
全景图像质量评价方法最新进展
2022-12-22 11:45白岩松于可欣
计算机工程与应用 2022年24期
艾 达,白岩松,于可欣,元 辉,刘 颖
1.西安邮电大学 通信与信息工程学院,西安 710121
2.山东大学 控制科学与工程学院,济南 250100
通过佩戴虚拟现实(virtual reality,VR)设备,人们可以享受全景视频图像沉浸交互式的体验。全景图像作为VR媒体内容最主要的形式之一,由同一位置面向不同方向的场景图像拼接而成。全景图像的显示效果会极大影响VR使用者的视觉感受,因此有效评价全景图像的质量,对VR技术的发展至关重要。
数字图像在采集、存储、处理与传输过程中,受拍摄设备、压缩程度与传输带宽等因素影响,不可避免地造成各种失真,导致图像质量降低受损不能达到令人满意的效果。因此准确预测图像的感知质量对于生成高质量图像与图像处理极为重要。获取图像感知质量的方法被称作图像质量评价,依据其评价主体可分为主观质量评价与客观质量评价[1]。主观质量评价需要测试人员对图像进行人工打分,评价结果符合人类感知但人力时间成本过高,通常用于构建数据集,现实应用较少。客观质量评价通过计算机设计模型来模拟人类的主观质量评价,在实际中应用广泛,其相关技术也在不断发展。传统二维图像质量评价方法可根据通用性程度的不同分为针对特定失真类型[2]和通用型[3]。针对特定失真类型包括对比度失真[4]、失焦模糊[5]、噪声模糊[6]和平移锐化[7]等。深度学习方法的应用也极为广泛[8]。全景图像在存储传输中会引入与传统图像相同的失真类型,例如压缩编码失真、噪声模糊和几何失真等,因此传统图像质量评价方法一定程度上可以应用于全景图像。但是,全景图像由于自身拼接生成特性与内容球面呈现特性产生了传统图像不具备的特殊失真类型,例如缝合失真和投影失真,使得传统图像质量评价方法直接应用于全景图像评价效果不佳。全景图像的图像分辨率较高、数据集量级较小使得基于深度学习的评价方法效果受限。此外,全景图像质量评价数据集大多为研究者自建自用,缺乏权威的公共数据集来对不同评价方法进行性能对比。
随着VR技术的发展和元宇宙时代的到来,全景图像成为一种重要的视觉媒体。全景图像的质量评价也成为近年来的研究热点。有必要梳理总结全景图像质量评价的最新成果与进展。本文旨在对近年来全景图像质量评价方法最新进展进行综述。
1 全景图像客观评价指标
VR用户的观察视角是从球体的中心向外看向球体的内表面,图像内容由360°全球面视图呈现[9]。这一特点使传统二维图像的客观质量评价指标应用于全景图像上很难达到令人满意的效果,因此提出了基于峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)的改进方法。
1.1 改进PSNR方法
Yu等[10]提出一种基于球形的峰值信噪比(spherical PSNR,S-PSNR),该方法放弃在全景图像的等矩形投影上采样,而是选择均匀分布在球面上的采样点来计算PSNR。对于球上一采样点,通过三维到二维的投影分别在参考图像与失真图像上找到对应的点,计算两点之间的均方误差,然后计算所有采样点(采样点数量有限)的误差并累加。Sun等[11]提出了加权球形峰值信噪比(weighted-to-spherically-uniform PSNR,WS-PSNR),根据投影平面与观察空间(球面)之间的畸变非线性关系,对平面全景图像每个像素位置的误差进行加权再计算PSNR。该方法可以在二维平面直接计算,其中权重与投影格式有关。Zakharchenko等[12]提出了克拉斯特抛物线投影峰值信噪比(Craster’s parabolic projection PSNR,CPP-PSNR),将失真图像和参考图像投影到没有空间分辨率变化的克拉斯特抛物线投影(CPP)格式下计算PSNR。
全景图像改进PSNR的方法总结如表1所示。

表1 PSNR改进方法分析Table 1 Analysis of PSNR improvement methods
