全像素双核成像技术及应用研究综述
2022-12-21 03:23戴玉超章飞宇潘利源项末初何明一
中国图象图形学报 2022年12期
戴玉超,章飞宇,潘利源,项末初,何明一*
1.西北工业大学电子信息学院,西安 710129; 2.北京理工大学计算机学院,北京 100081
0 引 言
全像素双核(dual-pixel,DP),最初是由佳能(Canon)公司于2013年7月在英国发布的一项应用在数码单反相机EOS 70D上的自动对焦技术,其完整的名称是全像素双核CMOS自动对焦技术或全像素双核自动对焦技术(dual-pixel CMOS auto focus,DP CMOS AF)。
DP传感器将传统的Bayer阵列传感器的每个像素一分为二,因而一次拍摄能够捕获两幅带有微小基线(小于等于1 mm)的图像对。DP图像对的视差由其点扩展函数(point spread function, PSF)产生,与模糊量相对应。聚焦平面几乎不存在视差,离焦平面存在视差(Punnappurath和Brown,2019),因而又称为离焦视差。全像素双核图像对及离焦视差如图1所示。离焦视差在焦点前后的方向相反。
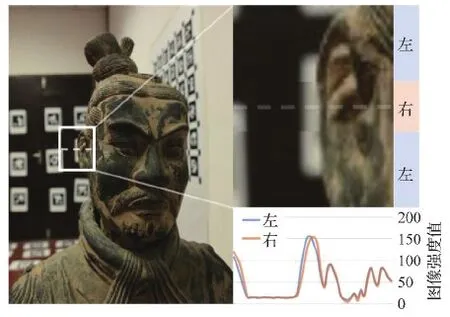
图1 全像素双核图像对及离焦视差示例Fig.1 Dual-pixel image pair and defocus disparity example
离焦视差首先得到了工业界的广泛关注。佳能公司自2013年起在中高端相机中全部使用DP自动对焦。因DP在单反相机中优异的自动对焦性能,2016年起各大手机制造厂商纷纷将其用于手机自动对焦。目前,索尼、三星两大消费级相机传感器制造厂商均使用DP结构。近5年来,各大主流手机厂商如三星、小米、VIVO和荣耀的上百款手机均搭载DP传感器。根据离焦视差估计图像合焦镜头所需移动的距离,DP自动对焦具有更快的对焦速度和更高的对焦精度,因此,DP自动对焦在目前消费级相机传感器中占有大量比例,如图2所示。
由于DP数据采集无需标定,离焦视差与模糊量直接相关,DP也受到了学术界的广泛关注。场景深度与模糊相关,因此,近年来DP自动对焦技术自然地应用于深度估计(Wadhwa等,2018;Gage等,2019;Zhang等,2020;Pan等,2021)、离焦模糊去除(Abuolaim和Brown,2020;Abuolaim等,2021;Pan等,2021)和反射去除(Punnappurath和Brown,2019)等方面的研究。可以说,全像素双核为计算机视觉领域相关任务带来了新的解决方案。
为了更好地理解、应用和发展全像素双核成像技术,本文对其自动对焦、成像原理以及在计算机视觉的深度估计、反射去除和离焦模糊去除几个任务中的应用进行系统综述(如图3所示),最后展望其未来发展方向。

图2 全像素双核工业界发展历程Fig.2 Development history of dual-pixel in industry
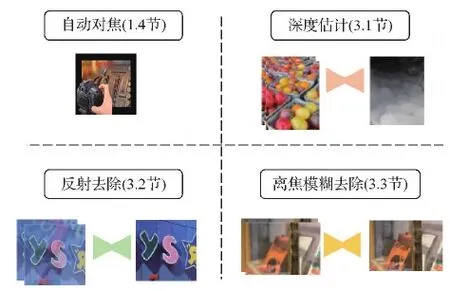
图3 全像素双核的典型应用(自动对焦、深度估计、反射去除、离焦模糊去除)Fig.3 Applications of dual-pixel sensors (auto-focus,depth estimation,reflection removal,defocus deblur)
本文首先从自动对焦技术入手,对全像素双核自动对焦的原理进行阐述。随后,结合近期各领域对全像素双核成像机制的研究,进行了系统性的归纳总结。其次,详细综述了近几年来全像素双核在计算机视觉领域的研究进展和应用成果,并介绍了目前几个全像素双核数据集。最后,讨论了全像素双核面临的挑战并对未来发展方向进行展望。
1 自动对焦
1.1 相位检测自动对焦
相位检测自动对焦,是一种需要光学相位检测器的自动对焦技术,是一种3维对焦方式。目前的相位对焦系统大多是透镜分离相位检测系统。
透镜分离相位检测方式为大多数单反相机所采用。它的原理是检测等效焦平面所成像经过分离透镜后位于电荷耦合器件(charge-coupled device, CCD)阵列上的相位差,从而判断离焦的方向和距离。透镜分离相位检测系统的主要组成部分是一组分离镜片和一组或多组由感光元件组成的测距组件。由镜头射入的光线大部分通过主反光板反射到五棱镜,一小部分透过主反光板到达副反光板,再反射到独立对焦系统。独立对焦系统的光路(https://www2.xitek.com/info/showarticle.php?id=1048)如图4所示。副反光镜反射的光线经过遮挡块和红外线滤光片滤除掉有害的光线,经过分离透镜,光线分成两束并分别投影到其后的测距组件上,如CCD线阵。

