
基于知识架构的持续学习情感分类方法
2023-02-20 09:38王松买日旦吾守尔古兰拜尔吐尔洪薛源
计算机工程 2023年2期
王松,买日旦·吾守尔,古兰拜尔·吐尔洪,薛源,2
(1.新疆大学 信息科学与工程学院,乌鲁木齐 830046;2.清华大学 电子工程系,北京 100084)
0 概述
机器学习模型在学习多个任务时通常会出现灾难遗忘现象,灾难遗忘现象是指在新任务中学习的知识会影响模型原有参数,降低模型在旧任务上的性能。因此,模型需要训练完成后才能进行部署应用,然而随着时间的推移,在训练集中未出现的新样本越来越多,导致模型无法正确分类,性能逐渐下降,此时需要在新旧数据集上重新训练模型,但该过程又消耗大量能源、计算资源与人力资源,也给项目管理带来了巨大挑战,更重要的是遵循这种孤立的学习方式,难以使模型将新旧知识融会贯通,实现通用人工智能。为解决上述问题,THRUN[1]于1995 年提出持续学习(Continual Learning,CL)概念。自提出以来,持续学习已经在计算机视觉(Computer Vision,CV)、自然语言处理(Natural Language Processing,NLP)、强化学习等领域得到广泛应用。由于情感分类是NLP 中的基础任务,因此很多研究围绕情感分类任务开展,主流网络均能应用于该任务并在测试中取得了较好的性能表现[2],但在实际应用中效果并不理想,面临知识的保留与迁移、领域适应等难题。CHEN等[3]尝试将持续学习与情感分类相结合来解决这些问题,并且之后几年国内外涌现出了一系列相关领域的研究成果。
在情感分类和图片分类这两种任务中,对于任务序列中分类任务的定义是不同的,根据任务的定义不同发展出类持续学习(Class Continual Learning,CCL)和任务持续学 习(Task Continual Learning,TCL)[4-5]。类增加学习假设任务序列中每个任务包含不同的类别。系统仅使用一个分类器来学习所有任务,当新的任务到来时,模型需要能够分类迄今为止在训练集中未出现的所有样本。任务增加学习假设任务序列中的每一个任务都是独立的分类任务。这些分类任务的类别可以是相同的也可以是不同的,每一个任务都有对应的分类器,在测试时测试样本包含任务序列的标识,以帮助模型使用对应的分类器对其进行分类。因为分类器的设置不同,所以进一步产生了研究目标的差异。CCL 研究在分类器上不断增加新的类别,因此侧重减轻学习过程中的灾难遗忘。TCL 为每个任务训练独立的分类器,因此侧重分类器的知识积累与分类器之间的知识迁移。根据持续学习在计算机视觉和自然语言处理领域现有的研究成果,将其主要分为基于样本重复、基于正则化、基于动态网络结构和基于知识架构4 类持续学习方法[2,6-7]。
