
基于自适应特征融合与转换的小样本图像分类
2022-12-22 11:47刘小明刘济宗郭清宇
计算机工程与应用 2022年24期
许 栋,杨 关,刘小明,刘 阳,刘济宗,陈 静,郭清宇
1.中原工学院 计算机学院,郑州 450007
2.河南省网络舆情监测与智能分析重点实验室,郑州 450007
3.中原工学院 前沿信息技术研究院 网络舆情研究中心,郑州 450007
4.西安电子科技大学 通信工程学院,西安 710071
深度学习在图像处理[1]和自然语言处理[2]等领域有着广泛的应用,但是传统深度神经网络的学习大多依赖大量的数据。由于数据的采集等过程需要耗费大量的资源,并且人工标注存在着一定失误,所以建立一个大型数据集代价高昂,这在一定程度上制约着深度学习的发展。因此,适用于少量标注数据训练的小样本学习[3]甚至零样本学习[4]也就应运而生。小样本学习是元学习[5]在监督学习领域的应用,通过一定的先验知识,利用少量具有标注信息的样本进行特定的任务应用。
现有的小样本学习方法有四种基本策略:基于数据、基于模型、基于外部记忆、基于参数[6]。基于数据的方法通过使用先验知识来扩充小样本训练集,在增强的样本集上再利用传统的机器学习算法建模,从而使经验风险最小化[7]。基于模型的方法则使用先验知识缩小假设空间H,在H空间中,小样本数据集更容易得到稳定可靠的经验风险最小化效果。基于外部知识则是向模型中添加额外的记忆知识来保存信息,助力模型学习。基于参数的方法同样使用了先验知识,目的是搜寻假设空间中使得模型效果最好的超参数θ,先验知识用于提供合理的参数初始化或者用于指导更改参数搜索策略,从而训练出较好泛化性能的模型。除了MatchingNet[8]、Protonet[9]、RelationNet[10]等经典模型,越来越多的小样本模型开始涌现。
Huang等人[11]提出了利用泊松学习算法(Poisson transfer network,PTN)来改进标签传递,PTN主要设计用于半监督的少量样本分类模型,并进一步增强了嵌入对比自我监督学习的特征,然后通过使用基于图的方法来改进推理过程。Ye等人[12]提出了直接调整特征的方法,使用set-to-set函数将一组任务不确定的特征转化为特定的特征,并且使用了transformer这种较为复杂的结构来提升效果。Yoon等人[13]提出了XtarNet来学习任务场景特定的特征,其中,模型在基础数据集中进行训练,来适应给定的新类数据集,从而应用于新类的分类。但是包括这些方法在内的大部分方法的改进效果几乎掩盖了特征提取所带来的增益。DenseNet[14]等经典网络模型表明了特征的有效提取对于模型效果的重要性。更重要的是,由于小样本学习数据采样的特殊性,每次只有少量数据输入网络进行训练,这可能造成模型无法充分提取与利用特征。Chen等人[15]指出,神经网络特征提取能力的大小影响着小样本模型的表现,对于领域相似的分布特征,这种影响更大。即特征提取成为影响模型性能的关键因素。目前小样本学习模型采用诸如ResNet10、ResNet12等浅层网络,在有限层网络和小样本数据训练模式下,如何充分利用特征,是改进模型、提高模型表现的一个重要方向。
针对这些问题,提出了基于多分支自适应加权特征提取模块的神经网络。该神经网络主要包含以下两个阶段:
(1)特征提取阶段,通过引入多分支特征提取,使得模型在无需构建较深网络的情况下,能够提取到丰富的特征,同时缓解了较深网络中经常出现的梯度爆炸和梯度消失;通过给予不同特征提取分支相应的自适应权重,使得在特征融合阶段,分支能够自适应地抑制或者放大不同分支的特征信号,从而能够较好地融合特征。
(2)特征相似度度量阶段,通过引入自适应的中心二范数归一化(adaptive central L2 normalization,ACL2N)特征转换层,使得模型对于不同域的特征能够较好地适应,同时也起到了正则效果抑制过拟合,提高了模型在相似数据域和交叉数据域的准确率。
1 相关工作
1.1 数据增强