图4 透镜分离相位检测独立对焦系统光路Fig.4 Optical path of lens separation phase detection independent focusing system
如果物体合焦,即焦平面与像平面重合,分离透镜分出的两束光投射到CCD线阵上所产生的电信号的位置是固定的。CCD阵列会告知相机中央处理器(central processing unit, CPU),此时合焦。如果物体离焦,则有两种情况。一种是焦点在像平面前方,此时接受光的两只CCD线阵上产生的电信号之间的距离小于合焦时的距离;另一种是焦点在像平面后方,此时接受光的两只CCD线阵上产生的电信号之间的距离大于合焦时的距离。通过相机CPU计算CCD阵列上接收的一对电信号的相位差并与合焦状态下相位差进行比较,可计算出离焦量及离焦方向(https://www2.xitek.com/info/showarticle.php?id=1048),如图5所示。
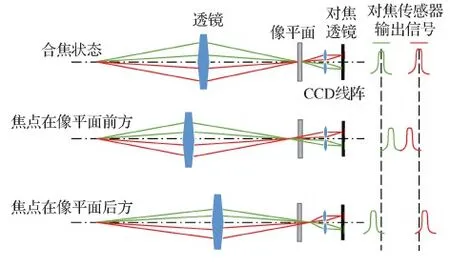
图5 相位检测自动对焦原理示意图Fig.5 Overview of auto focus principle of phase detection
透镜分离相位检测系统使用独立的透镜和CCD阵列,优点是信号敏感度高、数据处理简单、高效可靠以及长焦性能优秀。缺点则是体积庞大、结构复杂、成本高以及对焦区域有限。对焦时只利用原光束的一部分,因此对原始光线要求较高,光线不足会降低对焦的准确度。透镜分离相位检测系统主要适用于反光镜光学取景,不适用于电子取景。
1.2 反差检测自动对焦
反差检测自动对焦是电子取景特有的一种2维对焦方式,其原理是利用传感器上成像的对比度变化,通过逐步调节镜头使检测到的对比度最大化实现调焦。
反差检测与相位检测的自动对焦比较:
1)对焦速度。相位检测自动对焦比反差检测自动对焦快。因为相位检测自动对焦是“一步到位”进行对焦,而反差检测自动对焦则需要随机摸索比较。反差检测对焦时,镜头起初的移动方向是随机确定的,在寻找合焦点的过程中画面逐渐清晰,直到对比度最高时,镜头处于合焦状态。但是镜头无法确定此时是否合焦,往往会错过合焦点后再返回到合焦处,因此反差检测自动对焦比相位检测自动对焦速度慢。但随着成像元件刷新率的提高和对焦算法的不断优化,一些微单的反差检测自动对焦速度也已经超过某些单反的相位检测自动对焦。
2)对焦精度。由于相位检测自动对焦光路系统的存在,其精度受设备精度和外界环境影响较大,而反差检测自动对焦没有此类问题。
3)弱光和强光下的表现。强光下反差检测的采样结果严重过曝,无法识别其对比度差异,难以对焦;弱光下进入相位检测对焦系统的光十分微弱,可能会导致相位检测自动对焦失败。弱光下,场景的对比度虽小,会导致反差检测自动对焦性能降低,速度变慢,但是只要能够识别到微小的对比度,反差检测自动对焦仍然能够正确对焦。
4)长焦下的表现。长焦镜头的对焦负担大、景深浅。反差检测时,镜头平面的轻微移动都会导致画面模糊程度发生较大变化,使反差检测自动对焦的性能降低。相位检测自动对焦不存在这类问题。
1.3 混合自动对焦
混合对焦(Hybrid CMOS AF)(Jang等,2016)是结合反差检测自动对焦和成像传感器相位检测自动对焦两种技术的优点并克服传统自动对焦技术的缺点而提出的一种新的对焦技术。首先,成像传感器由相位检测自动对焦提示对焦的方向和大致距离,让镜头迅速移动到合焦点附近;然后,再使用反差检测自动对焦进行精准对焦。
混合对焦中,成像传感器相位检测是利用成像元件表面的微透镜代替分离透镜并使用多个像素代替CCD阵列实现的。其与透镜分离相位检测的区别是:前者检测的是分离光束的位置;后者检测的是分离光束的强度。成像传感器无法容纳大尺寸的分离透镜,由成像元件的微透镜汇聚光线,设置挡板遮住一半的光线,两个检测像素分别接收来自透镜两半的光线。如果合焦,来自透镜两半的光线强度一致;如果离焦,则光线强度会发生偏差。根据检测像素的偏差量计算出离焦量和离焦方向。
成像传感器相位检测将有限的像素作为对焦像素。如图6中灰色像素所示,这些用做对焦的像素只接收来自微透镜一半的光线,一般不参与成像。但是有限像素组成的对焦线阵由于面积有限,对焦系统获得光信号的总量只有普通像素的一半,因此弱光下对焦会有困难。对焦像素的微透镜和感光材料的尺寸及精度无法与透镜分离相位检测中的独立对焦系统媲美,其信噪比低,影响精度和可靠性。由于一部分像素只参与检测、不参与成像,因此会影响成像。此外,由于光路和成像问题,画面边缘部分对焦会有难度。
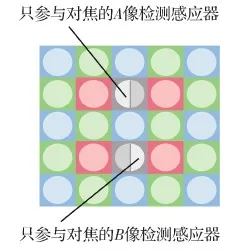
图6 混合自动对焦示意图Fig.6 Illustration of hybrid autofocus
1.4 全像素双核自动对焦
混合自动对焦使用有限像素进行相位检测,只在一定程度上提升了反差检测自动对焦的水平,无法达到相位检测自动对焦的水平。在弱光下,由于进光量不足,混合自动对焦的性能甚至不如反差检测自动对焦。因此为了改进混合自动对焦的缺点,佳能提出了全像素双核自动对焦,如图7所示,每个像素既参与成像又参与对焦。DP CMOS AF为每一个像素都配置了两个独立的光电二极管,例如Canon EOS 70D的2 020万有效像素配备了4 030万个光电二极管(考虑到老款镜头的适配性和成本因素,一些边缘像素未配备两个光电二极管)。为了突出每个像素被一分为二,而像素总数保持不变,dual-pixel的中文名称命名为“全像素双核”。每个光电二极管独立接受光线,在不同位置分别获取两个信号,通过比较两个信号的视差计算出镜头的驱动量和驱动方向,从而完成相位检测自动对焦。成像时拼合两个光电二极管A与B积蓄的电荷,作为一个像素进行读取,使得每个像素都参与对焦和成像,从而能够在不损失画质的情况下同时进行自动对焦和图像捕捉功能。
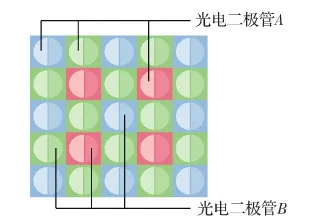
图7 全像素双核自动对焦结构示意图Fig.7 Illustration of dual-pixel autofocus structure
全像素双核自动对焦的原理为:DP CMOS AF中单个像素是无法独立进行相位检测的,它在水平方向上将多个像素连接,形成线性感应器(纵向线条感应器),调动多个像素进行对焦。RGB滤镜下,观测邻近像素左侧子像素光电二极管的成像信号与哪些像素的右侧子像素的成像信号存在关联,经过处理后解算对焦信息。其中的线性感应器的长度相当于取景器自动对焦感应器的基线,它会随光圈产生变化。
在合焦状态下,两个子像素的光电二极管的成像是重合且清晰的,但在离焦状态下则是模糊且错开的,而且位于焦前和焦后的图像视差是相反的,如图8所示(https://www.canon.com.cn/special/dualpixelcomsaf/principles.html)。因此,通过检测两个信号的视差,便可计算出聚焦过程中镜头的驱动方向和驱动距离。

图8 全像素双核自动对焦示意图(佳能)Fig.8 Illustration of dual-pixel CMOS AF(佳能中国,2013)((a) there is no disparity between two images when focusing; (b) disparity of two images when the focus is forward; (c) disparity of two images when the focus is backward)(Canon China, 2013)
全像素双核自动对焦的优点包括:
1)以全像素双核CMOS AF为例,它仅通过图像传感器相位检测完成对焦,不需要复杂的光学结构,比传统的相位检测自动对焦更简单、成本更低。能够实现高速对焦,且传统的反差检测自动对焦速度的5倍,比混合自动对焦的对焦速度提升了约30%。
2)DP所有像素均具有成像和对焦功能,绝大多数像素都参与对焦,相比混合自动对焦中有限像素参与成像,DP自动对焦受光面积更大、信噪比高、对焦范围比光学取景器更大。
3)DP每个像素接收到的光信号与普通像素相近,不再是普通像素的一半,而且相邻像素在计算差异值时可以互相验证,起到监督作用。因此对焦效率提升,对弱光的对焦性能也得到提高,不受特定的镜头光圈孔径限制。
全像素双核数据的获取方式为:目前佳能大多数单反相机和多款微单相机已经搭载了DP CMOS AF传感器。但是只有单反相机Canon EOS 5D Mark IV 和微单相机Canon EOS R5能够在佳能官方照片处理软件Digital Photo Professional中读取并处理全像素双核图像对。
为了将DP自动对焦的优势应用到手机相机上,CMOS厂商研发了多款手机相机传感器,如三星的S5KGN1、GN2,索尼的IMX555、IMX563等。绝大多数的智能手机厂商如谷歌、三星、小米、VIVO和魅族等将DP传感器配备在手机相机中,手机行业对全像素双核另一种表述为dual photo diode(Dual PD)。谷歌将全像素双核搭载在Google Pixel2,Pixel3,Pixel4等智能手机的相机中。使用谷歌特定的软件可以在Google Pixel上提取出DP数据,但是谷歌提供的DP图像并不是RGB三通道的图像,而是绿色单通道的灰度图像。
此外,富士、尼康、奥林巴斯和松下已申请了DP自动对焦(或非常相似)系统的专利。
2 全像素双核成像原理
2.1 全像素双核成像模型
Pan等人(2021)将全像素双核相机建模成一个满足微透镜模型的相机,可同时捕获两幅图像。在该模型中,相机焦平面被一分为二。一半焦平面捕获来自透镜左半部分的光线;另一半焦平面捕获来自透镜右半部分的光线。相机镜头被一分为二,两幅图像被看做由两个共面透镜捕获的图像。DP成像模型可近似为小孔成像模型和透镜成像模型。
全像素双核近似的小孔成像模型如图9所示,假设来自左图像IL的光线通过透镜左半部分区域AL,来自右图像IR的光线通过透镜右半部分区域AR,假设区域AL和AR尽可能小,看做是由两个点CL和CR组成。
在该模型中选定坐标系,透镜所在平面为X=0,透镜中心为原点。现实世界的场景位于透镜左侧(X<0的区域),由点集X=(X,Y,Z),X

