
跨模态检索研究综述
2022-12-22 11:45侯腾达王晏祎蒋义凯
计算机工程与应用 2022年24期
侯腾达,金 冉,2,王晏祎,蒋义凯
1.浙江万里学院 大数据与软件工程学院,浙江 宁波 315100
2.浙江大学 计算机科学与技术学院,杭州 310027
跨模态检索(cross-modal retrieval,CMR)是计算机视觉与自然语言处理的交叉领域,该领域在语音-面容匹配与检索、手语翻译、材料识别分类等实际应用方面都取得了重大突破。跨模态检索是指用户可用某一模态数据来查询不同模态的数据。例如在观看篮球比赛时,用户可通过球赛照片来检索与球赛相关的音频、视频、文字等多媒体信息,较单模态检索更加灵活,信息更丰富。以图像-文本检索为例,图像数据I={i1,i2,…,in},文本数据T={t1,t2,…,tm},当凭借任一文本数据tx,x∈[1,n]查询与文本对应图像数据时,则得到的跨模态检索结果集合可表示为vx={vy|max sim(tx,vy),y∈[1,n]}。
Peng等人[1]对2017年之前跨模态检索的相关技术进行分类总结,并制定了基准,为该领域发展奠定了良好基础。为便于跨模态检索领域初学者能够了解到此领域最新研究进展,本文研究跨模态检索领域由始以来发展的基本路线和近期研究现状,主要贡献如下:
(1)分析了跨模态检索主流方法近几年的最新研究进展,探讨了跨模态检索现阶段存在的挑战。
(2)介绍具有代表性的跨模态方法,与其他研究综述不同,本文聚焦于以深度学习为研究背景的跨模态学习方法,并根据几种主流的深度学习技术进行简述。
(3)列举了每类方法中具有代表性的方法,并对其优势和局限性做出对比分析,并对各类跨模态检索方法做出评述和总结。
1 实值表示学习方法
实值表示学习方法是指对不同模态进行特征提取,并直接对跨模态特征进行学习。根据实值表示学习方法的不断演化发展,文中列举了具有代表性的实值表示学习方法[2-6],如表1所示。本章根据每种方法的技术特点,将实值表示学习方法大致分为两大类,并介绍一些早期经典方法以及近几年领域内研究的热点模型。
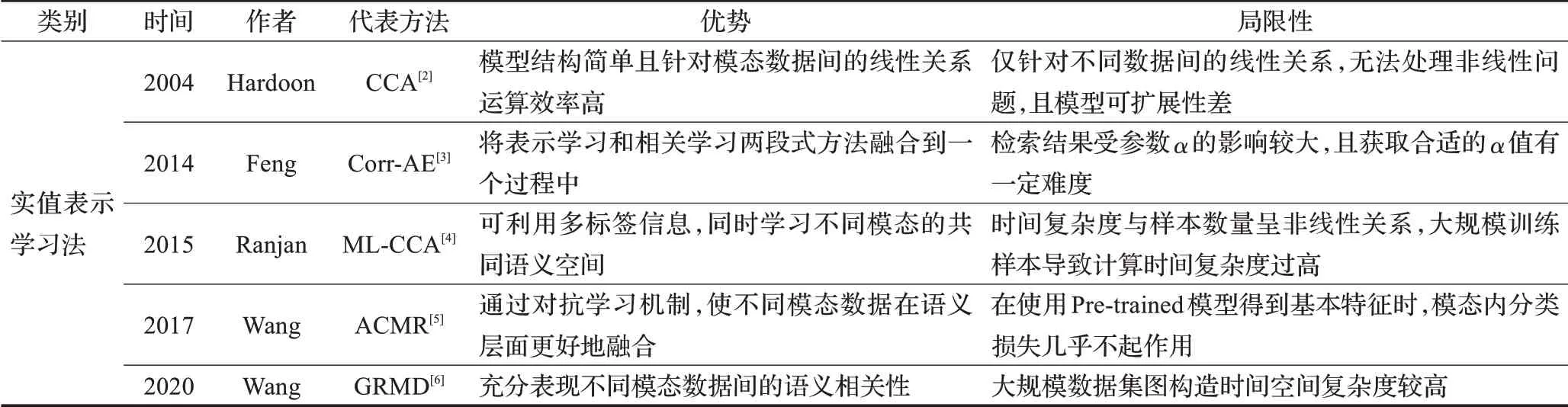
表1 代表性实值表示学习方法简要介绍Table 1 Brief introduction of representative real-valued representation learning methods
1.1 基于子空间学习的方法
基于子空间方法的跨模态检索越来越受到人们的关注,它通过学习变换矩阵,将异构数据映射到同一个语义空间,在同一个度量空间中比较不同的模态数据。子空间学习方法在跨模态检索任务中也表现出了其优异的检索性能。
1.1.1 传统统计相关学习法
典型相关性分析(canonical correlation analysis,CCA)能够将两个多维变量之间的线性关系进行关联的方法,从而使不同模态之间的线性关联最大化。1936年Hotelling[7]率先提出了CCA用于降低变量维度,并处理两变量之间的线性关系。假设两种不同模态特征矩阵X=[x1,x2,…,xn],Y=[y1,y2,…,yn],ωx、ωy是两投影向量,将特征矩阵转化为线性组合:

构建集合内协方差矩阵ΣXX、ΣYY和集合间协方差矩阵ΣXY:
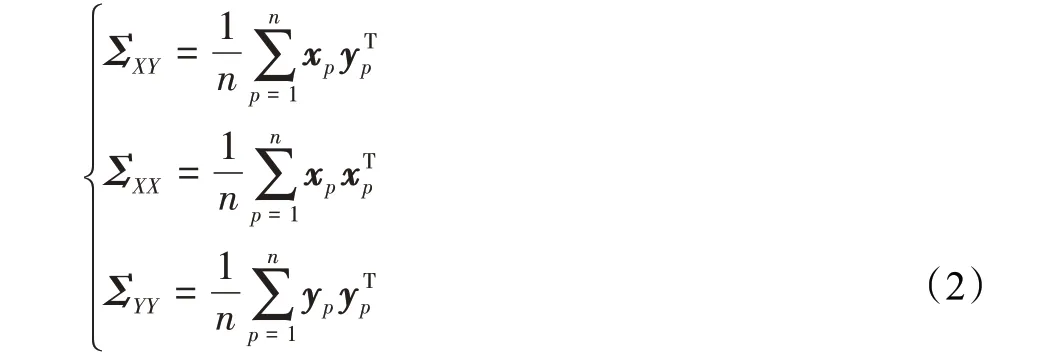
通过计算U和V两线性组合之间的相关系数ρ,体现两者间的相关性:
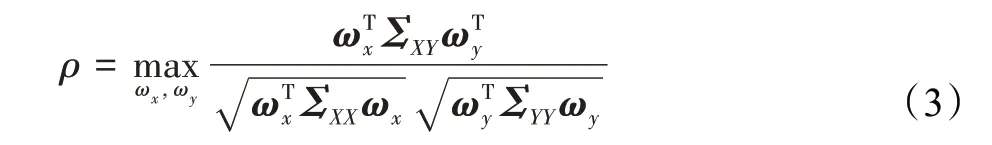
构建拉格朗日方程L,以ωTxΣXXωx=1,ωTyΣYYωy=1为约束条件,找到最佳投影向量ωx、ωy最大化线性组合U和V之间的相关性:
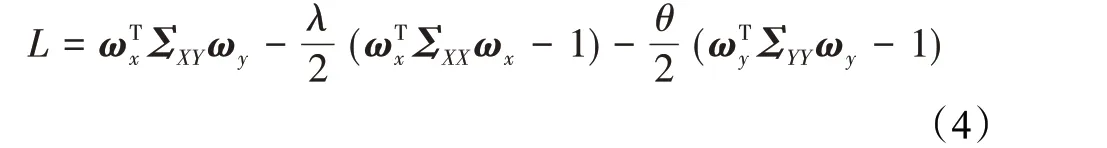
设λ和θ为系数变量,找到其特征值最大的特征向量:

其主要任务是将不同多维数据经线性变换投影为一维数据,其投影的主要标准是使得两组数据的相关系数最大化,由此便可得出两种不同模态数据间特征的最大相似性。但传统CCA方法具有一定局限性:
(1)仅对两个及两个以下的视图有效。
(2)仅能计算两视图间的线性相关性,不能解决实际应用中的非线性问题。