数据增强[16]是深度学习中一种最直接的提高模型性能的方法,通过对数据集进行各种图像预处理,进而扩充现有数据集。该方法利用先验知识扩充训练集来增加样本数量,丰富了监督信息,从增强的样本数据中就可获得可靠的特征空间[17]。对于小样本学习来说,恰当地对数据集进行相应的处理会使得模型更合理地利用数据,进而提高模型的泛化能力。以实例可信度推断(instance credibility inference)[18]为代表的数据增强方法就是引入了一种判断机制来增加训练样本。利用带有置信度预测标签的类别未标记数据来扩充训练集,从而在一定程度上增强了模型的泛化能力,提高了模型的分类精度。但是通常情况下,数据增强只能生成与已知样本相似分布的增广数据,所以一般作为辅助手段在数据预处理阶段使用。
1.2 嵌入学习
将高维特征嵌入到低维空间进行运算是嵌入学习[19]的一大特点。将样本特征xi∈X⊆Rd嵌入到低维以便于使相似的样本在低维空间更加容易分类。根据支持集(support set)和查询集(query set)[8]中特征提取器的同异,现有的嵌入学习模型主要分为两类。一类是两者的特征提取器相同,标记为fs;另一类两者的特征提取器则不同,标记为fd1、fd2。前者由于具有相同的特征提取器,所以提取器可以公用,减少了模型的参数,加快了推理时间;后者由于特征提取器不同,提取的特征更具有多样性,增强了模型的鲁棒性,在一定程度上对精度有着更好地提升。原型网络[9]是典型的相同特征提取器fs方法,支持集和查询集都使用卷积神经网络(con‐volutional neural networks,CNN)作为特征提取器。此外,还使用了欧氏距离作为度量方法来判断相似性。与原型网络不同,匹配网络[8]的支持集特征提取器使用卷积神经网络和双向长短期记忆网络(bi-long short-term memory,Bi-LSTM),而查询集则使用卷积神经网络和长短期记忆网络(long short-term memory,LSTM)作为特征提取器,并且使用余弦距离作为相似性度量方法。
1.3 领域适应
小样本学习的定义和训练模式意味着不可避免地出现跨域(cross domain)[20]问题:在基类上进行训练,在新类上进行测试,两者没有交集。域适应旨在减少源域与目标域之间的领域漂移问题。所以小样本学习在一定程度上需要借助域适应的方法来提高模型的效果。自从Yaroslav等人提出了域对抗神经网络[21],越来越多的方法基于此在特征级或者像素级层面上来缩小源域和目标域之间的分布差异。然而这些方法都只是在一系列先验类别学到相应特征参数,对于小样本中新类的分类效果只能起到一定的作用。赵小强等人[22]提出基于特征和类别对齐的领域适应算法,通过使同域内的样本类密度最大和联合判别网络来降低类的错分率、实现类与域的对齐。
2 模型方法
小样本图像分类的流程可以归纳为数据预处理与载入、特征提取、相似度度量处理三个步骤。本章首先介绍了小样本相关概念,其次探究了网络层数对小样本模型的影响,讨论了小样本模型网络层数较浅的原因,接着引出本文在特征提取阶段和相似度度量阶段所改进的方法。
2.1 问题定义
根据阶段的不同,将小样本模型需要采用的数据集分为三类。在训练阶段,将训练集划分为Base数据集和Val数据集。先验训练时,使用Base数据集,记为其中xi∈RD,yi∈Yb分别是第i个输入图片和该图片所属的类别标签。Base数据集作为先验知识来训练模型,包含许多标记的图像。验证时,使用验证集Val,标记为其中yi∈Yv。测试阶段,使用测试集Novel,标记为,其中yi∈Yn。Novel数据集中包含着少量被标记的图片。三个数据集互不相交,即Db∩Dv∩Dn=∅。
在小样本学习中,通常使用被称为Episode的模式[8]来训练和测试模型,该模式又称为K-way N-shot模式,其中,K-way表示有K个类,N-shot表示每类有N个样本。在每个Episode阶段,每次从Db采样两个子集来进行训练 ,一 个 约 定 为 支 持 集Support Set:,一个约定为查询集Que‐M的 含 义 同N。Dv和Dn的采样方式也是如此。在这种模式下,基于嵌入学习的小样本图像分类模型的目的就是在训练阶段,从Db中采样出S和Q,S用于模型训练,Q用于预测标签;预测阶段,从Db中采样出S和Q,直接匹配两者的相似度从而对Q进行分类。
2.2 小样本的模型层数
提升网络模型性能的方法很多,如采用更大的数据集、更好的硬件等[23]。但一般而言,最直接的方法就是增加网络的深度和宽度。采用深层网络会提升模型的特征提取能力,但是需要学习大量参数,由于小样本学习数据集中的样本少的特点,不可避免地会出现参数学习不充分,从而忽视重要特征甚至出现过拟合等问题。而采用浅层网络需要学习的参数会变少,相对地,提取主要特征的能力就会变弱。