1.2 改进SSIM方法
Chen等[13]提出了球面结构相似度(spherical SSIM,S-SSIM),将二维平面中的像素投影到球体,根据球体与投影平面的结构相似性关系和投影平面内的畸变程度,处理投影带来的干扰。S-SSIM基于亮度、对比度和结构比较来量化参考图像和失真图像之间的感知相似度。Zhou等[14]提出了球面加权结构相似度(weightedto-spherically-uniform SSIM,WS-SSIM),根据投影平面与观察空间(球面)之间的畸变非线性关系,对平面全景图像局部块的SSIM评价值加上适当的权重。
全景图像改进SSIM的方法总结如表2所示。

表2 SSIM改进方法分析Table 2 Analysis of SSIM improvement methods
1.3 小结
全景图像的客观评价指标主要基于传统客观评价指标PSNR和SSIM改进获得。球域与平面的差异是改进方法的重要切入点,例如直接选择在球域上采样进行计算,在平面上进行加权计算,其中权重由采样区域的被拉伸程度确定。将传统指标进行改进并应用至全景图像,计算简单且易于理解,并缓解了部分投影拉伸。但由于全景图像的分辨率较大且失真类型多样,客观评价指标的效果远不能令人满意。
2 基于深度学习的全景图像质量评价方法
近年来,全景图像质量评价大多采用了深度学习的方法,使用的数据集包含了全景图像可能出现的多种失真,例如JPEG压缩、HEVC压缩、高斯模糊和高斯噪声等。
2.1 网络输入为ERP图像
此类方法将完整的ERP图像作为输入或将ERP图像均分成图像块再输入到网络,数据预处理简单且计算复杂度低。
Lim等[15]提出了VR-IQA-NET(virtual reality image quality assessment NET)方法,其网络架构由质量分数预测器和人类感知引导器组成。质量分数预测器将失真图像分成256×256大小的图像块进行特征提取,利用潜在的空间和位置特征预测畸变图像的质量分数。人类感知引导器使用对抗性学习优化预测质量得分。
Truong等[16]设计了侧重于学习输入图像中间区域特征的模型Omni-IQA(omnidirectional image quality assessment)。该模型首先预测了从输入图像中采样获得的64×64大小图像块的质量分数,然后依据图像块所处位置来分配权重,给赤道区域图像块赋予高于顶部和底部区域的权重再来计算整体图像的质量分数。
Hou等[17]认为图像块式训练无法缓解全景图像局部区域内的失真问题,提出了一种多任务学习策略
SPIQA(stitched panoramic image quality assessment),该策略鼓励学习者减少对图像内容的依赖。训练一个具有两个权重共享的CNN分支的暹罗网络,将同一场景中的两幅完整图像一起输入网络,同时比较两幅图像的质量,并预测每幅图像的质量分数。由于同一个CNN处理同一场景的两幅图像,CNN在质量排名目标的约束下倾向于发现它们的质量差异,而不是内容差异。
Yang等[18]提出了基于空间注意的感知质量预测网络(spatial attention-based perceptual quality prediction network,SAP-net)。其网络架构由基于小波的残差增强模块、感知质量估计模块和质量回归模块组成,受损图像被分成256×256大小的图像块输入网络,在残差增强模块中实现客观的质量增强,然后将其作为误差图与失真图像本身合并送入感知质量估计模块进行质量预测并通过质量回归模块得到预测分数。该网络可以在没有人类显著性标签的情况下,通过自我注意的方式自适应地估计失真全景图像上的人类感知质量,在大大降低计算复杂度的同时显著提高了质量分数的预测性能。