图9 全像素双核近似的小孔成像模型(Pan等,2021)Fig.9 Pinhole imaging model based on dual-pixel approximation (Pan et al., 2021)
若针孔相机模型以点CL为投影中心且具有与透镜成像模型相同的焦平面,则传感器平面的成像与实际的DP传感器成像相同,成像平面获得左视图IL。同理,通过CR的小孔成像模型可得右视图IR。
全像素双核近似的透镜成像模型如图10所示,不同于DP小孔成像模型,DP透镜成像模型的透镜平面的光线汇聚区域不再看做小孔,而是半个透镜。光线从深度为d的场景点X穿过区域AL和AR,折射的光线聚焦于点X′,形成一个双面锥体,顶点为X′。

图10 全像素双核近似的透镜成像模型(Pan等,2021)Fig.10 Lens imaging model based on dual-pixel approximation (Pan et al., 2021)
这个锥体与深度为F的传感器平面相交于一个区域A′L和A′R,该区域的形状与AL和AR类似。区域AL和AR比小孔成像模型的区域更大,事实上,它们各自占透镜一半的区域。图像IL和图像IR是光线通过区域AL和AR在传感器平面上所成像的叠加。合焦图像是清晰的,而离焦图像将出现模糊,这种模糊与深度相关。出现这种模糊的原因是:真实世界中的一些点成像在焦平面处,这些点通过AL和AR,IL和IR成像在焦平面的同一个位置,因此左右视图叠加后它们是清晰的。而那些无法成像在焦平面处的点,IL和IR成像不在同一位置,叠加后是模糊的,并且呈现出视差。
2.2 全像素双核仿射歧义性
Garg等人(2019)指出DP图像不仅存在尺度歧义性(scale ambiguity)(Lowe,1999),而且还同时存在仿射歧义性(affine ambiguity),后者指不同的相机参数集和场景几何会产生相同的DP图像。
传统双目成像随着场景深度的改变而发生变化,如图11(a)所示。但是对于DP图像,随着深度的改变,如果相机的焦距、光圈和聚焦距离等参数发生变化,成像可能不会发生改变,这就是DP的仿射歧义性。光圈、焦距不变时,景深和对焦距离改变但和不变,最终成像相同,如图11(b)所示。
假设相机坐标系下存在一个以(x,y,D(x,y))为点光源的场景,像平面处的视差d(x,y)与离焦模糊量b(x,y)成正比,其中离焦模糊量的正负由点光源位于焦平面的前后决定。由近轴和薄透镜成像近似可得

(1)
式中,α为比例常数,L为光圈孔径,f为焦距,g为聚焦距离。式(1)通过定义A(L,f,g)和B(L,f,g)来表示深度与视差的关系。如果相机焦距、聚焦距离和光圈已知,则可以由DP两视图的视差推导出场景深度D(x,y)。
同时,式(1)也说明DP数据具有仿射歧义性。因为两组不同的相机参数可能会产生两组不同的仿射参数(A1,B1),(A2,B2), 继而导致不同的景深D1(x,y),D2(x,y)可能产生相同的平面视差,即
(2)
事实上,解决这种仿射歧义性最简单的方法是,利用相机内参(焦距、聚焦距离和光圈等)数据和图像视差,根据式(1)估计绝对深度。但是手机相机在记录相机内参数据时并不可靠(DiVerdi和Barron,2016),因此无法获得准确的绝对深度。但是从式(2)可知,DP视差d(x,y)与深度D(x,y)呈负相关,网络可根据DP视差预测一种相对深度D(x,y),但是该深度相比较绝对深度具有仿射歧义性和尺度歧义性,下文将其称为仿射歧义性深度。仿射歧义性深度是一种相对深度,能够体现绝对深度的变化。
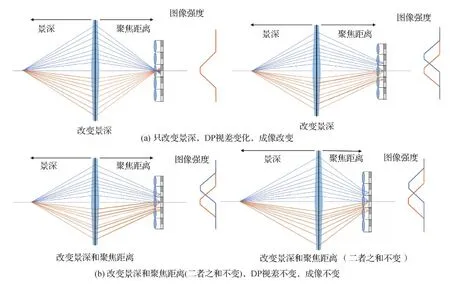
图11 全像素双核的仿射歧义性示意图Fig.11 Illustration of the affine ambiguity for dual-pixel((a) only change the depth of field, DP disparity changes, imaging changes; (b) change the depth of field and focus distance (the sum of the two remains unchanged), DP disparity remains unchanged, and imaging remains unchanged)
在Garg等人(2019)采集的数据集中,绝对真值深度被转换为具有仿射歧义性的视差。为了在该仿射歧义性下训练网络估计的仿射歧义性深度,Garg等人(2019)构造了仿射不变的损失函数(见3.1节)。即使绝对真值和网络输出均具有仿射歧义性,网络仍能够正确估计出具有仿射歧义性的深度。
相对深度顺序可以用于手机相机合成离焦模糊。手机相机光圈普遍较小,离焦模糊弱,利用式(2)的DP视差估计的仿射歧义性深度顺序可以模拟大光圈的强离焦模糊效果,在拍摄人像、微距时可以提升图片的美观程度。
2.3 全像素双核的点扩展函数
点扩展函数是点光源在成像平面的光场分布。在聚焦区域,点扩展函数可近似看做一个单位脉冲响应,但是多数情况下,使用弥散圆(circle of confusion, COC)表示点扩展函数。弥散圆是在焦点前后,光线聚散,物点在像平面形成的一个扩散的圆(吴佳泽 等,2011)。如果弥散圆的直径足够小,则成像清晰;如果圆形半径变大,成像会变得模糊,如图12所示。

图12 弥散圆与景深的关系Fig.12 The relationship between COC and depth of field((a) as the aperture increases, the diameter of COC becomes larger and the image becomes blurred; (b) as the aperture shrinks, the diameter of COC becomes smaller and the image becomes clear)
在双目立体图像对中,视差可以看做是图像内容的显式偏移。对于DP图像对,其视差是由点扩展函数产生的(Punnappurath和Brown,2019),视差与模糊量直接相关。在双目和DP的成像模型中,位于焦平面处的点,其点扩展函数都可以近似为一个单位脉冲响应。但是对于焦平面之外的点,双目图像对弥散圆的形状是一个圆盘形的模糊核,如图13(b)所示(图13(b)仅展示了双目中一张视图的点扩展函数)。DP传感器焦平面之外的点的弥散圆的形状为模糊核的一半,左右视图的弥散圆是对称的。此外,位于焦前和焦后的点的对应视图的弥散圆也是翻转的。视差与弥散圆的半径大小成正比,而视差的正负也与弥散圆半径的符号一致,如图13(c)所示。