(3)传统CCA是一种无监督算法,在处理有监督分类问题时,无法利用标签信息。
为解决上述传统CCA的缺陷,研究者在传统CCA的基础上进行了一系列相关研究:Hardoon等人[2]提出一种核典型相关性分析的方法(kernel canonical corre‐lation analysis,KCCA)改善了传统CCA无法检测非线性关系的缺点,并有效利用两组多维数据间的非线性关系,降低数据维度,随着技术发展需求,Hwang等人[8]将其用于跨模态检索任务中,但很多KCCA方法在高维特征空间产生过拟合现象,且难以处理大规模数据。为解决上述过拟合问题,提高CCA的稳定性,Cai等人[9]提出一种鲁棒性核CCA算法(KCCA-ROB)。
传统CCA两视图已满足不了检索对数据语义的多角度需求,为此,Gong等人[10]在两视图基础上结合第三个视图,用于捕捉高层图像语义,Shao等人[11]改进CCA算法(ICCA),将传统CCA的两视图扩展到了四视图,学习模态内语义一致性,并将四视图CCA嵌入到渐进式框架,来缓解过度拟合问题。除以上以CCA为基础进行优化的方法外,Pereira等人[12]还对CCA做出变形,提出无监督相关匹配(CM),有监督语义匹配(SM),以及两者结合的语义相关匹配(SCM),将多类逻辑回归应用于CCA获得的最大相关特征表示。
随着深度学习(deep learning,DL)的不断发展,深度典型相关性分析(deep-CCA,DCCA)[13]应运而生,DCCA不仅解决了非线性的问题,而且还解决了KCCA核函数选取不可知性和可扩展性问题。相对于KCCA模型来说,DCCA模型结构更为简洁,提高了跨模态检索性能,两视图DCCA结构图如图1所示。以此为基础,Zeng等人[14]采用有监督的方式,构建基于DCCA的跨模态检索方法,其注意力主要集中于利用标签信息来克服不同模态信息之间的异构鸿沟。受SCM的启发,Wei等人[15]提出Deep-SM来解决带有标签的样本的图像和文本之间的跨模式检索问题。
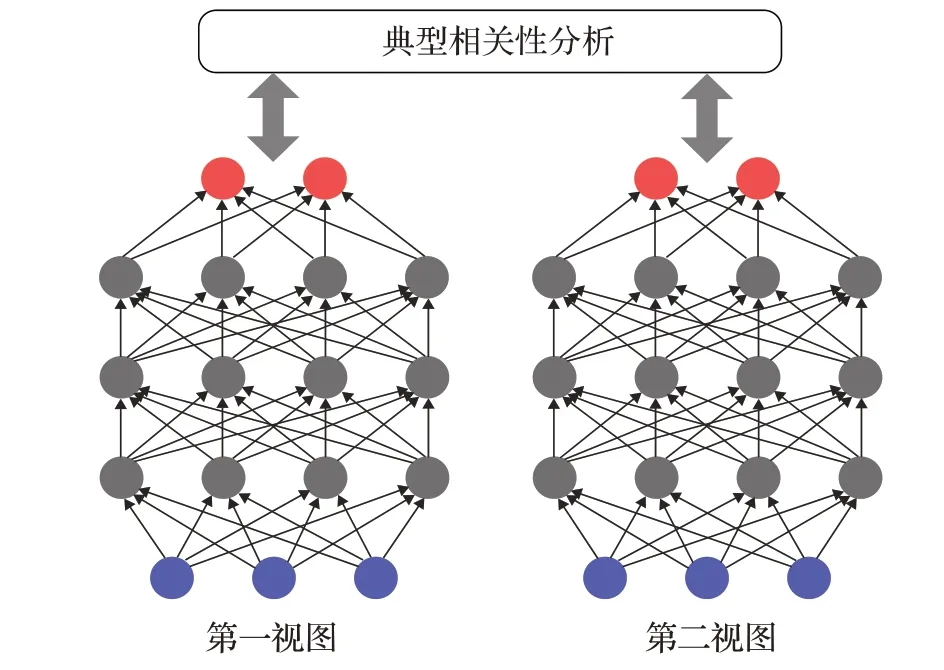
图1 DCCA示意图Fig.1 Schematic of DCCA
此外,将跨模态自编码器与DCCA相结合构造出的拓展DCCA模型[16]将对应模态缺失特征进行重构,极大地确保了两模态之间特征的最大相关性。在此之后,Zeng等人[17]又提出一种用于音频-视频检索,基于聚类CCA的端到端有监督学习网络结构(TNN-C-CCA)。除上述方法,Shu等人[18]对ML-CCA[4]做出了进一步改进,提出SML-CCA,不仅能够像ML-CCA一样同时学习两种模态数据的共同语义空间,而且很好地解决了MLCCA只关注语义相关性,忽略特征相关性的问题。在上述方法中,经过研究者的改进一定程度上弥补了CCA的缺点,证明了语义信息对提高跨模态检索精准度的有效性。
1.1.2 基于图正则化的方法
跨模态检索任务在执行过程中通常存在两个根本问题:相关性度量和耦合特征选择。在大部分跨模态工作研究中,研究者只针对模态间数据的相似性度量提出一些解决方案,通过学习投影矩阵的方式将不同模态数据投影到同一个子空间中,进而测量不同模态间的相似性。随着研究推进,Wang等人[19]解决了耦合特征选择问题,同时从不同的特征空间中选择合适且识别度高的特征。此外,对投影数据加入多模态图正则化项能够保持模态内和模态间的相关性。
图正则化在半监督学习中得到广泛应用[20],图中边的权值代表跨模态数据的关联度,通过权值来预测未标记数据的语义。为将语义信息和模态间相关系数进行统一优化,Zhai等人[21]提出联合表示学习算法(joint representation learning,JRL),首次将不同模态的稀疏矩阵和图正则化集成到统一优化问题中,在JRL的基础之上,JGRHML[22]将不同模态结构整合到联合图正则化中,利用不同模态之间的互补关系,学习更好的特征表示,使得两种模态之间的解平滑度更高。在跨模态检索任务中,若两个不同任务(如I-T,T-I)学习同一投影矩阵,会导致两任务性能趋向均衡,单一任务上不能表现出最佳性能,为使检索性能最优化,Wang等人[6]提出一种基于图正则化的方法GRMD,该方法针对不同任务学习两对投影,并保护模态内和模态间的特征相关性和语义相关性。图正则化方法能够有效在同一框架中对跨模态数据建模,且展示不同模态间的语义相关性,不足的是,在大规模数据集上,由于样本容量庞大,类别繁多,因此跨模态图的复杂度较高,构造难度较大。GRMD框架图如图2所示。
