
基于Fisher Score 与最大信息系数混合模型的三电平逆变器故障特征选择方法
2023-01-08 16:48任晓红刘显策韩向栋
电子设计工程 2023年1期
杜 磊,任晓红,刘显策,韩向栋,俞 啸
(1.兖州煤业股份有限公司兴隆庄煤矿,山东济宁 273500;2.中国矿业大学物联网(感知矿山)研究中心,江苏 徐州 221008)
逆变器作为直流信号转换为交流信号的关键器件,被广泛应用于矿井提升机和皮带变频控制系统等电力控制装置中[1]。多电平逆变器具有电压输出中的谐波失真较低、波形更接近正弦波、有效避免发生电位漂移并且对负载的影响较小等优点[2-3]。在工业领域中,中性点钳位三电平逆变器经常被用到[4-5]。基于三电平输出的开关状态遵循单位电平跳变的原则,控制开关管的通断可降低功率损耗[6]。绝缘栅双极晶体管(Insulated Gate Bipolar Transistor,IGBT)是中性点钳位型三电平逆变器中常用的电源开关,可在高电压、高温和高频率下长时间导通和关断[7-8]。
但若长时间处于过压高温状态,逆变器IGBT 会出现故障,故障会影响到整个煤矿运行。因此,有效且及时的诊断IGBT 运行状态尤其重要。
由于逆变器设备本身电路结构复杂、运行环境的复杂性以及多变性,逆变器IGBT 故障信号具有非平稳和非线性特点,导致逆变器的故障特征难以准确提取,进而影响故障诊断与识别的有效性[9-10]。工程上经常通过多角度提取反映逆变器系统各种运行状态的多种类型特征信息,以提高故障诊断和故障识别的准确率。但在提取多类特征信息的同时可能会带来特征维数增多以及特征之间冗余问题[11]。为了挖掘原始故障特征数据集中的关键特征和潜在信息,采用适当的特征选择方法对逆变器功率管IGBT 多故障特征进行选择,这对故障诊断更加重要。
特征选择是以从原始特征集中剔除相关性弱的特征,进而筛选出一组最能表征有效信息的子特征集为目标[12-13]。根据特征子集的搜索策略,可以将特征选择方法划分为两大类[14],即装式方法(Wrappers)[15]和过滤式方法(Filters)[16]。这两类方法是单一的特征选择方法,遇到多故障特征选择时,影响故障分类准确率。随着智能算法在高维特征数据中的应用,混合特征选择方法已慢慢被应用到特征选择中[17]。这种混合特征选择方法不仅可以提高分类准确率还能够减少计算时间。
1 相关理论介绍
1.1 Fisher Score算法
Fisher Score 是对样本故障特征进行评价的一种标准。其主要思想是在选择故障特征子集时,选择使得异类数据点间距离大,而同类别的数据点之间距离小的故障特征子集。