基于样本重复的持续学习方法在学习过程中会存储旧任务的部分样本或者关于样本的信息,在学习新任务时进行重复学习。该类方法根据任务样本如何产生又可分为两类:第一类将任务样本直接存储以备后用;第二类利用任务样本训练生成模型,在需要样本时利用生成模型输出伪样本。iCaRL[8]直接保存代表性样本,并在学习新任务时将这些样本进行重复学习。GEM[9]使用存储的样本来限制新模型中梯度更新的方向。MBPA++[10]存储所有训练样本,并在推理时寻找N个最相似的样本重新微调模型。DGR[11]和LAMOL[12]都使用旧任务数据训练一个生成模型,然后在新任务训练时利用生成模型生成伪样本。
基于正则化的持续学习方法会在损失函数中增加额外的正则项,通过限制参数更新的方式在学习新任务的同时保留旧任务参数,代表方法如EWC[13]、IMM[14]、LwF[15]和LFL[16]。EWC根据损失函数中的Fisher 信息正则项有选择地更新模型参数,并使模型倾向于保留对旧任务重要的参数。IMM 训练新模型并根据不同策略将新旧模型合并。LwF 将新旧模型的Softmax 层相加取平均值并计算知识蒸馏损失。LFL[16]将网络最后一层抽取出来,用欧氏距离作为正则项度量特征之间的差别。
基于动态网络结构的持续学习方法也被称为参数隔离方法[2],因为其目的是根据不同的任务动态调节网络结构,从而实现任务间部分参数的隔离。该类方法根据网络规模是否固定分为两类。PathNet[17]和任务门控注意力(Hard Attention on Task,HAT)机制[18]都使用固定的网络规模,并且为每个任务动态地分配部分网络,在学习新任务时,先前任务的参数会被Mask 屏蔽,其中PathNet 对参数进行屏蔽,HAT 对神经元进行屏蔽。PNN[19]会为每个新任务单独训练一列网络,网络规模会不断扩大,当新任务到来时就会新增一列,原有列的输出也会作为先验知识输入给新的列。
基于知识架构的持续学习方法主要应用在情感分类中。LSC[3]将终身学习用于情感分类任务,并设计终生机器学习架构,包含任务管理器、学习器、知识库和知识挖掘器。LNB[20]改进了LSC 的知识库内容和知识挖掘策略。LNB-DA[21]在中文数据集上进行了扩展,并在知识挖掘中提出领域注意力机制。SRK[22]使用门控循环单元(Gated Recurrent Unit,GRU)构建知识保留网络、特征提取网络和衔接两者的融合网络。KAN[5]拥有一个持续学习主网络和一个基于动态网络架构的知识库控制网络。BLAN[23]将LNB 中的知识库和层次注意力网络相结合。
本文基于文献[21]研究成果,提出一种基于知识架构的持续学习中文情感分类方法,并构建了知识保留网络(Knowledge Retention Network,KRN)和知识挖掘网络(Knowledge Mining Network,KMN)。
1 基于知识保留与挖掘的持续学习方法
