
基于深度强化学习的云边协同DNN 推理
2023-01-09 14:28刘先锋
计算机工程 2022年11期
刘先锋,梁 赛,李 强,张 锦
(湖南师范大学信息科学与工程学院,长沙 410081)
0 概述
近年来,随着计算机与通信技术的高速发展,网络边缘设备数量及其所产生的数据量呈现爆炸式增长趋势。深度神经网络(Deep Neural Network,DNN)[1]作为支持现代智能移动应用的关键技术,因其高精度和可靠的推理性能,在计算机视觉[2]、自然语言处理[3]、机器翻译[4]等大规模数据处理场景中得到广泛应用与研究。由于DNN 是计算密集型网络,通常包含十个以上的网络层及大量的神经元节点,对存储和计算资源要求很高,难以部署在资源受限的边缘设备。现有基于云计算的解决方案存在带宽资源消耗大、通信延迟无法预测和图像数据隐私泄露等问题。为了解决此类问题,文献[5-6]提出基于云边协同的DNN 分布式推理,通过将DNN 推理部分计算从云端下推到移动边缘,以缓解云服务器的负载压力,实现DNN 推理的低延迟和高可靠性[7]。然而,现有工作仅考虑同构设备下的静态划分策略,未考虑网络传输速率、边缘设备资源和云服务器负载等变化对DNN 推理计算最佳划分点的影响以及异构边缘设备集群间DNN 推理任务的最佳卸载策略。
针对动态环境下边缘设备与云服务器间DNN 推理计算划分以及异构边缘设备集群(Edge Device Cluster,EDC)间DNN 推理任务卸载问题,本文提出基于深度强化学习(Deep Reinforcement Learning,DRL)的自适应DNN 推理计算划分和任务卸载(DNN Inference Computation Partition and Task Offloading Based on Deep Reinforcement Learning,DPTO)算法。DPTO 算法对DNN 模型各网络层的计算资源需求和输出数据大小进行分析。根据模型结构特征,在资源受限的边缘设备和云服务器间建立分布式DNN 协作推理框架,以此优化DNN 推理时延。在DNN 推理计算划分的基础上,考虑推理任务在异构边缘集群间的卸载问题,对DNN 推理计算划分和任务卸载的优化目标和约束条件进行分析,建立DNN 推理计算划分和任务卸载的数学模型。DPTO算法具有自适应学习能力,能根据当前环境为DNN推理计算划分和推理任务卸载选择近似最优策略。最终选取3 种常用的DNN 模型、不同类型的边缘设备和网络传输速率验证DPTO 算法的有效性。
1 相关工作
目前,为在算力和存储等资源受限的边缘设备上部署和实现低时延DNN 推理,研究人员提出了一系列关于DNN 推理的优化技术。现有优化技术包括设计轻量级模型、模型压缩方法和模型提前退出机制。文献[8]提出SqueezeNet 小型DNN 模型,其将参数量缩减为原来的1/50,极大降低了模型复杂度。文献[9-10]提出模型压缩方法,通过参数共享、剪枝不敏感或冗余的权重参数,降低模型复杂度和资源需求,实现在资源受限边缘设备上的低延迟和低能耗DNN 模型推理。文献[11-12]提出模型分支退出机制,通过仅处理较为靠前的若干网络层来加速DNN 推理。以上技术虽然能有效降低资源需求、加速DNN 推理速度,但同时也会带来模型精度的损失,难以适应实际应用场景中DNN 推理愈加严格的精度要求。
