
利用图像超分辨率提升交通标志分类精度研究*
2023-01-31 02:09佘宇徐焕宇戴昕宇张福龙白洋洋
汽车技术 2023年1期
佘宇 徐焕宇 戴昕宇 张福龙 白洋洋
(1.南京信息工程大学,南京 210000;2.无锡学院,无锡 214000)
主题词:双重注意力 超分辨率重构 交通标志图像分类 级联网络
1 前言
在自动驾驶系统和辅助驾驶系统中,交通标志的识别一直是具有挑战性的任务。目前,车载摄像头受成本和带宽的限制,成像质量一般不高,获得的图片分辨率较低。为了保证安全性,车辆在接近交通标志前就要开始检测识别,此时得到的交通标志区域图像只占整幅图像的小部分,目标图像分辨率较低,可提取的特征较少,正确分类较为困难。如果直接使用基于插值的方法,会使目标图像失去高频细节信息,也会影响识别结果。
目前,交通标志识别研究主要针对识别网络结构的改进[1],最常见的方法是加深或加宽网络的结构来提升算法性能,但其不仅增加了计算量,还会因图像本身分辨率不高、有效信息较少而导致浅层特征信息的丢失,造成网络退化,从而影响分类准确率,并且网络设计没有考虑到一些现实问题,比如杂物遮蔽以及光线强弱都会使网络分类性能大打折扣,致使安全性得不到保障。
图像超分辨率(Super-Resolution,SR)作为计算机视觉领域的一个重要分支,属于底层视觉任务,通常用来将低分辨率图像转化为高分辨率图像,以提升图像的质量和解释性,在自动驾驶[2]、监控设备[3]、卫星遥感[4]和医学影像[5]等领域都有重要的应用价值。超分辨率技术主要分为基于重建的方法和基于学习的方法。随着深度学习的快速发展,超分辨率技术凭借细节精度高和推理速度快等优点逐渐成为主流。
本文使用超分辨率网络作为交通标志识别任务的前置网络。首先将低分辨率交通标志图像经过前置网络生成高分辨率图像,以包含更多有效信息,然后将该图像输入到网络中进行分类。考虑到现实检测系统中交通标志图像分辨率往往较低,且有树枝等嘈杂背景遮蔽等情况,为突出图像中的交通标志区域,本文在超分辨率网络中加入双重注意力机制,对特征图进行空间和通道上的自适应调整,通过加强或抑制特征图中元素的权重来重点突出图像中的交通标志区域,并利用模拟数据和真实数据验证本文方法的有效性。
2 本文方法
2.1 图像预处理
首先将图像数据集按照8∶2 的比例划分为训练数据和测试数据两部分,训练数据主要用于训练超分辨率网络和分类网络,测试数据则用于评估超分辨率算法对分类任务的影响。分类网络在训练过程中主要提取交通标志的轮廓和图形语义信息,对颜色属性不敏感,所以本文试验均使用灰度图像,同时可降低模型的复杂度。
