
基于CEEMDAN与KFCM聚类的转辙机退化状态识别方法
2023-02-15 18:50张友鹏魏智健
中国铁道科学 2023年1期
张友鹏,张 迪,杨 妮,魏智健
(1.兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070;2.武汉地铁集团有限公司 武汉地铁运营有限公司,湖北 武汉 430070)
随着铁路线路数量、运营里程以及行车密度的不断增加,铁路信号设备在保证行车安全和提高行车效率方面发挥着越来越重要的作用。转辙机作为铁路信号设备室外三大件之一是重要的线路转换设备,它通过缺口检查、判断尖轨与基本轨是否密贴以确保列车安全通过道岔。由于转辙机安装于室外,受雨雪等各种自然条件及震动、冲击等外界因素的影响较大,其故障率在铁路信号设备中居高不下。据统计发现,道岔转换设备故障占所有信号设备故障总数的40%以上[1]。目前,铁路现场主要通过设备周期性巡检以及电流曲线和功率曲线对道岔状态进行人工分析,这些方法都依赖于工作人员的现场经验,易造成道岔设备维修不足或维修过剩等问题[1]。在理论研究方面,对于转辙机状态的研究主要集中于故障状态的诊断以提高诊断的速度和准确率,而关于转辙机在使用寿命内由正常到失效整体状态的研究还较少。因此,有必要对转辙机的退化状态展开研究,为现场设备的维护与更换提供参考意见,从而降低故障发生的概率。
国内外学者在提高转辙机故障诊断的准确率和效率方面取得了一些研究成果。2015 年,肖蒙等人[2]提出一种基于粗糙集的高效贝叶斯网络故障诊断模型,由推理算法求解各类故障发生的概率。2016 年,Vileiniskis 等人[3]通过单类支持向量机(OCSVM)方法对道岔转换设备故障进行分类诊断学习,建立完整的故障诊断模型。2018 年,黄世泽等人[4]采用比较待测电流曲线与模板电流曲线弗雷歇距离的方法,根据相似度函数进行故障模式诊断。这些学者将转辙设备故障数据与机器学习算法相结合,能够对转辙机各类故障进行准确识别。但是以上研究只能将转辙机状态简单划分为正常和故障2 种状态,无法描述转辙机由正常到故障的整个退化过程,难以实现对故障的超前预判。
因此,一部分学者开始在转辙机退化状态识别与故障预测领域展开研究。2017 年,伏玉明等人[5]采用模糊综合评判法对转辙机健康状况进行综合评估。2018 年,戴乾军等人[6]将转辙机的退化过程按照全生命周期进行划分,利用动态粒子群算法优化隐半马尔科夫(HSMM)模型,实现对转辙机的故障预测。2019 年,候大山[7]将道岔设备故障分为突发故障和缓变故障,针对缓变故障构建性能退化指标并搭建缓变故障预测模型。2020年,高利民等人[8]利用自组织特征映射神经网络(SOM-BP)对转辙机功率曲线特征参数进行多次聚类学习,得到6 种转辙机退化样本数据,实现对道岔设备退化状态的识别。以上文献虽然对转辙机退化状态进行了划分,但仍存在评估过程中参考相关专家经验,导致评估结果具有一定的主观因素,且退化特征之间缺乏相关性分析,无法表征转辙机寿命退化的整个过程。2022 年,武晓春等人[9]提出一种基于小波包分解与GG 聚类相结合的退化阶段划分方法,构建退化性能指标;魏文军等人[10]将转辙机运行状态分为健康、亚健康、故障、严重故障4 种类型,但相关文献都没有明确转辙机退化状态识别相对应的转辙机故障类型。目前关于转辙机退化状态的相关研究仍然较少。
本文提出一种自适应白噪声完备经验模态分解方法(Complete Ensemble Empirical Mode Decom⁃position with Adaptive Noise,CEEMDAN)与核模糊C 均值聚类(Kernel-based Fuzzy C-Means clustering,KFCM)相结合的转辙机退化状态识别方法,通过CEEMDAN 算法选取各固有模态函数(Intrinsic Mode Functions,IMFs)分量的能量密度作为特征向量集,并通过KFCM 算法进行无监督聚类,从而实现对转辙机转换过程中阻力异常退化状态阶段的准确划分,对转辙机故障由正常到退化的整个过程进行描述。
1 转辙机功率曲线
信号集中监测系统(CSM)是监测铁路信号设备状态的综合监测平台,可以实时记录设备数据,为铁路现场维护工作提供参考依据[11]。CSM通过道岔采集单元对转辙机动作过程中的电流、电压、功率等数据进行实时采集。
1.1 功率曲线数据来源
交流转辙机数据采集主要通过在A,B,C 三相电路中并联电压采集配线、串联电流采集互感器得到转辙机动作过程中相应的电压和电流值,并将电压、电流输出至功率采集单元经过隔离采样、A/D 转换、编码传输后输出转辙机动作过程中的功率值[12]。
三相交流转辙机采集系统示意图如图1 所示。图中:1DQJ 和1DQJF 分别为转辙机1 启动继电器和1 启动复示继电器,采集系统通过断相保护器(DBQ)前级端子11,31 及51 点的配线采集三相电路电压;三相电流采集互感器采用互感方式穿芯采集三相电路电流。

