
基于注意力机制的手语语序转换方法
2023-02-09 01:49张哲岩王青山
合肥工业大学学报(自然科学版) 2023年1期
张哲岩,王青山
(合肥工业大学 数学学院,安徽 合肥 230601)
根据世界卫生组织最新的抽样调查[1],超过4.66亿人因听力受损而导致残疾。到2030年,预计将有近6.3亿人存在听力障碍问题,到2050年,这个数字可能会超过9亿。这些听障人士在日常生活中通常存在沟通障碍,导致其不能像健全人那样方便地学习、生活和就医等[2-4]。因此,准确理解手语对于听障人士与社会的正常交流是至关重要的。
文献[5]通过一系列的实验研究发现,听障学生在句子表征、局部连贯、整体连贯性上都不如健全学生。通过对听障人士手语和正常书面语比较[6],发现大部分听障人士的手语转化成书面语后虽然能够表达出关键词语,但句子语序混乱,健全人士无法准确理解,这种语序问题的原因是听障学生在进行书面语的表达时会遗失掉手语表达中的动作、身体姿态等一系列内容信息。对于手语作为第一语言的听障人士来说,学习第二语言书面语的难度较大[7]。因此,听障人士进行书面语表达时会使用便于他们自身的表达方式。促进听障人士与健全人士之间的交流已经成为全球关注的问题,目前已取得了一些成果[8-11]。但目前的工作都只考虑对手语进行识别,没有考虑到听障人士和健全人士语序存在差异,导致很多听障人士的手语虽然被识别出来,但是健全人士难以准确地理解。因此本文提出一种基于注意力机制的手语语序转换方法,如图1所示,通过设计语序转换器来实现手语语序到书面表达的转换。如手语语序为“同学看我电影”,经过语序转换得到书面表达为“我和同学一起去看电影”。