研究人员尝试在边缘设备上部署和运行完整的DNN 模型,主要分为边边协同和云边协同。边边协同通过将多个边缘设备作为计算节点参与DNN 推理以满足单个边缘设备的计算需求,提升系统的整体计算能力。DNN 模型通常由卷积层、池化层和全连接层组成,通常卷积层消耗的算力最多。针对这一特性,文献[13]提出DeepThings,利用FTP(Fused Tile Partition)划分方案在空间上将卷积层划分成多个分区任务,并分配给不同的移动边缘设备。文献[14]提出一种寻找最优网络层的划分方式和设备分区配置机制。在良好的网络环境下,文献[13-14]研究有效提高了DNN 推理速度,然而DNN 卷积层划分之后,相邻分区之间存在重叠数据,将导致设备间高频的重叠数据交互,当通信带宽降低时,DNN推理时延显著增加。
本文通过在Intel Mini PC CPU 1.9 GHz 上执行VGG19 模型[15]来展示DNN 模型的计算和通信特征。图1 给出了VGG19 各层的输出数据内存大小和计算时延,其中,input 表示输入层、conv 表示卷积层、fc 表示全连接层、pool 表示池化层。从图1 中可知:1)VGG19 各层有显著不同的输出数据内存大小,卷积层增加数据,池化层减少数据,池化层的计算时延较小,卷积层和全连接层的计算时延较高;2)每一层的计算时延和输出数据内存大小不成正比关系,计算时延大的层不一定有较大的输出值。基于以上结论,将DNN 模型划分成两部分,计算量小、传输时延大的前几层放在边缘设备端处理,计算量大、传输时延小的后几层放在云端处理。该方法充分利用边缘设备和云服务器的资源,不同层级的计算设备承担不同算力需求的任务,有效权衡了移动边缘设备和云服务器的计算量和通信量。针对基于云边协同的DNN 分布式推理,文献[5]提出Neurosurgeon,从最小化时延和能耗的角度出发,基于回归模型估算DNN 模型每一层执行时延,结合当前网络带宽返回边缘设备和云服务器间DNN 推理计算的最优划分点,以此达到时延或能耗最优。文献[6]利用边缘设备和云服务器的可用资源,为给定应用程序提供有效的模型部署方案。

图1 VGG19 每层输出数据内存大小及计算时延Fig.1 Memory size of output data and computation delay of each layer in VGG19
虽然目前已有基于云边协同的DNN 分布式推理研究,但是这些研究存在以下不足:
1)对于边缘设备与云服务器间DNN 推理计算的划分,网络传输速率、边缘设备资源以及云服务器负载等变化都会直接影响到DNN 推理计算的最佳划分。以VGG19 为例,图2~图4 分别给出了DPTO 算法在不同网络传输速率、边缘设备和云服务器负载下,以每层作为划分点的端到端推理时延以及当前环境下最佳划分点的选取,其中:第一列input 表示以输入层作为划分点,将DNN 推理计算全部卸载到云服务器执行;最后一列fc3 表示以输出层作为划分点,将DNN 推理计算全部放在边缘设备上执行;其他列表示以该层作为划分点,输入层到该层的推理计算放在边缘设备执行,剩余网络层的推理计算放在云服务器执行;箭头表示当前环境下的最佳划分策略。

图2 VGG19 在不同网络传输速率下以每层作为划分点的端到端推理时延Fig.2 End-to-end inference delay of VGG19 at different partition points under different network transmission rates

图3 VGG19 在不同边缘设备下以每层作为划分点的端到端推理时延Fig.3 End-to-end inference delay of VGG19 at different partition points under different edge devices