在情感分类任务中,单一模型难以适应多个特定的领域,因此将不同领域的商品评论数据视为不同的任务组成一个任务序列。模型依次学习任务序列中的每一个任务,利用持续学习方法缓解灾难遗忘现象,实现知识迁移。
知识保留与挖掘网络(Knowledge Retention and Mining network,KRM)设置了知识保留和知识挖掘两个子网络。在任务数据被输入模型后,首先使用参数固定的BERT 模型转化为特征向量,然后将向量和任务标志t一起输入知识保留网络,网络中包含两个改进的Transformer[24]编码器层,使用任务自注意力机制替换原有自注意力机制,从而为每个任务单独保留一组注意力矩阵参数,输出被传入知识挖掘网络,该子网络将HAT 机制与TextCNN[25]中三层全连接层相结合,最后得到分类结果。KRM 结构如图1 所示。
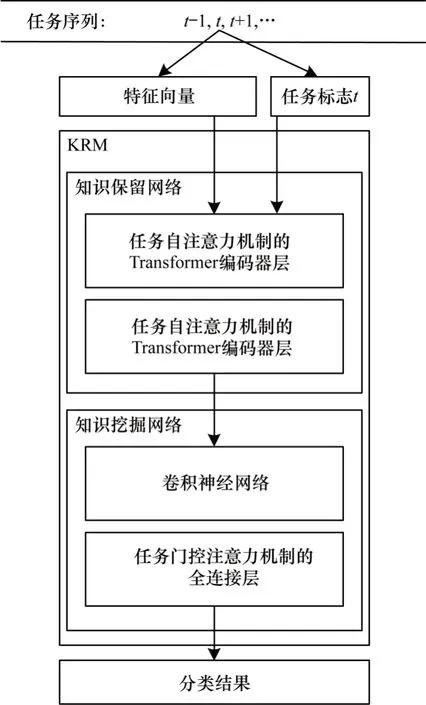
图1 KRM 结构Fig.1 KRM structure
1.1 知识保留网络
知识保留网络由两个相同的Transformer 编码器层组成,每层又包含两个子层:任务自注意力层(Self-Attention)和全连接层。每个子层的输出如式(1)所示:
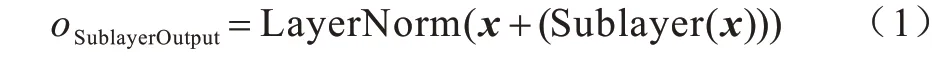
输入数据首先经过自注意力子层,输出结果和输入相加再做层正则化,然后作为全连接层的输入,最后在全连接层后做残差连接与层正则化后输出,如图2 所示。

图2 知识保留网络结构Fig.2 Knowledge retention network structure
知识保留网络中的Transformer编码器层进行了以下改进:1)移除了最初的位置编码;2)为每个任务设置了独立的参数矩阵,也就是任务自注意力机制。因为模型的输入是BERT 最后一层的输出,所以不必再重复嵌入位置信息。每个任务独立的参数矩阵有助于模型根据任务的不同,有针对性地使用符合任务特性的注意力,提高检索效率。
改进后的Transformer 编码器层首先使用任务自注意力机制,自注意力层内包含3 个参数矩阵,根据不同的任务t∈[T1,T2,…,Tn],模块会存储对应的,将任务输入的向量x转换成相对应的Q、K、V向量,如式(2)所示:

然后使Q和K的点积计算注意力得分,为保持梯度稳定为注意力得分做归一化处理,除以因子。经过Softmax 激活函数后再点乘V得到加权评分V。最后将所有V相加得到结果,如式(3)所示:

在实际运算过程中通常会由一组索引组成矩阵Q方便同时计算,对应的键和值也被打包成K和V,其中KT为K的转置。在引入多头注意力机制后的运算过程如式(4)所示:
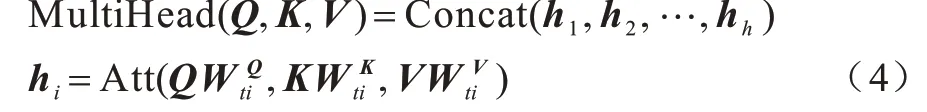
任务自注意力机制会为每个任务的每个注意力头均保留对应的矩阵。
1.2 知识挖掘网络
知识挖掘网络是一个经过改进的TextCNN网络,其中将任务门控注意力机制加入全连接层,知识挖掘网络结构如图3 所示。
