联合语义分割与边缘重建的深度学习图像修复
2022-12-21 03:23杨红菊李丽琴王鼎
中国图象图形学报 2022年12期
杨红菊,李丽琴,王鼎
1. 山西大学计算机与信息技术学院,太原 030006; 2. 山西大学计算智能与中文信息处理教育部重点实验室,太原 030006
0 引 言
近年来,图像修复已成为计算机视觉中的一项重要任务,在图像编辑、文物保护和老照片修复(Zhang和Chang,2021;Wan等,2020)等工作中有着广泛应用。成功修复的图像在缺失区域应该与其他区域表现出结构和纹理的一致性,然而当缺失区域较大时,现有方法通常难以产生看起来自然且与其他区域一致的图像结构(强振平 等,2019;Elharrouss等,2020)。
图像修复方法可分为传统方法和深度学习方法两类。传统方法使用低级特征修复图像,包括基于扩散和基于补丁的技术。基于扩散的方法通过求解偏微分方程,将梯度等关键信息从已知区域传播到未知区域(Ballester等,2001;Bertalmio等,2000;张桂梅和李艳兵,2019);基于补丁的方法从邻域中搜索相似的补丁,然后将这些补丁复制到缺失区域并融合(Kwatra等,2005)。基于补丁的方法在计算补丁之间的相似度时通常消耗大量计算资源,因此,Barnes等人(2009)提出一种快速最近邻搜索算法PatchMatch,以降低计算成本。传统方法虽然可以生成逼真的纹理,但由于无法理解图像的高级语义,面对复杂修复任务时,往往不能产生合理的结果。基于深度学习的图像修复方法可以从大量数据中学习到图像的高级语义信息,这是传统修复方法难以做到的。Pathak等人(2016)首次将生成式对抗网络(generative adversarial network, GAN)(Goodfellow等,2014)应用于图像修复任务,使用一个编解码器网络作为生成器,从原始图像中提取特征填充缺失区域。该方法能够利用高级语义信息产生有意义的结构与内容,但是修复结果包含视觉伪影。Iizuka等人(2017)提出使用联合的全局和局部鉴别器提高图像修复结果的一致性,通过添加膨胀卷积层增加感受野,并使用泊松融合细化图像,从而产生更清晰的结果。然而,这种方法严重依赖后期的泊松融合,且训练比较耗时。Liu等人(2018)和Yu等人(2019)设计了特殊的卷积层,使网络能够修复不规则掩膜遮挡的图像。Wadhwa等人(2021)将超图卷积引入空间特征,学习数据之间的复杂关系。包括上述方法在内的很多基于端到端的深度学习图像修复方法直接预测完整的图像,在面对复杂的结构缺失时,由于缺乏足够的约束信息,往往会产生边界模糊和结构扭曲的图像,无法获得令人满意的修复结果。
图像边缘包含丰富的结构信息。对此,人们提出了多种利用边缘信息改善图像修复质量的方法。Nazeri等人(2019)提出以边缘预测信息为先验,指导生成最终的图像。Li等人(2019)提出通过渐进方式不断修复缺失区域的边缘信息,提高边缘预测的准确性。然而,边缘结构丢失了大量的区域信息,且边缘与语义结构之间不明确的从属关系往往导致生成错误的边缘结构,从而误导图像的最终修复。
针对这个问题,本文提出利用语义分割信息指导边缘重建,从而减少边缘重建错误,并利用语义分割结构与边缘结构联合指导图像纹理细节的修复,进一步提高图像修复质量。具体地,将图像修复分解为语义分割重建、边缘重建和内容补全3个阶段,这与绘画时先绘制轮廓,然后绘制更细致的边缘,最后补全纹理和色彩的思路是一致的。在CelebAMask-HQ(celebfaces attributes mask high quality)(Liu等,2015)和Cityscapes数据集(Cordts等,2016)上将本文方法与其他先进方法进行对比实验,结果表明,当修复任务涉及复杂的结构缺失时,本文方法具有更高的修复质量。
1 模 型
图像修复是指输入受损图像Iin,其受损区域表示为二值掩膜M(1表示缺失区域,0表示非缺失区域),目的是预测完整的图像Ip,使其与真实图像Igt尽可能相似。本文设计了一个3阶段生成对抗网络来实现受损图像的修复,模型整体框架如图1所示。模型包含语义分割重建模块、边缘重建模块和内容补全模块,每个模块都由一对生成器和鉴别器组成,其中GS、GE和GI分别为3个模块的生成器,DS、DE和DI分别为3个模块的鉴别器。首先,语义分割重建模块预测受损图像的完整语义分割结构。然后,边缘重建模块在重建的语义分割结构指导下,预测受损图像的完整边缘结构。最后,前两阶段重建的语义分割结构和边缘结构联合指导内容补全模块,修复缺失区域的纹理与色彩。
1.1 语义分割重建模块
语义分割可以使图像简化,其结果能够很好地表示图像全局语义结构。现有的很多基于深度生成模型的修复方法由于没有利用语义分割结构来约束对象形状,通常导致边界上的模糊结果。语义分割重建模块通过重建缺失区域的语义分割信息来指导后续的图像修复,有助于语义不同的区域之间生成更清晰的恢复边界。
图2为语义分割重建模块的网络结构图,边缘重建模块和内容补全模块的网络结构与之类似。如图2所示,语义分割重建模块的网络结构基于生成式对抗网络,包括生成器和鉴别器两部分。其中生成器网络使用编解码器结构,从左到右依次为两次下采样的编码器、8个残差块(He等,2016)和将图像上采样回原始大小的解码器。在残差层中,使用膨胀系数为2的膨胀卷积代替普通卷积,从而在最终残差块处产生205×205像素的感受野。鉴别器网络使用70×70像素的PatchGAN(patch generative adversarial networks)结构(Isola等,2017;Zhu等,2017),它决定了70×70像素的重叠图像补丁是否真实。谱归一化(Miyato等,2018)通过将权重矩阵按其最大奇异值进行缩放来进一步稳定训练,有效地将网络的Lipschitz常数限制为1。虽然谱归一化最初提出时仅用于鉴别器,但Odena等人(2018)的研究表明,生成器也可以通过抑制参数和梯度值的突然变化从谱归一化中获益,因此本文将谱归一化应用于生成器和鉴别器。

