
基于域内特征间相似性的点击率预估优化
2023-02-20 09:39雷李想武志昊刘钰周子站
计算机工程 2023年2期
雷李想,武志昊,4,刘钰,4,周子站
(1.北京交通大学 计算机与信息技术学院,北京 100044;2.北京交通大学 网络科学与智能系统研究所,北京 100044;3.中国民航信息网络股份有限公司,北京 101318;4.民航旅客服务智能化应用技术重点实验室,北京 101318)
0 概述
自2020 年以来,在线广告[1]业务已达到1 000 亿美元,收入以每年超过15%的速度增长,在线广告业务是互联网企业收入的重要来源之一。点击率(Click-Through Rate,CTR)预估[2]在在线广告行业中至关重要,其主要目标是在正确的环境中为正确的用户提供正确的广告,点击率预估效果的提升能够给企业带来巨大的收益。因此,如何准确有效地预测点击率已引起学术界和产业界的关注。
早期使用线性模型建模点击概率,为每个特征分配一个可学习的权重,但该方法无法建模特征间的交互关系。因子分解机(Factorization Machine,FM)[3]为每个特征分配了一个低维的稠密向量即嵌入[4],通过两个向量的内积建模特征间的交互关系,此后多数点击率预模型采用了为每个特征分配一个嵌入的做法,区别在于如何利用特征的嵌入建立特征交互。
尽管大量基于嵌入的点击率预估方法[5]被提出,但多数方法只关注如何设计建立特征间交互关系的模型,较少有关注特征的嵌入是否得到了较好的更新。而在实际数据集中,由于特征分布的长尾效应[6],域内的大量特征出现次数极少,而少量的特征的出现次数极多,导致大量的特征嵌入没有得到较好的更新。文献[7]和文献[8]为新出现的商品在ID 域生成即使在少量样本数据下仍可更新较好的初始嵌入,但该工作只针对ID域,无法解决一般域上的稀疏性问题。
造成特征嵌入学习不充分的本质原因是:直接根据特征取出特征对应的嵌入,这也是现有点击率预估模型的一般做法。该做法的隐含假设是特征间相互独立。但实际上特征间存在相似性,以城市域为例,某些小城市出现次数较少,例如临平,其嵌入训练不充分,但临平与杭州相邻,不论是气候或居民习惯都与杭州相似,若它能够有效地利用杭州的嵌入,则能够提升模型的预测效果。
为解决上述问题,本文提出两种特征相似度的定义,并利用基于特征相似度的域内特征相似性图建模域内特征的相似性。在域内特征相似性图的基础上,设计基于域内特征相似性的嵌入生成器,该生成器为出现次数较少的特征利用与其相似的特征嵌入生成了新的嵌入,作为预处理过程对特征嵌入向量进行数据增强,新的嵌入与原嵌入维度一致,即可直接作为一般点击率预估模型的输入。
1 相关工作
1.1 点击率预估
点击率预估的输入由在不同域上取到的特征值组成,以商品点击行为预测任务为例,商品产地、商品类别属于域,而商品产地中具体的中国、日本、美国等称作特征。每个域下有多个特征,域分为离散域和连续域,离散域内有有限个特征,连续域的特征为连续的数值。
用向量x表示模型的输入,向量x由在不同域上的特征向量xi拼接而成,用Fi(i=1,2,…,T)表示第i个域,其中T是域的个数。若域Fi是离散域,在该域取到特征fi,a,则xi是一个one-hot 向量,在特征fi,a对应的位置为1,其余位置为0,xi的长度等于域Fi中的特征总数。若第i个域是连续域,则xi是该连续特征值。
点击率预估的结果用y表示,y=1 表示点击,否则y=0。点击率预估任务的目标是获得输出点击概率的映射函数fw(x),其中,∈[0,1],w表示函数的参数。
1.2 稀疏特征问题
稀疏特征指域中出现次数极少的特征,该问题导致对应的特征嵌入无法得到较好的更新,而该现象在大型数据集中十分普遍。以Criteo 数据集为例,图1 所示为Criteo 数据集中C3 和C4 域中特征出现次数的分布情况。从图1 可以看出:大量的特征出现的次数都非常少,即这些域中的特征存在稀疏性的问题。

