
基于全局感知和局部细化的夜间显著目标检测
2023-02-21 13:17汪虹余季思想
计算机工程与设计 2023年2期
张 彧,汪虹余,季思想,穆 楠
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言
在具有挑战性的夜间图像中,深度卷积神经网络方法主要存在下列挑战:①夜间图像视觉特征模糊且易受噪声干扰;②重复池化操作导致对象语义和图像结构信息的大量丢失;③深度网络只能分辨图像像素的二元标签,对于边缘特征不清晰的夜间图像,训练后的网络很难学习到显著目标的边界知识。
为了解决这些难题,本文提出了一种用于夜间图像中显著目标检测[1-4]的全卷积深度神经网络,主要加入了两个模块:全局语义感知模块(global semantic awareness,GSA)和局部结构细化模块(local structure refinement,LSR)。首先,模型对多层次特征中的局部信息与全局信息进行编码以充分利用其包含的结构信息与语义信息。然后,对不同卷积层的特征进行级联压缩从而获取具有全局语义信息的多层次全局特征图。并且将不同卷积层的多尺度局部特征、具有局部差异性的对比度特征和解卷积层的上采样特征进行合并以获取具有结构信息的局部特征从而增强局部对比度。最后,将全局与局部特征通过softmax函数进行融合来准确计算出像素级显著性。
本研究的主要贡献可以归纳为:①构建了级联局部结构信息和全局语义信息的深度全卷积编码器-解码器网络来学习夜间图像的显著性特征;②引入全局语义感知模块和局部结构细化模块分别用于完善显著目标的位置信息和保持目标边界细节的完整性;③致力于夜间图像的显著目标检测并取得了优越性能。
1 相关工作
目前,主流的显著目标检测方法主要有两大类:基于传统手工特征的方法和基于深度学习特征的方法。
传统的方法主要基于人工提取特征来检测显著目标,大多数的传统模型[5-8]主要基于人类直观感觉和启发式先验[5],如色度比较[6]、边界背景[7]和中心先验[8]。这些计算方法效率低下,很难捕获到目标的高级和全局语义知识,且容易破坏潜在的特征结构。因此,传统的检测方法很难得在具有挑战性的夜间图像上取得令人满意的显著性检测结果。