为了研究层数对于小样本模型的影响,这里选取了数据集中的图片进行可视化展示,如图1。该图为单目标图片,图中展示为一只狗。由于ResNet10只有四组Block的缘故,只展示这四组Block的网络可视化,剩下的ResNet18、ResNet34也抽取四组Block作为对比。可以看到,ResNet10首先关注到的是狗和背景的零散点状区域,接着由于特征的提取逐渐关注到不同的部位,最后一层则关注到图中狗的大部分躯干。ResNet18因为有着较深的层数,最终的模型开始阶段便可聚焦边缘部位,但是也关注了一些背景特征,随着模块的加深,高层语义也逐渐丰富,对于部位的定位也逐渐准确,可以关注到狗的肢体和部分面部,能够较好地滤掉无关区域及背景。ResNet34经过训练,一开始便可捕捉到相应的面部信息,选取了Block9、Block13可以发现关于面部特征的标记越来越大,这和网络层数的增多是密不可分的,最后可以关注到几乎整个狗的面部和部分四肢。从这个过程可以看出,从ResNet10到ResNet34,随着网络的加深,模型的关注点可以从四肢躯干逐渐到面部,对于语义的处理也逐渐汇聚到辨识度高的部位,但是网络的加深所带来的参数过多的效应也开始显现:少量样本的情况下,过于关注高级语义导致对于物体细节疏忽并且存在着过拟合,在进行后续分类时会影响模型判断,导致效果的提升不明显。
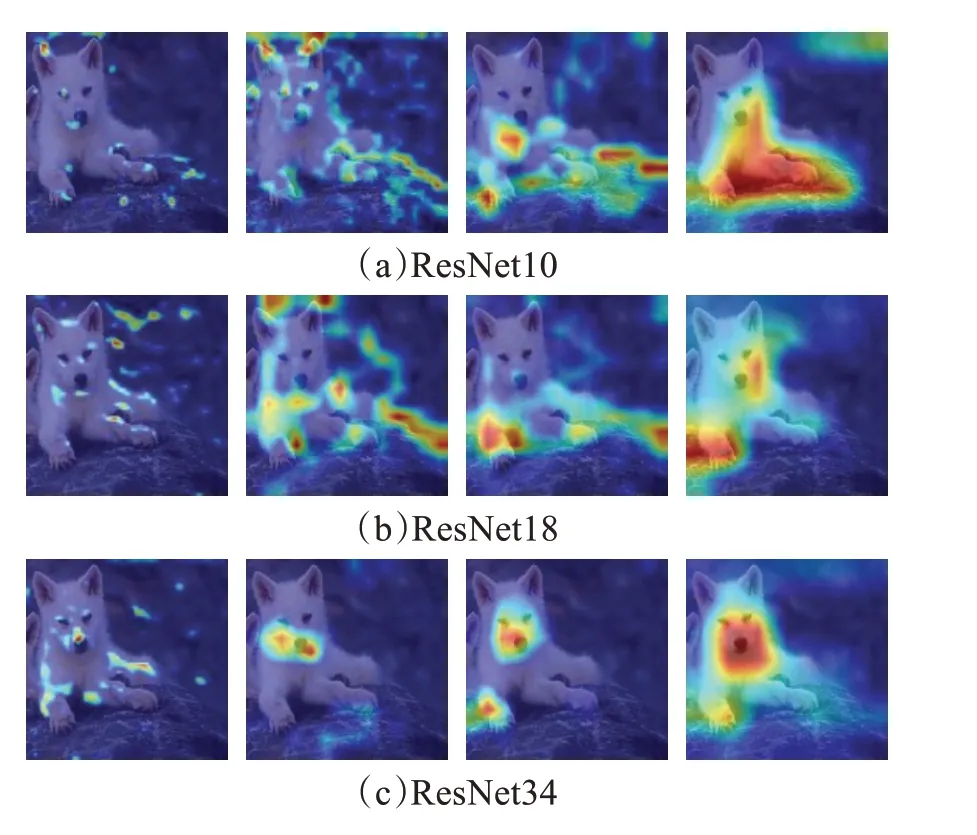
图1 不同层网络的CAMFig.1 CAM of different layer networks
另外,如表1所示,从模型成本角度来看,在参数总量和复杂度都非常大的情况下,ResNet34所得到的精度比ResNet10和ResNet18的高出不是很多:ResNet34的参数量和复杂度远远高于ResNet10(分别为5倍与4倍),精度仅仅提升了3%;并且也比ResNet18的参数量和复杂度大一倍,精度仅仅提升不到0.7%。即随着网络层数的提升,模型精度的提升增益与庞大参数量和复杂度的增加不成比例,这意味着,传统深度学习模型有效的、比较高的层数,在小样本的情况下,提升效果有限,并且提升所需的代价,是模型参数量和模型复杂度的激增。如何利用较少的层数在小样本数据上取得较好的效果,是探究提升模型表现的一个重要方向。
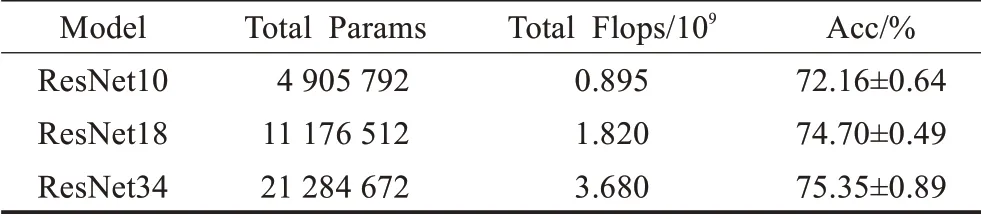
表1 不同层数的网络信息Table 1 Network information of different layers
2.3 特征提取
现有小样本学习模型大多采取了诸如ResNet10和ResNet12等浅层残差网络折中地进行特征提取工作,故网络深度在一定程度上受到限制。
受InceptionNet[23]的启发,在ResNet10的基础上,提出了自适应权重的多分支特征提取网络。首先,是残差网络标志性的残差分支Identity。其次,分别用两组1×1卷积将特征的通道进行减半压缩,一是减少参数量防止过拟合。二是方便后续进行卷积特征拼接进行加性融合。接着,在第一组1×1卷积后加入一组3×3卷积;另一组1×1卷积后加入两组3×3卷积来替代一组5×5卷积,分别用这两组感受野不同的卷积组合对同一组输入进行特征提取再按通道进行拼接。这一支路称为双卷积分支DConv,并标记为Fdconv,计算公式为:
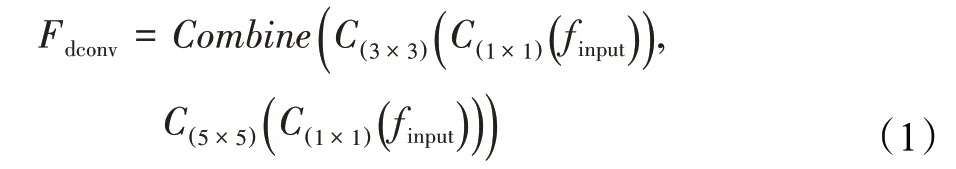
其中,Combine为按通道拼接函数,C()1×1为1×1卷积,C(3×3)为3×3卷积,C(5×5)为5×5卷积,finput为输入特征。由于卷积提取的丰富特征,在进行拼接之后,后面接入一个Squeeze-and-Excitation(SE)注意力模块[24]。
另外两组分别为平均池化分支和最大池化分支,平均池化用来提取全局背景特征,相对应地,最大池化提取局部特征。前者标记为Fmax,后者标记为Favg,池化分支在提取特征的时候一个额外的优势在于不需要学习参数。两者的特征提取计算公式为:

其中,max()为区域最大值函数,avg()为区域平均值函数,finput为输入特征。