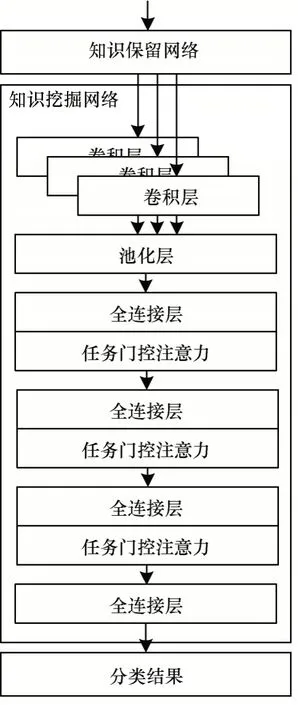
图3 知识挖掘网络结构Fig.3 Knowledge mining network structure
1.2.1 TextCNN
这部分沿用文献[25]中的设置,假设知识保留网络的输出为x∈Rn×k,其中n为网络设置的最大文本长度,k为词向量维度。首先采用窗口长度s为2、3、4 的filter 来生成特征c,如式(5)所示:

其中:b∈R;f为非线性函数。
然后利用MaxPooling获得特征=max{c},将3个filter 的特征做拼接得到最终的输出如式(6)所示:

1.2.2 任务门控注意力机制
任务门控注意力机制[18]最初运用于CV 领域,考虑到卷积层作为特征提取部分,应该在各个任务间尽可能地保持特征选择的稳定性,因此仅将HAT 用于全连接层。
门控注意力机制就像为全连接层的每一个神经元配置了一个开关,根据不同的任务t控制每一个神经元的开闭:打开对任务t重要的神经元而关闭其他的神经元,使网络的连接方式随任务的变化而变化。当学习任务t时,记全连接层为hl,经过门控注意力,输出为,门控注意力机制作用于全连接层的过程如式(7)所示:

HAT 正向传播过程如图4 所示。

图4 HAT 正向传播过程Fig.4 Procedure of HAT forward propagation
在全连接层中,首先根据任务t生成hl层的任务嵌入,再乘以一个正的缩放参数s,利用Sigmoid函数来模拟开关。不同于软注意力机制(soft attention)是一个概率的分布,更像是开关,被称为硬注意力机制(hard attention)。hl中的每一个神经元都有其对应的,全连接层的输出为hl的每个元素与对应位置的元素相乘,由此网络可以确定哪些神经元对任务t更重要。
由于在网络中的值接近0 或1 且反向传播过程中是可导的,在Sigmoid 函数中,当输入很大或很小时,输出则会接近0 或1,因此HAT 利用超参数smax≫1 使Sigmoid 函数来模拟单位跃阶函数:当s→∞时,at→{0,1};当s→0时,at→0.5。使 用式(8)更新s模拟Sigmoid 函数的退火过程:

其中:b代表batch;B代表一个epoch 中batch 的总数。在训练刚开始时,s很小,因此注意力还是软注意力,随着训练s越来越大,注意力变成了硬注意力。由于参数s的变化,因此在训练完成时更加倾向于0或者1,以表示一个神经元的开和关。
为任务门控注意力机制提供任务信息,并且是可训练的参数,然而退火机制的加入影响了参数的更新,因此HAT 引入嵌入梯度补偿,将梯度ql除以退火后Sigmoid 函数的导数,再乘以补偿系数,如式(9)所示:
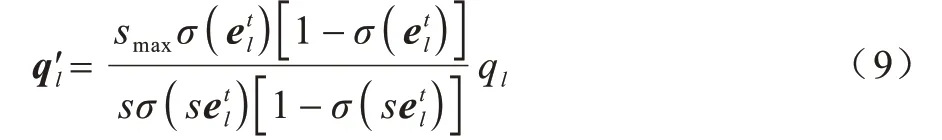
