
基于图书索书号识别的在架图书错序检测方法*
2023-02-17 09:46王红芳宣静雯
新世纪图书馆 2023年1期
王红芳 武 薛 宣静雯
0 引言
目前,高校图书馆普遍采用藏、借、阅一体化的开放式流通模式,该方式不仅提高了图书资源的流通效率,而且极大地满足了读者对图书资源的多样化和个性化需求,对发挥图书的利用价值起到了积极推动作用[1]。然而,在高校图书馆采用开架阅览的过程中,部分读者在浏览、借阅图书时,由于行为不规范等原因[2],普遍存在乱放错放现象,导致从数据库查询到的图书位置信息与图书在书架上的实际存放位置不一致[3-4],给读者借阅图书带来不便,严重影响了馆藏图书的流通效率和图书馆流通服务质量[5]。因此,借助图像处理和模式识别技术解决在架图书串架错序问题,对提高图书馆的运行管理效率和智能化管理水平具有重要的意义。
随着图书馆开放式借阅的日益普及,以及图书馆藏书量和读者数量的日益增多,图书错架、串架现象也日益严重。尽管现在国内大多数图书馆基本实现了以条形码[6-7]或无线射频技术(RFID)[8-10]结合数据库管理技术为基础的图书管理系统[11],但是依然需要手工方式完成图书上下架、图书错序整理等工作,图书整理成为一项耗时、费力、易错的常规性工作,导致了图书流通过程中人力资源成本的增加。
针对图书馆开放式流通中图书乱架错序问题,不少研究者从如何规范读者图书借阅意识、提高管理者工作热情度方面进行了研究。例如,梁秀玉从乱架因素进行剖析,从提高读者借阅素质、提高图书馆管理者工作水平和合理布局开架阅览室等方面提出了对策[12]。段小娇提出利用计算机统计读者借阅次数,按照图书流通率划分存书区域,以保证区域图书摆放的正确性。尽管以上方法对减少图书乱架具有一定效果,但显著增加了图书管理员的工作量,而且对图书馆馆藏物理空间大小有特殊的要求[13]。徐大芳等人针对图书乱架提出了一种不同颜色的索书号标签表示不同类别的图书的方法[14]。杨军提出了一种结合图书索书号和图书的购买时间的排架方式[15]。陈倩等人提出读者将借阅的图书归还中转书架上统一管理、建立监督图书管理者定期巡架机制、图书馆定期安排讲座活动等多个方法[16]。尽管上述方法在一定程度上减少了图书乱架现象,但仍然解决不了图书乱架的根本问题。
此外,研究者们也提出通过改善图书馆基础设施的方法解决图书馆图书乱架问题。康洪雷等人提出利用移动设备采集在架图书图像,利用LSD算法检测书脊边缘,并通过投影分离出索书号区域中字符,然后使用CNN网络对字符进行识别,并结合图书管理系统实现错序检测[17]。方建军等提出了一种基于HSV空间分布特征与霍夫变换结合对书脊边缘检测、图书索书号提取分割的算法[18]。苏志芳等人根据图书书脊图像特点,利用机器视觉技术和无线网络传输技术,设计并实现了一种基于嵌入式的图书乱架识别系统[19]。上述方法能较好地实现对一般索书号在架图书较好的错序检测,为图书馆图书的自动化整理提供一种可行的方案。然而,这些方法涉及的经验阈值较多,检测性能受环境因素和采集图像质量的影响较大。
本文在研究已有图书乱架检测方法的基础上,通过移动设备获取图书馆在架图书图像,首先使用Canny边缘检测和概率Hough变换直线检测方法,实现单本图书的书脊检测与分割;然后在HSV颜色空间实现对索书号标签区域的分割,最后使用光学字符识别技术识别索书号,通过在架图书的索书号排列规则进行错序分析,并标记错序图书在书架上的位置。本文方法能应用到图书馆在架图书错序检测系统中,对构建基于巡架机器人的图书乱架清点系统具有重要的应用价值。
1 书脊检测与分割