图1 Criteo 数据集中C3 和C4 域中特征出现次数分布Fig.1 Feature occurrence frequency distribution in C3 and C4 domains in Criteo data set
1.3 点击率预估模型
因为离散域的特征向量xi是高维的one-hot 向量,目前普遍的做法是将其映射到低维的稠密空间,其中,Vi=[ei,1,ei,2,…,ei,Ni]T为域Fi的嵌入矩阵,ei,a∈Rd表示特征fi,a对应的嵌入向量,Ni为域内的特征总数,xi是该域的特征向量,则该特征fi,a的嵌入可表示为:

现有的方法通常直接将ei作为后续分类模型的输入,即只考虑fi,a对应的嵌入ei,a。不同的模型区别在于:如何使用嵌入ei,a构建特征交互,FM 以特征嵌入的内积表示2 个特征的交互关系。然而,由于缺乏建模更深层特征交互的能力,它的预测能力有限。为了解决这一问题,目前的方法通常采用一个浅层组件学习丰富的低阶特征交互,以及一个深度神经网络[9]来建模高阶的特征交互。Wide &Deep[10]提出结合线性模型和深度神经网络的联合网络,但该方法依然需要特征工程[11]。深度因子分解机(Deep Factorization Machine,DeepFM)[12],将Wide &Deep中的线性模型替换为因子分解机,引入了嵌入来解决这一问题。此后,较新的方法通常都使用基于嵌入的神经网络来提升模型效果:神经因子分解机(Neural Factorization Machine,NFM)[13]用双线性交互池将嵌入向量和深度神经网络连接起来;xDeepFM(eXtreme Deep Factorization Machine)[14]提出了压缩交互网络(Compressed Interaction Network,CIN),并将其和深度神经网络结合,以显式和隐式方式自动学习高阶特征交互;AutoInt[15]提出了利用自注意力机制[16]以及残差连接[17]建模高阶的特征交互;Fi-GNN[18]用图神经网络[19]来建模特征间的高阶交互关系。
1.4 图神经网络
图卷积网络(Graph Convolutional Network,GCN)[20]借鉴卷积神经网络[21],将卷积算子泛化到图数据,提出了图卷积层,每层聚合节点的邻居节点的表示和其自身表示生成新的表示,公式如下:

其中:H(l)表示第l层的节点嵌入矩阵;表示A+I,A为图的邻接矩阵,I表示单位矩阵;表示的度矩阵;W(l)是可学习的参数矩阵。图卷积网络在聚合邻居节点信息时,只是简单地平均了近邻的信息,图注意力网络(Graph Attention Network,GAT)[22]引入注意力机制[16],更重要的近邻节点在聚合时被赋予更高的权重。图神经网络近些年发展迅速,在节点分类[23]和链路预测[24]领域取得了成功。
2 基于域内特征相似度的嵌入生成模型
2.1 模型框架
如1.3 节描述,现有的方法通常直接将ei作为后续分类模型的输入,根据损失函数进行反向传播更新时,只会更新ei,a。考虑丢掉这一假设,通过建模域内特征的相似性,在获得特征的嵌入时不只考虑该特征,同时考虑域内与其相似的其他特征。
通过建立域内特征相似性图建模特征的相似性,并根据图神经网络,在域内特征相似性图上聚合相似特征的嵌入信息。由于希望特征能够有选择地聚合其近邻的信息,因此选择使用图注意力网络,更新过程如图2 所示。具体来说,利用注意力机制决定节点近邻的重要性。以特征fi,a为例,设域Fi内特征间的相似性图为GFi,以N(fi,a)表示特征fi,a在GFi中的近邻,近邻指与fi,a在图中存在边的节点,ei,a表示特征fi,a的嵌入,首先计算特征fi,a与特征fi,k的注意力系数,如式(3)、式(4)所示:
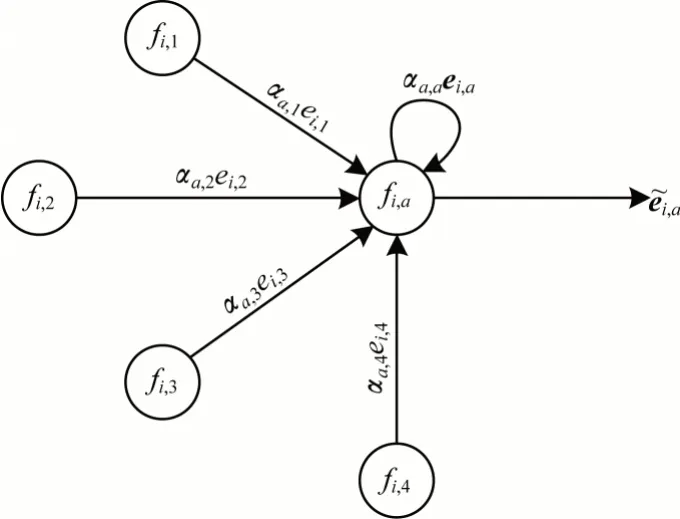
图2 特征嵌入的更新过程Fig.2 Update process of feature embedding