假设训练样本xk∈Rm,k=1,2,3…,多类之间的类间散度计算公式如式(1)所示:

针对多故障类型的重叠性和分布不均匀问题,改进Fisher Score 算法,其计算公式如式(2)所示:
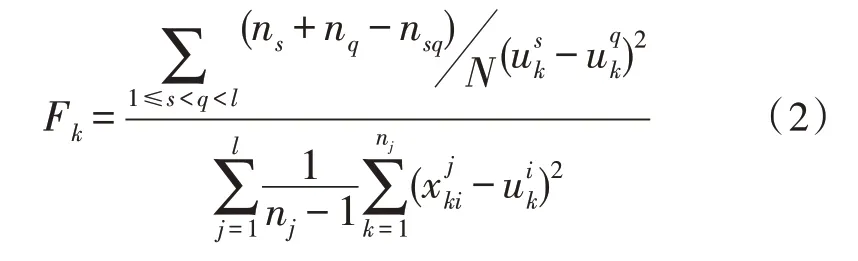
式中,N为除去重复特征值的样本总数,分母表示类内散度之和,nj为第j类的数据样本数。
1.2 最大信息系数
采用Fisher Score 算法只能确定逆变器不同故障特征的重要度,但是,多故障特征子集中的冗余度以及特征与特征彼此之间的相关性无法确定。最大信息系数是一种基于信息论的方法,它不仅可以挖掘不同特征之间的线性和非线性关系,还可以度量特征之间的非函数关系;采用最大信息系数对逆变器功率管IGBT 故障特征之间的相关性进行表征与计算。
假设两个随机变量X={xi,i=1,2,3,…,n}和Y={yi,i=1,2,3,…,n},n为样本数,互信息I(X∶Y):
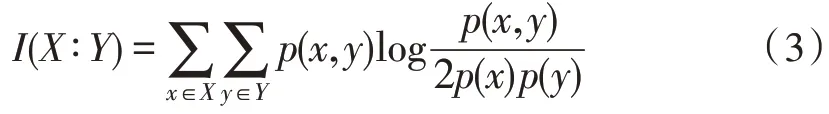
式中,p(x)是X边缘概率分布密度,p(y)是Y的边缘概率分布密度,p(x,y)是两个变量的联合概率密度。
定义在X×Y网格的最大互信息值为max(I(X∶Y)),则最大信息系数计算公式如式(4)所示:

式中,B是x×y网格划分上限值。
若n个样本的特征集F={f1,f2,…,fk},其中,k为特征数,对于任意两类特征fi和特征fj相关性为Mic(x,y),若Mic(x,y)值越大,则特征fi和特征fj之间的冗余性就越大。若Mic(x,y)为零,此时,特征fi和特征fj之间彼此相互独立。
在此基础上,定义冗余特征:对于特征集为F,特 征fi和特征fj的Fisher Score 值Fi>Fj,且Mic(x,y)>0.8,则特征fj是特征fi的冗余特征。
2 Fisher Score 与最大信息系数混合模型
为了能够更好地选择出最有效的敏感故障特征子集,建立了一种Fisher Score 与最大信息系数混合模型。该模型具体流程如图1 所示。

图1 Fisher Score与最大信息系数的混合模型流程
3 基于Fisher Score 与最大信息系数混合模型的特征选择方法框架
所提出的基于Fisher Score 与最大信息系数混合模型的三电平逆变器故障特征选择方法框架如图2所示,特征选择过程分为以下三个步骤。
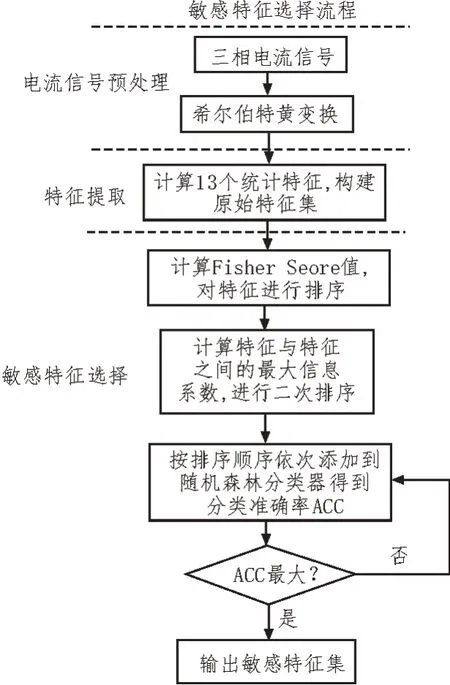
图2 基于Fisher Score与最大信息系数混合模型的特征选择方法框架图