基于深度学习的显著目标检测不再需要人工提取特征,其检测性能也大幅度提高。近年来,研究人员在不同的网络架构下,对显著性检测进行了大量的研究,致力于提高显著目标检测的性能。Hou等[9]为了使每一层的多尺度特征映射更加丰富,在HED(holistically-nested edge detection)体系结构中引入了具有短连接的跳跃结构,用以获得具有清晰边界的显著目标。Liu等[10]将卷积神经网络进行池操作,在U型结构的最顶层放入金字塔池块层来获取丰富的语义信息。Chen等[11]采用残差学习来训练侧输出残差特征以细化显著性,并进一步提出了反向注意机制,用自顶向下的方式指导这种侧输出的残差学习。Wang等[12]使用新颖的金字塔池模块和用于显著性检测的多阶段细化机制来增强前馈神经网络。Pang等[13]提出了用聚合交互模块来整合相邻层次的特征,在每个解码器单元中嵌入了自交互模块以此削弱了二元交叉熵损失带来的影响。Liu等[14]提出了一种像素化的上下文注意网络,选择局部或全局的上下文信息来检测显著目标。Zhang等[15]引入多路径递归操作,通过多路径循环连接,将来自顶层卷积层的全局语义信息传递到较浅的层,以此来增强提出的渐进式注意力驱动网络PAGR(progressive attention guided recurrent)。尽管基于深度学习的显著性模型已经能在各类复杂场景中也取得令人满意的效果,然而,由于具有低对比度、信噪比偏低等因素而导致夜间图像中缺乏明确的特征对显著性信息进行编码,这些已有深度模型在合并网络中的多个高级特征时,往往会丢失一些显著物体的结构细节和边界部分,同时还会引入大量非显著目标信息和背景内容。受深度模型的启发,本研究主要采取自顶向下的方式,提出全局语义感知模块充分利用语义信息对显著区域进行准确定位和局部结构细化模块进一步细化显著区域边界与内部结构来引导渐进式的显著性学习,从而使夜间图像中的显著目标检测结果更加准确高亮。
2 显著目标检测模型
本研究提出了基于局部与全局显著性信息的深度全卷积网络框架用于夜间图像的像素级显著性预测。在网络中引入全局语义感知模块(GSA)准确定位显著目标位置,引入局部结构细化模块(LSR)细化显著目标边界细节和内部结构信息。
2.1 网络结构
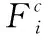
图1 夜间图像显著目标检测网络结构
基于全局卷积网络[16]的启发,本研究提出了全局语义感知模块来实现图像特征与卷积块之间的密集连接,从而使金字塔特征包含更加丰富的神经元信息。此外,本研究还利用了局部结构细化模块来连接每个卷积块以保存更多的细节信息。
在将语义感知知识分配给小区域之前,本研究主要通过收集高级别卷积特征来获取全局上下文信息。其中,FG为全局特征图,Conv()代表卷积层,公式如下
FG=Conv(F5)
(1)
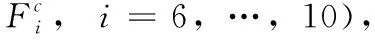
(2)