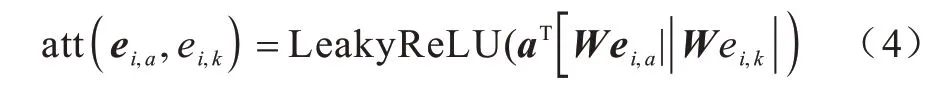
其中:att 表示注意力函数,首先利用变换矩阵W将嵌入从原始嵌入空间Rd映射到新的空间Rd′,然后将变换后的嵌入进行拼接并乘以长向量aT,最后对值采用激活函 数LeakyReLU[25]。接下来利用系数αa,k更新特征的嵌入,如式(5)所示:

2.2 模型输出和训练
经过嵌入生成器后,特征嵌入聚合了与其相似的特征的嵌入信息作为新的嵌入,此时数据的维度与原始嵌入一致,可以作为任意基于嵌入的点击率预估模型的输入,输出点击概率。
模型训练使用常用的交叉熵作为损失函数,定义如下:

其中:yj与分别表示真实标签和模型输出概率;M表示训练样本总量。利用梯度反向传播[26]最小化损失函数,对嵌入、嵌入生成器、分类器的参数进行更新,模型的整体流程与更新过程如图3 所示。

图3 模型整体流程Fig.3 Overall procedure of the model
3 特征相似性图构建方法
上文描述了利用域内特征相似性解决稀疏特征问题的整体框架,在该模型中利用了域内特征相似性图建模特征间的相似性,因此如何定义特征的相似以及建立域内特征相似性图非常关键。基于样本数据,本文提出了2 种特征相似度的定义及高效建立域内特征相似性图的算法。
3.1 特征相似度的定义
在直观上,如果2 个特征在其他域上经常取到相同的特征值,就认为这2 个特征较为相似。从该角度出发,提出基于共现概率的相似度定义,将特征相似度定义为2 个特征在其他域共享特征的概率。具体来说,设Fi表示第i个域,域的总数为T,fi,a表示Fi下的具体特征值a,将特征fi,a和特征fi,b在Fj取到相同特征的概率定义为特征fi,a和特征fi,b相对于Fj的相似度sim(fi,a,fi,b,Fj)。fi,a和fi,b在域Fj取到相同特征的概率可以理解为:随机抽取一条在Fi域取到fi,a的数据和一条在Fj域取到fi,b的数据,这一对数据在Fj域取到的特征是同一个特征的概率。利用频率估计概率,可得到sim(fi,a,fi,b,Fj)的表达式:

其中:R(Fi=fi,a)表示在Fi取到特征fi,a的数据集合;|R(Fi=fi,a)|表示集合内的元素个数,即在Fi取到特征fi,a的数据条数。最后用特征fi,a和特征fi,b在所有域上的相似度的平均来表示特征fi,a和特征fi,b的相似度:

在共现概率相似度定义中,需要利用特征fi,b的出现次数|R(Fi=fi,b)|对相似度做归一化,而在实际数据集中,某些特征的出现次数极高,会导致特征fi,a和这些特征的相似度值较小,因此该相似度倾向于其他出现次数较少的特征。为了让出现次数较多的特征也能够拥有较高的相似度,提出基于游走概率的特征相似度。相较于共现概率相似度,游走概率相似度的定义使用了不同的归一化形式,特征fi,a和特征fi,b相对于域Fj的相似度可用式(9)表示:

游走概率相似度与共现概率相似度的区别在于相似度定义中的分母,此时分母不再是fi,b的出现次数,而是求和项中fj,k的出现次数。游走概率相似度本质是在记录-特征二分图上,从特征fi,a对应节点游走到特征fi,b对应节点上的概率。
3.2 域内特征相似性图的构建
以上定义了不同的特征相似度,除了定义外,如何建立特征的相似性图也是一个关键问题。将域内特征相似性图定义为基于特征相似度的K 最近邻(K-NearestNeighbor)图,图中的每个节点对应一个特征,每个特征和其特征相似度最高的K个特征存在连边。
直接利用式(7)和式(8)计算特征fi,a和fi,b的相似度的时间复杂度为O(N),表示所有域的特征总数,Ni表示域Fi内的特征总数,则计算特征fi,a的前K个最相似特征的时间复杂度为O(NNi)。以Criteo 数据集为例,N约为106,对于特征较多的域,Ni约为105,因此想通过两两计算相似度,然后取前K个特征的方法是不可行的。针对该问题,提出了高效建立域内特征相似性图的算法,将特征的相似度计算问题描述为在记录-特征二分图上进行广度优先遍历的过程。记录-特征二分图如图4(a)所示,左侧的节点表示记录编号,每个点表示一条记录,右边的每个点是一个离散特征,连边表示该记录取到这一特征。
广度优先遍历的具体过程如算法1 所示。现以计 算sim(fi,a,fi,b,Fj) ∀fi,b∈Fi为例,说明该算法的 正确性。遍历从fi,a在记录-特征二分图中对应的节点开始,进行第1 层遍历,找到特征fi,a相邻的记录节点,如图4(a)所示,节点的集合可以表示为R(Fi=fi,a)。然后进行第2 层遍历,遍历这些记录节点在Fj内的近邻,此时遍历到域Fj内的特征节点,如图4(b)所示。将特征节点为起点,通过遍历,结束于另一个特征节点的跳转过程为路径,在遍历后,每个特征节点应该存在大于等于零条路径。对Fj内任意一个特征节点fj,x,其以fi,a为起点的路径数为|R(Fi=fi,a&。进行第3 层遍历,根据域Fj的特征节点找到其近邻的节点,如图4(c)所示,此时假设域Fj的特征节点是fj,x,其近邻是记录节点,可以表示为R(Fj=fj,x)。在进行第4 层遍历时,根据第3 层得到的记录节点找到其在域Fi内的近邻,如图4(d)所示。在进行第3 层和 第4 层遍历时,以域Fj的特征fj,x为起点,结束于域Fi特征fi,b的路径总数是R(Fj=fj,x&Fi=fi,b),因此4 层遍历从特征节点fi,a开始,经过特征节点fj,x传播至特征节点fi,b的路径总数是两者的乘积,在整个遍历过程中从特征节点fi,a经过域Fj传播至特征节点fi,b的路径总数是,此时即得到了式(7)中的分子,而分母可以简单地统计得到,因此只需计算并存储即可。而最终的传播在多个域上进行,所以最终可以得到sim(fi,a,fi,b)。在进行广度优先遍历后,通过fi,a到fi,b的路径数简单地计算出了sim(fi,a,fi,b),此时域Fi内所有特征都有相同的遍历过程,因此在一次广度优先遍历后可以计算出fi,a与域内其他所有特征的相似度。

图4 建网算法的遍历过程Fig.4 Traversal process of network building algorithm
算法1域内特征相似性图构建算法