步骤1:三相电流信号预处理,在希尔伯特黄变换(HHT)方法的基础上,采用噪声自适应完备总体平均经验模态分解CEEMDAN(Complete EEMD with Adaptive Noise)方法分别对三相电流信号样本数据集进行分解和重构,以去除电流信号中的噪声信号。
步骤2:特征提取,采用Hilbert 变换,对三电平逆变器三相电流进行希尔伯特边际谱和希尔伯特包络谱变换,得到其对应的三个边际谱和三个包络谱;对于每个希尔伯特边际谱,计算表1 中的前13 种统计特征,且计算三相电流Park 矢量变换后的模值和相角两种特征。则得到41 维(13×3+2)特征集;对于每个希尔伯特包络谱,计算表3 中前11 种统计参数,则得到33 维(11×3)特征集;对于每一个三相电流信号样本,得到原始特征集维数74 维(11×3+13×3+2)。
步骤3:敏感特征选择,对原始特征集进行Fisher Score 值计算,并根据值的大小按照降序进行排序,计算特征间的最大信息系数,进行二次排序调整,并采用随机森林分类算法对排序调整后的特征集进行分类,根据随机森林分类准确率筛选敏感故障特征子集。
4 实验验证与结果分析
4.1 实验设置
基于Matlab/Simulink 环境下,搭建三电平逆变器电路原理仿真模型,实验采用电感和电阻的不同组合来模拟负载变化,其负载组合参数设置如表1所示,负载组合设置了10 种电阻和电感组合类型,且这10 种组合代表10 种工况。在恒定的电压频率比下,采集电机在加速和匀速状态下的三相电流数据,采集时间是4 s,频率是10 kHz。通过仿真模型控制端模拟正常与故障共13 种状态,且采集13 种状态下的三相电流数据样本,每种状态下的电流信号划分378 个周期,每个周期为一个样本,10 种工况共有10×13×378 个样本,且构建仿真原始数据集Case1(10×13×378 个样本)。
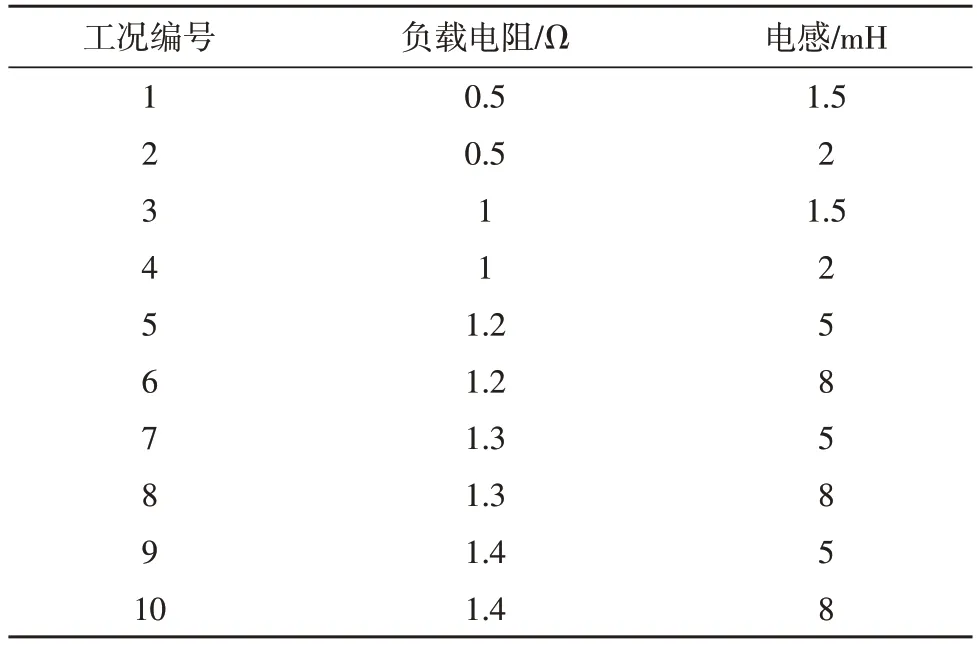
表1 仿真数据采集参数设置
利用直流电源、NPC 三电平逆变器、示波器、电阻电感等器材搭建了NPC 三电平逆变器电流信号采集实验台。采用电阻与电感组合表示负载,实验设置4 种负载类型,即4 种工况,如表2 所示。在电机为加速和匀速状态下,采集三相电流信号,采集频率仍设置为10 kHz,采集时长20 s,重复采集了5 次。通过实验台控制端采集正常状态和12 种故障状态下的三相电流数据,每一种状态下的电流数据划分378 个周期,将每个周期作为一个样本,4 种工况下,共有19 656(13×378×4)个样本,重复采集了数据5次,得到总样本数是98 280(5×4×13×378)个,即将总样本构建原始数据集Case2(5×4×13×378 个样本),即Case2 表示实验原始数据集。