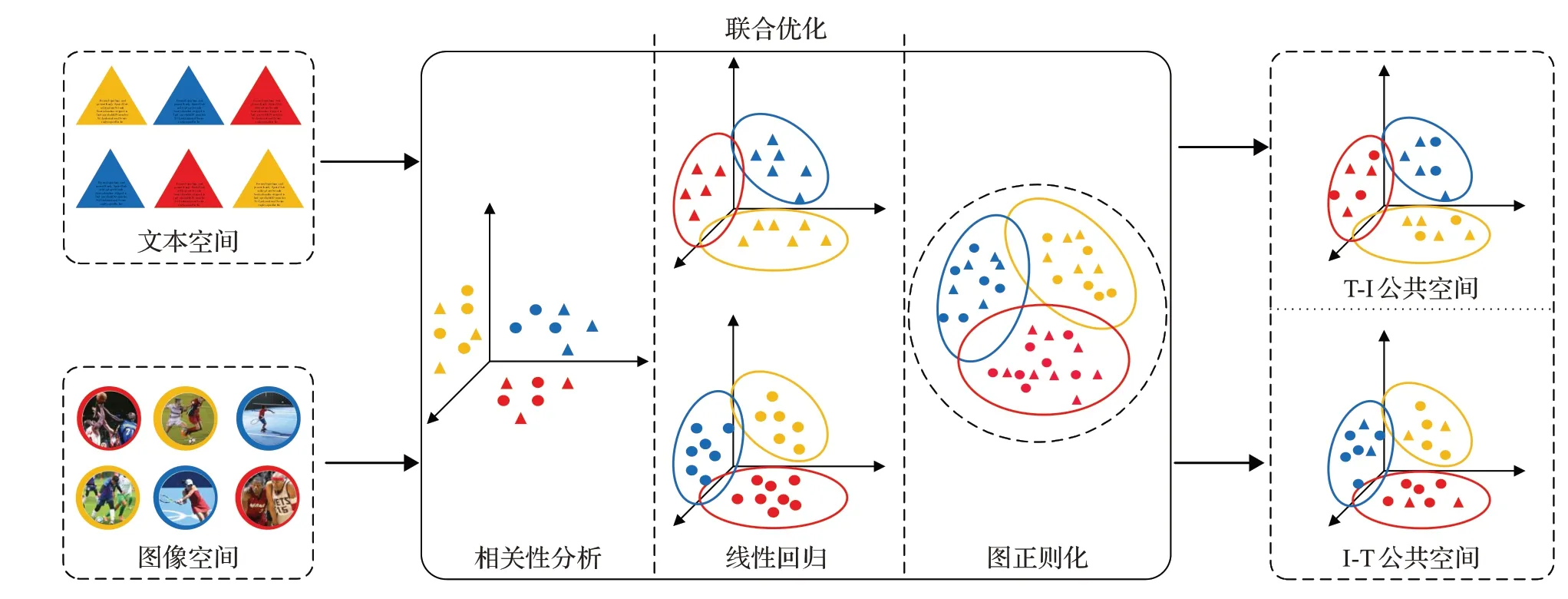
图2 GRMD框架结构图Fig.2 Flowchart of GRMD method
基于子空间学习的方法在跨模态信息检索中起着至关重要的作用,其为解决跨模态数据间的异构性有着非常显著的效果,另外,根据不同模态数据间的相关性,子空间学习能够捕捉到两模态之间的互补信息,并利用先验知识,挖掘多模态数据中的高层语义。
1.2 基于机器学习和深度学习的方法
1.2.1 基于特征表示的方法
基于特征表示的方法一般通过两种方式来提取更适合模型学习的数据特征,第一种是对特定场景选取相应网络结构来提取对模型学习影响较大的特征,另一种方法则是统揽全局特征,对经典神经网络做出改进调整。由于该类方法尤其对大规模、多标签数据集有良好的适应性,可为未来跨模态检索提供更有效的设计思路。
神经网络提取特征对模型学习效率和学习质量有着很大的影响,以针对不同场景或不同实体选用特定网络,能够使得特征提取更加高效,更具代表性。为此,Li等人[23]提出了DMASA,采用多种自注意机制从不同角度提取图像和文本的细粒度特征。然后,将粗粒度和细粒度特征集成到多模态嵌入空间中,在该空间中可以直接比较图像和文本之间的相似度。但自注意力机制在编码时会过度将注意力集中于自身的位置,为解决此问题,Jin等人[24]采用粗细粒度并行注意机制来处理多模式视频的全局和局部特征。因此,增强了相同模式视频特征中特征点之间的关联度,将多头注意力机制集成到粗细粒度并行注意力中,增强了模型对特征的接受程度,并从多个角度处理相同的视频模态特征。Ji等人[25]提出可解释的双路径图推理网络,该网络通过利用视觉元素和语言元素之间的细粒度语义相关性来生成关系增强的视觉和文本表示。为获取文本中的有效特征,Xie等人[26]提出SEJE,用于学习跨模态联合嵌入的两阶段深度特征提取框架,利用LSTM来识别关键术语。与前者类似,Zhao等人[27]设计了一个语义特征提取框架,为相似度度量提供丰富的语义特征并创建多个注意力图以从不同角度关注局部特征并获得大量语义特征,与其他积累多个语义表示进行均值处理不同,使用带有遗忘门的LSTM来消除重复信息的冗余。
另外,编码器在特征提取方面也做出重大贡献,Gao等人[28]提出图像编码器、文本编码器和多模式编码器,用于提取文本特征和图像特征。与单模态编码器相比,该编码器学习公共低维空间来嵌入图像和文本,从而使图像-文本匹配对象能够挖掘出丰富的特征信息。
1.2.2 基于图文匹配的方法
基于图文匹配的方法更关注于不同模态间的结构关联,此类方法通过研究图像和文本模态间的语义对应关系来增强模态间特征表示的一致性。图文匹配又可分为图像文本对齐,跨模态重构以及图文联合嵌入,下面将按照以上三类对基于图文匹配方法进行介绍。
跨模态重构是指以一种模态数据通过神经网络生成另一种模态结构的数据,跨模态重构能够保留重建模态信息,减少模态特征异质性,并增强语义辨识能力。Feng等人[3]提出一种跨模态学习模型(Corr-AE),通过多模态重构和单模态重构两组模型,将相关学习与表示学习作为一个整体来考虑,以最小化表示学习误差,并将输入模态进行重构。但在此模型中,高层语义信息被忽略掉,这使得该模型在检索精度上会受到一定的影响。Xu等人[29]提出AAEGAN通过相互重建每个模态数据,以类嵌入作为重建过程中的辅助信息,使跨模态分布差异最小化。为使生成模态更加具有模态间语义一致性,Wu等人[30]提出AACR,通过增强对抗训练将一种源模态转换为另一种目标模态,从而将来自不同模态的数据对齐。