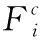
(3)
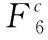
(4)
2.2 全局语义感知模块
为了使网络能够处理各种类型的转换,全局语义感知模块通过将分类器和特征图紧密连接来提升显著模型的分割能力。同时,由于全局语义感知模块的较大内核可以获取较大感受野而有利于编码更多的空间信息,从而使显著目标的定位更准确提高了显著目标定位的精度。
图1右上角方框为本文提出的全局语义感知模块,其包含左右两个分支,在左分支中应用了一个7×1和一个1×7的卷积块Conv,在右分支中应用了一个1×7和一个7×1的卷积块Conv,然后将两个分支通过密集连接来合并,以在具有更少的参数量和计算量的同时达到和一个7×7卷积核相同的感受野,但也能获取充分的全局信息。GSA获得的大感受野使得特征图能编码更多的空间信息从而充分利用全局的线索以更准确定位显著目标的位置。
2.3 局部结构细化模块
为了进一步保留边界信息并增强显著目标的内部结构与细节以使显著目标检测结果更加精细化,本研究设计了结构细化模块来优化目标边界。
图1左下角方框为本文提出的局部结构细化模块,其被建模为残差结构[17],其中一个分支直接连接输入和输出层,另一个分支由两个3×3核大小的卷积块Conv的残差网组成。两个分支连接后,能够避免在卷积过程中造成的信息损失而有利于学习显著目标的细节信息,从而提高边界像素的显著分数精确度。其输出与输入的维数相同。
2.4 显著目标检测
最终的显著图由全局特征图FG和局部特征图FL结合而成。令SM表示显著图,GT表示基准显著图,通过softmax函数来预测特征图中像素p属于显著还是非显著的概率P,公式如下
(5)
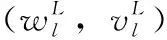
(6)
其中,调谐LCE的正加权常数为αr,LB的正加权常数为βr,区域Ωr中的像素p在真实显著图和生成显著图之间的交叉熵损失为LCE,N代表像素值的个数,公式如下
(7)
(8)
本研究的监督模型结合了LCE和LB的效果。由于两个损失函数共同训练了本研究的模型,因此,可以优化语义感知和结构细节的参数。
3 实验结果
本研究在6个显著目标检测数据集上进行了大量的实验,以评估本模型与9个先进的显著性模型的性能对比。
3.1 实验装置
3.1.1 评估数据集
