
改进U-net++的青光眼视盘视杯分割方法
2023-01-08 16:48刘然刘建霞王海翼
电子设计工程 2023年1期
刘然,刘建霞,王海翼
(太原理工大学信息与计算机学院,山西晋中 030600)
青光眼是造成不可逆致盲的最主要因素[1]。据有关数据统计,截止到2020 年,全球青光眼患病人数已经超过了8 000 万人。为了预防青光眼疾病的发生及加重,眼部疾病的早期诊断工作有着非常重要的意义。
深度学习技术在近年来被证明可以产生高区分度的精度,并在许多计算机视觉任务上取得了很好的效果。因此将深度学习运用到青光眼视盘(Optic Disc,OD)和视杯(Optic Cup,OC)分割方面具有很高的研究价值。在该文中,将青光眼的视盘和视杯分割作为一个多标签任务来解决,对原始U-net++[2]进行改进优化,设计了一种融合可变形卷积和注意力机制,并使用极坐标输入的PDAU-net++网络结构,从而达到更好的分割性能。
1 方法论
该文所提的PDAU-net++算法在数据预处理阶段使用了极坐标变换,较好地平衡了直角坐标系中视杯比例不平衡的问题;将网络结构关键层的常规卷积替换为可变形卷积并引入注意力机制SE 模块,解决了常规卷积不能很好地处理物体形变的问题并使得模型更加专注于待分割的关键区域;运用了一种基于Dice 系数的多标签损失函数,较好地处理了眼底图像按像素分割时多标签和数据不平衡的问题。该方法的结构示意图如图1 所示。

图1 PDAU-net++网络结构示意图
1.1 U-net++
在传统的U-net中,Skip connection(跳跃连接)是一种通过进行特征拼接来提高神经网络性能的技术,在一定程度上,使用该技术可以将粗细粒度的特征进行融合,但是之后又会产生一种关于语义鸿沟的问题。为了解决Skip connection 引起的语义鸿沟,文献[2]提出了如图2 所示的U-net++架构,该架构是一种基于嵌套密集跳跃连接的分割体系结构,它将多个不同层次的U 型网络进行了集合,从而使得整个架构可以在不同的层次分别提取各自层次的特征,然后再将这些不同层次的特征结合在一起。在图2 中,最外侧一层是原始的U-net网络,中间圆圈部分均表示在Skip connection上的密集卷积块,每个圆圈都代表两个连续的卷积操作,上方表示深监督(deep supervision)。用xi,j来表示单个节点Xi,j的输出,i为网络中所在的层数,j为新添加的卷积块,如式(1)所示:

图2 U-net++示意图

其中,函数H()· 表示带有激活函数的卷积操作,U()· 表示上采样操作。[]表示级联。
1.2 可变形卷积
由于标准卷积中固定卷积核的存在,使得其并不能很好地适应物体的形变。为了解决或者减轻标准卷积中存在的局限性,文献[3]提出了一种新的方法,将一个偏移的变量分别添加在标准卷积核中各个采样点的位置,通过添加变量,卷积核就不会再局限于标准卷积中的规则格点采样,这样添加偏移变量后的卷积操作被称为可变形卷积。如图3 所示,展示了3×3 大小的卷积核的两种不同采样方式,(a)为标准卷积核的规则采样,(b)、(c)、(d)均为可变形卷积核的采样,添加了一个位移变量(箭头)。

图3 常规卷积核和可变形卷积核
一般的卷积过程可以表示为式(2):

其中,pi为输入特征图中的感受野,pi={p1,p2,…,pn},w(pi) 表示不同卷积核的不同权重。在可变形卷积中,偏置变量Δpi会通过一个新的常规卷积操作来生成,并被添加到式(2)中得到式(3):

1.3 注意力机制
Attention(注意力机制)是20 世纪90 年代被部分科学家在研究视觉时发现的一种信号的处理机制,近年来被引入到人工智能领域内并取得了成功。在卷积神经网络中,卷积层是其核心所在,由于在不同空间或通道内所含有的各类信息重要程度也不相同,所以常规的卷积操作将空间和通道的各类信息进行无差别地融合就会成为新的问题。2017 年ImageNet的分类比赛冠军SE(Squeeze and Excitation)模块[4]的效果得到了广泛的认可,如图4 所示,该模块主要由Squeeze和Excitation两个操作构成。用X来表示输入特征图,用RH×W×C来表示维度,H、W和C分别为高度、宽度和通道数目。Squeeze操作即全局平均池化,经过Squeeze 操作后输入特征图会被压缩为1×1×C的向量[5]。而Excitation 操作由两个全连接层(Full Connection)构成,其中r是一个可以用来缩放的参数,可以控制该模块计算量的大小,不同大小的r会对网络性能造成不同的影响。最后会生成一个R1×1×C维度的向量,再通过Scale操作,得到输出结果Y。