图13 全像素双核传感器和传统传感器的弥散圆对比Fig.13 Comparison of COC between DP sensor and traditional sensor((a) traditional sensor vs DP sensor; (b) COC of traditional sensor; (c) COC of DP sensor)
2.4 全像素双核图像对与立体图像对的区别
DP的两个视图近似可以看做基线非常微小的立体图像对。但DP图像对与双目立体图像也存在如下差异:
1)DP图像对是完全同步的(在时间和空间上),并且具有相同的曝光和白平衡。
2)DP图像对具有可以编码额外深度信息的不同的点扩展函数。由此也为DP在应用双目立体视觉技术时带来了问题:传统的双目匹配技术在应用DP数据时,常常会忽视由焦点产生的额外深度信息;由于两视图的点扩展函数存在不同,传统的双目匹配可能会在离焦区失败。
3)DP图像对只在离焦处存在视差,合焦处几乎不存在视差。视差与深度的关系满足式(2);视差与离焦模糊量的关系满足式(1)。
3 全像素双核在计算机视觉中的应用
自2018年以来,全像素双核因其独特的成像原理、特性和潜在的应用,逐渐受到学术界关注。近年来计算机视觉的顶级会议都发表了一部分DP数据应用的论文,其应用领域也从深度估计逐渐扩展到反射去除、离焦模糊去除等领域,论文数量呈现逐年上升趋势,如表1所示。本节主要从深度估计、反射去除和离焦模糊去除3个方面介绍DP数据在计算机视觉的应用。
3.1 基于全像素双核数据的深度估计
深度估计一直以来都是计算机视觉领域的核心问题之一,既是视觉感知的基本组成部分,也服务于多种图像处理、图像识别和机器人的任务。场景深度可以使用特定的深度检测硬件设备(如激光雷达)直接获取,但是这类设备价格昂贵,并受限于环境。多视角几何技术结合多个相机可以推测深度(Hartley和Zisserman,2000),但是这些相机需要进行校正、标定和同步等复杂的过程,其计算复杂度高(毕天腾 等,2018)。而基于深度学习的单目深度估计的方法也存在图像成像过程中约束不足导致预测不准确的问题。DP相机在拍摄时能够提供两张子视图,这既为双目立体视觉算法开拓了应用场景,也为单目深度估计提供了新的方式。
景深往往由相机的光圈大小决定,较大的光圈会产生浅景深,而较小的光圈则产生宽景深。目前智能手机上传统的合成景深方法是使用双摄进行深度估计,根据深度图对图像进行浅景深合成,但这会增加生产成本,占据手机物理空间。也有一些厂商在手机上直接使用图像雷达方法(即飞行时间技术(time-of-flight))和结构光技术进行深度估计,但是这些硬件往往非常昂贵,并且难以在室外使用(黄军 等,2019)。为了节约成本、节省空间,Wadhwa等人(2018)提出了第1个使用配备DP传感器的单目相机合成浅景深的技术,并将其集成到Google Pixel的手机软件中。
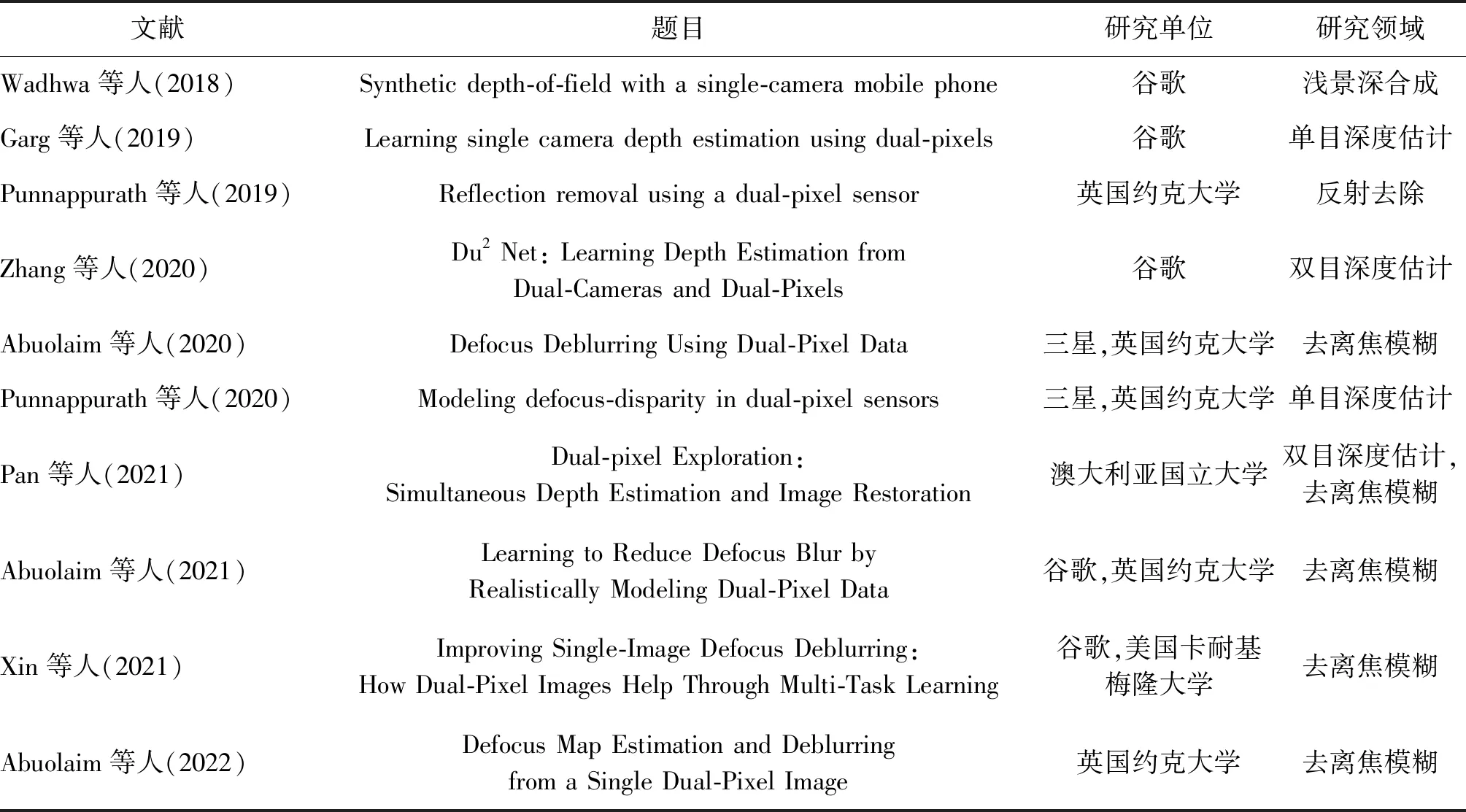
表1 全像素双核技术应用研究统计Table 1 Research status and statistics of dual-pixel
Wadhwa等人(2018)提出了3种算法,分别应用到3种不同的场合中。第1种算法将DP和人体分割网络结合,合成浅景深,对背景进行虚化处理。该方法适用于配置了DP传感器的相机拍摄人像的场景。当人物与背景颜色相近时,人体分割网络经常会分割错误。DP的加入使得网络面对这种问题时鲁棒性更好。第2种算法只使用DP数据合成浅景深,适用于配置了DP传感器的相机拍摄物体的场景;第3种算法只应用了人体分割网络,适用于使用非DP传感器相机(通常是前置摄像头)拍摄人像的场景。前两种方法都使用了DP数据来生成稠密深度图,它们首先对DP图像执行平均和对齐操作以减少噪声,然后使用立体算法推导出一组低分辨率和带有噪声的视差图。最后使用校准程序对视差图进行校正,使用双边空间技术对校正后的视差进行上采样与平滑,最终生成高分辨率的视差图。在进行面部检测时,如果画面中人数较多,传统技术会出现一些人随着背景被模糊的问题。因为DP数据可以得到背景与人的合理视差,所以使用DP数据可以帮助缓解这种问题。但是,使用DP数据会产生孔径问题(Morgan和Castet,1997),与基线平行的图像结构将无法被识别。而与人体分割网络融合可以消除这种问题对人像分割的影响。但是在非人像的场景以及人像照片的背景中,孔径问题仍然存在。该方法是第1个将DP传感器引入计算机视觉的方法,尽管在特定场景下仍存在传统的视觉问题,但是对于配备DP传感器的单摄手机具有重要的意义。
受该工作的启发,Garg等人(2019)发现由于DP图像视差与焦点的相关作用使得经典的立体算法与基于先验学习的单目深度估计算法表现不佳,于是他们分析了DP的仿射歧义性,并提出一种新的单目深度估计方法在这种仿射歧义性的尺度下进行深度估计。他们使用了5个不同视角的RGB图像与DP数据配对,以此监督这种未知的仿射歧义性下的深度预测结果。
Garg等人(2019)使用单目深度估计常用的自监督损失来监督网络。一般的视觉自监督损失函数表示为
(3)
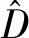
为了对仿射歧义性下的深度预测结构进行自监督,Garg等人(2019)提出了两种损失函数:分别是3D assisted loss和Folded loss。
3D assisted loss计算为

