
一种基于变分辨率机制的机坪目标检测算法
2023-02-01 01:35:38刘晓疆丁继存
西华大学学报(自然科学版) 2023年1期
刘晓疆,丁继存,刘 一
(1.青岛民航凯亚系统集成有限公司,山东 青岛 266000;2.中国民航管理干部学院大数据与人工智能系,北京 100102)
目标检测是近年来机器视觉领域发展快、应用广泛的一个研究方向。从传统的特征点检测算法到神经网络、深度学习的检测算法,目标检测的效果逐步提升,但在复杂场景的实际应用中仍面临很多挑战。
本文检测区域主要是机场机坪的停机位区域。在该区域中的检测属于目标尺度跨度较大的复杂场景下的物体检测问题。在停机位区域场景中,最大的目标飞机与最小目标锥桶的总面积相差高达万倍。利用不同规模的网络能够得到不同的目标信号,也可以利用神经网络模型对各种规模的目标物体进行检测[1−3]。He 等[4]通过在深度卷积网络中设计一种空间金字塔池化层的方法用于处理任何尺寸的空间选区,克服了仅仅进行固定尺寸输入的局限性,从而提高了多尺寸获取空间特征的能力。虽然这种技术可以解决物体尺度不同的特定情况,但小目标的测量精确度却无法达到和大目标相同的水准。为进一步提高机坪小型车辆的探测准确度,Razakarivony 等[5]针对航拍汽车的小目标系统,建立了VEDAI,以此作为对小目标探测的重要依据。TAkeki 等[6]针对大背景区域的小目标探测问题,给出了一个可以通过深度全卷积神经网络在大空间中探测鸟类的模式,并将深度学习的检测方法和语义分割技术融合,开发了一个深度全卷积的神经网络及其变体,通过支持聚类实现更高的检测性能。Redmon 等[7]推出了一种可测量多达9000种类型的实时目标测量技术YOLO 9000,提高了小数据测量效率。交通标志监测(TSD)任务的KB-RANN 大脑启发网络[8−9]是对小目标检测算法有很好的参考价值。Singh 等[10]和Singh 等[11]提出了SNIP 尺度不变性目标检测方法,对多种不同尺寸目标进行训练,使小目标检测性能大幅提升,同时还在目标定位与分类2 个层面上实现了伪监督的目标定位系统,以解决机坪中随机存在的大目标(如飞机、廊桥)和小目标(如人员、特定设备设施)的问题。UAV YOLO V3[12]是在YOLO V3 的基础上发展起来的,通过提高前期卷积层数,配合ResNet 实现了更高的检测效率。该方法对于机场廊桥机位视角小目标的检测,其交并比(intersection over union,IoU)和全类平均正确度(mean average precision,mAP)都大大提高。YOLO 系列算法虽然计算工作量大,但在机坪保障视角的小目标检测任务中优点突出。新YOLO V4 相比V3 的识别帧率可增加12%,全类平均正确度(mAP)可提高约10%[13]。
尽管上述方法在小目标检测方面的精度不断提高,但不可否认,相对于大尺度的目标,小目标的检测往往要在较小的尺度下进行检索,时间消耗和算力资源的消耗都显著增加。为了在小目标检测中保留足够丰富的特征信息,提高原始图像采集设备的分辨率是必要的,然而在停机位场景下,小目标分布较为稀疏,如果可以通过上下空间信息减少小目标的搜索空间,那么在不降低精度的前提下,可以提升检测速度,同时大幅度减少对算力资源的消耗。
