
基于深度多相似性哈希方法的遥感图像检索
2023-02-20 09:39何悦陈广胜景维鹏徐泽堃
计算机工程 2023年2期
何悦,陈广胜,景维鹏,徐泽堃
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)
0 概述
随着对地观测技术的快速发展,遥感图像数量呈爆炸性增长趋势,迫切需要对遥感数据进行高效化、轻量化的管理。基于内容的遥感图像检索(Content-Based Remote Sensing Image Retrieval,CBRSIR)旨在从大规模遥感图像库中检索到与查询图像具有相似语义特征的图像,常采用近似最近邻(Approximate Nearest Neighbor,ANN)搜索来实现[1]。其中,基于哈希学习方法由于其高效的查询速度和较低的存储空间,已成为图像检索的主流技术之一。哈希算法的目的是将图像集从高维空间转换为紧凑的二进制哈希码,并保持图像相似性[2],其能够显著降低存储成本并保持原有空间的语义结构。
主流的哈希学习方法主要分为监督哈希和无监督哈希两类[3-5]。其中,监督哈希方法在学习过程中使用监督信息以提高哈希算法的性能,如监督离散哈希(Supervised Discrete Hashing,SDH)[6]、深度监督哈希[7]等。这些方法将图像集的标签当成监督信息训练哈希模型,基本和相应的数据有关联。但是,对于遥感图像来说,标记大量的数据具有一定难度,此外,收集足够的标记数据需要投入巨大的时间和精力,因此,监督哈希方法很难满足实际需求。
为了解决上述问题,大量的无监督哈希方法相继被提出,包括局部敏感哈希(Locality-Sensitive Hashing,LSH)[8]、谱哈希(Spectral Hashing,SH)[9]、迭代量化哈希(Iterative Quantization Hashing,ITQ)[10]等。上述传统哈希方法往往采用浅层架构,性能上仍旧无法满足实际应用的需求,因此,无监督深度哈希技术开始受到关注[11-13]。文献[14]利用余弦距离和阈值从特征空间学习语义结构。文献[15]通过局部的流形语义相似结构重构进行哈希学习,通过研究输入图像的流形结构来优化网络。文献[16]使用训练后的模型输出来优化相似矩阵。虽然上述研究通过预训练的卷积神经网络(Convolution Neural Network,CNN)模型能提取高维特征,但是都只考虑了局部结构而忽略了同样重要的全局结构,导致伪标签不可靠。此外,这些研究采用的损失函数没有设立较好的惩罚机制,输入数据被同等对待,导致检索模型精度较低。
本文提出一种深度多相似性哈希(Deep Multi-Similarity Hashing,DMSH)来学习没有语义监督的高质量哈希码。DMSH 采用预训练的Swin Transformer模型作为骨干网络,并设计两个创新模块:自适应伪标签模块(Adaptive Pseudo-Labeling Module,APLM)采用K 最近邻(K-Nearest Neighbor,KNN)和核相似度实现伪标签生成和更新,以充分挖掘遥感图像的语义信息和相似关系;成对结构信息模块(Paired Structure Information Module,PSIM)的核心思想是通过结构相似度区分不同图像对的训练关注度,使得模型能够自适应地学习更高质量的哈希码。
1 本文方法
本文提出一种面向遥感图像检索的深度多相似性哈希方法,该方法的总体框架如图1所示,主要包括3个部分:基于Swin Transformer 骨干网络的特征提取与哈希码生成;基于自适应伪标签模块的相似矩阵生成与更新;基于成对结构信息模块的哈希编码学习。

图1 深度多相似性哈希方法总体框架Fig.1 General framework of deep multi-similarity hashing method
1.1 特征提取与哈希码生成
本文采用预训练的 Swin Transformer 的Tiny 版本作为骨干网络,用于遥感图像的特征提取。Swin Transformer 网络模型采用多层结构,包含Patch Merging 和多个 Blocks[17]。模型通过自适 应平均池化层和全连接层输出1 000 维的高维特征。为了让网络适用于哈希学习,在全连接层之后添加一个哈希层,输出值为-1~1 之间的近似哈希码。哈希层采用tanh()作为激活函数,如式(1)所示:

给定一幅图像xi,通过Swin Transformer 和哈希层,由哈希层输出图像对应的近似哈希码r(xi),采用sgn()函数生成图像xi的二进制哈希码b(xi),计算过程如式(2)所示:

1.2 自适应伪标签模块
考虑到遥感图像的特性,本文设计自适应伪标签模块(APLM)以充分捕获遥感图像的语义信息。APLM 包含伪标签的生成与更新两个部分。
1.2.1 伪标签生成
以往图像检索研究中通过CNN 模型进行高维特征提取,从而生成伪标签[18-20]。受此启发,本文建立一个基于Transformer 模型的相似度矩阵,将其作为伪标签来指导哈希学习。首先通过预训练的Swin Transformer 的全连接层提取遥感影像的高维特征,然后利用两阶段的KNN 生成语义相似矩阵:第一阶段,KNN 将高维特征的余弦距离设置为距离度量,前k1个邻近对象判定为相似图像;第二阶段,KNN 将相同邻居的数量设置为距离度量,前k2个邻近对象判定为相似图像。如果两张遥感图像在两阶段的最近邻搜索中均被判定为相似,即被认为是相似的。数据集通过上述流程生成的相似度矩阵W作为初始伪标签。预训练模型不能很好地挖掘遥感图像的深层语义信息,导致伪标签的可信度不高,因此,在哈希学习的过程中需要进行伪标签的同步更新。
1.2.2 伪标签更新
在开始训练后,使用数据集和初始伪标签来更新模型参数。参数优化后,模型会输出包含更多语义信息的高维特征,APLM 再采用高斯核函数计算每一个mini-batch 中图像对的核相似度,从而更新伪标签。核相似度的计算如式(3)所示:

其中:dij代表图像i和图像j之间的欧氏距离;σ2是超参数;n代表每一个mini-batch 中训练图像的数量。
通过采用新的相似度阈值(所有图像对的核相似度均值)来更新伪标签,阈值的计算如式(4)所示:)

APLM 的伪标签更新策略为:将核相似度高于阈值的图像对在相似度矩阵中更新为正样本对(相似),对于矩阵中原有的正样本对不做修改。伪标签相似矩阵W的更新如式(5)所示:

由于微调后的模型针对遥感图像集的判别性有所提升,因此每一轮mini-batch 更新后的伪标签会比初始伪标签更可靠,利用更可靠的伪标签再次训练模型并更新参数,多轮迭代,直至模型达到最佳性能。
1.3 成对结构信息模块
在以往研究中,模型计算相似损失时往往赋予所有图像对相同的训练权重,导致相似度差异大的图像对没有被充分学习,相似度差异小的图像对被过度学习。为了解决上述问题,本文设计一种成对结构信息模块(PSIM),如图2 所示,它能够得到模型训练过程中不同图像对的受关注度,为不同图像对赋予不同的训练权重,使相似度高的图像拉得更近,相似度低的图像推得越远,从而使得模型聚焦于贡献度更大的图像对。
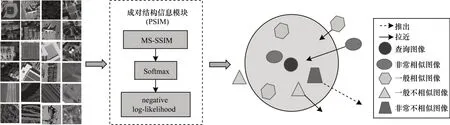
图2 成对结构信息模块Fig.2 Paired structure information module
PSIM 模块主要通过每个mini-batch 中图像间的多尺度结构相似性(Multi-Scale Structural Similarity,MS-SSIM)计算出自适应调制因子,以优化哈希学习。MS-SSIM 是一种基于多尺度测量两个图像之间相似性的方法[21],包含亮度(l)、对比度(c)、结构(f)这3 种对比模块,计算分别如式(6)~式(8)所示:

其中:μi代表图像i的均值;代表图像i的方差;σij代表图像i和图像j的协方差;C1、C2、C3是常数。
遥感图像集地物类型丰富,因此,相比仅适合特定场景的单尺度结构相似度方法,多尺度结构相似度方法更适用于多场景的遥感图像[22]。多尺度结构相似度评估是通过组合不同尺度的测量来获得,具体计算如式(9)所示:

其中:M代表最高尺度;h代表所在尺度层数;αM、βh、γh代表各成分间的关系权重。
如果图像j是图像i的最相似图像,则认为两者的结构相似度也是最高的,因此,将图像对的结构相似度作为输入,通过Softmax 函数计算每个minibatch 中各图像间的相似概率,如式(10)所示:

其中:τ是一个温度超参数,可以控制Softmax 输出差异的大小。
最终,本文采用负对数似然(negative log-likelihood)关联Softmax 函数,生成自适应的调制因子,用于确定图像对的训练关注度。自适应调制因子如式(11)所示:

对于结构相似度越低的图像对,认为其相似概率越低,能够为模型提供的信息更丰富,因此,为其设置较高的调制因子mij,便于模型训练过程中更关注这一类图像对。反之,图像对的结构相似度越高,调制因子mij设置越低。
1.4 多损失函数学习
在哈希学习阶段,本文采用基于自适应调制因子的相似损失函数和量化损失函数来更新模型参数。相似损失函数减少相似图像对(正样本)间的距离,并增大不相似图像对(负样本)间的距离,从而保证遥感图像之间的相似性可以保留在哈希编码中,如式(12)所示:

其中:sij代表图像i和图像j的余弦相似度。余弦相似度通过计算两个向量内积空间夹角的余弦值来判定相似性,如式(13)所示:

其中:ri代表图像i的近似哈希码;代表ri的转置;代表L2 范数。
量化损失函数将近似哈希码中的元素推向0 或1,减少近似哈希码和二进制哈希码之间的性能差距,如式(14)所示:

其中:B和R分别代表训练输出的二进制哈希码和近似哈希码;代表Frobenius范数。
用于模型训练的总损失函数如式(15)所示:

其中:λ是平衡Ls和Lq的超参数。
2 实验结果与分析
2.1 实验数据与评价准则
为了评估本文方法的检索性能,采用两个已发布的遥感数据集进行大量实验。第一个数据集是由德国凯泽斯劳滕大学提出的EuroSAT,该数据集有27 000幅场景图像,图像分为10 个类别[23],每个类别的样本数量从2 000到3 000不等,每张图像尺寸大小为64×64像素。第二个数据集是武汉大学发布的PatternNet,该数据集由38 个场景类别组成,包含30 400 张图像,每张图像尺寸为256×256 像素[24]。此外,PatternNet 的遥感图像空间分辨率为0.006 2~4.693 0 m。在两种数据集中,均针对每类随机选取100 张图像作为测试查询集,其他图像作为训练集。
本文采用3个广泛使用的评价指标来评估DMSH的检索性能,分别为平均精度均值(mean Average Precision,mAP)、Top-N检索返回的准确率(Precision@N)和查准率-查全率(Precision-Recall,P-R)曲线。其中,针对EuroSAT 和PatternNet 数据集,本文分别使用排名前1 900 和排名前700 的检索图像来统计mAP值。
2.2 实验环境
本文使用ImageNet-1K 数据集预训练Swin Transformer 模型作为骨干网络。实验所用GPU 为TeslaV100,采用PyTorch 来训练模型[25]。根据超参数的调试,最终的各超参数值在两个数据集上均能使模型达到最佳检索性能,超参数设置如下:k1和k2分别为20 和30,σ2和τ均为1,λ为10,mini-batch 为64,学习率为2e-5,采用Adam 优化器[26],总共训练40 个轮次。
2.3 与先进方法的比较
为了验证本文DMSH 方法的有效性,将其与多种无监督哈希学习方法进行比较,包括基于浅层模型的哈希方法与基于深度学习的哈希方法,浅层方法分别是LSH、SH 和ITQ,深度方法分别 是SSDH[14]、MLS3RDUH[15]和DUIH-MBE[27]。在两种数据集上进行的对比实验结果如表1、表2 所示,最优结果加粗标注。从中可以看出:在EuroSAT 数据集上,本文方法在16、24、32 和48 位哈希码的mAP 性能较对比方法的最优结果分别提升了1.8%、0.8%、2.3%、3.0%;在PatternNet数据集上,DMSH 在不同长度哈希码的mAP 结果上分别实现了12.5%、10.1%、9.8%和10.7%的增量。可以得出:1)除了表1 中ITQ 的mAP 结果之外,其余的无监督哈希方法的mAP 结果均随着哈希码长度的增长而提升;2)传统的无监督哈希方法虽然采用了高维特征作为输入,但是检索精度仍旧远低于深度无监督哈希方法,原因是传统方法大多将特征提取和哈希学习分开,无法在训练过程中获取包含更多语义信息的图像特征;3)DMSH 的检索精度高于其他深度无监督哈希方法,说明无监督哈希学习结合多种相似度,能够更好地实现伪标签和哈希编码的共同优化。