在超分辨率网络试验中,为了符合真实道路情况,需要将图像裁剪或缩放至分辨率为40×40,并对数据进行×2、×3和×4共3种规格的下采样处理,再将得到的低分辨图像输入到超分辨率网络中以获得超分辨率图像。下采样操作均使用双三次插值的方法。
2.2 超分辨率前置网络结构
Dong等[6]首次将深度学习引入超分辨率领域,提出超分辨率卷积神经网络(Super-Resolution Convolutional Neural Network,SRCNN),图像重建效果远超传统方法。随后,Kim等[7]将残差结构引入超分辨率重建任务,提出了深度残差超分辨率网络(Very Deep Convolutional Networks,VDSR),在图像超分辨率领域得到了广泛应用[8]。Shi 等[9]创新地提出了高效亚像素卷积网络(Efficient Sub-Pixel Convolutional Neural Network,ESPCN),这一改进能够让网络学习更加复杂的映射关系,后来提出的图像超辨率方法也大都沿用了这一方法。Gao 等[10]构建了一个用于交通图像识别的超分辨率生成对抗网络(Super-Resolution using Generative Adversarial Network,SRGAN),带来了更好的主观视觉效果。Yu等[11]在单幅图像增强型深度残差超分辨率网络(Enhanced Deep Residual Networks for Single Image Super-Resolution,EDSR)[12]的基础上,提出一种宽幅激活超分辨率网络(Wide Activation for Efficient and Accurate Image Super-Resolution,WDSR),在保证相同参数量的情况下,增加了修正线性单元(Rectified Linear Unit,ReLU)激活函数前的特征图宽度,并且创新地使用权重归一化代替传统的批归一化,提高了网络运算效率,网络结构如图1 所示,图中虚线框内为宽幅残差特征提取模块(WDSR-B Residual Block,WRB)。
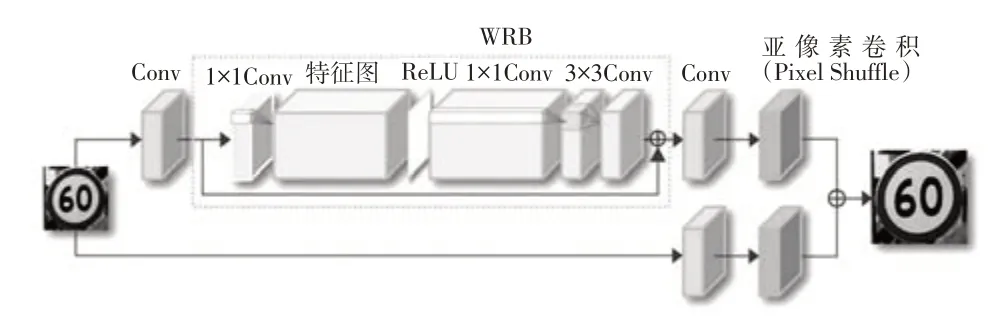
图1 宽幅激活超分辨率网络结构