图1 三相交流转辙机采集系统
完成电压、电流采集后,功率采集单元每40 ms 计算1 次有功功率,将动作过程中的采样点顺次记录形成电流曲线和功率曲线。由于电流曲线只能反映转辙机动作过程中电流值的变化情况,而功率曲线不仅能反映三相电流电压值的大小,更能反映转辙机转动过程中的阻力变化,所以选择转辙机功率曲线数据作为数据源。
1.2 正常动作功率曲线
同一个转辙机正常转动过程中4 个不同时刻的功率曲线如图2 所示。由图2 可以看出:4 条功率曲线都表示道岔能够无故障正常转换到位,但不同时刻的4条正常功率曲线并不相同,存在一定的差异;在转辙机正常转动过程中,启动解锁阶段由于三相电动机转动克服较大阻力,所以功率值急剧上升,阻力大小不同则功率峰值会有所不同;4 条曲线功率峰值依次为2.514,2.230,2.358 及2.488 kW,若在启动阶段道岔尖轨与基本轨之间密贴太紧而解锁不良,可能会出现启动功率过高的现象,若道岔密贴不足启动功率过低,或信号集中监测系统40 ms 的采样周期无法捕捉到转辙机启动解锁的峰值,避开了峰值采集点,又可能会造成功率曲线峰值的消失[10]。在转换阶段,转辙机动作杆拉动道岔尖轨到达指定位置,正常情况下道岔转换过程平稳,正常的转辙机功率曲线应较平直。但若道岔转换过程中由于滑床板缺油等情况引起转换阻力异常,从而导致道岔转换受阻。滑床板摩擦阻力的大小与转辙机动作功率曲线的波动程度具有相关性,功率曲线的波动程度反映了转辙机转换期间所受摩擦阻力的大小变化,具有退化过程[13-14]。若发现转辙机转换阶段功率值发生偏差而不及时调整,可能会导致道岔无法正常转换[15]。

图2 不同时刻正常动作功率曲线
大部分故障发生前,功率曲线虽会出现异常波动但与正常曲线无明显差异,监测人员可能会忽略这些细微的变化而错过最佳维修时间。若直至道岔出现故障才进行维修,不但增大维修成本,而且可能会影响行车安全与行车效率。如果对具有退化趋势的故障进行退化状态识别研究,进行针对性维修,可以提高铁路现场在日常维护中的维修效率。
2 特征提取
2.1 CEEMDAN算法
EMD(经验模态分解,Empirical Mode De⁃composition)将原始信号按照高频到低频的顺序分解为一系列固有模态函数,从而反映非平稳信号的局部特征。但EMD 在分解过程中会出现模态混叠的现象,对信号分解产生干扰。为了克服模态混叠,EEMD(集成经验模态分解,Ensemble Em⁃pirical Mode Decomposition)对原始信号添加高斯白噪音,利用EMD 滤波器的二元滤波器组特性填充整个时频空间以减少模态混合,但是EEMD 在对信号加噪的过程中可能会产生一定的虚假分量,影响后续的信号分析。为此,CEEMDAN在EEMD的基础上加以改进,在每次分解中加入成对的高斯白噪声并进行平均运算,解决白噪声从高频到低频的传递问题,从而抑制模态混叠和假分量的产生,更适用于对非线性、非平稳信号进行时频分析,而转辙机功率曲线信号非线性、非平稳的特点与CEEMDAN 算法的适用范围相匹配,因此选择CEEMDAN提取转辙机功率曲线信号特征。
CEEMDAN算法计算过程如下。
(1)用k表示第k阶模态分量,k=1 时,令转辙机功率曲线信号p(t)=r0(t),r0(t)为待分解信号,向p(t)中添加高斯白噪声Ni(t),添加i(i=1,2,…,I)次得到叠加信号xi(t)为

