
面向小样本数据的机器学习方法研究综述
2023-01-09 14:28陈良臣傅德印
计算机工程 2022年11期
陈良臣,傅德印
(1.中国劳动关系学院 计算机教研室,北京 100048;2.中国劳动关系学院 应用统计学教研室,北京 100048;3.中国科学院信息工程研究所,中国科学院网络测评技术重点实验室,北京 100093;4.武汉理工大学计算机科学与技术学院,武汉 430063)
0 概述
尽管机器学习在拟人化人工智能上实现了突破,并在数据密集型应用中取得了较好的效果,然而深度学习需要较强的算力和大量标注好的数据进行支撑。而在网络安全领域等很多实际应用场景中,收集和标注大量网络中的新型未知攻击样本是极其困难的。当带标签的数据样本很少或数据集较小时,确保机器学习模型能快速学习样本并提高泛化能力对研究人员不仅是巨大挑战,也是必须解决的现实问题[1]。为推动机器学习在这种样本数据极稀缺场景下的应用,研究人员提出了小样本学习[2]。
小样本学习是面向小样本数据的机器学习[3]。目前,小样本学习的研究主要关注如何在缺乏足够样本的条件下,仅通过较少数量的样本就能理解事物的本质特征,避免过拟合并给出泛化性良好的结果。根据训练样本数量将小样本学习分为3类:只有一个训练样本,称为单样本学习;不存在目标训练样本,称为零样本学习;目标训练样本在数十个量级时,称为小样本学习。很多文献将这3类统称为小样本学习,其中前两类为特殊情况[4]。目前,小样本学习的领域主要有概念学习和经验学习两个研究方向。概念学习是让机器尽量模拟人脑的学习过程,即通过少量样本理解事物本质概念这一过程,而另一种经验学习的思想是将小样本问题转化为通用的大数据范式。
针对小样本数据,很多学者从基于模型微调、基于数据增强、基于度量学习和基于元学习等4 个方面的机器学习方法进行研究。本文总结面向小样本数据的机器学习方法最新研究进展,对小样本学习方法进行归纳分类,并列举常用小样本数据集和评价指标,在此基础上整理常用机器学习方法在小样本数据集上的实验结果。最后,对目前面向小样本数据的机器学习方法进行总结并阐述其未来发展趋势。
1 小样本学习概念与应用
1.1 小样本学习定义
小样本学习也称为少样本学习,是通过从较少数量的样本数据中学习得到解决实际问题的机器学习方法[5]。在标记数据少甚至无标记数据场景下所做的工作都归为小样本学习问题。给定一个特定任务T,包含有少量可用信息的数据集DT,以及与T 无关的辅助数据集DA,为任务T 构建函数f,任务的完成使用了DT中很少的信息和DA中的知识。
如图1 所示,小样本学习的基本模型为p=C(f(x|θ)|ω),由特征提取器f(·|θ)和分类器C(·|ω)组成,其中:θ和ω分别表示f和C的参数;x表示待识别的样本;f(x|θ)表示对样本x提取的特征;p表示对样本x识别的结果。

图1 小样本学习基本模型Fig.1 Basic model of few-shot learning
在小样本学习模型训练的过程中,训练样本集所包含的样本数量过少,在该训练样本集上训练分类模型p所得到的参数θ和ω会导致模型过度拟合。
1.2 小样本学习应用
小样本学习最早出现在图像分类和识别的应用中,在实际场景中,小样本学习除了集中在深度学习比较有优势的计算机视觉领域和自然语言处理领域外,也被广泛地应用到很多机器学习的其他领域中,如表1 所示。这些领域的特点一般是训练数据的获取成本很高,甚至根本无法获取。例如:在罕见疾病诊断中,由于一些罕见疾病的病例数非常少,因此几乎无法获取训练样本;在人脸识别中,受采集条件限制,往往无法获取各个角度的人脸图片,在多数情况下每张人脸只有一张对应的训练图片;在小语种相关的机器翻译中,一些语系的训练数据采集工作往往难以开展等。
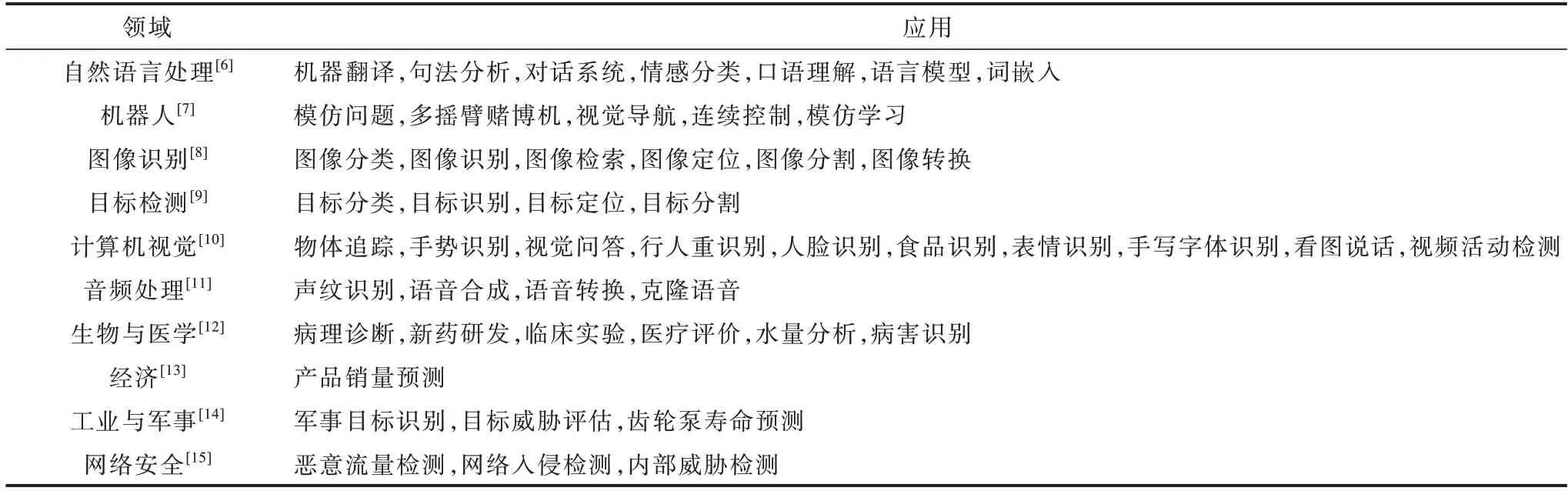
表1 小样本学习应用领域Table 1 Few-shot learning application areas
2 小样本数据的机器学习方法
2003 年,从LI 等[16]提出小样本学习的框架开始,小样本学习得到越来越研究者的关注,并有了一些研究和发展。目前主流的小样本学习方法主要分为基于模型微调、数据增强、度量学习和元学习四大类。各分类方法的核心内容如表2 所示。

表2 小样本学习方法的核心内容Table 2 The core content of few-shot learning methods