一部分研究者通过实现图像中实体与文本片段对齐来增强模态间语义一致性,Guo等人[31]提出使用图卷积神经网络编码以学习视觉关系特征,然后,在关系特征的监督下,使视觉与文本特征对齐。但面对多元场景中各种实体间的复杂关系,难以准确捕捉其中的对应关系,Chen等人[32]提出了一种迭代匹配与重复注意记忆(IMRAM)方法,该方法关注多模态数据的细粒度信息,通过多步对齐来获取图像和文本之间的对应关系。Cheng等人[33]提出双向聚焦语义对齐注意网络(BF‐SAAN),采用双向聚焦注意机制共享模态语义信息,进一步消除无关语义信息的负面影响,探索二阶协方差池以获得多模态语义表示,从而捕获模态通道语义信息,实现图像文本模态之间的语义对齐。
还有研究者认为,仅通过局部对齐难以使模型掌握数据整体关系,关注全局信息产生的特征辨识度不强,采用联合嵌入的方式才能有效减小“语义鸿沟”。因此,Wang等人[5]采用对抗机制,提出对抗式跨模态检索(adversarial cross-modal retrieval,ACMR),有监督地对抗跨模态检索特征空间内容更加丰富,以分类方式区分不同的模态,其利用特征投影产生模态不变性以及区分性表示,通过对抗性训练学习特征以混淆模态分类器,并引入三重约束机制,来保证公共子空间中的模态语义结构,其结构如图3所示。与对抗网络形成区分性表示不同,为学习不同模态的通用表示,Tian等人[34]提出MMCA-CMR,多模态数据嵌入到公共表示空间中,模型借助自编码器学习来自不同模式和内容信息的特征向量,有助于在跨模式检索中弥合多模式数据之间的异构鸿沟。He等人[35]提出CAAL,通过并行编码器分别生成图像和文本特征的通用表示,并由两个并行GANs生成虚假特征来训练鉴别器,弥合不同模态间差异。
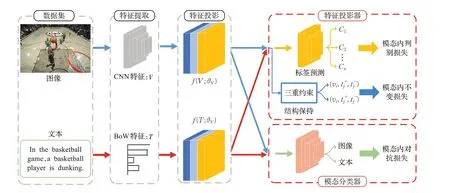
图3 ACMR基本框架图Fig.3 Flowchart of ACMR method
2 二进制表示学习方法
在海量多媒体数据中查找用户想要的信息难度越来越大,这不仅给跨模态检索任务精度提出了更高要求,同时检索效率也迎来很大的挑战。由于存储成本低,查询效率高,近年来,哈希技术在海量信息处理以及多模态信息检索上起到了重大的作用,在2010年,随着Bronstein等人[36]首次将哈希技术用于跨模态数据相似性研究中,跨模态哈希(cross-modal hashing,CMH)逐渐表现出其优势。首先要将多维特征向量X∈Rd×n转化成相应k位哈希码z={z1,z2,…,zk},由对应哈希函数获得:
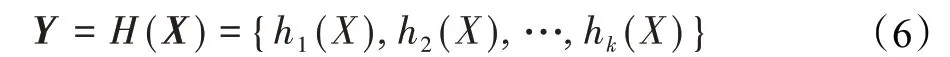
常用的哈希函数是线性哈希函数:

当z≥0时,sgn(z)=1,反之,sgn(z)=-1,w是投影向量,b是偏置变量,另外核哈希函数也是常用的:
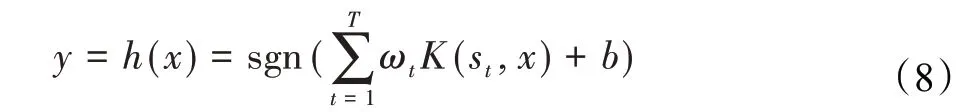
{st}是随机抽取的经典样本,{ωt}代表权重值。另外,还有基于最邻近向量分配的函数:
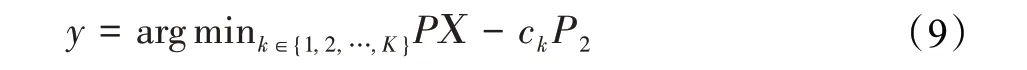
在汉明空间中,通常用汉明距离dhij来描述哈希码yi和yj之间的距离,汉明距离就是两哈希码之间对应不同的位数:

两哈希码之间的内积shij=yiTyj也可作为相似性衡量标准,在实际检索过程中,往往通过距离查找表来计算哈希码之间的距离,来推断跨模态数据间的相关程度。而在跨模态检索过程中,仅使用数据的单一特征作为学习内容已不足以满足跨模态数据之间的对比选择,Kumar等人[37]提出跨视图哈希(cross view hashing,CVH),这也为至今的基于哈希的跨模态检索研究奠定了良好的基础。
根据学习过程中对样本标签的使用情况,跨模态哈希大致可分为有监督哈希和无监督哈希,而有监督方法中还涉及半监督学习方法。通常来讲,使用标签信息训练模型会使得检索精准度更高,但随DL等技术的衍化发展,有些无监督的方法也可能取得令人满意的实验结果。下面对跨模态哈希检索最近几年的相关研究进展做出介绍,并选取近年来比较具有代表性的几种跨模态哈希方法[38-42]进行简要介绍,如表2所示。

表2 代表性二值表示学习方法简要介绍Table 2 Brief introduction of representative binary representation learning methods