真实场景中交通标志图像四周往往含有嘈杂的背景,不利于图像中心处交通标志的识别。针对这一问题,本文引入双重注意力机制[13],通过在超分辨率网络特征提取结构的基础上结合空间注意力机制,使网络更加注重图像中心交通标志的学习,有利于后期交通标志的分类。同时加入通道注意力组成双重注意力机制,通过网络自主学习的方式获取每个特征通道的重要程度,最后再为每个通道赋予不同的权重系数,从而强化重要特征,抑制非重要特征。
本文在WRB 结构中融合双重注意力机制,改进特征提取结构(WDSR-B Residual Attention Block,WRAB),如图2所示,并提出宽幅注意力超分辨率网络(Wide Attention Super-Resolution,WASR)。在改进的特征提取模块中,输入特征HI,先经过1×1 卷积、ReLU激活函数和3×3卷积得到特征F,然后输入到双重注意力网络。通道注意力(Channel Attention)单元包含全局平均池化(Pooling)、1×1卷积、ReLU激活函数和Sigmoid函数,设C为输入特征图的通道数,第1 层卷积后通道数变为C/r(r=16 为维度压缩比例),第2 层卷积后恢复为C层。空间注意力(Spatial Attention)单元包含1×1卷积、ReLU 激活函数和Sigmoid 函数,第1 层卷积后通道数变为C×i(i=2 为维度扩张比例),第2 层卷积后通道数变为1。得到通道和空间2 个特征后,分别与特征F相乘,再将2 个结果拼接起来经过一个1×1 卷积将特征通道数恢复为C,最后与输入特征HI相加得到输出特征HO。
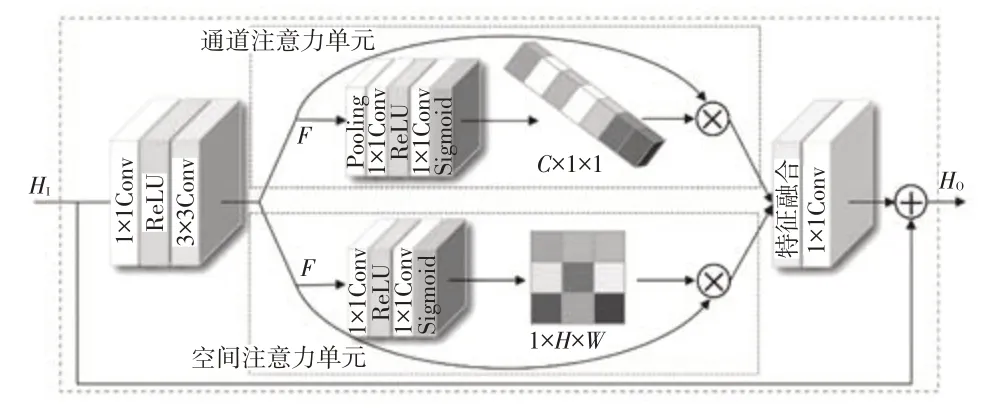
图2 改进的特征提取结构
2.3 级联网络结构搭建
神经网络由大量的神经元相互连接而成。每个神经元接受线性组合的输入后,开始只做简单的线性加权,然后经非线性的激活函数进行非线性变换后输出。重新审视传统卷积神经网络分类模型的工作方式可知,高层特征是低层特征组合的加权和,上一层输出神经元经过激活函数后与下一层神经元的权重相乘再相加,接着通过非线性激活函数进行激活,直到利用Softmax 函数计算各标签的占比,从而归为最大占比的标签。而目前存在的问题是,对于元素丰富的图片,内容的朝向和空间上的相对关系对网络特征提取来说并不重要,它只在乎是否存在特征;而且网络中的池化层会主动丢弃大量位置信息,降低了空间分辨率,导致输出对图像空间位置的变化不敏感,从而影响网络模型对于带有方向信息以及空间朝向标志图像的分类判断,造成交通安全隐患。