为了解决数据受限问题,基于数据增强的小样本学习方法使用生成模型等技术增强训练样本以增加模型中先验知识[17];基于度量的小样本学习方法则通过学习嵌入空间来解决资源不足时的过拟合问题;基于元学习的小样本学习算法关注算法本身设计,即设计一种可以快速收敛到最佳模型参数的跨任务优化策略[18]。其中,基于数据增强的小样本学习方法包括基于无标签数据、数据合成、特征增强等;基于度量学习的方法包括匹配网络、原型网络、关系网络、图神经网络等;基于元学习的方法包括模型无关学习、元转移学习、记忆增强神经网络、长短时记忆模型等。小样本学习方法分类如图2 所示。
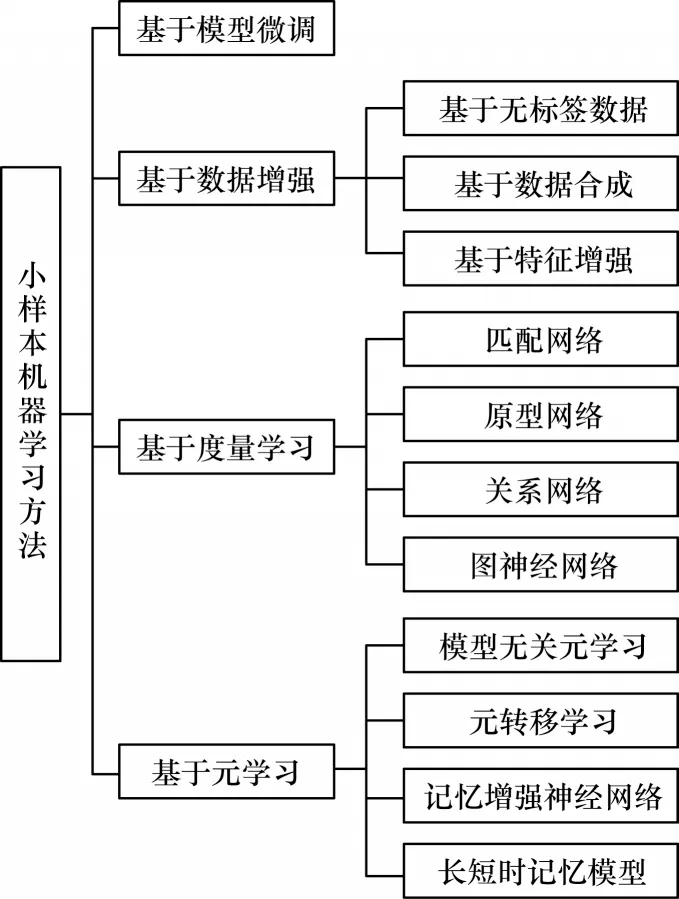
图2 小样本学习方法的分类Fig.2 Classification of few-shot learning methods
2.1 基于模型微调的小样本学习
基于模型微调的方法通常先在大量数据集上对网络模型进行预训练,然后固定部分参数,在小样本数据集上对网络模型中的特定参数进行微调,得到微调后的模型,如图3 所示。若目标数据集和源数据集分布较类似,则可采用模型微调的方法。该方法依赖的数据量较少,能较快地达到所需效果[1]。
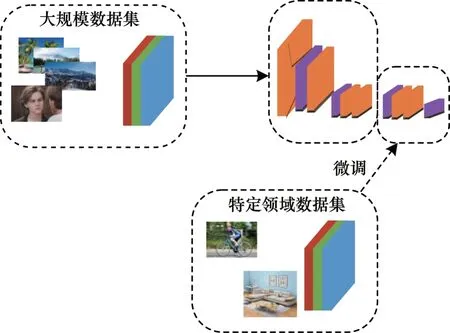
图3 基于模型微调的小样本学习方法Fig.3 Small sample learning method based on model fine-tuning
文献[9]提出重新赋权模块的FSRW 模型,首先通过基类样本训练特征调整模块,然后根据小样本新类与基类样本联合训练模型,以达到对新类样本的检测。文献[19]提出一种传导性微调的方法,首先利用大量带标签数据对模型进行第一阶段训练,接着使用少数的有标签数据微调模型,以达到新类数据的分类。文献[20]提出一种简单的微调方法,固定第一阶段训练后的特征提取模块,只对分类器和回归器进行微调。文献[21]设计一个通用微调语言模型,该模型的创新点在于改变学习速率来微调语言模型,使模型更符合目标任务。另外,文献[22]提出一种微调方法,在训练过程使用更低学习率,在微调阶段使用自适应梯度优化器。文献[23]提出一个基于T0 模型的微调方法T-Few,无需针对特定任务的调整或修改即可应用于新任务。
为了使小样本学习模型的分类效果更好,研究人员需要考虑选择哪种类型的微调方法。在真实的小样本学习的应用场景中,目标样本集和源样本集并不一定相似,采用模型微调的小样本学习方法可能会导致机器学习模型在目标样本集上出现过拟合问题[1]。因此,在解决实际问题中,一般将模型微调方法和数据增强、度量学习或元学习方法相结合来避免少量数据带来的模型过拟合问题。
2.2 基于数据增强的小样本学习
在深度学习中,经常通过对样本进行旋转、缩放、变形、剪切或者变换颜色等处理方法来增强数据。小样本学习因为数据量太少而导致样本多样性低,所以可使用数据增强来提高样本多样性。如图4所示,使用辅助数据或者辅助信息,本文根据某种规则将新类数据集Dnovel中的样本(xi,yi)转换成多个样本,转换生成的样本拥有与被转换样本相同的类别标签,并加入到原数据集Dnovel中,生成一个更大的数据集,新数据集包含更多数据,可直接通过深度学习模型训练。
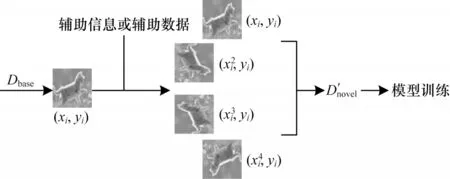
图4 基于数据增强的小样本学习方法Fig.4 Few-shot learning method based on data augmentation
数据增强是针对小样本集进行数据扩充或者特征增强。其中,数据扩充是添加新数据、无标签数据或合成的有标签数据,特征增强是在特征空间中添加新特征。基于数据增强的小样本学习方法主要包括基于无标签数据、数据合成和特征增强的方法[1]。
2.2.1 基于无标签数据的方法
基于无标签数据的方法是指使用大量的无标签数据对原有的小样本数据集进行扩充,包括无监督学习、半监督学习、直推式学习等常见方法。
无监督小样本学习是指辅助数据集由无标签数据组成,模型不需要标签数据,减少了收集和标注数据的成本,使小样本学习更符合生活中的实际应用场景。为了减少依赖辅助数据集,无监督小样本学习作为一个被重点关注的研究方向[24]。但是没有标签样本就无法构建小样本训练任务,这正是小样本学习方法成功的关键。文献[24-25]使用基于聚类的方法,根据不同的簇来构造伪标签并使用元训练优化模型,该方法对聚类效果有很高的要求。文献[26-27]使用基于数据增强的方法,利用其类别保持的性质来构造训练任务,增强的好坏直接影响模型的效果。文献[28]通过自训练获得无标注样本的伪标签来增强数据,并通过设计新度量伪标签置信度来挑选置信度高的样本。文献[29]在小样本场景的无标签数据上,通过利用数据增强方法提取更加通用的先验知识。文献[30]提出一种基于分离增强的无监督小样本学习框架,关注伪小样本学习任务分布差异,缓解模型过拟合问题。文献[31]提出一种基于度量的辅助学习的小样本学习框架,通过生成伪标签来动态指导模型迭代中的粗学习。
