掩膜融合下的人脸图像质量评价方法
2022-12-21 03:23李雷达殷杨涛吴金建董伟生石光明
中国图象图形学报 2022年12期
李雷达,殷杨涛,吴金建,董伟生,石光明
西安电子科技大学人工智能学院,西安 710071
0 引 言
人脸识别是生物特征识别领域的研究热点,已经在在线支付、安防等众多领域中广泛应用。虽然现有的人脸识别方法取得了优秀的性能,但往往需要有高质量的输入图像。然而,现实生活中人脸识别系统常处于开放多变的环境,对系统的鲁棒性要求极高。外部环境的变化,如光照强度不当、人脸姿态不正等,会导致人脸图像出现模糊、噪声点较多和人脸关键部位不突出等问题,从而导致人脸识别系统的性能大大降低。人脸图像质量评价方法可以用于改善人脸识别系统。一方面,由于影响人脸识别系统性能的往往是低质量图像,因此可以利用人脸图像质量模型过滤掉低质量人脸图像,从而在减少无效识别的同时提升识别效率;另一方面,可以将人脸质量特征与识别特征相结合,自适应地调谐人脸图像识别特征,进而提升人脸识别系统的性能。
目前,对于人脸图像质量评价的研究相对较少,已有方法可以分为基于手工特征的方法和基于深度学习的方法。基于手工特征的方法结合人的先验知识,提取与人脸质量相关的特征,并在此基础上训练回归模型实现人脸图像质量分数的预测。Luo(2004)采用与传统图像质量评价类似的方法,提取光强、模糊、噪声等10种特征,利用人工神经网络预测质量分数。Abdel-Mottaleb和Mahoor(2007)结合模糊、光照、面部姿势和表情等进行人脸图像质量评估;其中面部姿势定义为人脸偏离正面的角度,面部表情通过预训练的高斯混合模型来完成。Beveridge等人(2008,2010)利用广义线性混合模型提出了两种影响人脸验证性能的特征,分别为Sobel滤波器下由像素值平均大小组成的边缘密度度量和对脸部不同区域进行计数的区域密度度量。Sellahewa和Jassim(2010)利用通用图像质量评价中的亮度失真分量(Wang和Bovik,2002),将输入人脸图像与训练集中的参考图像进行比较,通过滑动窗口逐个计算平均亮度值,最后取所有窗口的均值作为人脸质量分数。Liao等人(2012)选取Gabor滤波的幅值作为特征,利用级联支持向量机预测人脸图像的5个质量等级。Chen等人(2014)提出了一种两阶段人脸图像质量评价方法;第1阶段中分别提取梯度直方图、空间包络特征(Oliva和Torralba,2001)、Gabor、局部二值特征(local binary pattern,LBP)和人脸关键点特征;第2阶段中基于多项式核函数生成人脸图像质量分数。基于手工特征的方法中,特征的设计主要取决于人对有限图像样本的观察和经验,因此特征的表征能力有限,在面对真实环境下多变的场景和失真类型时,适用能力较差,难以满足实际应用的要求。
随着深度学习在计算机视觉领域的广泛应用,研究者们也主要采用深度学习方法进行人脸图像质量评价的研究。Zhang等人(2017)首先创建了一个人脸图像照度质量数据库(face image illumination quality dataset, FIIQD),对200种不同照度下的224 733幅图像进行了主观质量评分,然后采用ResNet-50(He等,2016)网络训练人脸图像质量评价模型。Hernandez-Ortega等人(2019,2020)提出了两种人脸图像质量评价模型,即FaceQnet-v0(face quality net-v0)(Hernandez-Ortega等,2019)和FaceQnet-v1(face quality net-v1)(Hernandez-Ortega等,2020),采用BioLabICAO框架(Ferrara等,2012)从VGGFace2(Visual Geometry Group Face2)(Cao等,2018)数据集中选取最高质量的人脸图像作为基准,然后将待评价图像与基准图像同时输入人脸识别模型,得到不同向量间的距离,最后使用 ResNet-50(He等,2016)网络进行回归建模。