为了解决在超广视场中快速检出小目标的问题,王海涛等[9]设计了一种通过2 层迭代卷积网络检测宽场图像的小目标方法:首先针对低分辨率的宽场图像,通过一个FasteR-CNN 检出小目标附近的区域,然后将该检出区域用FasterR-CNN 对高分辨率原始图像进行小目标检测,其效果明显好于单级检测。
本文采用与文献[9]相似的思路。考虑到在停机位这一特殊场景下,小目标作业都围绕航空器进行,在空间分布上有高度的相关性,因此本文同样采用2 级检测方法:首先在降分辨率的图像上,使用训练的大尺度目标 YOLO V4 检测模型完成飞机、车辆等大目标的检测,然后将检测到的特定区域映射为高分辨率图像,再进行二次识别。该方法命名为基于变分辨率机制的YOLO 检测 (multiple resolution mechanism based YOLO,MRMY) 算法。考虑到机位作业是相对静态的场景,不同目标尺度变化较小,且目标的尺度呈两极分布,本文使用归一化层的缩放因子来移除网络中低优先级通道,从而提升在复杂场景下目标检测速度。
1 整体架构
由于停机位目标检测区域有限,同时监控摄像机离机位较远,因此机位目标在视场中的运动带来的尺度变化较小。同时本文主要针对的是尺寸较小且特征不明显的目标,例如反光锥桶、飞机舱门等。为此,本文提出一种变分辨率机制,以提高机坪目标检测的效率和小目标检测精度。
本文的检测图像是1080P 以上的高分辨率图像。首先对图像进行降分辨率处理,并对降分辨率图像使用训练的大尺度目标检测模型YOLO V4 完成飞机、车辆等大目标和飞机客舱门、人员等特征明显的小目标的检测,然后结合场景中大小目标间的空间位置关系,将检测到的特定区域(例如飞机货舱门一般位于右侧前部客舱门的左侧)映射到高分辨率图像,再进行小目标二次识别。
由于在相对静态的场景中,不同目标的尺度变化较小,且目标的尺度呈两极分布,因此本文基于归一化层的缩放因子剪裁掉网络中不重要的通道,以提升在复杂场景下目标的检测速度对冲由于分类操作而带来的额外算力需求。
1.1 检测流程
首先在任意时刻t,提取视频流中的一帧图片,命名为It。将It输入到YOLO V4 模型,进行第1 次检测。第1 次检测会对It进行降采样,以适应YOLO V4对图像尺寸的要求,将降采样后的图像命名为
如果检测发现图像It中存在目标,则需要根据图像中基于每个目标推导得到的区域Ω,映射到图像中的对应原始分辨率区域 Ω′,其中Ω=[x,y,w,h],x和y表示目标在图像中的左上角坐标,w和h分别表示目标检测限位框的宽度和高度,则

其中α和β分别表示在水平和垂直方向的降采样系数。从 Ω′中提取的高分辨率图像片段,运用更适用于细粒度特征检测的模型对其进行二次特征提取,得到针对该目标的详细特征表达,例如车辆类别、人员岗位(通过衣着判断)、飞机发动机位置等。其检测流程如图1 所示。

图1 检测流程Fig.1 Detection process
对于一次检测识别的小目标,可根据特定场景下大目标与小目标直接的相对位置关系映射得到一个子区域集合,在每个子区域调用R-CNN 模型进一步进行小目标检测。例如,某些场景需要检测反光锥桶是否摆放在飞机发动机下方。