本研究主要在5个公共数据集和1个夜间图像数据集上测试所提出的模型,包含:①MSRA-B数据集[18],该数据集包含5000张图像,大部分图像只有一个显著的物体。②DUT-OMRON数据集[19],包含5168张背景复杂的图像。③PASCAL-S数据集[20],其中有850张具有挑战性的自然图像。④HKU-IS数据集[21],它提供了4447张边界重叠、对比度较低并包含多个显著物体的图像。⑤DUTS数据集[22],其训练集包含了10 553张图像,测试集包含5019张图像,且这两组均为复杂场景的图像。⑥夜间图像(NI)数据集,该数据集是由本研究提出,包含了1000张图像,这些图像的采集工作均是在光照不足的夜间时段进行的,且图像的分辨率为500×667。
3.1.2 评估模型
本研究主要将所提出的显著目标检测模型9种基于深度学习特征的显著模型进行了比较,包括:非局部深度特征(NLDF)模型[23]、学习促进显著性(LPS)模型[24]、轮廓到显著性(C2S)模型[25]、反向注意显著性(RAS)模型[11]、叠加交叉细化(SCRN)模型[26]、预测细化(BAS)模型[27]、分割突出物体区域(F3)模型[28]、基于边缘的多尺度U型(MEUN)模型[29]和多感知增强(MPI)模型[30]。
3.1.3 评估标准
为了评估所提出的模型与其它模型的性能,本研究采用了7个评价指标,包括:
(1)真阳性率和假阳性率(TPRs-FPRs)曲线。 TPR=TP/(TP+FN) 表示正确检测到的显著像素与真实显著像素的比值,FPR=FP/(FP+TN)表示错误检测到的显著像素与所有非显著像素的比值。其中,TP(真阳性)和FN(假阴性)分别是正确检测到的显著像素和错误检测到的非显著像素的集合。FP(假阳性)和TN(真阴性)分别为错误检测到的显著目标像素和正确检测到的非显著像素的集合。
(2)精度-召回率(PR)曲线。 P=TP/(TP+FP) 定义为正确检测到的显著像素与所有检测到的显著像素之比, R=TP/(TP+FN) 与TPR相同,衡量检测到的显著像素的全面性。
(3)F-measure曲线。 F=(1+λ)P·R/(λ·P+R) 是利用P和R的加权谐波平均值计算的,其中λ的值设置为0.3用来强调P的效果。F-measure曲线是通过比较真实显著图和计算得到的二值显著性图来计算,其中,二值显著性图是通过改变阈值确定一个像素是否属于显著目标计算得到的。
(4)曲线下面积(AUC)得分,其被定义为TPRs-FPRs曲线下面积的百分比,能够直观地表明显著性图对真实显著目标的预测程度。
(5)平均绝对误差(MAE)得分,计算方法为求取所得的显著性图SM与真实显著图GT之间的平均绝对误差: MAE=mean(|SM-GT|)。 MAE值越小,说明SM和GT之间的相似度越高。