一般情况下,不同的卷积核提取的特征存在着差异,大的感受野意味着同一个点所含的语义信息丰富,小的感受野意味着物体的细节保存更好,在进行四组支路的特征提取后。一般地,Identity支路最大程度上保留着原始特征,双卷积支路蕴含着更多的语义信息,最大池化支路注重输入的局部信息,平均池化支路则关注输入的全局信息。对不同支路特征提取器的特征进行合理地融合,是充分利用特征、提高模型表现的一个重要手段。在提出的特征提取模型中,为了更好地利用特征,通过引入自适应的特征权重,来使模型根据数据的特征分布来自行决定在特定的层以特定的权重来融合特征。特征融合公式如下:

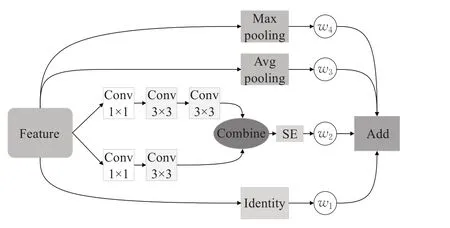
图2 自适应特征处理模块Fig.2 Adaptive feature processing module
2.4 相似性度量
小样本学习中一个很主要的方法就是利用一个相似度度量方法来比较支持集与查询集中图片的相似度,经过特征提取模块提取后的特征再输入进度量函数中就能不同程度上比较出两者的异同,从而达到分类的目的。目前主要的方法有很多,Oriol等人[8]使用Cosine函数作为相似度度量方法;Zhang等人[25]使用Earth Mover Distance作为相似度度量方法。
对特征提取模块提取的特征进行特征变换,然后再输入度量函数会大大提高分类精度。Wang等人[26]通过将特征进行中心化和L2归一化后,模型效果有所提升。受此工作启发,引进特征变换。小样本学习每次采取KWay N-Shot的模式采样训练样本,这就意味着特征分布在不停地变换。在特征提取模块由于自适应权值的变化,也使得特征信号随之变化。在这种情况下,定参数的特征变换层对于不同的特征分布只能有单一的变换,无法较好地解决上述问题。为此,引入两个参数,使得特征变换层对不同情况下的特征进行相应的适应,从而对新类别有很好地鲁棒性。将这种自适应的特征变换模块标记为Fft。具体计算为:

其中,xff为提取后的特征为L2归一化,xn为特征的第n维,FCL2N为特征变换函数CL2N,β和γ为控制线性变换的权重参数。在特征经过一系列变换后将其输入欧式度量函数中进行相似度比较。首先计算出支持集的原型pk:
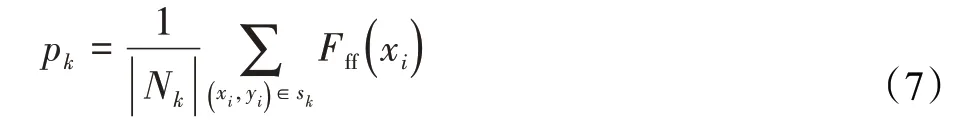
其中,Fff()为特征提取函数,Nk为第k次任务采样的N种类集合,sk为支持集。再将pk与查询集进行相似度dk比较:
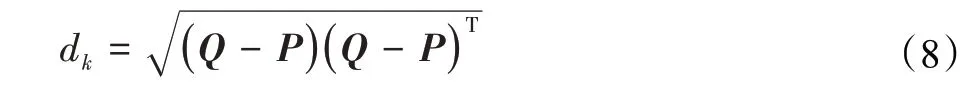
其中,Q为Query向量,P为Support原型pk,T为转置操作。最后利用SoftMax函数进行分类,得出概率p*k:

2.5 训练过程
利用数据增强使得数据集进行一定的数据样本扩充后,将数据集分为Train和Novel,根据训练时的不同阶段,Train划分为Base和Val。根据K-Way N-Shot策略,每次从Base中采样K个类别N个样本,共计K×N张图片进行训练。首先将图像输入AFP中进行特征提取与处理,然后输入到ACL2N中进行变换,最后进行特征的相似性度量以进行分类。每个Batch训练完之后,从Val中采样出相同数量的K个类别N个样本来验证模型的精度。整个Epoch结束之后,在Novel上测试模型对新类的分类效果。训练的整个流程如图3所示。

图3 模型结构Fig.3 Module structure
3 实验与分析
3.1 数据集介绍
本文实验采用两个主要的小样本学习数据集作为实验数据,在三个分类场景中验证所提模型的有效性。数据集分别为Caltech-UCSD Birds-200-2011数据集(CUB)[27]和mini-ImageNet数据集[28]。
对于常规分类,使用mini-ImageNet数据集。该数据集是ImageNet数据集的一个子集,由100类不同的物体组成,每个类都含有600张图片,如前所述,数据集被划分为Base、Val和Novel,相对应地,三者所含种类分别为64、16、20。每张图片的尺寸为84×84像素。对于细粒度分类,使用Caltech-UCSD Birds-200-2011数据集。CUB数据集是加州理工学院与加州大学圣地亚哥分校联合提出的图像细粒度分类数据集,该数据集是CUB-2010的扩充,含有200类不同的鸟类,总计11 788张图片,每张图片尺寸为84×84像素。用100类训练模型,验证和测试各50类。对于跨域分类,使用mini-ImageNet数据集作为Base,总计100类。CUB的Val和Novel作为跨域场景的Val和Novel,各50类。做该类实验是为了评估在数据分布差异较大的情况下,所提模型的鲁棒性。