将计算特征与域内其他特征的相似度描述成广度优先遍历具有以下优点:1)广度优先遍历无法遍历到相似度为零的特征,避免了和相似度为零的特征的不必要的计算;2)若想获得近似的前K个特征,只需要进行近似的广度优先遍历即可,即对每层的广度优先遍历进行剪枝,并不考虑所有近邻节点,而是抽样一定数量的近邻节点,从而满足时间和空间复杂度的要求。
在计算得到fi,a和域内其他特征的相似度后,取其中相似度最高的K个特征,在域内特征相似性图中分别对fi,a和这些特征建立一条边,完成域内特征相似性图的构建。
以上是基于共现概率特征相似度建立域内特征相似度图的过程,对于游走概率相似度,只需改变归一化系数,将Num(fi,k)×Num(fi,*)改 为Num(fi,k)×Num(fj,*)即可。
4 实验
本文实验主要关注以下3 个问题:1)由于本文提出的模型可以用在任意的基于嵌入的模型上,因此在多个点击率预估模型上进行了实验,并且关注了不同相似度下点击率预估的效果;2)嵌入生成器对不同的模型的运行时间的影响;3)在建图算法中,进行广度优先遍历的采样数对时间效率以及结果准确性的影响。
4.1 实验设置
在2 个点击率预估领域常用的公开真实数据集Criteo 和Avazu 上进行实验。Criteo 是一个点击率预测的基准数据集,有4 500 万条用户点击记录,它包含26 个离散域和13 个连续域。Avazu 数据集包含用户的手机行为,包括显示的手机广告是否被用户点击,它有23 个域,从用户/设备功能到广告属性,都是离散域。
4.1.1 评估指标
使用2 个在点击率预估任务中最常用的评估指标来评价模型的表现。
1)AUC:AUC 指在ROC 曲线下的面积,AUC 用于衡量点击率预估模型为一个随机选择的正样本给出的预测值大于一个随机选择的负样本的概率,更高的AUC 意味着更好的预测表现。
2)LogLoss:指式(6)表示的损失函数,因为所有的模型尝试去最小化LogLoss,用它作为一个直接的评估指标。
4.1.2 基准模型
在多个主流的点击率预估模型上加入嵌入生成器来证明模型的有效性。
FM:FM 利用了因子分解的技术建模二阶的特征交互。
DeepFM:在FM 模型的基础上加入了深度神经网络,大幅提升了模型的效果。xDeepFM:利用CIN 和深度神经网络的双塔模型。Autoint:利用自注意力机制捕获特征间的低阶和高阶交互关系。
Autoint*:在AutoInt 的基础上加入了深度神经网络来进一步提升模型效果。
4.1.3 参数设置
在Criteo 和Avazu 数据集上,嵌入生成器的注意力隐层分别为16 和32,其中Criteo 数据集分别在C3、C4、C12、C16、C21 这几个特征个数较多的域上使用嵌入生成器,并且只对出现次数小于50 的特征的嵌入进行生成。在Avazu 数据集中,由于该数据集中的特征基本都在device_ip 域中,因此只对device_ip 域进行了嵌入生成,并且只对出现次数小于5 的特征的嵌入进行生成。
模型训练的batch size、嵌入维度根据经验取1 024和16,都用了adagrad 优化器对模型进行优化。
4.2 点击率预估结果
表1 所示为在Criteo 数据集和Avazu 数据集上10 次实验的平均结果,其中,某个模型后的加号表示在该模型的基础上使用嵌入生成器,v1、v2 分别表示共现概率相似度和游走概率相似度。评估指标上表现更好的模型效果会被加粗。在点击率预估领域,评估指标10-4级别的提升也是十分关键的。可以看出:1)在大部分模型上,使用嵌入生成器都提升了模型的预测效果;2)嵌入生成器对预测效果的提升相较于Avazu 数据集,在Criteo 数据集上更明显;3)在大多数模型上,游走概率相似度取得了最好的效果。这是由于嵌入生成器针对的是出现次数较少的低频特征,为这些特征生成新的嵌入表示。基于共现概率相似度的域内特征相似性图中,低频特征的相似特征同样是低频特征,嵌入同样没有得到较好的训练,因此难以取得较好的效果。基于游走概率相似度的域内特征相似性图中,低频特征的相似特征是高频特征,低频特征能够利用高频特征的嵌入,生成一个具有更好表示能力的嵌入,因此在大多数模型上,游走概率相似度都取得了最好的表现。