图4 VGG19 在不同云服务器负载下以每层作为划分点的端到端推理时延Fig.4 End-to-end inference delay of VGG19 at different partition points under different cloud server loads
2)已有基于云边协同的DNN 模型推理仅考虑了单个边缘设备与云服务器的协作,在实际场景中通常有多个异构边缘设备,当把所有任务全部卸载到单个边缘设备时,会使该边缘设备超出承载范围,造成较大的响应延迟以及其他边缘设备计算资源的浪费。因此,在多个异构边缘设备上进行任务卸载,实现边缘集群内部的协作以此提高计算性能是一个亟待解决的问题。
异构边缘集群中共有m台边缘设备,DNN 模型含有n层,在异构边缘集群上进行DNN 推理计算划分和任务卸载的所有情况为m×(n+1)。求解空间随着DNN 模型层数和边缘设备数量的增加而增大。传统解决方法包括遗传学算法、启发式算法、迭代搜索算法等,这些算法在解决此类问题时取得了一定成果。为了得到最优解,这些算法的设计需要专家知识的辅助,这会导致算法缺乏灵活性、不稳定、效果提升不明显。随着深度学习技术的发展,DRL[16-17]将深度学习与强化学习[18]相结合作为一种人工智能算法,被广泛应用于组合优化、多方博弈等各种复杂决策求解问题,具有重要研究价值。DRL的主要思想是在一个交互环境中利用创建的智能体(agent)不断与环境互动,通过环境反馈的奖励或惩罚信息,逐步逼近最优结果。相比于传统算法,DRL具有以下优势:1)与许多一次性优化方法相比,深度强化学习可以随环境变化调整策略,更好地适应复杂环境的变化;2)DRL 在学习过程中不需要了解网络状态随时间变化规律的相关先验知识。DRL 通过不断与环境进行交互,能够学习不同状态下应该采取的最优策略。基于以上特点,深度强化学习是解决复杂环境下决策问题的有效方法[19-20]。为此,本文提出基于DRL 的自适应DNN 推理计算划分和任务卸载算法,对于不同的推理任务,该算法能有效降低推理任务执行总时延。
2 系统框架和推理时延
2.1 系统框架
基于深度强化学习的云边协同DNN 推理框架如图5 所示。该框架由3 个部分组成:1)时间预估模型,基于当前边缘设备和云服务器资源,在不同边缘设备和云服务器上建立不同类型DNN 层的时间预估模型;2)DNN 推理计算划分和任务卸载,结合当前网络传输速率、边缘设备资源和云服务器负载,通过DPTO 算法选择DNN 推理计算划分和任务卸载的最佳策略;3)DNN 分布式推理,根据DNN 推理计算划分和任务卸载策略,将划分点之前的DNN 推理计算卸载到相应的边缘设备上执行,划分点之后的DNN 推理计算卸载到云服务器执行。

图5 基于深度强化学习的云边协同DNN 推理框架Fig.5 Framework of cloud-edge collaborative DNN inference based on deep reinforcement learning
2.2 时间预估模型
在DNN 推理计算过程中,主要计算集中于卷积层和全连接层。卷积层与全连接层的计算时间与每秒浮点运算次数(Floating Point Operations,FLOPs)具有相关性,通过计算FLOPs 可以预估卷积层和全连接层的计算时间,为DNN 推理计算划分和任务卸载提供决策依据。文献[21]介绍了卷积层和全连接层的FLOPs 计算公式,如式(1)和式(2)所示:

其中:H和W表示输入特征图的高和宽;Cin和Cout表示卷积计算的输入和输出通道数;K表示卷积核的大小;I、O表示全连接层的输入和输出维数。