图2 语义分割重建模块的网络结构图Fig.2 Network structure diagram of the semantic segmentation reconstruction module
真实图像Igt对应语义分割结构为Sgt,语义分割生成器GS输入受损图像Iin=Igt⊙(1-M)、受损图像的语义分割结构Sin=Sgt⊙(1-M)和不规则掩膜M,输出预测语义分割结构Sp,⊙表示哈达玛乘积。生成器GS的预测过程具体为
Sp=GS(Iin,Sin,M)
(1)

(2)


(3)

(4)
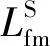
1.2 边缘重建模块
边缘是图像发生变化最显著的部分,边缘两侧灰度、亮度、颜色和纹理等特征会发生突变,因此边缘包含丰富的结构信息。正确的边缘结构可以有效指导图像修复,然而现有模型直接预测缺失区域的边缘信息,往往会生成错误的边缘结构,最终误导图像修复。边缘重建模块通过引入语义分割结构来指导边缘结构重建,可以提高边缘重建的准确性。
真实图像Igt对应边缘结构为Egt,边缘生成器GE输入受损图像Iin、第1阶段预测的语义分割结构Sp、受损图像的边缘结构Ein=Egt⊙(1-M)和不规则掩膜M,输出预测边缘结构Ep。生成器GE的预测过程为
Ep=GE(Iin,Sp,Ein,M)
(5)
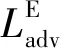
(6)


(7)
(8)
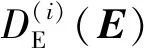
1.3 内容补全模块
前两个阶段重建的语义分割结构和边缘结构作为全局结构信息,可以有效指导图像缺失区域的补全。结构与内容分阶段修复,使内容补全模块只需要专注颜色纹理等细节信息的补全。
生成器GI输入受损图像Iin、预测的语义分割结构Sp和边缘结构Ep以及不规则掩膜M,输出预测图像Ip。生成器GI预测过程可以表示为
Ip=GI(Iin,Sp,Ep,M)
(9)
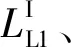
(10)

重建损失表示为
(11)
生成对抗损失表示为

(12)
感知损失通过定义预先训练的网络特征图之间的距离度量,对感觉上与标签不相似的结果进行惩罚。感知损失定义为
(13)
式中,Φi(I)表示图像I在预训练网络第i层的输出特征图,在本文中对应于在ImageNet数据集(Russakovsky等,2015)上预训练的VGG-19网络relu1_1、relu2_1、relu3_1、relu4_1和relu5_1层的输出特征图。这些特征图也用于计算风格损失,风格损失测量特征图协方差之间的差异。给定大小为Cj×Hj×Wj的特征图,风格损失定义为
(14)