(6)加权F-measure(WF)得分[31],通过引入一个加权P来衡量精确性和一个加权R来衡量完整性: WF=[(1+β2)WP·WR]/β2·WP+WR。 WP和WR分别代表预测精度和召回精度。
(7)重叠率(OR)得分,其定义为二值显著性图SBM与基准显著图GT之间的重叠显著像素的比值,通过OR=|SBM∩GT|/|SBM∪GT| 来计算。OR得分考虑显著像素的完整性和非显著像素的正确性。
3.2 实验分析
图2为本研究提出的模型(带正方形标注图线所示)在6个数据集上与最近3年内显著性模型的客观性能比较(TPRs-FPRs曲线横坐标代表假阳性率,纵坐标代表真阳性率;PR曲线横坐标代表召回率,纵坐标代表精准率;F-measure曲线横坐标代表完整性,纵坐标代表精准性),表1为在6个数据集上的各显著性模型的定量结果对比(排名前三的结果分别表示为单下划线,点下划线和波浪线。向上箭头↑表示值越大,性能越好。向下箭头↓表示值越小,性能越好)。本研究基于7个指标在6个数据集上比较了本研究所提出的显著性模型与上述9个先进模型的性能。定量比较结果如图2和表1所示,结果表明所提出的模型在大多数情况下都达到了排名前三的性能,因为本研究所得到的显著性图更接近于真实显著图。具体而言,模型的局部-全局策略,能够有效提升目标与背景之间的对比度。GSA和LSR也进一步完善了显著区域的结构和边界。因此,本研究的模型对于夜间图像中的显著目标检测任务是有效的。
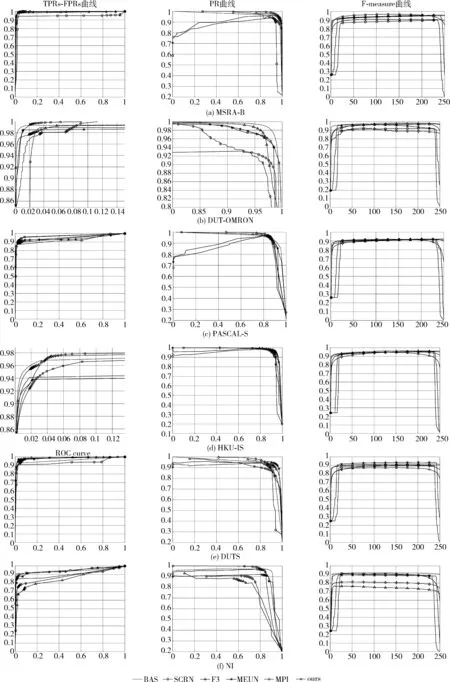
图2 在6个数据集上本研究提出的模型(带正方形标注图线所示)与最近3年内显著性模型的客观性能比较
在MSRA-B数据集上性能对比如图2(a)和表1(a)所示,大多数图像具有单一对象和简单背景,所提出的模型在TPRs-FPRs曲线、PR曲线、F-measure曲线、AUC得分、WF得分和OR得分上均获得了最优性能。同时,F3模型在AUC和WF得分上表现仅次于所提出的模型。
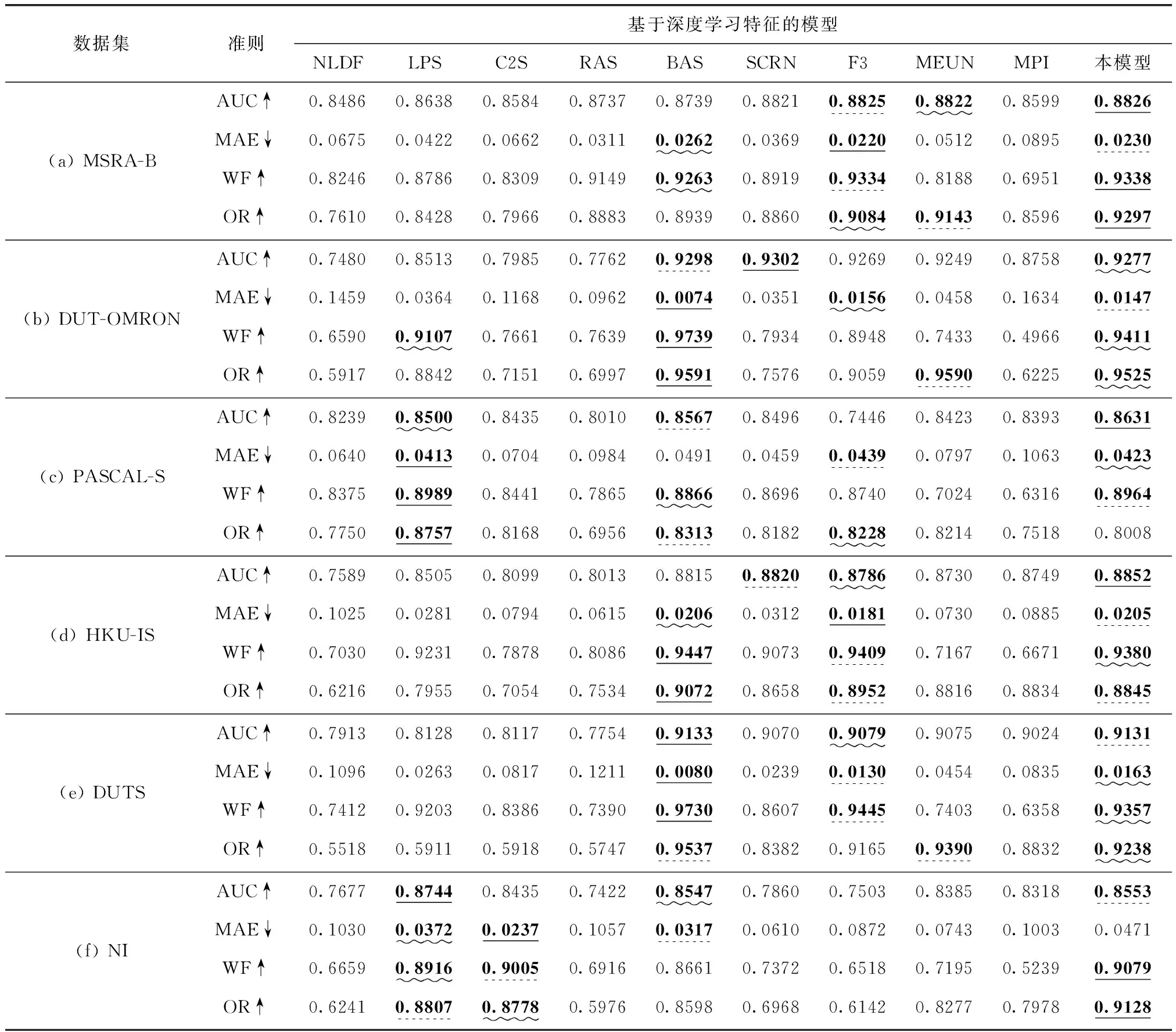
表1 在6个数据集上的各显著性模型的定量结果对比
在DUT-OMRON数据集上性能对比如图2(b)和表1(b)所示,虽然图像比较复杂和多样,但所提出的模型在TPRs-FPRs曲线上获得了最优性能。本研究所提出的模型的所有性能测试指标得分除MAE排第二外,其余指标均排第三,BAS模型在DUT-OMRON数据集上除AUC上排第二外,其余排名均为第一。尽管BAS性能最优,但其训练集所包含样本数是本研究的2倍,主要通过扩大训练数据规模来提高模型鲁棒性。