Zhou等[19]提出了基于深度学习的PFAHQP(pyra‐mid feature aggregation for hierarchical quality prediction)。其网络架构由虚拟参考生成(imaginary reference gen‐eration,IRG)模块和层次质量预测(hierarchical quality prediction,HQP)模块组成,IRG模块通过迁移学习模拟人类视觉系统(human visual system,HVS)在面对失真图像时想象参考图像的能力。HQP模块通过金字塔特征聚合适应图像失真的特殊性和复杂性。
2.2 网络输入为视口图像
人们在VR设备中查看全景图像时,其视觉内容首先由3D球坐标中的球体表示,然后被渲染为与球体相切的平面段,该平面段称为视口(viewport),其大小由VR设备的视角和视场角FoV(field of view)决定。简单来说是部分球体在2D平面上的投影。视口图像的优点是与VR设备中看到的360°图像的视觉内容保持一致。图1表示了从VR球面中获得视口图像。
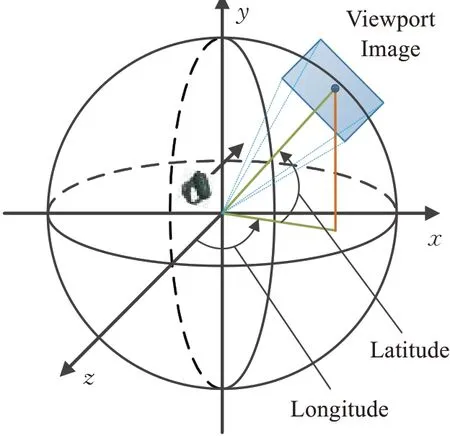
图1 从VR球面内容获得视口图像示意图Fig.1 Schematic diagram of obtaining viewport image from VR spherical content
Sun等[20]提出了MC360IQA(multi-channel convolu‐tional neural network(CNN)for blind 360-degree image quality assessment),网络模型采用视口图像作为输入,将每个全景图像投影到六个视口图像中,覆盖了全方位的视觉内容。网络由多通道CNN和图像质量回归器两部分组成。多通道CNN包括六个并行ResNet34网络,用于提取相应六个视口图像的特征。图像质量回归器融合特征并将其回归到最终分数。
Xu等[21]提出了面向视口的图卷积网络(viewport oriented graph convolutional network,VGCN),建立了一个全景图像中视口之间的相互依赖关系模型。图形节点首先由被看到概率较高的选定视口定义,然后通过空间关系将这些节点连接起来,捕获它们之间的交互。最后通过图卷积网络对获得的图像进行推理。
Tian等[22]提出了一种基于视口的全景图像质量评价器(viewport-based stitched omnidirectional image quality evaluator,VSOIQE)。其网络架构由视口选择、特征提取和质量回归组成,视口选择方面,选择了全景图像缝合区域的视口和显著性较高区域的视口。特征提取方面,通过提取多方向边缘一致性、高宽比相似度和颜色相似度特征度量图像的几何失真、形变和色差,并使用基于局部置信度和结构复杂度的自适应池化(self-adaptive pooling,SAP)。最后采用多元线性回归得到质量分数。
Zhou等[23]提出了失真鉴别辅助多流网络(distortion discrimination assisted multi-stream network,DDAMSN)。其网络架构由视口生成模块、共享网络模块和两个独立的任务学习模块组成。视口生成模块模拟用户在VR中感知的内容,共享网络模块学习两个任务之间的互信息,两个学习模块分别用于质量评价任务和失真识别任务。通过失真识别辅助网络优化共享网络,以提高质量评价网络的预测性能。
2.3 小结
基于深度学习的图像质量评价方法根据模型输入的类型可以分为基于完整ERP图像与基于视口图像。表3分析和归纳了近年来基于深度学习的全景图像质量评价方法。基于ERP图像的方法思路类似于传统IQA方法,将整张图像直接输入网络进行相应特征提取,操作相对简单快捷,但忽略了ERP图像所含有的投影拉伸失真。而视口图像的生成就是模拟人类在VR中查看全景图像的行为,将视口投影至平面很大程度上缓解了全景图像的投影拉伸。视口图像相较于ERP图像也更为符合人的感知过程,符合人眼视觉特性。此外,同一张全景图像可以依据不同的方法生成多组视口图像,实现了数据集的数据增强,一定程度上解决了深度学习所需数据量不足的问题。因此在最新提出的评价方法中,基于视口图像的方法较多且评价性能总体来说优于基于ERP图像的方法。