3.2 实验设置
3.2.1 实验环境
本文实验均在linux操作系统下使用pytorch深度学习框架完成,硬件配置如下:CPU为Intel Xeon E5-2678,GPU为GeForce RTX 2080,RAM为32 GB。
3.2.2 参数设置
由于深度学习的特点,模型的性能很大程度上取决于网络结构的设计和参数的初始化。特征提取阶段,在ResNet10的基础上实现骨干网络。多分支特征提取模块中,残差分支和双卷积支路中的卷积核参数初始化,采用默认的正态分布初始化。最大池化支路,将池化尺寸设置为3。平均池化分支,将池化尺寸设置为2。在进行加性特征融合时,为了保证公平并且评估特定阶段各支路对特征贡献程度,将各特征的权重全部初始化为1。同样地,在度量相似度阶段,将自适应特征转换层ACL2N中 的β和γ初始 化为1。此外,整 个实 验 中,BatchSize设置为21;Epoch在1-Shot中设置为600,在5-Shot中设置为400;优化器使用Adam,学习率设为0.001。为了在一定程度上扩充数据集,使用了数据增强等预处理,采用随机剪裁、像素级处理、随机翻转,张量化及归一化等五种预处理方法。
3.3 实验结果与分析
3.3.1 实验结果
所有的实验均在K-Way N-Shot分类下进行。和主流的K、N设置一样,分别选取5-Way 1-Shot和5-Way 5-Shot场景进行分类实验。为了评估模型的性能,本文与优秀模型的结果进行了比较。结果如表2、表3、表4所示。
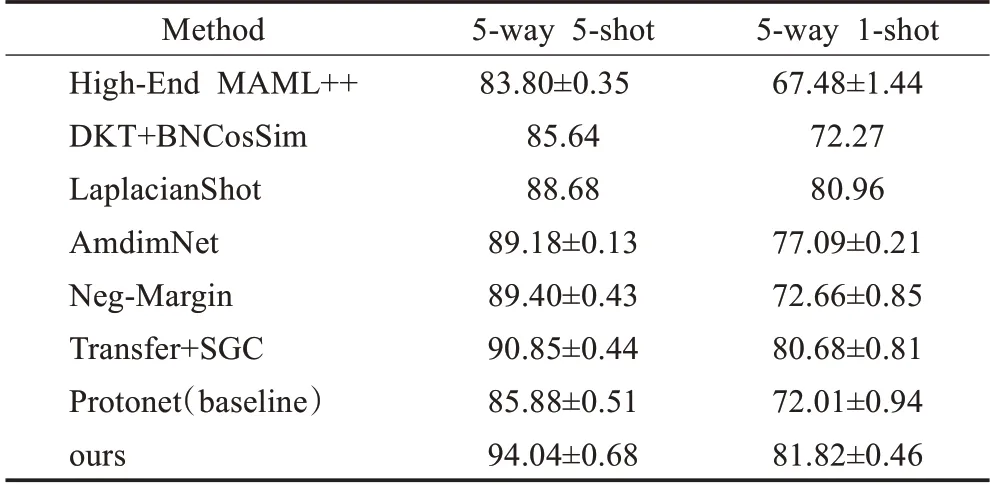
表2 CUB精度表Table 2 Accuracy of CUB 单位:%
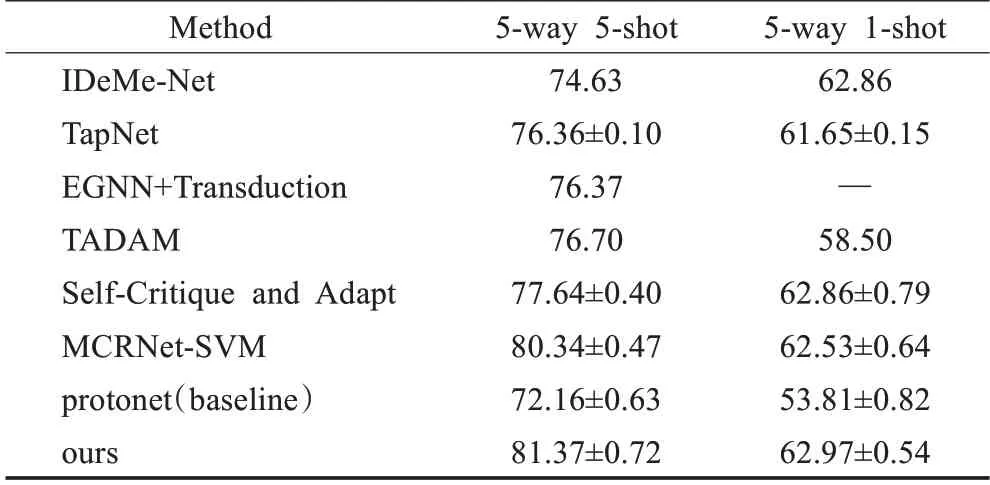
表3 mini-Imagenet精度表Table 3 Accuracy of mini-Imagenet单位:%
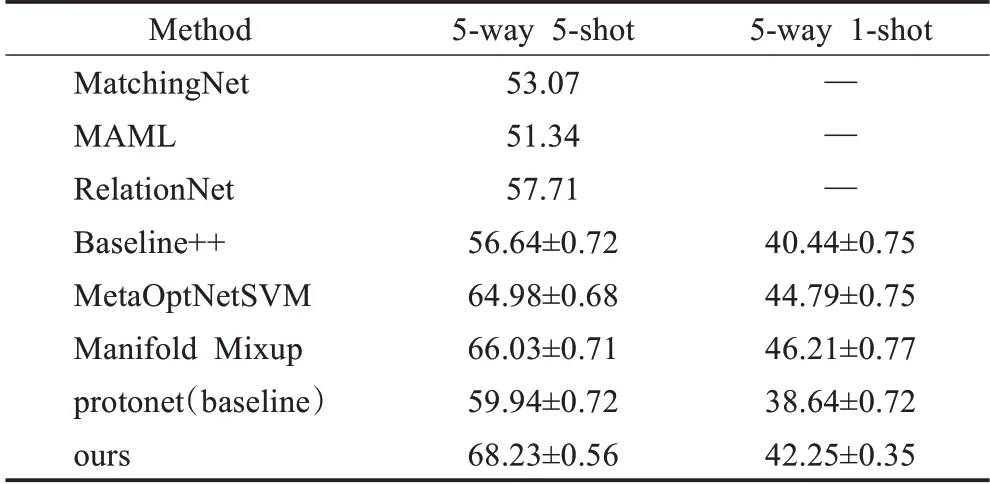
表4 Cross Domain精度表Table 4 Accuracy of Cross Domain单位:%
由实验结果所示,本文模型在CUB数据集上相比Baseline提升了9.81(5-Way 1-Shot)和8.16个百分点(5-Way 5-Shot),在mini-ImageNet数据集上相比Baseline提升了9.16(5-Way 1-Shot)和9.21个百分点(5-Way 5-Shot),在Cross Domain上相比Baseline提升了3.61(5-Way 1-Shot)和8.29个百分点(5-Way 5-Shot)。
3.3.2 结果分析
可以看到,三个实验中,在mini-ImageNet数据集上的平均提升最为显著。如前所述,mini-ImageNet是一个多种类的数据集,所以在该数据集上有好的效果从侧面验证了模型有较好的鲁棒性。在模型中需要尺寸为5×5卷积核的地方,都用两个尺寸为3×3的卷积核来进行替代。在保证感受野不损失的情况下构建了更深的网络层,减少了模型的参数量。基于自适应权重的多层四路特征处理模块可以根据特征的特点在不同层对该层每一支路赋予相应的权重并进行融合,如表5所示,在特征融合模块的不同层中,权重各不相同。其中,每一层中双卷积支路的权重占比都接近50%,表明基于卷积的特征融合的重要性。特征输入进该模块的第一层时最大池化分支占比较大(24%)说明模块对于特征首先进行图像的边缘纹理提取;在第三层时最大池化分支的比重(25%)来到了四组中最大的时候并且与双卷积分支的比重差距最小(14%),说明经过多层特征提取后高层语义中的边缘纹理信息起了相对重要的作用。在自适应的特征转换层中,经过训练得到的自适应参数组βs、γs、βq、γq的值分别为0.77、0.99、1.13、0.83。支持集和查询集参数的变化程度不同说明对于两者来说,特征的变换程度是不同的,支持集的β值更加敏感;查询集的β和γ对于变换都有不同程度的响应。