表1 在EuroSAT 数据集上各方法的mAP 比较 Table 1 mAP comparison of methods on EuroSAT dataset

表2 在PatternNet 数据集上各方法的mAP 比较 Table 2 mAP comparison of methods on PatternNet dataset
为进一步验证DMSH 的有效性,采用其他指标进行对比实验。图3 和图4 分别为两个数据集下不同方法的48 位哈希码的Precision@N指标对比,从中可以看出,在两种数据集上DMSH 的Precision@N均高于其他方法。图5 和图6 分别为两个数据集下不同方法的48 位哈希码的P-R 曲线对比,从中可以看出,当召回率逐渐提高时,全部方法的查准率都会降低,然而,在相同召回率下DMSH 的查准率仍高于其他方法,在相同查准率下DMSH 的召回率也优于其他方法。DMSH 在上述两种评估指标下依然具有优越性,说明该方法在大规模遥感图像数据集上具有有效性和通用性。

图3 在EuroSAT 数据集上各方法的Precision@N 比较Fig.3 Precision@N comparison of methods on EuroSAT dataset

图4 在PatternNet 数据集上各方法的Precision@N 比较Fig.4 Precision@N comparison of methods on PatternNet dataset

图6 在PatternNet 数据集上各方法的P-R 曲线比较Fig.6 P-R curve comparison of methods on PatternNet dataset
2.4 消融实验
为了验证DMSH 中两个模块的有效性,在DMSH 中删减APLM 模块以及同时删减APLM 和PSIM 模块,48 位哈希码的mAP 性能指标对比如表3所示。从中可以看出:在EuroSAT 数据集中,删减APLM 模块会使模型的mAP 精度下降1.8 个百分点,完全删减两个模块会导致检索精度再次下降6.3 个百分点;在PatternNet 数据集中,不采用APLM 和PSIM 模块也会导致mAP 精度下降9.5 个百分点。因此,同时运用APLM 和PSIM 模块能够更有效地保留遥感图像的相似性,生成更高质量的哈希编码。

表3 消融实验结果 Table 3 Results of ablation experiment
2.5 可视化实验
为了更直观地展示DMSH 的有效性,图7 所示为EuroSAT 和PatternNet上48 位哈希码的检索结果,输出与查询图像最相似的10 张检索图像,图中带叉号的图像代表错误结果。从图7 可以看出,DMSH 在两个数据集上的检索效果明显好于最优对比方法DUIH-MBE,尤其是在河流类别和交叉路口类别上,本文方法分别克服了公路和立交桥类别图像的干扰,这是因为基于核相似度迭代更新后的伪标签能提供更加准确的监督信息,同时基于结构相似度的调制因子能更有效地实现最小化类间相似度、最大化类内相似度,即DMSH 相比其他方法可以更好地判别多类遥感图像。

图7 DMSH 和DUIH-MBE 的检索结果比较Fig.7 Comparison of retrieval results between DMSH and DUIH-MBE
3 结束语
本文提出一种多相似性联合的深度无监督哈希方法DMSH,利用预训练的Swin Transformer 模型作为特征提取器,结合核相似度在训练过程中迭代更新伪标签,挖掘遥感图像间潜在的语义相似关系,同时通过结构相似度设计自适应调制因子,赋予不同图像对不同的关注度权重,从而更充分地利用图像对的判别信息,提高哈希码的辨识力。实验结果验证了DMSH 方法的有效性。下一步将考虑设计新的网络结构并优化量化损失函数,以期在更复杂的遥感图像数据集上实现更高的检索精度。
猜你喜欢
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
专利代理(2016年1期)2016-05-17
公民与法治(2016年10期)2016-05-17
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
少儿科学周刊·少年版(2015年2期)2015-07-07
质量与标准化(2010年5期)2010-05-03