表1 点击率预测结果 Table 1 CTR predict results
4.3 复杂度分析
本节将展示不同模型加上嵌入生成器之后的训练时间,由于不同模型训练时的batch size 是相同的,利用每秒钟训练的batch 个数来衡量模型的训练速度。在Avazu 数据集上的运行结果如图5 所示。从图5 可以看出:FM 模型的效率下降的最明显,约为20%,而xDeepFM 模型效率下降的最少,这是因为xDeepFM 模型中的CIN 模块的时间复杂度较高,影响了运行效率。可以从图5 看出:加上嵌入生成器后模型的效率仍可以接受。

图5 各模型运行效率Fig.5 Running efficiency of each models
4.4 建图算法实验
本节通过实验对建图算法进行分析,主要有以下2 个方面:
1)近似的建图算法相较于准确的建图算法的效率提升,以及在广度优先传播时选取的采样数对建网效率的影响。
2)由于在广度优先传播中进行采样,因此此时计算的前K个相似特征是近似结果,所以需分析采样数对建图算法准确程度的影响。
4.4.1 高效性
本节主要分析建图算法的高效性,以在Criteo数据集的C4 域上建立相似性图为例,取100 个特征,利用高效建图算法分别在不同的广度优先采样数下计算前K个最相似的特征,记录其花费的时间,如表2 和图6 所示。