2 实 验
2.1 数据与预处理
实验采用的图像数据集为带语义分割标签的CelebAMask-HQ和Cityscapes数据集。CelebAMask-HQ数据集是从CelebA(celebfaces attributes)数据集中选择了30 000幅高分辨率面部图像进行像素级标注,共19个类别,包括背景、眼睛、帽子、眼镜、耳环等。本文将30 000幅图像随机划分为27 000幅训练图像和3 000幅测试图像。Cityscapes数据集是交通视图的语义分割图像数据集,包含50个城市的街道场景中驾驶视角的高质量像素级标注图像,共35个类别,包括道路、建筑、天空、人、车辆等,实验使用其中2 975幅训练图像进行训练,500幅验证图像进行测试。
本文使用从Liu等人(2018)工作中获得的不规则掩膜数据集,部分掩膜如图3所示。掩膜根据其相对于整个图像大小的面积比(例如0-10%、10%-20%)进行分类,共包含55 116幅训练图像和12 000幅测试图像。

图3 掩膜数据集示例样本Fig.3 Samples of irregular mask dataset
图4为数据集的预处理结果,从左到右依次是原始图像、受损图像以及受损图像的语义分割结构和边缘结构。如图4所示,将不规则掩膜遮挡在原始真实图像及其语义分割图像上,获得待修复受损图像和受损语义分割图像,使用Canny边缘检测器获得受损图像的边缘结构图像。Canny边缘检测器的灵敏度由高斯平滑滤波器σ的标准差控制,从Nazeri等人(2019)的研究可知,σ≈2可以产生较好的结果。

图4 数据集预处理Fig.4 Dataset preprocessing
2.2 训练细节
实验基于深度学习框架pytorch实现,GPU为NVIDIA1080Ti显卡,批处理大小为8,使用Adam优化器优化目标函数。为了与现有的先进方法进行公平比较,采用256×256像素的图像。3个模块单独进行训练,首先设置生成器的学习率为10-4,鉴别器的学习率为10-5,使用图像的语义分割标签训练语义分割重建模块,使用Canny算子生成的边缘标签训练边缘重建模块,使用真实图像标签训练内容补全模块,直至损失平稳。然后调整生成器的学习率为10-5,鉴别器的学习率为10-6,继续微调模型直至损失平稳。