为了解决这一问题,本文使用Sara提出的胶囊网络(Capsule Network,CapsNet)[14],如图3 所示,其使用向量神经元代替传统的标量神经元,克服了CNN 对物体之间的空间辨识度差及物体大幅度旋转后识别能力低下的缺陷,有效弥补了卷积神经网络模型的不足。胶囊相当于打包好的神经元,神经元输出标量,胶囊输出向量,向量携带了一部分空间信息(姿态信息),胶囊能更好地理解事物的组成、位置和姿态信息。胶囊网络首先依靠卷积层提取交通标志特征,通过动态路由算法实现初级胶囊层到高级胶囊层的表达与传递,最终将其封装成一个高维向量输出。
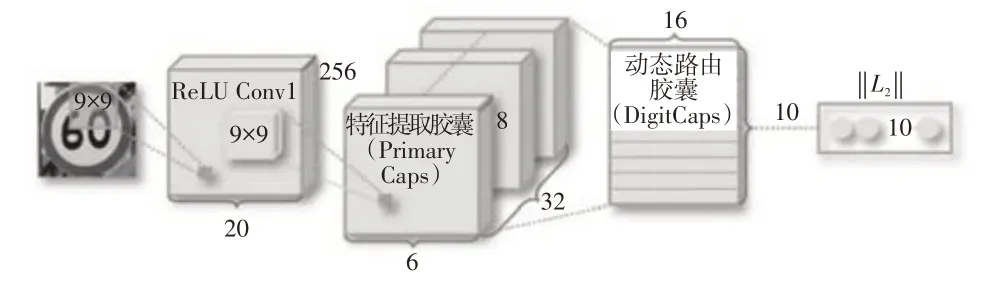
图3 胶囊网络模型结构
在级联网络的搭建中,首先使用超分辨率网络作为级联网络的前置子网络,再以胶囊网络作为级联网络的分类网络,超分级联网络的整体结构如图4所示。
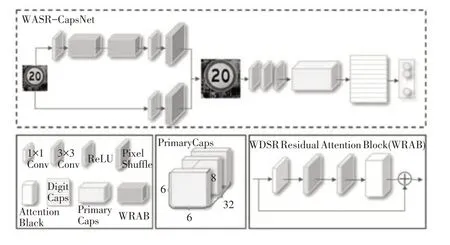
图4 超分级联网络结构
3 试验与分析
3.1 试验数据集
本文试验主要采用3 种公开数据集。在超分辨率网络训练阶段,主要使用2K 高清图像(DIVerse 2K Resolution High Quality Images,DIV2K)数据集[15]和中国交通标志数据库(Chinese Traffic Sign DataBase,CTSDB)。DIV2K 数据集共有1 000 张2K 高清图像,可以使超分辨率网络学习到更加良好的映射关系;CTSDB共有6 164 张交通标志图像,包含58 种标志类别,且图像质量良好,适合作为超分辨率网络针对交通标志图像的微调数据集。在胶囊分类网络训练阶段,使用德国交通标志识别数据集(Germany Traffic Sign Recognition Benchmark,GTSRB),共有51 839张交通标志图像,包含43 种标志类别,能有效满足分类网络对数据量的要求。交通标志图像部分样本如图5所示。

图5 交通标志示例
3.2 超分辨率网络对比试验
本节采用主观效果和客观评价指标2 种方式,对SRCNN、SRGAN 和WDSR 经典超分辨率算法与本文提出的改进算法进行对比,评价图像重建质量的客观指标使用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似度(Structural SIMilarity,SSIM)[16]。