此外,为在学习新任务时保留旧任务已经学到的参数,在学习完任务T并且获得了后,HAT 会按照式(10)递归地计算所有的:

通过对注意力值的比较能够保留对旧任务重要的神经元,并且在学习新任务时起到一定的限制作用。当学习新任务时,根据已有的注意力值对梯度gl的更新进行修改,如式(11)所示:

在全连接层上,梯度首先经过式(11)的处理后,将传递给全连接层,同时梯度补偿接收梯度ql、s和smax,由式(9)计算补偿后梯度传递给任务嵌入。
HAT 反向传播过程如图5 所示。
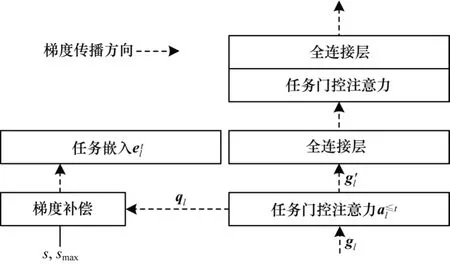
图5 HAT 反向传播过程Fig.5 Procedure of HAT back propagation
2 实验与结果分析
本节将介绍实验中所使用的数据集、评价指标、对比方法等内容并对实验结果进行分析。实验相关源代码参见https://github.com/ws719547997/KRM。
2.1 数据集
文献[21]构建持续学习中文情感分类数据集JD21(https://github.com/ws719547997/LNB-DA),其中包含京东官方网站上21 个不同品类的商品评论,其被视为21 个不同的情感分类任务,在实验中被看作1 个任务序列。在JD21 数据集中,一星~三星的评论被视为负类,四星和五星的评论被视为积极。在JD21 数据集中的评论字数多数为10 字~30字,且消极占比较低,属于不平衡数据集,符合实际情况。JD21 数据集详细信息见表1。
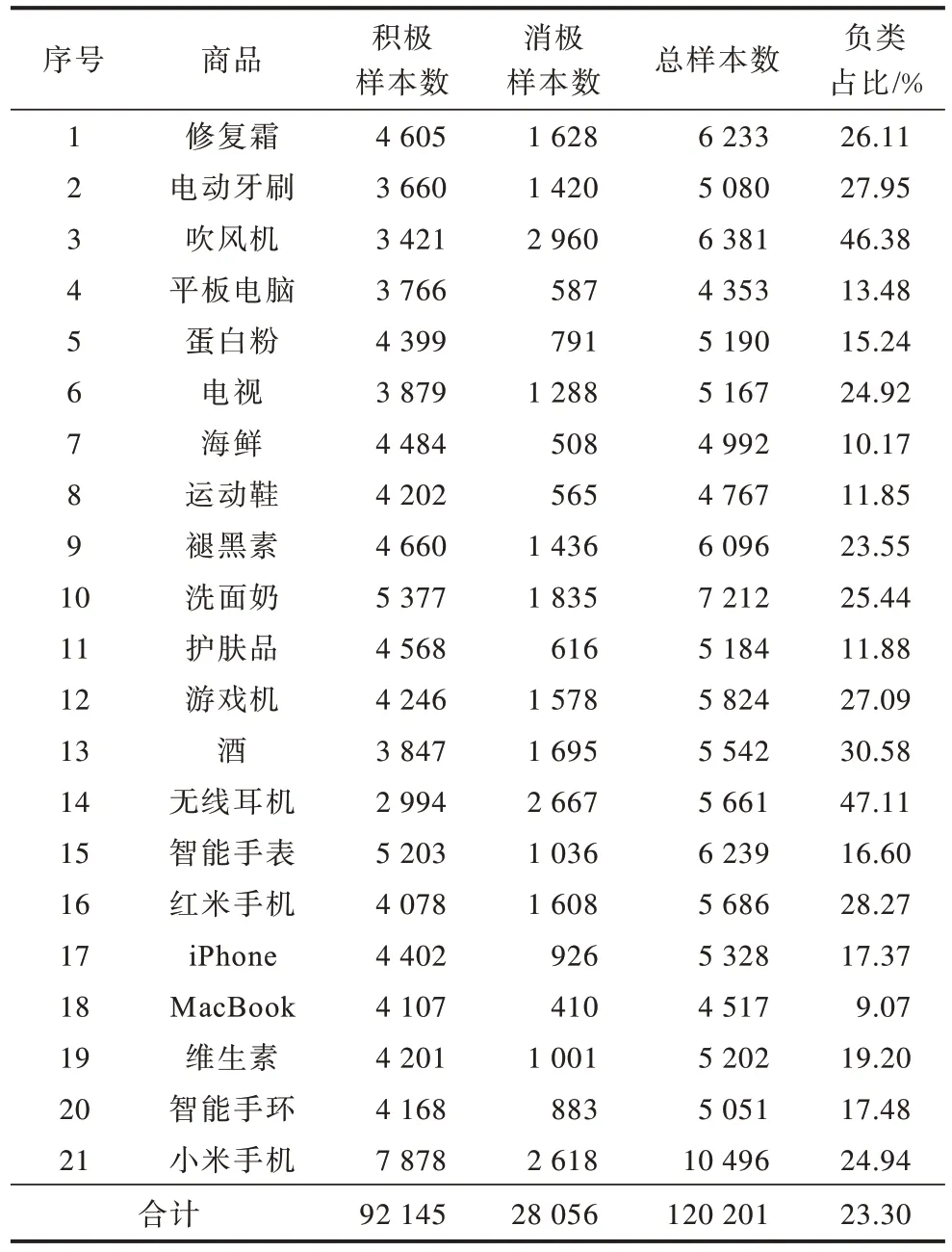
表1 JD21 数据集信息 Table 1 JD21 dataset information
2.2 实验设置
2.2.1 评价标准
为了度量持续学习模型的性能,实验引入准确率矩阵并计算First ACC、Last ACC 和反向转移(Backward Transfer,BWT)指标。假设有一个矩阵R∈RT×T,矩阵中的元素Ri,j表示模型在学习完任务T1至Ti后在任务Tj上的准确率。3 个度量指标定义如式(12)所示:

其中:Ri,i表示模型学习完T1至Ti后在Ti上的准确率;RT,i表示模型学习完全部任务后在Ti上的准确率;First ACC 度量模型首次学习任务时的准确率;Last ACC 度量模型在学习全部学习完成后,在旧任务上的准确率;BWT度量Last ACC 和First ACC 之间的差值,用于评估知识迁移的程度,是持续学习性能评估的重要指标:值越大,说明知识迁移越多,值越低,说明灾难遗忘越严重。根据已有研究,以Last ACC 作为主要评价指标,因为负类占比少,更难分类,所以也使用负类F1 值(F1-NEG)作为参考,计算方法类似于Last ACC。
2.2.2 模型参数
在本文模型中,经实验发现当知识保留网络中Transformer 设置为2 层、知识挖掘网络中全连接层设置为3 层时效果最佳,HAT 参数设置与文献[18]保持一致,其余参数设置与其他对比实验保持一致。