半监督学习是机器学习研究领域的重要方向,将半监督学习应用到小样本学习中已经有很多不同的尝试,并取得了较好的效果。文献[32]对原型网络进行拓展,提出一种半监督的小样本学习方法,使用小样本分类中生成的少量已标注样本和多数未标注样本来计算原型,获得了更好的效果。文献[33]提出一种基于标记传导的传感前传模型,在基于半监督的小样本学习中获得非常好的分类准确率。文献[34]在半监督学习思想下,提出增加无监督元训练阶段,使多个顶层单元学习大量的无标注数据。文献[35]提出一种使用MAML 模型进行半监督学习的方法,分别使用无标签样本和有标签样本调整嵌入函数参数和分类器参数。
直推式学习被认为是半监督学习的子问题,目标是通过未标注数据的测试数据让深度模型取得最佳的泛化能力。模型在学习阶段除了能够看到训练样本和标签外,还能接触到测试样本,期望能够使用测试样本的内在结构,将测试样本作为一个整体预测分类,而不是孤立地预测每一个测试样本。文献[33]使用直推式学习提出了转导传播网络来解决小样本问题,使标签从标注数据传播到无标注数据。文献[36]提出一种基于直推式学习的交叉注意力网络和转换推理算法,迭代地使用未标记数据以增加数据集,使类别特征更具有代表性。
2.2.2 基于数据合成的方法
基于数据合成的方法为小样本类别合成新的带标签数据,以达到扩充训练数据的目的。现有的数据生成方法不能捕捉复杂的样本分布,无法泛化小样本类别且合成的特征不可解释。
文献[29]提出一种用于小样本学习的自动数据增强框架,采用强化学习探索能给模型带来最大收益的自动数据增广,并结合数据增强模型和任务模型,采用端到端的方式进行优化。文献[37]提出一种生成对抗网络模型GAN,并基于博弈论思想将噪声分布映射到接近数据的真实分布,对小样本数据进行数据增强。文献[38]在生成对抗网络基础上,提出了数据增强生成对抗网络DAGAN,组合UNet和ResNet,通过生成与样本近似分布的增强数据来改善模型质量。文献[39]提出一种生成对抗残差成对网络来处理单样本学习问题。文献[40]基于语义信息提出了语义自编码器以对更高层面数据进行增强,通过元学习对训练集样本插值,并将样本原始特征和转换后特征进行融合以达到数据增强。文献[41]提出一种融合元学习的数据生成模型,使用数据生成、特征提取和分类共同训练生成对任务实用的样本以扩充样本多样性。文献[42]设计一种Meta-GAN 模型,结合生成对抗网络和分类网络优化,使用产生的数据进行小样本数据增强。文献[43]改进了自动编码器,将源数据中不同样本方差应用在新类别中生成新样本,实现对小样本任务的数据增强。文献[44]结合变分编码器和GAN,集成新网络,完成小样本学习分类,并使得生成样本的特征空间具有可解释性。文献[45]利用CWGAN 生成扩充数据集以提高分类能力和生成样本的多样性。文献[46]提出一种适用于小样本学习的数据增强生成对抗网络f-DAGAN,使用双重鉴别器来处理生成的数据和生成的特征空间,以更好地学习给定的数据。
2.2.3 基于特征增强的方法
基于无标签数据和数据合成的方法都是使用辅助数据或辅助信息来增强样本空间。在小样本学习中,为了提高样本的多样性,还可增强样本的特征空间,小样本学习最重要的是获得泛化性较高的特征提取器[1]。
文献[18]提出一种基于特征增强元学习的小样本算法,能解决线性分类器容易过拟合问题和增强嵌入特征以强化任务表示。文献[47]针对3D 图像提出了一种基于属性引导的扩展模型学习合成数据的映射,该方法先映射图像到某一特定空间,然后使用训练过的编码器和解码器生成多样式的样本图像。文献[48]将特征向量进行多次转换,生成新类别的特征向量,并将生成图像添加到新类别训练集以增强数据。文献[49]提出一种特征迁移网络,以记录随物体姿态变化导致的运动轨迹变化。文献[43]提出一种编码器,利用少量样本合成新类别样本并用于分类器训练,该模型能有效地合成新类样本并提取同类样本间的类内变形。文献[50]提出一个双向网络模型TriNet,基于编码器-解码器,结合标签语义空间和图像特征空间,更好地提取图像特征,对样本的特征进行增强。文献[51]将提取的不同样本的前景和背景随机组合以增强样本。文献[52]从深度学习模型的表征层层面提出了一个更加适用于小样本学习的新表征方法:判别变分表征算法。该算法通过约束表征空间的先验分布,使得表征分布呈现出良好的类无关的迁移性质。文献[53]使用仿射变换进行图像特征增强,并通过扰动输入的数据特征分布以提高模型对分布差异的鲁棒性。文献[54]提出一种新颖的特征增强网络FAN,用于小样本无约束掌纹识别,旨在同时消除由无约束采集引起的图像变化,并仅从少数支持样本中增强其特征表示。