训练过程共120 轮,前80 轮使用DIV2K 数据集进行训练,后40轮使用CTSDB进行微调。训练结束后,任意选取一张交通标志图像进行超分辨率×2重建,如图6所示。从图6中可以看出:SRCNN算法的重建效果明显好于双三次插值算法(Bicubic),但视觉效果仍然比较模糊;SRGAN算法细节效果很清晰且比较真实,但是周围生成过多伪影导致指标分数较低;WASR算法目视效果最好,纹理细节清晰,最接近原始图像。

图6 重建主观效果展示
对现有5 种超分辨率方法在×2、×3 和×4 放大倍数下进行定量比较,结果如表1所示。基于深度学习的方法与双三次插值算法相比,在评价指标和视觉效果方面都得到明显提升,表明基于深度学习的超分辨率算法能有效提高图像质量。WASR 算法在各放大倍数下的客观评价指标和主观视觉效果均为最优,证明了改进的双重注意力特征提取结构能够提高超分辨率算法性能。最后保存超分辨率模型参数,进行下一轮训练。
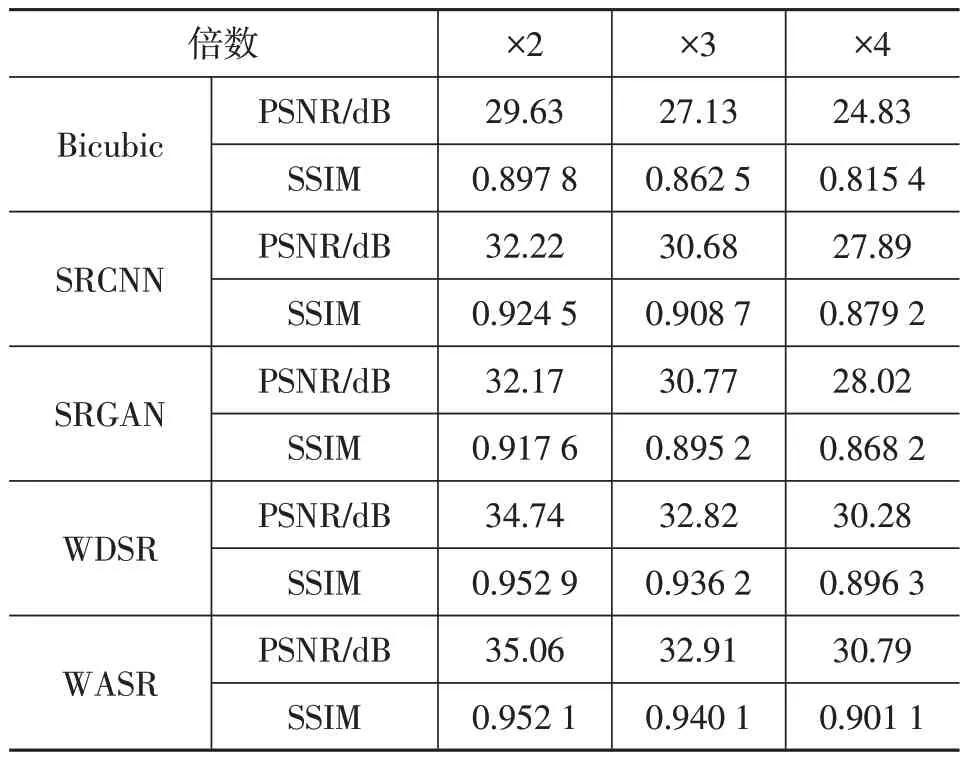
表1 CTSDB测试集在×2、×3、×4尺度下的超分辨率客观评价指标
3.3 交通标志分类试验结果分析
为了验证超分级联算法的有效性,本文使用德国交通标志识别数据集,通过模拟数据和真实数据2种验证方式进行×2、×3和×4放大倍数的对比试验[17],试验结果将43类交通标志分为禁令标志、警告标志和指示标志3大类别以方便展示。
模拟数据试验是指在测试过程中,测试数据集的图像预处理方式与训练测试集相同,即所有测试图像分辨率均调整至40×40,再将图像进行下采样操作,此时图像分辨率降低,高频细节丢失,随后通过基于插值的方法(Bicubic)和基于学习的方法(WASR)重建图像,分别将分辨率恢复至40×40,再将图像分别输入到胶囊网络中进行分类以完成对比试验,最终通过分类准确率衡量2种算法的重建效果。
在各缩放尺寸的试验中,使用上述2种重建方法分别计算3种标志类别的分类准确率,结果如表2所示。
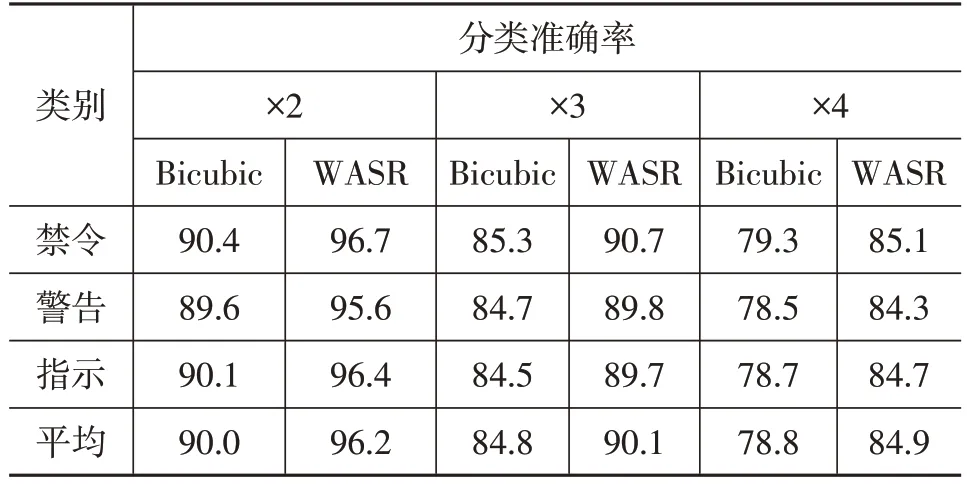
表2 模拟数据各缩放尺寸客观指标 %