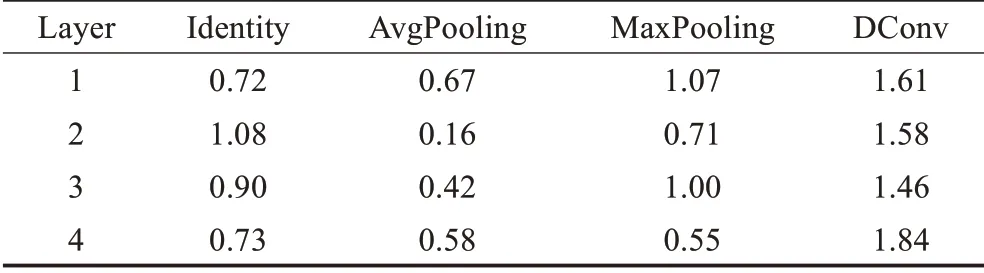
表5 特征处理模块各层权重Table 5 Weight of each layer of feature processing module
分别在单目标物体、双目标物体和多目标物体上设计实验,以便观察相关网络是否对物体特征进行了正确处理。
结合权重模型表,在单目标(图4(a))中,采用上一章讨论模型层数影响时所采用的图片,Block1阶段,最大池化和平均池化的比重在四个阶段里是各自分支最大的,表明在开始阶段模型先关注边缘纹理特征和背景。但是由于权重归一化后比重控制在0到1之间,所以此阶段只能提取到一些微小地边缘特征和背景信息。Block2阶段,由于残差分支的比重较大,使得模型保留了Block1阶段的特征,最大池化的比重有所下降是因为该阶段模型对于背景信息的重视程度较大。值得注意的是,平均池化的比重反而下降,是因为除去最终比重较为合理的第四阶段外,在前三个阶段中,该阶段的双卷积分支比重为最大。由于双卷积分支提取的是局部特征,引入平均池化的初衷是为了与双卷积分支和最大池化分支互补,在权重还不稳定的时候提供一定的背景信息,现在双卷积分支的比重大,平均池化的比重也就相应减少。另外可以看到,残差分支较为契合地对Block1阶段的特征注意进行了再深化,并且由于双卷积分支和平均池化分支的共同作用,使得对背景信息的提取得到提升,需要注意的是,如果给定目标图片只有极少量背景信息,这种背景信息的捕捉在一定程度上会影响到目标物体的捕捉,这种现象在双目标(双甲虫,图4(b))中有一定的体现:在有少量背景信息的情况下,模型仍然对背景有不少的关注。Block3阶段,最大池化分支的权重再次提升,和残差分支的权重基本接近,相应地,在保留上一阶段信息的同时,模型提取到了更多的边缘纹理特征,值得注意的是,对于单目标物体来说,模型对于图像背景的特征提取过多,是由于特征融合不可避免地会融合背景信息,即使如此,模型还是主要聚焦于物体轮廓周围的边缘信息;而作为对比,双目标和多目标(鸭群,图4(c))上,模型可以很好地注意到目标物体:在最大池化捕捉了精确的边缘信息的同时,双卷积分支可以捕捉部分物体信息。在Block4阶段,双卷积分支的比重来到了最大,意味着语义信息的提取与整合越来越重要,高级语义越来越占据重要作用。残差、平均池化、最大池化分支的比重趋于平衡,即目标与背景之间的特征注意处于一个合理的状态。在图中可以看到,目标物体的注意程度越来越高,并且能够较为清晰地分辨出物体本身和背景(这一点在双目标和多目标中更为明显)。从而,模型所提取特征的合理性趋于完善。
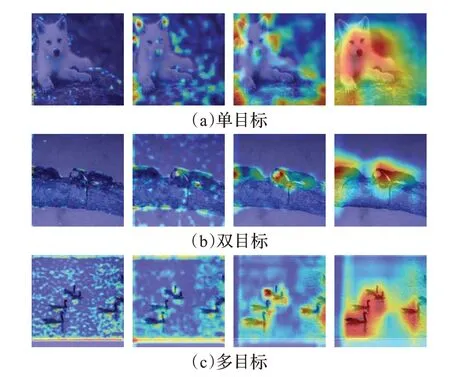
图4 不同任务的CAMFig.4 CAM of different tasks
在双目标中,采用的是两个甲虫的图片。如上所述,Block1阶段模型只提取到零散的边缘信息;Block2是对Block1中提取信息的再扩大,并且由于双卷积分支和最大池化分支的作用,捕捉了一定的背景信息,用于特征的融合;Block3中已经对物体有具体的信息捕捉,并且滤去了大部分背景信息,重点提取物体本身;Block4由于权重趋于合理化,模型已经比较合理地关注双目标物体的大部分信息。值得注意的是,模型对于双目标物体由于特征融合的作用,对于物体的整体关注度相比于单目标要完整许多,这一点在多目标的可视化中得到了进一步验证。可以看到,随着各阶段分支的不断学习,权重也在不断变化并最终趋于合理,对于背景信息的处理也较为理想,使得模型可以较好地捕捉物体进行分类。特别是物体较多的目标任务场景中,模型可以很好地捕捉目标并赋予注意。
3.3.3 模型参数规模及运算
从模型信息表(表6)中可以看出,随着网络的加深,模型所需要的参数和运算规模也成倍地增长,每600循环的实时推理也是如此。由于采用了1×1卷积对特征进行了降维,并且用3×3卷积来代替更大的5×5、7×7卷积,平均池化分支和最大池化分支也没有需要学习的参数,这些设定使得本文模型在增加了多分支的情况下网络参数没有进一步增加。
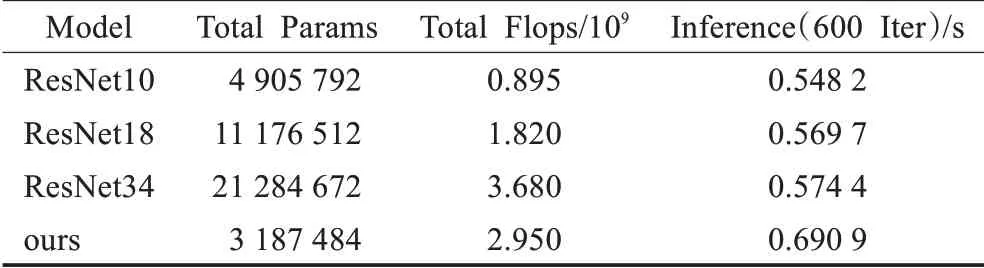