基于数据增强的小样本学习方法,仅需通过辅助数据或者辅助信息来进行数据扩充或特征增强,不需要调整模型的参数,但可能会引入噪声或特征,对学习模型的效果形成不利的影响,模型通常会比较复杂且计算量较大。此外,因为实际样本数目较少,现有的机器学习方法在实际的数据增强中,容易出现知识偏移和过拟合的问题,所以实际的应用效果并不是特别理想。但是数据增强的思想对于解决实际的样本缺失问题来说具有普遍意义,因此将数据增强的思想融入度量学习或元学习的方法中是非常值得研究的方向[5]。
2.3 基于度量学习的小样本学习方法
度量学习也称相似度学习,使用给定距离函数来度量两个数据样本间的距离,以计算其相似度[55]。基于度量学习的小样本分类过程可分为映射和分类两个阶段。基于度量学习的小样本学习方法如图5所示,其中:f是将支持集样本xj映射到特征空间的嵌入模型;θf是f对应的参数;g是将查询集样本xi映射到特征空间的嵌入模型;θg是g对应的参数;S(·,·)是度量支持集样本与查询集样本的相似性度量模块,可以是一个简单的距离度量,也可以是一个可学习性网络。通过相似性度量模块输出的相似度可以用来对查询样本进行分类预测。

图5 基于度量学习的小样本学习方法Fig.5 Few-shot learning method based on metric learning
基于度量学习的小样本学习方法主要关注与学习模型的有判别性和可泛化特征[56]。该方法利用大量数据训练特征提取网络,然后对特征使用相似计算以获得不同度量表示。相似性度量通常采用欧氏距离、曼哈顿距离或余弦相似度等。采用度量学习的小样本学习方法主要有以下两种:固定度量,如匹配网络和原型网络;可学习度量,如关系网络和图神经网络等。
基于匹配网络的方法是第一个将度量学习用于小样本分类的工作,关键思想是将图像映射到一个封装了标签分布的嵌入空间,然后使用不同体系结构将测试图像投影到同一嵌入空间中,接着使用余弦相似度来衡量相似度,以确保测试数据点是否已知,实现分类和检测效果。以匹配网络为代表,小样本学习算法领域涌现出一大批学习特征表示模型的算法[57-59]。文献[60]基于深度神经特征度量学习的思想,提出一种基于Attention 机制匹配网络,编码支持集样本与目标集样本并计算其相似度,根据测试样本和各类的相似度来决定其分类,在小样本数据的分类任务中具有很好的效果。文献[61]提出了粗粒度原型匹配网络Meta-RPN,使用基于度量学习的非线性分类器代替传统的线性目标分类器,去处理查询图片中的锚框和新类之间的相似性,从而提高对少量新类候选框的召回率。文献[62]提出一种基于网络匹配的元学习方法MGIMN,它执行实例比较,然后聚合以生成类匹配向量,实例比较的关键是类特定上下文和情节特定上下文中的交互匹配。
基于原型网络的方法关键思想是寻找各类别在嵌入空间中的原型,学习一个度量函数以找到该类别的原型中心。匹配网络对训练集和测试集用了两个不同的嵌入函数,而原型网络中的训练集和测试集都是同一个嵌入函数。原型网络利用每个样本类别中所有样本的平均值来代表该类,并通过余弦距离计算样本和原型的相似度。文献[56]提出一种可用于小样本学习的原型网络,并通过计算样本和原型的距离来确定所属类别,此方法在小样本数据取得了很好的分类效果。文献[63]提出基于距离权值的原型网络和子空间原型网络,提高了小样本图像分类的准确率。原型网络可应用于零样本学习,但是该方法只通过一个原型来代表整个类,可能会导致一些有效信息的丢失,而且度量方式的选择也非常困难。研究人员可以在已有基于原型网络的小样本学习研究的基础上,在原型表示和度量选择等领域进一步深入探索[64]。文献[65]提出一个基于样本自适应的动态原型网络DPNSA,用于小样本恶意软件检测。该方法将原型定义为支持集中每个类的所有恶意软件样本的动态嵌入的平均值;然后提出了一种双样本动态激活函数,利用双样本的相关性来减少样本之间不相关的特征对度量的影响;最后使用基于度量的方法计算查询样本与原型之间的距离,以实现恶意软件检测。