(2)对xi(t)进行EMD分解,获得I个IMF分量c0i(t)。
(3)对c0i(t)集合平均得到第1 阶IMF 分量c1(t)为

(4)计算第1阶余量r1(t),计算式为

(5)向1 阶余量中继续添加i次白噪声E(Ni(t)),得到新的待分解信号Yi(t),计算式为

(6)对Yi(t)进行EMD 分解得到IMF 分量c1i(t),并集合平均得到第2 阶IMF 分量c2(t),计算式为

(7)当k=2,3,…,K时,第k阶余量rk(t)计算式为

第k+1阶IMF分量ck+1(t)计算式为

(8)将k依次递加,重复步骤(5)—步骤(7),当余量为单调函数时停止分解,得到最终分解结果为
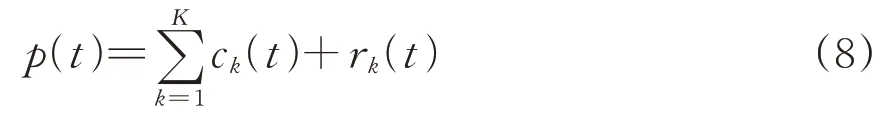
2.2 CEEMDAN能量熵
信号在不同频率下能量幅值会发生相应的变化,为了反映这种变化,可以在CEEMDAN 分解之后计算各IMF分量的能量分布[16]。
通过对非线性信号进行CEEMDAN 分解可以得到T个IMF 分量,通过熵值计算可以得到相应的能量E1,E2,…,ET。假设最后分解余量忽略不计,由CEEMDAN 分解的正交性可知,分解后的IMF 分量能量之和等于原式功率信号的总能量,从而得到功率信号在频率域上的能量分布。CEEMDAN能量熵HEN定义为

其中,
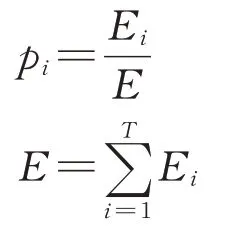
式中:pi为第i个本征模函数的能量占总能量E的比重;Ei为第i个本征模函数的能量。
3 退化状态聚类识别
3.1 KFCM算法
转辙机结构复杂,其退化过程具有模糊、随机的特点,且其功率信号非平稳非线性。KFCM 算法为无监督聚类算法且核函数的引入更适用于处理非线性数据,具有在没有人为干预条件下通过数据特征寻找潜在数据结构[17],从而将数据划分为不同退化阶段的能力,可以很好地解决转辙机功率数据退化阶段划分的问题。
KFCM 算法通过核函数将数据通过非线性映射Φ:X→H:Φ(x)=y,将特征映射至高维特征空间,由高维特征空间的线性函数对数据集进行划分,相比于FCM 算法能够更精确地进行样本聚类。
(1)给定原始特征数据集X,聚类个数c,收敛精度ε,由FCM算法初始化聚类中心v0;
(2)定义vi(i=1,2,…,c)为第i个聚类中心,uij(i=1,2,…,c;j=1,2,…,n)为第j个样本第i类的隶属度函数,KFCM目标函数为

式中:U={uij};v={v1,v2,…,vc};m为加权指数;为Φ(xj)到Φ(vi)之间距离的平方;K(xj,vi)为高斯核函数;σ为平滑程度参数。
(3)由拉格朗日乘子法得到U,v的迭代表达式为