从表2 中可以看出,在相同分辨率测试图像中,通过超分级联网络得到的分类准确率明显优于传统插值方法。测试图像经过各缩放尺寸下采样后,超分级联网络算法的分类准确率比双三次插值算法分别高6.2百分点、5.3百分点和6.1百分点,由此可知,对于低分辨率图像,传统的双三次插值方法只能增大图像分辨率,难以引入额外的有效信息。超分级联网络在重建图像并提升图像分辨率的同时,引入了相同类型的数据信息结构进行重建,使生成的图像具有更多的有效信息,分类效果比较理想,也证明了超分辨率算法重建效果的优越性。
真实数据试验是指在测试过程中,将测试集中的数据按照分辨率大小分为3类,不对测试图像做任何额外处理,直接输入至2种算法中进行分类。
在GTSRB 中挑选25×25~30×30、30×30~35×35 和35×35~40×40 共3 种分辨率的图像,每种标志类别取100 张图像用于测试,3 种标志类别的分类准确率结果如表3所示。其中CapsNet表示使用原始胶囊网络分类方法,将测试图像直接输入至胶囊网络进行分类。WASR表示采用本文提出的超分级联网络,将测试图像先经过超分辨率网络提升分辨率,再输入至胶囊网络进行分类。
从表3中可以看出,测试图像的分辨率很大程度上影响分类准确率。在各分辨率图像的测试中,超分级联网络的分类准确率比胶囊网络分别高6.7百分点、7.4百分点和6.0 百分点,说明超分级联网络中的超分辨率网络提高了测试图像的分辨率,生成的图像较测试图像包含更多的有效信息,更有利于网络的信息提取,分类准确率也更高,证明了超分级联网络的有效性。
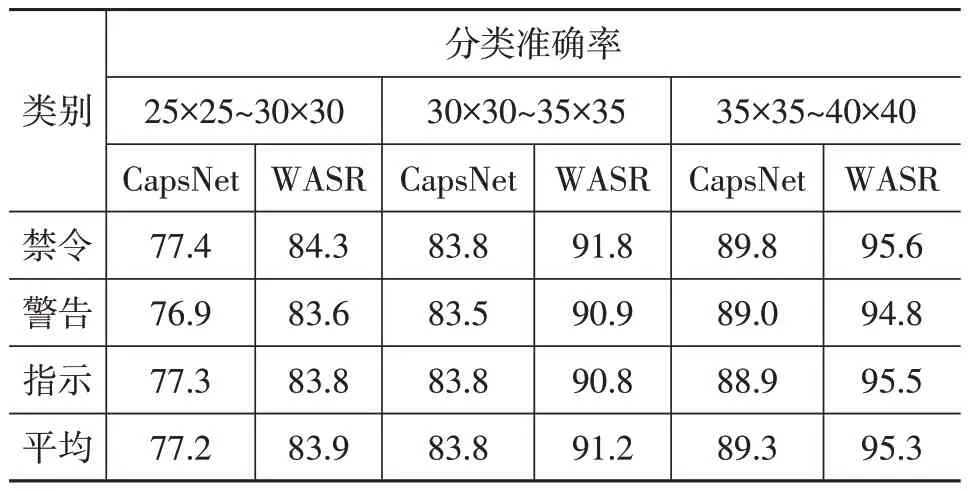
表3 真实数据各尺寸客观指标 %
4 结束语
本文提出一种超分级联网络来提升交通标志分类任务的准确率。针对交通标志分类任务,在已有的超分辨率算法WDSR中融合空间注意力和通道注意力,改进特征提取模块,提出WASR 超分辨率网络,并通过不同算法和各尺寸的对比试验证明了改进的特征提取结构能够提高超分辨率算法性能。超分级联网络无论在模拟数据还是真实数据试验中,都能明显提高分类准确率,说明经过指定任务训练的超分辨率网络能重建更多的图像高频信息,证明了超分级联网络的有效性。
本文验证了超分辨率重建技术能够很好地提升自动驾驶领域的计算机视觉任务效果,下一步的研究将针对车道线识别任务和语义分割等高级交通视觉任务应用超分辨率前置网络,设计一种通用型即插即用的超分辨率网络模块,用以提升各种自动驾驶领域视觉任务的效果。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
小天使·一年级语数英综合(2016年8期)2016-05-14