3 结 果
3.1 结构重建定量分析
3.1.1 语义分割重建结果定量分析
使用语义分割中常用的像素精度(pixel accuracy,PA)和平均交并比(mean intersection over union,MIoU)来评估语义分割重建模块的性能。其中,PA为标记正确的像素占总像素的百分比,MIoU为真实语义分割与预测语义分割结果之间的交并比,两个指标值越高,表示重建的语义分割结构与真实语义分割结构越相似。
表1是语义分割重建模块在两个数据集上重建语义分割结构的定量结果。可以看出,在两个数据集上,随着掩膜比例的增大,重建结构的PA和MIoU均呈下降趋势,但依然保持较高的预测性能。该实验的目的不是为了获得最佳的指标性能,而是为了展示语义分割重建模块的重建结果与真实语义分割结构的相似程度。需要注意的是,与一般语义分割解决识别分类任务不同,语义分割重建模块是预测缺失区域的像素级语义分割,因此二者的指标性能之间不具有可比性。
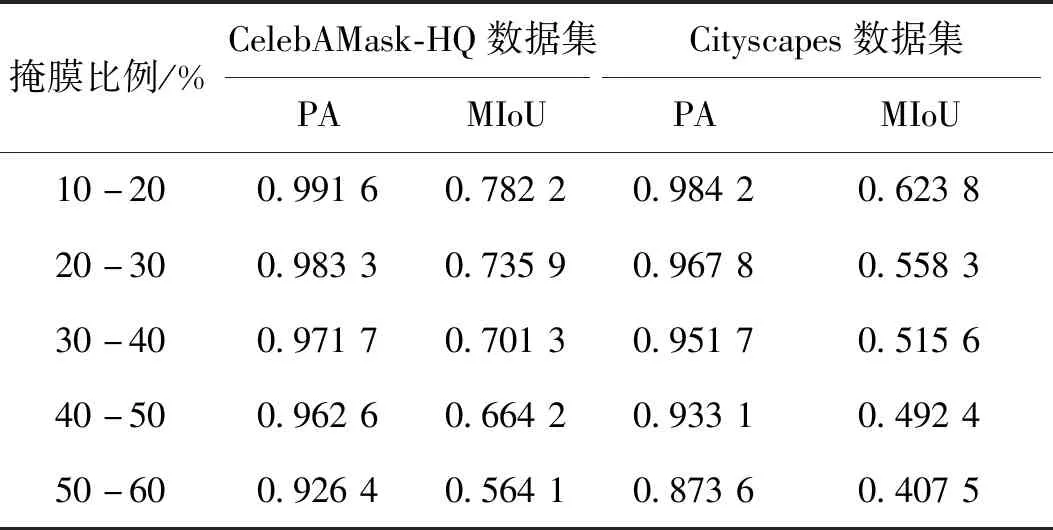
表1 语义分割重建的定量结果Table 1 Quantitative results of semantic segmentation reconstruction
3.1.2 边缘重建结果定量分析
通过实验验证本文关键假设:语义分割结构有助于提高边缘结构重建的准确性。
表2为有、无语义分割结构指导情况下,重建的边缘结构在两个数据集上的准确率和召回率比较。可以看出,有语义分割指导的边缘重建性能明显优于无语义分割指导,说明相较于直接预测边缘结构的方法,本文方法在语义分割结构的指导下预测边缘结构,可以有效减少边缘重建错误。
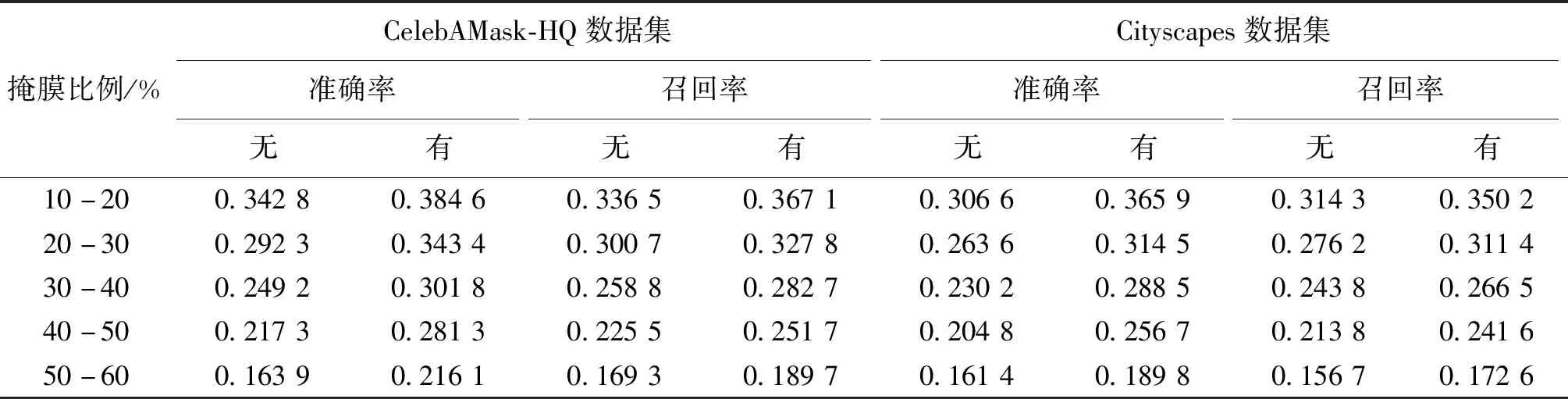
表2 边缘重建结果定量比较Table 2 Quantitative comparison of edge reconstruction results
3.2 阶段修复定性分析
本文设计的3阶段生成对抗网络的3个阶段层层递进,前一阶段的修复结果会直接影响后续阶段的修复效果,所以3个阶段都必须能够完成各阶段设计的相应任务,本文模型的各阶段修复效果如图5所示。
图5(a)为模型第1阶段修复效果,从左到右依次是受损语义分割结构、重建语义分割结构和真实语义分割结构。可以看出,对于结构简单的人脸图像,眼睛、鼻子和嘴巴等部位在绝大部分遮挡情况下,重建的结构在视觉上依然合理。在结构复杂的街景语义图像上也成功重建出缺失的道路、行人和汽车等语义分割结构。语义分割重建模块可以重建图像缺失区域的合理语义分割结构,重建的语义分割结构在视觉上都较为合理,且与真实语义分割结构相似。
图5(b)为模型第2阶段修复效果,从左到右依次是受损边缘结构、重建边缘结构和真实边缘结构。可以看出,对于人脸图像,边缘重建模块可以重建出遮挡区域较为合理的人脸边缘、眼睛边缘和头发边缘等信息,并且在第1阶段重建语义分割结构指导下,生成了与图5(a)中语义分割结构相一致的边缘结构(如脸的轮廓、耳环和牙齿等)。在边缘结构复杂的城市景观边缘缺失图像上也重建出了合理的街道、汽车和树等的边缘结构。边缘重建模块可以重建出较为真实合理的边缘结构,指导第3阶段的内容补全。
图5(c)为模型第3阶段修复效果,从左到右依次是受损图像、最终修复结果和原始图像。可以看出,对于人脸图像,在语义分割结构与边缘结构的指导下,内容补全模块生成的图像与第1、2阶段的修复结果结构上保持一致,并且较为真实地补全了缺失的图像内容(如眼睛、鼻子和人脸皮肤等)。补全的图像与原始图像相比,眼袋消失、增加了没有露出的牙齿,但在视觉上仍然自然合理。对于复杂的城市景观图像,内容补全模块同样生成了真实合理的汽车、影子和建筑等内容,没有产生结构缺失和过于模糊的结果。在语义分割结构和边缘结构的联合指导下,内容补全模块能够对缺失区域的纹理色彩等细节做出合理预测,产生视觉上真实的修复结果。