本文基于关系网络的方法来研究距离度量函数的表示,提出学习一种深度网络的方式来设计相似性的度量标准。在关系网络中,度量的选择极为关键,可以通过学习的方式确定度量,这避免了手工选取度量的弊端。文献[66]提出一种基于CNN 的关系网络小样本分类模型,代替固定度量方式的线性分类器,关系网络利用神经网络模型提取样本特征并拼接后使用关系模块计算出相似性度量。文献[67]提出一种基于注意力关系网络的小样本无线胶囊内镜图像分类方法,将关系网络、注意力机制和元学习训练策略相结合,在少量标记样本下对无线胶囊内镜图像进行有效分类。文献[68]提出一种适用于小样本学习的多尺度克罗内克积关系网络MsKPRN,该方法将特征图与从克罗内克积模块生成的空间相关图相结合,以捕获比较特征之间的位置相关性,然后将它们馈送到关系网络模块,该模块以多尺度方式捕获组合特征之间的相似性。
基于图神经网络的方法是一种基于深度学习的处理图领域信息模型,每个样本都设定为图中节点,可同时学习所有节点和边的嵌入向量。文献[69]提出图神经网络,对图节点之间的依赖关系进行建模。由于其较好的性能和可解释性,已被应用到基于度量学习的小样本学习上。文献[70]提出一种基于图神经网络的小样本学习模型,使用图神经网络提取两个节点间的特征差异,将小样本学习扩展到半监督学习与主动学习,其提出一种基于图卷积网络小样本短文本分类模型,在异构图卷积网络中利用双重注意力机制度量不同相邻节点的重要性和不同节点类型对当前节点的重要性,可有效缓解小样本短文本分类过程中出现的语义稀疏与过拟合问题。文献[71]借鉴图神经网络的思想,并引入了两种惩罚项解决小样本学习中梯度消失和过拟合问题。文献[72]提出一种新颖的混合GNN 模型HGNN,该模型由两个GNN、一个实例GNN 和一个原型GNN 组成,这些GNN 充当特征嵌入适应模块,用于将元学习特征嵌入快速适应小样本学习中的新任务。文献[73]提出一种用于小样本学习任务的新型标签引导图学习神经网络模型LGLNN,该模型结合标签信息,通过采用成对约束传播来学习GNN 的最佳度量图,可以通过聚合来自相邻边的度量信息来学习每个图边的度量,从而可以协同一致地对所有边进行度量学习。
匹配网络在输入数据不成对情况下也可获得类似KNN 的度量识别准确率。关系网络在匹配网络模型基础上实现了更复杂的距离度量,实际的识别性能会比匹配网络更好。原型网络反映了更简单的归纳偏差,更利于数据少的情况,在存在噪声数据的场景中,原型网络一般会取得更好的学习性能[5]。基于度量学习的小样本学习方法简单易操作,便于计算和公式化,只需通过距离来衡量样本间相似度,通过对比减轻样本稀少带来的负面影响[74]。但是模型过度依赖度量方式的选择和特征表示的质量,在小样本数据情况下,只通过简单的距离衡量相似度会导致准确率降低[75]。基于度量的小样本学习方法借助非参数化的分类模型,降低了特征提取器的训练难度,更加适合小样本分类,而且模型结构更加灵活和高效。
2.4 基于元学习的小样本学习方法
在小样本学习中,元学习从大量先验任务中学习元知识,然后指导模型更好地完成小样本任务[4]。基于元学习的小样本学习方法如图6 所示,主要思想是设计一种快速搜索到模型最优参数的方法,加速学习模型在新的任务上的收敛速度[18]。常用的基于元学习的小样本学习方法有模型未知元学习方式、元转移学习和记忆神经网络元学习。
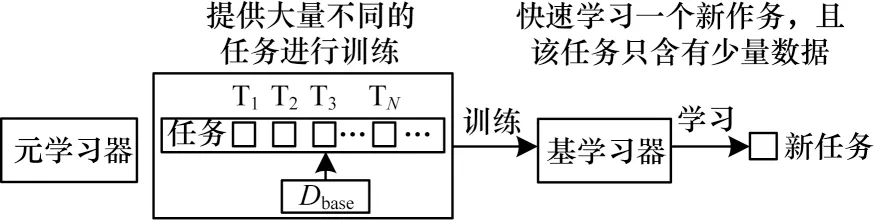
图6 基于元学习的小样本学习方法Fig.6 Few-shot learning method based on meta-learning
基于模型无关元学习方法的更新方式与模型之间没有关联,只需要在更新学习器权重的时候使用梯度,并且也没有引入更多的参数。文献[76]提出一种模型无关元学习算法MAML,该方法重新定义了梯度下降算法,设计了一个与模型无关的元学习器,只需少量梯度下降次数和少量新任务样本就能生成很好的泛化性能。文献[77]提出了未知任务元学习方法TAML,在输出预测时加入了一个正则化项,以避免元学习模型对训练任务过拟合。文献[78]将MAML 应用到了文本领域,提出一种基于注意力机制的未知任务元学习方法。文献[79]在MAML 基础上,同时训练参数初始化、更新方向及步长,提高了模型性能。文献[80]提高了MAML 对高维数据的适应度,通过大量训练样本训练特征提取器,获得参数生成模型以提取各类参数。文献[42]结合MAML 与模型回归网络,使用常见的参数初始化方法,使模型支持小样本的快速学习。文献[81]结合MAML 与数据增强,提出基于生成伪标签的MAML 模型GP-MAML,利用查询集的统计数据来提高小样本学习中新任务的性能。