对比实验参数遵从原论文中的设置。TextCNN[25]中3 个卷积核的滑动窗口长度分别为2、3、4,输出通道为100,使用最大池化策略,LSTM[5]隐藏层维度为768,Transformer[24]中有8个注意力头,Q、K、V变换矩阵为64维,全连接层为2 048维。LNB-DA[21]使用Unigram 生成特征。实验使用参数固定的BERT 模型bert-base-chinese(https://hugging face.co/bert-base-chinese/tree/main)的输出作为特征向量。
2.2.3 实验设置
实验采用固定的任务序列顺序,依次学习每一个任务,每学习一个任务都在新旧任务上做一遍测试。待所有任务学习完成后,准确率矩阵R为一个下三角矩阵,根据R计算评价指标。在训练过程中,设置epoch 为50、batch_size 为64,learning_rate 为0.005 并且随训练动态调整。
2.3 实验结果
实验结果如表2 所示,其中:RNN、KRM-RM(Transformer)、MLP-Mixer[26]为非持续学习(Non-CL)方法;LNB 和LNB-DA 基于传统机器学习方法,也被称为终生机器学习方法;MBPA++是一种样本重复方法,只有该方法会对整个BERT 网络参数进行调整,其他方法都是以参数固定的BERT 的输出作为输入;UCL[27]是TCL方法;OWM[28]是CCL 方法;KAN、SRK 都是专门针对持续学习情感分类所提出的方法;HAT、PNN、PathNet 是基于动态网络结构的方法;EWC、LwF、IMM、LFL 是基于正则化的方法;将各个指标中的前三进行加粗。
由表2 可以看出,本文KRM 方法在Last ACC、F1-NEG 上取得最佳值,First ACC 为第三,BWT 为第四,具体分析如下:
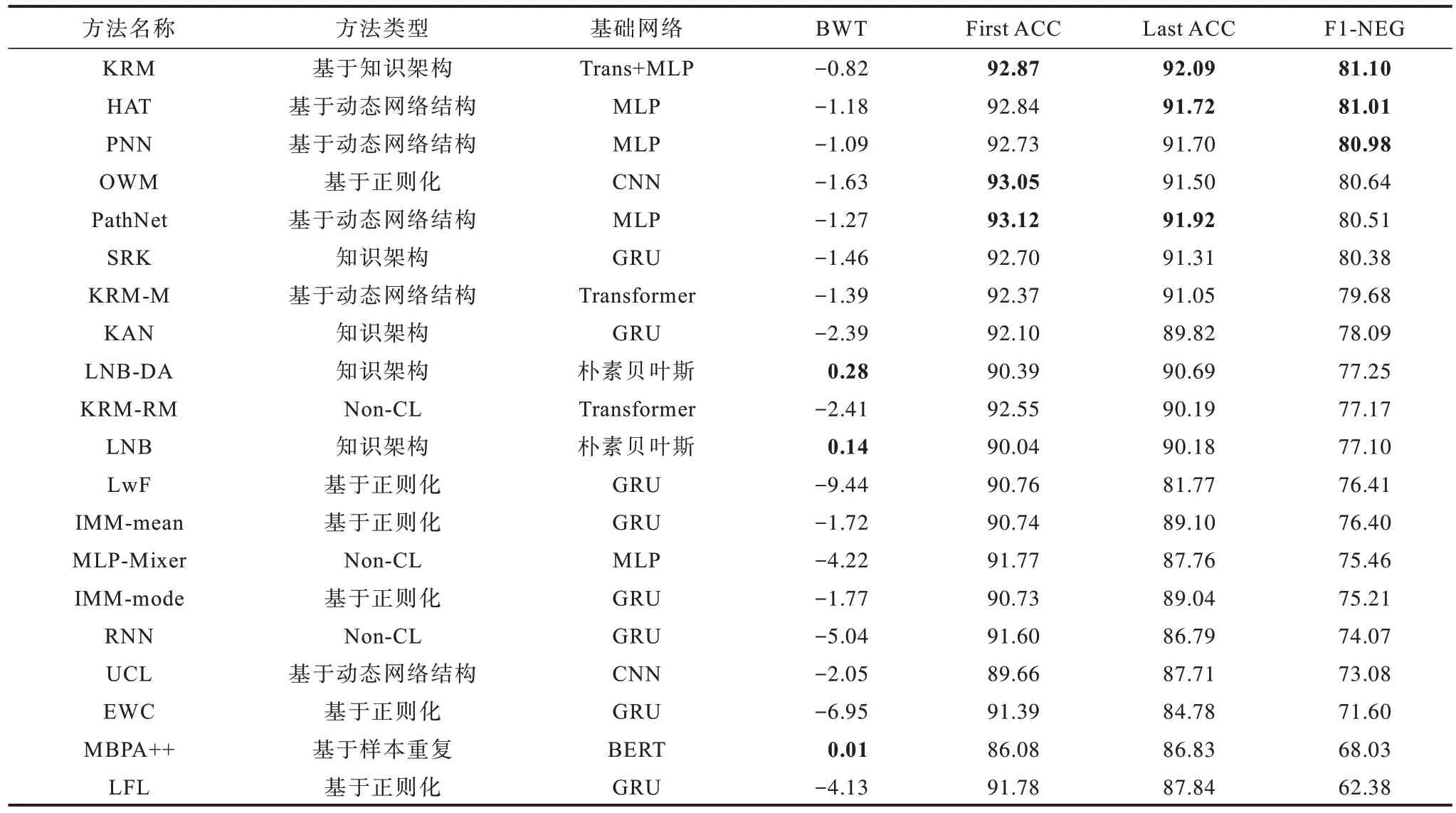
表2 基于JD21 数据集的持续学习方法实验结果 Table 2 Experimental results of continual learning method based on JD21 dataset %
1)通过观察Last ACC 可知,在学习完任务序列中所有的任务后,KRM 在所有旧任务上都保持了良好的分类性能,灾难遗忘的程度较轻。KRM 的Last ACC 和F1-NEG 优于其他对比方法,比HAT 方法提升了0.37 和0.09 个百分点。
2)通过对KRM 删去部分网络得到了两种对比方 法:KRM-RM 和KRM-M,其中,KRM-RM是在KRM 的基础上去除了知识保留网络中的任务自注意力机制与知识挖掘网络,KRM-M 是在KRM 的基础上去除了知识挖掘网络。实验结果表明,和非持续学习方法KRM-RM 相比,KRM 与KRM-M的BWT 分别提高了1.59 和1.02 个百分点,说明了本文方法中的两个网络都对减轻灾难遗忘有帮助,也验证了任务自注意力机制和任务门控注意力机制的有效性。