表3 基于深度学习的全景图像质量评价方法分析Table 3 Analysis of panoramic image quality assessment methods based on deep learning
3 针对全景图像特殊失真的质量评价方法
全景图像是由全景相机拍摄后通过拼接算法得到的球体信号。将球体信号投影至二维平面以便压缩、存储与传输。这造成了全景图像不同于传统二维图像的特殊失真:边缘缝合失真和投影拉伸失真。基于全景图像两种特殊失真的质量评价方法如下。
3.1 全景图像缝合失真
全景图像是由多个方位的视口图像缝合拼接而成,因此存在缝合失真,主要表现形式为重影和结构不一致的视觉伪影,如图2红色框内所示。

图2 拼接图像常见失真Fig.2 Common distortions on stitched image
Ling等[24]使用卷积稀疏编码(convolutional sparse coding,CSC)和一组卷积滤波器来定位目标图像中特定的缝合失真,提出了用于准确评估特定缝合伪影的度量NR-CSC-SIQA(no reference CSC stitched IQA),并使用一种新的序列特征选择算法来量化上述复合失真效应。
考虑到人类视觉系统(HVS)的特点,Zhu等[25]提出了差分信息感知模型(difference information sensing model,DISM)。该方法首先利用Gabor滤波检测图像的边缘,然后构造差分图像,最后结合just noticeable difference(JND)差异阈值形成评价模型。
为了关注局部和全局两个层面的特征,Li等[26]提出注意力驱动的全景图像质量评估方法(attentive quality assessment,AQA),其全局度量主要考虑环境差异,如色差和盲区现象;局部度量主要关注影响平均意见分数的显著性区域和拼接区域。Liu等[27]提出了结合局部和全局特征的评价方法(combining local and global features for quality assessment,CLGFQA)。将全景图像分为失真区域和非失真区域,分别提取失真和非失真区域的质量特征,然后计算特征之间的距离作为局部质量度量。全局质量使用一般的图像质量评价特征。Cui等[28]提出了基于局部视觉和全局深度特征的盲缝合全景图像质量评价方法(local visual and global deep features based blind stitched panoramic image quality evaluation,LVGD_BSPIQE),局部视觉特征方面,通过稀疏特征提取获得图像的结构、纹理和颜色畸变,通过加权局部二值模式特征度量各种弱畸变。全局特征方面,通过预训练好的卷积神经网络模型提取深度特征表示高级语义。并采用集成学习提高泛化性能。
基于全景图像缝合失真的质量评价方法分析对比如表4所示。
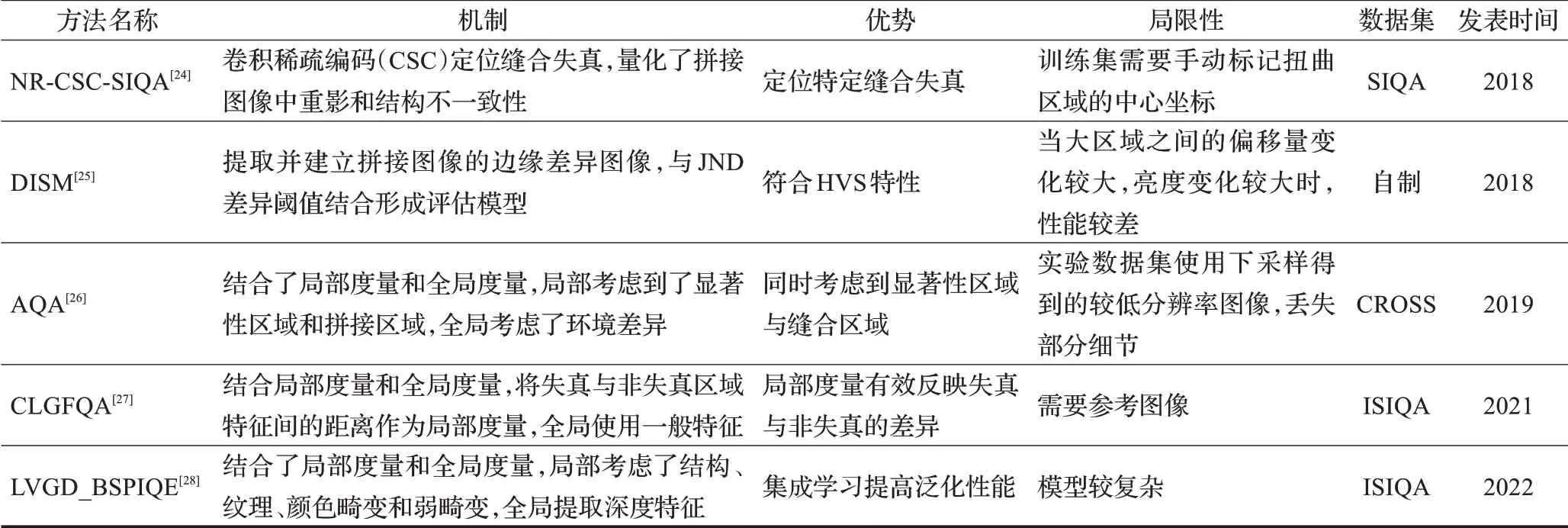
表4 基于全景图像缝合失真的质量评价方法Table 4 Panoramic image quality assessment methods based on stitching distortion
3.2 全景图像投影失真
动态图像专家组(moving picture experts group,MPEG)开发了全向媒体应用格式[9](omnidirectional media format,OMAF)。在此格式中,使用等矩形投影(equirectangular projection,ERP)作为全向媒体的默认投影,将原始球形信号投影到二维(2D)平面上,以便使用现有编码标准进行压缩和传输。图3表示了ERP投影过程。