FaceQnet-v1与FaceQnet-v0的主要不同在于人脸识别特征提取器的数量(前者使用3个,后者仅1个)。Zhang等人(2019)提出了多分支人脸图像质量评价网络,由特征提取和质量评价两部分组成;前者利用卷积神经网络(convolutional neural networks, CNN)提取特征,后者将特征送到4个全连接分支预测不同的质量属性,包括对齐、可见性(遮挡)、姿势和清晰度。Terhörst等人(2020)提出了基于随机张量鲁棒性的人脸质量评价方法SER-FIQ(stochastic embedding robustness-face image quality)。通过比较人脸图像经过多个随机选择子网络模型的输出向量来计算人脸图像质量;这里通过所有输出向量间欧氏距离的平均值表示质量,因此不需要人为标注。Ou等人(2021)提出了基于相似度分布距离的人脸质量评价方法(similarity distribution distance-face image quality assessment,SDD-FIQA),首先计算输入图像在类间和类内的相似度分布,然后对两种分布计算Wasserstein距离作为人脸图像的质量特征,最后训练回归网络实现评价。尽管目前基于深度学习的人脸图像质量评价方法取得了重要进展,然而这些方法对于人脸图像质量,尤其是其可用性特性的描述仍不够准确和直观。由于人脸图像主要供识别算法使用,因此不同于传统的图像质量评价(Mittal等,2012a,b;Venkatanath等,2015;富振奇 等,2018;方玉明 等,2021),人脸图像质量评价模型既要符合人脸识别算法的特点,又要符合人眼的感知特性。
本文提出了一种新的基于掩膜的人脸图像质量评价方法。从人眼识别人脸图像的角度出发,人脸图像的质量,即可用性的高低,主要是由脸部的关键区域(眼睛、鼻子和嘴等)决定,因此关键区域对于人脸识别至关重要。并且,这些区域的变化对不同质量人脸图像的影响程度存在不同,而这正是本文算法的主要动机。具体地,对一幅待评价的人脸图像,首先对关键区域加上掩膜,进而得到由评价图像和掩膜图像构成的人脸图像对;然后,将上述图像对输入特征提取模块得到人脸质量特征对;最后,通过质量特征对映射得到输入人脸图像的质量分数。基于5个人脸图像数据库的实验结果表明,本文方法能够有效评估人脸图像的质量,性能优于目前的主流方法。
1 提出的方法
1.1 核心思想
本文算法的主要思想是受人识别人脸特点的启发,即人在进行人脸识别时往往主要依据眼睛、鼻子和嘴巴等关键区域(Liu等,2017;章坚武 等,2019;孙浩浩 等,2020)。现有人脸识别算法在设计时也利用了上述特点(Sun等,2014;Taigman等,2014)。因此,在设计人脸图像的质量评价模型时,也需要考虑关键区域对人脸识别算法的影响,进而获得与人脸识别算法更加一致的质量评价模型。如何挖掘上述关键区域的特点,进而实现对人脸质量的有效表示是问题的核心,下面详细阐述。
人脸图像的质量评价不同于一般的图像质量评价问题,其本质上是人脸图像的可用性评价,即依附于特定识别系统存在的质量度量。在人脸识别系统中,人脸图像的质量是通过输入图像与人脸数据库中基准图像特征对的相似度来进行度量的(这里的基准图像一般是无失真的高质量清晰人脸图像),相似度越高说明输入的人脸图像质量越高,相似度越低说明输入的人脸图像质量越低。如图1所示,输入的第1幅人脸图像比第2幅更加清晰,辨识度更高,因此经过人脸识别模型得到的人脸特征与基准图像特征有着更高的相似度,反映出第1幅输入人脸图像的可用性质量更高,即该图像的可用性价值更高。