假设FLOPs 与计算时间的预估模型计算公式如式(3)~式(5)所示:

其中:x表示FLOPs;k表示设备计算能力;y表示计算时间;b表示卷积层或全连接层计算的固有时间开销。通过设置不同的输入特征图(H×W)、输入输出通道数(Cin,Cout)以及输入和输出维数(I,O)在边缘设备上分别做卷积和全连接运算,求得FLOPs 和平均计算时间。记录多组FLOPs 与计算时间的值,使用最小二乘法求得预估模型。
2.3 DNN 推理时延
DNN 模型含有n层,将DNN 推理计算在边缘设备和云服务器上进行划分,所有可选划分策略p={0,1,…,n},其中p=n和p=0 为特殊的分区点,p=n表示DNN 推理计算全部放在边缘设备上处理,p=0 表示DNN 推理计算全部上传到云服务器处理。0<p<n表示输入层到第p层在边缘设备上执行,剩余的网络层传输到云服务器执行,网络层第p层的输出数据大小为Dp。当采用云边协同方式执行DNN 推理时,单个图片的推理时延主要由以下3 个部分组成:1)边缘设备上的执行时延Td;2)中间输出数据上传到云服务器的传输时间Tt;3)云服务器上的执行时延Tc。由于推理结果往往很小,其返回的传输延迟通常忽略不计。

基于式(6)得到的预估模型预测各层在边缘设备和云服务器上执行所需时间,每一张图片的推理时延可以表示如下:

其中:表示第j层在移动设备上执行所需的时间;Dp表示第p层的输出数据大小;B表示网络传输速率;表示第j层在云服务器上的执行时间。任务T中含有k张图片,则处理该任务所需的总时延如下:

其中:C1、C2、C3为优化目标的约束条件。在约束条件C1和C2中,M和C分别表示边缘设备的内存和CPU 资源,t表示正在执行的任务数,只有当所有任务所需的内存和CPU 资源总和少于边缘设备的总资源时,该边缘设备才可处理新的任务。约束条件C3表示所选边缘设备和DNN 推理计算划分点的策略在所有可选策略中。
3 自适应DNN 推理计算划分和任务卸载
3.1 马尔可夫决策过程
为利用DRL 方法来寻找最优解,需要把问题转化为强化学习的基本要素。首先将问题建模为马尔可夫决策过程(Markov Decision Process,MDP),MDP 可以表示为一个四元组{S,A,P,R},其中,S表示环境中的状态空间,A表示动作空间,P表示状态转移函数,P(s'|s,a)表示在状态s上执行动作a之后转变为状态s'的概率,R为奖励值函数。
1)状态空间:S={s|s=(B,EED,CCS,D)},其中,B表示当前网络传输速率为具有m个元素的序列,表示当前m个边缘设备中各设备的计算资源,CCS表示云服务器的计算资源,D=(Dinput,D1,D2,…,Dn)表示原始输入数据以及DNN 模型各层的输出数据大小。
2)动作空间:由所有可选的决策方案组成。对于DNN 推理计算划分和任务卸载而言,动作就是在边缘设备和云服务器间选择DNN 推理计算划分点以及执行该部分任务的边缘设备。基于当前状态,DNN 模型有n+1 个推理计算划分点,边缘集群中有m个边缘设备。动作空间,其中,{P0,P1,…,Pn}表示DNN 推 理计算划分点的集合,表示当前所有可用的边缘设备。
3)奖励值:环境会根据智能体执行的动作反馈相应的奖励值。奖励值越大,表示选择的动作越好。以任务推理时延为优化目标,设置任务执行响应时延的负值作为奖励值。

其中:r表示奖励值大小。
3.2 基于深度Q 网络的DNN 推理计算划分和任务卸载