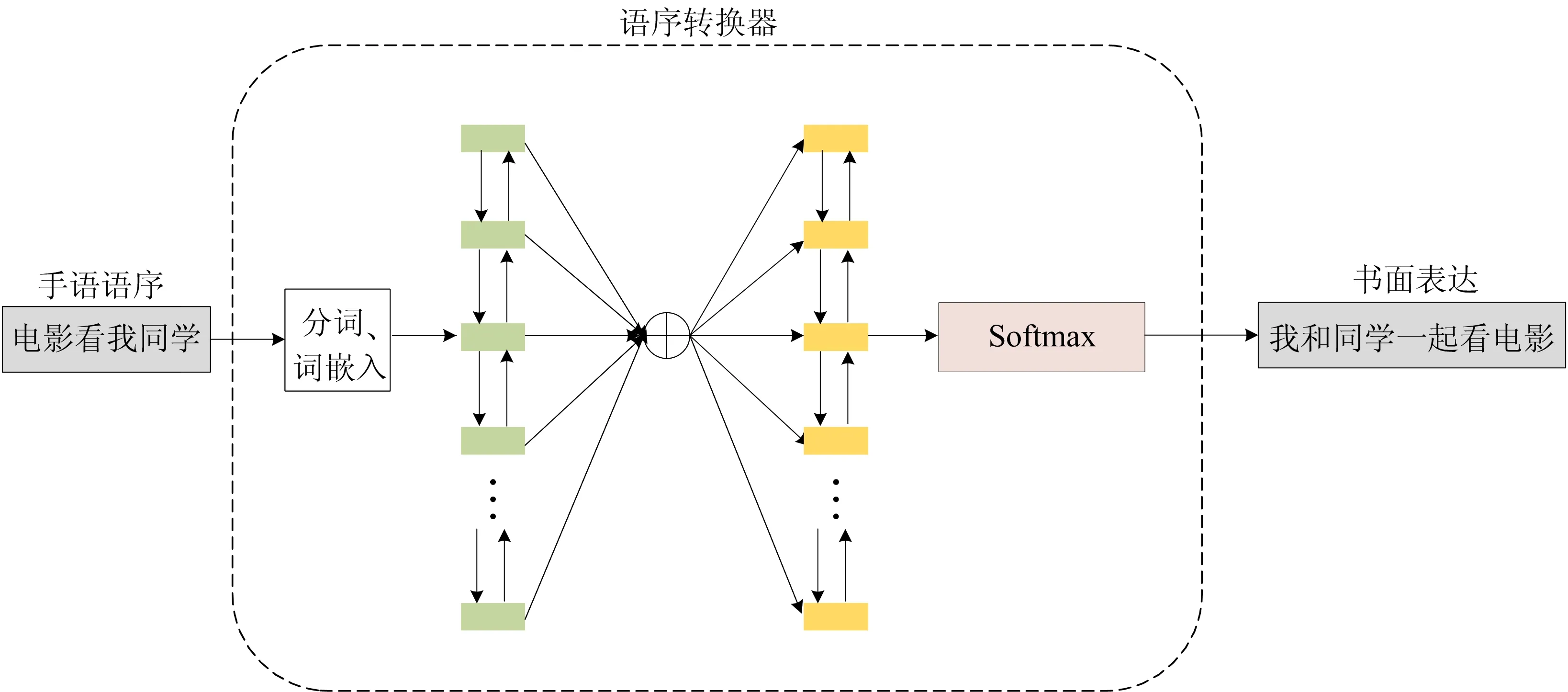
图1 语序转换实例
目前,循环神经网络(recurrent neural network,RNN)模型是用于处理手语时序的主要方法。文献[12]使用带有注意力机制的双层 RNN 构建编解码器模型,使用类似神经机器翻译的框架,端到端地将连续手语视频翻译成口语化语句;文献[13]指出,随着输入序列长度的增加,基于RNN的编解码器性能迅速恶化,在反向传播时,过长的序列导致梯度计算异常,容易发生梯度消失或爆炸;为了解决上述问题,文献[14]提出使用注意力机制向解码器传递附加信息,通过构建上下文向量来减少信息损失,实现句子的翻译对齐。
本文根据手语语序特点,在编码阶段使用双向长短期记忆网络(long short-term memory,LSTM)分别从序列两端出发,更完整地提取手语语序的信息,解码时使用一维卷积提取编码器隐藏状态的特征,并利用注意力机制避免长距离的依赖问题,实现手语语序到书面表达的转换。
1 语序转换器
本节提出的语序转换器是一个基于注意力的编解码器模型,实现手语语序到书面表达语序的转换。编码阶段使用双向LSTM将分词后的句子以固定大小的向量形式投射到潜在空间中,在解码阶段加入注意力机制,确定关注输入序列的具体部分,减少将输入的所有信息编码成固定长度向量的负担,让解码器选择性地检索输入序列的隐藏状态。工作原理如图2所示。