图1 传统人脸图像质量的计算Fig.1 Traditional calculation of face image quality

(1)
在实际的应用场景中,希望能够直接使用输入的人脸图像Ii,快速判断其质量的高低。因此,如何在仅使用输入图像的情况下,实现人脸图像质量的无参考评价,是问题的核心。
考虑到可用性质量Q本质上代表输入图像与高质量基准图像之间的相似度,即输入图像特征越接近基准图像特征可用性质量越高,反之越低。在不使用高质量基准人脸图像的条件下,可以换一种对比的基准,即使用输入人脸图像所对应的低质量图像作为伪参考。不同于高质量的基准人脸图像,伪参考图像可视为人脸图像可用性质量的另一个极端;输入图像与伪参考图像越接近,其可用性质量越低,反之越高。
受此启发,本文引入了人脸图像的掩膜操作,即对脸部关键区域(如眼睛、鼻子和嘴等)添加黑色覆盖。掩膜过程用M表示,添加了掩膜的图像Im可表示为:Im=M(Ii),相比一般的人脸识别参考图像,这里的掩膜图像可以认为是一种伪参考图像,即图像包含的人脸可用性信息几乎可以忽略。对于任意一幅输入人脸图像,可以在没有高质量基准人脸作为参考的情况下,利用伪参考掩膜图像作为比较的基准;与掩膜图像距离越近则可用性质量越低,距离越远则可用性质量越高。上述特点可以用图2表示,这样就可以在只使用输入人脸图像的情况下进行无参考评估,从而得到人脸图像的可用性质量表示。
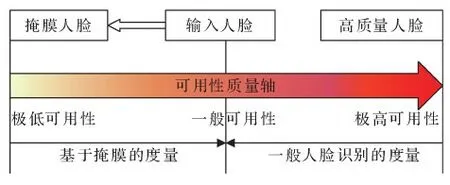
图2 人脸可用性质量的度量Fig.2 Utility measurement of face image quality
1.2 算法设计
围绕核心思想,本文算法的构建主要分为两部分,即人脸掩膜的设计和回归网络的构建,如图3所示。人脸掩膜的设计主要得到人脸图像的掩膜图像,即伪参考图像;回归网络构建部分主要通过输入的人脸和掩膜图像去预测人脸质量。
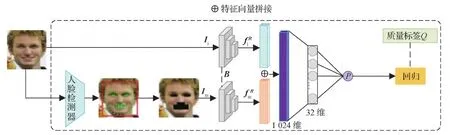
图3 本文算法的框图Fig.3 Framework of the proposed algorithm
1)人脸掩膜的设计。人眼识别人脸图像时主要通过关键区域(眼睛、鼻子和嘴等)进行分析和判断,所以关键区域的破坏将直接影响图像质量的高低;并且关键区域的破坏对不同质量的人脸图像带来的影响也不相同。相较于低质量的人脸图像,增加掩膜对高质量人脸图像的识别性能影响更大。设计掩膜的目的是掩盖掉关键区域的作用,然后通过比较增加掩膜前后识别性能的影响程度表示人脸图像的质量。因此,本文中设计掩膜的原则是将人脸图像中关键区域的有用信息消除,从而得到所需的掩膜图像。本文采用专门用于人脸检测(非人脸识别)的Retinaface(Deng等,2019b)识别出人脸的关键区域,获得人脸关键区域的坐标。从关键区域中选取左右眼、鼻子及嘴巴等4个区域,并将区域中的像素值全部置0,即获得掩膜人脸图像Im。掩膜图像Im符合本文所期望的伪参考图像的特点,即可用性质量是极低的。具体效果如图4所示。

图4 掩膜操作Fig.4 Mask operation
2)回归网络构建。对于回归网络构建,考虑到训练模型的计算成本不能太高,并且需要在视觉领域的应用较广,表现性能较好,本文选取Inception结构(Szegedy等,2015)的网络模型。综合考虑网络的性能表现和计算成本,最终选取InceptionResnetV1(Szegedy等,2017)作为主干结构,并且抽取最后的分类层,只采用分类层之前的512维特征,然后用两个全连接层进行连接,最后预测的分数值P可表示为
(2)

考虑到人脸图像质量表示是连续的数值,因此采用均方误差函数作为训练时的损失函数,即
(3)
式中,K为样本数,j代表样本的索引。
本文提出的人脸图像质量评价模型总体参数量为23.52 M(million),浮点运算次数为2.85 GFLOPs (giga float-point operations per second)。将所提出的算法取名为基于掩膜的人脸图像质量评价方法(mask-based face image quality,MFIQ),需要说明的是,评估模型MFIQ训练完成之后,即可以直接用于评价任何输入的人脸图像,不再需要参考图像,即无参考评价。
2 实 验
2.1 实验设置
2.1.1 数据集
实验中采用5个人脸图像数据集:包括1个新构建的人脸数据集和4个已有的人脸识别数据集。其中新构建的数据集取一定比例的人脸数据用来进行模型训练,剩下的图片数据和其余4个公开数据集用于模型测试。4个现有数据集分别为LFW(labeled faces in the wild)(Huang等,2008)、VGGFace2(Cao等,2018)、CASIA-WebFace(Institute of Automation, Chinese Academy of Science-Website Face)(Yi等,2014)和CelebA(CelebFaces Attribute)(Liu等,2015),详细信息如表1所示。