表6 模型参数及运算量Table 6 Model parameters and computational volume
虽然参数较少,但是由于模型采用分支结构以及融合等操作,所以复杂度更高。这点从模型总的FLOPs上也可以看出来。但FLOPs只是通过理论上的计算量来衡量模型,在实际应用时,由于各种各样的优化计算操作,导致计算量并不能准确地衡量模型的速度:相同的FLOPs会有不同的推理速度,低FLOPs也可能有较高耗时的推理,高FLOPs也可能会有较低耗时的推理。除了FLOPs,还有两个重要的因素,其一就是存储访问成本(memory access cost,MAC),其二是并行度,在同样FLOPs的情况下,并行度高的模型推理速度是要快于并行度低的模型[29]。从表中可以看出,本文模型的FLOPs要比ResNet34低,但是推理时间却变得更长。对比Params也是这样:参数较少并不意味着模型简单、推理时间少。在本文模型中,使用了多条支路,最后通过融合的方式将特征送入下一级。如上所述,支路的增加对GPU并行运算并不友好,并且由于支路的融合操作必须要有同步操作,需要等待所有的支路完成相应的运算再进行融合,从而增加了计算时间;1×1卷积虽然减少了参数量,但是进行升降维操作导致MAC变高;在进行特征融合的时候,需要进行Element-Wise操作,然而该操作在GPU上占用的时间是很多的。所以以上因素会导致模型降低效率,增加模型复杂度及实时性推理时间。
3.4 消融实验
为了分析每个模块对模型产生的影响,本文做了以下对比实验:模型无添加模块,模型只添加SE模块,模型只添加多分支特征提取模块AFP,模型只添加特征转换模块ACL2N,模型添加全部模块。对比实验结果如表7所示。
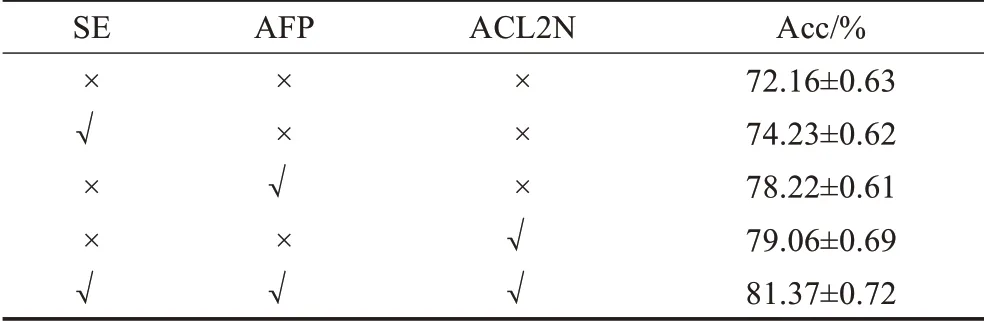
表7 各模块精度Table 7 Acc of each Module
结果表明,三个模块对于分类精度都有不同程度的提升,SE模块的提升相对较少,所以注意力机制可以作为辅助手段添加到模块中,以提升网络的表现,在本文所提的网络也是这样做的。AFP模块和ACL2N模块相较于Baseline,精度都有较大提升,分别为78.22%和79.06%。说明两者都可以作为网络的主模块对特征进行处理。在最后将三个模块同时加入网络取得了81.37%的分类进度,表明三个模块同时使用对网络的提升作用更大。
对于后两个模块,由于有自适应权重的引入,本文将在3.4.1和3.4.2两个小节探究参数对模块性能的影响。
3.4.1 特征融合模块权重分析
在特征融合模块中,将各个分支的权重全部初始化为1是为了使初始时每个分支的重要程度相同。所以在对比实验中设置初始化为1的权重归一化模型(weight normalization model,WNM)和各个分支固定为1的权重平衡模型(weight balance model,WBM)、权重未归一化模型(weight unnormalization model,WUM)进行实验。结果如图5所示,可以看到,与WBM、WUM相比,WNM的表现要优秀不少,表明其权值可以针对特征对特定层的特定分支赋予相应的权重来更好地提升模型的表现。
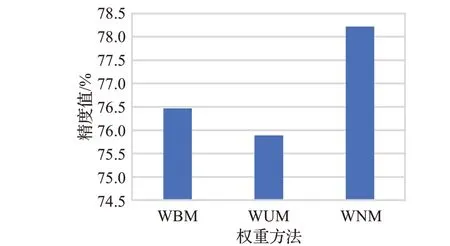
图5 不同权重的精度Fig.5 Precision of different weights
在含有不同物体的混合目标、多目标上进行了实验结果的可视化,结果如图6、图7所示。
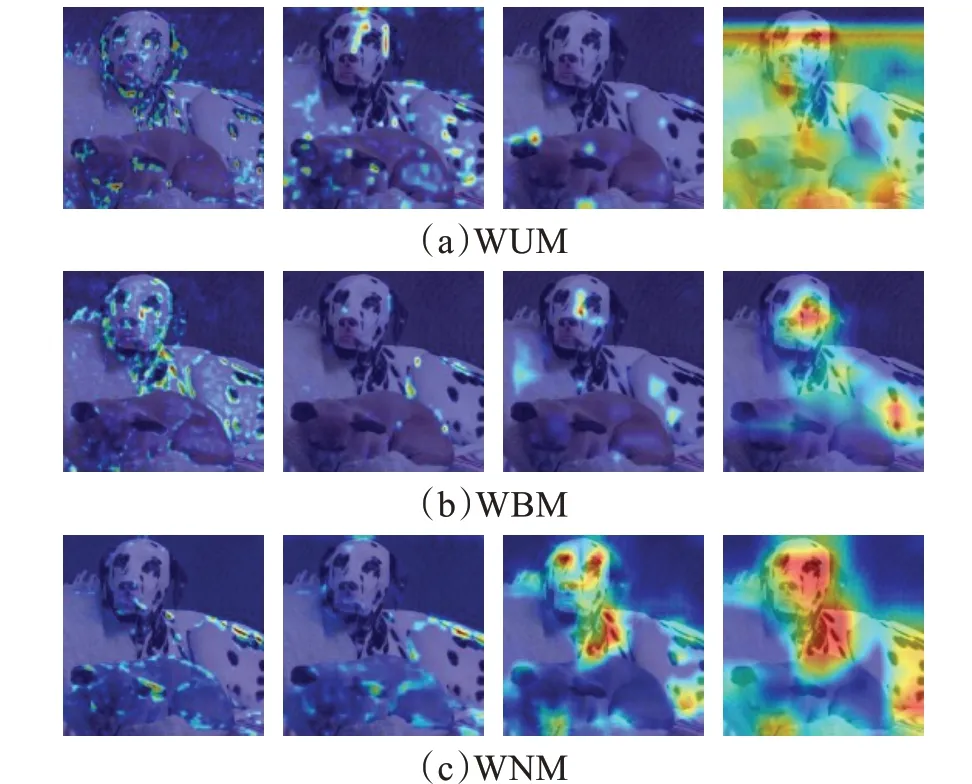
图6 不同权重的混合目标Fig.6 Mixed targets with different weights
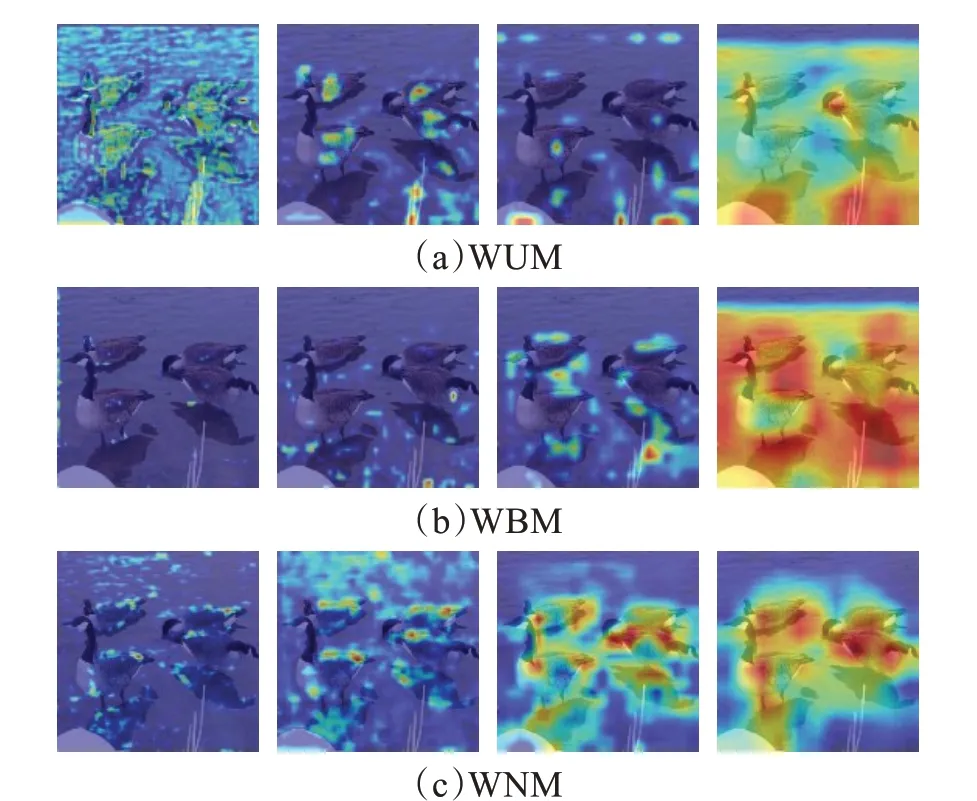
图7 不同权重的多目标Fig.7 Multiple targets with different weights