(4)
Folded loss不需要绝对真值深度,而是使用了优化方法求解仿射参数。将变量a和b与每个训练实例I0相关联,定义如下损失函数

(5)
并对θ,a,b进行梯度下降优化
(6)
Garg等人(2019)使用VGG(Visual Geometry Group)模型架构(Godard等,2017)和类似U-Net网络(Ronneberger等,2015)的具有残差块(He等,2016)的轻量化网络DPNet作为其单目深度估计网络。
由于DP图像存在的仿射歧义性,DP预测的深度并不与绝对深度对应,因此无法使用常规指标进行评估。Garg等人(2019)使用斯皮尔曼等级相关(用绝对真值深度的置信度作为权重,评估估计深度的序数正确性)的加权变量作为评估指标。除此之外,该任务还使用仿射不变性的加权版本平均绝对误差(mean absolute error, MAE)和均方根误差(root mean squared error, RMSE)作为评估指标。DPNet在应用DP数据时,使用的损失函数提高了基于单目深度估计方法的视觉监督的精度,与只使用RGB图像作为输入相比,DPNet的性能有很大提升,证明了DP在深度估计的优势。该方法首次提出全像素双核几何,揭示了全像素双核成像中深度与模糊量之间的关系,为之后多个领域研究提供了理论基础。但该方法也存在缺点:对于远距离的无纹理物体,深度预测的准确度会急剧下降。
尽管经典的立体算法在应用DP数据时效果不佳,但是将DP与双目图像结合能够解决很多传统的双目匹配中的问题。众所周知,双目立体视觉被孔径问题、遮挡问题和重复纹理等问题困扰,因此为了克服纯双目立体匹配的限制,Zhang等人(2020)提出了第1种将双目图像和DP图像相融合的深度估计神经网络。但是由于DP仿射歧义性的存在,DP图像和双目图像无法直接整合,因此他们还提出了一种方法融合DP和双目视觉的置信体,在视差细化阶段结合DP数据推导最终的精准视差图。
因为DP图像之间的基线较小,因此两视图之间的遮挡区域更少,在物体边界附近,DP估计的深度比双目相机估计的深度更精准。但是微小的基线也会导致远距离处估计的深度更差。因此Zhang等人(2020)提出将双目相机与DP传感器融合的方法,设定一个双目系统,其中的一个相机具有DP传感器。来自双目相机和DP两种深度的误差互补,这样的设置可以保证在近距离、远距离以及物体边界附近获取精确的深度,以弥补二者的不足。此外,双目相机与DP的基线是正交的,可以避免孔径问题,即能够估计平行于二者基线的图像纹理区域的深度。
DP和双目相机基线正交,缓解了孔径问题和重复纹理引起的误差。此外,Du2Net克服了DPNet准确率随着距离增加而急速下降的问题。其在遮挡边界处表现优异,因此在合成浅景深的应用中能够更好地避免物体边界的伪影问题。Du2Net在高频细节和纹理场景表现精准,但在无纹理区域表现相对较差。在3D图片的结果中,Du2Net深度误差导致了场景结构的非自然变形。针对出现的问题,Zhang等人(2020)也提出了改进方案:1)结合附加模式的信息,例如主动深度传感器;2)考虑将两个相机镜头都配备DP传感器。

图14 Du2 Net网络结构图(Zhang等,2020)Fig.14 Overview of the Du2 Net network structure (Zhang et al., 2020)
3.2 基于全像素双核数据的反射去除
DP图像对在离焦处存在视差,利用该离焦视差能够区分图像中清晰的前景与模糊的背景。受离焦视差的启发,Punnappurath和Brown(2019)提出了一种利用DP图像对去除反射的新方法。该方法应用DP数据的离焦视差,获得背景层与反射层的梯度,进而将该梯度信息整合到优化框架,能够以更高的精度从单幅图像中提取背景层。此外,他们还收集了第1个由DP数据组成的反射去除数据集。
Punnappurath和Brown(2019)利用DP传感器的离焦视差区分反射层和背景层。他们做了两种假设:1)假设背景层比反射层有更强的图像强度;2)假设背景层场景位于相机景深内,反射层场景位于相机景深外。在这种情况下,观测到的图像是合焦背景层和离焦反射层的叠加。
基于这种假设,Punnappurath和Brown(2019)提出了图15(a)中的成像模型。合焦位置处的背景物体发射的光线通过透镜聚焦到传感器的单个像素上。合焦处没有视差,左右视图强度值的总和作为该像素处的图像强度存储。观测反射层的金字塔物体,来自该物体一点的光线聚焦在传感器平面的前面,并在传感器上产生5像素宽的离焦模糊图像。DP图像对的视差与模糊大小成正比,如图15(d)所示。经左右信号相加获得模糊的反射图像,如图15(e)所示。最终,合成的DP图像是合焦背景层(零视差)与离焦反射层(非零视差)的叠加。图15(f)(g)体现了视角之间的转换,最终的合成图像如图15(h)所示。
设b代表背景层,f代表潜在的反射层,合成的DP左视图gLV和右视图gLR可分别表示为
(7)
(8)
式中,矩阵WLV和WRV与背景层f分别相乘,产生左右视图的离焦和偏移的半强度部分。观测到的图像g=gLV+gRV=b+r,其中r代表模糊的反射层,r=(WLV+WRV)f。
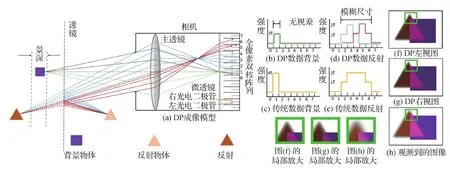
图15 全像素双核相机捕获的带有反射场景的成像模型(Punnappurath和Brown,2019)Fig.15 Imaging model of scene with reflection captured by a dual-pixel camera (Punnappurath and Brown, 2019)((a) DP imaging model; (b) background of DP data; (c) background of traditional data; (d) reflection of DP data; (e) reflection of traditional data; (f) DP left image; (g) DP right image; (h) observed images)
Levin和Weiss(2007)提出标定输入图像的梯度可以作为反射去除的一个重要机制。受这种方法的启发,Punnappurath和Brown(2019)提出利用DP的离焦视差自动判别哪些梯度属于背景层,哪些梯度属于反射层,并由此构建出反射层和背景层的梯度图。背景层和反射层之间的清晰度差异为反射去除提供了另一个有价值的线索。离焦的反射层比合焦背景层有更少的大梯度。Punnappurath和Brown(2019)的方法以离焦视差为主要线索,结合背景层和反射层之间的清晰度差异,在分离反射层和背景层时能够具有更高的鲁棒性。但是该方法也存在一定的局限性:由于其假设反射层处于离焦状态、背景层处于合焦状态,如果反射的场景和背景层场景到玻璃板的距离近似相等,即两个层都是合焦的,而且视差小到难以观测,则该方法无法完全区分两层的梯度。
3.3 基于全像素双核数据的离焦模糊去除
车载摄像头往往具有固定的快门速度,要获得充足的光线,唯一的方法是采用大光圈。但是使用大光圈拍摄浅景深图像会产生离焦模糊,由于模糊是随空间变化的,且难以预测,因此校正离焦模糊便成为一项亟待解决的任务。
DP图像对的视差与点扩展函数中弥散圆的尺寸成正比(弥散圆尺寸是模糊程度的表征),且视差的方向也与弥散圆的方向一致(详见2.3节),因此在使用DP数据进行离焦模糊去除的任务时,充分利用视差与离焦模糊之间的关系尤为重要。
Abuolaim和Brown(2020)提出了第1个基于学习的使用DP数据去除离焦模糊的方法,并捕获了一组包含DP图像的数据集。Abuolaim和Brown(2020)设计的深度神经网络DPDNet(图16)结构上类似U-Net,输入为DP图像对,输出为三通道的sRGB图像。