基于元转移学习的方法主要应用在浅层卷积网络模型中,可有效解决面对深度神经网络时极易导致过拟合及深层网络性能降低的问题。文献[42]提出了元转移学习模型MTL,该模型使用大量数据集训练深度神经网络,将获得的预训练网络权重进行缩放和平移,在不增加网络神经元数量的情况下,模型得到快速拟合并解决灾难性遗忘问题[82]。文献[83]提出一种元转移学习方法,基于零样本的超分辨率,找到适用于内部学习的通用初始化参数,利用梯度更新来训练,效果较好。文献[84]通过改进注意力网络模型,提出一种注意力元转移学习方法AttentionMTL,在小样本虹膜识别中获得了很高的准确率。
基于记忆神经网络的方法可通过在神经网络上添加记忆网络来实现学习经验的长时间保存。早在2001 年,文献[48]就证明了记忆神经网络可适用于元学习。记忆神经网络元学习包括记忆增广神经网络、基于长短时记忆模型的元学习等。其中记忆增广神经网络的元学习方法使用基于外部记忆的加权优化机制代替原来的随机梯度下降优化器,基于长短时记忆模型的元学习方法使用基于长短期记忆网络的元学习器来代替原来的随机梯度下降优化器,这样能够使整个优化过程兼容小样本学习任务。文献[60]基于外部记忆增强神经网络提出了匹配网络算法,在小样本分类任务中表现出色。文献[85]提出一种基于长短期记忆网络的元学习器模型,替代了随机梯度优化器,以使用小样本学习神经网络参数。文献[86]借鉴神经图灵机引入外部记忆模块,提出一种具备记忆增强神经网络的小样本元学习模型,能够对于少量的样本类别进行记忆增强,并且可以针对单个样本进行快速学习。
基于元学习的小样本学习方法通过基学习器学习先验任务,使模型具备自动学习能力,能够学习训练之外的知识,在解决不同类问题时变得灵活。元训练提升基类泛化能力会导致模型对新泛化能力变差,模型复杂度较高,需要改进方面较多。如何设定任务通用参数和特定参数,有效训练元学习模型等一直是该领域研究热点。此外,不同任务的数据具有不同分布,数据分布差异较大会导致模型难以收敛。元学习机制缺乏可解释性,如何从理论上解释元学习,也是今后重要的研究方向[5]。
3 小样本学习数据集和评价指标
3.1 小样本学习数据集
早期的小样本学习研究主要集中在小样本图像识别的任务上,以Mini-Image 和Omnigraffle 两个数据集为代表。一些标准开放的小样本数据集被广泛使 用,主要包括Omniglot、Mini-ImageNet、Tiered-ImageNet、CUB-200、CIFAR-100、Stanford Dogs 和Stanford Cars,其中:Omniglot 是单样本学习最常用的数据集;Mini-ImageNet 是小样本学习最常用的数据集;CIFAR-100、Stanford Dogs 和Stanford Cars 是细粒度小样本图像分类最常用的数据集。近年来,在自然语言处理领域也开始出现小样本学习的数据集,如FewRel、ARSC 和ODIC 数据集。
1)Omniglot,火星文数据集,主要是各种字母组成的手写数据集,该数据集由Amazon 亚马逊的Mechanical Turk收集。其中包含50个字母的1 623个手写字符,每个字符都是由20 个不同的人手写得到,即每类样本含有20 个样本。
2)Mini-ImageNet,是由google DeepMind 团 队从ImageNet 提取得到的,其中包含100 个类,如蘑菇、鸟等类别,每类含有600 个图像。
3)Tiered-ImageNet,是ImageNet 的子集,相比Mini-ImageNet 数据集,Tiered-ImageNet 数据集中类别更多,有608 种,共16 185 张图像,每一类约有1 281 张图片。
4)CUB-200,是一个鸟类图像数据集,由加州理工学院提出,包含200 种鸟类,共计11 788 张图像,每类约60 张图片。
5)CIFAR-100,共100 个类,每类包含600 张图像,共20 个父类和100 个子类,每个图像有一个父类标签和子类标签。
6)Stanford Dogs,共20 580 张图像,包括120 类狗的样本,一般用于细粒度图像分类任务。
7)Stanford Cars,共16 185 张图像,包括196 类车的样本,一般用于细粒度图像分类任务。
8)FewRel,小样本关系分类数据集,共70 000 个关系样本,包括100 个类,每类包含700 个关系样本。
上述部分数据集的相关信息如表3 和图7 所示。由文献[87]的实验结果可知,类别越多或类内样本越多,对小样本图像进行分类越有利,这表明数据量级的大小对小样本图像的分类结果具有一定影响。

图7 部分小样本公用数据集样本示例Fig.7 Sample examples of some few-shot public datasets