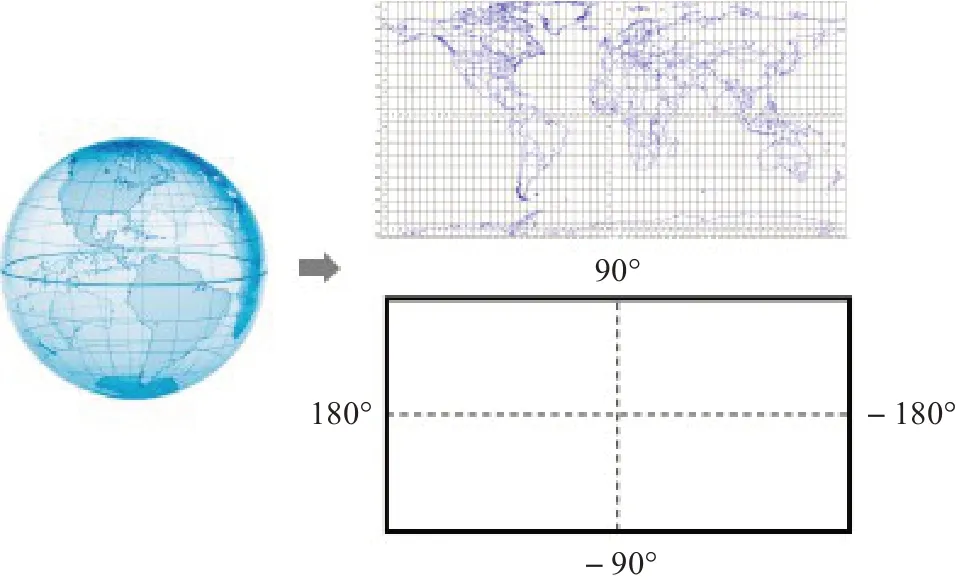
图3 等矩形投影格式Fig.3 Equirectangular projection format
从球体投影向二维平面的过程中,不可避免地会产生投影拉伸的失真,如图4框线内所示。图4中(a)为全景图像球面顶部投影的视口图像,(b)为全景图像的ERP格式投影。其中红色框线内为该全景图像的相同区域,可见相同区域在ERP投影格式下产生了明显的拉伸失真,越接近双极区域,投影拉伸就越严重。
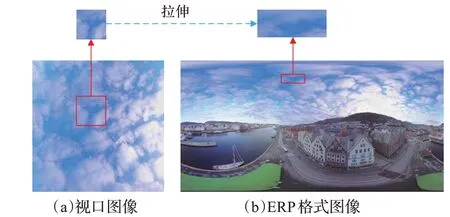
图4 全景图像投影拉伸失真Fig.4 Projection stretch distortion on panoramic image
针对这一特点,研究者们开始使用不同的投影格式来进行全景图像的质量评价。Zheng等[29]提出了一种基于分段球面投影(segmented spherical projection,SSP)的盲全景图像质量评价(SSP based blind omnidirectional image quality assessment,SSP-BOIQA)方法,首先将ERP格式的图像转换为SSP格式的图像,以解决ERP格式图像双极区的拉伸变形问题,但保留了ERP格式图像的赤道区域。并提出一种扇形窗口的局部/全局感知特征提取方案来估计全景图像双极区域的失真。并以热图为权重因子提取赤道区域的感知特征。最后将从全景图像的双极区和赤道区提取的特征集合起来,预测失真全景图像的质量。Jiang等[30]提出了基于立方体贴图的感知驱动盲质量评估(cubemap-based perceptiondriven blind quality assessment,CPBQA)框架,通过六个相互关联的立方体映射投影(cubemap projection,CMP)方法来实现全景图像的全方位观看。基于CMP的六个立方体映射面,提出了感知驱动的全景图像质量评价框架,该框架考虑了人类的注意行为,提高了框架的有效性。Jiang等[31]提出了基于多角度投影的盲全景图像质量评价(multi-angle projection based blind omnidirectional image quality assessment,MP-BOIQA)方法。将全景图像以不同视角生成的多组彩色立方体映射投影图像组成彩色全向失真(COD)单元,并用等角区间投影表示同一图像的不同失真水平。通过张量分解降维,再从降维数据中提取特征预测质量分数。
基于全景图像投影失真的质量评价方法分析对比如表5所示。
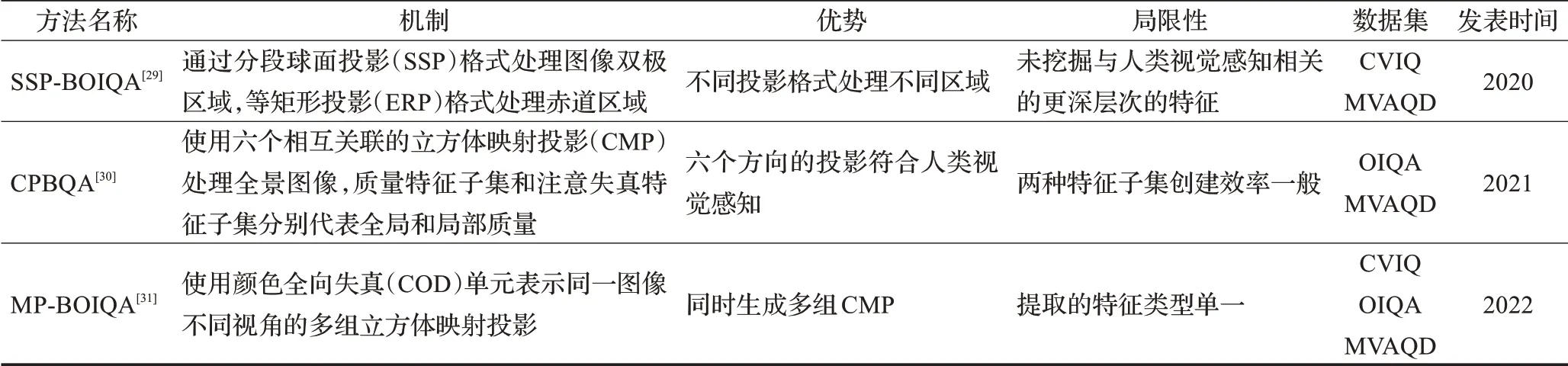
表5 基于全景图像投影失真的质量评价方法Table 5 Panoramic image quality assessment methods based on projection distortion
全景图像的视口图像由VR设备的视角和视场角FoV决定。Jabar等[32]评估了广义透视投影对全景图像视口渲染的感知影响,经过一系列主观评价实验与总结后得到了图像内容和FoV在决定哪种投影在感知上最适合全景图像和视频的视口渲染方面起着核心作用。其后Jabar等[33]又进行了主观测试实验,旨在评估FoV对感知质量的影响,并找到在用户沉浸式体验和感知几何失真之间进行最佳权衡的FoV。最终在参与测试的观察者中,对接近110°的FoV偏好最佳。
3.3 小结
缝合失真和投影失真是全景图像所特有的两种特殊失真类型。缝合失真由全景图像的生成机制不可避免地产生,出现在图像的拼接缝合区域,包括结构、纹理和颜色等失真。现有方法主要定位失真区域并综合考虑多种失真特性提取相应特征进行质量评价。投影失真则是全景图像由球域投影至默认ERP格式不可避免引入的失真,越靠近双极区域投影失真越严重。现有评价方法多为使用不同的投影方法对ERP图像进行投影来缓解投影拉伸,其中立方体映射投影(CMP)常用于获取视口图像。针对两种特殊失真的质量评价方法能有效评价对应失真类型的全景图像,但无法有效应对日常存储传输中的常见失真类型,通用性不足。