2.1 有监督哈希方法
有监督哈希的主要任务是学习两个模态的哈希函数:f(x):→{-1,1}c,g(y):→{-1,1}c,Zhang等人[43]提出一种典型有监督跨模态哈希方法最大化语义相关性(semantic correlation maximization,SCM),巧妙地将标签信息添加到哈希学习过程中,并且利用监督信息学得相似矩阵,通过顺序计算方式求解哈希函数。SCM在不同模态的训练复杂度分别是O(cdy),O(cdx),c表示二进制哈希码的长度,dx,dy分别表示每个模态的特征维度,尽管相比其他方法其训练复杂度在一定程度上存在优势,但其并不适用于现有深度哈希高维度特征数据集。
Liong等人[41]提出跨模态离散哈希方法(CMDH),由两个步骤对跨模态哈希码学习过程进行离散优化,在初步学习中学得不同模态特定的哈希函数,然后根据语义相似性,学习构建统一的二进制码集,因二进制码集在不同模态中是共享的,故有效减少了模态间的差异性。与CMDH相同,由语义增强符和快速离散优化模块组成的NSDH[44]同样不采用任何松弛的离散约束,有效避免了累积误差,学习到高效的哈希码,此外,NSDH可以直接学习哈希码,相比SCM中的逐位优化,更加节省时间,符合现阶段大规模跨模态数据检索的实际应用要求。
Jiang等人[45]提出了一种新颖的离散潜在因子模型(DLFH)来学习二进制哈希码且无需连续松弛,试图在保持成对相似性情况下最大化跨模态数据的可能性,并使用逐列学习策略解决离散约束优化,将相似度信息有效地保存到二进制码中。以此为基础,Zhan等人[42]提出离散在线哈希方法(discrete online cross-modal hashing,DOCH),将有监督的标签信息嵌入到待学习的哈希码中,以便于二进制码进行分类,进一步学习统一哈希码,构建新的计算复杂度与新数据规模成线性关系,解决了DLFH扩展存在局限性的问题。
尽管传统有监督哈希方法利用标签信息,取得一系列显著成果,但深度神经网络(deep neural networks,DNN)在非线性表示学习取得优异的成绩,于是Jiang等人[39]将DNN引入CMH,提出端到端的深度学习框架DCMH使用负对数似然损失来保持跨模态相似性,来弥补传统方法的不足。Li等人[40]提出SSAH首次引用对抗学习处理跨模态哈希问题,为更好地弥合模态间的异质鸿沟,设计了LabNet用于逐层提取多标签向量的语义特征,进而监督ImgNet和TxtNet中的特征学习,即将三元组(vi,ti,li)中li作为vi、ti的自监督语义信息,从而构建不同模态之间的语义关联,一致化不同模态特征分布。与之类似,DSSAH[46]同样利用了对抗学习,但作者并未对标签特征进行深度抽取,而是以对抗网络作为模态鉴别器,寻找公共特征空间,计算不同模态相似性。为有效利用多标签语义相关性,Zou等人[47]提出MLSPH以集成方式联合学习高级特征和哈希码,增强哈希码独特性。
由于DNN提取跨模态数据特征不能准确识别哪些特征对跨模态检索任务帮助较大,导致检索性能次优,为赋予跨模态特征对应权重,Peng等人[48]DSADH和Wang等人[49]提出SCAHN中引入注意力机制来高效地使用与检索任务相关的特征来引导哈希编码。与之类似,为提高检索性能,SDCH[50]、TA-ADCMH[51]对哈希码学习进行改进,前者采用多标签信息监督的方式生成有区别性的哈希码,后者通过非对称哈希学习,针对两个子任务学习不同的哈希码。
为应对样本标签数量有限问题,半监督哈希方法被引入跨模态检索任务中,半监督哈希基于非加权距离和简单的线性映射来处理数据之间的语义相似性和不相似性,其目标是最小化标记数据集的经验误差并提高编码性能,其中经典的半监督哈希方法如SSH[38],受信息论启发,该方法将成对监督与无监督学习目标相结合。近年来,基于图的半监督哈希方法取得重大进展,最近Shen等人提出了MGCH[52],在传统图哈希方法基础上采用多视图结构图作为唯一的学习辅助来连接标记和未标记的数据,对图特征进行精细化。