表2 不同计算方式运行时间 Table 2 Running time of different calculation methods 单位:s

图6 建图算法运行时间Fig.6 Running time of mapping algorithm
从表2 和图6 可以看出:1)在采样数小于100时,所花费的时间基本没有变化,此时算法的时间主要是消耗在其他部分;2)在采样数大于100后,所增加的花费时间约和采样数成正比;3)不采样的建图算法的运行时间与采样相比会大幅上升,通常是无法接受的。
4.4.2 准确性
通过2 个指标来评估建图方法的准确性:1)该采样数下获得的近似前K个相似特征占准确的前K个相似特征的比例;2)该采样数下获得的近似前K个特征,每个特征的相似度在所有特征的相似度中所处的平均位置(例如处于前10%)。接下来详细介绍这2 个指标的计算方式。
对于特征fi,k,其与域Fi内的其他特征fi,*的相似度可以 表示为sim(fi,k,fi,*),将sim(fi,k,fi,*)fi,*∈Fi进行降序排序,记sim(fi,k,fi,*)在排序中的序号为orderfi,*,即fi,*是与fi,k第orderfi,*相似的特征,用set(fi,k)记录与fi,k最相似的K个特征的集合。以上的结果是指通过不进行采样的建图算法获得的准确结果,对于在广度优先遍历采样数为n时,同样可以计算出fi,k与其他特征fi,*的相似度,此时是近似值,同样可以获得与fi,k最相似的K个特征的集合,用setn(fi,k)来表示。第1 个指标可表示为;第 2 个指标可表示为,其中,Ni表示域Fi内特征的总数。
同样以在Criteo 数据集的C4 域上建立相似性图为例,取100 个特征,分别在不同的采样数下运行建图算法,计算以上2 个指标,并在100 个特征上计算指标的均值,结果如图7 和图8 所示。从图中可以看出:在采样数较小时(小于200),采样数的上升会让建图算法的准确程度较快地提升,而采样数较大以后(大于500),则提升较慢。综合效率和准确率在实验中建图都采用200 的采样数。
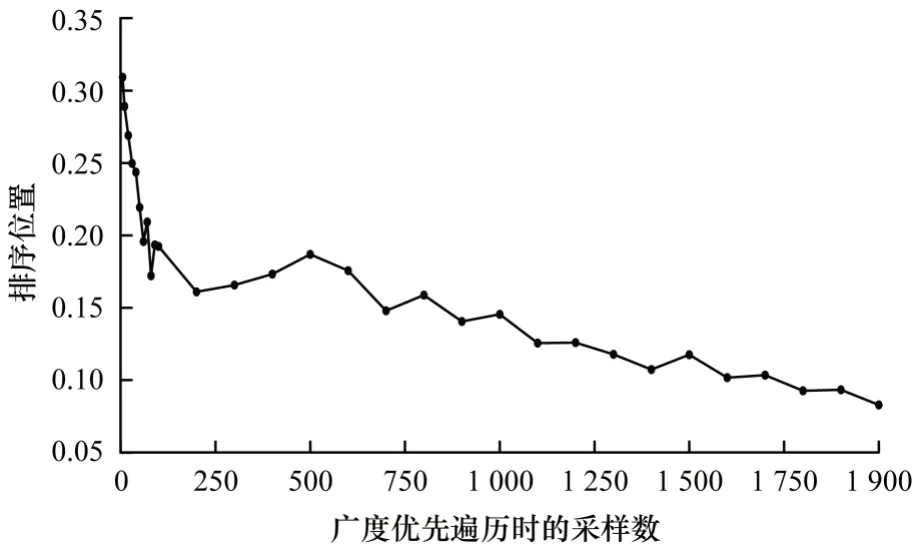
图7 前K 个相似特征的平均排序位置Fig.7 Average ranking position of the top K similar features
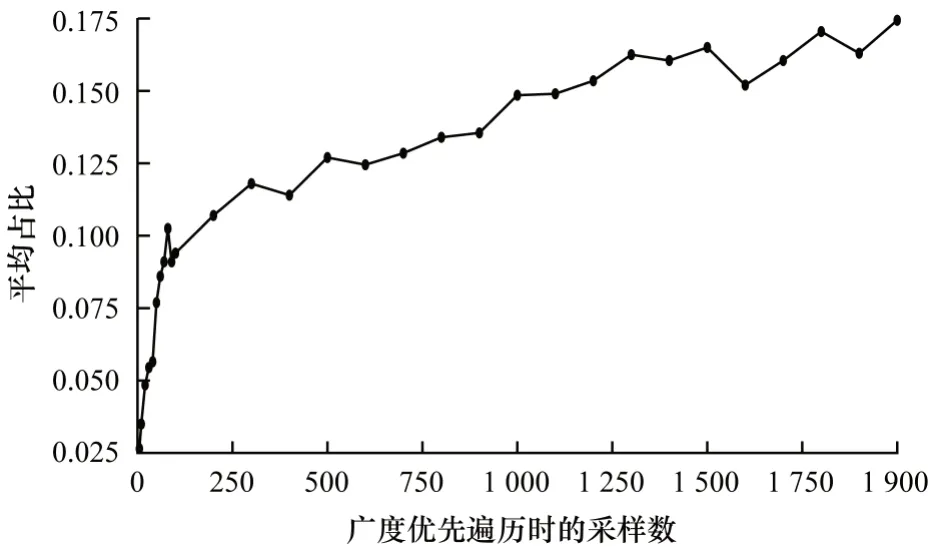
图8 前K 个相似特征的平均占比Fig.8 Average proportion of the top K similar features
5 结束语
特征的稀疏性问题普遍出现在大型的点击率预估数据集中,造成特征嵌入学习不充分的问题。为解决该问题,本文提出了基于数据集的特征相似度定义以及建立域内特征相似度图的算法,用于建模域内特征相似度,并设计了利用图神经网络在域内特征相似度图上聚合相似特征嵌入信息的嵌入生成器,用于对出现次数较少的特征生成嵌入,缓解由于特征出现次数过少导致的特征嵌入学习不充分问题。实验结果证实了嵌入生成器的有效性以及建网算法的高效性。本文运用特征的域内信息解决稀疏特征问题,未来可考虑使用域外特征的信息,引入更先进的图神经网络,以在域内相似性图上更好地捕获相似特征的信息。
猜你喜欢
矿山安全信息(2022年22期)2022-11-24
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
浙江大学学报(工学版)(2016年2期)2016-06-05
当代化工研究(2016年2期)2016-03-20
海峡姐妹(2015年8期)2015-02-27
海外英语(2013年3期)2013-08-27
俄罗斯问题研究(2013年1期)2013-03-11