图16 DPDNet网络结构图(Abuolaim和Brown,2020)Fig.16 Overview of the DPDNet network structure (Abuolaim and Brown, 2020)
为了更好地处理较大的离焦模糊,以扩展感受域的大小,网络使用了多个池化层进行下采样。经过实验,DPDNet能够以较高质量去除离焦模糊。网络对不同光圈设置均适用,即使测试时场景的光圈设置与训练时不同,网络同样可以进行去模糊处理。但是该方法并未显式地将DP离焦视差与离焦模糊量之间的关系引入到网络中;而是将整幅图像无差别地输入网络,并未考虑图像中不同模糊区域之间的差异。
Abuolaim等人(2021)在上述工作的基础上进一步改进。针对DP数据采集受限问题,构造了一个DP数据模拟器,合成具有离焦模糊的DP数据集。此外,还提出了一个利用DP数据进行视频去模糊应用的循环卷积神经网络(recurrent convolutional neural network, RCN)。该方法不仅在原方法的基础上得到了改善,还在众多去离焦模糊的方法中表现出优异的性能。DP模拟器原理将在4.4节进行详细介绍。该模拟器接收多帧DP图像对作为输入,首先经过编码层提取特征,随后通过ConvLSTM(convolutional long short term memory)层学习时序输入的时间动态特征。ConvLSTM将LSTM中的点积计算转换为卷积计算以保存空间信息。然后,通过解码ConvLSTM的输出得到最终的去模糊图像。
与上述工作类似,Pan等人(2021)同样提出了一个DP数据模拟器,并设计了一个使用DP的端到端神经网络(DDDNet)用于深度估计和去离焦模糊。结合DP仿真器构造了Reblur loss,用于为深度估计提供监督。网络结构如图17所示。

图17 DDDNet网络结构图(Pan等,2021)Fig.17 Overview of the DDDNet network structure (Pan et al., 2021)
该网络可以分为两部分:基于Cheng等人(2020)的DepthNet和基于Zhang等人(2019)的DeblurNet。先由DepthNet估计出粗略的深度图,再将粗略的深度图和模糊的左右视图输入DeblurNet得到去模糊的图像和精确的深度图。数据集具有深度真值,对深度网络直接监督。同时,DeblurNet输出的去模糊图像输入到作者提供的仿真器中生成两幅模糊的DP图像对,与输入的DP图像对计算Reblur loss,对网络进行监督。
该方法使用双目网络对DP进行深度估计,并将深度信息融入去离焦模糊过程中。但是该方法同样没有考虑到图像中不同模糊区域之间的差异。
考虑到难以捕获大规模的DP数据,Xin等人(2021)使用多平面图像(multiplane image, MPI)的优化方法从DP图像中恢复离焦图和全聚焦图像,并合成了DP图像对。
4 全像素双核数据集
当前DP公开数据集有6个,其中2个用于估计深度:DPNet dataset(Garg等,2019)、Du2Net dataset(Zhang等人,2018);3个用于去除离焦模糊DPD(dual-pixel defocus deblurring dataset)(Abuolaim和Brown,2020)、DPD-disp(the defocus depth estimation dataset)(Punnappurath等人,2020)和DP-based DDD(depth and deblur dataset)(Pan等人,2021);1个用于去除反射DPRR(dual-pixel reflection removal dataset)。
4.1 全像素双核深度估计数据集
DPNet dataset(Garg等,2019)的图像采集装置如图18所示,作者构造了一个由5台Google Pixel组成的采集设备:带有DP传感器的中央摄像头和4个分布在四周的摄像头。使用COLMAP(Schönberger等,2016)立体技术获取了绝对真值深度。数据集使用了两款具有DP传感器的手机:Google的Pixel 2和 Pixel 3采集数据。数据集包括3 575个场景,一共3 575×5=17 865幅RGB和DP图像(Google Pixel采集的DP图像为单通道RGB图像)。RGB和DP图像的分辨率为1 512×2 016像素,但是为了降低噪声,以该分辨率的一半计算绝对真值深度图。在数据预处理时,使用中央裁剪的方式将DP图像裁剪到原始分辨率的66.67%。裁剪后,网络输入分辨率是1 008×1 344像素,输出分辨率是504×672 像素,与绝对真值相同。训练集包括2 757幅图像,测试集包括718幅图像。