图5 各阶段的修复效果Fig.5 Inpainting effects of each stage ((a) the first stage;(b) the second stage;(c) the third stage)
由上述分析可知,本文设计的3个阶段都能够按照模型设计的阶段任务,生成相一致且真实合理的结果。
3.3 定性比较
将本文模型与PC(partial convolutions)(Liu等,2018)、RFR(recurrent feature reasoning)(Li等,2020)、EC(edge connect)(Nazeri等,2019)和HC(hypergraphs convolutions)(Wadhwa等,2021)等4种先进模型进行定性比较。
图6是各模型在CelebAMask-HQ数据集上的比较结果。可以看出,第1行中,对于较小的掩膜,各模型都能完整修复出缺失区域的内容,但本文模型生成的图像在眼睛等细节上更加自然真实。第2-5行中,对于中等或较大的掩膜,PC无法完成合理的修复,生成的图像结构扭曲、视觉上不真实;RFR生成的图像边界模糊、存在伪影;EC生成的图像视觉上不自然,例如生成的眼睛左右不对称;HC生成图像结构合理,但眼睛、耳朵等内部细节不真实;本文模型生成的图像不仅边界清晰,而且在细节上更加真实自然。
CelebAMask-HQ数据集中的人脸大多为正脸,且具有左右对称、结构相似的特点。而Cityscapes数据集中的街景构造复杂并且差异较大、标签类别多,所以图像修复较为困难,具有挑战性。