Zhang等人[53]利用生成对抗网络设计了一个半监督的跨模态哈希学习模型(SCH-GAN),该模型可以从大量未标记的数据中学习丰富的语义信息,并选择边界样本。随着研究的深入,新技术的更替迭代,以及规模更大的跨模态数据的出现,Wang等人[54-56]通过引入深度神经网络来提高半监督跨模态哈希的性能。
2.2 无监督哈希方法
尽管大多数现有的基于多媒体数据标签信息的方法已经取得了很好的效果,但由于标签数据通常耗费庞大的资源,尤其是在大规模多媒体数据集上,从标签数据中获益的性能成本很高,因此,无监督跨模态学习的出现,使得跨模态检索在实际应用中得到发展。无监督的跨模态哈希方法学习原始数据的低维嵌入,没有任何语义标签。由于缺少语义标签的介入,不同模态间的语义鸿沟问题难以解决,因此CMFH[57]采用集合矩阵分解,从同一实例的不同模态中学习统一的哈希码弥合语义鸿沟。但学习统一哈希码会给检索任务带来次优性能,因此Cheng等人[58]针对不同模态的检索任务学习特定的哈希码。Li等人[59]以知识蒸馏(knowledge distillation,KD)的方式,通过无监督教师模型重构相似度矩阵,进一步指导学生模型学习,从而生成更多区分性的哈希码,为进一步提高跨模态哈希的性能,Liu等人[60]将统一的哈希码和单独的哈希码组合,保留模态间共享属性和模态内专有属性。
为获取更加有效的哈希码,大多方法将模态内相似性和模态间相似性结合起来,以充分挖掘语义相关性,并在汉明空间中保持模态间表示一致性[61-62],Shi等人[63]提出一种视觉-文本关联图方法(visual-textful correlation graph hashing,OVCGH),在对象层面构建模态内部和不同模态之间的依赖关系,以捕获不同模式之间的相关语义信息。与现有方法主要关注保持相互约束的模态内和模态间相似关系不同,CMSSR[64]将不同模态的数据视为从不同视角对场景的描述,并相应地整合不同模态的信息,学习包含场景内相关跨模态信息的完整公共表示。
尽管二值表示学习方法在处理跨模态异构问题上表现出其优势,但在哈希码学习过程中造成的信息损失是不可避免的,因此优化哈希码学习过程,减少信息损失和是目前需要研究的必要内容。
表3给出了各类具有代表性的方法,对其优势和局限性进行分析及总结。

表3 跨模态检索方法简要评述及总结Table 3 Brief review and summary of cross modal retrieval methods
3 常用数据集及结果对比与分析
3.1 常用数据集及评价指标
随着互联网上各种模态数据的爆发式增长,在深度学习的不断发展中,对于各种模态数据的需求也多样化,为迎合各模型的预训练和测试需求,涌现出一大批容纳不同模态,不同类别的数据集,数据集对跨模态检索任务起着至关重要的作用,数据集中数据质量直接影响模型预训练的结果。在跨模态检索任务中,常用的几种数据集[65-70]如表4所示。

表4 跨模态检索常用数据集Table 4 Common datasets for cross modal retrieval
(1)ImageNet:其中包含12个类别分支,共320万张图片。目前ImageNet按照同义词集索引分为21 841个类别,图片总量超过1 400万张。另外,ImageNet数据集有很多子集,常被用于各种视觉任务,其中最常用的一个子数据集是ILSVRC2012。
(2)Wikipedia:该跨模态数据集中包含2 866个图像文本对,每幅图像都配有相应的文本描述,总共29个概念类别,其中10个为主要概念,官网提供128维的SIFT图像特征和10维的LDA文本特征。
(3)Pascal Sentence:数据集中容纳1 000幅图像,每幅图像配备5条描述语句,图像被分为20个类别,每个类别含有5幅图像,图像源自Pascal VOC 2008数据集,常被用于跨模态检索和图像标题生成等任务。
(4)NUS-WIDE:该数据集共计269 648幅图像和对应的文本描述,共81个概念类别。在具体使用过程中,通常会抽取其中一部分样本用于实验,常用的有NUSWIDE-10k、NUS-WIDE-21k两种,10 k表示抽取10个类别,每个类别1 000张图片和相应文本描述。