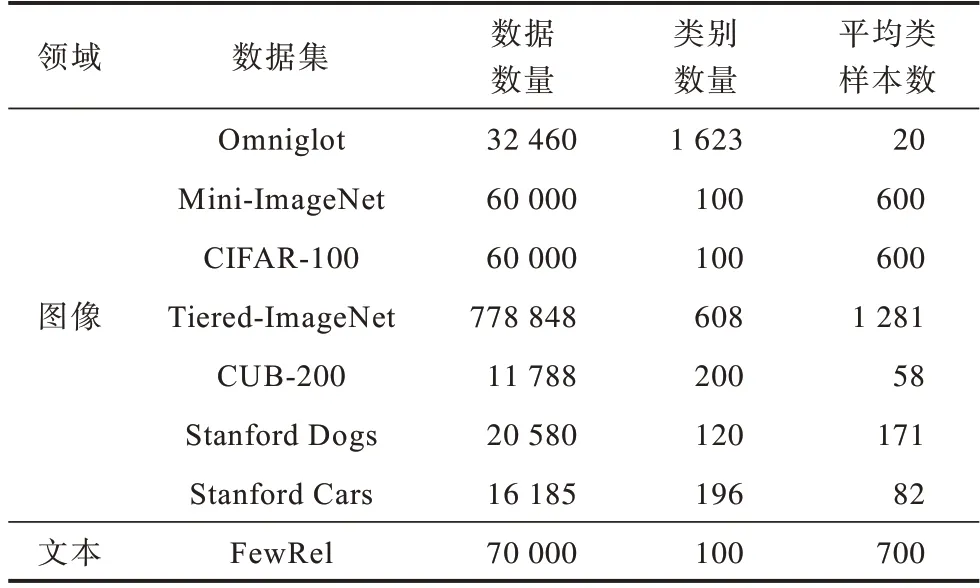
表3 部分小样本公用数据集信息Table 3 Few-shot public dataset information
3.2 小样本学习评价指标
评价指标对机器学习任务非常重要,不同的机器学习任务具有不同的评价指标。当前对小样本数据的分类结果将从整体评估指标和单类别评估指标这两个层次来度量。整体评估指标可以度量整个数据集上的分类结果,而单类别评估指标则更细致地度量每一个类别的分类结果。
3.2.1 单类别评估指标
对于单个类别的评估和传统分类任务一样,相关指标主要包括精确率(Precision)、召回率(Recall)和F 值(F1-score)等。
1)精确率。精确率是指用于衡量分类结果中分类正确的正样本数和全部正样本数的比例,用来分析正样本被预测正确的概率大小。精确率计算公式如下:

其中:TTP代表正类被判定为正类;FFP代表负类被判定为正类。
2)召回率。召回率是指用于衡量分类过程中被正确分类的正样本数占被正确分类的总样本数的比例。召回率计算公式如下:

其中:FFN代表正类被判定为负类。
3)F 值。F 值是精确率和召回率的调和平均值,用于综合评估分类结果的准确性。F 值计算公式如下:

3.2.2 整体评估指标
整体评估指标为准确率(Accuracy),如果多分类存在显著的不平衡,则可以使用各类精度的平均与多分类版的几何平均、曲线下平均面积等指标。
1)准确率。准确率是指用于衡量分类检测过程中被检测模型分类准确的样本数和全部样本数占比。准确率计算公式如下:
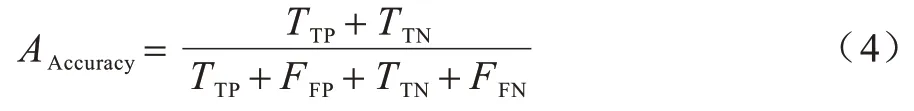
其中:TTN代表负类被判定为负类。
2)几何平均G-mean(GM)。几何平均指标评估一个学习算法的综合性能。在数据不平衡时,这个指标具有参考价值,可以用来评定数据的不平衡度。GGM等于所有召回率的几何平均值,计算公式如下:

3)曲线下平均面积(MAUC)。曲线下平均面积是AAUC的多类扩展,计算公式如下:

其中:AAUC为ROC 曲线下的面积。
3.3 面向小样本数据的机器学习方法实验
为了更好地对比已有面向小样本数据的机器学习方法和常用数据集以进行后续研究,本节整理了一些基于典型小样本学习方法在Omniglot 和Mini-ImageNet 数据集上的实验结果,因为Omniglot 和Mini-ImageNet 数据集使用最多,其他数据集相对使用较少,所以选择了5-way 1-shot 和5-way 5-shot 的结果进行比较。具体如表4 所示。
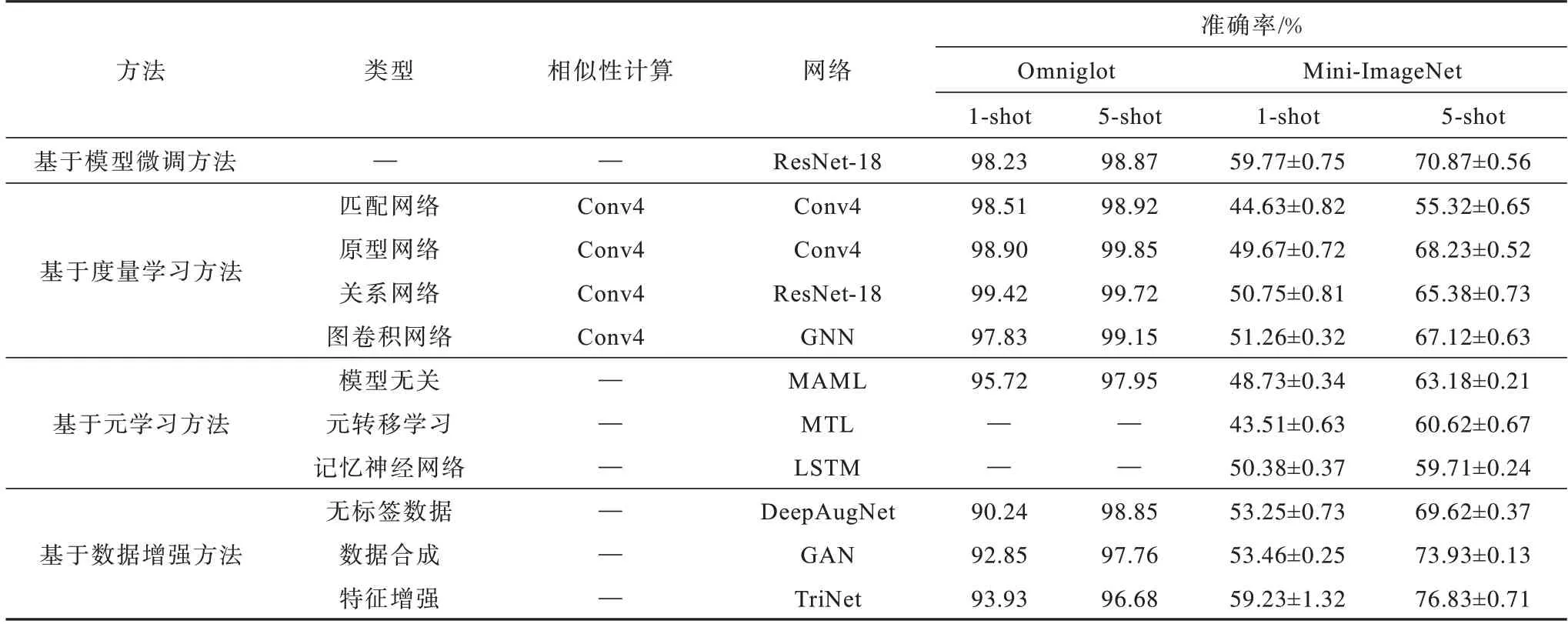
表4 小样本学习方法在Omniglot 和Mini-ImageNet 数据集上的准确率Table 4 Accuracy of few-shot learning methods on Omniglot and Mini-ImageNet datasets
从表4 可以看出,对于任意机器学习方法,每个数据集中5-shot 都比1-shot 的准确率高很多。这表明可用于训练的数据越多,模型学到的知识也越多,分类效果就会越好。由于Omniglot 数据集比较简单,所有模型在1-shot 的准确率都在92%以上,在5-shot 的准确率都在96% 以上,部分准确率接近100%,可提升的空间较少。在Mini-ImageNet 数据集上,不同模型之间的提升较大,而且还有较大的提升空间。因此,后期小样本机器学习方法大都会在Mini-ImageNet 数据集上进行验证。由于本节使用不同机器方法,采用的数据预处理及网络框架等设置并不相同,因此很难对比不同机器学习方法的优势。
4 小样本学习方法总结及发展趋势
小样本学习是在人类的学习方式和人工智能之间建立联系的桥梁,使深度学习在样本稀有的案例上部署成为可能,未来面向小样本数据的机器学习方法的研究会逐渐深入,并将取得良好的发展。
4.1 小样本学习方法总结
小样本学习各类方法的总结和优缺点如表5所示。
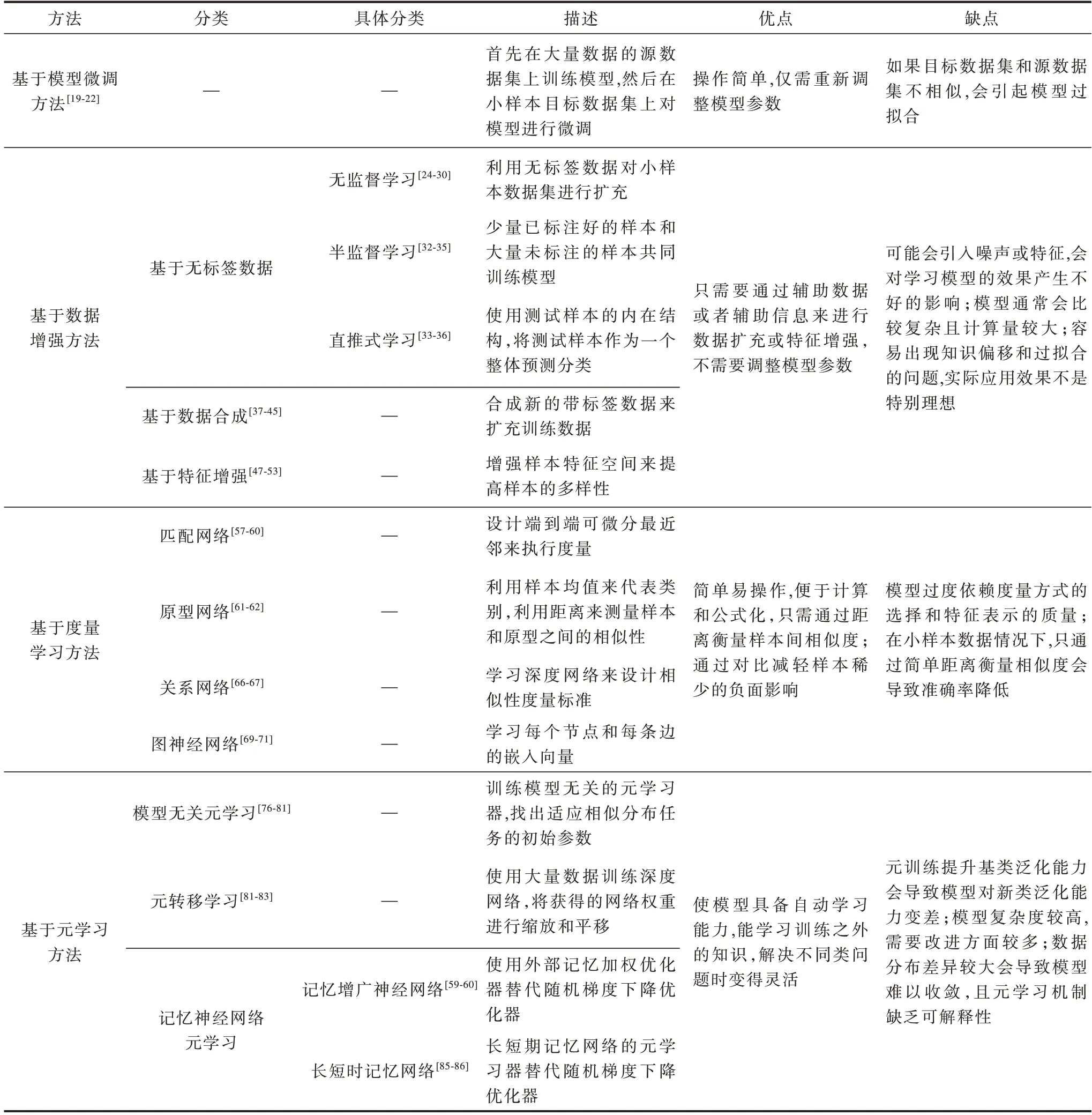
表5 小样本学习方法优缺点对比Table 5 Comparison of advantages and disadvantages of few-shot learning methods