3.2 聚类效果评估
为了分析KFCM 算法分类的准确度,采用分类系数F和平均模糊熵H进行聚类效果评估。

分类系数为隶属度的均方值,F越接近1,聚类效果越好。
平均模糊熵反映了隶属度分布所蕴含的信息熵的大小,H越接近0,聚类效果越好。
3.3 转辙机退化状态划分
以S700K 转辙机退化状态为研究核心,以其使用寿命内功率曲线数据为研究对象,构建转辙机退化状态识别模型,具体流程示意图如图3 所示。首先通过CEEMDAN 算法将功率曲线数据展开为多个IMFs,根据其能量密度获得特征向量集;其次由KFCM 聚类算法进行转辙机退化状态划分;最后通过分类系数和平均模糊熵对KFCM 算法聚类效果进行综合评估,证明所提方法的有效性。
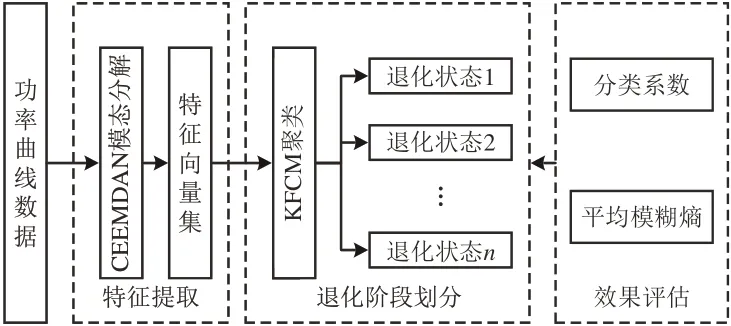
图3 退化状态划分示意图
4 试验验证及结果分析
4.1 特征提取
为验证基于CEEMDAN 算法与KFCM 聚类算法进行转辙机退化状态研究方法的可行性,对某铁路公司1 台发生转换阻力异常故障的转辙机进行研究,向前回溯该发生故障的转辙机3 个月内的正常动作功率曲线数据共434条进行分析验证。
由CSM 采集的转辙机动作过程功率曲线作为数据源,通过CEEMDAN 算法进行模态分解并得到能量熵特征。相关系数越大,与原始信号的相关性越高,越能反映原始信号的物理信息,所以通过计算各IMF 分量的相关系数大小确定IMF 分量的个数为8 个。由于每组数据前6 个IMF 能量幅值较高,第6 个以后的能量幅值很小,所以选取前6 个IMF 分量的能量熵作为退化状态识别数据特征集见表1。
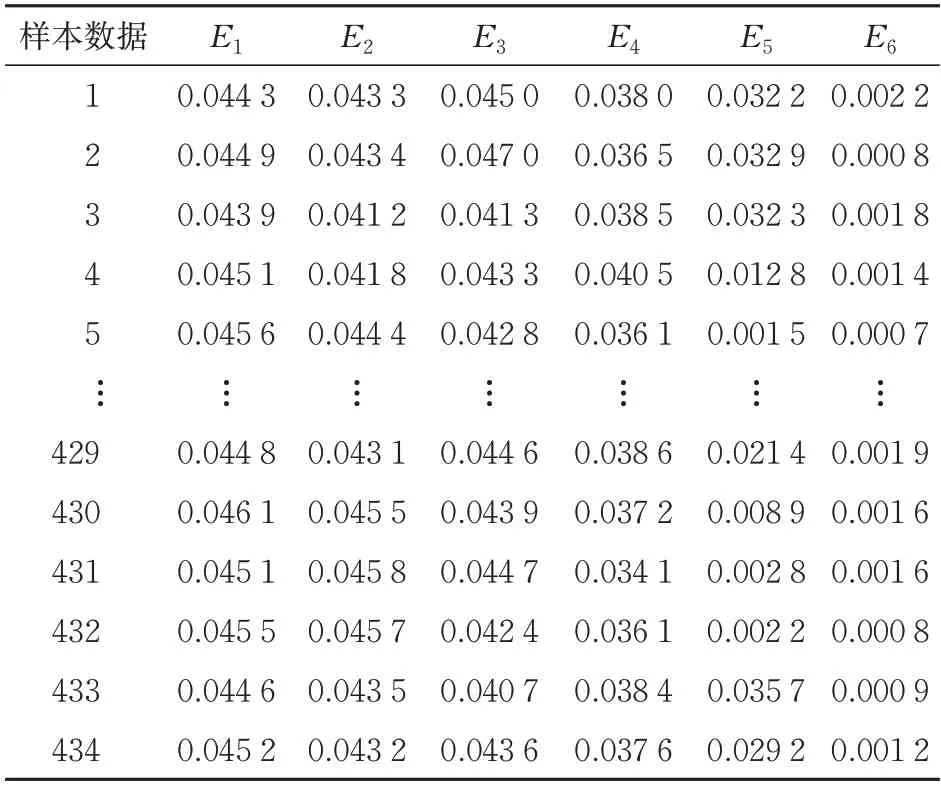
表1 特征参数数据集
4.2 退化状态划分
通过KFCM 聚类算法对转辙机从正常到失效的整个过程进行研究,由退化状态研究各类参考文献[9,18]可知,退化状态通常划分为3~5 个退化阶段。本文将CEEMDAN 分解得到的特征向量进行PCA 降维后得到二维特征向量A1,A2,通过KF⁃CM 聚类算法对于聚类数目c分别取3,4,5 时进行无监督聚类,KFCM 参数设定为:m=2,ɛ=0.000 01。KFCM 聚类图如图4 所示。图中:P1和P2分别为聚类中心的横坐标与纵坐标;红色圆圈为聚类中心。由图4可知:当c=4时,聚类簇之间的间隔更大,聚类划分效果更好。通过分类系数和平均模糊熵对于c分别取3,4,5 时的聚类效果进行评估,结果见表2。
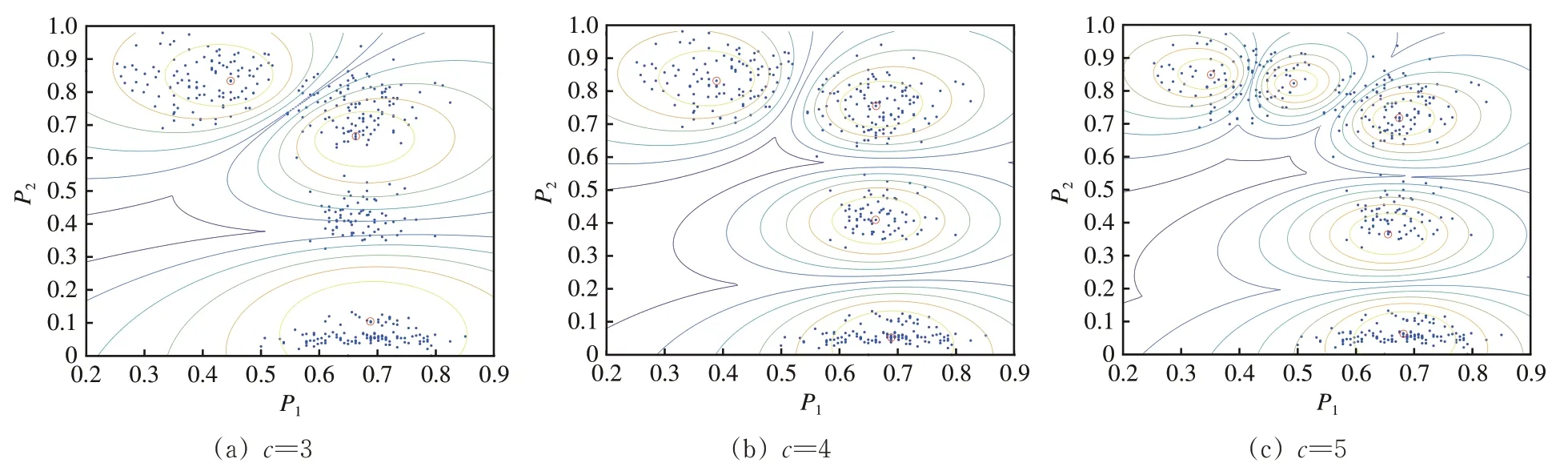
图4 KFCM 聚类等高线图