图18 DPNet dataset具有同步相机的数据采集模型(Garg等,2019)Fig.18 Data capture rig with synchronized cameras for DPNet dataset (Garg et al., 2019)
Du2Net dataset(Zhang等,2018)使用5台同步的Google Pixel 4手机捕获数据集。每台手机都有一组由配备DP传感器的主摄和一个普通长焦镜头组成的双摄系统,采集时将主摄作为右相机,长焦镜头作为左相机,相机排布与图18相同。每次拍摄捕获10幅RGB图像,利用多视角几何技术在10个视角估计绝对真值视差图。使用运动恢复结构(structure from motion, SfM)的3维重建算法和多视角几何技术生成深度图。与Garg等人(2019)方法相同,通过检查相邻视图的深度一致性来计算每个像素的深度置信度。该数据集收集了3 308幅训练图像,1 077幅测试图像。调整网络输入的大小以使之匹配预测的分辨率和绝对真值视差(448×560 像素),DP图像的分辨率是1 000×1 250像素。
4.2 全像素双核去除离焦模糊数据集
DPD(Abuolaim和Brown,2020)使用 Canon EOS 5D Mark IV单反相机的光圈优先模式采集数据。该数据在500个场景下,拍摄3组照片:1)使用大光圈(f/4)捕获的离焦模糊图像;2)两张DP视图;3)小光圈(f/22)拍摄的全焦图像。所拍摄照片的分辨率为6 720×4 480像素,低噪声(低ISO),最终处理为sRGB格式,以每个RGB通道无损16位深度进行编码。同时也使用Google Pixel 4采集了部分图像用于测试。
DPD-disp(Punnappurath等,2020)使用Canon EOS 5D Mark IV单反相机捕获数据集。收集的数据集提供具有深度图的DP图像。使用Canon EOS 5D Mark IV在10种不同的焦距设置下拍摄了12张明信片,其中10张作为训练集,2张作为验证集,共120幅RGB图像,120对DP图像。对DP图像对中心66%的区域进行裁剪,得到111×111像素的图像块(patch)用于训练和验证。总共生成了17 500个patch用于训练,2 100个patch用于验证。同样,使用Canon EOS 5D Mark IV在10组不同焦距的设置下拍摄了多个场景,每组包括75-90幅图像。不同于训练集,测试集的背景多是一些纹理复杂的印刷海报,其利用离焦估计深度(depth-from-defocus)技术计算绝对真值深度图。
DDD(Pan等,2021)则包括两种数据集:1)使用Canon EOS 5D Mark IV单反相机捕获的真实数据集,其中包括在多种光照条件下捕获的150个室内室外场景。光圈值从f/4到f/22之间变化,每一幅全聚焦图像(f/22)都与多幅离焦模糊图像相关联,从而产生了多样性的数据集。2)Pan等人(2021)提出了DP模拟器(DP simulator),该模拟器能够从任何RGBD数据中创建DP图像对。以NYU(New York University)深度数据集(Silberman等,2012)作为输入,输出DP图像。给定不同相机参数,模拟了500个图像对进行测试。
4.3 全像素双核反射去除数据集
Punnappurath和Brown(2019)使用Canon EOS 5D Mark Ⅳ相机捕获数据集,捕获的数据集包括两种类型:具有绝对真值的室内场景和室外场景。基于Wan等人(2017)的单图像反射去除数据集的捕获方法,Punnappurath和Brown(2019)对室内数据集使用不同的明信片作为背景和反射。选择纹理复杂度从中到高的明信片,将其成对组合,作为背景层和反射层,使捕获到的数据集具有复杂的重复纹理。数据集最终选择6张明信片作为背景,5张明信片作为反射,总共组合了30个场景。
离焦模糊大小和视差都是光圈的函数,为了评估算法的离焦模糊程度和视差程度的鲁棒性,实验选择了5个光圈值{F13, F10, F8, BZ.6, F4}。每个场景都使用5个光圈捕获图像,从而为室内数据集提供了150幅图像。
4.4 全像素双核模拟器
Pan等人(2021)和Abuolaim等人(2021)均提出了DP模拟器,但是二者采取了不同的建模方式构造模拟器。Pan等人(2021)基于透镜成像模型和小孔成像模型建模了DP成像模型。Abuolaim等人(2021)则构造DP的点扩展函数生成数据。本节将重点阐述两种DP模拟器的原理。
4.4.1 基于成像模型的全像素双核模拟器
Pan等人(2021)构造的DP模拟器能够在给定原始RGB图像及其对应的深度图的前提下,生成一对DP图像。
RGB-D图像与DP图像的关系如图19所示,RGB-D图像提供图像中所有可见点的3D坐标。假设世界坐标系中一点X=(X,Y,Z),对应在虚拟空间(透镜右侧的空间)中的点为
式中,f代表焦距。
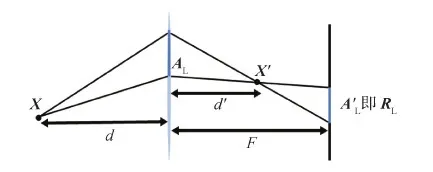
图19 全像素双核成像模型(Pan等,2021)Fig.19 Imaging model of dual-pixel (Pan et al., 2021)
区域A(以AL为例)中的点C映射到像平面A′L的点C′=sC+t。这里的t表示2维偏移,s表示缩放。对于给定的点X,s和t的值是连续的,与C点的选取无关,而与X点的选取有关。通过相似三角形得
C′=T(C)=(1-s)C+sX′
(9)
式中,s=F/d′,F表示像距,即传感器平面到透镜平面的距离。式(9)表明了在世界坐标系下,像平面的点与透镜平面的点的映射关系。
由于RGB-D图像中每个像素都有其对应的深度,假设图像中一点的像素坐标为(y,z),定义空间中其对应的光线为-d(1,y/f,z/f),随d的变化而变化。图像坐标系下的一点(y,z)转换到世界坐标系下的3D坐标为-d(1,y/f,z/f)。点X=-d(1,y/f,z/f)映射到像平面上的点X′=d′(1,y/f,z/f),其中1/d+1/d′=1/f。
C=(0,Y0,Z0)是位于区域A的点。起点为C,通过X′的光线被表示为式(9)所示的(1-s)C+sX′,其值随s变化。当s=F/d′时,该光线与传感器平面相交,因此对应在传感器平面上的点坐标为
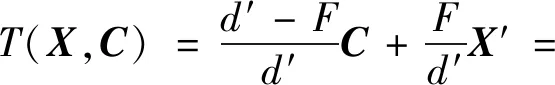
(10)
在图像坐标系下
(11)
该式表示了图像坐标系下,像平面的点T(X,C)与真实世界场景点(y,z)之间的关系。由于(Y0,Z0)表示透镜平面AL上的点,因此真实世界的场景点(y,z)映射到像平面的点T(X,C)应为一个点集,即真实世界到像平面的映射为点到面的映射。
基于成像模型的DP模拟器原理为:给定一幅清晰图像及其深度图。如图19所示,在图像坐标系中,对于图像中的每个像素(y,z),像素的强度分布在DP的左视图和右视图中的区域RL和RR上,RL即图19中的A′L。每个区域包含一组点p,其中包含|R|个像素,并且像素(y,z)的强度In(y,z)均匀地分布在这组点集上。遍历所有像素(y,z)求和,从而生成了一对DP图像对。这可以理解为每个真实世界中的点映射到像平面的一个区域,这个区域即模糊核/弥散圆,它与深度相关。遍历像素求和的操作非常耗费计算量,它需要遍历图像上的每一个像素(y,z),并且需要遍历区域R上的每一个像素。为了节省计算量,作者利用“积分图像”的概念来加速计算,使得它的复杂度与区域R的大小无关,从而达到O(n)级,其中n是像素数。
假设光圈的左半部分和右半部分是近似矩形,给定深度的RGB-D图像的一个像素(y,z),其对应的光线将穿过AL的每个点。为了计算像平面的模糊区域RL的面积,只需计算穿过AL的4个顶角的光线的终点,即
ptl=(ytl,ztl),ptr=(ytr,ztr)
pbl=(ybl,zbl),pbr=(ybr,zbr)
(12)
这4个点的位置由式(11)给出。下标tl、tr、bl、br分别表示左上角、右上角、左下角和右下角。为区域RL创建一个差分掩膜IL,即
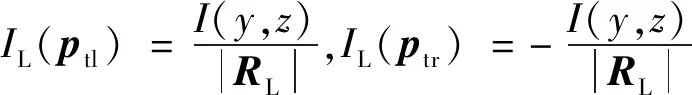
(13)
对图像中的所有点(y,z)在像平面对应的区域对式(13)的4个公式求和,以创建差分图像。最后对差分图像进行积分,得到DP图像对的左/右视图
IL,R=T(IL,R)
(14)
式中,T表示积分操作。
该仿真器建立了图像坐标系下真实世界场景点到图像的映射关系,能够模拟DP成像过程中与深度/视差紧密相关的模糊核,还通过将透镜近似为矩形和积分的方法减少了仿真的计算量和复杂度。
4.4.2 基于点扩展函数的全像素双核模拟器
Punnappurath等人(2020)建模了DP的点扩展函数,该模型能够模拟DP左右图像对之间点扩展函数的对称性,但是该模型较为简单,只与弥散圆大小有关,并不能完全反映真实的DP点扩展函数。
真实的点扩展函数如图20(a)所示,由于光学像差,弥散圆中呈现圆环形的损耗。因此,为了更接近真实的建模,Abuolaim等人(2021)基于2维的巴特沃斯滤波器B提出了一个参数化的模型
(15)
式中,n代表滤波器的阶数,参数D0取决于3 dB截止点。为了模拟DP图像对弥散圆中的点扩展函数模型,Abuolaim等人(2021)基于上述的巴特沃斯滤波器定义了参数化的DP模型,如图20(c)所示
H=B∘COC(x0,y0)
(16)
式中,COC代表弥散圆圆环,“∘”表示阿达玛积运算符(矩阵对应元素相乘)。B和COC都以(x0,y0)为中心,H代表DP左右视图的点扩展函数之和
H=Hl+Hr
(17)
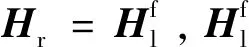
Hl=H∘M
(18)
式中,M是具有恒定衰减性质的2维斜坡掩膜,这种衰减可以看做在给定方向的强度衰减。该方向由薄透镜模型计算的弥散圆半径的符号决定,正号表示位于焦平面之后的物体模糊,负号表示位于焦平面之前的物体模糊。该点扩展函数模型使用5个参数进行参数化,更接近真实的点扩展函数形状。此外,为了使数据集更加真实,模拟器还仿真了径向畸变和图像噪声。