1.2 基于深度可分离卷积的MRMY 算法的网络结构模型
本文通过深度可分离卷积优化MRMY 算法的网络结构模型:采用深度可分离卷积方法在MRMY 网络提取特征卷积层,以有效地减少卷积核参数,获得更低的计算成本。传统卷积是对三维卷积核与输入的特征图进行卷积。每个卷积核同时操作输入特征图的每个通道,输入特征图的通道数与卷积核的通道数一致。如果卷积层l的输入张量为xl∈,该层的卷积核编号为fl∈。三维输入卷积运算只是将二维卷积扩展到相应位置(即Dl)的所有通道,最后将一次卷积运算处理的所有HWDl元素相加作为该位置卷积运算的结果。具体过程如图2 所示。
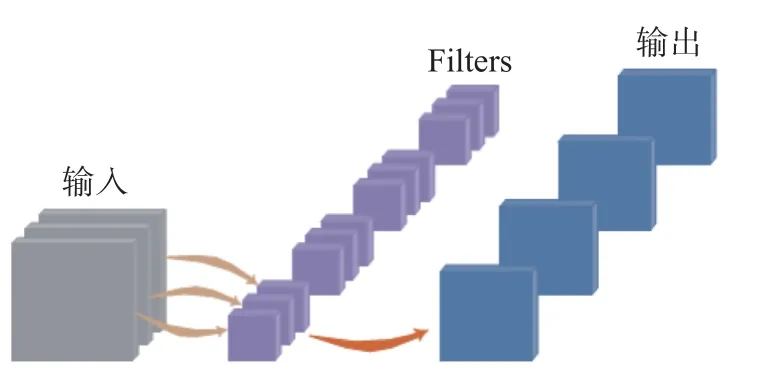
图2 传统的卷积操作Fig.2 Traditional convolution operations
深度可分离卷积法是将一个完整的卷积操作分解成纵深卷积(depthwise convolution,DW)和点卷积(pointwise convolution,PW)2 个卷积。与传统的卷积操作不同,纵深卷积是一个特殊的三维卷积核。一个卷积核只负责一个通道,通道的数量与输入特征图通道的数量不一致。深度卷积完全是在一个二维平面内完成的。在纵深卷积操作中,每个卷积核只与输入的每个通道进行卷积。顺时针卷积操作负责特征融合,将之前的卷积结果整合。传统三维卷积核是在输入的多通道卷积核之间进行卷积运算,得到唯一的输出。本文通过深度可分离卷积改进后只需要一个通道用1×1 卷积进行通道特征融合就可以得到一个输出通道,如图3 所示。这显著地减少了参数及其计算量。深度可分离卷积的参数数量约为传统卷积的1/3,可减少约80%的计算量[13]。MRMY 通过将YOLO V4 的主干网络由CSPDarknet53 替换为深度可分离卷积网络,在不影响精度的条件下,提升了在嵌入式设备上的运算速度。
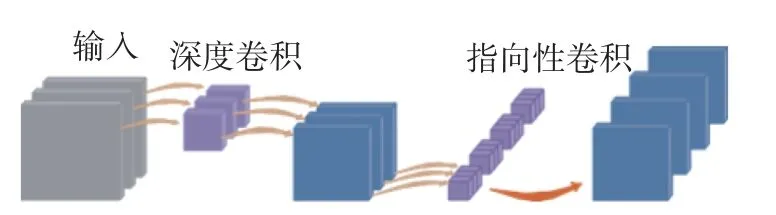
图3 深度可分离卷积法Fig.3 Depth-separable convolution method
在航班保障的目标检测中,通过深度可分离卷积法改进的MRMY 的轻量级网络模型被设计为嵌入式,具有更强的适用性。原来的标准卷积操作将被分成2 部分:纵深卷积和点状卷积。网络结构的修改方法如图4 所示。
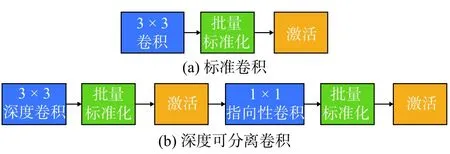
图4 标准卷积与深度可分离卷积的网络结构对比Fig.4 Network structure comparison of standard convolutions versus deeply separable convolutions
2 实验及结果分析
2.1 硬件平台
本文实验中使用的操作系统、CPU 和内存的详细信息如表1 所示。

表1 实验硬件环境参数Tab.1 Experimental hardware environment parameters
2.2 评价指标
评价目标一般包括检测算法准确程度的正确度(precision,P)、召回率(recall,R)、平均正确度(average precision,AP)、全类平均正确度(mean average precision,mAP),以及检测速度FPS 等。本文对算法评价也继续沿用这些指标。