表2 聚类效果评估分析
由表2 可知:当c=4 时分类系数为0.956 2,更接近1,平均模糊熵为0.056 1,更接近0,因此c=4 更能展示不同退化状态之间的特征差异,同种特征之间的差异也最小,所以分为4类时的聚类效果最好。
通过现场调研并与相关技术人员交流沟通,将转辙机的4种退化过程划分为正常、轻微退化、中度退化、严重退化4个阶段,并通过聚类结果对该转辙机各个退化阶段的功率曲线进行分析以证明该聚类算法的有效性,各个退化阶段的功率曲线如图5所示。
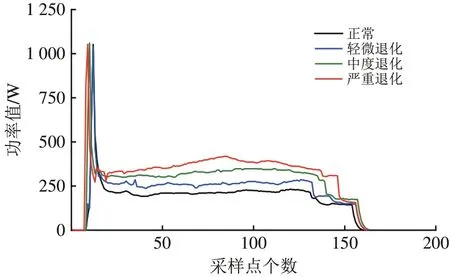
图5 S700K转辙机各退化状态功率曲线
由图5 可知:正常状态转辙机功率曲线较平稳;轻微退化状态功率曲线会产生小幅度波动;中度退化状态功率值明显高于轻微退化状态;而严重退化状态转辙机因为受摩擦阻力较大而在转换阶段出现了明显凸起,与聚类结果一致。
4类状态聚类中心坐标见表3。
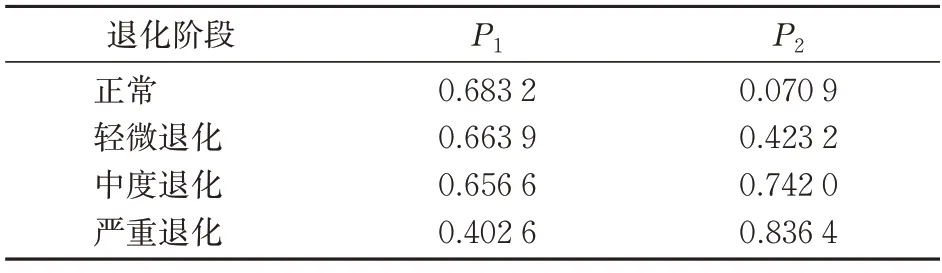
表3 KFCM聚类中心坐标
为了验证本文所提方法的有效性,除去训练聚类模型所用到的434 条转辙机正常转换功率曲线数据,从故障发生前3个月的转辙机功率曲线数据中继续等间隔抽取100 条使用寿命内转辙机功率曲线数据构成测试数据集,对聚类模型的聚类准确性进行分析验证,最终测试样本的分类准确率达到95.6%。由于测试数据集中有小部分样本数据位于2 种退化状态的边界位置,对于2 个聚类簇的隶属度都不高,难以界定属于何种退化状态,对于分类准确度有一定的影响,所以仍有4.4%的数据未能准确识别。
不同聚类算法在聚类数目c=4 时的聚类识别结果以及相应的分类系数与平均模糊熵见表4。通过选择在退化状态识别领域应用较广泛的FCM 算法[19]和GK 算法[20]进行比较分析。由于FCM 算法对初始聚类中心较敏感,GK 算法对于球类数据聚类更加有效。由表4 可知:相较于FCM 算法和GK 算法,KFCM 算法聚类效果更佳,具有一定的优越性。