Q-Learning(QL)是无监督的自适应学习算法,从与环境的交互作用中学习知识,适用于求解马尔可夫决策问题。在Q-Learning 算法中使用二维矩阵存储每一个状态下所有动作的Q 值,即状态-动作值函数Q(s,a)。当状态空间和动作空间较大时,受计算机内存限制,会导致Q 表爆炸[22]。本文提出基于深度Q 网络(Deep Q-Network,DQN)[23]的任务卸载和DNN 推理计算划分算法,DQN 算法是DRL 中的一种具体算法,使用神经网络替换Q 表,将Q 表更新转化为函数拟合问题。如图6 所示,DQN 由两个结构相同但参数不同的神经网络构成,在DQN 算法的训练过程中,Main 网络用来计算当前状态动作对的估计价值Q(s,a,w),w表示Main 网络的参数,Target网络用于计算下一状态s'在所有动作下的Q(s',a',w'),并选取最大值所对应的动作。根据所选动作a'计算目标价值函数,如式(11)所示:
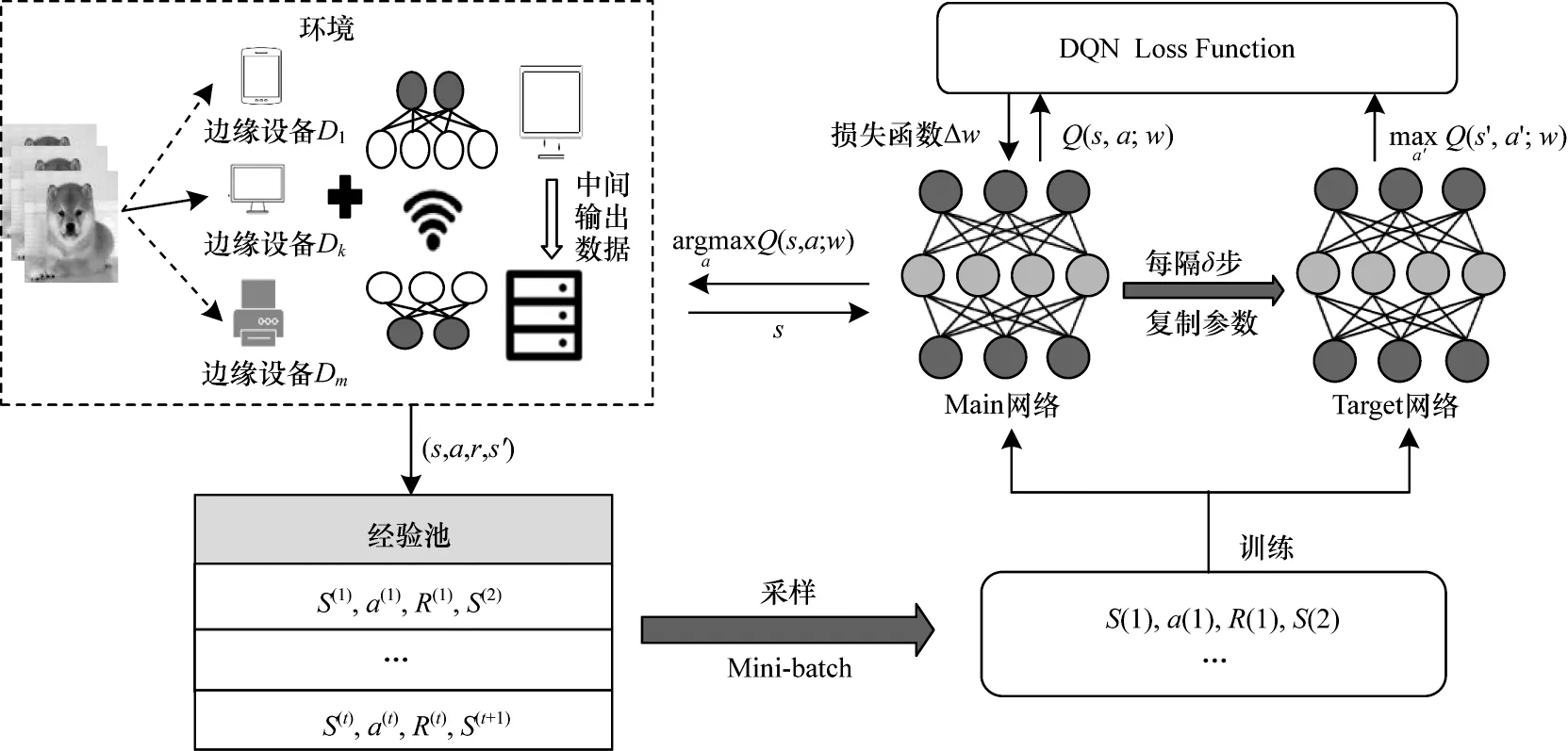
图6 基于DQN 的自适应DNN 推理计算划分和任务卸载框架Fig.6 Framework of adaptive DNN inference computation partition and task offloading based on DQN
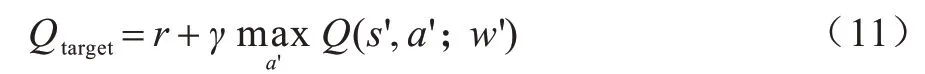
其中:r表示奖励值;γ表示折扣因子。在神经网络的参数更新过程中,Main 网络使用最新参数,在每次计算当前状态的估计价值后都会更新其参数。在每隔δ步骤之后,复制Main 网络的参数到Target 网络以更新Target 网络。
由于强化学习的动作选择是一个连续的过程,因此前后数据关联性很大,而神经网络的训练通常要求数据样本是静态独立分布。在DQN 算法中,除了构建两个神经网络降低状态间的相关性外,还使用经验回放方法解决相关性及非静态分布问题,具体做法为:对于状态s,用ε-greedy[24]策略选取动作a,与环境交互后生成一个样本(s,a,r,s'),将其储存在经验池中。当经验池中的元组数目达到一定值(例如数量N)时,随机选择经验样本组成Mini-batch来训练DQN。当经验池容量大于N时,则会删除最老的经验样本,仅保留最后的N个经验样本。
DQN 算法训练的本质是使得当前Q 值无限接近于目标Q 值,最终达到收敛状态。损失函数定义如式(12)所示:
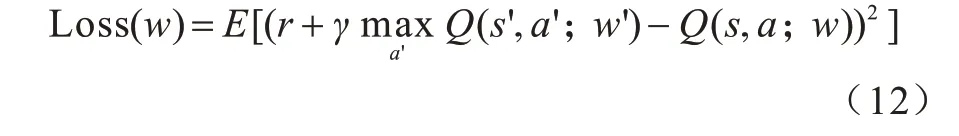
在得到损失函数后,通过损失的反向传播机制调整神经网络参数w,同时Main 网络会利用Adam优化器来不断地降低神经网络的损失函数,提高神经网络精度。
3.3 DPTO 算法
DPTO 算法用来解决异构边缘集群下的任务卸载以及边缘设备与云服务器之间的DNN 推理计算划分问题。DPTO 首先实时获取各状态特征值,agent 根据当前状态输出任务卸载和DNN 推理计算划分策略。DPTO 算法的伪代码如算法1 所示。
算法1DPTO 算法
输入当前网络传输速率B,当前各边缘设备和云服务器资源,原始输入数据以及DNN模型各层输出数据大小D={Dinput,D1,D2,…,Dn},推理任务T
输出DNN 推理计算划分和任务卸载策略
1.初始化DQN 模型;
2.初始化实验参数;
3.for episode in T do:
4.for each task do:
5.获取DNN 推理计算划分点和可用边缘设备集合Ω;
6.设置各特征值得到状态s 并传输给agent;
7.使用DQN 方法在Ω 中选择DNN 推理计算划分点和执行该任务的边缘设备;