表1 人脸图像数据集信息Table 1 Information of face image datasets
尽管上述数据集中包含大量不同环境下的人脸图像,然而其中人脸图像的失真程度普遍较弱,主要为高质量人脸图像,因而无法很好地代表真实环境中复杂的人脸图像失真。为了获得普适性更好的模型,训练数据集中图像失真的种类和失真程度应当有足够的多样性,这样才能保证模型的泛化性。为此,本文构建了一个新的人脸图像质量评价数据库,取名为DDFace(diversified distortion face),包含更加广泛的人脸图像失真类别和失真强度,数据集的具体信息如表2所示。

表2 本文构建的DDFace数据集信息Table 2 Information of the DDFace dataset
考虑到VGGFace2数据集中每个人脸对应的图像数量较多,有利于确定基准人脸图像,因此从中选取1 000个人脸图像作为DDFace数据库的基准人脸图像,每个人脸ID下有10种不同角度或环境的图像。然后,在确定的基准人脸图像基础上添加5种模拟的失真操作,包括高斯模糊、高斯噪声、对比度失真、运动模糊和图像压缩(joint photographic experts group, JPEG);每种失真类型又包含6种不同的失真等级。同时,为了模拟真实环境下图像中存在的复合失真,采用Ou等人(2019)的方法,并设置4种不同的失真等级。对基准人脸图像添加失真的效果如图5所示。

图5 DDFace数据库失真图像示例Fig.5 Samples of distorted images in DDFace dataset
2.1.2 人脸图像质量标注
人脸图像的质量本质上是可用性质量,即面向人脸识别系统,如图6所示,用D表示距离度量,∝表示正相关,则人脸图像的质量Q可以等效为
(4)
人脸图像质量的标注主要包含3个步骤:人脸基准图像的选择、人脸识别模型以及相似性度量方式的选择。需要说明的是,采用基准图像进行人脸图像的标注仅在模型训练阶段需要,当模型训练完成之后即可以对任何输入的人脸图像直接进行质量评价,不需要任何额外的信息。

图6 人脸图像可用性质量的标注Fig.6 Annotations of the face image utility quality
1)人脸基准图像It。所构建的DDFace数据集里面每一张人脸都会有一幅高质量图像作为基准图像,基准图像具有高质量、高辨识度以及脸部方向朝正的特点,用于与其他人脸图像进行相似度的计算。
2)人脸识别模型F。考虑到训练数据集DDFace中人脸图像尺寸均为160×160 像素,本文选取了输入要求为112×112像素,即也是等宽高的Insightface(Deng等,2019a)人脸识别模型,该模型在各个数据集上的表现都很优秀。
3)距离度量D。输入人脸图像和基准人脸图像经过人脸识别网络得到人脸特征对之后,采用余弦距离来表示输入图像的人脸质量分数。在人脸图像质量模型的训练中,采用上述分数为训练标签。
2.1.3 模型训练与评估
1)训练。对构建的DDFace数据集,按照8 ∶1 ∶1的比例划分训练、验证和测试集。训练InceptionResnetV1网络时超参数的具体设置为:初始学习率0.001,学习率衰减因子0.9,衰减步长2,总训练轮次为40。
2)评估。为了评估人脸图像质量评估模型的性能,实验采用Grother和Tabassi(2007)提出的错误拒绝曲线(error versus reject curve,EVRC),该曲线通过样本拒绝比例和错误拒绝率(false non-match rate,FNMR) 来度量评价模型性能的优劣程度。除了错误拒绝曲线,实验中还利用了SDD-FIQA方法中的曲线面积(area over curve,AOC)指标进一步量化该曲线,具体定义为