(5)MS-COCO:COCO数据集是跨模态学习中非常重要的数据集,数据库中图像素材来自于日常生活场景,总计91个类别,并且采用实例分割,在328 000幅图像中标记了2 500 000个实例。
(6)Flickr-25k:图像数据源于Flickr网站,并提取标签和EXIF(可交换图像文件格式)图像元数据。图像标签包括原始标签和处理后标签两种形式。在Flickr-25k中手动注释25 000幅图像。每幅图像平均有8.94个标签。有1 386个标签与至少20个图像关联。同样,Flick-30k则代表拥有30 000幅图像的数据集。
mAP值指平均精准度,衡量检索到的模态与查询模态类别是否一致,常用于评估跨模态检索算法性能。给出查询数据和n个检索结果,其检索精度可表示为:

P(i)表示前i个检索结果的精准度,若检索结果与查询项相关,则δ(i)=1,反之δ(i)=0,Q代表发起查询的数量,最终mAP值的公式如下:

R@k(Recall@k)常在MS-COCO和Flickr-30k等数据集中作为实值表示方法的评价指标,表示正确结果出现在前k个返回样例占总样例的比例。RELk代表Top-k结果中的相关项数,REL表示给定查询的相关项总数。这个指标回答了Top-k中是否找到了相关的结果,其计算公式如下:
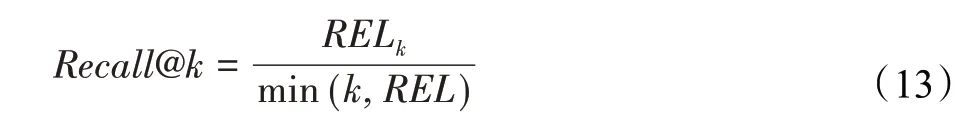
3.2 实验结果对比与分析
本章选取几种比较重要的实值表示学习方法分别在不同数据集上,以mAP值为评价指标用于性能对比,如表5所示,以R@k值为评价指标,如表6所示。
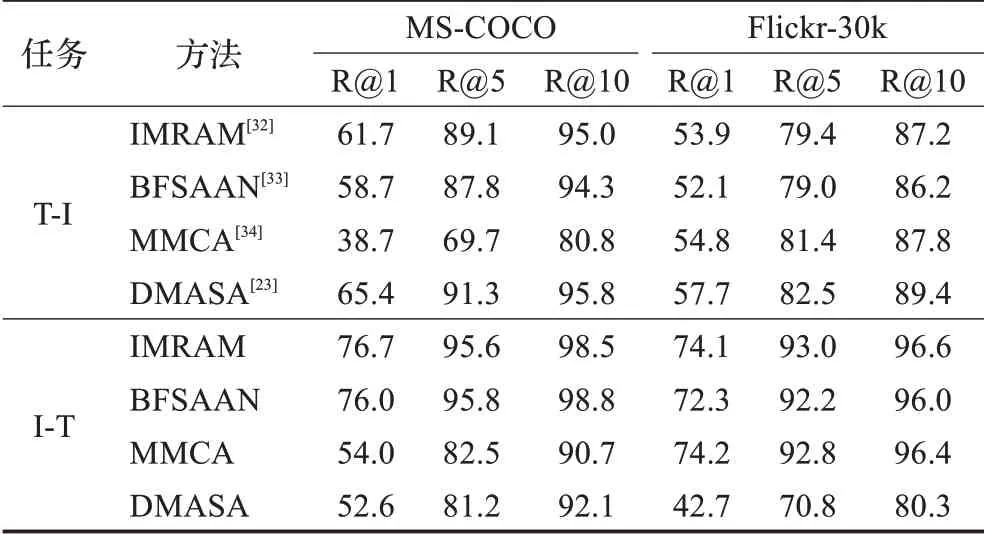
表6 实值表示学习方法R@k值比较Table 6 Performance comparison of real-valued techniques on basis of R@k scores单位:%
在表5中,ACMR等基于深度学习方法性能明显优于SCM等传统子空间学习方法,尽管SCM在原有CCA基础上进行了语义匹配,但GANs等深度神经网络给模型提供的模态内和模态间语义一致性表示是传统方法无法比拟的,其性能的提高取决于数据规模的大幅增加。而在子空间学习方法当中,JRL结合了稀疏和半监督正则化,以丰富训练集并使解平滑,较其他子空间学习方法在数据集上有着更好的表现。
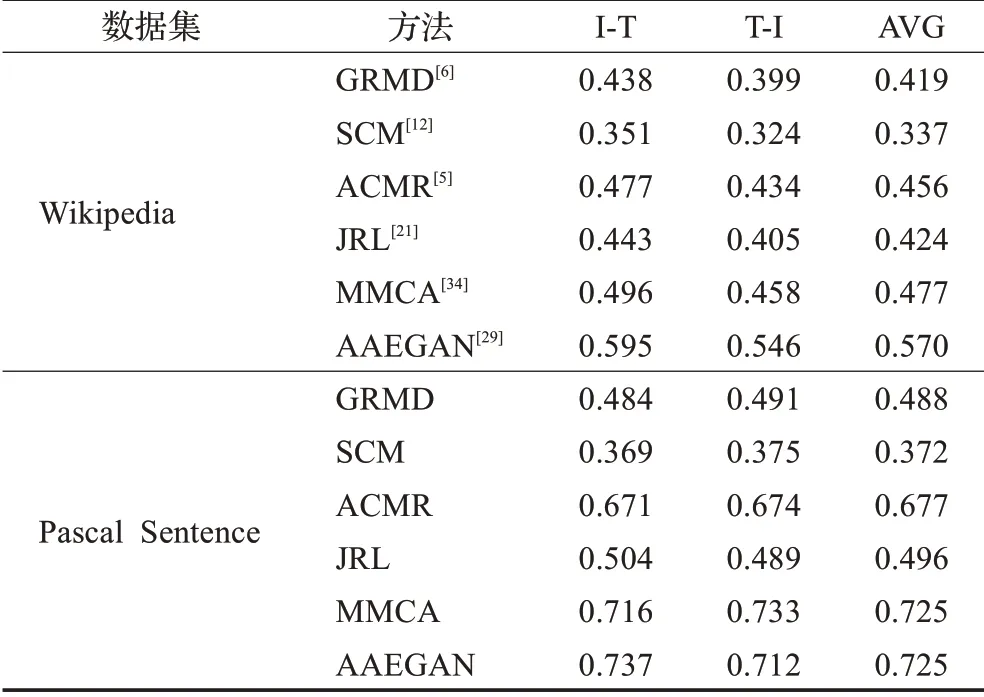
表5 两个数据集上几种重要实值表示方法的mAP值比较Table 5 Comparison of mAP scores for prominent real-valued techniques on two data sets
由表6可以看出,DMASA在以文搜图的任务中取得更优R@k值,分别从MS-COCO和Flicker数据集选取10 000和1 000张图像,验证测试比为1∶1,设置3个自注意力角度。由于多角度的自注意力机制,相比其他方法能够获取更加全面的图像信息,因此在图像检索中效果极佳,但其文本特征提取网络并未得到更加有效的优化,因此在文本检索任务中其性能较差。IBRAM在两数据集中都有不错的性能表现,可以验证该方法面对各种规模数据的鲁棒性,在双向检索任务中,其性能指标也都位于前列,且较为均衡,因此可看出注意力机制等深度神经网络和模态间细粒度信息的匹配对跨模态检索模型性能提升起着重要作用,为下一步研究提供了重要思路。
从表7中哈希方法实验结果可以看出,DGCPN等无监督方法更适合于小规模数据分布的检索任务;在Flicker-25k中,图像的标签信息更加丰富,监督方法充分利用了标签信息通常可以获得更好的检索性能。此外,DCMH等引入深度神经网络的有监督哈希方法在特征提取和哈希学习方面更具优势,因此相比传统哈希方法在各数据集上有着更好的性能表现。由于SCH-GAN等半监督方法充分利用未标记数据进行哈希码学习,在Flicker-25k数据集缺少标签信息的情况下表现良好。由此可见DNN对哈希码学习和特征提取的重要性以及引入DNN来提高CMH性能的必要性。
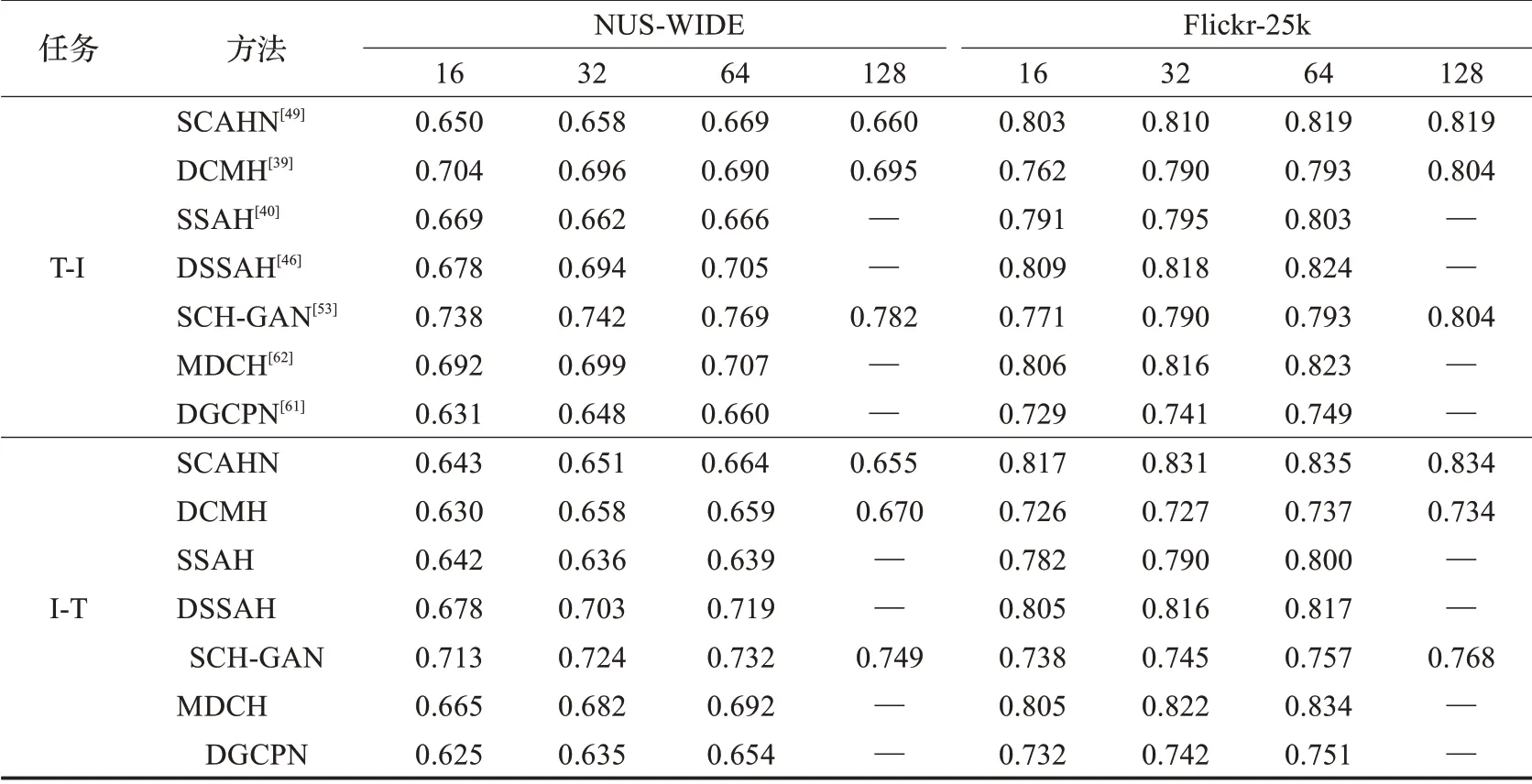