2.3 数据集
本文数据集来源于国内3 个千万级吞吐量机场现场实际航班保障运行数据,是能够覆盖特定机位保障作业的摄像头历史数据,并对视频数据进行了分析,筛选出较具有代表性的视频帧,既包括了需要识别的目标物样本,又包含了足够的雨、雪、雾以及黑夜等环境下的样本。
本文的数据集由机场监控视频拍摄的12 759张图片组成。这些图像中训练集和测试集的比例大约为4∶1。它们既包含不同天气的情况,例如晴天、雨天、雪天等,又有不同光线的情况,例如白天、晚上,如图5 所示。光线条件是一个不可忽视的因素,它经常导致保障车辆物体检测的错误。实验准备了足够的数据集来考虑航班保障的多种情况,以确保数据的可靠性。

图5 机场机坪数据集样本示例Fig.5 Sample of airport apron data set
实验对图像进行手动标注:使用限位框——所有可见像素的最小轴线平行矩形来代表一种保障目标(飞机、车辆、廊桥、机门等)。
2.4 数据增强
神经网络的准确判断需要大量数据进行训练,而实际情况中训练数据往往因为机坪监控架设与存储成本和多种天气、机型、保障车辆等客观条件不足难以取得足够的数量,尤其是在对机坪目标的检测任务中。
机坪保障目标识别任务面临机坪内部监控较少,多种机场监控位置各不相同且异常天气和特殊机型和保障车辆少见的情况,出现了样本较少且特殊样本比例非常低的问题。因此,通过机器对抗来自动化生成训练数据成为保证算法可靠性的关键。其核心是通过构建一个图片扩增处理程序,生成更多的测试图像,实现机坪视角图像的数据自动化增多,从而进行更多神经网络训练。本文主要通过以下方法实现。
1)构建数据资源池。将已有图像数据根据标签文件数据裁剪出训练目标,并随机施加旋转、镜像、变形等变换操作,生成目标池。同时将抠去目标块的背景图像存放在背景池中备用。
2)重新生成新目标块。机坪的监控有些安装在廊桥上视角较高,类似俯视,部分安装在廊桥下方或者侧面对应视角较低,类似平视,2 种视角图像中目标的差别明显。为了得到更好的训练效果,需要将目标池中选取的目标块进行变形、缩放等操作调整为与实际场景类似的尺寸。
3)生成训练图像。首先从背景池中抽取随机背景,然后加入调整后的新目标块,生成新图像。系统结合变换参数和之前的原始数据生成目标图像标注。
2.5 实验及结果分析
本文设立了7 个实验组进行比较分析,以全面摸清通过深度可分离卷积法减少参数对计算效率的影响。MRMY 网络模型共有9 个卷积层。实验对MRMY 网络模型中除第一层和最后一层外的7 个卷积层进行改进,逐一用深度卷积和点卷积取代每一层的标准卷积。这7 个改进的网络模型分别是M1、M2、M3、M4、M5、M6和M7。它们唯一的区别在于卷积层。这种循序渐进的改进方式更有利于直观、清晰地观察每个卷的基础层和每个卷积层中还原参数的速度。改进的网络模型结构如图6 所示。
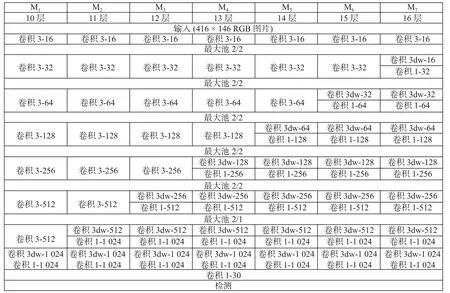
图6 改进的 MRMY 网络结构Fig.6 Improved MRMY network structure