在PASCAL-S数据集上性能对比如图2(c)和表1(c)所示,本研究提出的模型与其它模型相比取得了具有竞争性的性能,在TPRs-FPRs曲线上依然优于其它模型,能够在AUC得分上表现最优。
在HKU-IS数据集上性能对比如图2(d)以及表1(d)所示,由于大部分图像都有相对复杂的背景,本研究所提出的模型在PR曲线、AUC指标上表现最好。在MAE得分上排名第二,其WF和OR得分比取得最佳结果的BAS模型略微逊色。
在DUTS数据集上性能对比如图2(e)以及表1(e)所示,图像复杂多样,本研究所提出的模型在TPRs-FPRs曲线和OR得分上均为第一。
在NI数据集上性能对比如图2(f)和表1(f)所示,本研究所提出的模型在TPRs-FPRs曲线、PR曲线、WF分数和OR分数上都取得了最好的结果。在F-measure曲线上,表现仅次于最优模型BAS,在AUC得分方面,本研究的模型取得了排名第二的分数,与LPS模型的最佳结果只有0.0191的差异。这些客观的性能对比表明,本研究提出的模型在复杂环境显著性检测中具有较大的潜力。
图3为不同模型在6个数据集上生成显著图的主观视觉性能对比。所提出的模型与其它显著性模型在6个数据集上的定性比较如图3所示。可以看出,传统模型的性能始终逊色于深度学习模型,并且深度模型能检测出更接近于真实显著图的显著预测图。尽管在简单场景下,大多数方法的性能都较优,但与本研究相比依旧不够精确,本研究抑制了大部分背景。在复杂场景下,尽管是一些具有竞争性的深度学习方法仍旧不能准确识别出显著目标。令人鼓舞的是本研究的模型在复杂场景下依旧能准确地定位出显著目标。特别是在夜间场景下,大多数模型几乎不能检测出显著目标,而本模型不仅可以定位出准确的显著目标还能够精细化其细节结构。这些结果说明了本研究提出的显著目标检测网络在具有挑战性的场景下有着较高的有效性和鲁棒性。

图3 不同模型在6个数据集上生成显著图的主观视觉性能对比
3.3 消融实验
为了验证所提出的各个模块的优势并评估不同模块的贡献,本研究分别设计了3组基准来训练显著性模型。①基准1,通过结合局部和全局线索并使用完整的卷积编码器-解码器网络来进行显著目标的检测。该基准不包含GSA和LSR模块,只保留了VGG16主干网络来训练生成显著性检测模型,主要用来对比没有GSA和LSR模块的显著性网络性能。②基准2,将GSA嵌入到基础网络中,不考虑局部结构细化,这个基准可以表现出GSA对于定位真正显著目标的重要性。③基准3,将LSR嵌入到基础网络中,不包含全局语义感知模块,用来测试LSR对显著目标检测结果的贡献度。