表7 NUS-WIDE和Flickr-25k数据集上几种重要二值表示方法的mAP值比较Table 7 Performance comparison of prominent hashing learning methods on basis of mAP score
4 跨模态检索未来展望
从传统方法到深度学习方法,跨模态检索的性能依靠各种深度神经网络一直在不断提高,但这并不能满足现实生活中对跨模态信息检索的需求,为提高跨模态检索性能与实际应用价值,还需做出以下思考。
4.1 跨模态检索方法改进
近年提出的跨模态检索算法,大多以复杂的组合结构形成检索框架,如嵌入GANs、注意力机制(attention mechanism)等[71-72],虽检索精度上得到提升,但其复杂计算过程,在实际检索任务中面对大规模的跨模态数据会有一定的检索时延且检索效率较低。为使模型能够嵌入到移动设备当中,可采用知识蒸馏的手段,将精细化大模型学习到的知识转移给简化的小模型,既不损失原有参数信息,又做到了模型轻量化。
为确保检索框架学习到有效的哈希码,后续研究工作中,可嵌入情感融合、场景分析和上下文语义分析,以及获取跨模态信息中更高层的语义,采用强监督学习或弱监督学习关注细粒度特征,并根据注意力机制的选择性,选取有效特征,既避免了特征信息冗余导致时间复杂度变高,又使哈希码变得更加有效。
4.2 图神经网络的应用
多模态数据图的拓扑结构非常复杂,况且图结构中各节点是无序的,图中包含多模态数据的特征信息,面对这种非结构化数据,现有很多哈希方法是基于图的,传统的神经网络无法对其进行建模,图神经网络(graph neural networks,GNN)[73]可有效地计算各节点之间的关联度,在跨模态检索任务中,GNN能够计算DNN无法处理的复杂数据网络。
在GNN中,节点之间的边代表着独立信息,可以通过图结构来进行传播,而不是将其看作是特征;通常而言,GNN更新隐藏节点的状态,是通过近邻节点的权值和,传播步骤使用的方法通常是不同的聚合函数(在每个节点的邻居收集信息)和特定的更新函数(更新节点隐藏状态)。一个节点或边的信息不仅限于其本身,还要看它相邻元素的加权求和来决定,通过池化(pooling)来进行层内聚合,层内信息传递,层间通过邻域聚合来进行层级间信息传递。因此在图中的各个节点,除自身特征信息外,还包含与之相关联的同一层或更深层节点信息,甚至全局信息,因此图全局节点之间的关联度变得更强,更容易计算获得。
4.3 构建面向实际应用的数据集
数据集中的各种多模态数据都被赋予标签和相应的文本描述,如MS-COCO等大型数据集都有着丰富的数据类别。但在实际检索任务中,现有数据库中的样本种类丰富度较日常生活所见还有很大差距,很难达到令人满意的模型训练效果。因此,构建面向专属任务的数据集,或者将原有数据集样本类别进一步扩充,并赋予数据更加丰富的标签和文本描述,给跨模态检索任务的实际应用提供有利条件。
4.4 提高模型可扩展性
现有跨模态检索方法大多针对一对一检索,而在实际检索过程中,某一检索对象可能有多个与之匹配的跨模态结果,为更贴合实际应用,多对多的大规模跨模态检索框架应是未来研究的方向。对预训练模型进行局部调整,使跨模态检索模型适应任务多样化,且能接纳不同数据类型的数据库,提高模型可扩展性,缩短模型训练时间,提高研究效率。
5 结束语
概述了跨模态检索近年来的研究进展,介绍了相关数据集,另外还选取几种比较具有代表性的方法在不同数据集上进行性能对比分析。尽管近年跨模态检索领域迎来蓬勃发展,但不同模态间存在的语义鸿沟问题尚未解决以及数据集的不完备,目前跨模态检索还面临着很大的挑战。如何有效达成模态间语义一致性,怎样构建更加全面的数据集且更加广泛的应用在实际场景中仍然是未来研究中需要长期追求的目标。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
开放教育研究(2020年2期)2020-03-31
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
专利代理(2017年1期)2017-07-21
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
