征,减少了无关和冗余特征干扰。
4 结束语
本文提出一种基于局部标记相关性的标记分布学习算法(LDL-LLC),该算法将特征选择和局部标记相关性结合起来。通过引入局部流形正则化器,不去预先指定任何标记相关性矩阵来生成流形正则化器中的拉普拉斯矩阵,而是将拉普拉斯矩阵当成变量去迭代更新,探索和利用局部标记相关性。同时,利用l1和l2,1范数对权重参数矩阵进行正则化约束,来学习每个标记的私有特征和所有标记的共享特征,以减少无关和冗余特征干扰。最后,用求得的权重参数矩阵去预测未见示例的标记分布。在多个真实标记分布数据集上的对比实验结果表明本文提出的算法是有效且可行的。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
怀化学院学报(2021年5期)2021-12-01
数学物理学报(2021年2期)2021-06-09
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
山东冶金(2019年1期)2019-03-30
数学年刊A辑(中文版)(2019年1期)2019-01-31
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
数学杂志(2018年5期)2018-09-19
发明与创新(2016年38期)2016-08-22