基于模型微调的小样本学习方法通过大量样本的源数据集对模型进行训练,然后在小样本目标数据集上进行微调,操作简单而且仅需重新调整参数,但是如果目标数据集和源数据集不相似,会引起模型过拟合。一般将模型微调方法和数据增强、度量学习或元学习等方法结合,以避免少量数据带来的模型过拟合问题。基于数据增强的小样本学习方法仅需通过辅助数据或者辅助信息来进行数据扩充或特征增强,不需要调整模型的参数,但是可能会引入噪声或特征,对学习模型的效果形成不好的影响,模型通常会比较复杂且计算量较大。现有的机器学习方法在实际的数据增强中容易出现知识偏移和过拟合的问题,所以实际的应用效果并不是特别理想,一般将数据增强的思想融入度量学习或元学习的方法中。基于度量学习的小样本学习方法模拟样本之间的距离分布,使用非参数估计的方法进行分类,简单易操作,便于计算和公式化,只需通过距离来衡量样本间相似度,通过对比减轻样本稀少带来的负面影响,但是模型过度依赖度量方式的选择和特征表示的质量,在小样本数据情况下,只通过简单的距离衡量相似度会导致准确率降低[76]。基于度量的小样本学习方法借助非参数化的分类模型,降低了特征提取器的训练难度,更加适合小样本分类,而且模型结构更加灵活和高效。基于元学习的小样本学习方法通过基学习器学习先验任务,通过辅助元学习器学习策略,加速学习模型在新任务上的收敛速度,使模型具备自动学习能力,能学习训练之外的知识,在解决不同类问题时变得灵活。元训练提升基类泛化能力会导致模型对新泛化能力变差,模型复杂度较高,需要改进的方面较多。不同任务的数据具有不同数据分布,数据分布差异较大会导致模型难以收敛,且元学习机制缺乏可解释性。
4.2 发展趋势
传统深度学习模型在训练数据不足以及训练数据和测试数据不是同分布的情况下性能存在明显下降,小样本学习要解决的问题是如何提升深度学习模型的泛化能力,以实现真正的强人工智能。通过对当前小样本学习研究进展的梳理,下文从数据层面、理论研究和应用研究3 个方面对小样学习的未来发展进行展望。
1)小样本学习的数据层面:(1)现有的面向小样本数据的机器学习模型都需要在大量数据集上预训练,除了在小样本图像分类任务中有被广泛应用的标准数据集外,其他很多领域都缺少可用的预训练数据集,如何构建能被多种任务广泛使用的具备细粒度标记的小样本学习数据集,并选择合适的数据标记方法是一个非常有必要的研究方向;(2)在许多应用场景中,有标签样本量很少,但是大量的无标签数据拥有非常丰富的信息,如何更好地使用无标注数据信息训练模型值得深入研究。为了使小样本学习更接近真实场景,需要进一步研究和寻找不依赖模型预训练和先验知识就能获得较好效果的机器学习方法。
2)小样本学习的理论研究:(1)针对基于度量学习的小样本学习方法,以距离函数度量的方法相对成熟,通过神经网络计算样本间相似性将成为主流的度量方法,如何设计更优秀的神经网络度量方法是未来研究趋势;(2)针对基于数据增强的小样本学习方法,如何设计更好的生成方法,更好地利用无标注数据或辅助特征是未来研究的方向;(3)针对基于元学习的小样本学习方法,因为元学习无法从小样本中获得足够可理解的信息,使其学习不具备可解释性,后续可以从元学习注意力机制和元学习因果推断机制[75]方面进一步研究,如何设计更合理的元学习机制,使用先验知识把部分不可解释问题转化为可解释问题,并证明其合理性是重要的研究方向[88];(4)已有的小样本学习方法大多运用单一的数据增强或者转移学习技术,未来可以尝试不同小样本学习方法的融合,从数据和模型两个层面共同改进,也可以尝试将主动学习和强化学习等先进框架应用到小样本学习上。
3)小样本学习的应用研究:现有的小样本学习研究主要集中在图像分类和视觉任务等领域,但在工业界仍然存在大量的实际问题也迫切需要通过小样本学习来进一步解决,虽然可能有少量应用,但是效果还不太理想。典型的例子包括商品分类、新药研发、罕见疾病诊断、实时环境感知、机器与人类的交互等场景。在这些场景中,训练样本往往难以获取,或是需要模型即时做出响应,而小样本学习恰好可以提升深度学习模型对样本数据的利用效率,这些都是未来小样本学习的重要应用场景和应用研究方向。
5 结束语
拥有从少量样本数据中学习和概括的能力是将人工智能和人类智能进行区分的分界点,小样本学习在机器学习领域具有重要意义和挑战性。本文分别阐述了基于模型微调、数据增强、度量学习和元学习这4 大类小样本学习方法的最新研究进展,整理和分析了常用方法在两种公开数据集中的表现,并对各种方法及其优缺点进行了总结。在此基础上,对面向小样本数据的机器学习方法的未来研究方向进行了展望,未来可从数据层面构建能被多种任务广泛使用的小样本学习数据集,从理论层面尝试融合不同小样本学习方法,从应用层面提升深度学习模型对样本数据的利用效率,以适应各种实际应用场景。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