首先,在混合目标上,采用的是斑点狗与小皮狗的图片。由于WBM和WUM的权重数值要比WNM的要大,在Block1阶段即捕捉到较多的边缘特征信息,其中,关注到不少的不相关物体信息。在Block2阶段,WBM由于权重较为均衡,在经过了一组Block之后,可以减少无关物体和背景信息的关注度,只较少保留了相关物体信息;而WUM的权重大,对于所有物体的信息都会有所捕捉,同时也会有部分背景信息;WNM的归一化权重则收缩了注意范围。在Block3中,值得注意的是由于没有进行归一化,WUM的权重调节过于极端,这一点在下个阶段得到了进一步的验证。在最后一组Block中,各个模型已经有了丰富的特征信息,在WBM中,权重一直处于一成不变的状态,所以最终模型只是对已注意特征的扩大,能够较好地捕捉到相关物体;WUM由于过大的权重,捕捉了过多的物体信息,使得相当一部分背景信息融合进了特征之中,会影响到分类结果;而WNM的归一化权重经过训练,已经有了较为合理的分支权重分配,可以看到,对相关物体有很好的捕捉,对于不相关的物体以及背景信息都有较好的识别。在多目标(图7,鸟群)的展示中,这种现象有了进一步的展示。
3.4.2 特征转换模块系数β和偏置γ数值分析
为了研究ACL2N特征转换函数中β和γ对实验的影响程度,设计了对比不同数值参数的实验。对于support和query的特征转换,本文基于自适应的参数组数值来设置对照参数。这样做的原因是对于初始参数而言,选取训练后在测试集中取得最好精度的自适应参数,将参数组的每个参数换值来进行探究。自适应参数组βs、γs、βq、γq的值分别为0.77、0.99、1.13、0.83,可以看到在训练后γs的受影响程度最小,所以对剩下三个参数进行实验。对于βs,分别以等差为0.1的取值,取βs为0.57、0.67、0.77、0.87、0.97、1.07进行实验。如图8为实验结果,可以看到从0.57精度开始提升,在0.77处取得极大值,之后精度开始降低。对于βq,自适应值为1.13,同样地,分别以0.1为间隔取值,取βq为0.93、1.03、1.13、1.23、1.33、1.43。如图9所示,精度随着值的增加而增加,在1.13处取得极大值后下降。对于γq,自适应值为0.83,取γq分别为0.63、0.73、0.83、0.93、1.03、1.13,结果如图10所示。精度呈现先高后低再升高的波动,在0.83处取得极大值。上述实验表明,在训练时取得的自适应参数组(0.77、1.13、0.83)上的精度最高。
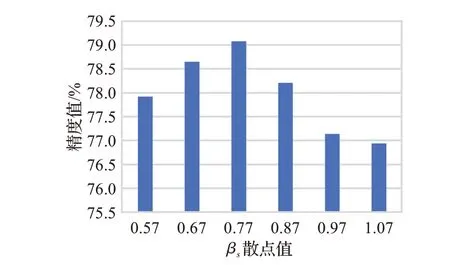
图8 βs变化结果Fig.8 Result of βs changes
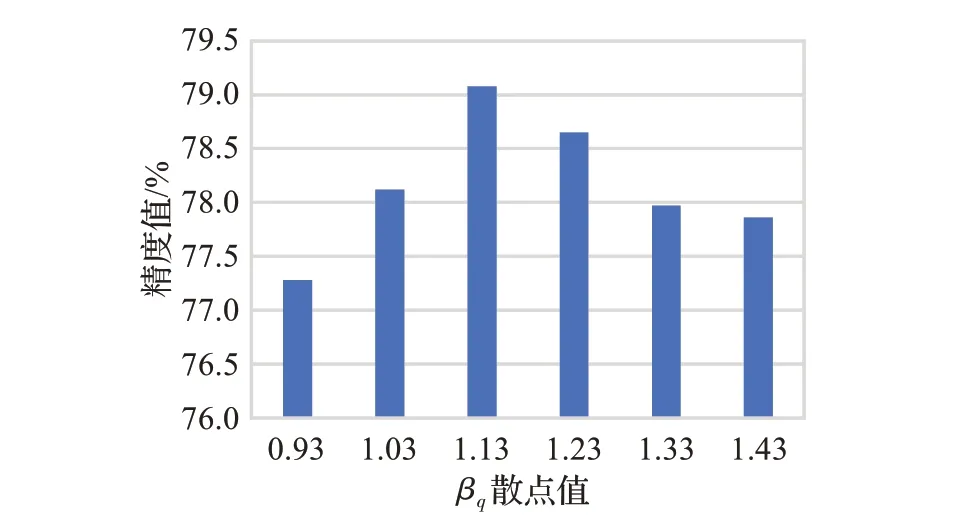
图9 βq变化结果Fig.9 Result of βq changes
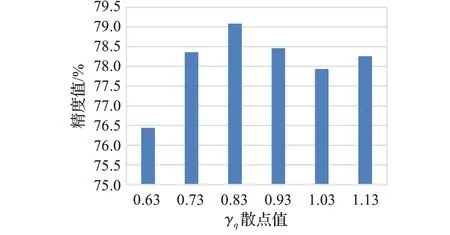
图10 γq变化结果Fig.10 Result of γq changes
结果表明,添加了自适应权重,可以使模块在Episode不断变化的情况下不断学习适应不同的特征分布,从而学习到最佳的适应性参数。
4 结束语
本文根据小样本学习的特点提出了一个针对特征进行操作的小样本图像处理模型。该模型可以较好地利用特征。在特征提取阶段,通过使用自适应加权多路特征提取模块,使得输入图像以不同的特征提取方式进行提取与融合,在此基础上引入自适应的权重使得对于特征可以适应性放缩其中某一支路的特征信号,起到了良好的鲁棒性和正则作用。在相似性度量阶段,对于不断变化的采样,自适应特征变换层ACL2N可以对特征进行相应的分布适应变换,从而匹配特征提取信号的变化,进一步提高模型的表现。通过在CUB和mini-ImageNet数据集上一系列的对比实验和可视化,展示了模型中所提模块的效果,从而验证了模型的有效性。进一步的探究工作可以使用ResNet18等多层网络作为特征提取网络结合层与层之间的特征融合,以便在较深网络中达到更好的分类效果。
猜你喜欢
计算机应用(2022年9期)2022-09-25
黑龙江大学自然科学学报(2022年1期)2022-03-29
软件导刊(2022年3期)2022-03-25
计算机系统应用(2021年10期)2022-01-06
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
学生天地(2019年28期)2019-08-25
计算机技术与发展(2019年1期)2019-01-21
电子制作(2018年19期)2018-11-14
智能计算机与应用(2018年2期)2018-05-23