8.if DNN 推理计算划分点为n、边缘设备计算节点为设备m then
9.任务仅在边缘设备m 上执行;
10.计算任务执行时延;
11.end
12.else if DNN 推理计算划分点为0 then
13.任务卸载到云服务器上执行;
14.计算任务执行时延;
15.end
16.else
17.DNN 推理计算划分到边缘设备和云服务器上共同处理;
18.根据式(7)和式(8)计算任务执行时延;
19.end else
20.根据式(9)计算奖励值;
21.更新DPTO 算法的最优策略;
22.end for
23.返回到步骤3;
24.end for
DPTO 算法的空间复杂度为:2d(S)+O(l)+H+E+L,其中:d(S)为神经网络参数的维度,存储两个参数相同的神经网络内存空间为2d(S);O(l)为其他参数所占的内存空间,例如学习速率、折扣因子等;H为存储所有可选动作的内存空间;E为经验池所占内存空间;L为从经验池中采样的数据样本数目的内存空间。
DPTO 算法前向推理的计算复杂度计算如下:在DPTO 算法中输入层的神经元个数为所有状态的集合s,网络的第1 个隐藏层和第2 个隐藏层的节点个数分别设为k1和k2,输出层的神经元个数为所有可选动作的集合m×n,则输入层到第1 个隐藏层的矩阵运算为[k1×s]×[s×1],计算复杂度为O(k1×s2)。以此类推,第1 个隐藏层到第2 个隐藏层的计算复杂度为O(k2×),第2 个隐藏层到输出层的计算复杂度为O(m×n×)。对于T个任务,DPTO 算法的总计算复杂度为O(T(k1×s2+k2×+m×n×))。
4 实验结果与分析
为测试DPTO 算法的可行性和有效性,本节搭建仿真实验环境,通过对比实验衡量DPTO 算法中基于深度强化学习的DNN 推理计算划分和任务卸载在时延方面的优化效果。
4.1 实验平台
实验使用阿里云服务器提供云计算支持,以Intel Mini PC CPU 900 MHz、Intel Mini PC CPU 2.4 GHz、树莓派3B+(1.2 GHz ARM Cortex-A53 处理器,1 GB 内存)模拟异构边缘设备。边缘设备和云服务器都加载已训练好的DNN 模型,边缘设备与云服务器的通信采用TCP/IP 协议,Wondershaper 设置边缘节点网络传输速率。DNN 模型推理采用PyTorch1.3 框架,Python3.7.4 编程语言。在DPTO 算法中设置学习速率为0.01,折扣因子为0.9,训练批次大小为32,经验池大小为500。DPTO 算法收敛结果如图7 所示。

图7 DPTO 算法收敛结果Fig.7 Convergence result of DPTO algorithm
4.2 DNN 推理计算划分算法评估
通过在不同环境下执行VGG19[15]、AlexNet[25]、YOLOv2[26]3 种DNN 模型,对比以下3 种经典DNN推理算法来衡量基于深度强化学习的DNN 推理计算划分(DNN Computation Partition Based on Deep Reinforcement Learning,DP)算法对DNN 推理时延的优化效果:
1)纯云计算(EC):DNN 推理计算全部卸载到云服务器执行,云服务器将推理结果返回给移动设备。
2)纯边缘计算(EM):DNN 推理计算全部放在边缘设备上执行。
3)离线划分(OF):通过在离线阶段多次测量所有DNN 推理计算划分点的执行时延,选择具有最小平均时延的划分点作为云边协同的DNN 推理计算划分点。