本研究将3组基准模型与完整模型进行了性能比较。主要在MSRA-B数据集上训练,训练集包含2500张图像,验证集包含500张图像,这些图像被组合起来训练本研究的4个模型。对于完整模型,完成整个训练过程大约需要8个小时,共迭代10次。训练后的模型被用于检测所有6个数据集的显著性图。相比之下,NLDF和RAS模型的训练集与本研究相同,LPS和C2S模型的训练集分别包含1万和3万张图像。
表2为本研究模型以及各基准模型的定量结果对比表格。本模型及3个基准在6个数据集上的客观性能对比见表2。
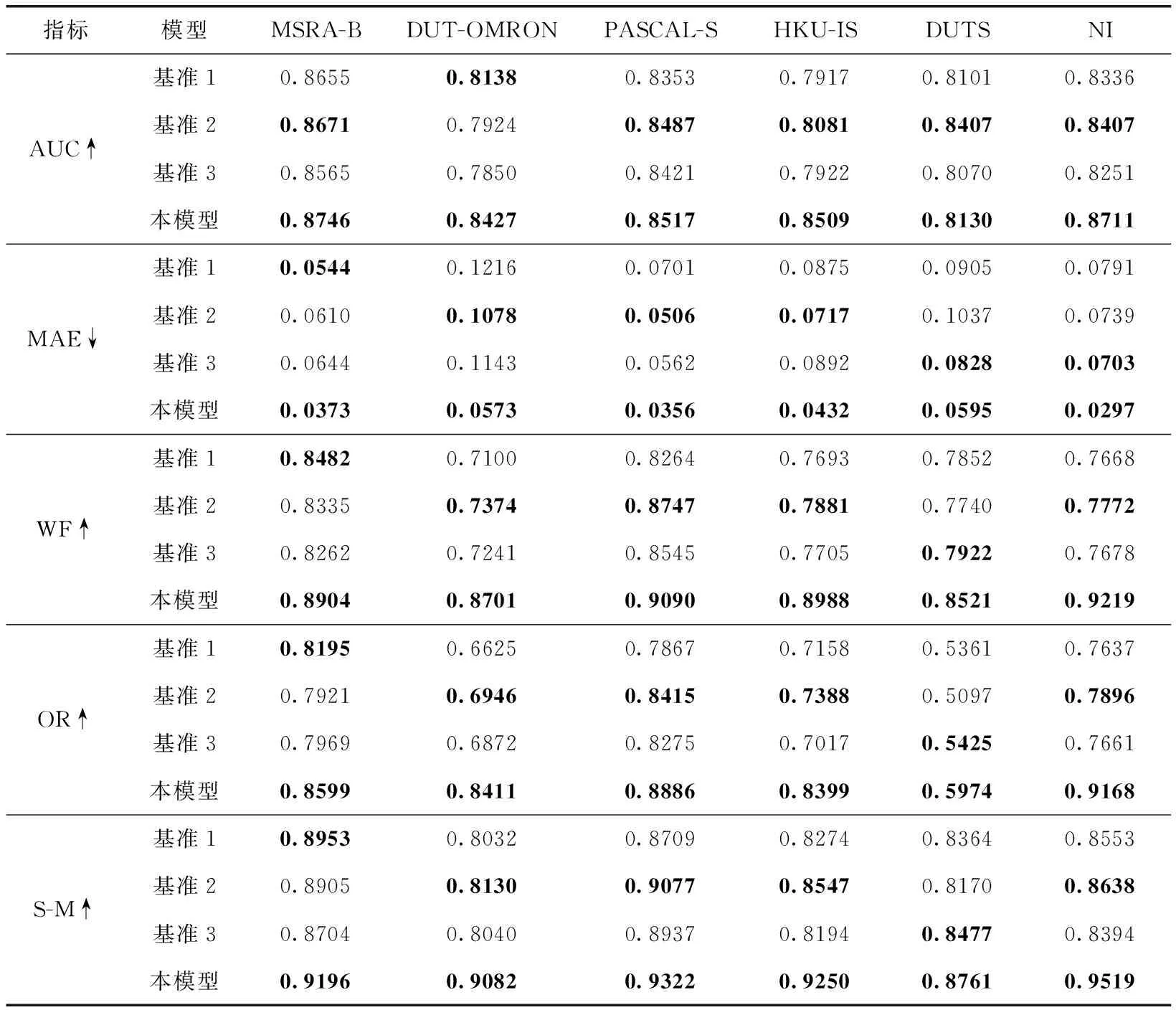
表2 本研究模型以及各基准模型的定量结果对比
由表2可以看出,加入了GSA和LSR后本模型在不同数据集上的各评价指标均得到了有效提升。其中,在DUT-OMRON、PASCAL-S和HKU-IS数据集上,基准2的各个评价指标均能排名第二,也即本研究提出的全局感知模块有着较好的效果;此外,在DUTS和NI数据集上,基准3能够在部分评价上排名第二,这表明本研究提出的局部细化模块能发挥一定作用。整体而言,本研究提出的全局感知模块和局部细化模块有效改善了模型的性能,能够在复杂场景的图像,特别是夜间图像上取得良好的检测结果[32]。图4为NI数据集上各基准模型所得的显著性结果对比图。在NI数据集上使用不同基准得到的显著性图的视觉对比如图4所示。

图4 NI数据集上各基准模型所得的显著性结果对比
从图4中可以看出,基准2的显著目标的形状比基准1更为准确,而基准3则保留了显著目标的平滑边界。对比3个基准,本模型能准确地检测出完整的显著目标,并产生连贯的边界,可以得知局部-全局方法、GSA和LSR给夜间图像显著性结果带来了很多优势。
4 结束语
本研究提出了一种用于检测夜间场景中的显著目标的深度全卷积网络,通过设计全局语义感知模块和局部结构细化模块,并将其嵌入到深度网络各层次中,以逐步编码不同层次丰富的多尺度语义信息与结构信息从而提高显著目标位置判断的准确性与结构细化的精确性。本模型可以有效获取更多的夜间图像判别特征,从而实现了精确的显著目标检测。通过在6个数据集上进行大量实验,结果表明,本模型优于大多数先进的显著性检测方法,能够在夜间图像显著目标检测等计算机视觉任务中发挥价值。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
电子制作(2019年11期)2019-07-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
中国卫生(2014年5期)2014-11-10