4 评价方法性能对比
4.1 质量评价数据集
图像质量评价数据集一般包含失真图像与相应的主观质量评分。主观质量评分需要测试人员根据一定的评价准则或自身经验对单幅图像的视觉效果进行主观质量评判。由于个人的主观差异性,需要多位观测者进行打分,最终在去除异常值的情况下进行加权平均,得到平均主观得分(mean opinion score,MOS)。另一种评分标准为平均主观得分差异(differentiation mean opinion score,DMOS),描述的是人眼对参考图像和失真图像评价得分的差异。MOS值越大代表图像质量越好,DMOS值则相反,数值越小代表质量越好。
传统二维图像已拥有LIVE、TID、CSIQ等较为权威通用的图像质量评价数据集,但全景图像质量评价尚未存在公认权威的公共数据集。现存的全景图像质量评价数据集大多为研究者自建自用。
4.1.1 数据集介绍
(1)SIQA
SIQA数据集[34]由Cheung等于2017年建立。该数据集中共有34张参考图像和1 224张失真图像。包含多种拼接算法导致的缝合失真。分辨率为3 000×2 000。MOS的主观评分范围为[0,100]。
(2)SUN360
SUN360数据集[35]是Xiao等2012年建立的全景图像数据集,其中包含80个类别和67 583张全景图像,分辨率为9 104×4 552。但该数据集并没有进行主观质量评价。文献[15-16]从SUN360中随机选择部分图像进行失真处理与主观评价来构建用于自身实验的数据集。文献[15]数据集包含60张参考图像和720张失真图像,包含JPEG[36]、JPEG2000[37]和HEVC压缩[38]三种失真类型,分辨率为2 048×1 024。文献[16]数据集包含10张参考图像和120张失真图像,失真类型为JPEG压缩,分辨率为4 096×2 160。本文将文献[15]使用的数据集记作SUN360(a),文献[16]使用的数据集记作SUN360(b)。
(3)OIQA
OIQA数据集[39]由Duan等 于2018年建立。该数据集中共有336张图像,其中16张参考图像和320张同源的失真图像。包括四种失真类型:JPEG压缩、JPEG2000压缩、高斯模糊和高斯噪声。所有图像均为等距矩形格式,分辨率范围从11 332×5 666到13 320×6 660。MOS值的主观评分范围为[1,10]。
1.1一般资料2014年10月至2015年6月我院对100例精神分裂症患者开展了分析研究,将患者分成对照组和观察组,均有50例。对照组有24例女性和26例男性,最小23岁,最大75岁,平均(42.73±10.76)岁;体重最低42 kg,最高82 kg,平均体重(63.89±6.04)kg。观察组共有25例男性和25例女性,最小25岁,最大74岁,平均(42.58±10.47)岁;体重最低41 kg,最高82 kg,平均体重(63.21±6.26)kg。两组的普通资料对比不存在统计学差异性,可以开展比较分析。
(4)CVIQ
CVIQ数据集[40]由Sun等于2018年建立。该数据集中共有544张图像,其中16张参考图像和528张同源的失真图像。包括三种失真类型:JPEG压缩、H.264/AVC压缩和H.265/HEVC压缩。参考图像包含各种场景,如城镇、风景、人物和物体,分辨率为4 096×2 048。MOS值被归一化并重新调整到范围[0,100]。
(5)MVAQD
MVAQD数据集[41]由Jiang等于2019年建立。该数据集中共有315张图像,其中15张参考图像和300张同源的失真图像。包括五种失真类型:JPEG压缩、JPEG2000压缩、H.265/HEVC压缩、高斯模糊和高斯白噪声。分辨率为5 780×2 890。MOS的主观评分范围为[1,5]。