4.2.1 不同网络传输速率下DNN 推理时延评估
图8 给出了EC、EM、OF、DP 4 种DNN 推理算法在不同网络传输速率下处理单一图片推理所消耗的时间。对于VGG19、AlexNet、YOLOv2 3 种不同类型的DNN 模型,DP 明显优于EC、EM、OF。与EC 相比,DP 的DNN 推理时延减少了约23.45%~60.32%。在EC 中,所有数据需上传到云服务器,当网络传输速率过低时,其传输时延过大,导致整个DNN 推理时延增大。与EM 相比,DP 的DNN 推理时延减少了约31.86%~62.77%,这是由于边缘设备资源有限,DNN 推理计算都在边缘执行,响应时延较大。与OF相比,DP 的模型推理时延减少了约0.29%~22.87%,因为在不同网络传输速率下,DNN 推理计算的最佳划分点不同。在OF 中,固定的DNN 推理计算划分点不一定是当前环境下的最佳划分点。当传输速率较高时,DP 的推理时延接近于EC,其选择将整个DNN 推理计算全部上传到云服务器执行。在传输速率较低时,云边协同DP 通过结合当前环境选择最佳DNN 推理计算划分点,以使DNN 推理时延最小化。

图8 不同网络传输速率下4 种算法的DNN 推理时延Fig.8 DNN inference delay for four algorithms under different network transmission rates
4.2.2 不同边缘设备下DNN 推理时延评估
VGG19、AlexNet、YOLOv2 3 种DNN 模型在不同推理算法和边缘设备(高性能边缘设备Intel Mini PC CPU 900 MHz 和低性能边缘设备Intel Mini PC CPU 2.4 GHz)下的推理时延如图9 所示。DP 的DNN推理时间相比于EM 减少了约18.35%~39.36%,相比于EC 减少了约46.48%~61.35%。当边缘设备计算能力较强时,DP 的推理时延接近于EM,其选择将整个DNN 推理计算全部放在边缘设备上执行,避免数据传输带来较大的响应延迟。当边缘设备计算能力较弱时,DP 在边缘设备和云服务器之间自适应分配DNN推理计算或将整个DNN 推理计算全部上传到云服务器执行。由于DP 能在动态环境下做出最优决策,DNN 推理时间相比于OF减少了约6.22%~10.29%。
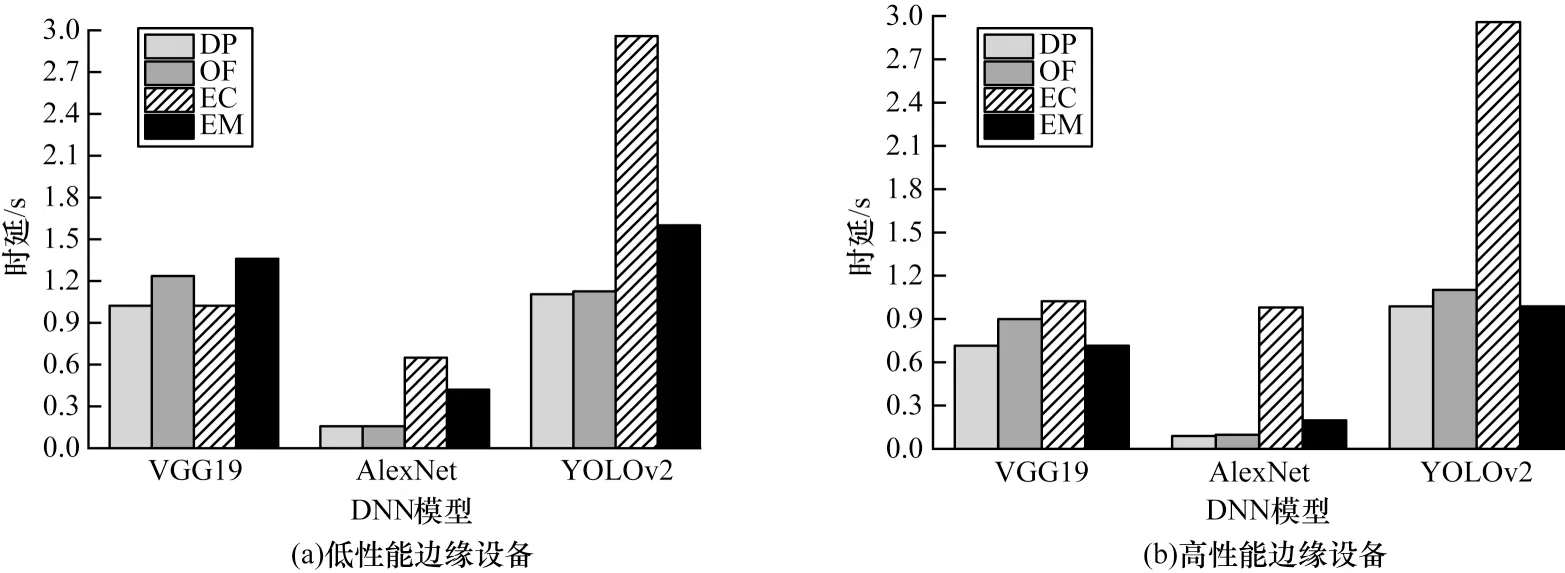
图9 不同边缘设备下4 种算法的DNN 推理时延Fig.9 DNN inference delay for four algorithms under different edge devices
4.2.3 不同云服务器负载下DNN 推理时延评估
图10 给出了4 种算法在不同云服务器负载下的DNN 推理时延。DP 的DNN 推理时延相比于EM 减少了约0.24%~55.39%,相比于EC 减少了约28.12%~48.88%。当云服务器负载相对较高时,DP 的DNN推理时延接近于EM,其选择将整个DNN 推理计算全部放在边缘设备上执行,避免云服务器负载过高带来巨大的响应延迟。当云服务器负载相对较低且网络状况良好时,DP 将DNN 推理计算全部上传到云服务器执行。在其他情况下,DP 将DNN 推理计算划分成两部分,分别在边缘设备和云服务器上共同执行。DP 的推理时延相比于OF 减少了约14.41%~27.12%,因为DP 能在动态环境下自适应选择最佳DNN 推理计算划分点。
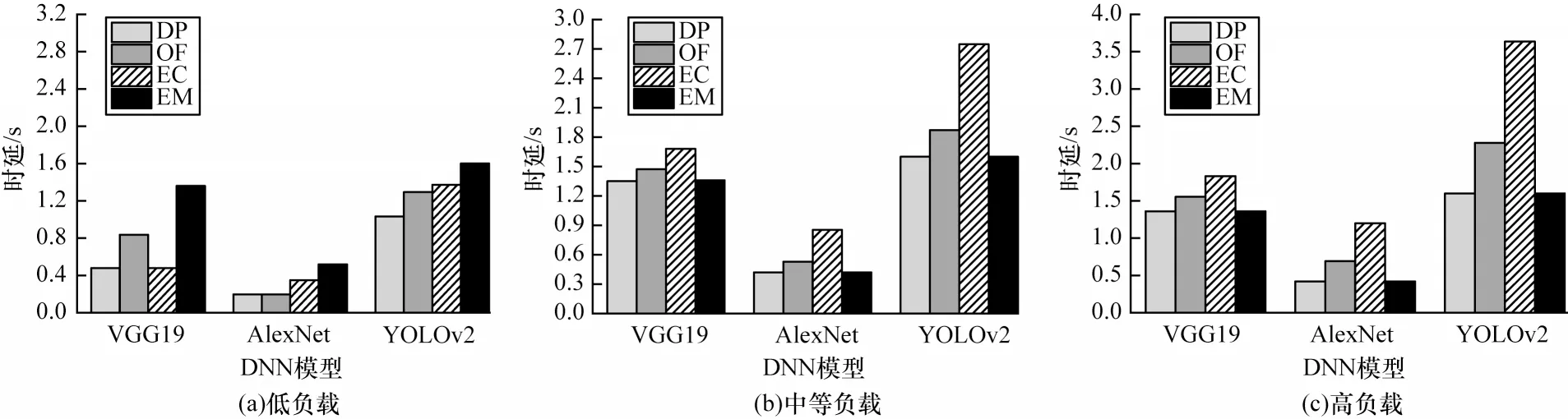