图6 CelebAMask-HQ数据集上修复结果比较Fig.6 Comparison of inpainting results on CelebAMask-HQ dataset((a) original images; (b) damaged images; (c) PC; (d) RFR; (e) EC; (f) HC; (g)ours)
图7是各模型在Cityscapes数据集上的比较结果,各列代表的模型与图6相同。可以看出,本文模型的修复结果较其他模型明显减少了不一致性,视觉上也更加自然真实。可以看出,在第1行右边汽车和左边窗户等缺失区域细节修复上,本文模型的结果更加清晰完整。第2行中,本文模型可以修复出正确的路肩细节,而其他模型修复结果在语义上不正确。第3、4、5行中,PC和RFR生成的图像(如第3行的大客车、第4行的行人以及第5行的建筑等)结构缺失且模糊;由于街景图像边缘复杂,不同对象的边缘相互交错,导致EC生成的图像结构错误且边界模糊;HC的修复效果较EC有了很大改善,但由于缺少明确的结构指导,生成的图像边界模糊;相比于HC,本文模型在语义分割结构的指导下进行边缘重建,有效减少了边缘重建错误,生成的图像边界清晰、结构合理,视觉上更加真实。
总的来说,在CelebAMask-HQ和Cityscapes数据集上,PC和RFR由于缺少有效的结构指导,生成的图像边界模糊、存在大量伪影且不真实。EC在边缘结构的指导下生成的图像边界清晰,但由于缺少语义分割结构的指导,往往会生成错误的边缘结构,最终导致生成的图像视觉上不自然。HC缺少明确的结构指导,虽然语义大致正确,但生成的图像边界不清晰。本文模型的修复结果明显优于其他模型,生成的图像结构更加合理,具有较少伪影,纹理细节也更加真实。
3.4 定量比较
使用图像修复中常用的平均绝对误差(mean absolute error,MAE)、峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structure similarity index measure,SSIM)指标(Wang等,2004)评估各模型的修复效果。表3和表4分别为PC、RFR、EC、HC以及本文模型在CelebAMask-HQ和Cityscapes数据集上不同比例不规则掩膜的定量比较结果。
从表3可以看出,在CelebAMask-HQ数据集上,各模型的性能均随掩膜比例的增加逐渐变差。在掩膜比例为10%-20%时,本文模型的结果略差于HC和RFR。而在掩膜比例较大时,本文模型表现出了最优的性能。这可能是因为面对较小的掩膜遮挡时,人脸图像结构相对简单,没有出现结构缺失现象,所以HC和RFR取得较好的结果。

图7 Cityscapes数据集上修复结果对比Fig.7 Comparison of inpainting results on Cityscapes dataset((a) original images; (b) damaged images; (c) PC; (d) RFR; (e) EC; (f) HC; (g)ours)

表3 不同方法在CelebAMask-HQ数据集上的定量比较Table 3 Comparison of results of different methods on CelebAMask-HQ dataset
从表4可以看出,在Cityscapes数据集上的定量比较结果表现出与CelebAMask-HQ数据集相似的趋势,各模型的性能同样随掩膜比例的增加逐渐变差。在Cityscapes数据集上,3项指标数据都较CelebAMask-HQ数据集差,这是因为城市景观图像结构复杂,较小的掩膜遮挡就会导致图像结构缺失,所以修复具有挑战性。本文模型在3项指标上均优于其他模型,表明面对复杂结构的受损,本文的多阶段修复模型展现出了明显的优越性,能够合理修复出缺失的结构信息,视觉上更加真实。

表4 不同方法在Cityscapes数据集上的定量比较Table 4 Comparison of results of different methods on Cityscapes dataset
总的来说,本文模型的定量比较结果整体上优于其他对比模型,这也对应了定性分析中各模型的视觉比较结果。
4 结 论
本文针对现有图像修复方法存在的生成图像边界模糊和结构扭曲问题,提出了一种基于深度生成模型的3阶段图像修复方法,并在CelebAMask-HQ和Cityscapes数据集上与多种先进方法进行对比实验。结果表明,本文方法生成的图像结构更加合理,纹理细节更加真实。本文方法将图像修复任务解耦为语义分割重建、边缘重建和内容补全3个阶段。一方面,首先进行语义分割重建可以有效减少后续结构重建中的错误;另一方面,在语义分割结构和边缘结构的双重约束下能够实现图像纹理细节更加精细的修复。
本文方法存在以下不足,有待继续研究。1)在网络模型设计上,受限于物理设备,3个阶段均为结构简单的网络,如果使用更加复杂的网络模型,可以进一步提高图像修复质量。2)本文方法很大程度上依赖于语义分割结构和边缘结构的预测准确性,如果设计神经网络能够更好地理解图像的结构信息,可以进一步做出更准确的结构预测。
本文提出的3阶段解耦方法使用户可以与图像修复系统交互,能够很容易地扩展到其他图像任务,包括条件图像生成、图像编辑、图像去噪和图像超分辨率等,这也是本文方法未来的实际应用方向。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
人工晶体学报(2021年3期)2021-04-17
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
电子技术与软件工程(2018年5期)2018-04-09
制造技术与机床(2017年10期)2017-11-28
通信产业报(2016年44期)2017-03-13
新课程学习·中(2013年3期)2013-06-14
雕塑(1999年2期)1999-06-28