3)Non-CL 方法在持续学习场景下表现较差,KRM-RM、MLP-Mixer、RNN的BWT分别为-2.41%、-4.22%、-5.04%,神经网络都出现了较为严重的灾难遗忘现象,说明了灾难遗忘现象的存在。
4)LNB 与LNB-DA 是以朴素贝叶斯文本分类算法为基础的学习器,经过分词后直接以unigram 作为特征进行学习,BWT 为正,说明知识迁移的效果超过了灾难遗忘,且占用资源少,训练速度极快,但在准确率等指标上略逊于部分神经网络方法。两种方法均使用知识架构的设计思想,后续方法SRK、KAN 以及本文方法也沿袭了这一设计思路,加入神经网络后这类方法的性能不断提升,是一个很有潜力的研究方向。
5)MBPA++在训练过程中会调整BERT 模型的参数,并在测试时选择部分与测试集相似的样本重新微调网络,因此BWT 为正,且需要明确的任务指示符来指明样本来自哪个任务,但运算时间极长,不太符合情感分类的使用场景。同时需要注意的是,虽然MBPA++效果不佳,但将持续学习方法与预训练语言模型相结合将是未来发展的趋势。
6)基于动态网络结构和基于知识架构的方法性能普遍优于基于正则化的方法,尤其是对比方法中提出较早的LwF、LFL、EWC,虽然此类方法最初提出时使用网络相比BERT 结构相对简单,且任务数量通常为3~5,但是最新的OWM 就具有良好的性能,很多基于正则化的思想也被运用在一些新方法中。在现在的持续学习方法中,通常会将融合多种方法来提升整体模型性能。
3 结束语
本文提出一种基于知识架构的持续学习中文情感分类方法。采用任务自注意力机制,为Transformer中每个任务单独设置注意力变换矩阵,以保存任务特有的注意力参数,实现知识保留。将任务门控注意力机制应用于TextCNN 中的全连接层,为全连接层中每个神经元配置一个开关,以便于根据任务调整网络结构,加强知识挖掘。实验结果表明,该方法的Last ACC和F1-NEG 相比于基于HAT 的持续学习方法提升了0.37 和0.09 个百分点,相比于基于PathNet 的持续学习方法提升了0.17 和0.59 个百分点,灾难遗忘现象相比于同类方法也得到了有效缓解,BWT 仅为-0.82%。下一步可将基于任务自注意力机制、任务门控注意力机制的持续学习方法应用于预训练语言模型的Transformer 编码层中,使模型参数也加入训练过程,进一步缓解灾难遗忘现象,提升知识迁移效率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
数学学习与研究(2017年3期)2017-03-09
第二课堂(课外活动版)(2016年2期)2016-10-21