书脊检测与分割是实现图书串架检测的第一步,如图1是书脊的检测与分割流程图。首先,通过移动图像采集设备获取在架图书图像,然后对在架图书图像进行灰度变换、图像增强等预处理后,采用Canny边缘检测算法检测书脊边缘信息,然后对边缘检测结果进行概率Hough变换,提取书脊边缘直线信息后,再对提取的边缘直线进行过滤处理,得到正确的书脊边缘直线,最后根据书脊边缘直线分割出单本书脊,并完成在架图书的数量统计。

图1 书脊的检测与分割流程图
1.1 书脊检测
为实现图书索书号的识别,首先需要实现图书书脊区域的检测。利用边缘检测算法可以有效提取图书书脊边缘,从而实现对索书号区域的准确分割。常用的边缘检测算法有Roberts边缘检测算子、Sobel边缘检测算子、Prewitt边缘检测算子、LOG边缘检测算子和Canny边缘检测算子。如果像素点是边缘上的点,那么该点在灰度导数中表现为一阶的局部极值和二阶的零交叉点。为了避免噪声影响,提高微分运算获取边缘的可靠性,对采集的彩色图书图像首先进行灰度化和中值滤波预处理操作。由于Roberts、Sobel和Prewit算子均属于一阶边缘检测器,如果计算出某个像素点的一阶导数大于某一阈值,就认为是边缘点,因此这三种边缘检测子对噪声比较敏感,容易将边缘信息误认为是噪声,不利于后续的书脊分割。相比而言,LOG边缘算子引入了高斯滤波和各向同性的拉普拉斯两阶差分算子,对噪声具有较好的鲁棒性,而Canny边缘算子是在LOG边缘算子基础的一种更有效的边缘检测方法,边缘检测效果更好[20]。本文使用Canny边缘检测算子进行书脊边缘的检测。
在完成图书书脊边缘提取后,采用概率霍夫变换(Probability Hough Transform)算法实现对书脊边缘的提取。概率霍夫变换是在霍夫变换直线检测的基础上实现线段的查找,它对图像中的一些长的线段分割效率较高,并能够检测到每个线段的起点和终点,有利于提取准确的书脊边缘。
1.2 书脊分割
对于实际的在架图书,同一书脊线通过概率霍夫变换检测出来的书脊边缘往往由多个不连续的边缘直线组成。而且笔者在实验中发现,利用概率霍夫变换检测到的直线段位置是随机排列的,因此需要将检测出的直线进行排序、过滤和合并,以实现单本图书书脊的准确分割。为此,先将检测的直线按照起点或终点的行坐标进行排序,然后设定线段间隔阈值,如果相邻两条线段的水平间隔小于该阈值,可将这两条线段合并成一条直线,否则不做处理。通过对书脊边缘直线滤除,能有效滤除无效的书脊边缘,从而获得更加准确有效的书脊边缘区域。
在对图像进行预处理、书脊边缘检测、书脊边缘提取等一系列处理后,最后对单本书脊进行分割。书脊分割结果如图2所示。由图2书脊分割结果可知,当确定单本书脊的左右边缘位置后,可以根据书脊左右两边缘线段的起点和终点坐标对原图像进行裁剪,实现单本书脊逐一分割,然后将分割出的单本书脊整齐排列到一张白色图像上,并统计分割的书脊数量,生成所需要的书脊分割图像。

图2 书脊分割结果
1.3 索书号区域定位
在分割出单本书脊图像后,接下来需要定位图书书脊下方的索书号区域,然后识别索书号字符,并根据识别出的索书号进行错序分析。索书号标签分割流程图如图3所示。依照索书号标签分割流程,首先获取书本索书号标签的红色边缘图像,然后获取红色边缘图像的色调H通道和饱和度S通道,接着分别计算H通道和S通道的灰度直方图,根据灰度直方图确定H通道和S通道的阈值范围,然后根据阈值确定索书号标签的位置分割出索书号标签区域,然后识别索书号字符,并根据识别出的索书号进行错序检测。
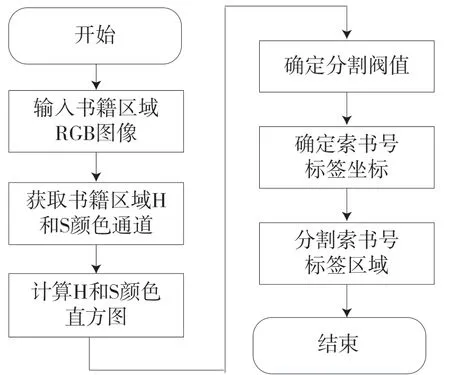