在7 组对比实验中,对MRMY 网络模型和改进后的MRMY 网络模型(M1、M2、M3、M4、M5、M6和M7)在平均精度(AP)、耗时、每秒帧数(FPS)和模型权重大小等方面进行了对比。在乘客物体检测任务中:在AP 方面,每个网络模型的数值都略有不同,差别较大的数值只是下降了约1%;在检测耗时方面,与MRMY 网络模型相比,改进后的网络模型检测一幅图像的时间从0.915 s 减少到0.225 s;在FPS 方面,检测速度从1.093 帧提高到4.449 帧,速度提高明显;在权重文件大小方面,改进后的网络模型从原来的61 MB 减少到7 MB。对比结果如表2 所示。
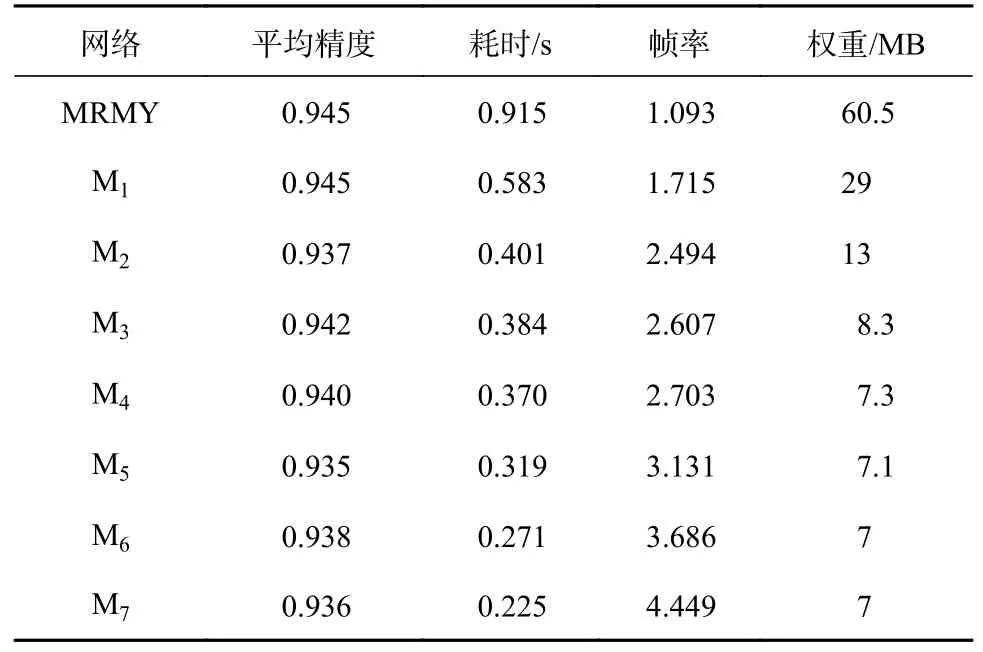
表2 改进的网络性能情况表Tab.2 Improved network performance situation table
图7 示出网络模型的精度—召回率曲线,横轴是召回率,纵轴是检测精度。从图7 中可以发现:在3 个不同的画面中,MRMY 和改进的M7 网络模型都可以实现保障目标的识别,并且检测上没有差异;当召回率超过0.93 时,每个网络模型的检测精度都有明显下降。在这种低召回率的情况下,改进后的网络模型比原始网络模型具有更高的检测精度。
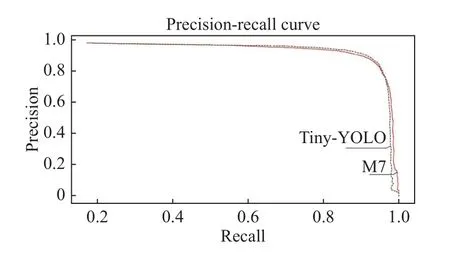
图7 TinyYOLO 与MRMY 网络模型的精度—召回率曲线Fig.7 Precision-recall curve of TinyYOLO and MRMY network model
图8 显示了部分检测结果,其中:(a)是使用YOLO V4 模型的检测结果,打开的货舱门被识别为关闭,油泵车也被误识别为了垃圾车;(b)是MRMY 的识别结果,货舱门和油泵车都被正确地识别了。可见,MRMY 模型的检测结果优于YOLO V4 模型的检测结果。

图8 部分检测结果对比Fig.8 Comparison of some test results
3 结论
本文提出了一种针对机坪复杂目标的检测算法,即MRMY 算法,实现机坪远距离成像的实时小目标检测。该算法通过采用变分辨率机制,先对压缩后图像进行一次检测,再对复杂目标进行二次识别,最后基于归一化层的缩放因子剪裁掉网络中不重要的通道,进一步提升在复杂场景下复杂目标的检测速度。采用深度可分离卷积方法改进的MRMY 网络模型可以减少检测时间以及权重文件大小,从而显著提升检测速度,而且在检测精度上几乎没有任何牺牲。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
西安航空学院学报(2020年5期)2020-12-08 05:23:20
电子制作(2019年11期)2019-07-04 00:34:38
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
物联网技术(2018年4期)2018-05-15 10:10:34
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国科技博览(2017年35期)2017-10-19 06:57:19