图10 不同云服务器负载下4 种算法的DNN 推理时延Fig.10 DNN inference delay of four algorithms under different cloud server loads
4.3 DPTO 算法评估
在4.2 节中验证了基于深度强化学习的DNN 推理计算划分对DNN 推理时延的优化效果,根据不同任务的推理情况,其中任务1、任务2、任务3、任务4分别包含1、30、50、100 张不同图片,对比以下3 种算法来评估DPTO 算法在DNN 推理时延上的进一步优化效果:
1)DP:仅考虑DNN 推理计算的划分,未考虑DNN推理任务在异构边缘集群上的卸载优化,其将所有任务分配给当前计算资源最多的边缘设备处理。
2)轮询(RR):将任务随机分配给边缘设备进行处理。
3)QL:具有良好学习效果的经典强化学习算法,基于Q 表选择卸载策略。
图11 给出了4 种不同任务在不同算法下的执行时间。对于4 种不同的任务,DPTO 的任务执行时间相比于DP 减少了48.08%,在DP 中把所有任务全部卸载到单个边缘设备时,会导致该边缘设备出现资源竞争问题,任务等待时间变长。而其他边缘设备上的计算资源处于空闲状态,造成响应时延的增加和计算资源的浪费。与RR 相比,DPTO 的任务执行时间减少了29.18%,由于RR 没有考虑边缘设备计算能力的差异性,边缘设备之间的负载不平衡导致任务执行产生较大时延。与QL 相比,DPTO 的任务执行时间减少了3.99%,QL 基于Q 表选择卸载策略,Q 表采用二维数组存储每一状态下的动作值函数,随着任务和边缘设备数量的增加,QL 中的状态和动作数量增多,通过遍历整个Q 表寻找最优卸载策略的开销时延增大,从而导致任务执行时延也增大。综上,不同的卸载策略对任务的执行时延有着较大的影响。当只有一个任务时,边缘设备的计算压力较小,选择最好的边缘设备就能应对该任务。但随着任务的不断增加,根据任务的大小选择合适的边缘设备计算节点对时延的优化具有重要的作用。

图11 不同任务数量下4 种算法的执行总时延Fig.11 Total execution delay of four algorithms under different number of tasks
5 结束语
目前,深度神经网络发展迅速,广泛应用于计算机视觉、自然语言处理和机器翻译等智能任务。为了优化DNN 推理性能,本文提出基于深度强化学习的云边协同DNN 推理算法。将动态环境下边缘设备和云服务器间DNN 推理计算划分以及异构边缘集群间任务卸载转换为马尔可夫决策过程下的最优策略确定问题,利用深度强化学习方法在经验池中学习异构动态环境下DNN 推理计算划分和任务卸载最佳策略。实验结果表明,对于不同的DNN 推理任务和DNN 模型,DPTO 算法在不同环境下相比于已有算法推理时延平均降低了约28.83%。下一步将对边缘设备宕机和恶意攻击等异常情况进行研究,提出高效的容错解决方案,以保证云边协同DNN 推理的可靠性和安全性。
猜你喜欢
经济研究导刊(2022年9期)2022-04-19
通信电源技术(2020年8期)2020-07-21
中国计算机报(2020年15期)2020-05-13
电子制作(2019年23期)2019-02-23
名作欣赏(2017年25期)2017-11-06
绿色科技(2017年2期)2017-03-23
中国信息化(2016年9期)2016-12-26
CHIP新电脑(2016年9期)2016-09-21
电子制作(2016年19期)2016-08-24
现代防御技术(2016年1期)2016-06-01