图3 索书号标签分割流程图
在获得图书书脊分割结果后,针对分割出的书脊进行感兴趣区域定位,感兴趣区域(Regions of Interest,ROI)是进一步处理的重点关注目标区域。本文的感兴趣区域即是索书号标签区域,能否准确地提取索书号标签区域,直接影响索书号识别的准确度。目前,ROI提取算法很多,常用的算法有HSV颜色空间算法、卷积神经网络提取算法、形态学定位算法。由经验可知,一般情况下,索书号标签区域都有其固定的特征,如颜色、形状、尺寸、位置等。以西安工程大学图书馆藏书为例,通常索书号标签上下各有一条红色边线,索书号字符为黑色,背景颜色为白色,二者颜色相差较大,索书号宽高比有一定比例等特征,这些都是分割索书号标签区域的先验信息[16]。根据这些先验特征信息,由于颜色分量R、G、B之间的相关性较高,而H、S、V能较好地反映人眼对颜色的主观感受,为保证后续识别效果,本文将分割出的RGB书脊图像变换到HSV颜色空间提取索书号标签区域。在HSV颜色空间,色调分量H和饱和度分量S反映了色彩的本质特性,而V分量反映图像的亮度,因此可以分析书脊区域H分量和S分量的颜色直方图确定分割阈值,以消除图像亮度变化对索书号区域分割的影响。
为了确定索书号标签区域,本文对方建军等人提出的索书号标签区域直方图统计方法[18]加以改进,通过对大量索书号标签的上下红色边线进行直方图统计确定分割阈值。利用直方图确定红色标签的色调分量H和饱和度分量S的值域,从而确定H分量和S分量取值范围,进而提取得出索书号标签区域。为了确定H分量和S分量的具体阈值范围,需要对大量的索书号标签的红色边线进行灰度直方图统计,选出出现频率高的公共区间,即为某一分量的阈值范围。以色调H为例,对大量的索书号标签的红色边线的H值进行排序,得到颜色分布直方图,选出分布概率较高的区间作为H分量的值域。采用类似方法可得到S分量值域[18]。通过上述的直方图统计方法确定索书号区域的H、S分量的阈值范围如表1所示(以西安工程大学图书馆图书索书号标签颜色特征为例)。

表1 索书号标签HSV分量阈值范围
将RGB图像转换成HSV图像后,对在阈值范围内的图像区域置为1,即为白色,阈值范围外的目标图像置为0,即为黑色。在黑色的背景下更容易提取到索书号标签的准确位置。通过确定索书号标签位置,再通过边缘坐标将索书号标签切割出来。索书号标签的分割结果如图4所示。可以看出,索书号上下边缘所在位置为白色,其余部分为黑色,根据白色像素的位置即可确定索书号位置,从而实现索书号标签区域的正确分割。

图4 索书号区域分割结果
2 索书号识别与错序检测
2.1 索书号识别
将分割出的索书号标签作为输入图像,利用pytesseract库对图像中的字符进行识别[20]。pytesseract能够从图片中识别和“读取”其中嵌入的字符。字符识别结果如图5所示。

图5 字符识别结果
2.2 索书号错序检测
在识别出索书号字符后,计算每个字符对应的ASCII码,逐位比较当前索书号与相邻前一索书号对应位置的ASCII码的大小。若相邻前一索书号的ASCII码小于等于当前索书号的ASCII码,则继续比较下一位ASCII码,直到所有位ASCII码比较完成或出现相邻前一索书号的ASCII码大于当前索书号的ASCII码为止。如果所有位的ASCII码都满足相邻前一索书号的ASCII码小于或等于当前索书号的ASCII码,则相邻前一本书与当前书位置正确,否则可以判断当前图书在书架上的排放发生错序。同理,可以使用相同的方法判断当前图书与相邻的后续图书的排序关系,后续图书的索书号的ASCII码必须大于或等于当前索书号的ASCII码。当且仅当书架上的所有图书满足“前者索书号<=当前索书号<=后者索书号”的条件,则说明当前书架上的图书摆放位置正确,否则存在错序。错序检测过程如图6所示。