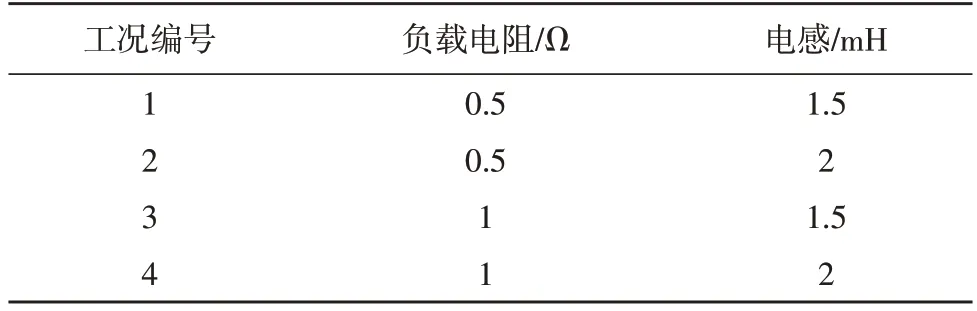
表2 实验数据采集参数设置
4.2 实验结果分析
采用CEEMDAN 方法分别对仿真和实验台采集的三相电流信号样本集进行分解和重构,以去除噪声信号。逆变器三相电流经过CEEMDAN 分解得到10 个本征模态函数(IMF)分量。对于CEEMDAN 变换之后的IMF 分量中一般含有虚假分量,而虚假分量不仅不能反映信号特征信息,而且会干扰其他的IMF 分量,采用相关分析方法剔除虚假分量。根据IMF 分量与原始信号特征信息间的相关系数,判断虚假IMF 分量,若相关系数小于0.2,则判断为虚假IMF 分量。
CEEMDAN 分解出的10 个IMF 分量与特征相关系数对应关系如图3所示。根据相关系数计算,后6阶IMF 分量的相关系数小于0.2,属于虚假IMF 分量,不能表征原始信号的信息特征,该实验选择前4 阶IMF分量,并将其重构为CEEMDAN 分解之前信号。
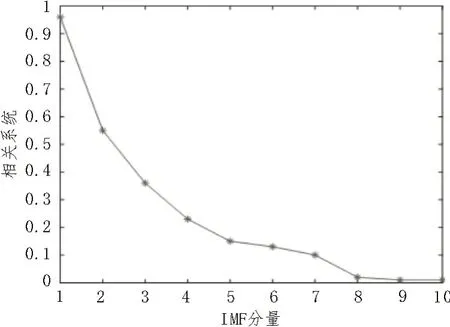
图3 IMF分量与信号特征相关系数对应关系
采用Hilbert 变换算法对前4 阶IMF 分量重构之后的信号进行变换,得到三相电流对应的三个Hilbert 边际谱和三个Hilbert 包络谱;对于每个希尔伯特边际谱,计算与表3 标题不符统计特征,且计算三相电流Park 矢量变换后的模值和相角两种特征。则得到41维(13×3+2)特征集;对于每个希尔伯特包络谱,计算表3 中前11 种统计参数,则得到33 维(11×3)特征集;综上所述,对于每一个三相电流信号样本,得到原始特征集的维数为74 维(11×3+13×3+2)。

表3 15种统计特征
首先,采用Fisher Score 计算方法评估特征指标重要度,并进行排序;再采用最大信息系数评价特征与特征之间相关度,并将相关度低的特征调整到最后;借助随机森林算法的强大分类能力,采用随机森林分类器筛选敏感特征子集。
为了验证所提出的特征选择方法具有更好的有效性和可靠性,开展了对比实验,选择仿真数据样本数24 570×74 个样本(Case3),实验台数据样本数为63 960×74 个样本(Case4)。故障类别数为13 种,特征数为74,选择mRMR 算法和reliefF 算法与所提出的特征选择方法(Fisher-MIC)进行对比实验,采用随机森林算法进行故障分类,根据故障分类准确率的高低判断特征选择算法的效果。不同特征选择方法的特征选择效果如图4 和图5 所示。