图2 语序转换器工作原理
1.1 编码阶段
在编码阶段,由于连续手语信号中的词语边界难以确定,因此对手语识别器得到的手语语序利用隐马尔可夫模型(hidden Markov model,HMM)进行分词。在分词时,计算每个位置上词语的出现概率:
P(Observed[t],Status[t-1])=
p(Status[t-1])×
p(Observed[t]|Status[t-1])
(1)

(2)


(3)
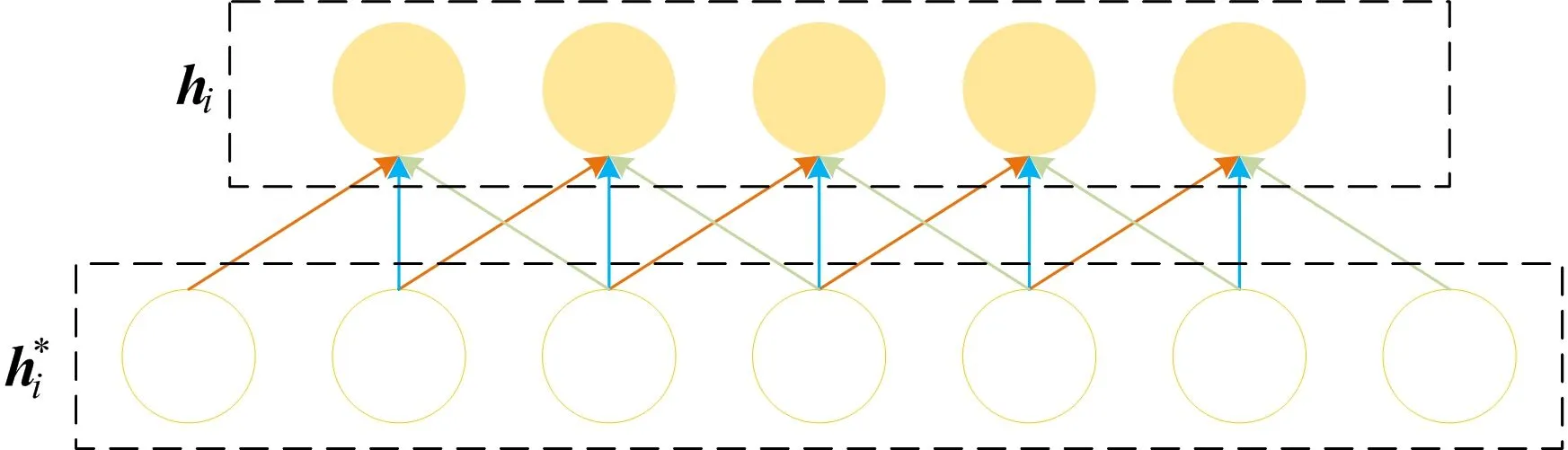
图3 一维卷积提取特征
图3中,hi为提取特征后的隐藏状态。
1.2 解码阶段
在解码阶段,本文设计的解码器在文献[19]模型的基础上加入注意力机制,它克服了使用固定长度的向量表示整个序列信息所造成的长距离依赖和梯度消失问题,如图2右侧所示。解码器加入基于注意力机制可以确定关注输入序列的具体部分,从而减少将输入的所有信息编码成固定长度向量的负担,可以让解码器选择性地检索输入序列的隐藏状态。
首先,由编码器的隐藏状态计算上下文向量。考虑到编码器的隐藏状态hi(i=1,2,…,n)包含整个输入序列的信息,特别是输入序列的第i个词语附近的部分,可根据hi来计算上下文向量ci:
(4)
其中,oij为注意力权重,表示i时刻编码器输入与解码器输出的相关性。oij的计算公式为:
(5)
其中,gi为解码器中LSTM层输出的隐藏状态。评分函数score取决于所使用的注意力机制,本文主要考虑2种评分函数,具体如下:
score(gi,hj)=giWhj
(6)
score(gi,hj)=VTtanh(W[gi,hj])
(7)
其中:(6)式为文献[20]提出的乘法函数;(7)式为文献[14]提出的基于连接的函数;W和V为待学习的参数。
然后,将上下文向量ci与隐藏状态gi进行连接,得到注意力向量ai:
ai=tanh(Wc[ci,gi])
(8)