图6 错序检测过程
3 结果分析
为进一步验证本文方法对实际在架图书是否存在错序的检测效果,使用Pycharm中PyQt5工具设计Windows平台下的应用程序,利用OpenCV-Python4.4.0版本和pytesseract库实现所有算法。利用移动手机图像采集设备获取50幅西安工程大学图书馆在架图书图像进行验证实验,每幅图像采自同一书架的一排图书。表2是实验中测试图像的测试结果。
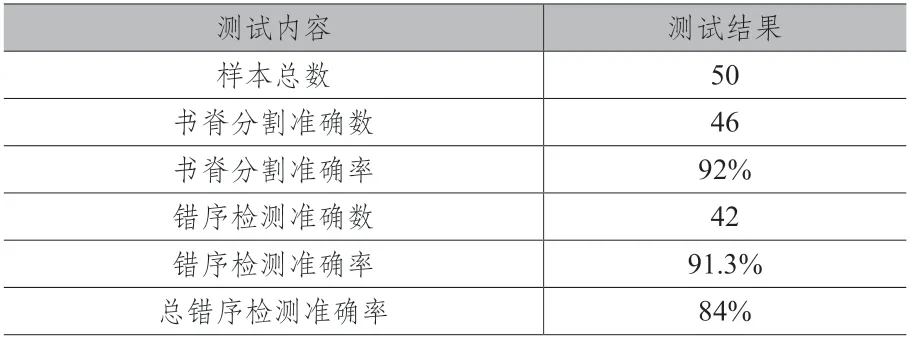
表2 测试结果
由表中结果可以看出,对采集的50张在架图书图像进行测试,成功分割出单本书脊图像的有46张,书脊分割准确率达92%,能正确检测出图书错序信息的有42张,总错序检测准确率为84%,能够满足本系统的设计要求。
对书架上排放错序的图书,检测时系统自动使用红色的矩形框标记出它在书架上的位置,以方便图书管理员快速定位错序图书的位置并进行整理。尽管本文方法正确检测出图书错位的情况较多,但也存在少数错误检测的情况。错误检测主要存在漏检和错检两种情况,其原因在于通过手机采集的在架图书图像分辨率不高,如果不能正确识别出图书的索书号,则会导致错序分析失效而发生误判。因此,本文设计的图书错序检测方法的性能在一定程度上依赖于采集的书架图像的质量,采集的图书图像质量越高,分割得到的索书号区域图像就越清晰,索书号的识别准确率就越高,发生错判的概率就越低。
4 结语
本文提出了一种基于索书号识别的图书串架检测方法,该方法首先利用边缘检测和霍夫变换直线检测算法获取在架图书书脊边缘并分割图书图像,然后利用颜色直方图特征定位并分割出图书书脊上的索书号区域,并采用光学字符识别识别索书号。最后,通过对识别出的索书号进行错序分析,从而判断书架上排放的图书是否存在错序情况。
尽管本文方法取得了较好的检测效果,但仍存在不足之处,有待进一步研究与完善,主要包括以下三个方面:(1)在架图书图像是由人工通过手机采集,因而图像质量不稳定。在实际应用中,可以利用安装在云台上的高清晰摄像头自动采集在架图书图像,然后利用网络传输到计算机中进行分析,从而使系统对工作环境具有更好的适应性。(2)实验中,采集的在架图书摆放整齐,但实际图书馆中的图书并不全都整齐摆放,对于存在摆放倾斜的图书,该系统不能有效检测。因此,需要进一步完善书脊检测算法,通过倾斜检测与校正算法,保证检测算法的鲁棒性,从而提高系统的实际应用能力。(3)对索书号进行识别时,有些索书号出现误识现象,其原因主要在于采集的在架图书图像的质量不高。一方面,可以在采集图像时应利用专门的高清晰度图像采集设备获取高质量图像;另一方面,可以改进索书号识别算法,增强检测算法对低质量图像的识别能力。
猜你喜欢
阅读(高年级)(2020年8期)2020-11-06
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
通信产业报(2016年44期)2017-03-13
文体用品与科技(2016年7期)2016-06-15
公民与法治(2016年10期)2016-05-17
文体用品与科技(2016年3期)2016-03-24
少儿科学周刊·少年版(2015年2期)2015-07-07
环球时报(2009-12-04)2009-12-04
雕塑(1999年2期)1999-06-28