图20 全像素双核点扩展函数Fig.20 Dual-pixel point spread function((a) the real DP PSF; (b) PSF modeled by Punnappurath et al. (2020); (c) PSF modeled by Abuolaim et al. (2021))
Abuolaim等人(2021)使用SYNTHIA(the synthetic collection of imagery and annotations)数据集(Juarez等,2017)作为数据源。该数据集包含来自虚拟城市的GC渲染图像序列。每个序列平均有400帧。该数据集还包括深度图及其标记的分割图。合成DP视图的过程如下:
首先根据每个像素的深度值将图像分为多个离散层。然后将每个离散层与上述建模的参数化点扩展函数进行卷积。接下来,按照从后到前的顺序对模糊的每个离散层图像进行alpha混合。对于每个全聚焦的视频帧Is,能够生成两张DP子视图IL和IR
IL=Is*HL,IR=Is*HR
(19)
式中,Is是所有像素来自相同深度的一个离散层。“*”代表卷积操作。随后,对IL和IR分别添加相应的噪声和径向畸变以模拟多样性。合成最终的离焦模糊图像Ib=IL+IR。
5 全像素双核的挑战与展望
尽管DP传感器在工业界广泛应用于各种单反相机、微单相机和智能手机自动对焦,DP在计算机视觉的深度估计、反射去除和离焦模糊消除方面也已取得初步效果,但是在将DP深入精准应用计算机视觉问题时,仍面临着很多问题和挑战。
1)DP图像对之间存在离焦视差,基线只有几个像素,相比双目的基线十分微小,因此在低分辨率的图像或经过下采样后的特征图中,会损失一部分离焦视差信息。如何充分利用离焦视差与模糊量之间的关系,提高去模糊效果是一个值得考虑的问题。目前的方法通过引入额外的信息帮助提升精度:如使用双目相机捕获的双目图像对(Zhang等,2018)解决DP传感器存在孔径问题,引入图像重建损失(Pan等,2021)将离焦去模糊和深度估计结合起来、构造仿射不变的损失函数(Garg等,2019)估计具有仿射歧义性的深度。DP图像在离焦去模糊的应用中,Abuolaim和Brown(2020)的方法并没有考虑DP图像对的离焦视差与模糊量之间的关系,但在当时仍取得了令人满意的结果,可见DP潜在的额外信息能够帮助改善网络性能。未来可以考虑结合DP的成像原理,利用仿射歧义性与模糊量之间的关系,通过减少下采样、提升图像分辨率等方法来减少信息损失等思路,对DP在深度估计、离焦去模糊等领域开展更深入精准的研究。
2)对于学术界,DP原始数据难以获取。目前工业界中,DP传感器主要用于自动对焦。但是绝大多数工业界的制造厂商将DP图像对的解算过程集成到传感器芯片中,并不公开提供在自动对焦过程中产生的DP图像对。即使使用配备有DP传感器的相机,对于非制造商内部人士,仍无法获取DP图像对的原始数据。目前,只有Canon EOS 5D Mark IV和EOS R5相机以及Google Pixel系列手机为用户提供数据提取权限。Google为用户提供了一款APP能够直接使用Google Pixel系列手机拍摄DP图像对,操作简单,但是手机拍摄的图像无法大范围改变其光圈,景深的可改变范围也有限,且手机相机内参无法准确获取。Canon EOS 5D Mark IV单反相机和EOS R5微单相机费用较高且得到DP图像对的过程十分烦琐,需要耗费大量时间。Abuolaim和Brown(2020),Punnappurath等人(2020)和Pan等人(2021)均使用Canon EOS Mark IV采集数据,但是受限于处理烦琐,采集的数据集规模小。因此,仿真DP数据便成为目前较为经济、省时的解决办法。虽然Pan等人(2021)使用仿真器通过仿真NYU数据集的DP图像对构造其仿真数据集,但是仍存在数据集规模小、图像分辨率低以及部分仿真数据不符合成像原理等问题。此外,仿真数据对算法和设备算力的要求较高,仿真数据与真实数据之间如何缩小差异,如何提升网络由仿真到真实的泛化能力等,都是目前亟待解决的问题。
DP视图与双目图像对的相似性为深度估计、离焦模糊去除等问题的解决提供了新的思路。如何充分利用DP的离焦视差,将其与深度、离焦模糊和反射等因素联系起来,是解决这些问题首先要考虑的。其次,需要研究者们思考如何将DP应用于深度学习的神经网络中,提高网络精度并提升泛化能力。这可能是DP在相关领域取得突破的关键。DP图像对在计算机视觉领域具有重要的研究价值与应用前景,需要研究者们共同努力提供更多的开源数据,探索更多的研究领域。
6 结 语
全像素双核应用于自动对焦后,引起了成像工业界的一场变革,使得自动对焦技术摆脱了繁杂庞大的光学结构,并提升了复杂场景下的对焦速度。全像素双核初步应用在深度估计、反射去除和离焦模糊去除等计算机视觉领域表现不俗。但是限于全像素双核数据的稀缺,目前国内外缺乏对全像素双核的进一步研究及系统性的综述总结,也缺乏对全像素双核对焦和成像原理的详细研究。
本文系统调研总结了全像素双核自动对焦及其在计算机视觉的应用发展状况,充分涵盖领域内主要工作和技术内容,形成了国内首篇关于全像素双核的综述。本文对全像素双核自动对焦和成像原理进行了系统性的总结和归纳,有助于未来研究者理解全像素双核原理。对近年来全像素双核在计算机视觉的初步应用进行对比分析,其中既有全像素双核在各领域的研究进展和应用取得的突出成果,也有其存在的一些问题和挑战。总的来说,全像素双核具有很重要的应用价值,值得电子成像、工业机器视觉和计算机智能视觉等相关领域关注。作者希望本文能够为推进全像素双核技术及其在电子成像、工业视觉检测和计算机视觉等领域的深入研究与应用发展有所帮助和启发。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
房地产导刊(2022年1期)2022-02-28
中学生数理化·八年级物理人教版(2022年11期)2022-02-14
中学生数理化·八年级物理人教版(2022年11期)2022-02-14
小型微型计算机系统(2022年1期)2022-01-21
中学生数理化·八年级物理人教版(2021年11期)2021-12-06
中学生数理化·八年级物理人教版(2021年11期)2021-12-06
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
计算机测量与控制(2017年6期)2017-07-01
现代计算机(2016年3期)2016-09-23