(6)ISIQA
ISIQA数据集[42]由Madhusudana等于2019年建立。该数据集中共有26张参考图像和264张失真图像。包含多种拼接算法导致的缝合失真。分辨率为9 270×1 680。MOS的主观评分范围为[0,100]。
(7)CROSS
(8)IQA-ODA
IQA-ODA数据集[21]由Xu等于2021年建立。该数据集中共有120张参考图像和960张失真图像。包含JPEG压缩以及多种投影模式。分辨率为7 680×3 840。DMOS的主观评分范围为[0,100]。
4.1.2 小结
全景图像质量评价数据集可以依据包含的失真类型大致分为两类:一类是以ISIQA数据集为代表的,主要包含使用不同图像拼接方法生成全景图像时所引入的缝合失真;另一类是以OIQA、CVIQ数据集为代表的,主要包含全景图像日常压缩存储传输过程中引入的失真,例如压缩失真、高斯模糊等。数据集的不同导致评价算法的侧重点不同,同时包含两类的数据集尚不存在,因此能同时应对拼接算法导致的缝合失真和日常使用引入的失真的评价算法也不存在。全景图像数据集还具有分辨率高、数量级小的特点,这限制了深度学习方法的发挥。此外,还缺乏权威的公共数据集进行评价方法性能对比。表6将近年全景图像质量评价的公共数据集进行总结对比。
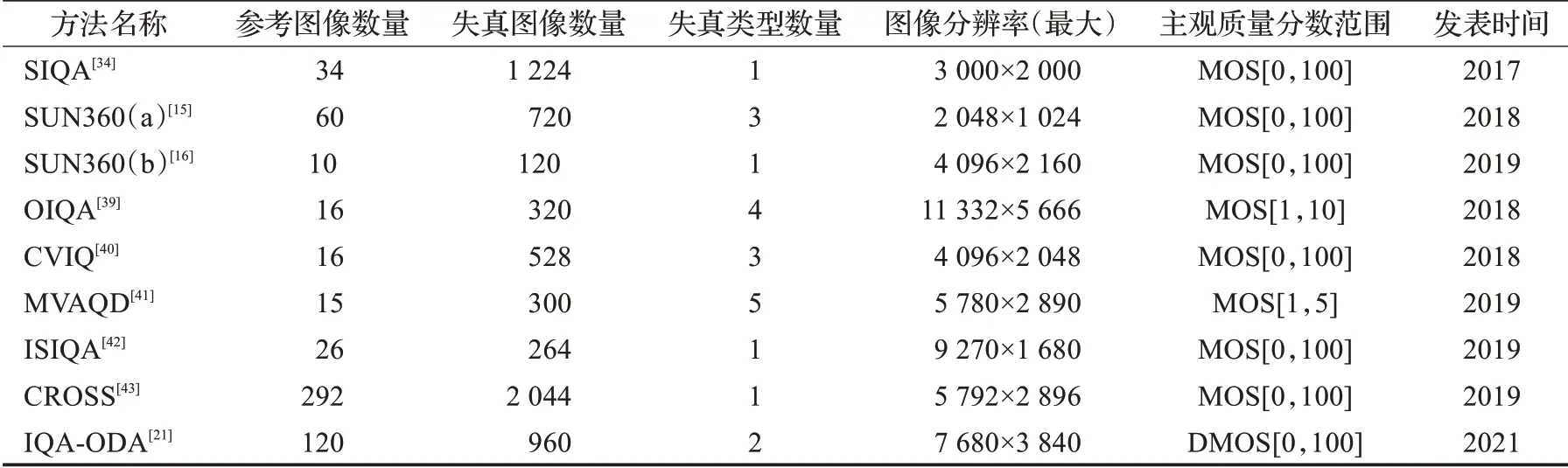
表6 公共全景图像质量评价数据集Table 6 Public panoramic image quality assessment datasets
4.2 评价性能对比
4.2.1 评价指标
国际通用图像质量评价性能指标主要有:皮尔森线性相关系数(Pearson linear correlation coefficient,PLCC)、斯皮尔曼秩相关系数(Spearman rank order correlation coefficient,SRCC)和均方根误差(root mean squarederror,RMSE)[44]。PLCC、SRCC和RMSE分别衡量客观质量评价方法得到的预测分数与图像的MOS值之间的准确性、单调性和误差。PLCC、SRCC的取值范围为[0,1],绝对值越接近1越好,RMSE则越小越表明客观质量评价方法的性能越好。
4.2.2 性能对比
表7对比了采用公开数据集OIQA、CVIQ和MVAQD进行实验的全景图像质量评价方法性能,其中包含客观评价指标CPP-PSNR、WS-SSIM,基于全景图像投影失真的SSP-BOIQA、MP-BOIQA以及基于深度学习的MC360IQA、VGCN和DDAMSN。表8对比了采用SIQA、ISIQA和CROSS数据集进行实验的方法性能,其中包含针对全景图像缝合失真的NR-CSC-SIQA、AQA、CLGFQA和LVGD_BSPIQE以及基于深度学习的SPIQA、PFAHQP和VSOIQE。表9列举了VR-IQA-NET、Omni-IQA和SAP-net在各自数据集上实验的方法性能。
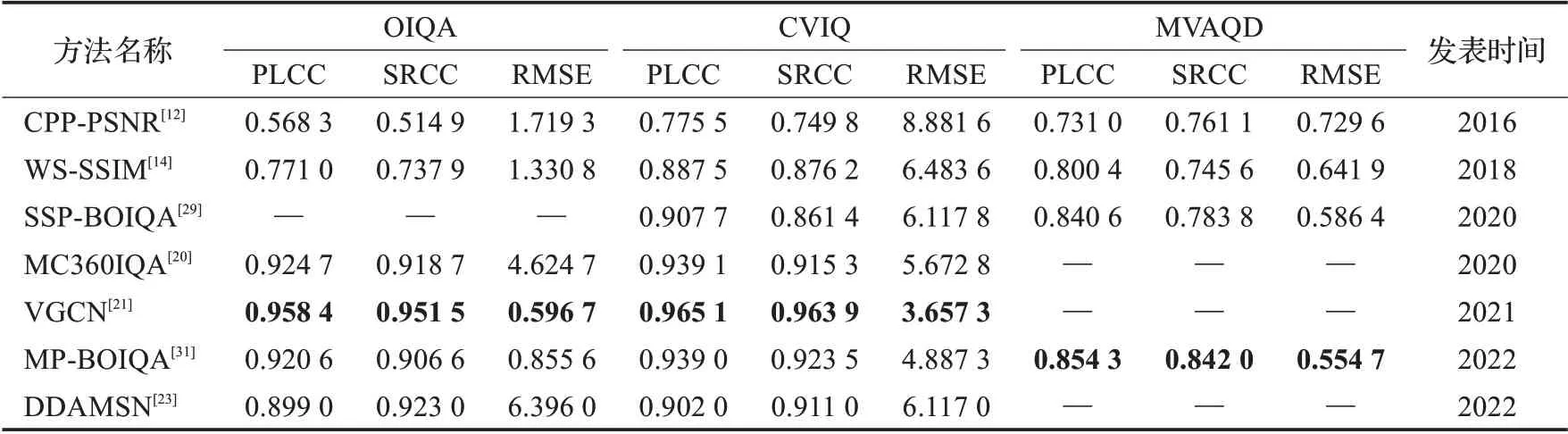
表7 公共数据集评价性能比较(OIQA,CVIQ,MVAQD)Table 7 Performance comparison on public datasets(OIQA,CVIQ,MVAQD)
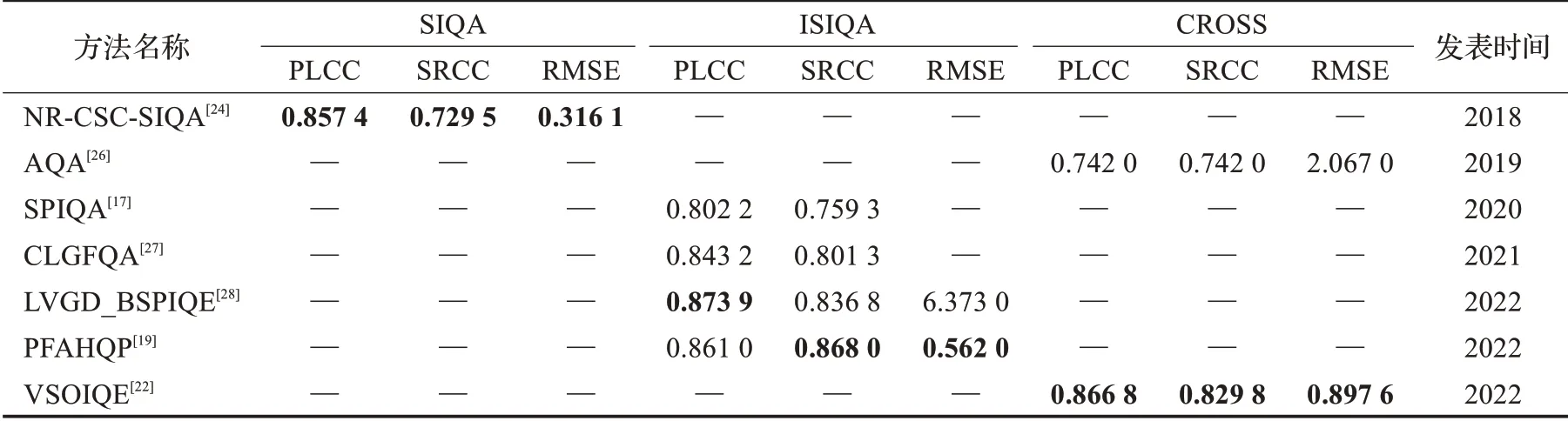
表8 公共数据集评价性能比较(SIQA,ISIQA,CROSS)Table 8 Performance comparison on public datasets(SIQA,ISIQA,CROSS)
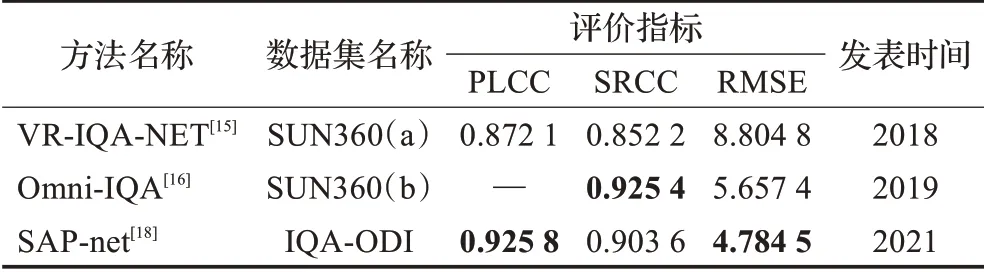
表9 公共数据集评价性能比较(SUN360,IQA-ODI)Table 9 Performance comparison on self-built datasets(SUN360,IQA-ODI)