图4 仿真数据集不同特征选择方法的特征选择效果图
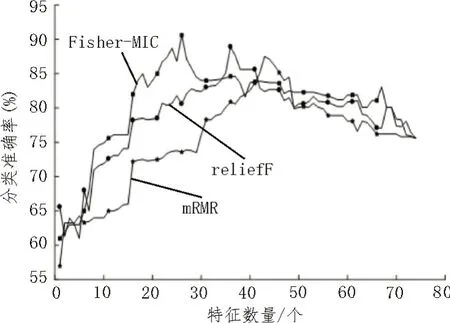
图5 实验数据集不同特征选择方法的特征选择效果图
根据图4 和图5 可知,三种特征选择方法在三电平逆变器仿真数据集和实验数据集上的分类准确率整体都呈现先上升后下降的趋势。三种方法筛选出的特征集,输入分类器中,分类准确率不同。其结果如表4 和表5 所示。
根据表4 和表5 可知,对比Fisher-MIC、reliefF 和mRMR 三种特征选择方法,对于Fisher-MIC 特征选择方法,仿真数据和实验数据测试分类准确率都比其他两种特征选择方法下的分类准确率高。仿真实验和实验台实验结果表明,Fisher-MIC 特征选择方法相比其他两种特征选择方法有较好的效果,所选择出的敏感特征子集能够更好地反映逆变器功率管IGBT 相应故障状态的特征信号。

表4 13种统计特征仿真数据集测试结果

表5 13种统计特征实验数据集测试结果
5 结论
为了提高三电平逆变器故障识别准确率,提出了一种基于Fisher Score 与最大信息系数的混合模型的三电平逆变器特征选择方法,该方法采用希尔伯特黄变换对三相电流信号进行时频域变化,得到包络谱和边际谱,并将经过计算的统计特征集构建原始特征集;采用Fisher Score 方法对原始特征集进行相关故障特征重要度排序;且采用最大信息系数对特征之间的相关性进行评价,进而对特征排序结果进行调整;以故障分类准确率为评判依据,基于随机森林算法对Fisher Score 与最大信息系数混合模型进行修正,进而实现敏感故障特征筛选。进行了仿真实验和实验台实验。实验结果表明,所提出的方法在筛选有效的故障特征上效果明显,与传统的reliefF 和mRMR 特征选择方法相比,所提出的特征选择方法有利于逆变器故障诊断识别分类,且故障识别准确率分别提高了2.1%和1.3%。
猜你喜欢
电工技术学报(2022年20期)2022-10-29
重庆理工大学学报(自然科学)(2022年5期)2022-06-18
微电机(2022年1期)2022-03-21
科学家(2021年24期)2021-04-25
通信电源技术(2018年5期)2018-08-23
自动化学报(2017年5期)2017-05-14
电子制作(2017年10期)2017-04-18
电子制作(2017年23期)2017-02-02
智能系统学报(2015年4期)2015-12-27
客车技术与研究(2015年3期)2015-08-24