图4 SE模块
1.4 多标签损失函数
该文采用了一种多标签损失函数来进行OD、OC 的联合分割[6],并将OD 和OC 分割作为一个多标签问题。由于在OD 和OC 的分割中,OD 区域覆盖了OC 区域,即标记为OC 的像素也有着OD 的标签。此外,由于青光眼患者OC 的不断扩大,导致OD 和OC之间的像素不断减少,造成了非常失衡的不同区域类。因此为了解决上述问题,将OD 和OC 看作两个相互独立的二分类器,并使用了一种新的多标签损失函数,如式(4)所示:

其中,N表示图像中像素的个数,p(k,i)∈[0,1]和g(k,i)∈[0,1]分别表示k类的预测概率和二元标注真实标签。K表示类别数,∑kωk=1 表示类别权重值,对于OD 和OC 分割任务,K设置为2。ωk是控制OD和OC 的权衡权重,设为0.5。
2 数据预处理
2.1 数据集
Drishti-GS1 数据集包含了101 幅眼底图像,所有图像都在马杜雷的阿拉文德眼科医院收集,由四名具有不同临床经验的眼科专家进行标记。选定的患者年龄在40~80 岁之间,男性和女性人数大致相等。所有图像都以OD 为中心,其视野(FOV)为30度,尺寸为2 896 ×1 944 像素,PNG 未压缩图像格式。图5 中(a)为原始眼底图像,(b)、(c)为专家手工分出的视盘和视杯的标注(Groundtruth),为了防止血管、病变区域等对视盘视杯分割结果的影响,使用普通的U-net 网络和相应的OD 标签进行训练并对数据集进行OD 预测[7],然后将预测的OD 映射回原始图像,并根据预测OD 的中心从整张图中裁剪出大小为512×512 像素的区域,如图5(d),同理,将视杯和视盘标注进行融合后也裁剪为512×512 像素的区域,如图5(e)所示。

图5 数据集图像
2.2 限制对比度自适应直方图均衡化(CLAHE)
在初始的眼底图像中,OD 和OC 的边界相对而言并不是很明显,对比度比较低,使用CLAHE来预处理眼底图像可以改善眼底的对比度和光照情况,如图6 所示,并以此来提高网络分割的性能。

图6 CLAHE前后图像
2.3 数据扩充
由于目前公开的青光眼数据集较少,为了获取更好的结果,训练模型之前将数据集中的图像通过多角度的旋转及水平、垂直和镜像翻转扩充到原来的12 倍。
2.4 极坐标变换
在该文方法中,引入了极坐标变换来改善视盘和视杯的分割性能。像素级别的极坐标变换将原始眼底图像从直角坐标转换到极坐标。图7(a)中,点O为视盘中心点,p(u,v)为任一点,θ和r分别表示该点的方向角和到圆心的距离,由此便可以得到该点在极坐标的对应点,即图7(c)中p′(θ,r)。
极坐标和直角坐标之间的转换公式如式(5)所示:

极坐标变换主要具有以下特性:
1)空间约束:极坐标变换可以将原始图像中OC与OD 的几何约束转换为如图7(d)所示的有序的空间层次结构。
2)平衡视杯比例:在原始眼底图像中,视盘所占整个图像的区域较小,视杯所占比例更加失衡。在经过极坐标变换之后,如图7(d)所示,扩大了视杯的区域比例,比原始图像更加平衡。
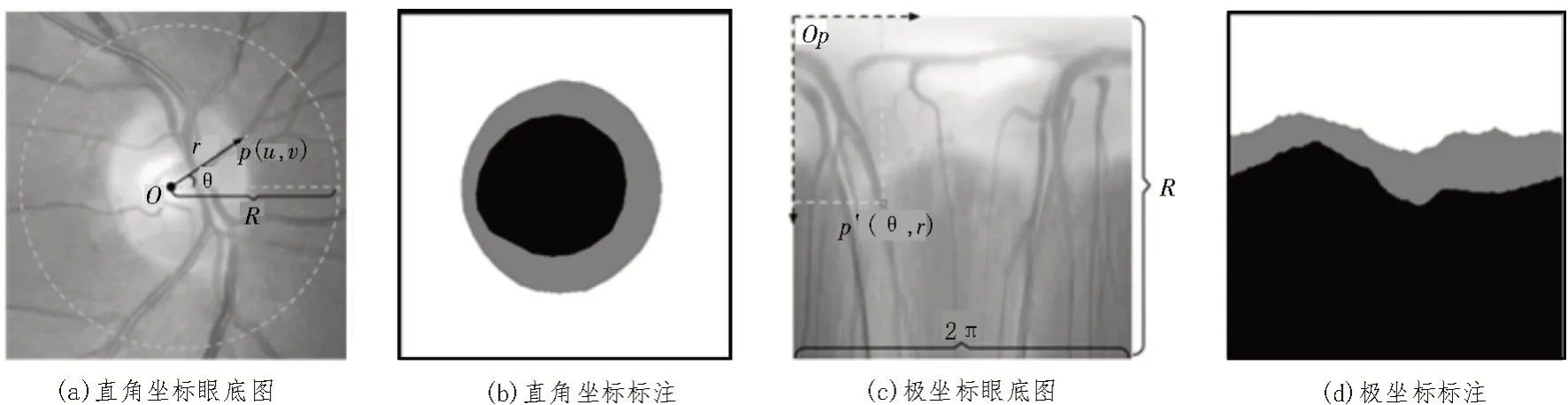
图7 不同坐标系下的图像
3 实验过程及结果
3.1 实验环境
实验硬件配置:Intel(R) Xeon(R) Gold 5120 CPU@2.20 GHz 处理器,显卡为NVIDATeslaP4,内存容量为128G[8]。
实验软件配置:python 编程语言,pycharm 编译器,Pytorch 框架,batch size 设置为32,Adam 优化器,learning rate 为0.001,SE 模块的r设置为8。
3.2 评价指标
该文将青光眼视杯视盘分割结果与数据集中专家手工标注作比较,可以看出算法的优越性。采用Dice 系数d(A,B)来作为算法的评价指标,其取值范围是0~1,越接近1,算法效果越好,计算公式如式(6)所示:

其中,A是得到的分割结果,B表示相对应的标注。
此外,该文还使用oe来表示真实杯盘比(CDR)值与预测杯盘比值之间的误差,误差越小,表示算法分割的结果越接近专家手工分割结果。oe和CDR的计算如式(7)所示,其中,CDRp表示预测的CDR,CDRg表示真实CDR,SDcup表示视杯面积,SDdisc表示视盘面积。

3.3 实验结果及分析
表1 直观地展示了七种不同模型在Drishti-GS1数据集视杯视盘分割任务上的性能指标。为了更好地对比该文所添加模块的效果,增加了多组对比模型,其中DU-net++表示使用可变形卷积代替关键层的传统卷积;DAU-net++表示使用可变形卷积代替关键层的传统卷积并添加注意力模块。通过表1 中的各个实验的对比分析,证明所添加模块的有效性,其中,Dicecup表示OC 的Dice 系数;Dicedisc表示OD的Dice 系数;oe表示真实CDR值与预测得到的CDR之间的误差。对比U-net[9]、DRIU[10]、M-net[11]和Unet++四种基础网络模型可以发现,U-net++模型无论是在视杯视盘的Dice 系数得分还是在oe误差上都较前三种模型分割性能更好。对比DU-net++和U-net++可以验证引入可变卷积块代替关键层的传统卷积块后,视杯和视盘的Dice 系数分别提升了0.009 4和0.011 9,oe误差降低了0.001 8。对比DAUnet++和DU-net++可以验证引入注意力机制后,视杯和视盘的Dice 系数分别提升了0.013 1 和0.001 3,oe误差降低了0.003 08。对比DAU-net++和PDAUnet++可以验证使用极坐标输入后,视杯和视盘的Dice 系数分别提升了0.023 8 和0.012 4,oe误差减少了0.001 68。PDAU-net++较原始框架U-net++视杯和视盘的Dice 系数分别提升了0.046 3 和0.025 6,oe误差降低了0.006 56。

表1 算法改进前后与经典分割网络的性能指标
如图8 所示,从多种模型分割结果中发现该文方法的分割效果比其余对比方法更精准。由于眼底图像中血管和部分病变区域的影响,U-net、DRIU 和M-net 在分割时容易受到干扰,不能准确地分割出视杯和视盘的边界,U-net++分割的效果较为理想。相对来说,该文提出的PDAU-net++网络可以更好地分割出视杯和视盘区域,分割结果也更加接近于专家的实际手工标注结果。

图8 不同网络模型的分割结果
为了进一步证明该文算法在青光眼视盘视杯分割领域的性能,将该文算法与近期文献结果进行了比较,结果如表2 所示。基于Drishti-GS1 数据集进行对比,该文方法的视杯Dice 系数达到了0.925 3,视盘Dice 系数达到了0.985 0,oe误差为0.061 58,均优于上述文献中的算法。

表2 Drishti-GS1数据集不同算法的性能指标
综上所述,该文改进的PDAU-net++网络,可以获得比较好的分割性能指标,具有较高的稳定性和抗干扰能力,不仅保证了一定的高准确率,还降低了杯盘比的误差,具有一定的先进性。
4 结论
该文提出一种PDAU-net++网络分割模型。以U-net++网络架构为基础,先将关键层的传统卷积替换为可变形卷积,又引入了SE 模块,增大模型对感兴趣区域的分割,并引入了一种多标签的损失函数来解决分类中的类不平衡问题,此外还引入了极坐标变换来平衡视杯和视盘所占图片的比例,进而提升分割性能。最后通过一系列的对比实验证明了该文方法的有效性。
猜你喜欢
中老年保健(2022年3期)2022-08-24
眼科学报(2021年6期)2021-07-18
山东医药(2021年14期)2021-05-27
临床眼科杂志(2021年2期)2021-05-26
河北理科教学研究(2020年1期)2020-07-24
中医眼耳鼻喉杂志(2019年3期)2019-04-13
中医眼耳鼻喉杂志(2018年1期)2018-04-10
中学数学研究(广东)(2018年23期)2018-03-05
中国中医药现代远程教育(2014年18期)2014-03-01
中国眼耳鼻喉科杂志(2012年2期)2012-11-11