(5)
式中,g(φ)表示在拒绝比例φ下,人脸验证的FNMR;φ=1-σ是被去除的低质量图像所占比例,a和b分别表示它的下界和上界,在本文实验中分别设置为0和1。
2.2 实验结果
实验中,将本文提出的MFIQ算法与传统的图像质量评价算法BRISQUE(blind reference image spatial quality evaluator)(Mittal等,2012a)、NIQE(natural image quality evaluator)(Mittal等,2012b)和PIQE(perception image quality evaluator)(Venkatanath等,2015)以及基于深度学习的人脸图像质量评价方法FaceQnet-v0、FaceQnet-v1和SER-FIQ进行对比。
2.2.1 算法性能比较
本节实验利用Insightface模型来进行人脸验证,在5个数据集下分别对比不同的质量评价模型,实验得出的EVRC曲线如图7所示(考虑到全部数据集下的曲线图展示占用过大篇幅,这里仅展示3种数据集下的结果,其中两个为公开数据集里代表性较强的LFW和CASIA-WebFace数据集,另一个为本文所构建的DDFace数据库测试集部分),AOC的结果在表3中给出。实验结果表明,在3种错误匹配率(FMR)值下(0.1, 0.01和0.001),MFIQ都获得了最好的AOC结果,其中在LFW数据集上相比于次优模型的AOC结果提高约4%,在CASIA-WebFace数据集上提升1.1%,在VGGFace2、DDFace和CelebA数据集上也均有不同程度的性能提升。
2.2.2 跨模型下的性能比较
在真实场景部署中所使用的人脸识别模型可能各不相同,本文训练MFIQ过程中人脸质量的标签是基于Insightface模型生成的。为了验证MFIQ模型在不同人脸识别模型下的扩展性能,本文采用另一种人脸识别模型Sphereface进行测试,在5个数据集下分别对比不同的质量评价模型,实验的EVRC曲线如图8所示(考虑到全部数据集下的曲线图展示占用过大篇幅,这里仅展示3种数据集下的结果,其中两个为公开数据集里代表性较强的LFW和CASIA-WebFace数据集,另一个为本文所构建的DDFace数据库测试集部分),AOC结果在表4中展示。实验结果表明,在LFW数据集上MFIQ方法相比于其他模型的AOC结果提高大约14.8%,在CASIA-WebFace上提高了2.9%,在DDFace数据集上提高了4.7%,而在CelebA和VGGFace2两个数据集上的性能表现也是最好的。

图7 错误拒绝曲线图(Insightface模型下)Fig.7 Error rejection curves (Insightface model)((a) LFW (FMR=0.1);(b) CASIA-Webface (FMR=0.1);(c) DDFace (FMR=0.1);(d) LFW (FMR=0.01);(e) CASIA-Webface (FMR=0.01);(f) DDFace (FMR=0.01);(g) LFW (FMR=0.001);(h) CASIA-Webface (FMR=0.001);(i) DDFace (FMR=0.001))
两种人脸识别模型下的实验结果均表明,本文提出的MFIQ方法在性能上优于其他主流的人脸质量评估方法,相较于传统的质量评价方法性能提升更为显著。
2.2.3 MFIQ模型下的数据分布评估
本部分用MFIQ评价模型对5个数据集里的人脸图像进行可用性质量的预测。5个数据集中图像的特点分别为:
1)CASIA-WebFace、VGGFace2和CelebA中的人脸图像大部分都是质量较高的人脸图像,其中CelebA数据集中高质量清晰图像所占的比重最大。
2)LFW数据集中人脸图像质量较低的图像数量较少,大部分都是较为清晰和辨识度较高的图像,噪声较少。
3)本文中所构建的DDFace数据集是从VGGFace2里选取的人脸图像通过添加不同类型不同等级的失真得到的,很多人脸图像里面含有各种噪声,因此DDFace中低质量的人脸图像占比较大。
本部分用MFIQ方法对数据集中所有的人脸图像进行质量评估,得到各数据集下的质量分数分布图,如图9所示。从图9中可以看出,5个数据集里面DDFace数据集中低质量人脸图像占的比重最大,而CASIA-WebFace、VGGFace2和CelebA中的人脸图像大部分的质量分数在0.7以上,即高质量图像的占比较大;LFW数据集中大部分图像的质量分数都在0.5之上,即人脸图像的可用性也都较高,这与数据集实际分布的特点十分吻合。

表3 AOC结果(Insightface模型下)Table 3 The AOC results (Insightface model)