4.2.3 小结
全景图像质量评价目前缺乏公认权威的公共数据集,不同评价算法之间的性能对比比较困难,目前只能在较为常用的数据集上分别对比分析。OIQA、CVIQ和MVAQD数据集主要面向存储传输中引入失真的评价,基于投影失真和基于深度学习的方法使用较多。由表7中实验结果表明,全景图像客观评价指标的效果较差,例如CPP-PSNR、WS-SSIM的PLCC和SRCC性能与人的主观感知匹配度较低。基于全景图像投影失真的方法性能比之客观评价指标有了部分提升,但提升幅度有限;基于深度学习的全景图像质量评价方法则实现了显著的性能提升,PLCC与SRCC已经突破0.9,其中VGCN达到了最好的评价效果,与人眼主观感受较为一致。并且深度学习方法中以视口图像为网络输入的性能要整体优于以ERP图像为输入的方法。SIQA、ISIQA和CROSS数据集主要面向拼接算法导致缝合失真的评价,其中ISIQA数据集使用频次较高,由表8显示,实验结果最优的PLCC和SRCC性能超过0.85但尚未突破0.9,仍有一定提升空间。表9中评价方法使用数据集难以找到其他方法与之对比,所以参考价值较低。
5 总结与展望
5.1 总结
近年来随着VR技术的发展和元宇宙时代来临,全景图像质量评价成为研究热点。相关图像质量评价数据集和先进评价方法被相继提出。
(1)目前全景图像的客观评价指标主要是基于传统客观评价指标峰值信噪比PSNR与结构相似性SSIM改进而来,但评价效果与人眼主观感知匹配度较低。
(2)基于深度学习的评价方法进一步提升了评价的效果与精度,其中部分方法的评价结果已经较为符合人类感知。但现常用全景图像质量评价数据集失真图像数量仅为300到500,尚未存在量级较大且包含各类失真的数据集。这限制了深度学习方法的性能。并且全景图像质量评价研究使用的数据集多为自建自用,尚未存在公共权威的数据集能够满足不同评价方法横向对比的需求。
(3)全景图像由于自身的拼接生成特性与内容球形展示,具备不同于传统二维图像的特有失真:缝合失真和投影失真。基于特殊失真提出的方法部分效果尚可,但仍需进一步提高。
(4)图像质量评价是利用计算机模拟人眼对图像的视觉感受进行评价,人眼视觉系统特性是影响评价效果的重要因素,评价效果要符合人眼主观感受。
5.2 展望
(1)全景图像的客观评价指标以及全参考质量评价方法的性能较低,远不能达到较为令人满意的效果。因此探寻新的客观评价指标或将传统二维图像全参考质量评价方法改进适配至全景图像领域值得进一步研究。
(2)基于深度学习的IQA方法性能受限于数据集数据不足的情况,这在全景图像数据集中尤为显著。因此在方法中进行数据扩充并建立一个能够满足多方实验需求且数据量足够的公共权威数据集是未来的研究方向之一。
(3)针对全景图像自身特殊失真的质量评价方法具有一定的现实应用性,但应用面严重受限。因此探索能够同时应对各类失真的通用型全景图像质量评价方法在近些年逐渐兴起,但仍需进一步研究。
(4)有些方法的评价效果与人眼的主观感受相悖,这是由于未考虑到人眼视觉系统特性。不同评价方法效果对比也可以看出蕴含人眼观察特点的方法效果往往较好。因此探索符合人眼视觉系统特性和人类视觉感知特点的全景图像质量评价方法值得深入研究。
猜你喜欢
军事文摘(2022年8期)2022-05-25
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
家庭影院技术(2020年11期)2020-12-28
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
作文小学中年级(2020年6期)2020-07-24
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
英美文学研究论丛(2018年1期)2018-08-16
家庭影院技术(2017年12期)2017-02-06