表4 不同聚类方法退化状态识别比较
5 结语
针对S700K 交流转辙机运行状态与其动作功率曲线之间的关系,提出时频分析与能量熵相结合的S700K 转辙机退化状态核模糊聚类分析方法。该方法以转辙机转换过程中阻力异常故障的退化发展过程为具体研究对象,根据转辙机在不同性能退化状态下功率信号能量分布的差异,利用CEEM⁃DAN 将非线性功率曲线数据分解成不同的IMF 分量,并根据IMF 分量的能量密度获得特征向量集,实现转辙机功率曲线典型特征信息的表征,并在S700K 交流转辙机退化状态聚类识别过程中采用KFCM 无监督聚类算法进行聚类,降低主观经验对于聚类结果的影响,无需对模型进行训练即可实现退化状态识别。
试验结果表明该方法能够较好地划分转辙机性能退化各个阶段的不同状态,识别准确率达到95.6%,对于铁路现场转辙设备的故障预判以及维修维护具有一定的指导意义。
猜你喜欢
基层中医药(2021年12期)2021-06-05
铁道通信信号(2020年3期)2020-09-21
铁道通信信号(2020年1期)2020-09-21
铁道通信信号(2020年10期)2020-02-07
智族GQ(2019年9期)2019-10-28
铁道通信信号(2019年3期)2019-04-25
铁道通信信号(2018年10期)2018-12-06
铁道通信信号(2018年10期)2018-12-06
英美文学研究论丛(2018年1期)2018-08-16
铁道通信信号(2016年6期)2016-06-01