图8 错误拒绝曲线图(Sphereface模型下)Fig.8 Error rejection curves(Sphereface model)((a) LFW (FMR=0.1);(b) CASIA-Webface (FMR=0.1);(c) DDFace (FMR=0.1);(d) LFW (FMR=0.01);(e) CASIA-Webface (FMR=0.01);(f) DDFace (FMR=0.01);(g) LFW (FMR=0.001);(h) CASIA-Webface (FMR=0.001);(i) DDFace (FMR=0.001))
实验结果表明了本文MFIQ方法对数据集的可用性质量分布预测和真实的情况十分接近,模型预测的结果具有可信度。
2.2.4 MFIQ算法质量评价效果
实验选取相同人脸和不同人脸条件下不同失真程度的示例图像,并用4种不同的人脸质量评估模型进行质量预测。相同人脸条件下预测的结果如图10所示,每一行代表一个人,从左到右人脸图像质量依次升高。
实验结果表明,MFIQ方法能够有效地区分人脸高低质量,预测的质量排序与真实质量一致,而其他3种人脸质量评价模型都存在一定的预测偏差。例如,SER-FIQ错误地认为图10(d)所示的人脸比图10(c)中的人脸质量要低,且预测的质量分数过于集中,区分度低;FaceQnet-v0预测图10(b)中的人脸质量比图10(a)低,图10(g)的人脸质量比图10(f)差,图10(a)和图10(c)人脸的质量相近,这与实际质量存在较大的偏差。FaceQnet-v1则错误地认为图10(c)和图10(d)人脸比图10(a)人脸质量要差,同时对图10(e)和图10(f)的预测出错。
对于不同人脸条件下的人脸图像预测也进行了对比,如图11所示。预测结果表明,MFIQ方法能够有效地对不同人脸下的不同质量图像进行区分和预测。例如,SER-FIQ错误地认为图11(a)和图11(b)中的人脸比图11(d)中的人脸质量高;FaceQ-net-v0判断图11(c)和图11(d)中的人脸质量时现了偏差,并且错误地认为图11(f)和图11(g)所示的人脸比图11(h)中的人脸质量要高;FaceQnet-v1预测结果出现的问题与FaceQnet-v0类似。

表4 AOC结果(Sphereface模型下)Table 4 The AOC result (Sphereface model)

图9 数据集分布预测Fig.9 Prediction of the dataset distribution
上述实验结果表明,SER-FIQ、FaceQnet-v0和FaceQnet-v1几种主流的人脸质量评价模型对低质量人脸图像的辨识度不强,即对于失真人脸图像预测的鲁棒性不高,导致在低质量人脸图像多的情况下容易出现误判。
相比而言,本文提出的MFIQ方法能够更加准确地区分出不同等级失真人脸图像的可用性质量,性能更加优秀。

图10 相同人脸ID下不同失真强度的可用性质量分数预测Fig.10 Face image utility quality score prediction with wide distoration range under the same face ID((a) face 1-1;(b) face 1-2;(c) face 1-3;(d) face 1-4;(e) face 2-1;(f) face 2-2;(g) face 2-3;(h) face 2-4)

图11 不同人脸ID下不同失真强度的可用性质量分数预测Fig.11 Face image utility quality score prediction with wide distoration range under different face ID((a) face 1;(b) face 2;(c) face 3;(d) face 4;(e) face 5;(f) face 6;(g) face 7;(h) face 8)
3 结 论
本文提出了一种基于掩膜的人脸图像质量评估方法,该方法从人脸识别的固有特点出发,充分考虑关键区域在人脸识别过程中的决定性作用,通过构建掩膜图像作为伪参考,进而获得待评价人脸图像质量的无参考表示。在不同人脸识别模型下的实验结果表明,本文方法能够准确地预测不同失真强度下人脸图像的可用性质量,相比于传统的质量评价方法和主流的人脸质量评价方法,本文方法对人脸图像的预测更加贴近真实结果,并且在对低质量人脸图像的评估表现上,本文方法的鲁棒性更高。
本文方法在人脸质量评估任务上表现性能优异,而如何将其融入到现有的人脸识别模型中并提高模型在低质量图像上的识别精度是进一步的难点,未来将着重从这方面入手,将人脸质量评价模型和人脸识别模型相结合,辅佐人脸识别模型,改善现有人脸识别模型在低质量人脸图像上识别效果不佳的状况。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
海洋信息技术与应用(2021年1期)2021-06-11
人工晶体学报(2021年3期)2021-04-17
现代建筑电气(2018年12期)2019-01-14
动漫星空(2018年9期)2018-10-26
电子技术与软件工程(2018年5期)2018-04-09
制造技术与机床(2017年10期)2017-11-28
中国医疗设备(2017年2期)2017-03-09