(9)
通过对每个词语的交叉熵来计算损失,这些损失通过网络向后传播到LSTM和词嵌入层,从而更新网络参数。解码器逐词生成句子:
(10)
其中:y0为句子的开始标记
2 实 验
本文从机器翻译大赛中所用的专业数据集WMT中挑选5 000条中文句子,共5 730个词,来训练语序转换器,训练集和测试集的划分为9∶1。用BLEU-1、BLEU-2、BLEU-3、BLEU-4的分值以及准确率评估语序转换器的性能,在不同层次上对翻译结果进行打分。实验从递归网络、注意力机制的选择、批次大小、波束宽度4个方面验证不同模块的选择对语序转换性能的影响,后续也给出语序转换的实验结果。
2.1 递归单元
本文通过将双向LSTM、LSTM和文献[21]中单一RNN进行比较,验证对于递归单元的选择。语序转换器使用文献[20]中提出的注意力机制,批次大小为128,波速宽度设置为1,实验结果见表1所列。
从表1可以看出,使用双向LSTM时语序转换器的表现最佳,使用RNN效果最差。原因是LSTM存在门结构,反向传播有较多的路径选择,而且只用了对应元素相乘和相加使其更为稳定,因此LSTM发生梯度消失的概率远远小于RNN。

表1 递归单元的选择
双向LSTM则能更全面地获取到输入序列的信息。因此,在后面的实验中递归单元均选择使用双向LSTM。
2.2 注意力机制
本文讨论不同的注意力机制对语序转换器的影响,使用文献[14]和文献[20]提出的注意力机制进行比较,还使用了一个不含注意力机制的模型作为空白对照。语序转换器使用双向LSTM、批次大小为128,波速宽度设置为1,实验结果见表2所列。
从表2可以看出,加入文献[20]提出的注意力机制后的语序转换器性能最好,这是由于在生成词语时使用了解码器的隐藏状态,可以提取更多信息。因此,在后面的实验中均使用文献[20]提出的注意力机制。

表2 注意力机制的选择
2.3 批次大小
本节讨论不同的批次大小对语序转换性能的影响,实验中均使用双向LSTM、波速宽度设置为1以及文献[20]提出的注意力机制。虽然更大批次的训练能够使得梯度更加平滑,但是在收敛速度上有一定程度的降低,且容易陷入局部极小值。小批量训练能够使得网络更有效地表示数据使其更接近目标分布,实验结果见表3所列。

表3 批次大小的选择
从表3可以看出,批次大小为1时模型性能最好,但整体训练的复杂度更高,这是梯度差异过大造成的。在后续实验中,将批次大小设为32进行随机梯度下降训练。
2.4 波速宽度
使用波束搜索(beam search)作为解码预测词语方法,相对贪心搜索扩大了搜索空间,但远不及穷举搜索指数级的搜索空间,是两者的一个折中方案。然而更大的波束宽度并不能带来更好的性能,反而会增加解码的时间和内存。本节通过实验验证不同波束宽度对语序转换器性能的影响。语序转换器使用双向LSTM以及文献[20]中提出的注意力机制,批次大小为32,使用实验准确率和BLEU-4作为评估指标,结果见表4所列。从表4可以看出,波束宽度为2时在验证集上得到了最好的性能。

表4 波速宽度的选择
2.5 语序转换结果
本节展示语序转换器的具体结果,使用基于Theano深度学习框架实现的RNNSearch模型作为基准系统,实验结果见表5所列。

表5 语序转换结果
从表5可以看出,第1句使用基准系统出现了语序颠倒的情况,应该是“有问题之后再进行退换”;第2句缺少主语“同学”;而在第3句中则出现了“有空调热水”这一缺少谓语的情况。而在使用语序转换器时能有效地避免这些问题,但和完整的书面表达仍有差距,这可能是由于输入的手语语序与书面表达之间的信息缺失所导致的。
3 结 论
本文研究了手语语序到书面表达转换的问题,提出了一种基于注意力机制的手语语序转换方法。该方法将手语语序分词放入基于注意力机制的语序转换器中,从而实现了从手语语序到书面表达的转换。最后,本文通过实验验证了该方法的性能,结果表明,语序转换器的准确率最高能达到92.64%。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
活力(2019年15期)2019-09-25
国际汉语学报(2016年1期)2017-01-20
现代特殊教育(2016年21期)2016-12-14
青少年科技博览(中学版)(2015年8期)2015-10-28
